

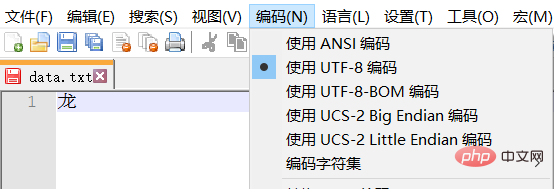
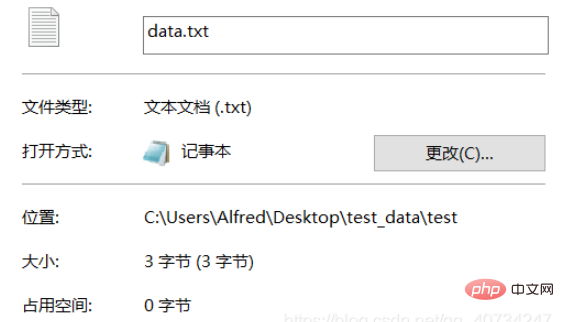
注: テスト テキストは UTF-8 でエンコードされており、中国語の文字は通常 3 バイトを占めます。 GBK の漢字は通常 2 バイトを占めます。
import os
# 对于单个文件进行操作的函数,如果需要对文件夹进行操作,可以使用一个函数包装它,这样不用修改本函数,即达到扩展的目的了。
def transfer_encode(source_path, target_path, source_encode='GBK', target_encode='UTF-8'):
with open(source_path, mode='r', errors='ignore', encoding=source_encode) as source_file: # 读取文件时,如果直接忽略报错,则程序正常执行,但是文件已经损坏了。
with open(target_path, mode='w', encoding=target_encode) as target_file: # 所以,应该捕获异常,停止程序执行。
line = source_file.readline()
while line != '':
target_file.write(line)
line = source_file.readline()
print("Execute End!")
# 这个函数的功能和上面是一样的,区别在于它是以二进制读取的,然后解码、转码再写入的
def transfer_encode2(source_path, target_path, source_encode='GBK', target_encode='UTF-8'):
with open(source_path, mode='rb') as source_file:
with open(target_path, mode="wb") as target_file:
bs = source_file.read(1024)
while len(bs) != 0:
target_file.write(bs.decode(source_encode).encode(target_encode))
bs = source_file.read(1024)
print("Execute End!")
source_path = r'C:\Users\Alfred\Desktop\test_data\test\data.txt'
target_path = r'C:\Users\Alfred\Desktop\test_data\test\data1.txt'
transfer_encode(source_path=source_path, target_path=target_path, source_encode="UTF-8", target_encode="GBK")
# transfer_encode2(source_path=source_path, target_path=target_path)
# 在cmd中使用 type命令,可以查看文件的内容,并且使用cmd默认的编码。
# 使用 chcp 命令可以查看当前使用的编码的数字编号コンソール出力 この関数実行の出力は意味不明ですが、変換されたか知りたい実行されましたので、印刷されます。

テスト フォルダー data1.txt は、変換およびエンコードされたテキストです。
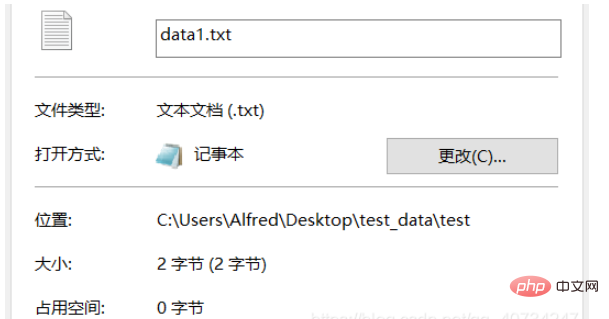
龙」という漢字が表示されます。そこで、ここでは別のアプローチと別の視聴方法を使用します。
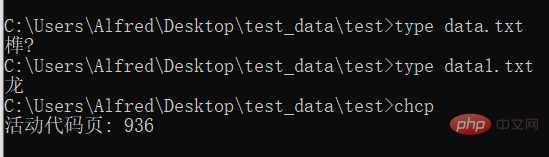
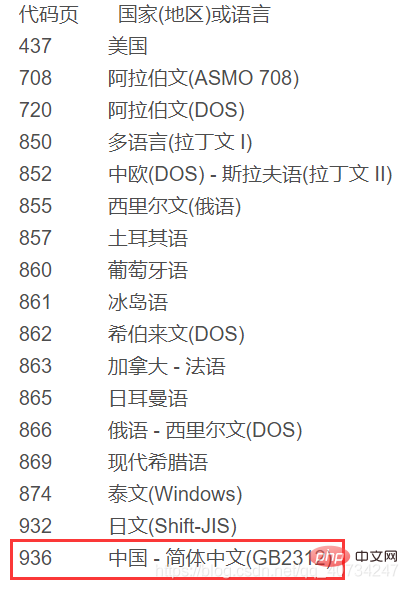
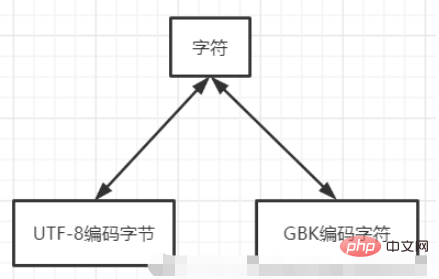
文字は乗り換え駅の機能に似ています。 ある文字セットを直接使用して別の文字セットの内容を読み取ると、上記の cmd に表示される文字化けが発生します。

以上がPython でのテキスト ファイル変換エンコーディングの問題を解決するにはどうすればよいですか?の詳細内容です。詳細については、PHP 中国語 Web サイトの他の関連記事を参照してください。
















![[Web フロントエンド] Node.js クイック スタート](https://img.php.cn/upload/course/000/000/067/662b5d34ba7c0227.png)



