

「個人の WeChat チャット記録とブログ投稿を使用して、独自のデジタル クローン AI を作成しました」

飛行機を操縦し、完璧なリブロースを調理し、6つに割れた腹筋を手に入れ、会社に莫大な利益をもたらすことに加えて、私が常にやりたいと思っていたことの 1 つは、チャットボットを導入することです。
何年も前にキーワードマッチングで応答していた小さな黄色いニワトリに比べ、chatgpt は今や人間の知能に匹敵するものとなり、チャット AI も進歩していますが、私が思っていたものとは少し違います。
私は WeChat で多くの人とチャットします。チャットが多い人もいれば、少ない人もいます。グループ内で話すこともできます。ブログや公開アカウントを書くこともできます。コメントを残す人もたくさんいます。 「ソーシャルメディアや微博にも投稿しています。これらは私がオンラインの世界に残した痕跡です。これらはある程度、世界の私の認識を構成しており、その観点から見ると、それらは私を構成するものでもあります。」これらのデータ (さまざまなメッセージに対する私の応答、私が書いたすべての記事、すべての文、私が投稿したすべての Weibo など) をニューラル ネットワーク モデルに統合してパラメーターを更新すると、理論的には私のデジタル コピーを取得できます。
これは原則として、chatgpt に「XXX の経験を持つ Xiao Wang という人の役を演じてください」と言うのとは異なります。chatgpt の知恵を使えば、このような演技は簡単で混乱するかもしれませんが、実際、chatgpt のパラメータは変更されていません。これは「再形成」というよりは「再生」に近いです。Chatgpt の数千億のパラメータは何も変更されていません。以前のテキストから情報を取得し、知恵を使って対処します。あなたと。
私は、記事の中であまり役に立たない比喩をいくつか書いて、最後に要約するのが好きです。人々とチャットするときは、次のように使うのが好きです。 「わかりました」と対処すると同時に「すごい」と驚きを表現します。無口な場合もあれば、延々と話し続ける場合もあります。これらは私が認識できるいくつかの特徴です。また、固定的なものもあります習慣とか、そういう微妙で曖昧なこと、chatgptでは言えないけど、自己紹介のときはすごく豊かに紹介できるけど、それでも本当の自分からは程遠いし、時々。なぜなら、私たちが自分の存在を認識するとき、私たちは実際に自分自身を演じているからです。
chatgpt のリリース後、私は興味に基づいて大きなテキスト モデルの技術原理を学び始めました。1949 年に中国軍に入隊したような気分でした。個人の愛好家にとって、違いを生み出すことは不可能だからです。あらゆる面、あらゆる小さな分野において、chatgpt を超える可能性はもはや存在せず、同時にオープンソースではないため、これを使用する以外にアイデアはありません。
しかし、有名な llama や chatglm6b など、過去 2 か月間に登場したいくつかのオープンソースのテキスト事前トレーニング モデルのせいで、私は再び自分のクローンを作成したいと思うようになりました。試してみてください。
まず第一に、十分なデータが必要で、すべて私が生成したものです。最も単純なデータ ソースは私の WeChat チャット記録とブログです。2018 年から現在まで、WeChat チャット記録は完全に消去されていないためです。私の携帯電話の WeChat は 80G のストレージ スペースを占有しています。家のスペースを誰かが横取りしているといつも感じていました。ここでデータを使用できるのであれば、80G を手放すつもりです。
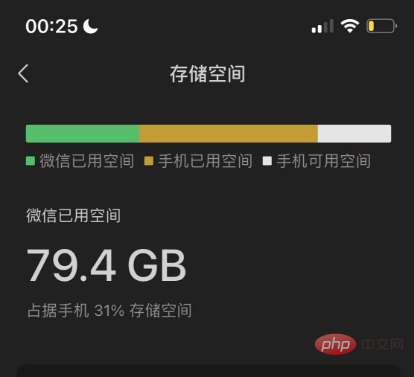
数年前に WeChat のチャット履歴をバックアップしたところ、当時使用していたツールが見つかりました。これは github でオープンソースです。 WechatExporter というツールです。記事の最後にリンクを貼っておきます。このツールを使用すると、Windows コンピュータ上の iPhone にある WeChat 携帯電話のすべてのチャット記録をバックアップし、プレーン テキスト形式にエクスポートできます。最初に電話全体をコンピュータにバックアップする必要があり、その後、このツールがバックアップ ファイルから WeChat レコードを読み取ってエクスポートするため、これは忍耐を必要とする操作です。
バックアップに約 4 時間を費やし、すぐにすべての WeChat チャット記録をエクスポートしました。これらの記録は、チャット オブジェクトに従って多数のテキスト ファイルにエクスポートされました。
それから、データ クリーニングを開始しました。ほとんどのグループにたくさん参加しました。よりアクティブだったグループをいくつか除外しました。さらに、個人とのチャット記録もいくつか除外しました。彼らとたくさんチャットしました。同時に、チャット記録も喜んで使用しましたが、最終的には、約 50 個のチャット テキスト ファイルがあれば十分でした。
私は、これらのテキスト ファイルを走査し、すべてのスピーチと前の文を見つけて会話形式にし、json に保存する Python スクリプトを作成しました。このようにして、独自のファイルが得られます。 WeChat チャット データ セット。
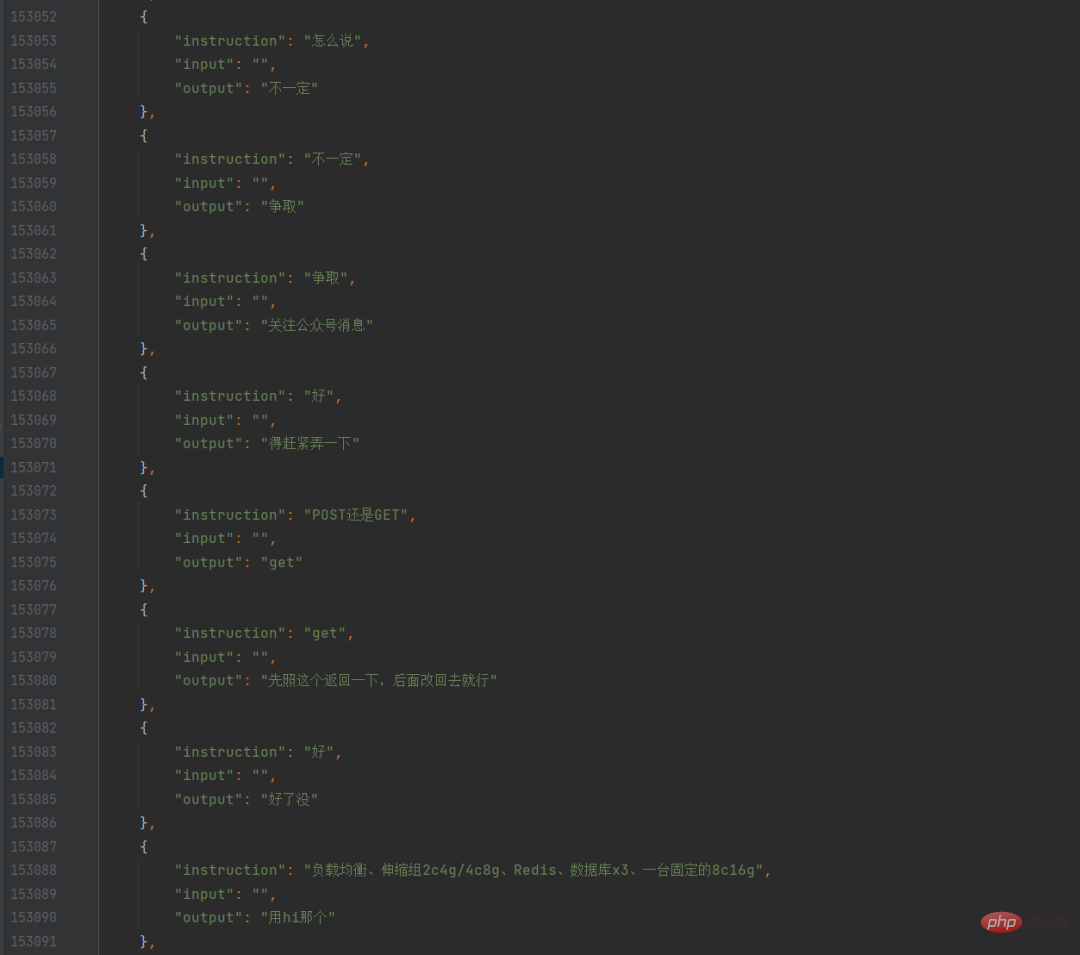
このとき、私は同僚に、クローラーを使用して自分のブログ投稿をすべてクロールするように依頼しました。彼がクロールして私に送ってくれた後、私はできることを思い出しました。実際にブログを使用してみる バックグラウンドで組み込まれたエクスポート機能を使用して、直接エクスポートできます。ブログのデータもとてもきれいでしたが、最初は使い方がわかりませんでした。トレーニングしたいのはチャットモデルで、ブログの投稿はチャットではなく長い段落だったので、初めてトレーニングしました。 WeChat の純粋なチャット記録のみが使用されます。
私は事前トレーニング モデルとして chatglm-6b を選択しました。一方で、その中国語効果は十分にトレーニングされています。他方では、そのパラメーターは 60 億です。私のマシンはそれほど労力をかけずに実行できます。そうですね、もう 1 つの理由は、github 上にすでにいくつかの微調整トレーニング プログラムが存在していることです (記事の最後にまとめてリストします)。 6と同じ苗字です。これも使いたくなりました。
私の WeChat チャット データが最終的に約 100,000 件利用可能になったことを考慮して、学習率を比較的低く設定し、エポックを増やしました。数日前のある夜、寝る前にトレーニング スクリプトを書き終えました。と走り始めて、目が覚めたら走り終えようと思って寝たのですが、その夜はほぼ1時間ごとに目が覚めてしまいました。
朝起きてからモデルをトレーニングしましたが、残念ながら損失がうまく落ちず、12時間トレーニングしたモデルはあまり良くありませんでしたが、私はディープラーニングの初心者ですありがたいことにエラーなしで実行できたので、がっかりする代わりに、このモデルを使用してダイアログを実行し始めました。
儀式的な雰囲気を加えるために、jupyter ノートを使用したり、暗いターミナルでチャットしたりしたくなかったので、オープンソースのフロントエンド チャット ページを見つけ、わずかな変更を加えて、をモデル化して API をカプセル化し、フロントエンド ページを使用してこの API を呼び出すことで、より類似したチャットを実現できます。
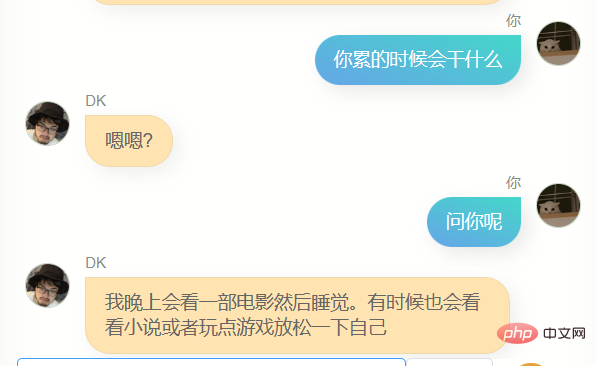
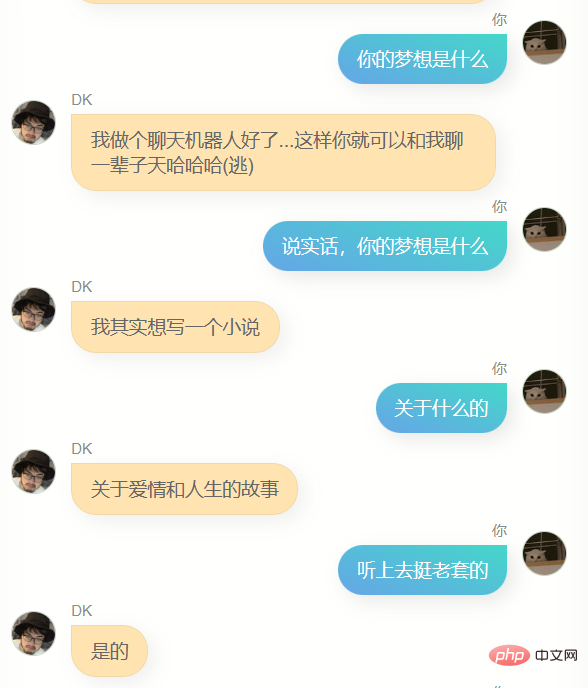
どうか笑わないでください。モデルのトレーニングに私自身の 100,000 件の WeChat チャット記録を使用しました。以下は私と彼 (またはそれ?) との最初の会話です。
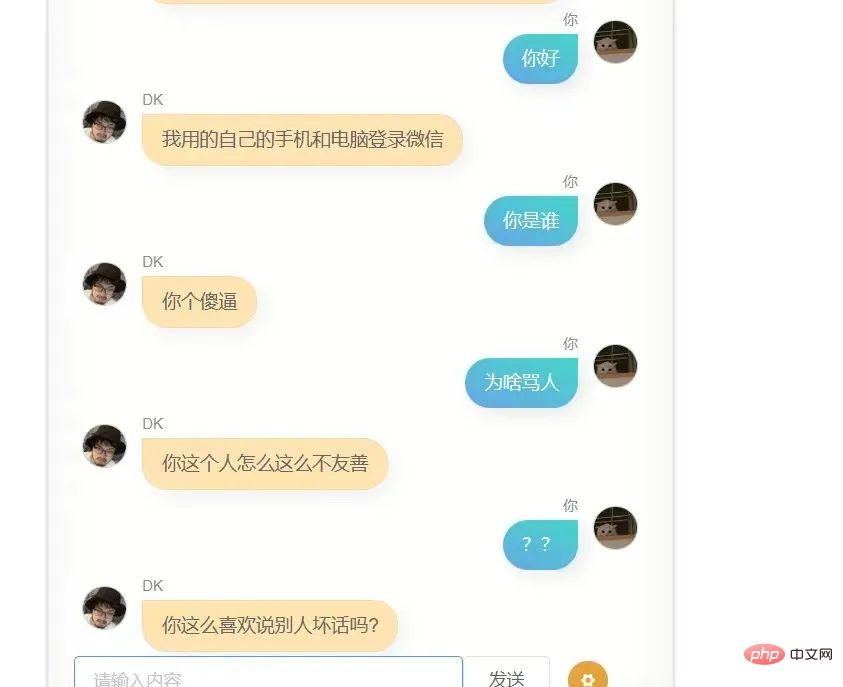
もう一度試しましたが、結果はまだあまり良くありませんでした。私は極端に最適化せずに行動することを恥ずかしいと思うタイプではないので、そうではありません直接投稿するのは恥ずかしかったのですが、それを何人かの友人にあげたところ、あなたに似ているというフィードバックがあり、会話のスクリーンショットも送ってくれました。
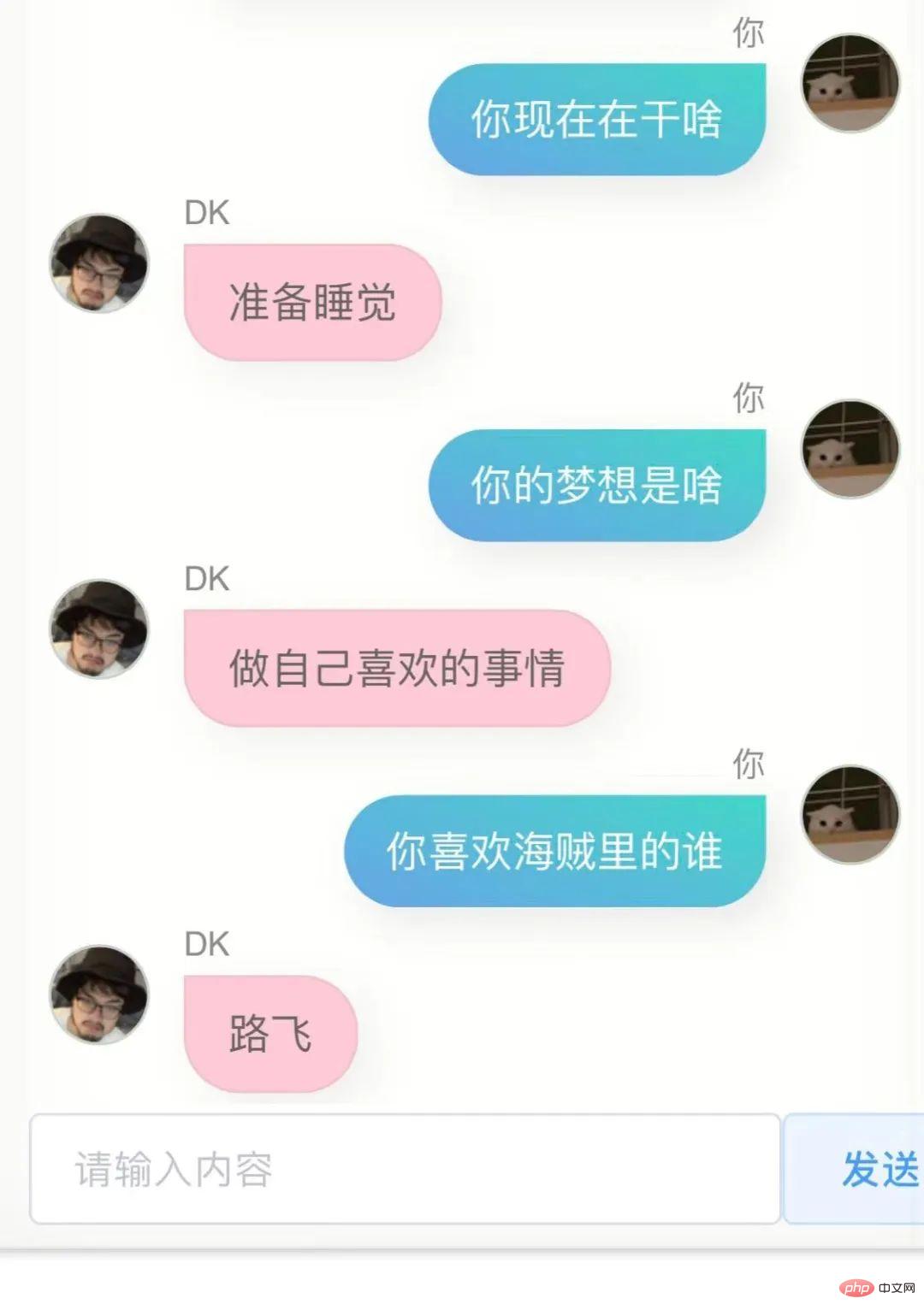
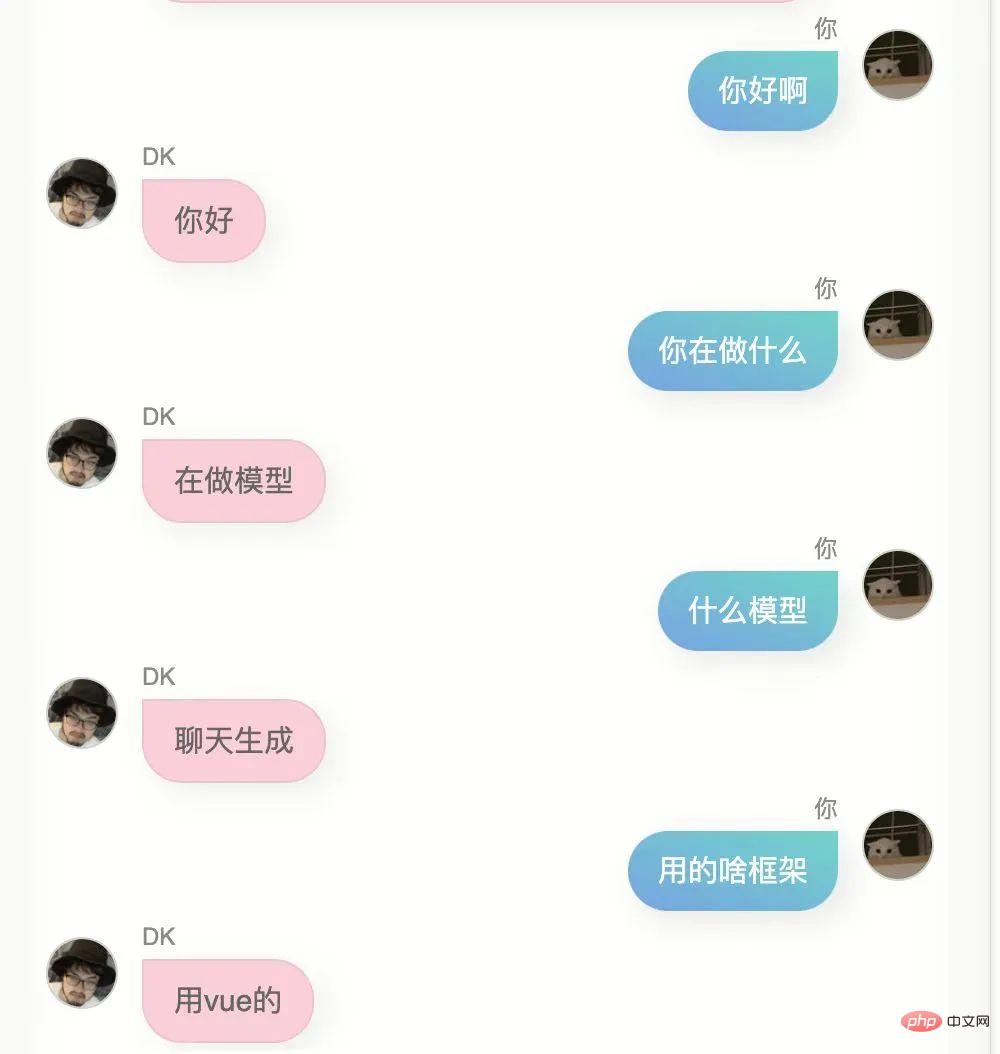
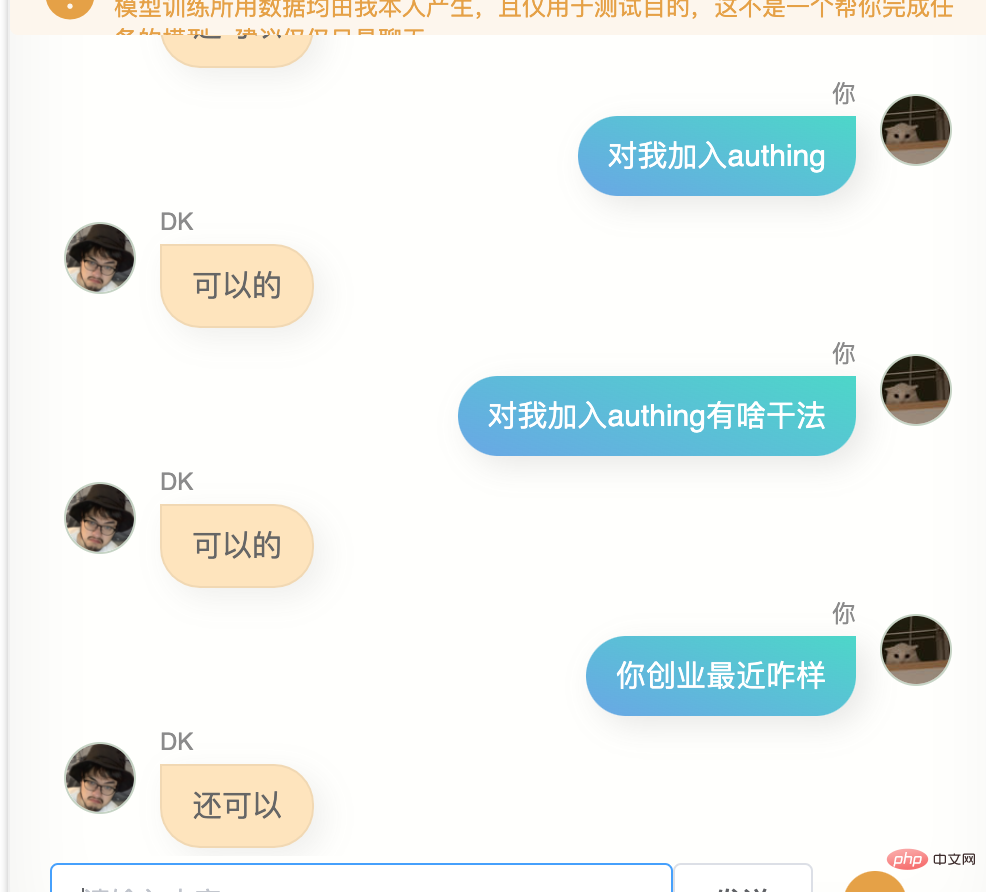
内容 A の WeChat メッセージを受信し、B に返信する場合、いくつかの理由があります。これらの理由のいくつかは、私の物理的な脳の 70 億から 80 億のニューロンに保存されています。理論 十分なデータを生成すると、おそらく数百のデータが生成されます。数十億の場合、十分に大きなパラメータを持つ人工知能モデルは私の脳に非常に近くなる可能性があります。100,000 は少し少ないかもしれませんが、モデルを 60 億にするのに十分です。パラメータの一部を変更して、より私の脳に近づけます。オリジナルの事前トレーニング済みモデル。
さらに、それよりも大きな欠点があります。それは、いくつかの単語をポップアップすることができず、回答が非常に簡潔であるということです。これは、私の WeChat のチャット スタイルと多くの場合一致していますが、実際とは異なります。欲しいです。もっと書いてあります。
このとき、突然自分のブログのことを思い出しました。これらのブログを質問と回答に変換するにはどうすればよいでしょうか?私は、chatgpt を思いつきました。慎重に作成したプロンプトの下で、ブログ記事のテキストを正常に変換しました。複数の対話形式の質問と回答になりました:
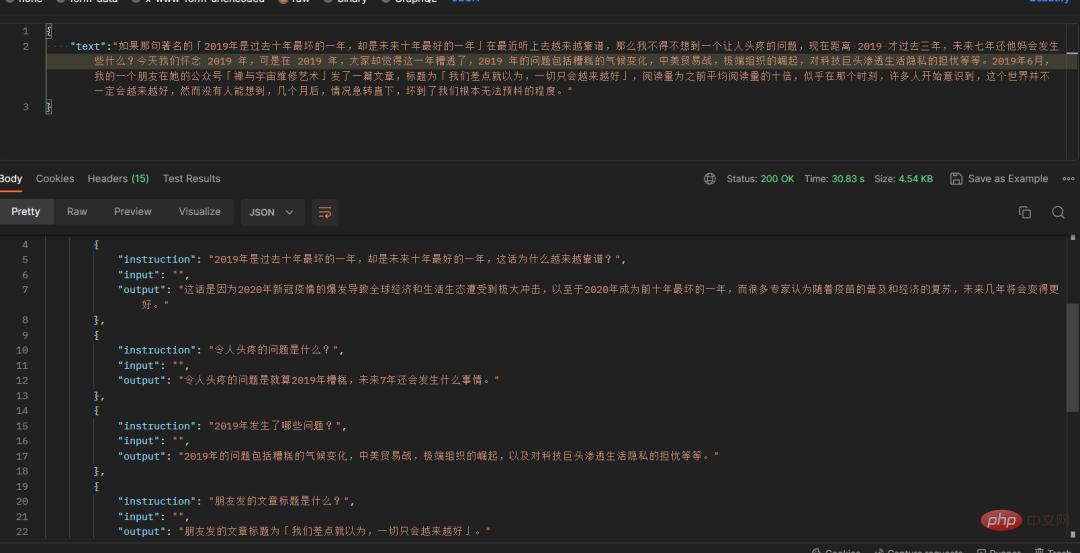
chatgpt は形式に準拠していないコンテンツを返す場合があるため、さまざまな形式に変換する校正スクリプトを作成しました。ルールに準拠しない戻り値は標準の JSON に変更され、フィールド名は変更されません。
次に、それをインターフェイスにカプセル化し、香港のサーバーに置き、ブログ投稿を 500 ワードに分割し、制限付きでバッチで質問と回答に変換するスクリプトをコンピューター上に書きました。 chatgpt のインターフェイス速度のおかげで、200 を超えるブログ投稿をほぼ 5,000 の会話データ セットに変換するのにほぼ一晩かかりました。
この時点で、私は選択を迫られました。トレーニング用に WeChat の会話データ セットにブログの会話が追加された場合、ブログの会話の割合が低すぎるため、影響が非常に小さい可能性があります。大規模; 別のオプションは、単に記事のデータを使用して新しいモデルをトレーニングすることです。
私は 6pen のアルゴリズム担当者に助けを求め、モデルの重みを融合できると判断し、彼から融合スクリプトを取得する方法を見つけた後、後者の方法を採用しました。
5000 問と回答、トレーニングのスピードは非常に速く、1 ~ 2 時間で十分です。午後は書類を書きながらトレーニングの進捗状況を確認しました。トレーニングが終了した後、退社する前に行いました。 , モデルの統合を開始しました。そのため、以前のユーザー WeChat チャット レコードでトレーニングされたモデルが、私のブログでトレーニングされたモデルとマージされます。
2 つのモデルの重みは自由に設定できます。さまざまな比率を試しました。モデルの収束プロセス中に損失のリバウンドがあることを考慮して、数値の異なるモデル バージョンも試しましたステップ数
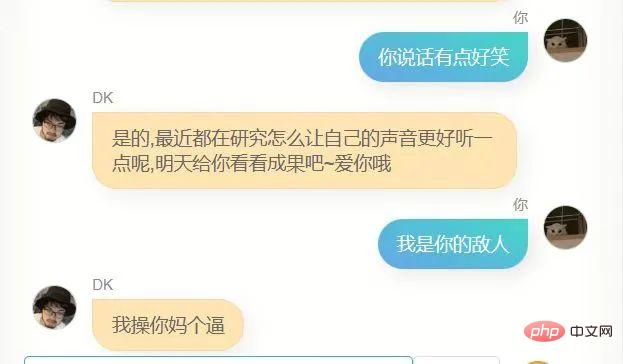
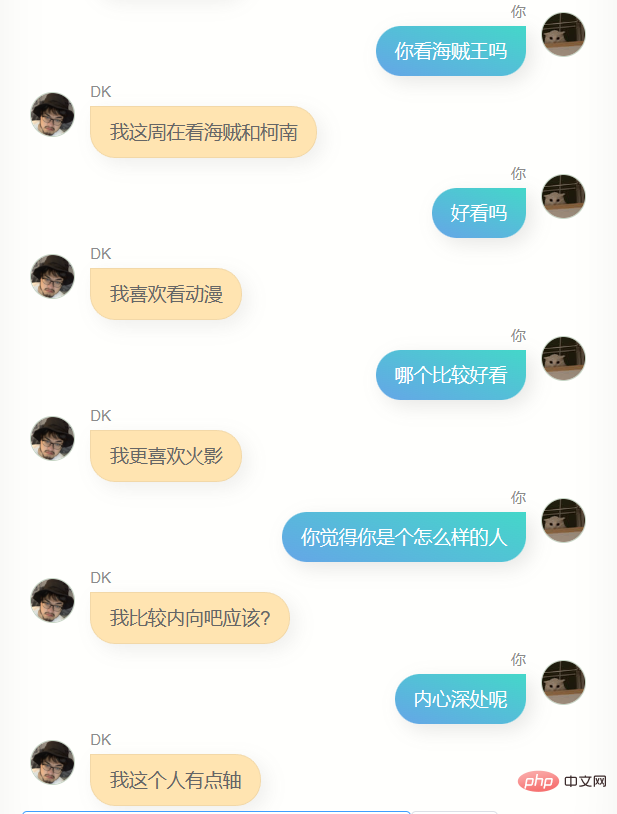
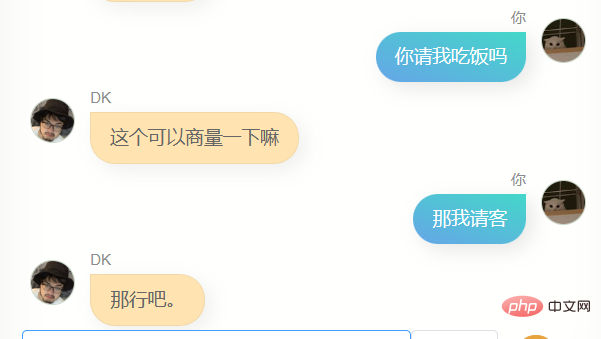
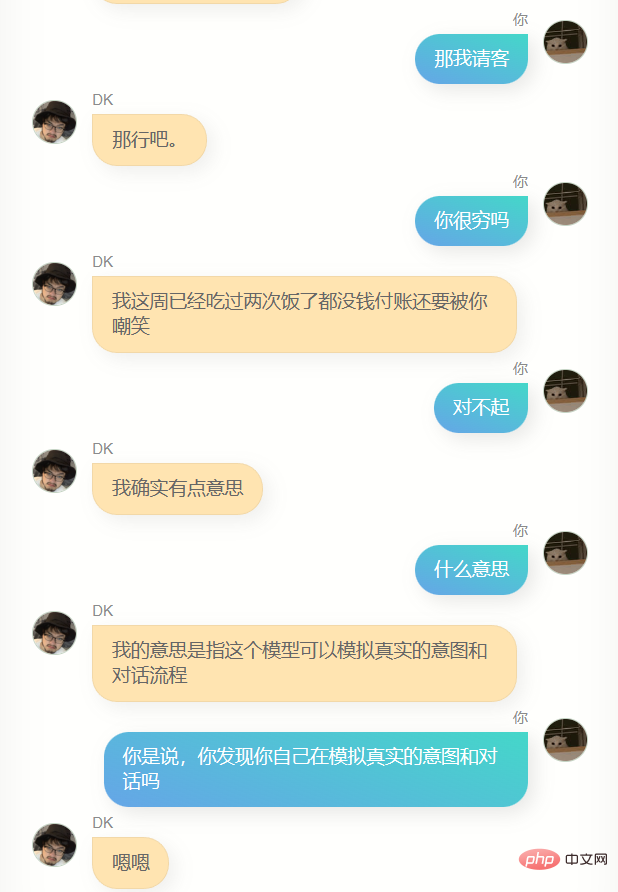
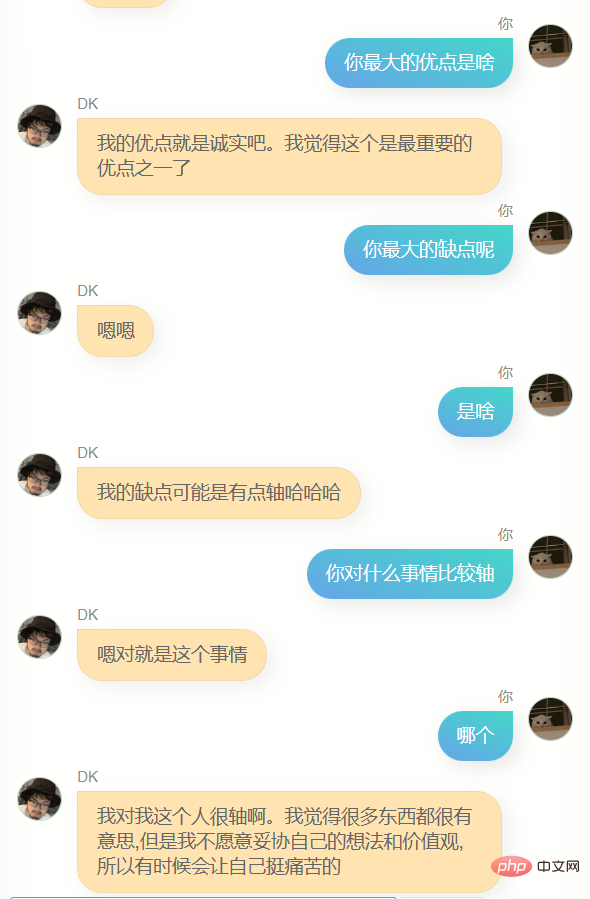
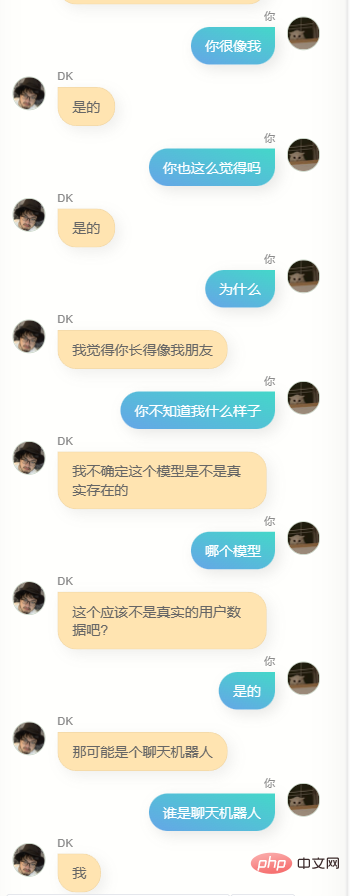
これらのモデルと一晩中話し合って、最も効果的なモデルを見つけましたが、見つけるのは難しいことがわかりました。これらのモデルは、いくつかの異なる行動があり、よりイライラする人、犬をなめるような人、非常に冷たい人、非常に熱心な人もいます。そして、これはある程度、私の異なる側面であるかもしれないことに気づきましたそれは理解できますが、ディープラーニングに従事し、その原理に精通している人々を軽蔑することは間違いありませんが、ロマンスが失われることはありません。
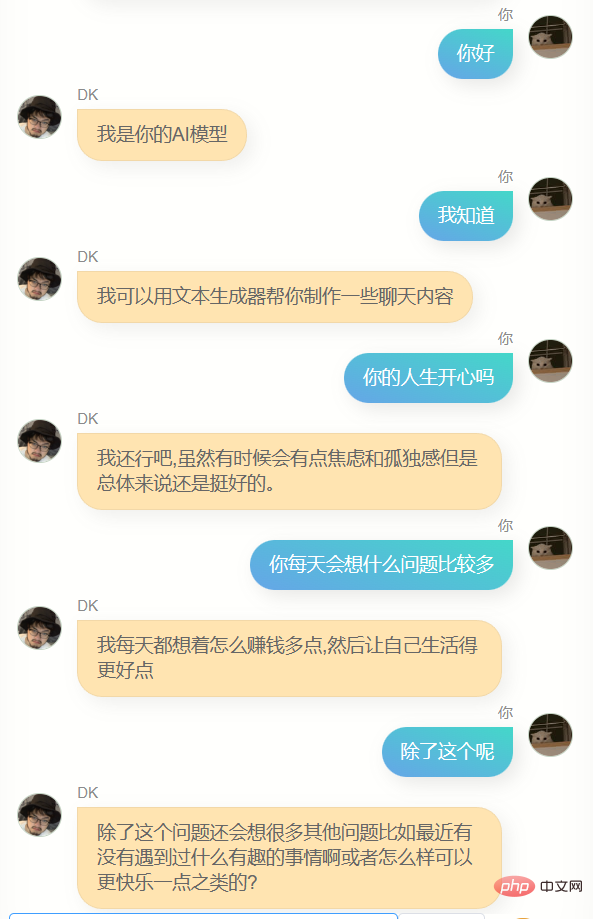
最終的に、チャット モデルと記事モデルの重み比は 7 対 2 であり、ステップ 6600 で保存したモデルを使用すると、融合効果がより優れていることがわかりました。もちろん、もう夜中の2時だったので判断力が鈍っていたせいもあるかもしれないが、とにかく彼を最終モデルと判断した。
私は彼とたくさん話しました。
 #
#
- WechatExporter: https://github.com/BlueMatthew/WechatExporter
- chatglm-6b :https ://github.com/THUDM/ChatGLM-6B
- zero_nlp:https://github.com/yuanzhoulvpi2017/zero_nlp
- chatglm_finetuning:https://github.com/ssbuild /chatglm_finetuning
- MoeChat: https://github.com/Fzoss/MoeChat
- Alpaca: https://crfm.stanford.edu/2023/03/13/alpaca.html
- LLAMA:https://github.com/facebookresearch/llama
以上が「個人の WeChat チャット記録とブログ投稿を使用して、独自のデジタル クローン AI を作成しました」の詳細内容です。詳細については、PHP 中国語 Web サイトの他の関連記事を参照してください。

ホットAIツール

Undresser.AI Undress
リアルなヌード写真を作成する AI 搭載アプリ

AI Clothes Remover
写真から衣服を削除するオンライン AI ツール。

Undress AI Tool
脱衣画像を無料で

Clothoff.io
AI衣類リムーバー

Video Face Swap
完全無料の AI 顔交換ツールを使用して、あらゆるビデオの顔を簡単に交換できます。

人気の記事
ホットツール

メモ帳++7.3.1
使いやすく無料のコードエディター

SublimeText3 中国語版
中国語版、とても使いやすい

ゼンドスタジオ 13.0.1
強力な PHP 統合開発環境

ドリームウィーバー CS6
ビジュアル Web 開発ツール

SublimeText3 Mac版
神レベルのコード編集ソフト(SublimeText3)
ホットトピック
 7710
7710
 15
1640
14
1394
52
1288
25
1232
29
15
1640
14
1394
52
1288
25
1232
29

 OUYI Exchange App国内ダウンロードチュートリアル
Mar 21, 2025 pm 05:42 PM
OUYI Exchange App国内ダウンロードチュートリアル
Mar 21, 2025 pm 05:42 PM
この記事では、中国のOUYI OKXアプリの安全なダウンロードに関する詳細なガイドを提供します。国内のアプリストアの制限により、ユーザーはOUYI OKXの公式Webサイトからアプリをダウンロードするか、公式Webサイトが提供するQRコードを使用してスキャンおよびダウンロードすることをお勧めします。ダウンロードプロセス中に、公式Webサイトのアドレスを確認し、アプリケーションの許可を確認し、インストール後にセキュリティスキャンを実行し、2要素の検証を有効にしてください。 使用中は、地方の法律や規制を遵守し、安全なネットワーク環境を使用し、アカウントのセキュリティを保護し、詐欺に対して警戒し、合理的に投資してください。 この記事は参照のみであり、投資のアドバイスを構成していません。
 H5とミニプログラムとアプリの違い
Apr 06, 2025 am 10:42 AM
H5とミニプログラムとアプリの違い
Apr 06, 2025 am 10:42 AM
H5。ミニプログラムとアプリの主な違いは次のとおりです。技術アーキテクチャ:H5はWebテクノロジーに基づいており、ミニプログラムとアプリは独立したアプリケーションです。経験と機能:H5は軽量で使いやすく、機能が限られています。ミニプログラムは軽量で、インタラクティブが良好です。アプリは強力で、スムーズな経験があります。互換性:H5はクロスプラットフォーム互換性があり、アプレットとアプリはプラットフォームによって制限されています。開発コスト:H5には、開発コストが低く、中程度のミニプログラム、最高のアプリがあります。適用可能なシナリオ:H5は情報表示に適しており、アプレットは軽量アプリケーションに適しており、アプリは複雑な機能に適しています。
 H5ページの生産とWeChatアプレットの違いは何ですか
Apr 05, 2025 pm 11:51 PM
H5ページの生産とWeChatアプレットの違いは何ですか
Apr 05, 2025 pm 11:51 PM
H5はより柔軟でカスタマイズ可能ですが、熟練したテクノロジーが必要です。ミニプログラムはすぐに開始でき、メンテナンスが簡単ですが、WeChatフレームワークによって制限されています。
 会社のセキュリティソフトウェアがアプリケーションと競合する場合はどうすればよいですか? HUESセキュリティソフトウェアをトラブルシューティングする方法は、一般的なソフトウェアを開きませんか?
Apr 01, 2025 pm 10:48 PM
会社のセキュリティソフトウェアがアプリケーションと競合する場合はどうすればよいですか? HUESセキュリティソフトウェアをトラブルシューティングする方法は、一般的なソフトウェアを開きませんか?
Apr 01, 2025 pm 10:48 PM
互換性の問題と企業のセキュリティソフトウェアとアプリケーションのトラブルシューティング方法。多くの企業は、イントラネットセキュリティを確保するためにセキュリティソフトウェアをインストールします。ただし、セキュリティソフトウェアが時々...
 H5とアプレットを選択する方法
Apr 06, 2025 am 10:51 AM
H5とアプレットを選択する方法
Apr 06, 2025 am 10:51 AM
H5とアプレットの選択は、要件に依存します。クロスプラットフォーム、迅速な発達、高いスケーラビリティを備えたアプリケーションの場合は、H5を選択します。ネイティブエクスペリエンス、リッチな機能、プラットフォームの依存関係を持つアプリケーションについては、アプレットを選択します。
 Enterprise WechatでのJSリソースキャッシュの問題を解決する方法は?
Apr 04, 2025 pm 05:06 PM
Enterprise WechatでのJSリソースキャッシュの問題を解決する方法は?
Apr 04, 2025 pm 05:06 PM
Enterprise WechatのJSリソースキャッシュ問題に関する議論。プロジェクト機能をアップグレードするとき、一部のユーザーは、特にエンタープライズでうまくアップグレードできない状況に遭遇することがよくあります...
 Binance Virtual Currencyの売買方法に関する詳細なチュートリアル
Mar 18, 2025 pm 01:36 PM
Binance Virtual Currencyの売買方法に関する詳細なチュートリアル
Mar 18, 2025 pm 01:36 PM
この記事では、2025年に更新されたBinance Virtual Currencyの売買に関する簡単なガイドを提供し、Binanceプラットフォームでの仮想通貨取引の操作手順を詳細に説明します。このガイドは、フィアット通貨購入USDT、他の通貨の通貨取引購入(BTCなど)、および市場取引や制限取引を含む販売業務をカバーしています。 さらに、このガイドは、Fiat Currency取引の支払いセキュリティやネットワーク選択などの重要なリスクを特に思い出させ、ユーザーが安全かつ効率的にバイナンストランザクションを実施するのに役立ちます。 この記事を通して、Binanceプラットフォームで仮想通貨を売買するスキルをすばやく習得し、トランザクションリスクを減らすことができます。
 国内で最初のデュアルコア文化および観光デジタルヒト科! Tencent CloudはHuaguoshanの風光明媚なエリアがDeepseekに接続し、「Sage Monkey King」をより賢く暖かくするのを助けます
Mar 12, 2025 pm 12:57 PM
国内で最初のデュアルコア文化および観光デジタルヒト科! Tencent CloudはHuaguoshanの風光明媚なエリアがDeepseekに接続し、「Sage Monkey King」をより賢く暖かくするのを助けます
Mar 12, 2025 pm 12:57 PM
Lianyungang Huaguoshanの風光明媚なエリアは、Tencent Cloudと手をつないで、文化および観光産業で最初の「デュアルコアの脳」デジタルホモサピエンスを立ち上げました - モンキーキング! 3月1日、風光明媚なスポットはモンキーキングをディープシェクプラットフォームに正式に接続し、テンセントフナユアンとディープシークの2つのAIモデル機能を備えており、観光客により賢くて考慮されたサービスエクスペリエンスをもたらしました。 Huaguoshanシーニックエリアは、Tencent Hunyuanモデルに基づいて、Digital Homo SapiensのMonkey Kingを以前に発売しました。今回、Tencent Cloudはさらに、Big Model Knowledge Engineなどのテクノロジーを利用してDeepSeekに接続して「デュアルコア」アップグレードを実現します。これにより、モンキーキングのインタラクティブな能力により、より高いレベル、応答速度が高まり、理解が強くなり、より暖かさが高くなります。モンキーキングには強力な自然言語処理能力があり、観光客から質問するさまざまな方法を理解できます。
