

機械学習の分野では、一部のモデルは非常に効果的ですが、その理由は完全にはわかりません。対照的に、比較的よく理解されている研究分野の中には、実際に適用できる範囲が限られているものもあります。この記事では、機械学習の有用性と理論的理解に基づいて、さまざまなサブフィールドの進歩を探ります。

ここでの実験的有用性は、方法の適用範囲の広さ、実装の容易さ、そして最も重要な要素である現実の有用性を考慮した包括的な考慮事項です。世界。いくつかの方法は非常に実用的であるだけでなく、広範囲に応用できますが、いくつかの方法は非常に強力ではありますが、特定の領域に限定されています。信頼性があり、予測可能で、大きな欠陥がない方法は、より有用性が高いと考えられます。
いわゆる理論的理解とは、モデル手法の解釈可能性、つまり、入力と出力の関係は何か、期待される結果を得るにはどうすればよいか、この手法の内部メカニズムは何か、などを考慮することです。そして、文書の深さと完全性を考慮した方法を検討してください。
理論的理解の度合いが低い方法では、通常、実装においてヒューリスティックな方法や多数の試行錯誤方法が使用されます。理論的理解の度合いが高い方法では、多くの場合、強力な理論的基盤と予測可能な結果を伴う定型的な実装が行われます。 。線形回帰などの単純な手法では理論上の上限が低くなりますが、深層学習などのより複雑な手法では理論上の上限が高くなります。ある分野の文献の深さと完全性に関しては、その分野はその分野の仮定の理論的な上限に照らして評価されますが、これは部分的に直感に依存します。
効用マトリックスを 4 つの象限に構成できます。軸の交点は、平均的な理解力と平均的な効用を備えた仮想の参照領域を表します。このアプローチにより、フィールドが配置されている象限に応じて定性的な方法でフィールドを解釈できるようになります。次の図に示すように、特定の象限内のフィールドは、その象限の特性の一部またはすべてを持つ可能性があります。
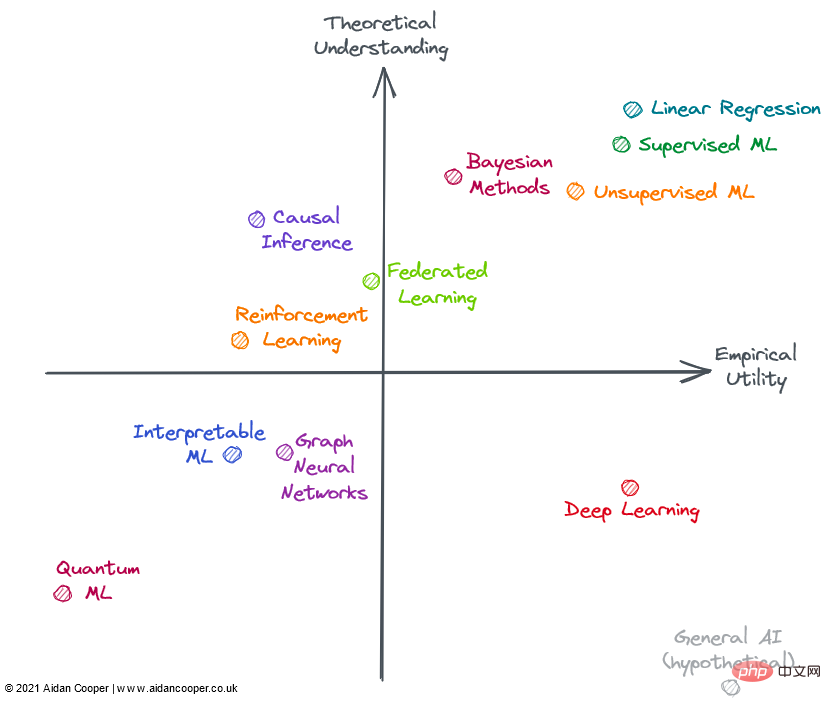
一般に、有用性と理解には緩やかな関連性があり、理論的理解の程度が低い方法よりも、理論的理解の度合いが高い方法の方が有用であると考えられます。 。これは、ほとんどのフィールドが左下の象限または右上の象限に存在する必要があることを意味します。左下から右上の対角線から離れた領域は例外を表します。通常、初期の研究理論を実際の応用に移すには時間がかかるため、実際の実用性は理論よりも遅れるはずです。したがって、この対角線は原点を直接通過するのではなく、原点の上にある必要があります。
上の図のすべてのフィールドが機械学習 (ML) に完全に含まれているわけではありませんが、すべて ML のコンテキストで適用できるか、機械学習と密接に関連しています。それ 。評価される領域の多くは重複しているため、明確に説明することはできません。強化学習、フェデレーテッド ラーニング、グラフ ML の高度な手法は、多くの場合、深層学習に基づいています。したがって、私はディープラーニング以外の理論的および実践的な有用性について検討します。
線形回帰は、シンプルで理解しやすく、効率的な手法です。過小評価され無視されることが多いですが。ですが、その用途の広さと徹底的な理論的根拠により、図の右上隅に配置されています。
従来の機械学習は、高度な理論的理解と実用性を備えた分野に発展しました。勾配ブースト決定ツリー (GBDT) などの複雑な ML アルゴリズムは、一部の複雑な予測タスクにおいて線形回帰よりも優れたパフォーマンスを発揮することが多いことが示されています。これは確かにビッグデータの問題に当てはまります。おそらく、過剰にパラメータ化されたモデルの理論的理解にはまだギャップがありますが、機械学習の実装は繊細な方法論的なプロセスであり、うまく行えば、モデルは業界内で確実に実行できます。
ただし、余分な複雑さと柔軟性により、いくつかのエラーが発生することがあります。そのため、私は機械学習を線形回帰の左側に置きました。一般に、教師あり機械学習は教師なし機械学習よりも洗練され、影響力がありますが、どちらの方法も異なる問題空間を効果的に解決します。
ベイジアン手法は、より一般的な古典的な統計手法よりも優れていると宣伝する実践者の間で熱狂的な支持を得ています。ベイジアン モデルは、点推定だけでは不十分で不確実性の推定が重要な場合、データが限られているか欠損が大きい場合、データ生成プロセスがモデル時間に明示的に含まれることを理解している場合など、特定の状況で特に役立ちます。ベイズ モデルの有用性は、多くの問題では点推定で十分であり、人々は単純に非ベイズ手法をデフォルトで使用するという事実によって制限されます。さらに、従来の ML では不確実性を定量化する方法があります (ほとんど使用されないだけです)。多くの場合、データ生成メカニズムや事前分布を考慮せずに、単純に ML アルゴリズムをデータに適用する方が簡単です。ベイジアン モデルは計算コストも高く、理論の進歩によってサンプリングと近似の方法が改善されれば、さらに有用性が高まるでしょう。
ほとんどの分野の進歩とは対照的に、理論的側面では進歩が根本的に難しいことが証明されているにもかかわらず、ディープラーニングはいくつかの驚くべき成功を収めています。ディープ ラーニングは、あまり知られていないアプローチの特徴の多くを体現しています。モデルは不安定で、信頼性の高い構築が難しく、弱いヒューリスティックに基づいて構成され、予測できない結果が生成されます。ランダムシードの「微調整」のような疑わしい慣行は一般的であり、作業モデルの仕組みを説明するのは困難です。しかし、ディープラーニングは進歩を続けており、コンピュータービジョンや自然言語処理などの分野で超人的なパフォーマンスレベルに達し、自動運転などの他の方法では理解できないタスクの世界を切り開きます。
仮に、一般的な AI が右下隅を占めることになります。定義上、超知能は人間の理解を超えており、あらゆる問題の解決に使用できるためです。現時点では、これは思考実験としてのみ含まれています。
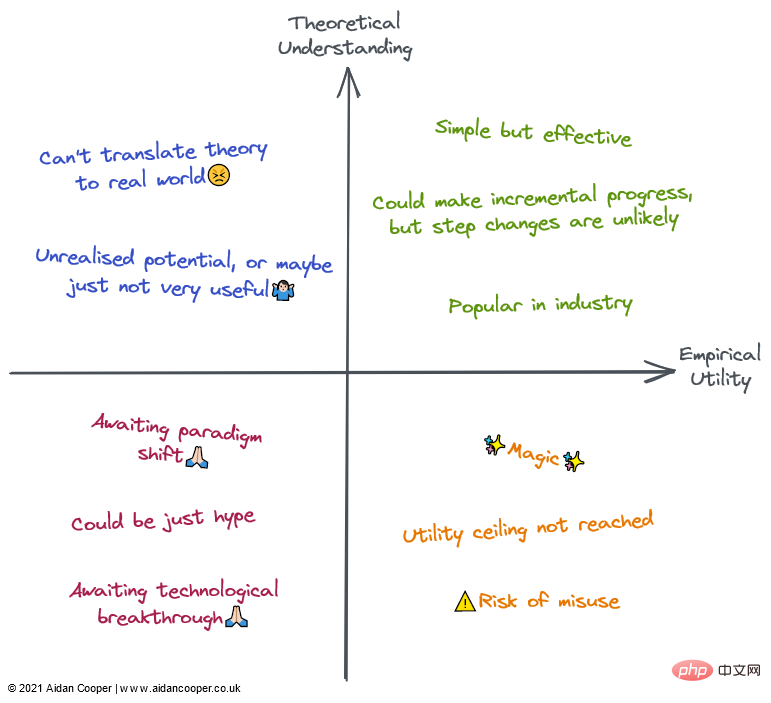
各象限の定性的な説明。フィールドは、対応する領域の説明の一部またはすべてによって説明できます。
ほとんどの形式の因果推論は機械学習ではありませんが、機械学習である場合もあります。 、予測モデルに常に興味を持っています。因果関係は、ランダム化比較試験 (RCT) と、観察データから因果関係を測定しようとするより洗練された因果推論の方法に分類できます。 RCT は理論的には単純で、厳密な結果が得られますが、多くの場合費用がかかり、現実世界で実施するのは不可能ではないにしても非現実的であるため、実用性は限られています。因果推論手法は基本的に何もせずに RCT を模倣するため、実行が非常に簡単になりますが、結果を無効にする可能性のある制限や落とし穴が数多くあります。全体として、因果関係は依然としてもどかしい追求であり、これらの質問がランダム化比較試験を通じて調査できる場合、またはそれらの質問が何らかのフレームワークにきちんと適合しない限り(たとえば、「自然実験」)。
Federated learning (FL) はクールなコンセプトですが、ほとんど注目されていません。おそらく、その最も魅力的なアプリケーションは多数のスマートフォン デバイスに配布する必要があるため、FL には 2 つのプレイヤーしかいません。実際に調査するには、Apple と Google が必要です。 。独自のデータセットをプールするなど、FL の他のユースケースも存在しますが、これらの取り組みを調整する際には政治的および物流上の課題があり、実際の有用性は制限されています。それでも、派手なコンセプトのように聞こえるもの (大まかに要約すると、「モデルにデータを入れるのではなく、モデルをデータに入れる」) ですが、FL は機能し、キーボード テキストの予測やパーソナライズされたニュースの推奨などの分野で応用できます。 FL の背後にある基本理論と技術は、FL をより広範に応用するには十分であると思われます。
強化学習 (RL) は、チェス、囲碁、ポーカー、DotA などのゲームにおいて、前例のないレベルの能力に到達しました。しかし、ビデオ ゲームやシミュレーション環境以外では、強化学習はまだ現実世界のアプリケーションに納得のいく形で応用されていません。ロボット工学は、RL の次のフロンティアであるはずでしたが、それは起こりませんでした。現実は、非常に制約されたおもちゃの環境よりも困難に思えました。そうは言っても、RL のこれまでの成果は心強いものであり、チェスが本当に好きな人なら、その有用性はさらに高いはずだと主張するかもしれません。私は、RL がマトリックスの右側に配置される前に、その潜在的な実用的なアプリケーションのいくつかを実現することを望みます。
グラフ ニューラル ネットワーク (GNN) は現在、機械学習の分野で非常に人気があり、多くの分野で満足のいく結果を達成しています。しかし、これらの例の多くでは、深層学習アーキテクチャと組み合わせた従来の構造化データを使用する代替手段よりも GNN が優れているかどうかは不明です。ケモインフォマティクスにおける分子など、データが自然にグラフ構造になっている問題では、より説得力のある GNN 結果が得られるようです (ただし、これらは一般にグラフに関連しない方法よりも劣ります)。ほとんどの分野に比べて、GNN を大規模にトレーニングするためのオープンソース ツールと業界で使用されている社内ツールとの間には大きなギャップがあるようであり、そのため、これらの壁に囲まれた庭園の外で大規模な GNN の実現可能性が制限されています。分野の複雑さと広さは理論上の上限が高いことを示唆しているため、GNN が成熟し、特定のタスクに対する利点を説得力を持って実証する余地があり、それがより大きな実用性につながるはずです。現在、グラフは既存のコンピューティング ハードウェアに自然に適合しないため、GNN も技術の進歩から恩恵を受ける可能性があります。
Interpretable Machine Learning (IML) は、引き続き注目を集めている重要かつ有望な分野です。 SHAP や LIME などのテクノロジーは、ML モデルを調べるための非常に便利なツールになっています。ただし、採用が限られているため、既存のアプローチの有用性はまだ完全には実現されておらず、確実なベスト プラクティスと実装ガイドラインはまだ確立されていません。ただし、IML の現在の主な弱点は、私たちが本当に関心のある因果関係の質問に対処していないことです。 IML は、モデルがどのように予測を行うかを説明しますが、基礎となるデータがモデルとどのように因果関係があるのかについては説明しません (ただし、このように誤解されることがよくあります)。理論的に大きな進歩が見られる前は、IML の正当な用途はほとんどがモデルのデバッグ/監視と仮説生成に限定されていました。
量子機械学習 (QML) は私の操舵室のはるか外にありますが、現時点では、実行可能な量子コンピューターが利用可能になるのを辛抱強く待つという仮説的な演習のようです。それまで、QML は左下隅に目立たなかった。
この分野が理論的理解と経験的有用性マトリックスを横断する際に経由する 3 つの主なメカニズムがあります (図 2)。
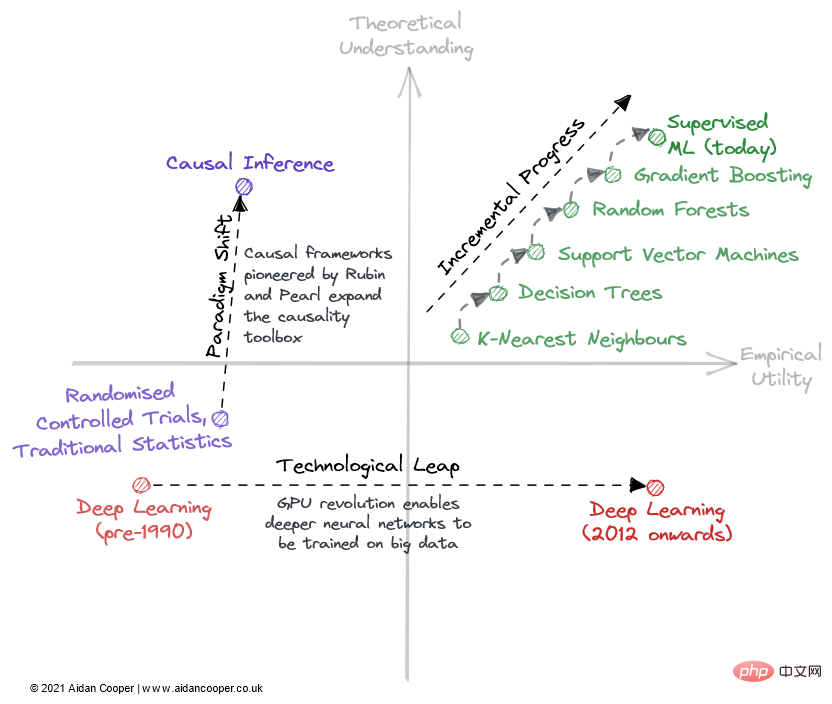
フィールドをマトリックス内で走査する方法の例。
プログレッシブ進行は、マトリックスの右側のインチ フィールドを上に移動するゆっくりとした安定した進行です。その良い例が、過去数十年にわたる教師あり機械学習です。その間、ますます効果的な予測アルゴリズムが洗練され、採用され、今日私たちが享受している強力なツールボックスが得られました。技術の飛躍やパラダイムシフトによる劇的な動きの時期を除いて、すべての成熟した分野では段階的な進歩が現状維持です。
技術の飛躍の結果、一部の分野では科学の進歩に段階的な変化が見られました。 *ディープ ラーニング* の分野は、2010 年代のディープ ラーニングの流行の 20 年以上前に発見された理論的基礎によって解明されたわけではありません。その復活を促進したのは、コンシューマ GPU によって可能になった並列処理でした。技術的な飛躍は通常、経験的効用軸に沿った右へのジャンプとして現れます。ただし、テクノロジー主導の進歩のすべてが飛躍的なものであるわけではありません。今日の深層学習は、より多くのコンピューティング能力とますます専門化したハードウェアを使用して、ますます大規模なモデルをトレーニングすることによって達成される段階的な進歩によって特徴付けられます。
この枠組みにおける科学進歩の究極のメカニズムはパラダイムシフトです。トーマス・クーンが著書『科学革命の構造』で指摘したように、パラダイムシフトは科学分野の基本概念と実験実践における重要な変化を表しています。ドナルド・ルービンとジューデア・パールによって開拓された因果関係のフレームワークはその一例であり、因果関係の分野をランダム化比較試験や伝統的な統計分析から、因果推論の形でより強力な数学的学問へと高めています。パラダイムシフトは多くの場合、理解の上向きの動きとして現れ、それは有用性の増加に続いて、またはそれを伴うこともあります。
ただし、パラダイム変換は行列を任意の方向に横断できます。ニューラル ネットワーク (およびその後のディープ ニューラル ネットワーク) が従来の ML とは別のパラダイムとしての地位を確立したとき、これは当初、実用性と理解力の低下に相当しました。多くの新興分野は、このようにしてより確立された研究分野から分岐しています。
要約すると、将来起こるかもしれないと私が考えている推測的な予測をいくつか示します (表 1)。右上象限のフィールドは、成熟しすぎて大きな進歩が見られないため省略されています。
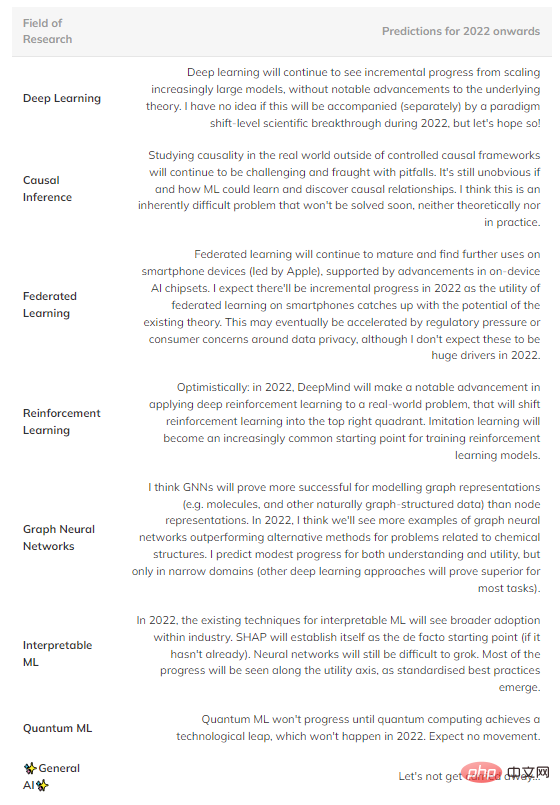
表 1: 機械学習のいくつかの主要分野における将来の進歩の予測。
しかし、個々の分野がどのように発展するかよりも重要な観察は、経験主義への全体的な傾向と、包括的な理論的理解を認める意欲の高まりです。
歴史的な経験から、一般に理論(仮説)が最初に現れ、その後アイデアが定式化されます。しかし、ディープラーニングは、これを覆す新しい科学プロセスをもたらしました。つまり、理論に注目する前に、メソッドは最先端のパフォーマンスを実証することが期待されます。経験的な結果が重要であり、理論はオプションです。
これにより、機械学習研究では、この分野で有意義に理論を進歩させるのではなく、単に既存の手法を変更し、ベースラインを超えるためにランダム性に依存するだけで最新の最先端を取得するという、体系的に広範なゲームが行われるようになりました。 。 結果。しかし、おそらくそれが、この機械学習ブームの新たな波に対して私たちが支払う代償なのかもしれません。
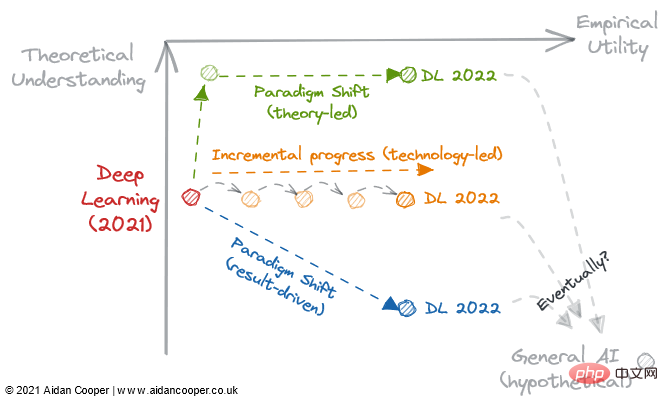
図 3: 2022 年のディープラーニング開発の 3 つの潜在的な軌道。
ディープラーニングが不可逆的に結果指向のプロセスになり、理論的な理解を任意性に追いやるかどうかは、2022 年が転換点になるかもしれません。次の質問を考慮する必要があります:
理論的なブレークスルーにより、私たちの理解は実用性に追いつき、深層学習を従来の機械学習のようなより構造化された分野に変えることができるでしょうか?
既存のディープ ラーニングの文献は、モデルをますます大きくするだけで、実用性を無限に高めるのに十分ですか?
それとも、経験的なブレークスルーは、私たちをウサギの穴のさらに奥深くに導き、たとえそれについてあまり知られていないとしても、実用性を高める新しいパラダイムに導くのでしょうか?
これらのルートの中に、一般的な人工知能につながるものはありますか?時間だけが教えてくれます。
以上が機械学習の理論的基盤の信頼性をどのように評価するか?の詳細内容です。詳細については、PHP 中国語 Web サイトの他の関連記事を参照してください。
















![[Web フロントエンド] Node.js クイック スタート](https://img.php.cn/upload/course/000/000/067/662b5d34ba7c0227.png)



