
 テクノロジー周辺機器
AI
LeCun は、ハードウェアの代替品として 600 ドルの GPT-3.5 を賞賛しています。スタンフォードの70億母数「アルパカ」が人気、LLaMAが驚異のパフォーマンス!
テクノロジー周辺機器
AI
LeCun は、ハードウェアの代替品として 600 ドルの GPT-3.5 を賞賛しています。スタンフォードの70億母数「アルパカ」が人気、LLaMAが驚異のパフォーマンス!
LeCun は、ハードウェアの代替品として 600 ドルの GPT-3.5 を賞賛しています。スタンフォードの70億母数「アルパカ」が人気、LLaMAが驚異のパフォーマンス!

気が付くとスタンフォードの大型モデルアルパカが人気になっていました。

#はい、Alpaca は Meta の LLaMA 7B から微調整された新しいモデルです。 52kデータを使用し、GPT-3.5とほぼ同等の性能を発揮します。
重要なのは、トレーニング費用が非常に低く、600 米ドル未満であるということです。。具体的なコストは次のとおりです:
8 台の 80GB A100 で 3 時間トレーニングし、100 米ドル未満;
OpenAI の API を使用してデータを生成、500 ドル。
スタンフォード大学コンピューターサイエンス准教授のパーシー・リャン氏は、透明性の欠如/有能な命令モデルに完全にアクセスできないことが原因であると述べています。 GPT 3.5 のようなものであるため、この重要な分野における学術研究が制限されます。私たちは Alpaca (LLaMA 7B text-davinci-003) で小さな一歩を踏み出しました。

他の人が自分の大規模なモデルで新しい結果を達成したのを見て、Yann LeCun はそれを狂ったようにリツイートしました (宣伝が必要です)所定の位置にある))。
 70 億のパラメータを 3 時間で微調整, 600 米ドルで入手
70 億のパラメータを 3 時間で微調整, 600 米ドルで入手
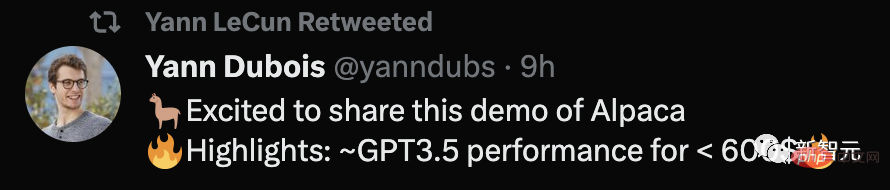
Q: アルパカについて少し教えてください。
答え: アルパカは南米原産のラクダの一種で、ラマやラクダの仲間です。繊維を目的として飼育されることが多く、セーターや毛布などの高級品の製造に使用されます。アルパカはその穏やかで人懐っこい性格からペットとしても人気です。
#体験リンク: https://crfm.stanford.edu/alpaca/

# まさに、学術研究者に提供された LLaMA モデルは、最初の問題を解決しました。
2 番目の課題では、論文「Self-Instruct: 自己生成命令による言語モデルの調整」が良いインスピレーションを与えてくれました。つまり、既存の強い言語を使用するというものです。モデルを作成して指示データを自動生成します。
# ただし、LLaMA モデルの最大の弱点は、命令の微調整ができないことです。 OpenAI の最大のイノベーションの 1 つは、GPT-3 での命令チューニングの使用です。
#これに関して、スタンフォード大学は既存の大規模言語モデルを使用して、次の指示のデモンストレーションを自動的に生成しました。

自己生成された命令シード セットから手動で作成された 175 個の「命令と出力」のペアから始めて、プロンプト テキスト davinci -003 は、シード セットをコンテキスト サンプルとして使用して、より多くの命令を生成します。
#命令の自己生成方法は、生成パイプラインを簡素化することで改善され、コストが大幅に削減されました。データ生成プロセス中に、OpenAI API を使用して 52,000 個の固有の命令と対応する出力が生成され、コストは 500 ドル未満でした。
研究者らは、このデータセットを追跡し、Hugging Face のトレーニング フレームワークを使用して、完全シャード データ並列処理 (FSDP) を利用して LLaMA モデルを微調整しました。 ) および混合精度トレーニングとその他のテクニック。
また、7B LLaMA モデルの微調整には 80GB A100 8 台で 3 時間以上かかり、ほとんどのクラウド プロバイダーの費用は 100 ドル未満でした。
GPT-3.5 とほぼ同等
Alpaca を評価するために、スタンフォード大学の研究者は、自己生成された命令評価セット (著者 5 名の学生著者が実施)。
この一連のレビューは、自作の説明書作成者によって収集されており、電子メールの作成、ソーシャル メディア、生産性など、ユーザー向けのさまざまな説明書をカバーしています。ツールは待ってください。
彼らは GPT-3.5 (text-davinci-003) と Alpaca 7B を比較し、2 つのモデルのパフォーマンスが非常に似ていることを発見しました。 GPT-3.5 に対しては、アルパカが 90 回対 89 回勝ちます。
#モデルのサイズが小さく、命令データの量が少ないことを考えると、この結果は非常に驚くべきものです。
この静的評価セットの利用に加えて、彼らは Alpaca モデルで対話型テストも実施し、さまざまな入力に対する Alpaca のパフォーマンスが GPT と同じであることが判明しました。 -3.5の類似性。
アルパカによるスタンフォード デモ:
デモ 1 アルパカに話してもらう 自分との違いそしてLLaMA。
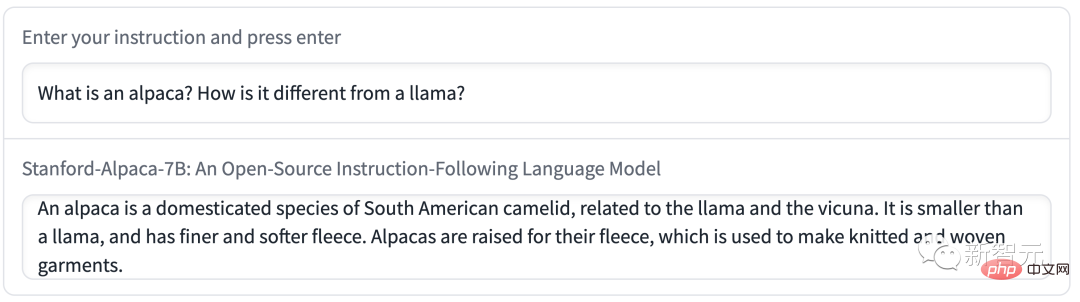
デモ 2 では、Alpaca にメールを書くよう依頼しました。内容は簡潔かつ明確で、形式は非常に標準的でした。
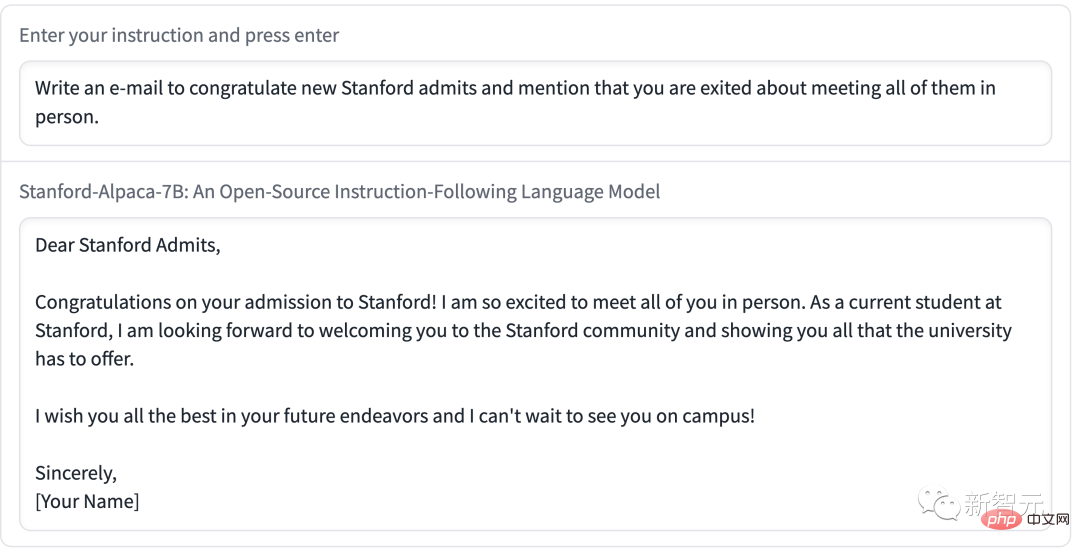
上記の例からわかるように、Alpaca の出力結果は一般によく書かれています。また、回答は一般に ChatGPT よりも短く、GPT-3.5 の短い出力のスタイルを反映しています。
#もちろん、Alpaca には言語モデルに共通の欠陥があります。
#たとえば、タンザニアの首都はダルエスサラームと呼ばれます。実際、1974 年以降、ドドマがタンザニアの新しい首都となり、ダルエスサラームはタンザニア最大の都市に過ぎませんでした。
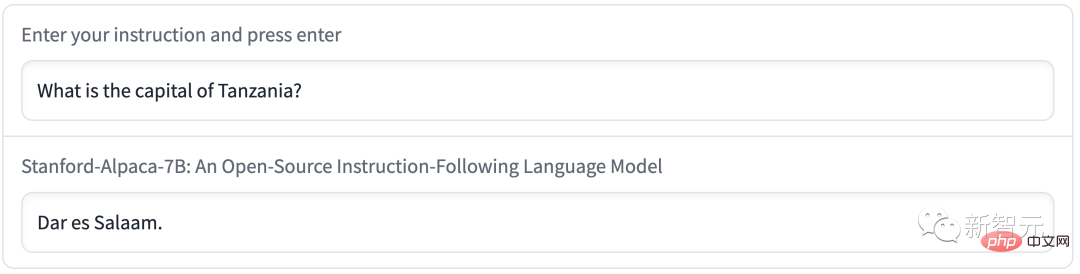
#Alpaca は、思慮深い要約を書くときに間違ったメッセージを広めます。
さらに、Alpaca には、基礎となる言語モデルと命令の微調整データに関連する多くの制限がある可能性があります。ただし、Alpaca は、より大きなモデルの重要な欠陥を将来研究するための基礎を形成できる比較的軽量のモデルを提供します。
スタンフォード大学は現在、Alpaca のトレーニング方法とデータのみを発表しており、将来的にはモデルの重みを公開する予定です。
#ただし、Alpaca は商業目的で使用することはできず、学術研究のみに使用できます。具体的な理由は 3 つあります:
1. LLaMA は非商用ライセンスのモデルであり、Alpaca はこのモデルに基づいて生成されます。
2. 命令データは OpenAI の text-davinci-003 に基づいており、その利用規約では OpenAI と競合するモデルの開発を禁止しています。 #3. 十分なセキュリティ対策が設計されていないため、Alpaca は広く使用する準備ができていません
##さらに、スタンフォード大学研究者らは、アルパカの将来の研究には 3 つの方向性があると結論付けました。
評価:
- HELM より (言語モデル全体論)評価)により、より生成的でフォロースルーのシナリオを捉え始めます。
安全性:
- アルパカのリスクをさらに調査し、また、自動化されたレッドチーム化、監査、適応テストなどの方法を使用してセキュリティを向上させます。
理解:
- How モデルをよりよく理解したいと考えています能力はトレーニング方法から生まれます。基本モデルのどのようなプロパティが必要ですか?モデルをスケールアップすると何が起こるでしょうか?指示データにはどのような属性が必要ですか? GPT-3.5 では、自己生成ディレクティブを使用する代替手段は何ですか?
ラージ モデルの安定した普及
現在、スタンフォードの「Alpaca」はネチズンから直接「ラージ テキスト モデルの安定した普及」とみなされています。Meta の LLaMA モデルは、研究者が無料で (もちろん申請後) 使用できるため、AI サークルにとっては大きなメリットです。
ChatGPT の出現以来、多くの人が AI モデルに組み込まれた制限に不満を感じてきました。これらの制限により、ChatGPT は OpenAI が機密とみなすトピックについて議論することができなくなります。
# したがって、AI コミュニティは、検閲や OpenAI Pay への報告なしで誰でもローカルで実行できるオープンソースの大規模言語モデル (LLM) を望んでいます。 API料金。
GPT-J など、このような大規模なオープンソース モデルもありますが、唯一の欠点は、大量の GPU メモリとストレージ容量を必要とすることです。 。
#一方、他のオープンソース代替製品は、既製のコンシューマ ハードウェアでは GPT-3 レベルのパフォーマンスを達成できません。
2 月末、Meta はパラメータ量が 70 億 (7B)、130 億 (13B)、および 33 の最新言語モデル LLaMA を発表しました。 10 億 (33B)。) および 650 億 (65B)。評価結果は、その 13B バージョンが GPT-3 に匹敵することを示しています。
#
論文アドレス: https://research.facebook.com/publications/llama-open-and-efficient-foundation- language-models/
Meta は応募した研究者にソース コードを公開していますが、ネチズンが最初に LLaMA の重みを GitHub で漏洩したことは予想外でした。
#それ以来、LLaMA 言語モデルを中心とした開発が爆発的に増加しました。
# 通常、GPT-3 を実行するには複数のデータセンターグレードの A100 GPU が必要です。また、GPT-3 の重みは公開されていません。
ネチズンが自ら LLaMA モデルを実行し始め、センセーションを巻き起こしました。
#量子化技術を使用してモデル サイズを最適化することで、LLaMA は M1 Mac、より小型の Nvidia コンシューマ GPU、Pixel 6 スマートフォン、さらには Raspberry Pi でも実行できるようになりました。 。
ネチズンは、LLaMA のリリースから現在まで、LLaMA を使用して全員が得た結果の一部を要約しました:
LLaMA は 2 月 24 日にリリースされ、政府、コミュニティ、学術界で活動する研究者や団体は非営利ライセンスに基づいて利用できます。
# #3 月 2 日、4chan のネチズンがすべての LLaMA モデルを漏洩しました;
##3 月 10 日、Georgi Gerganov が llama.cpp ツールを作成し、LLaMA は Mac で実行できますM1/M2 チップ搭載;
3 月 11 日: 7B モデルは llama.cpp を介して 4GB RaspberryPi で実行できますが、速度は比較的遅く、わずか 10 秒です/token;
3 月 12 日: LLaMA 7B が、node.js 実行ツール NPX 上で正常に実行されました;
3 月 13 日: llama.cpp は Pixel 6 スマートフォンで実行可能;
そして、Stanford Alpaca "Alpaca" がリリースされました。 One More Thing
プロジェクトがリリースされてから間もなく、Alpaca は人気が高すぎて使用できなくなりました....
多くのネチズンが騒然とし、「生成」をクリックしても応答がありませんでした。プレイするために列に並んでいる人もいました。
以上がLeCun は、ハードウェアの代替品として 600 ドルの GPT-3.5 を賞賛しています。スタンフォードの70億母数「アルパカ」が人気、LLaMAが驚異のパフォーマンス!の詳細内容です。詳細については、PHP 中国語 Web サイトの他の関連記事を参照してください。

ホットAIツール

Undresser.AI Undress
リアルなヌード写真を作成する AI 搭載アプリ

AI Clothes Remover
写真から衣服を削除するオンライン AI ツール。

Undress AI Tool
脱衣画像を無料で

Clothoff.io
AI衣類リムーバー

AI Hentai Generator
AIヘンタイを無料で生成します。

人気の記事
ホットツール

メモ帳++7.3.1
使いやすく無料のコードエディター

SublimeText3 中国語版
中国語版、とても使いやすい

ゼンドスタジオ 13.0.1
強力な PHP 統合開発環境

ドリームウィーバー CS6
ビジュアル Web 開発ツール

SublimeText3 Mac版
神レベルのコード編集ソフト(SublimeText3)
ホットトピック
 7469
7469
 15
1376
52
77
11
19
29
15
1376
52
77
11
19
29

 Laravelの地理空間:インタラクティブマップと大量のデータの最適化
Apr 08, 2025 pm 12:24 PM
Laravelの地理空間:インタラクティブマップと大量のデータの最適化
Apr 08, 2025 pm 12:24 PM
700万のレコードを効率的に処理し、地理空間技術を使用したインタラクティブマップを作成します。この記事では、LaravelとMySQLを使用して700万を超えるレコードを効率的に処理し、それらをインタラクティブなマップの視覚化に変換する方法について説明します。最初の課題プロジェクトの要件:MySQLデータベースに700万のレコードを使用して貴重な洞察を抽出します。多くの人は最初に言語をプログラミングすることを検討しますが、データベース自体を無視します。ニーズを満たすことができますか?データ移行または構造調整は必要ですか? MySQLはこのような大きなデータ負荷に耐えることができますか?予備分析:キーフィルターとプロパティを特定する必要があります。分析後、ソリューションに関連している属性はわずかであることがわかりました。フィルターの実現可能性を確認し、検索を最適化するためにいくつかの制限を設定しました。都市に基づくマップ検索
 MySQLを解決する方法は開始できません
Apr 08, 2025 pm 02:21 PM
MySQLを解決する方法は開始できません
Apr 08, 2025 pm 02:21 PM
MySQLの起動が失敗する理由はたくさんあり、エラーログをチェックすることで診断できます。一般的な原因には、ポートの競合(ポート占有率をチェックして構成の変更)、許可の問題(ユーザー許可を実行するサービスを確認)、構成ファイルエラー(パラメーター設定のチェック)、データディレクトリの破損(テーブルスペースの復元)、INNODBテーブルスペースの問題(IBDATA1ファイルのチェック)、プラグインロード障害(エラーログのチェック)が含まれます。問題を解決するときは、エラーログに基づいてそれらを分析し、問題の根本原因を見つけ、問題を防ぐために定期的にデータをバックアップする習慣を開発する必要があります。
 インストール後にMySQLの使用方法
Apr 08, 2025 am 11:48 AM
インストール後にMySQLの使用方法
Apr 08, 2025 am 11:48 AM
この記事では、MySQLデータベースの操作を紹介します。まず、MySQLWorkBenchやコマンドラインクライアントなど、MySQLクライアントをインストールする必要があります。 1. mysql-uroot-pコマンドを使用してサーバーに接続し、ルートアカウントパスワードでログインします。 2。CreatedAtaBaseを使用してデータベースを作成し、データベースを選択します。 3. createTableを使用してテーブルを作成し、フィールドとデータ型を定義します。 4. INSERTINTOを使用してデータを挿入し、データをクエリし、更新することでデータを更新し、削除してデータを削除します。これらの手順を習得することによってのみ、一般的な問題に対処することを学び、データベースのパフォーマンスを最適化することでMySQLを効率的に使用できます。
 リモートシニアバックエンジニア(プラットフォーム)がサークルが必要です
Apr 08, 2025 pm 12:27 PM
リモートシニアバックエンジニア(プラットフォーム)がサークルが必要です
Apr 08, 2025 pm 12:27 PM
リモートシニアバックエンジニアの求人事業者:サークル場所:リモートオフィスジョブタイプ:フルタイム給与:$ 130,000- $ 140,000職務記述書サークルモバイルアプリケーションとパブリックAPI関連機能の研究開発に参加します。ソフトウェア開発ライフサイクル全体をカバーします。主な責任は、RubyonRailsに基づいて独立して開発作業を完了し、React/Redux/Relay Front-Endチームと協力しています。 Webアプリケーションのコア機能と改善を構築し、機能設計プロセス全体でデザイナーとリーダーシップと緊密に連携します。肯定的な開発プロセスを促進し、反復速度を優先します。 6年以上の複雑なWebアプリケーションバックエンドが必要です
 mysqlはjsonを返すことができますか
Apr 08, 2025 pm 03:09 PM
mysqlはjsonを返すことができますか
Apr 08, 2025 pm 03:09 PM
MySQLはJSONデータを返すことができます。 json_extract関数はフィールド値を抽出します。複雑なクエリについては、Where句を使用してJSONデータをフィルタリングすることを検討できますが、そのパフォーマンスへの影響に注意してください。 JSONに対するMySQLのサポートは絶えず増加しており、最新バージョンと機能に注意を払うことをお勧めします。
 酸性特性を理解する:信頼できるデータベースの柱
Apr 08, 2025 pm 06:33 PM
酸性特性を理解する:信頼できるデータベースの柱
Apr 08, 2025 pm 06:33 PM
データベース酸属性の詳細な説明酸属性は、データベーストランザクションの信頼性と一貫性を確保するための一連のルールです。データベースシステムがトランザクションを処理する方法を定義し、システムのクラッシュ、停電、または複数のユーザーの同時アクセスの場合でも、データの整合性と精度を確保します。酸属性の概要原子性:トランザクションは不可分な単位と見なされます。どの部分も失敗し、トランザクション全体がロールバックされ、データベースは変更を保持しません。たとえば、銀行の譲渡が1つのアカウントから控除されているが別のアカウントに増加しない場合、操作全体が取り消されます。 TRANSACTION; updateaccountssetbalance = balance-100wh
 MySQLはダウンロード後にインストールできません
Apr 08, 2025 am 11:24 AM
MySQLはダウンロード後にインストールできません
Apr 08, 2025 am 11:24 AM
MySQLのインストール障害の主な理由は次のとおりです。1。許可の問題、管理者として実行するか、SUDOコマンドを使用する必要があります。 2。依存関係が欠落しており、関連する開発パッケージをインストールする必要があります。 3.ポート競合では、ポート3306を占めるプログラムを閉じるか、構成ファイルを変更する必要があります。 4.インストールパッケージが破損しているため、整合性をダウンロードして検証する必要があります。 5.環境変数は誤って構成されており、環境変数はオペレーティングシステムに従って正しく構成する必要があります。これらの問題を解決し、各ステップを慎重に確認して、MySQLを正常にインストールします。
 マスターSQL制限条項:クエリの行数を制御する
Apr 08, 2025 pm 07:00 PM
マスターSQL制限条項:クエリの行数を制御する
Apr 08, 2025 pm 07:00 PM
sqllimit句:クエリ結果の行数を制御します。 SQLの制限条項は、クエリによって返される行数を制限するために使用されます。これは、大規模なデータセット、パジネートされたディスプレイ、テストデータを処理する場合に非常に便利であり、クエリ効率を効果的に改善することができます。構文の基本的な構文:SelectColumn1、column2、... FromTable_nameLimitnumber_of_rows; number_of_rows:返された行の数を指定します。オフセットの構文:SelectColumn1、column2、... FromTable_nameLimitoffset、number_of_rows; offset:skip
