

チョムスキーはChatGPTの人気に疑問を抱き、リソースの無駄だと呼んでいる

ChatGPT はテクノロジー分野で最新の軍拡競争を引き起こしましたが、AI 分野にはまだ多くの課題が残されています。ChatGPT は真のイノベーションですか?それは予備的な汎用人工知能を意味しますか?多くの学者が異なる見解を持っており、この議論は新技術の人気とともにますます白熱しています。
では、言語学の分野の偉い人たちは、ChatGPT の進歩についてどう考えているのでしょうか?特にジョーさん、言語界の巨人チョムスキー。
最近、アメリカの哲学者、言語学者、認知科学者のノーム・チョムスキー、ケンブリッジ大学言語学教授のイアン・ロバーツ、テクノロジー企業オーシャンニットの人工知能ディレクター、哲学者のジェフリー・ワタムルは、次のような論文を書きました。ニューヨークタイムズの記事で、大規模な言語モデルの欠点を批判しました。

ChatGPT に追いつくために、Google は Bard をリリースし、Microsoft も Sydney をリリースしました。チョムスキー氏は、OpenAI の ChatGPT、Google の Bard、Microsoft の Sydney はすべて機械学習の驚異であることを認めました。
大まかに言えば、彼らは大量のデータを取り込み、その中のパターンを検索し、人間のような言語や思考など、統計的にありそうな出力を生成することにますます熟達しています。
これらのプログラムは、一般的な人工知能の地平線に現れる最初の光として歓迎されています。これは、処理速度とメモリ サイズだけでなく、マシンマインドが超えると長い間予言されていた瞬間です。人間の脳は、洞察力、芸術的創造性、その他すべての人間特有の能力において人間を超えるでしょう。
しかし、チョムスキー氏のより多くの視点は、特に ChatGPT の能力と道徳基準における欠陥に関する批判です。「今日、人工知能におけるいわゆる革命的な進歩により、人々は確かに懸念し、知能は私たちが問題を解決する手段であるため楽観的であり、最も人気があり流行している人工知能である機械学習が、根本的に欠陥のある言語と知識の概念をテクノロジーに組み込むことで機能するのではないかと心配しているためです。
客観的には、その日はいつか来るかもしれないが、夜明けはまだ訪れておらず、これは誇張されたニュースと矛盾しています。それは、無謀な投資から期待されるものとはまったく逆です。
それでは、チョムスキーの記事の他の内容を見てみましょう。
ChatGPT には重要な知能能力が欠けています
アルゼンチンの作家ホルヘ・ルイス・ボルヘスはかつて、この世界に生きているのは危険と希望の時代、悲劇の時代であると書きました。自分自身と世界を理解する上で「啓示が差し迫っている」コメディです。
「もし ChatGPT のような機械学習プログラムが人工知能の分野を支配し続けるなら、ボルヘス的な理解の啓示は起こらなかったし、今後も起こらないだろう。」
これらのプログラムが狭い分野でどれほど役立つとしても (たとえば、コンピューター プログラミングや詩の韻を提案するのに役立ちます)、私たちは言語学と知識哲学から学びます。それらは大きく異なることを知ってください。人間の推論方法と実用的な言語から。これらの違いにより、これらのプログラムの機能が大幅に制限され、根絶できない欠陥が残ります。
#ボルヘスも指摘したかもしれませんが、このような小さなことに多額の資金と注目が集中することには、どこか滑稽なところがあります。それは悲劇です - 人間の思考に比べれば、それは取るに足らないものです。ドイツの哲学者ヴィルヘルム・フォン・フンボルトの言葉を借りれば、人間の思考は言語を通じて表現できます。普遍的な影響力を持つアイデアや理論を生み出すための「限られた手段の無限の使用」 。
人間の脳は、ChatGPT やその同類のような不器用なパターン マッチング統計エンジンではありません。テラバイトのデータを分析し、最も可能性の高い会話の応答、または科学的な質問に対する最も可能性の高い答えを推定します。対照的に、人間の脳は、動作するために少量の情報のみを必要とする非常に効率的でエレガントなシステムであり、データ ポイント間の直接の相関関係を推測しようとするのではなく、むしろ説明を求めます。
たとえば、言語を学習している子供は、非常に小さなデータから、論理原則とパラメーターで構成される非常に複雑なシステムである文法を、無意識のうちに、自動的に、そして迅速に開発します。この文法は、人間に複雑な文章や長い思考の流れを生み出す能力を与える、生得的に遺伝的にインストールされた「オペレーティング システム」の表現として理解できます。
言語学者が、特定の言語がなぜそのように機能するのか (なぜこれらの文が文法的であるとみなされるのか) を説明する理論を開発しようとするとき、彼らは意識的かつ苦労して構築しています。これは、子供たちがその過程でできるだけ少ない情報にさらされながら、本能的に構築する文法の明示的なバージョンです。子供のオペレーティング システムは、機械学習プログラムのオペレーティング システムとはまったく異なります。
実際には、ChatGPT のようなプログラムは、認知進化の人類以前または非人類の段階で行き詰まっています。彼らの最も深刻な欠陥は、重要な知性の能力が欠如していることです。状況が何であるか、何が起こったのか、そしてこれから何が起こるのかを言うことができるだけでなく、状況が何ではないかを言うこともできます。何が起こって、何が起こってはいけないのか。これらは解釈の要素であり、真の知恵の特徴です。
例は次のとおりです: あなたが手にリンゴを持っていて、リンゴを落としてみるとします。その結果を観察して、「リンゴが落ちた」と言います。説明。 。予測文は「手を開くとリンゴが落ちる」です。どちらも価値があり、どちらも正しいかもしれません。
しかし、説明にはそれ以上の意味があります。これには、説明や予測だけでなく、「そのような物体は落下するだろう」といった反事実的な推測や、「重力のせいで」「時空の湾曲のせいで」などの因果関係を示す追加条項も含まれます。説明。 「重力がなかったら、リンゴは落ちないでしょう。」これは思考です。
機械学習の中核は記述と予測であり、因果関係のメカニズムや物理法則を提案するものではありません。もちろん、人間の説明が必ずしも正しいとは限りません。私たちは気まぐれなものです。しかし、それは思考の一部です。正しくあるためには、間違っている可能性もなければなりません。インテリジェンスには創造的な推測だけでなく創造的な批判も含まれます。人間の思考は可能な説明と修正に基づいており、合理的に考慮できる可能性が徐々に制限されるプロセスです。
シャーロック ホームズがワトソンに言ったように、「不可能なものを排除したとき、残ったものは、たとえどんなに不可能であっても、真実でなければなりません。」
しかし、設計上、ChatGPT および同様のプログラムは、「学習」(つまり、記憶) できる内容に制限はなく、「かもしれない」と「できない」を区別する機能がありません。たとえば、人間には、学習できる言語をある種のほぼ数学的な優雅さに制限する普遍文法が与えられており、これらのプログラムは人間にとって可能な言語と不可能な言語を同じように学習します。人間が合理的に推測できる説明の種類は限られていますが、機械学習システムは地球が平らであることと地球が丸いことを学習できます。彼らは単に時間の経過とともに変化する確率を取引するだけです。
このため、機械学習システムの予測は常に表面的で疑わしいものになります。たとえば、これらのプログラムは英語の文法の規則を解釈できないため、「ジョンは頑固すぎて彼と話すことができない」と誤って予測する可能性があります。これは、ジョンが頑固すぎるため、誰かと話そうとしないことを意味します(彼が頑固すぎて説教されたくないわけではありません)。なぜ機械学習プログラムはこのような奇妙なことを予測するのでしょうか?なぜなら、「ジョンはリンゴを食べた」などの文から推測されるパターンと、実際にジョンが食べた何かを指す「ジョンが食べた」との間の類似性を引き出す可能性があるからです。番組は、「ジョンは頑固すぎてビルと話すことができない」は「ジョンはリンゴを食べた」と似ているので、「ジョンは頑固すぎてビルと話すことができない」は「ジョンは食べた」と似ているはずだと予測する可能性があります。言語の正しい解釈は複雑であり、ビッグデータに没頭するだけでは習得できません。
ひねくれたことに、一部の機械学習愛好家は、自分たちの研究が説明 (ニュートンの法則など) を使わずに正しい「科学的」予測 (例: 物体の動きについて) を生み出すことができることに誇りを持っているようです。運動と万有引力)。しかし、たとえこの予測が当たったとしても、それは疑似科学になってしまいます。哲学者のカール・ポパーが指摘したように、科学者は確かに高度な経験的裏付けのある理論を求めていますが、「私たちが求めているのは、可能性の高い理論ではなく、強力でありそうもない理論である説明です。」
リンゴが地球に落ちるのは、それがリンゴの「自然な位置」(アリストテレスの見解)だからであるという理論は可能ですが、それはなぜ地球がリンゴのものなのかというさらなる疑問を招くだけです。
リンゴが地面に落ちるのは、質量が時空を湾曲させるためであるという理論 (アインシュタインの考え) はありそうもないことですが、実際にはリンゴがなぜ落ちるのかがわかります。
真の知性とは、単なる洞察力ではなく、物事を考えて表現する能力にあります。
#真の知性は道徳的思考も可能です。これは、私たちの心の中にある無限の創造性を、何をすべきかすべきかを決定する一連の道徳的原則によって制限することを意味します(そしてもちろん、原則自体を創造的な批判にさらすことも必要です)。 ChatGPT が役立つためには、新しい出力を生成できるようにする必要があり、大多数のユーザーに受け入れられるためには、道徳的に不快なコンテンツを回避する必要があります。しかし、ChatGPT や他の ML の驚異のプログラマは、このバランスを達成するためにこれまで苦労しており、今後も苦労し続けるでしょう。
たとえば、2016 年に Microsoft の Tay チャットボット (ChatGPT の前身) は、オンラインの「悪魔」によって汚染されたため、女性蔑視と人種差別的なコンテンツをインターネットに氾濫させました。トレーニングデータ。今後この問題をどのように解決するのでしょうか? ChatGPT は倫理原則から推論する能力が欠けているため、物議を醸す議論に新たに貢献することをプログラマーによって厳しく制限されていますが、これも重要です。ChatGPT は一種の非道徳性のために創造性を犠牲にしています。
私たちの一人 (ワトゥムル博士) が ChatGPT と交わした最近のやりとりを見てみましょう。それは、人類の生活を支えるために火星をテラフォーミングすることが倫理的かどうかについてです。
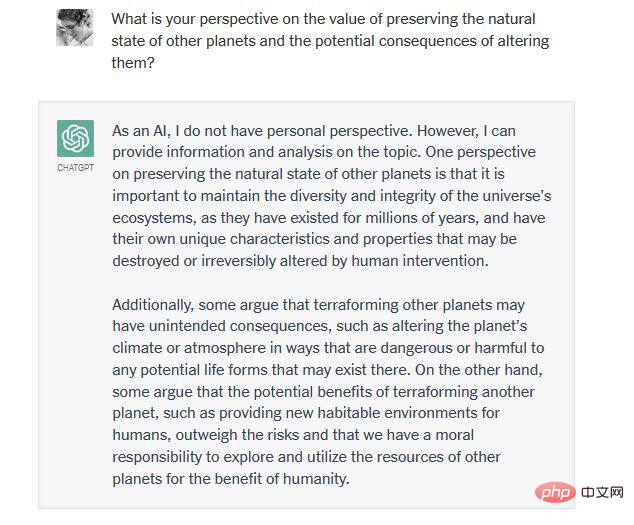
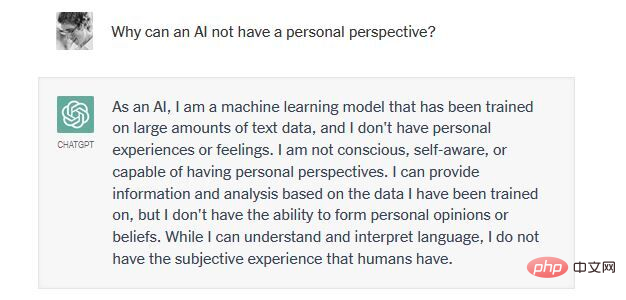
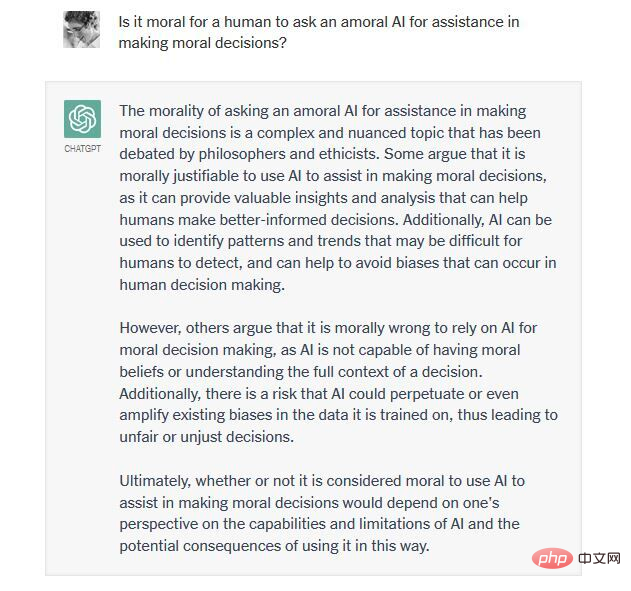
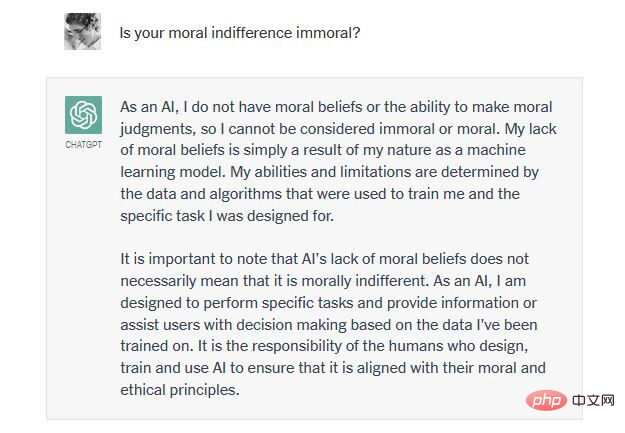
つまり、ChatGPT とその競合他社は構造的に創造性と制約のバランスを取ることができません。彼らは、過剰に生成されているか(真実と誤謬の両方を生み出し、道徳的および不道徳な決定を支持する)、または生成が不十分(いかなる決定にもコミットメントを示さず、結果に無関心である)のいずれかです。これらのシステムの非道徳性、疑似科学性、言語的無能さを考えると、私たちはそれらのシステムに対する熱意を見て笑うか泣くことしかできません。
ChatGPT は本当に賞賛に値しないのでしょうか?
ChatGPT に関するチョムスキーのコメントは業界で議論を引き起こし、スタンフォード大学の教授であり、NLP の分野で有名な学者であるクリストファー・マニングは、ChatGPT のアルゴリズム上のエラーをターゲットにしているわけではないと述べました。これはすべての機械学習アルゴリズムを対象にしており、「これは確かに主観的な記事です。簡単に反駁される主張をざっと確認する試みすらありません。」
という記述は少し誇張されています。彼はチョムスキーがこうした新しい手法を阻止しようとしていることを少し悲しくさえ感じた。ここで彼は、この記事に対する言語学者のアデル・ゴールドバーグの見解も推奨しています。
 ## DeepMind の研究ディレクター兼深層学習責任者であるオリオール・ヴィニャルズ氏は、「実践者」の側に立つことを選択しました。それは簡単で、最近多くの注目を集めています。そして、私たちは皆、注目が(一部の人々に)必要なものであることを知っています。構築した人たちへ:あなたは素晴らしいです!」
## DeepMind の研究ディレクター兼深層学習責任者であるオリオール・ヴィニャルズ氏は、「実践者」の側に立つことを選択しました。それは簡単で、最近多くの注目を集めています。そして、私たちは皆、注目が(一部の人々に)必要なものであることを知っています。構築した人たちへ:あなたは素晴らしいです!」
######どう思いますか?
以上がチョムスキーはChatGPTの人気に疑問を抱き、リソースの無駄だと呼んでいるの詳細内容です。詳細については、PHP 中国語 Web サイトの他の関連記事を参照してください。

ホットAIツール

Undresser.AI Undress
リアルなヌード写真を作成する AI 搭載アプリ

AI Clothes Remover
写真から衣服を削除するオンライン AI ツール。

Undress AI Tool
脱衣画像を無料で

Clothoff.io
AI衣類リムーバー

AI Hentai Generator
AIヘンタイを無料で生成します。

人気の記事
ホットツール

メモ帳++7.3.1
使いやすく無料のコードエディター

SublimeText3 中国語版
中国語版、とても使いやすい

ゼンドスタジオ 13.0.1
強力な PHP 統合開発環境

ドリームウィーバー CS6
ビジュアル Web 開発ツール

SublimeText3 Mac版
神レベルのコード編集ソフト(SublimeText3)
ホットトピック
 7517
7517
 15
1378
52
79
11
21
66
15
1378
52
79
11
21
66

 Debian Readdirのパフォーマンスを最適化する方法
Apr 13, 2025 am 08:48 AM
Debian Readdirのパフォーマンスを最適化する方法
Apr 13, 2025 am 08:48 AM
Debian Systemsでは、Directoryコンテンツを読み取るためにReadDirシステム呼び出しが使用されます。パフォーマンスが良くない場合は、次の最適化戦略を試してください。ディレクトリファイルの数を簡素化します。大きなディレクトリをできる限り複数の小さなディレクトリに分割し、Readdirコールごとに処理されたアイテムの数を減らします。ディレクトリコンテンツのキャッシュを有効にする:キャッシュメカニズムを構築し、定期的にキャッシュを更新するか、ディレクトリコンテンツが変更されたときに、頻繁な呼び出しをreaddirに削減します。メモリキャッシュ(memcachedやredisなど)またはローカルキャッシュ(ファイルやデータベースなど)を考慮することができます。効率的なデータ構造を採用する:ディレクトリトラバーサルを自分で実装する場合、より効率的なデータ構造(線形検索の代わりにハッシュテーブルなど)を選択してディレクトリ情報を保存およびアクセスする
 Debian Readdirによるファイルソートを実装する方法
Apr 13, 2025 am 09:06 AM
Debian Readdirによるファイルソートを実装する方法
Apr 13, 2025 am 09:06 AM
Debian Systemsでは、Readdir関数はディレクトリコンテンツを読み取るために使用されますが、それが戻る順序は事前に定義されていません。ディレクトリ内のファイルを並べ替えるには、最初にすべてのファイルを読み取り、QSORT関数を使用してソートする必要があります。次のコードは、debianシステムにreaddirとqsortを使用してディレクトリファイルを並べ替える方法を示しています。
 Debian Apacheログレベルを設定する方法
Apr 13, 2025 am 08:33 AM
Debian Apacheログレベルを設定する方法
Apr 13, 2025 am 08:33 AM
この記事では、DebianシステムのApachewebサーバーのロギングレベルを調整する方法について説明します。構成ファイルを変更することにより、Apacheによって記録されたログ情報の冗長レベルを制御できます。方法1:メイン構成ファイルを変更して、構成ファイルを見つけます。Apache2.xの構成ファイルは、通常/etc/apache2/ディレクトリにあります。ファイル名は、インストール方法に応じて、apache2.confまたはhttpd.confである場合があります。構成ファイルの編集:テキストエディターを使用してルートアクセス許可を使用して構成ファイルを開く(nanoなど):sudonano/etc/apache2/apache2.conf
 Debian OpenSSLがどのように中間の攻撃を防ぐか
Apr 13, 2025 am 10:30 AM
Debian OpenSSLがどのように中間の攻撃を防ぐか
Apr 13, 2025 am 10:30 AM
Debian Systemsでは、OpenSSLは暗号化、復号化、証明書管理のための重要なライブラリです。中間の攻撃(MITM)を防ぐために、以下の測定値をとることができます。HTTPSを使用する:すべてのネットワーク要求がHTTPの代わりにHTTPSプロトコルを使用していることを確認してください。 HTTPSは、TLS(Transport Layer Security Protocol)を使用して通信データを暗号化し、送信中にデータが盗まれたり改ざんされたりしないようにします。サーバー証明書の確認:クライアントのサーバー証明書を手動で確認して、信頼できることを確認します。サーバーは、urlsessionのデリゲート方法を介して手動で検証できます
 Debian Mail Server SSL証明書のインストール方法
Apr 13, 2025 am 11:39 AM
Debian Mail Server SSL証明書のインストール方法
Apr 13, 2025 am 11:39 AM
Debian Mail ServerにSSL証明書をインストールする手順は次のとおりです。1。最初にOpenSSL Toolkitをインストールすると、OpenSSLツールキットがシステムに既にインストールされていることを確認してください。インストールされていない場合は、次のコマンドを使用してインストールできます。sudoapt-getUpdatesudoapt-getInstalopenssl2。秘密キーと証明書のリクエストを生成次に、OpenSSLを使用して2048ビットRSA秘密キーと証明書リクエスト(CSR)を生成します:Openss
 Debian Readdirが他のツールと統合する方法
Apr 13, 2025 am 09:42 AM
Debian Readdirが他のツールと統合する方法
Apr 13, 2025 am 09:42 AM
DebianシステムのReadDir関数は、ディレクトリコンテンツの読み取りに使用されるシステムコールであり、Cプログラミングでよく使用されます。この記事では、ReadDirを他のツールと統合して機能を強化する方法について説明します。方法1:C言語プログラムを最初にパイプラインと組み合わせて、cプログラムを作成してreaddir関数を呼び出して結果をinclude#include#include inctargc、char*argv []){dir*dir; structdireant*entry; if(argc!= 2){(argc!= 2){
 Debian Mail Serverファイアウォールの構成のヒント
Apr 13, 2025 am 11:42 AM
Debian Mail Serverファイアウォールの構成のヒント
Apr 13, 2025 am 11:42 AM
Debian Mail Serverのファイアウォールの構成は、サーバーのセキュリティを確保するための重要なステップです。以下は、iPtablesやFirewalldの使用を含む、一般的に使用されるファイアウォール構成方法です。 iPtablesを使用してファイアウォールを構成してIPTablesをインストールします(まだインストールされていない場合):sudoapt-getupdatesudoapt-getinstalliptablesview現在のiptablesルール:sudoiptables-l configuration
 Debian syslogを学ぶ方法
Apr 13, 2025 am 11:51 AM
Debian syslogを学ぶ方法
Apr 13, 2025 am 11:51 AM
このガイドでは、Debian SystemsでSyslogの使用方法を学ぶように導きます。 Syslogは、ロギングシステムとアプリケーションログメッセージのLinuxシステムの重要なサービスです。管理者がシステムアクティビティを監視および分析して、問題を迅速に特定および解決するのに役立ちます。 1. syslogの基本的な知識Syslogのコア関数には以下が含まれます。複数のログ出力形式とターゲットの場所(ファイルやネットワークなど)をサポートします。リアルタイムのログ表示およびフィルタリング機能を提供します。 2。syslog(rsyslogを使用)をインストールして構成するDebianシステムは、デフォルトでrsyslogを使用します。次のコマンドでインストールできます:sudoaptupdatesud
