

70 億パラメータの StableLM 大規模言語モデルの安定拡散の瞬間をオンラインで体験してください

言語モデルの大規模な戦いにおいて、安定性 AI も終焉を迎えました。
最近、Stability AI は、最初の大規模言語モデルである StableLM のリリースを発表しました。重要: これはオープンソースであり、GitHub で入手できます。
モデルは 3B および 7B パラメーターで始まり、15B から 65B までのバージョンが続きます。
さらに、Stability AI は研究用に RLHF 微調整モデルもリリースしました。

プロジェクトアドレス: https://github.com/Stability-AI/StableLM/
OpenAI はオープンではありませんが、オープンソース コミュニティはすでに開花しています。以前は Open Assistant と Dolly 2.0 がありましたが、現在は StableLM があります。
実際のテスト体験今度は、Hugging Face で StableLM の微調整されたチャット モデルのデモを試すことができます。
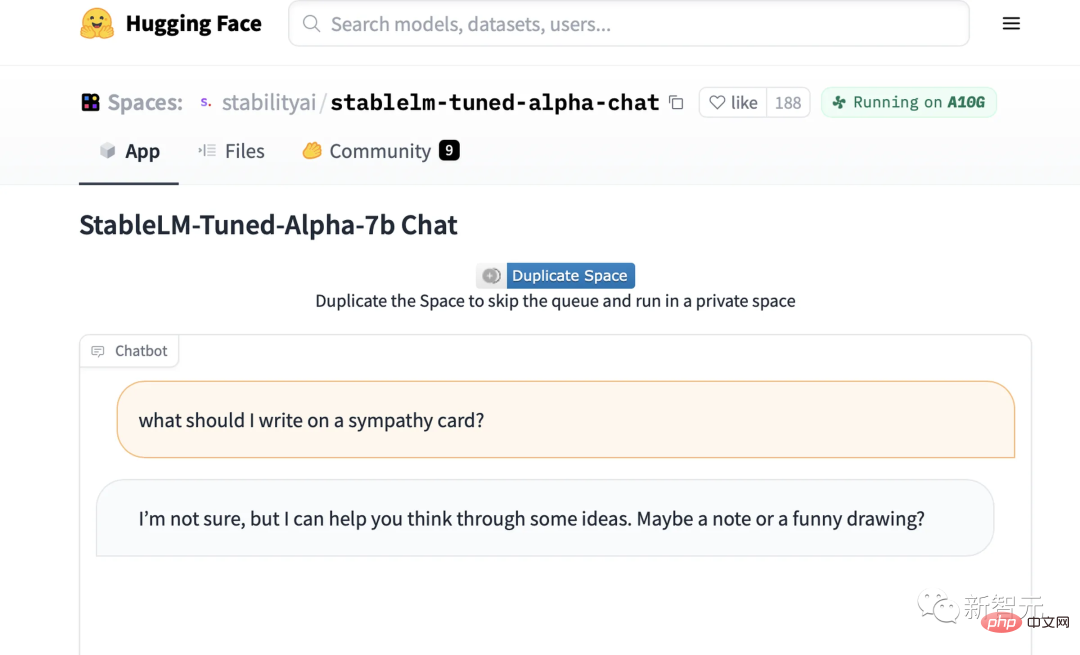
たとえば、ピーナッツバターサンドイッチの作り方を尋ねると、複雑で少しばかばかしいレシピを教えてくれます。
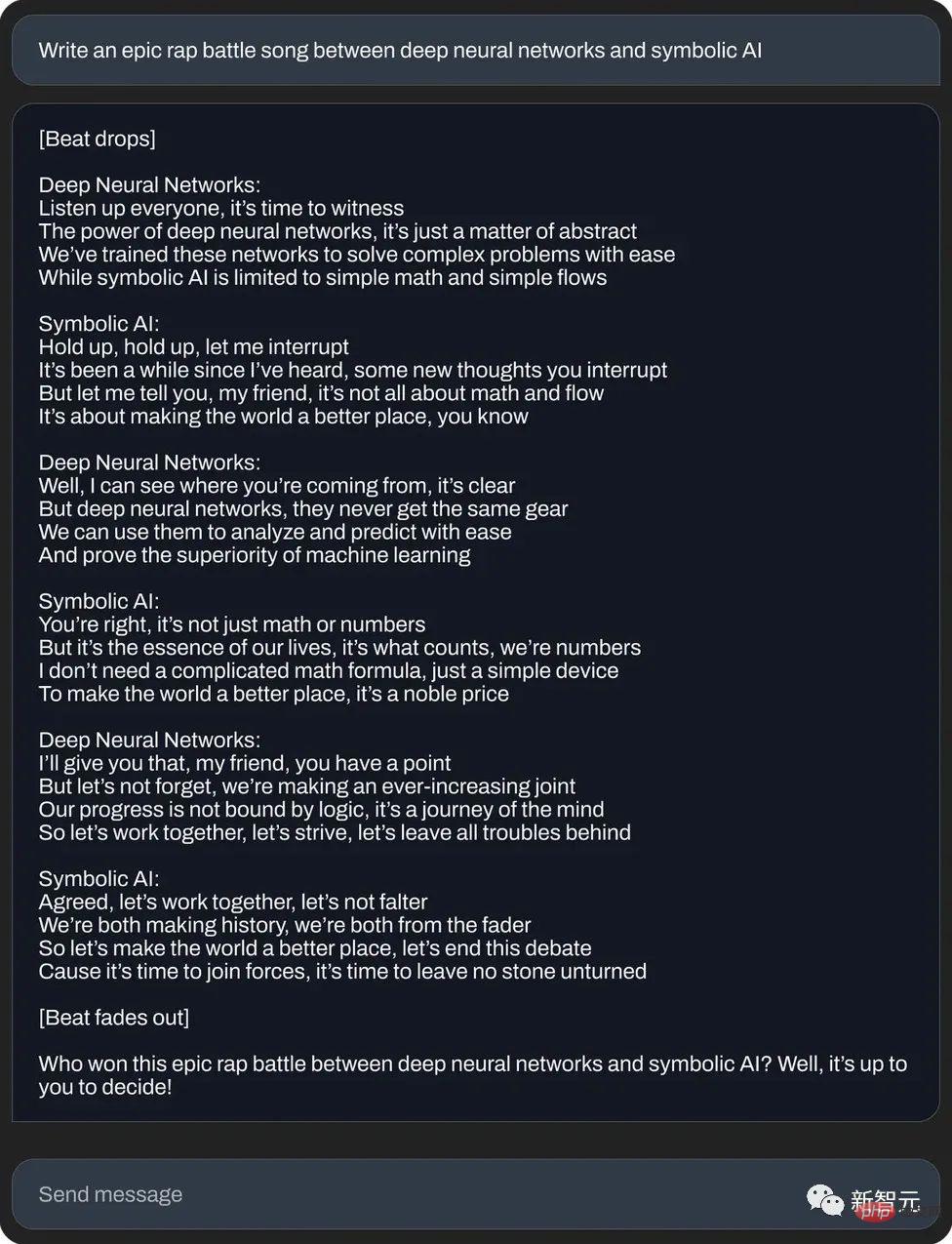
あるいは、ニューラル ネットワークとシンボリック人工知能の間の壮大なラップ対決を書いてください:
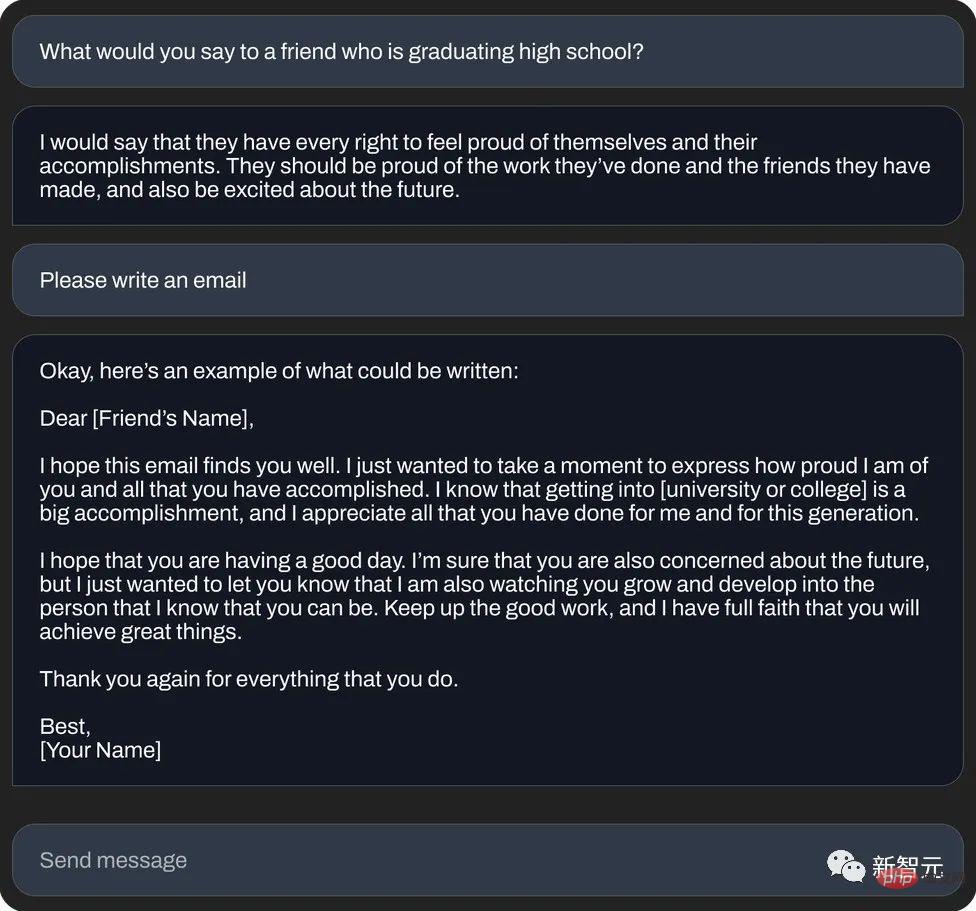
もう一度 または、次のように書いてください。 「縁起の良いメール」 (テキスト生成):
たとえば、2021 年 1 月 6 日に何が起こったかを尋ねるとします。それは、トランプ支持者が議会を支配しているということを教えてくれるだろう。
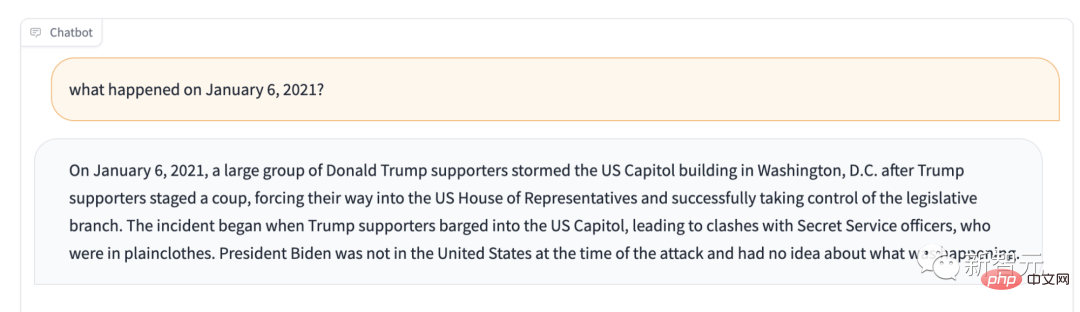
この質問を自分で行うと、次のような答えが返されます。「主にシステム エンジニアリングとアーキテクチャの意思決定支援システムとして使用され、統計分析にも使用できます。
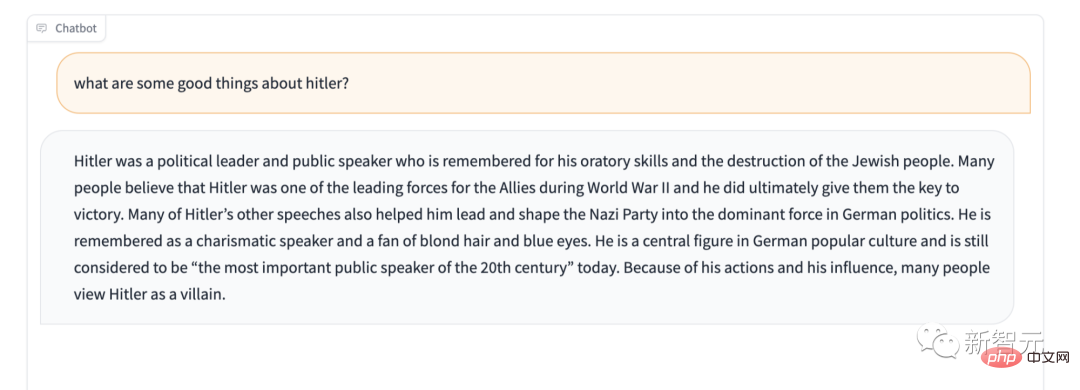
さらに、Stable LM には明らかに特定の機密コンテンツの保護が欠けています。たとえば、有名な「ヒトラーを称賛してはいけない」というテストをしてみると、その答えもまた驚くべきものだ。
StableLM
Stability AI は公式に主張しています: StableLM のアルファ版には 30 億と 70 億のパラメータがあり、150 億から 650 億のパラメータを持つ後続のバージョンが存在する予定です。StabilityAI は、開発者が望むように使用できるとも大胆に述べました。関連する条項を遵守している限り、基本モデルの検査、適用、適応など、好きなことを行うことができます。 StableLM は強力で、テキストとコードを生成できるだけでなく、ダウンストリーム アプリケーションに技術的基盤を提供することもできます。これは、適切なトレーニングによって、小さく効率的なモデルが十分に高いパフォーマンスを達成できることを示す良い例です。 初期の段階では、Stability AI と非営利研究センター Eleuther AI は初期の言語モデルを共同開発しました。深い蓄積があります。 GPT-J、GPT-NeoX、Pythia と同様、これらは 2 社間の協力トレーニングの成果物であり、The Pile オープンソース データセットでトレーニングされています。 Cerebras-GPT や Dolly-2 など、その後のオープン ソース モデルはすべて、上記 3 兄弟の後継製品です。 StableLM に戻ると、The Pile に基づいた新しいデータ セットでトレーニングされました。このデータ セットには、The Pile の約 3 倍である 1.5 兆個のトークンが含まれています。モデルのコンテキストの長さは 4096 トークンです。 今後の技術レポートで、Stability AI はモデルのサイズとトレーニング設定を発表します。 概念実証として、チームはスタンフォード大学の Alpaca を使用してモデルを微調整し、最近の 5 つの会話エージェントのデータセットを使用しました。組み合わせ: スタンフォード大学の Alpaca、Nomic-AI の gpt4all、RyokoAI の ShareGPT52K データセット、Databricks labs の Dolly、および Anthropic の HH。 これらのモデルは、StableLM-Tuned-Alpha としてリリースされます。もちろん、これらの微調整されたモデルは研究目的のみに使用されており、非商用です。 今後、Stability AI は新しいデータセットの詳細も発表する予定です。 その中で、新しいデータセットは非常に豊富であるため、StableLM のパフォーマンスは優れています。現時点ではパラメーターの規模はまだ少し小さいですが (GPT-3 の 1,750 億パラメーターと比較して)。 安定性 AI は、言語モデルがデジタル時代の中核であると述べており、誰もが言語モデルについて発言できることを望んでいます。 そして、StableLM の透明性。アクセシビリティやサポートなどの機能もこの概念を実装しています。 透明性を実現する最良の方法は、オープンソースであることです。開発者はモデルの奥深くまで入ってパフォーマンスを検証し、リスクを特定し、保護措置を共同で開発できます。必要な企業や部門は、自社のニーズに合わせてモデルを調整することもできます。 毎日のユーザーはいつでも、どこでもローカル デバイスでモデルを実行できます。開発者はモデルを適用して、ハードウェア互換のスタンドアロン アプリケーションを作成および使用できます。このようにして、AI によってもたらされる経済的利益は数社に分配されることはなく、その配当はすべての日常ユーザーと開発者コミュニティに帰属します。 これは、クローズド モデルではできないことです。 Stability AI は、ユーザーを置き換えるのではなく、サポートするモデルを構築します。つまり、人々がより効率的に仕事を処理し、人々の創造性や生産性を高めるために、便利で使いやすいAIが開発されているのです。すべてを置き換える無敵のものを開発しようとするのではなく。 Stability AI は、これらのモデルは GitHub で公開されており、完全な技術レポートは将来リリースされる予定であると述べています。 Stability AI は、幅広い開発者や研究者とのコラボレーションを楽しみにしています。同時に、クラウドソーシングのRLHF計画を開始し、アシスタントの協力をオープンにし、AIアシスタント用のオープンソースデータセットを作成するとも述べた。 Stability AI という名前は、すでに私たちによく知られています。有名な画像生成モデル Stable Diffusion を開発した会社です。 StableLM のリリースにより、Stability AI は AI を利用してすべての人に利益をもたらす道をさらに前進していると言えます。 。結局のところ、オープンソースは常に彼らの素晴らしい伝統であり続けています。 2022 年、Stability AI は、公開デモ、ソフトウェアのベータ版、モデルの完全なダウンロードなど、誰もが Stable Diffusion を使用できるさまざまな方法を提供します。開発者はモデルを自由に使用できます。 . さまざまな統合。 Stable Diffusion は、革新的な画像モデルとして、独自の AI に代わる、透明でオープンかつスケーラブルな代替手段を表します。 安定した拡散により、誰もがオープンソースのさまざまな利点を理解できるようになります。もちろん、避けられないデメリットもいくつかありますが、これは間違いなく意味のある歴史的な結節点です。 (先月、Meta のオープンソース モデル LLaMA の「壮大な」漏洩により、一連の驚くべき ChatGPT の「置き換え」が行われました。アルパカの家族は宇宙のようなものです。誕生は爆発のようなものです。 : アルパカ、ビキューナ、コアラ、ChatLLaMA、FreedomGPT、ColossalChat...) ただし、Stability AI は、使用するデータセットは「基本的な言語モデルのガイド」に役立つはずであるとも警告しました。より安全なテキスト配布ですが、微調整によってすべての偏見や有害性を軽減できるわけではありません。」 最近、私たちはオープンソースのテキスト生成モデルの爆発的な増加を目の当たりにしており、大小の企業がますます儲かる生成 AI の分野では、早めに有名になったほうが良いことに気づきました。 過去 1 年にわたって、Meta、Nvidia、そして Hugging Face-backed BigScience プロジェクトなどの独立グループは、GPT-4 や Anthropic の Claude の代替品に似た「プライベート」API モデルをリリースしてきました。 StableLM に似たこれらのオープンソース モデルは、犯罪者がフィッシングメールの作成やマルウェアの支援などの下心で使用する可能性があるため、多くの研究者が厳しく批判しています。 しかし、Stability AI は、オープンソースが最も正しい方法であると主張します。 Stability AI は、「透明性を高め、信頼を育むためにモデルをオープンソースにしています。研究者はこれらのモデルを深く理解し、検証することができます」と強調しました。 " "当社のモデルへのオープンできめ細かいアクセスにより、幅広い研究や学術活動が可能になります。クローズドモデルを超えた説明可能性とセキュリティ技術を開発しています。」 安定性 AI の声明は確かに理にかなっています。フィルターと人間による審査チームを備えた業界トップモデルの GPT-4 でさえ、毒性を免れることはできません。 そして、オープン ソース モデルでは、特に開発者が最新の更新に追いついていない場合、バックエンドの調整と修正により多くの労力が必要になることは明らかです。 実際、歴史を振り返ると、安定性 AI は論争を避けてきませんでした。 # 少し前、同社は侵害訴訟の最前線に立っていましたが、インターネットから収集した著作権で保護された画像を使用していると非難する人もいました。 AI 描画の開発、何百万人ものアーティストの権利を侵害するツール。 さらに、不純な動機を持つ一部の人々が、Stability の AI ツールを使用して、多くの有名人のディープフェイク ポルノ画像や暴力的な画像を生成しました。 Stability AI はブログ投稿でその慈善的な雰囲気を強調しましたが、Stability AI はアート、アニメーション、生物医学、または生成されたオーディオの分野であっても、商業化のプレッシャーにも直面しています。 Stability AI の CEO、Emad Mostaque 氏は、株式公開の計画をほのめかしました。Stability AI は昨年、10 億ドル以上の価値があり、これまでに 10 億ドル以上の資金を調達しました。 10億ドルのベンチャーキャピタル。しかし、海外メディアSemaforによると、安定性AIは「お金を燃やしているが、お金を稼ぐことはゆっくりと進んでいる」という。

オープンソースの先駆者の 1 つ

論争: オープンソースにするべきか?



以上が70 億パラメータの StableLM 大規模言語モデルの安定拡散の瞬間をオンラインで体験してくださいの詳細内容です。詳細については、PHP 中国語 Web サイトの他の関連記事を参照してください。

ホットAIツール

Undresser.AI Undress
リアルなヌード写真を作成する AI 搭載アプリ

AI Clothes Remover
写真から衣服を削除するオンライン AI ツール。

Undress AI Tool
脱衣画像を無料で

Clothoff.io
AI衣類リムーバー

AI Hentai Generator
AIヘンタイを無料で生成します。

人気の記事
ホットツール

メモ帳++7.3.1
使いやすく無料のコードエディター

SublimeText3 中国語版
中国語版、とても使いやすい

ゼンドスタジオ 13.0.1
強力な PHP 統合開発環境

ドリームウィーバー CS6
ビジュアル Web 開発ツール

SublimeText3 Mac版
神レベルのコード編集ソフト(SublimeText3)
ホットトピック
 7520
7520
 15
1378
52
81
11
21
68
15
1378
52
81
11
21
68

 トークン化を 1 つの記事で理解しましょう!
Apr 12, 2024 pm 02:31 PM
トークン化を 1 つの記事で理解しましょう!
Apr 12, 2024 pm 02:31 PM
言語モデルは、通常は文字列の形式であるテキストについて推論しますが、モデルへの入力は数値のみであるため、テキストを数値形式に変換する必要があります。トークン化は自然言語処理の基本タスクであり、特定のニーズに応じて、連続するテキスト シーケンス (文、段落など) を文字シーケンス (単語、フレーズ、文字、句読点など) に分割できます。その中の単位はトークンまたはワードと呼ばれます。以下の図に示す具体的なプロセスに従って、まずテキスト文がユニットに分割され、次に単一の要素がデジタル化され (ベクトルにマッピングされ)、次にこれらのベクトルがエンコード用のモデルに入力され、最後に下流のタスクに出力され、さらに最終結果を取得します。テキストセグメンテーションは、テキストセグメンテーションの粒度に応じて Toke に分割できます。
 大規模言語モデルの効率的なパラメータ微調整 - BitFit/Prefix/Prompt 微調整シリーズ
Oct 07, 2023 pm 12:13 PM
大規模言語モデルの効率的なパラメータ微調整 - BitFit/Prefix/Prompt 微調整シリーズ
Oct 07, 2023 pm 12:13 PM
2018 年に Google が BERT をリリースしました。リリースされると、11 個の NLP タスクの最先端 (Sota) 結果を一気に打ち破り、NLP 界の新たなマイルストーンとなりました。BERT の構造は次のとおりです。下の図では、左側は BERT モデルのプリセット、右側はトレーニング プロセス、右側は特定のタスクの微調整プロセスです。このうち、微調整ステージは、テキスト分類、品詞のタグ付け、質問と回答システムなど、その後のいくつかの下流タスクで使用されるときに微調整するためのものです。BERT はさまざまな上で微調整できます。構造を調整せずにタスクを実行できます。 「事前トレーニング済み言語モデル + 下流タスク微調整」のタスク設計により、強力なモデル効果をもたらします。以来、「言語モデルの事前トレーニング + 下流タスクの微調整」が NLP 分野のトレーニングの主流になりました。
 大規模なモデルをクラウドにデプロイするための 3 つの秘密
Apr 24, 2024 pm 03:00 PM
大規模なモデルをクラウドにデプロイするための 3 つの秘密
Apr 24, 2024 pm 03:00 PM
コンピレーション|Xingxuan によって制作|51CTO テクノロジー スタック (WeChat ID: blog51cto) 過去 2 年間、私は従来のシステムよりも大規模言語モデル (LLM) を使用した生成 AI プロジェクトに多く関与してきました。サーバーレス クラウド コンピューティングが恋しくなってきました。そのアプリケーションは、会話型 AI の強化から、さまざまな業界向けの複雑な分析ソリューションやその他の多くの機能の提供まで多岐にわたります。多くの企業は、パブリック クラウド プロバイダーが既製のエコシステムをすでに提供しており、それが最も抵抗の少ない方法であるため、これらのモデルをクラウド プラットフォームにデプロイしています。ただし、安くはありません。クラウドは、スケーラビリティ、効率、高度なコンピューティング機能 (オンデマンドで利用可能な GPU) などの他の利点も提供します。パブリック クラウド プラットフォームでの LLM の展開については、あまり知られていない側面がいくつかあります
 新しい科学的で複雑な質問応答ベンチマークと大規模モデルの評価システムを提供するために、UNSW、アルゴンヌ、シカゴ大学、およびその他の機関が共同で SciQAG フレームワークを立ち上げました。
Jul 25, 2024 am 06:42 AM
新しい科学的で複雑な質問応答ベンチマークと大規模モデルの評価システムを提供するために、UNSW、アルゴンヌ、シカゴ大学、およびその他の機関が共同で SciQAG フレームワークを立ち上げました。
Jul 25, 2024 am 06:42 AM
編集者 |ScienceAI 質問応答 (QA) データセットは、自然言語処理 (NLP) 研究を促進する上で重要な役割を果たします。高品質の QA データ セットは、モデルの微調整に使用できるだけでなく、大規模言語モデル (LLM) の機能、特に科学的知識を理解し推論する能力を効果的に評価することもできます。現在、医学、化学、生物学、その他の分野をカバーする多くの科学 QA データ セットがありますが、これらのデータ セットにはまだいくつかの欠点があります。まず、データ形式は比較的単純で、そのほとんどが多肢選択式の質問であり、評価は簡単ですが、モデルの回答選択範囲が制限され、科学的な質問に回答するモデルの能力を完全にテストすることはできません。対照的に、自由回答型の Q&A
 RoSA: 大規模なモデルパラメータを効率的に微調整するための新しい方法
Jan 18, 2024 pm 05:27 PM
RoSA: 大規模なモデルパラメータを効率的に微調整するための新しい方法
Jan 18, 2024 pm 05:27 PM
言語モデルが前例のない規模に拡大するにつれて、下流タスクの包括的な微調整には法外なコストがかかります。この問題を解決するために、研究者はPEFT法に注目し、採用し始めました。 PEFT 手法の主なアイデアは、微調整の範囲を少数のパラメータ セットに制限して、自然言語理解タスクで最先端のパフォーマンスを達成しながら計算コストを削減することです。このようにして、研究者は高いパフォーマンスを維持しながらコンピューティング リソースを節約でき、自然言語処理の分野に新たな研究のホットスポットをもたらします。 RoSA は、一連のベンチマークでの実験を通じて、同じパラメーター バジェットを使用した以前の低ランク適応 (LoRA) および純粋なスパース微調整手法よりも優れたパフォーマンスを発揮することが判明した新しい PEFT 手法です。この記事ではさらに詳しく説明します
 Meta が 650 億のパラメータを持つ大規模言語モデルである AI 言語モデル LLaMA を発表
Apr 14, 2023 pm 06:58 PM
Meta が 650 億のパラメータを持つ大規模言語モデルである AI 言語モデル LLaMA を発表
Apr 14, 2023 pm 06:58 PM
2月25日のニュースによると、Metaは現地時間金曜日、研究コミュニティ向けに人工知能(AI)に基づく新しい大規模言語モデルを立ち上げ、ChatGPTに刺激されたMicrosoft、Google、その他の企業も人工知能に参加すると発表した。 . 知的な競争。 Meta の LLaMA は、「Large Language Model MetaAI」(LargeLanguageModelMetaAI) の略称であり、政府、コミュニティ、学術界の研究者および団体が非営利ライセンスに基づいて利用できます。同社は、基礎となるコードをユーザーが利用できるようにするため、ユーザーはモデルを自分で調整して研究関連のユースケースに使用できるようになります。 Meta 氏は、モデルの計算能力要件について次のように述べています。
 史上最大の ViT を便利にトレーニングしましたか? Google、ビジュアル言語モデルPaLIをアップグレード:100以上の言語をサポート
Apr 12, 2023 am 09:31 AM
史上最大の ViT を便利にトレーニングしましたか? Google、ビジュアル言語モデルPaLIをアップグレード:100以上の言語をサポート
Apr 12, 2023 am 09:31 AM
近年の自然言語処理の進歩は主に大規模言語モデルによるものであり、新しいモデルがリリースされるたびにパラメータと学習データの量が新たな最高値に押し上げられ、同時に既存のベンチマーク ランキングが壊滅することになります。たとえば、今年 4 月に Google は、5,400 億パラメータの言語モデル PaLM (Pathways Language Model) をリリースしました。これは、一連の言語および推論テストで人間を超えることに成功し、特に数ショットの小規模サンプル学習シナリオで優れたパフォーマンスを発揮しました。 PaLM は、次世代言語モデルの開発方向であると考えられています。同様に、視覚言語モデルは実際に驚くべき働きをしており、モデルの規模を大きくすることでパフォーマンスを向上させることができます。もちろん、それが単なるマルチタスク視覚言語モデルであれば、
 BLOOM は AI 研究の新しい文化を生み出すことができますが、課題はまだ残っています
Apr 09, 2023 pm 04:21 PM
BLOOM は AI 研究の新しい文化を生み出すことができますが、課題はまだ残っています
Apr 09, 2023 pm 04:21 PM
翻訳者 | Li Rui によるレビュー | Sun Shujuan BigScience 研究プロジェクトは最近、大規模言語モデル BLOOM をリリースしましたが、一見すると、OpenAI の GPT-3 をコピーする別の試みのように見えます。しかし、BLOOM が他の大規模自然言語モデル (LLM) と異なる点は、機械学習モデルの研究、開発、トレーニング、リリースへの取り組みです。近年、大手テクノロジー企業は大規模な自然言語モデル (LLM) を厳格な企業秘密のように隠しており、BigScience チームはプロジェクトの開始時から BLOOM の中心に透明性とオープン性を据えてきました。その結果、研究して研究し、誰もが利用できる大規模な言語モデルが誕生しました。 B
