

2023年卒業論文リストの解釈:合格したドラフトに怯えていますか?反論で運命を変えるのは難しいですか?査読者には偏見があるのでしょうか?

また上位が発表されると、喜ぶ人もいれば悲しむ人もいます。
今回の IJCAI 2023 では、合計 4,566 件の全文提出があり、採択率は約 15%です。

質問リンク: https://www.zhihu.com/question/578082970
Zhihu のフィードバック結果から判断すると、全体的なレビューは質 まだまだ満足のいくものではなく(拒否されたことへの憤りもあるかもしれませんが…)、反論の内容も読まずに拒否した査読者もいます。

同じスコアで結末が異なる論文もあります。

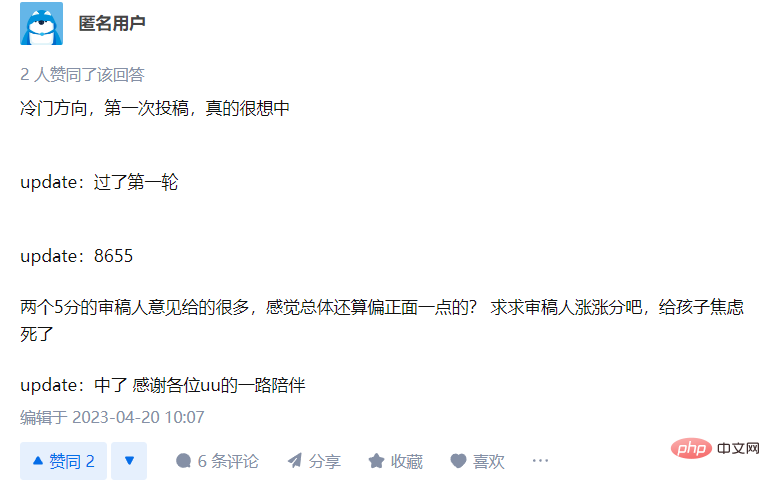
一部のネチズンもメタレビューを拒否する理由を投稿しましたが、それらはすべて大きな欠点でした。

しかし、拒絶されて終わりではなく、もっと重要なことは継続することです。
Netizen Lower_Evening_4056 は、画期的な論文であっても何度も拒否されるだろうし、十分に優れていなくても受け入れられる論文もあると考えています。
次に進んで、合理的なレビュー コメントを 振り返ると、自分の作品をさらに高いレベルに改善できることがわかります 。
この審査システムには欠陥があります。さらに重要なのは、拒否を個人的または仕事上の価値の評価結果と見なさないことです。あなたが学生で、アドバイザーがあなたの仕事の質ではなくレビューの結果に基づいてあなたを評価している場合は、アドバイザーとの関係を再考した方がよいかもしれません。

NeurIPS カンファレンスは以前に一貫性実験を実施しました。平均スコアが 5 ~ 6.5 の論文の場合、承認結果は基本的に次のとおりです。はい、それはあなたが会うレビュアーによって異なります。
たとえば、ある人の論文の結果は 9665 でした。その人が 9 点を与えた査読者に会わなかった場合、結果は拒否されるはずですが、その人は偶然にもボールに会いました。そしてレビュー結果を覆しました。
最後に、人工知能研究の発展に貢献したとして論文が受理された研究者の皆様、おめでとうございます!
ここでは、ソーシャル メディアで共有されている受理された論文をいくつか紹介します。
#IJCAI 2023 採択論文エンドツーエンドのアンチノイズ音声認識におけるマルチタスク学習の勾配補正
ダウンストリームの自動音声認識システム (ASR) では、音声強調学習戦略 (SE) が、ノイズの多い音声信号によって生成されるノイズを効果的に低減できることが証明されています。 2 つのタスクを共同で最適化するタスク学習戦略。
ただし、SE ターゲットを通じて学習された強化された音声は、常に良好な ASR 結果を生み出すわけではありません。
最適化の観点から見ると、適応タスクと適応反応タスクの勾配の間に干渉が発生する場合があり、これによりマルチタスク学習が妨げられ、最終的には適応反応のパフォーマンスの低下につながります。 。

論文リンク: https://arxiv.org/pdf/2302.11362.pdf
この論文では、ノイズに強い音声認識におけるタスク勾配間の干渉問題を解決するための、シンプルで効果的な勾配補償 (GR) 方法を提案します。
具体的には、SE タスクの勾配は、最初に ASR 勾配と鋭角で動的サーフェスに投影され、それらの間の競合を排除し、ASR の最適化を支援します。
さらに、2 つの勾配のサイズは、支配的な ASR タスクが SE 勾配によって誤解されるのを防ぐために適応的に調整されます。
実験結果は、この方法が勾配干渉の問題をより適切に解決できることを示しています。マルチタスク学習ベースラインでは、9.3% を達成し、RATS および CHiME-4 データセットでは 11.1 を達成しました。 % 相対的な単語誤り率 (WER) の減少。
簡潔な論理スキーマを構築するための Tsetlin machine 句のサイズの制約
Tsetlin Machine (TM) はロジックベースの透過的でハードウェアに優しいという重要な利点を持つ機械学習アプローチ。
TM は、ますます多くのアプリケーションでディープ ラーニングの精度と同等かそれを上回っていますが、大規模な文節プーリングでは、多くのリテラル (長い文節) を含む文節が生成され、理解しにくくなる傾向があります。
さらに、句が長くなると、ハードウェア内の句ロジックのスイッチング アクティビティが増加し、消費電力が高くなります。

紙のリンク: https://arxiv.org/abs/2301.08190 ##本稿では、節サイズにソフト制約を設定できる新しい TM 学習法である節サイズ制約学習法 (CSC-TM) を紹介します。
制約で許可されている以上のリテラルが句に含まれると、リテラルは除外されるため、より大きな句は短時間しか表示されません。
CSC-TM を評価するために、研究者らは表形式データ、自然言語テキスト、画像、ボード ゲームに対して分類、クラスタリング、回帰実験を実施しました。
結果は、CSC-TM が最大 80 倍のテキスト削減で精度を維持し、実際に TREC、IMDb、および BBC Sports が文節が短いほど精度が高く、精度がピークに達した後はゆっくりと低下することを示しています。文節のサイズが単一のテキストに近づくにつれて減少します。
この記事では、最終的に CSC-TM の消費電力を分析し、新しい収束特性を取得します。
#DNN 検証の問題: ディープ ニューラル ネットワークへの安全でない入力の計算
ディープ ニューラル ネットワークはますます多くの機能を備えています。これは主に、自動運転など、高レベルのセキュリティを必要とする重要なタスクに使用されますが、最も高度な検証ツールを使用して、DNN が安全でないかどうかを確認できます。一部の属性 (つまり、少なくとも 1 つの安全でない入力構成があるかどうか) については、モデルの「はい/いいえ」出力は、他の目的 (シールド、モデルの選択、トレーニングの改善など) には十分な情報が得られません。
紙のリンク: https://arxiv.org/abs/2301.07068
##この論文では、#DNN-Verification 問題を紹介します。これには、特定のセキュリティ プロパティの違反につながる DNN 入力構成の数を数えることが含まれます。研究者は、この問題の複雑さを分析し、新しいアプローチを提案します。正確な違反数。 
問題は P 完全であるため、計算要件を大幅に削減しながら、証明可能に正しい確率限界のカウントを提供する確率的近似法を提案します。
この論文では、セーフティ クリティカルな一連のベンチマーク、近似法の有効性を実証し、制約の厳しさを評価する実験結果も紹介しています。
以上が2023年卒業論文リストの解釈:合格したドラフトに怯えていますか?反論で運命を変えるのは難しいですか?査読者には偏見があるのでしょうか?の詳細内容です。詳細については、PHP 中国語 Web サイトの他の関連記事を参照してください。

ホットAIツール

Undresser.AI Undress
リアルなヌード写真を作成する AI 搭載アプリ

AI Clothes Remover
写真から衣服を削除するオンライン AI ツール。

Undress AI Tool
脱衣画像を無料で

Clothoff.io
AI衣類リムーバー

Video Face Swap
完全無料の AI 顔交換ツールを使用して、あらゆるビデオの顔を簡単に交換できます。

人気の記事
ホットツール

メモ帳++7.3.1
使いやすく無料のコードエディター

SublimeText3 中国語版
中国語版、とても使いやすい

ゼンドスタジオ 13.0.1
強力な PHP 統合開発環境

ドリームウィーバー CS6
ビジュアル Web 開発ツール

SublimeText3 Mac版
神レベルのコード編集ソフト(SublimeText3)
ホットトピック
 7791
7791
 15
1644
14
1401
52
1298
25
1234
29
15
1644
14
1401
52
1298
25
1234
29

 Stable Diffusion 3 の論文がついに公開され、アーキテクチャの詳細が明らかになりましたが、Sora の再現に役立つでしょうか?
Mar 06, 2024 pm 05:34 PM
Stable Diffusion 3 の論文がついに公開され、アーキテクチャの詳細が明らかになりましたが、Sora の再現に役立つでしょうか?
Mar 06, 2024 pm 05:34 PM
StableDiffusion3 の論文がついに登場しました!このモデルは2週間前にリリースされ、Soraと同じDiT(DiffusionTransformer)アーキテクチャを採用しており、リリースされると大きな話題を呼びました。前バージョンと比較して、StableDiffusion3で生成される画像の品質が大幅に向上し、マルチテーマプロンプトに対応したほか、テキスト書き込み効果も向上し、文字化けが発生しなくなりました。 StabilityAI は、StableDiffusion3 はパラメータ サイズが 800M から 8B までの一連のモデルであると指摘しました。このパラメーター範囲は、モデルを多くのポータブル デバイス上で直接実行できることを意味し、AI の使用を大幅に削減します。
 ICCV'23論文賞「Fighting of Gods」! Meta Divide Everything と ControlNet が共同で選ばれました、審査員を驚かせた記事がもう 1 つありました
Oct 04, 2023 pm 08:37 PM
ICCV'23論文賞「Fighting of Gods」! Meta Divide Everything と ControlNet が共同で選ばれました、審査員を驚かせた記事がもう 1 つありました
Oct 04, 2023 pm 08:37 PM
フランスのパリで開催されたコンピュータービジョンのトップカンファレンス「ICCV2023」が閉幕しました。今年の論文賞はまさに「神と神の戦い」です。たとえば、最優秀論文賞を受賞した 2 つの論文には、ヴィンセント グラフ AI の分野を覆す研究である ControlNet が含まれていました。 ControlNet はオープンソース化されて以来、GitHub で 24,000 個のスターを獲得しています。拡散モデルであれ、コンピュータ ビジョンの全分野であれ、この論文の賞は当然のことです。最優秀論文賞の佳作は、同じく有名なもう 1 つの論文、Meta の「Separate Everything」「Model SAM」に授与されました。 「Segment Everything」は、発売以来、後発のものも含め、さまざまな画像セグメンテーション AI モデルの「ベンチマーク」となっています。
 チャットのスクリーンショットから AI レビューの隠されたルールが明らかになります。 AAAI 3000元は強力に受け入れられますか?
Apr 12, 2023 am 08:34 AM
チャットのスクリーンショットから AI レビューの隠されたルールが明らかになります。 AAAI 3000元は強力に受け入れられますか?
Apr 12, 2023 am 08:34 AM
AAAI 2023 の論文提出期限が近づいていたとき、AI 投稿グループの匿名チャットのスクリーンショットが突然 Zhihu に表示されました。そのうちの1人は、「3,000元で強力なサービスを提供できる」と主張した。このニュースが発表されるとすぐに、ネットユーザーの間で国民の怒りを引き起こした。ただし、まだ急ぐ必要はありません。 Zhihuのボス「Fine Tuning」は、これはおそらく単に「言葉による喜び」である可能性が高いと述べた。 『ファイン・チューニング』によると、挨拶や集団犯罪はどの分野でも避けられない問題だという。 openreview の台頭により、cmt のさまざまな欠点がますます明らかになり、小さなサークルが活動できる余地は将来的には小さくなるでしょうが、余地は常にあります。これは個人の問題であり、投稿システムや仕組みの問題ではないからです。オープンRの紹介
 紙のイラストも拡散モデルを使用して自動生成でき、ICLR にも受け入れられます。
Jun 27, 2023 pm 05:46 PM
紙のイラストも拡散モデルを使用して自動生成でき、ICLR にも受け入れられます。
Jun 27, 2023 pm 05:46 PM
生成 AI は人工知能コミュニティに旋風を巻き起こし、個人も企業も、Vincent 写真、Vincent ビデオ、Vincent 音楽など、関連するモーダル変換アプリケーションの作成に熱心になり始めています。最近、ServiceNow Research や LIVIA などの科学研究機関の数人の研究者が、テキストの説明に基づいて論文内のグラフを生成しようとしました。この目的のために、彼らは FigGen の新しい手法を提案し、関連する論文も TinyPaper として ICLR2023 に掲載されました。絵用紙のアドレス: https://arxiv.org/pdf/2306.00800.pdf 絵用紙のチャートを生成するのは何がそんなに難しいのかと疑問に思う人もいるかもしれません。これは科学研究にどのように役立ちますか?
 NeRFと自動運転の過去と現在、10本近くの論文をまとめました!
Nov 14, 2023 pm 03:09 PM
NeRFと自動運転の過去と現在、10本近くの論文をまとめました!
Nov 14, 2023 pm 03:09 PM
Neural Radiance Fieldsは2020年に提案されて以来、関連論文の数が飛躍的に増加し、3次元再構成の重要な分野となっただけでなく、自動運転の重要なツールとして研究の最前線でも徐々に活発になってきています。 NeRF は、過去 2 年間で突然出現しました。その主な理由は、特徴点の抽出とマッチング、エピポーラ幾何学と三角形分割、PnP とバンドル調整、および従来の CV 再構成パイプラインのその他のステップをスキップし、メッシュ再構成、マッピング、ライト トレースさえもスキップするためです。 、2D から直接入力画像を使用して放射線野を学習し、実際の写真に近いレンダリング画像が放射線野から出力されます。言い換えれば、ニューラル ネットワークに基づく暗黙的な 3 次元モデルを指定されたパースペクティブに適合させます。
 中国チームが最優秀論文賞と最優秀システム論文賞を受賞し、CoRLの研究成果が発表されました。
Nov 10, 2023 pm 02:21 PM
中国チームが最優秀論文賞と最優秀システム論文賞を受賞し、CoRLの研究成果が発表されました。
Nov 10, 2023 pm 02:21 PM
2017 年に初めて開催されて以来、CoRL はロボット工学と機械学習の交差点における世界トップクラスの学術会議の 1 つになりました。 CoRL は、理論と応用を含むロボット工学、機械学習、制御などの複数のトピックをカバーするロボット学習研究のための単一テーマのカンファレンスであり、2023 年 CoRL カンファレンスは 11 月 6 日から 9 日まで米国アトランタで開催されます。公式データによると、今年は25か国から199本の論文がCoRLに選ばれた。人気のあるトピックには、演算、強化学習などが含まれます。 CoRLはAAAIやCVPRといった大規模なAI学会に比べて規模は小さいものの、今年は大型モデル、身体化知能、ヒューマノイドロボットなどの概念の人気が高まる中、関連研究も注目されるだろう。
 CVPR 2023 ランキング発表、採択率は 25.78%! 2,360 件の論文が受理され、投稿数は 9,155 件に急増しました。
Apr 13, 2023 am 09:37 AM
CVPR 2023 ランキング発表、採択率は 25.78%! 2,360 件の論文が受理され、投稿数は 9,155 件に急増しました。
Apr 13, 2023 am 09:37 AM
ちょうど今、CVPR 2023 が次のような記事を発表しました: 今年は記録的な 9,155 件の論文 (CVPR2022 より 12% 増) を受け取り、2,360 件の論文を受理し、受理率は 25.78% でした。統計によると、CVPRへの投稿数は2010年から2016年の7年間で1,724件から2,145件に増加しただけです。 2017年以降は急上昇して高度成長期に入り、2019年には初めて5,000件を超え、2022年には投稿数が8,161件に達した。ご覧のとおり、今年は合計 9,155 件の論文が投稿され、確かに記録を樹立しました。流行が緩和された後、今年のCVPRサミットはカナダで開催される予定だ。今年はシングルトラックカンファレンスとなり、従来の口頭選考は中止される。グーグルリサーチ
 上海交通大学の卒業生が最優秀論文賞を受賞、ロボット工学の最高峰カンファレンスCoRL 2022の賞も発表
Apr 11, 2023 pm 11:43 PM
上海交通大学の卒業生が最優秀論文賞を受賞、ロボット工学の最高峰カンファレンスCoRL 2022の賞も発表
Apr 11, 2023 pm 11:43 PM
2017 年に初めて開催されて以来、CoRL はロボット工学と機械学習の交差点における世界トップクラスの学術会議の 1 つになりました。 CoRL はロボット学習研究のための単一トラックのカンファレンスであり、理論や応用を含むロボット工学、機械学習、制御などの複数のトピックをカバーしています。 2022年CoRLカンファレンスは12月14日から18日までニュージーランドのオークランドで開催されます。この会議には合計 504 件の投稿があり、最終的に 34 件の口頭論文、163 件のポスター論文が受理され、採択率は 39% でした。現在、CoRL 2022 は、Best Paper Award、Best System Paper Award、Special Innovation Award を含むすべての賞を発表しています。ペンシルベニア大学でのGRASP実験
