

Java ガベージ コレクションのメカニズムを理解する

メモリ セットとカード テーブルについて話す前に、まず世代間参照の問題について紹介します。
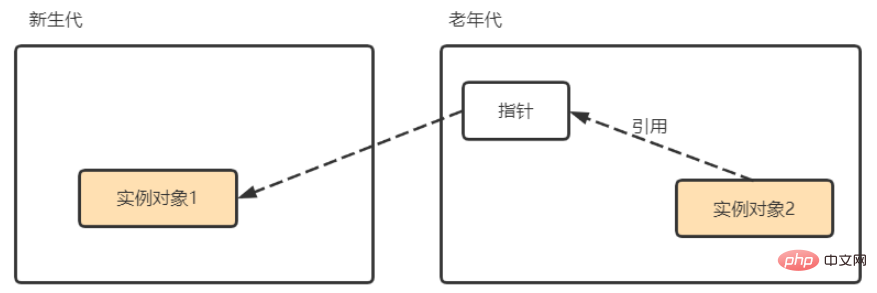
新世代領域に限定したコレクション(マイナーGC)を行いたいが、新世代のインスタンスオブジェクト1が旧世代で参照されている場合を見つけるには、この領域 (新しい世代) で生き残っているすべてのオブジェクトを削除するには、固定された GC ルートに加えて、古い世代全体のすべてのオブジェクトをさらに走査して、到達可能性分析結果の正確性を確認する必要があります。その逆も。古い世代全体のすべてのオブジェクトを走査するという解決策は理論的には実現可能ですが、メモリのリサイクルに大きなパフォーマンスの負荷がかかることは間違いありません。
実際、世代間の参照の問題は、新世代と旧世代の間だけでなく、G1、ZGC、Shenandoah など、部分領域コレクション (部分 GC) 動作を伴うすべてのガベージ コレクターにも発生します。すべてのデバイスが同じ問題に直面します。
では、世代間参照を解決するにはどうすればよいでしょうか?
まず第一に、世代を越えた引用は、同世代の引用と比較して非常に少数にすぎません。その理由は、世代を超えて参照されるオブジェクトは同時に存続するか消滅する傾向があるためです (たとえば、新しい世代のオブジェクトに世代間の参照がある場合、古い世代のオブジェクトは消滅しにくいため、この参照により新しい世代のオブジェクトが存続することが可能になります)世代オブジェクトは収集時に収集されます。存続し、古くなると古い世代に昇格します。その際、世代間の参照も削除されます)。
上記の内容に基づいて、少数の世代間参照を見つけるために古い世代全体をスキャンする必要もなくなりました。また、各オブジェクトが存在するかどうか、およびどのオブジェクトがどの世代間の参照であるかを記録するためにスペースを無駄にする必要もなくなりました。世代参照が存在します。古い世代全体をスキャンして、少数の世代間参照を確認するだけで済みます。グローバル データ構造を作成します (この構造は「記憶セット」と呼ばれます)。この構造は、古い世代をいくつかの小さなブロックに分割します。そして、古い世代のどのメモリ部分が世代間参照を持つかを特定します。その後、マイナー GC が発生すると、世代間参照を含むメモリの小さなブロック内のオブジェクトのみがスキャンのために GCRoot に追加されます。この方法では、オブジェクトの参照関係が変更された場合 (オブジェクト自体や特定の属性の割り当てなど)、記録されたデータの正確さを維持する必要があり、実行時のオーバーヘッドが若干増加しますが、それでも古い世代全体をスキャンするよりもコスト効率が高くなります。収集中のものです。
このグローバル データ構造メモリ セットを紹介しましょう。
メモリ セット
メモリ セットは、非収集領域から収集領域へのポインタのセットを記録するために使用される抽象データ構造です。効率とコストを考慮しない場合、最も単純な実装では、次のコードに示すように、非コレクション領域に世代間参照を含むすべてのオブジェクト配列を使用してこのデータ構造を実装できます。レコード 世代間の参照オブジェクトを含む実装ソリューションは、スペース使用量と保守コストの点で非常に高価です。ガベージ コレクションのシナリオでは、コレクターはメモリ セットを使用して、特定の非コレクション領域にコレクション領域を指すポインターがあるかどうかを判断するだけでよく、これらの世代間ポインターの詳細をすべて知る必要はありません。設計者はメモリ セットを実装するときに、メモリ セットのストレージとメンテナンスのコストを節約するために、より粗いレコード粒度を選択できます。以下に、選択できるレコードの精度をいくつか示します (もちろん、この範囲外を選択することもできます):
- ワード長の精度: 各レコードは 1 つのマシン語長まで正確です (つまり、プロセッサ (一般的な 32 ビットまたは 64 ビットなどのアドレス指定ビットの数、この精度によってマシンが物理メモリ アドレスにアクセスするために使用するポインタの長さが決まります)、このワードには世代間ポインタが含まれます。
- オブジェクトの精度: 各レコードはオブジェクトに対して正確であり、オブジェクトには世代間のポインターを含むフィールドがあります。
- カードの精度: 各レコードはメモリ領域に対して正確であり、この領域には世代間ポインタを含むオブジェクトがあります。
- 上記の 3 番目のタイプの「カード精度」は、「カード テーブル」と呼ばれるメソッドを使用してメモリ セットを実装することを指します。これは、現在最も一般的に使用されているメモリ セットの実装です。
カードリストとメモリーセットの関係は何ですか?
以前にメモリ セットを紹介したとき、メモリ セットは実際には「抽象」データ構造であると述べました。抽象化とは、メモリ セットの動作上の意図を定義するだけであり、メモリ セットの特定の実装を定義するものではないことを意味します。その振る舞い。カード テーブルはメモリ セットの特定の実装であり、メモリ セットの記録精度、ヒープ メモリとのマッピング関係などを定義します。メモリセットとカードテーブルの関係は、JavaにおけるMapとHashMapの関係(つまり、インターフェースと実装クラスの関係)から類推して理解できます。
メモリ セットの具体的な実装について詳しく説明します カード テーブル
カード テーブル
カード テーブルは、各要素のバイト配列 CARD_TABLE[] を使用して実装されます。識別されたメモリ領域は特定のサイズのメモリ ブロックです。各メモリ ブロックはカード ページと呼ばれます。ホットスポットで使用されるカード ページのサイズは 2^9、つまり 512 バイトです。以下の図に示すように、
#このようにして、カード ページに応じて特定の領域を分割することができます。新しい世代の領域をガベージ コレクションしたい場合は、次のようにすることができます。時代エリアは下図のようにカードページごとに分かれています。 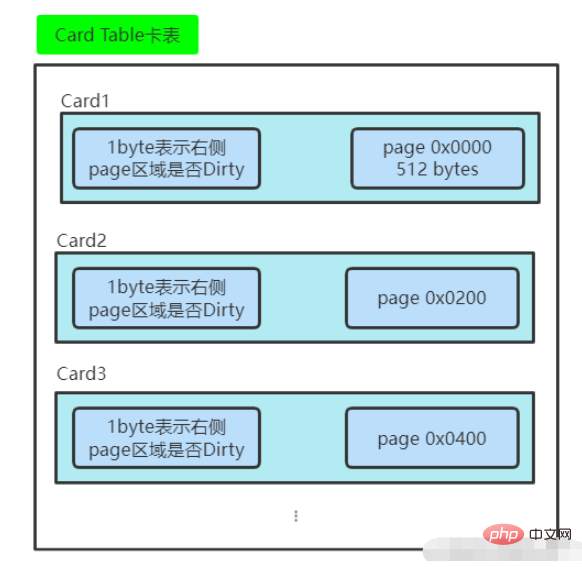
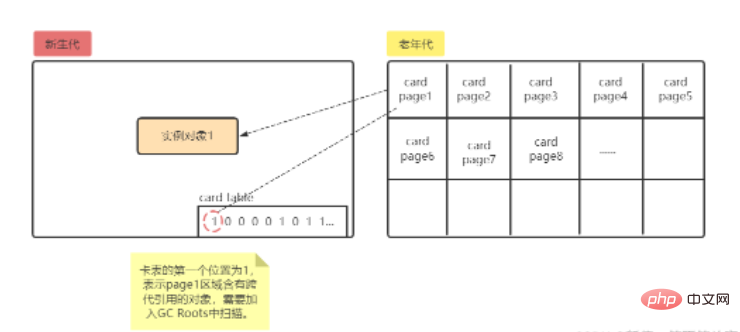
図に示すように、cardpage1 には新しい世代を指す世代間参照があるため、対応するカード テーブルの最初の位置は 1 となり、カードページ 1 に新しい世代が存在することを示します。このページ領域オブジェクトの世代間アプリケーション。
カード テーブル アングル: page1 には世代を超えた飲酒オブジェクトがあるため、カード テーブルに対応する最初の位置は 1 として記録され、page1 要素がダーティであることを示します。
メモリ リサイクルの観点: カード テーブルの最初の位置は 1 であるため、ページ領域に世代を超えたアプリケーション オブジェクトがあり、この領域をスキャンする必要があることを示します。ゴミ収集。
カード ページのメモリには通常、複数のオブジェクトが含まれています。カード ページ内の 1 つ (または複数) のオブジェクトのフィールドに世代間ポインタがある限り、対応するカード テーブルは次のようになります。配列要素の値は 1 としてマークされます。これは、要素がダーティ (Dirty) であることを意味します。そうでない場合は、0 としてマークされます。ガベージ コレクションが発生すると、カード テーブル内のダーティ要素がフィルターで除外されている限り、どのカード ページ メモリ ブロックに世代間ポインタが含まれているかを簡単に見つけ出し、それらを GC ルートに追加して一緒にスキャンできます。これにより、古い世代全体をスキャンする必要がなくなり、GC ルートのスキャン範囲が大幅に減少します。
以上がJava ガベージ コレクションのメカニズムを理解するの詳細内容です。詳細については、PHP 中国語 Web サイトの他の関連記事を参照してください。

ホットAIツール

Undresser.AI Undress
リアルなヌード写真を作成する AI 搭載アプリ

AI Clothes Remover
写真から衣服を削除するオンライン AI ツール。

Undress AI Tool
脱衣画像を無料で

Clothoff.io
AI衣類リムーバー

AI Hentai Generator
AIヘンタイを無料で生成します。

人気の記事
ホットツール

メモ帳++7.3.1
使いやすく無料のコードエディター

SublimeText3 中国語版
中国語版、とても使いやすい

ゼンドスタジオ 13.0.1
強力な PHP 統合開発環境

ドリームウィーバー CS6
ビジュアル Web 開発ツール

SublimeText3 Mac版
神レベルのコード編集ソフト(SublimeText3)
ホットトピック
 7514
7514
 15
1378
52
79
11
19
64
15
1378
52
79
11
19
64


 Java の乱数ジェネレーター
Aug 30, 2024 pm 04:27 PM
Java の乱数ジェネレーター
Aug 30, 2024 pm 04:27 PM
Java の乱数ジェネレーターのガイド。ここでは、Java の関数について例を挙げて説明し、2 つの異なるジェネレーターについて例を挙げて説明します。
 ジャワのウェカ
Aug 30, 2024 pm 04:28 PM
ジャワのウェカ
Aug 30, 2024 pm 04:28 PM
Java の Weka へのガイド。ここでは、weka java の概要、使い方、プラットフォームの種類、利点について例を交えて説明します。

 Java Springのインタビューの質問
Aug 30, 2024 pm 04:29 PM
Java Springのインタビューの質問
Aug 30, 2024 pm 04:29 PM
この記事では、Java Spring の面接で最もよく聞かれる質問とその詳細な回答をまとめました。面接を突破できるように。
 Java 8 Stream Foreachから休憩または戻ってきますか?
Feb 07, 2025 pm 12:09 PM
Java 8 Stream Foreachから休憩または戻ってきますか?
Feb 07, 2025 pm 12:09 PM
Java 8は、Stream APIを導入し、データ収集を処理する強力で表現力のある方法を提供します。ただし、ストリームを使用する際の一般的な質問は次のとおりです。 従来のループにより、早期の中断やリターンが可能になりますが、StreamのForeachメソッドはこの方法を直接サポートしていません。この記事では、理由を説明し、ストリーム処理システムに早期終了を実装するための代替方法を調査します。 さらに読み取り:JavaストリームAPIの改善 ストリームを理解してください Foreachメソッドは、ストリーム内の各要素で1つの操作を実行する端末操作です。その設計意図はです
 Java での日付までのタイムスタンプ
Aug 30, 2024 pm 04:28 PM
Java での日付までのタイムスタンプ
Aug 30, 2024 pm 04:28 PM
Java での日付までのタイムスタンプに関するガイド。ここでは、Java でタイムスタンプを日付に変換する方法とその概要について、例とともに説明します。
 カプセルの量を見つけるためのJavaプログラム
Feb 07, 2025 am 11:37 AM
カプセルの量を見つけるためのJavaプログラム
Feb 07, 2025 am 11:37 AM
カプセルは3次元の幾何学的図形で、両端にシリンダーと半球で構成されています。カプセルの体積は、シリンダーの体積と両端に半球の体積を追加することで計算できます。このチュートリアルでは、さまざまな方法を使用して、Javaの特定のカプセルの体積を計算する方法について説明します。 カプセルボリュームフォーミュラ カプセルボリュームの式は次のとおりです。 カプセル体積=円筒形の体積2つの半球体積 で、 R:半球の半径。 H:シリンダーの高さ(半球を除く)。 例1 入力 RADIUS = 5ユニット 高さ= 10単位 出力 ボリューム= 1570.8立方ユニット 説明する 式を使用してボリュームを計算します。 ボリューム=π×R2×H(4
