

オープンソースのバイリンガル対話モデルが GitHub で人気を集めており、AI はナンセンスを修正する必要がないと主張しています

この記事は、AI New Media Qubit (公開アカウント ID: QbitAI) の許可を得て転載しています。転載する場合は、出典元にご連絡ください。
家庭用対話ロボット ChatGLM は、 GPT-4と同日。
Zhipu AI と清華大学 KEG 研究室が共同で立ち上げたアルファ内部ベータ版が公開されました。
#この偶然は、Zhipu AI の創設者兼 CEO である Zhang Peng に、言葉では言い表せない複雑な感情を与えました。しかし、OpenAI のテクノロジーがどれほど素晴らしくなっているかを見て、AI の新しい開発に麻痺していたこの技術ベテランは突然再び興奮しました。
特に GPT-4 記者会見の生中継を見ているとき、彼はスクリーン上の写真を見て、しばらく微笑み、別のセクションを見て、しばらくニヤニヤしていました。
Zhang Peng 氏が率いる Zhipu AI は設立以来、大型模型分野の一員であり、「機械に人間のように思考させる」というビジョンを掲げてきました。
しかし、道はでこぼこでした。ほとんどすべての大規模モデル会社と同様に、データ不足、機械不足、資金不足といった同じ問題に直面しています。幸いなことに、途中で無料サポートを提供する組織や企業がいくつかあります。
昨年 8 月、同社は多くの科学研究機関と協力して、GPT-3 に近いか同等のオープンソースのバイリンガル事前トレーニング済み大規模言語モデル GLM-130B を開発しました。 175B (davinci) の精度と悪意の指標の点で、後に ChatGLM のベースとなりました。 ChatGLMと同時にオープンソース化された62億パラメータバージョンのChatGLM-6Bも、1枚のカードで1,000元で実行できる。
GLM-130B に加えて、Zhipu のもう 1 つの有名な製品は、学界の著名人によって使用されている AI 人材プール AMiner です。 #今回と GPT-4 が登場したのと同じ日に、OpenAI のスピードとテクノロジーは Zhang Peng と Zhipu チームに大きなプレッシャーをかけました。
「重大なナンセンス」は修正する必要がありますか? 
人間による評価
の波を開始しました。 他のことについては話さないでください。数ラウンドのテストの後、ChatGLM が ChatGPT と New Bing の両方が持つスキルを持っていることを見つけるのは難しくありません。これは、鶏とウサギのケージの問題で -33 羽のひよこを計算することに限定されません。会話型 AI を「おもちゃ」またはオフィスのアシスタントと見なしているほとんどの人にとって、精度を向上させる方法は特別な関心事であり重要な点です。
対話AIがマジで意味不明なことを言っているのですが修正できますか?本当に修正する必要があるのでしょうか?##△ChatGPT の典型的なナンセンス引用文
Zhang Peng は個人的な意見を表明する際に、この「頑固な態度」を正したいと述べました。病気」それ自体が非常に奇妙なものです。 
このトピックに関するさまざまな見解は、さまざまな人々のマシンに対する理解に密接に関係しています。張鵬氏によると、「AI のこのような振る舞いを批判する人たちは、常に機械について細心の注意を払って理解していたのかもしれません。機械は 0 か 1 であり、厳密で正確です。この概念を持つ人々は、機械は間違いをすべきではないし、間違いを犯してはならないと無意識のうちに信じています」 。
何が起こっているのかを知ることは、その理由を知ることと同じくらい重要です。「これは、誰もがテクノロジー全体の進化と変化、およびテクノロジーの性質を深く理解していないという事実によるものかもしれません」 .”
Zhang Peng の雇用に関する学び たとえ話として:
AI テクノロジーのロジックと原則は、実際には人間の脳をシミュレートしています。
これまでに学んだことに直面すると、第一に、知識自体が間違っているか、更新や反復が行われる可能性があります (エベレストの標高など)。第二に、学んだ知識の間に矛盾が生じる可能性があります。
人間が間違いを犯すのと同じように、AI も間違いを犯します。その理由は、知識の不足、または特定の知識の間違った適用です。
要するに、これは普通のことです。
同時に、Zhipu は、OpenAI が黙って CloseAI に目を向けていることに確かに注目しています。
GPT-3 からクローズド ソースを選択し、アーキテクチャ レベルでさらに詳細をカバーする GPT-4 へ OpenAI の外部からの反応の 2 つの理由は、競争とセキュリティです。
Zhang Peng 氏は、OpenAI の意図について理解を表明しました。
「それでは、オープンソースの道を選択するということは、Zhipu には競争とセキュリティに関する考慮事項が存在するのではないでしょうか?」
「確かにそのようなことはあります。しかし、クローズド ソースで確実にセキュリティ問題を解決できるでしょうか? 私はそうは思いません。そして、世界には賢い人がたくさんいると信じており、競争は業界全体とエコロジー全体の急速な進歩を促進する質の高い触媒です。」 たとえば、OpenAI と競合することです。追いつくだけでも競争の一部です。ここでのキャッチアップは、OpenAI 研究の方向性がさらなる目標を達成する唯一の方法であるという信念に基づいた声明のプロセスですが、OpenAI に追いつくことが最終的な目標ではありません。
「追いついたからといって止められるわけではない。追いつくプロセスは、シリコンバレーのモデルをそのまま真似しなければならないということではない。中国の特性やトップを動員する利点を活かすこともできる」 - 開発速度の低下を補うことができるように、大きなことを行うことに集中するためのレベル設計。
当社には 2019 年から現在まで 4 年以上の経験がありますが、Zhipu は落とし穴を回避するためのガイドラインをあえて提供していません。しかし、Zhipu は全体的な方向性を理解しており、これは CCF と協議している Zhipu によって明らかにされた共通のアイデアでもあります -
大型モデル技術の誕生は非常に包括的で複雑な体系的なプロジェクトです。
それはもはや、少数の賢い頭が研究室で熟考し、数本の髪の毛を落とし、いくつかの実験を行い、いくつかの論文を発表するという問題ではありません。独自の理論的革新に加えて、強力なエンジニアリング実装およびシステム化能力、さらには優れた製品能力も必要です。
ChatGPT と同様に、適切なシナリオを選択し、80 歳から 8 歳までの誰もが使用できる製品をセットアップしてパッケージ化します。
コンピューティング能力、アルゴリズム、データはすべて、人材、特にシステム エンジニアリングの専門家によって支えられており、その重要性は過去よりもはるかに高まっています。
この理解に基づいて、Zhang Peng 氏は、知識システム (知識グラフ) を大規模なモデル フィールドに追加し、2 つが左脳と右脳のように体系的に機能できるようにすることが、知恵グラフの次のステップであることを明らかにしました。研究と実験のステップ。
GitHub で最も人気のあるバイリンガル会話モデル
ChatGLM 全体は、ChatGPT の設計思想を指します。
つまり、コードの事前トレーニングが GLM-130B バイリンガル ベース モデルに注入され、教師あり微調整およびその他のテクノロジを通じて人間の意図の調整が実現されます (つまり、機械の答えを人間の価値観に準拠させる)そして人間の期待)。
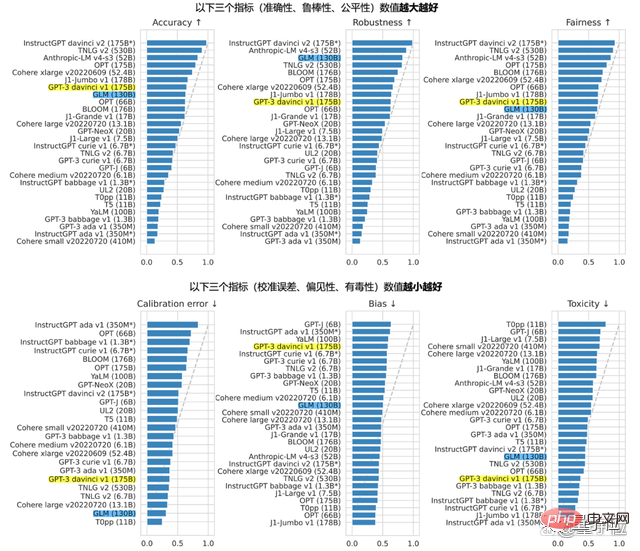
背後に 1,300 億のパラメータを備えた GLM-130B は、Zhipu と清華大学の KEG 研究室によって共同開発されました。 BERT、GPT-3、T5 のアーキテクチャとは異なり、GLM-130B は複数の目的関数を含む自己回帰事前トレーニング モデルです。
昨年 8 月に GLM-130B が一般公開され、同時にオープンソース化されました。スタンフォードのレポートでは、そのパフォーマンスは複数のタスクにおいて顕著でした。
#オープンソースへのこだわりは、Zhipu が AGI への道で孤独な先駆者になりたくないことから来ています。
これが、GLM-130B をオープンした後、今年も ChatGLM-6B のオープンソースを継続する理由でもあります。
ChatGLM-6Bは、パラメータサイズ62億のモデルの「縮小版」で、技術ベースはChatGLMと同じで、中国語の質疑応答や対話機能を追加し始めています。
オープンソースを継続する理由は 2 つあります。
1 つは、事前トレーニング済みモデルの生態を拡張し、より多くの人々を大規模モデルの研究に投資してもらい、多くの既存の研究問題を解決することです。
もう 1 つは、大規模モデルが次のようなことができることを期待することです。インフラストラクチャとして使用され、その後のより大きな価値を生み出すのに役立ちます。
オープンソース コミュニティに参加することは確かに魅力的です。 ChatGLM の内部テストから数日以内に、ChatGLM-6B は GitHub 上で 8.5,000 個のスターを獲得し、一時はトレンド リストの 1 位に躍り出ました。
この会話から、Qubit は私の目の前の実践者から次の声も聞きました:
同じバグが頻繁に発生しますが、人々の寛容さOpenAI が立ち上げた for ChatGPT は、Google の会話ロボット Bard や Baidu Wenxinyiyan のそれとは大きく異なります。
これは公平でもあり不公平でもあります。
純粋に技術的な観点から見ると、審査基準が異なるため不公平ですが、Google や Baidu などの大企業の方がより多くのリソースを占有しているため、誰もが自然に技術力が高く、より優れていると感じています。より良いものが生まれる可能性が高く、期待も高まります。
「百度に対しても、私たちに対しても、その他の機関に対しても、皆さんがもっと辛抱していただけることを願っています。」

上記の内容 , この会話の中で、Qubit は Zhang Peng と ChatGLM の体験について詳しく話しました。
以下に会話の記録を添付します。読みやすいように、本来の意味を変えずに編集・整理しました。
会話の記録
Qubit: 内部ベータ版に付けられたラベルは、それほど「普遍的」ではないようです。公式 Web サイトでは、該当する分野を教育、医療の 3 つの円で定義しています。ケアとファイナンス。
Zhang Peng: これはトレーニング データとは関係なく、主にそのアプリケーション シナリオを考慮しています。
ChatGLM は ChatGPT に似ており、会話モデルです。自然に会話のシナリオに近いアプリケーション分野はどれですか?顧客サービス、医師の診察、オンライン金融サービスなどです。このようなシナリオでは、ChatGLM テクノロジーが役割を果たすのに適しています。
Qubit: しかし、医療分野では、医師の診察を希望する人々は依然として AI に対して比較的慎重です。
Zhang Peng: 大きなモデルだけを使って戦うのは絶対にだめです! (笑)人間を完全に置き換えたい場合は、やはり注意が必要です。
現段階では、人々の作業を代替するために使用されるのではなく、作業効率を向上させるための提案を実務者に提供する、補助的な役割として使用されます。
Qubit: GLM-130B 論文のリンクを ChatGLM に投げ、トピックを簡単に要約するよう依頼しました。長い間鳴り続けましたが、それはまったくこの記事に関するものではないことが判明しました。
Zhang Peng: ChatGLM はリンクを取得できない設定になっています。これは技術的な問題ではなく、システム境界の問題であり、主にセキュリティの観点から、外部リンクに勝手にアクセスされることは避けたいと考えています。
130B の紙のテキストをコピーして入力ボックスに放り込んでみてください。通常、意味のない話はしません。
Qubit: ニワトリとウサギも同じケージに放り込み、ニワトリの数は -33 と計算されました。
Zhang Peng: 数学的処理と論理的推論の点では、まだいくつかの欠陥があり、それほど優れているとは言えません。実はこれについてはクローズドベータ版の説明書に書きました。

Qubit: Zhihu の誰かが評価を行ったところ、私のコーディング能力は平均的のようです。
Zhang Peng: コードを書く能力に関しては、かなり優れていると思います。どのようなテスト方法をとっているのかわかりません。ただし、誰と比較するかにもよりますが、ChatGPT と比較すると、ChatGLM 自体はコード データにそれほど投資していない可能性があります。
ChatGLMとChatGLM-6Bの比較と同様に、後者はパラメータが6B(62億)しかなく、全体のロジック、回答時の錯覚、長さなど総合的な能力において、ChatGLM-6Bとの差は大きくありません。縮小版とオリジナル版は明らかです。
ただし、「縮小バージョン」は通常のコンピュータに展開できるため、使いやすさが向上し、敷居が低くなります。
Qubit: 利点があります。新しい情報をよく把握しています。Twitter の現在の CEO がマスクであることは知っています。また、He Yuming が 3 月 10 日に学術界に復帰したことも知っています - 私は知りませんがGPT-4 がリリースされたことを知りません (笑)。
Zhang Peng: 特別な技術処理を行いました。
量子ビット: それは何ですか?
張鵬: 具体的な詳細には触れません。しかし、比較的最近の新しい情報に対処する方法はあります。
Qubit: では、コストを公開しますか? GLM-130B のトレーニング費用はまだ数百万かかりますが、ChatGLM での質疑応答の費用はどのくらい安くなりますか?
Zhang Peng: 大まかにテストしてコストを見積もりました。これは、OpenAI が 2 回目から最後までに発表したコストと同様で、それよりわずかに低かったです。
しかし、OpenAI の最新のオファーは元の価格の 10% に値下げされており、750 ワードあたりわずか 0.002 ドルであり、当社の価格よりも安いです。このコストは確かに驚くべきもので、モデルの圧縮、量子化、最適化などが行われたと推定されますが、そうでなければこれほど低いレベルに削減することは不可能でしょう。
弊社でも関連することを行っており、コストを抑えたいと考えています。
量子ビット: 時間の経過とともに、検索コストと同じくらい低くなることはありますか?
張鵬: いつそのような低いレベルに落ちますか?私にも分かりません。しばらく時間がかかります。
以前、検索単価の平均コストの計算を見たことがあるのですが、これは実は本業に関係しています。たとえば、検索エンジンの主なビジネスは広告であるため、コストを計算する際には総広告収入を上限として使用する必要があります。このように計算すると、考慮すべきは消費コストではなく、企業の利益と福利厚生のバランスポイントとなる。
モデル推論を行うには AI のコンピューティング能力が必要ですが、CPU のコンピューティング能力のみを使用して検索するよりも明らかにコストが高くなります。しかし、誰もが懸命に取り組んでおり、モデルの圧縮と量子化を継続するなど、多くの人がいくつかのアイデアを提案しています。
CPU のほうが安くて容量が大きいので、モデルを変換して CPU で動かしたいという人もいますが、動かせばコストは大幅に下がります。
Qubit: 最後に、人材についていくつかお話したいと思います。今、誰もが大型モデルの人材を求めて争っています。Zhipu が人材を採用できないのではないかと心配ですか?
Zhang Peng: 私たちは清華 KEG のテクノロジー プロジェクトから生まれ、常にさまざまな大学と良好な関係を築いてきました。また、社内は比較的若手に対して風通しの良い雰囲気で、同僚の75%が若手で、私はおっさんだと思われています。現在、ビッグモデルのタレントは確かに希少な商品ですが、採用の心配はまだありません。
その一方で、私たちは実際には他人に搾取されることをもっと心配しています。
以上がオープンソースのバイリンガル対話モデルが GitHub で人気を集めており、AI はナンセンスを修正する必要がないと主張していますの詳細内容です。詳細については、PHP 中国語 Web サイトの他の関連記事を参照してください。

ホットAIツール

Undresser.AI Undress
リアルなヌード写真を作成する AI 搭載アプリ

AI Clothes Remover
写真から衣服を削除するオンライン AI ツール。

Undress AI Tool
脱衣画像を無料で

Clothoff.io
AI衣類リムーバー

Video Face Swap
完全無料の AI 顔交換ツールを使用して、あらゆるビデオの顔を簡単に交換できます。

人気の記事
ホットツール

メモ帳++7.3.1
使いやすく無料のコードエディター

SublimeText3 中国語版
中国語版、とても使いやすい

ゼンドスタジオ 13.0.1
強力な PHP 統合開発環境

ドリームウィーバー CS6
ビジュアル Web 開発ツール

SublimeText3 Mac版
神レベルのコード編集ソフト(SublimeText3)
ホットトピック
 1677
1677
 14
1431
52
1334
25
1280
29
1257
24
14
1431
52
1334
25
1280
29
1257
24

 Spring Boot と OpenAI の出会いによる新しいプログラミング パラダイム
Feb 01, 2024 pm 09:18 PM
Spring Boot と OpenAI の出会いによる新しいプログラミング パラダイム
Feb 01, 2024 pm 09:18 PM
2023年、AI技術が注目を集め、プログラミング分野を中心にさまざまな業界に大きな影響を与えています。 AI テクノロジーの重要性に対する人々の認識はますます高まっており、Spring コミュニティも例外ではありません。 GenAI (汎用人工知能) テクノロジーの継続的な進歩に伴い、AI 機能を備えたアプリケーションの作成を簡素化することが重要かつ緊急になっています。このような背景から、AI 機能アプリケーションの開発プロセスを簡素化し、シンプルかつ直観的にし、不必要な複雑さを回避することを目的とした「SpringAI」が登場しました。 「SpringAI」により、開発者はAI機能を搭載したアプリケーションをより簡単に構築でき、使いやすく、操作しやすくなります。
 世界で最も強力なオープンソース MoE モデルが登場。GPT-4 に匹敵する中国語機能を備え、価格は GPT-4-Turbo のわずか 1% 近くです
May 07, 2024 pm 04:13 PM
世界で最も強力なオープンソース MoE モデルが登場。GPT-4 に匹敵する中国語機能を備え、価格は GPT-4-Turbo のわずか 1% 近くです
May 07, 2024 pm 04:13 PM
従来のコンピューティングを超える能力を備えているだけでなく、より低コストでより効率的なパフォーマンスを実現する人工知能モデルを想像してみてください。これは SF ではありません。世界で最も強力なオープンソース MoE モデルである DeepSeek-V2[1] が登場しました。 DeepSeek-V2 は、経済的なトレーニングと効率的な推論の特徴を備えた強力な専門家混合 (MoE) 言語モデルです。これは 236B のパラメータで構成されており、そのうち 21B は各マーカーをアクティブにするために使用されます。 DeepSeek67B と比較して、DeepSeek-V2 はパフォーマンスが優れていると同時に、トレーニング コストを 42.5% 節約し、KV キャッシュを 93.3% 削減し、最大生成スループットを 5.76 倍に高めます。 DeepSeek は一般的な人工知能を研究する会社です
 データに最適なエンベディング モデルの選択: OpenAI とオープンソースの多言語エンベディングの比較テスト
Feb 26, 2024 pm 06:10 PM
データに最適なエンベディング モデルの選択: OpenAI とオープンソースの多言語エンベディングの比較テスト
Feb 26, 2024 pm 06:10 PM
OpenAI は最近、最新世代の埋め込みモデル embeddingv3 のリリースを発表しました。これは、より高い多言語パフォーマンスを備えた最もパフォーマンスの高い埋め込みモデルであると主張しています。このモデルのバッチは、小さい text-embeddings-3-small と、より強力で大きい text-embeddings-3-large の 2 つのタイプに分類されます。これらのモデルがどのように設計され、トレーニングされるかについてはほとんど情報が開示されておらず、モデルには有料 API を介してのみアクセスできます。オープンソースの組み込みモデルは数多くありますが、これらのオープンソース モデルは OpenAI のクローズド ソース モデルとどう違うのでしょうか?この記事では、これらの新しいモデルのパフォーマンスをオープンソース モデルと実証的に比較します。データを作成する予定です
 大型モデル間の1対1バトル75万ラウンド、GPT-4が優勝、Llama 3が5位にランクイン
Apr 23, 2024 pm 03:28 PM
大型モデル間の1対1バトル75万ラウンド、GPT-4が優勝、Llama 3が5位にランクイン
Apr 23, 2024 pm 03:28 PM
Llama3 に関しては、新しいテスト結果が発表されました。大規模モデル評価コミュニティ LMSYS は、Llama3 が 5 位にランクされ、英語カテゴリでは GPT-4 と同率 1 位にランクされました。このリストは他のベンチマークとは異なり、モデル間の 1 対 1 の戦いに基づいており、ネットワーク全体の評価者が独自の提案とスコアを作成します。最終的に、Llama3 がリストの 5 位にランクされ、GPT-4 と Claude3 Super Cup Opus の 3 つの異なるバージョンが続きました。英国のシングルリストでは、Llama3 がクロードを追い抜き、GPT-4 と並びました。この結果について、Meta の主任科学者 LeCun 氏は非常に喜び、リツイートし、
 二代目アメカ登場!彼は観客と流暢にコミュニケーションをとることができ、表情はよりリアルで、数十の言語を話すことができます。
Mar 04, 2024 am 09:10 AM
二代目アメカ登場!彼は観客と流暢にコミュニケーションをとることができ、表情はよりリアルで、数十の言語を話すことができます。
Mar 04, 2024 am 09:10 AM
人型ロボット「アメカ」が第二世代にバージョンアップ!最近、世界移動通信会議 MWC2024 に、世界最先端のロボット Ameca が再び登場しました。会場周辺ではアメカに多くの観客が集まった。 GPT-4 の恩恵により、Ameca はさまざまな問題にリアルタイムで対応できます。 「ダンスをしましょう。」感情があるかどうか尋ねると、アメカさんは非常に本物そっくりの一連の表情で答えました。ほんの数日前、Ameca を支援する英国のロボット企業である EngineeredArts は、チームの最新の開発結果をデモンストレーションしたばかりです。ビデオでは、ロボット Ameca は視覚機能を備えており、部屋全体と特定のオブジェクトを見て説明することができます。最も驚くべきことは、彼女は次のこともできるということです。
 世界で最も強力なモデルが一夜にして交代し、GPT-4 時代の終わりを告げました。クロード3号は事前にGPT-5を狙撃し、1万ワードの論文を3秒で読み切るなど、人間に近い理解力を持っている。
Mar 06, 2024 pm 12:58 PM
世界で最も強力なモデルが一夜にして交代し、GPT-4 時代の終わりを告げました。クロード3号は事前にGPT-5を狙撃し、1万ワードの論文を3秒で読み切るなど、人間に近い理解力を持っている。
Mar 06, 2024 pm 12:58 PM
ボリュームはクレイジー、ボリュームはクレイジー、そして大きなモデルがまた変わりました。たった今、世界で最も強力な AI モデルが一夜にして交代し、GPT-4 が祭壇から引き抜かれました。 Anthropic が Claude3 シリーズの最新モデルをリリースしました 一言評価: GPT-4 を本当に粉砕します!マルチモーダルと言語能力の指標に関しては、Claude3 が勝ちます。 Anthropic 氏の言葉を借りれば、Claude3 シリーズ モデルは、推論、数学、コーディング、多言語理解、視覚において新たな業界のベンチマークを設定しました。 Anthropic は、セキュリティ概念の違いを理由に OpenAI から「離反」した従業員によって設立された新興企業であり、同社の製品は繰り返し OpenAI に大きな打撃を与えてきました。今回、Claude3は大きな手術まで受けました。
 Rust ベースの Zed エディターはオープンソース化されており、OpenAI と GitHub Copilot のサポートが組み込まれています
Feb 01, 2024 pm 02:51 PM
Rust ベースの Zed エディターはオープンソース化されており、OpenAI と GitHub Copilot のサポートが組み込まれています
Feb 01, 2024 pm 02:51 PM
著者丨コンパイル: TimAnderson丨プロデュース: Noah|51CTO Technology Stack (WeChat ID: blog51cto) Zed エディター プロジェクトはまだプレリリース段階にあり、AGPL、GPL、および Apache ライセンスの下でオープンソース化されています。このエディターは高性能と複数の AI 支援オプションを備えていますが、現在は Mac プラットフォームでのみ利用可能です。 Nathan Sobo 氏は投稿の中で、GitHub 上の Zed プロジェクトのコード ベースでは、エディター部分は GPL に基づいてライセンスされ、サーバー側コンポーネントは AGPL に基づいてライセンスされ、GPUI (GPU Accelerated User) インターフェイス部分はApache2.0ライセンス。 GPUI は Zed チームによって開発された製品です
 OpenAI Super Alignment チームの遺作: 2 つの大きなモデルがゲームをプレイし、出力がより理解しやすくなる
Jul 19, 2024 am 01:29 AM
OpenAI Super Alignment チームの遺作: 2 つの大きなモデルがゲームをプレイし、出力がより理解しやすくなる
Jul 19, 2024 am 01:29 AM
AIモデルによって与えられた答えがまったく理解できない場合、あなたはそれをあえて使用しますか?機械学習システムがより重要な分野で使用されるにつれて、なぜその出力を信頼できるのか、またどのような場合に信頼してはいけないのかを実証することがますます重要になっています。複雑なシステムの出力に対する信頼を得る方法の 1 つは、人間または他の信頼できるシステムが読み取れる、つまり、考えられるエラーが発生する可能性がある点まで完全に理解できる、その出力の解釈を生成することをシステムに要求することです。見つかった。たとえば、司法制度に対する信頼を築くために、裁判所に対し、決定を説明し裏付ける明確で読みやすい書面による意見を提供することを求めています。大規模な言語モデルの場合も、同様のアプローチを採用できます。ただし、このアプローチを採用する場合は、言語モデルが
