

「中国人民大学の研究者Lu Zhiwu氏は、マルチモーダル生成モデルに対するChatGPTの重要な影響を提案しました。」

以下は、Heart of the Machine が開催した ChatGPT および Large Model Technology Conference での Lu Zhiwu 教授の講演内容を、Heart of the Machine がそのまま編集・整理したものです。本来の意味:

皆さんこんにちは、中国人民大学のLu Zhiwuです。今日の私のレポートのタイトルは「マルチモーダル生成モデルに関する ChatGPT の重要な啓発」で、4 部構成になっています。

まず第一に、ChatGPT は研究パラダイムの革新に関するインスピレーションを私たちにもたらしてくれます。 1つ目のポイントは、ChatGPTの基礎研究パラダイムでもあり、検証を重ねてきた研究パラダイムである「ビッグモデルとビッグデータ」を活用することです。大規模なモデルが特定のレベルに達した場合にのみ、コンテキスト内学習、CoT 推論、その他の機能などの創発的な機能が備わることを強調することが特に重要です。これらの機能は非常に素晴らしいものです。
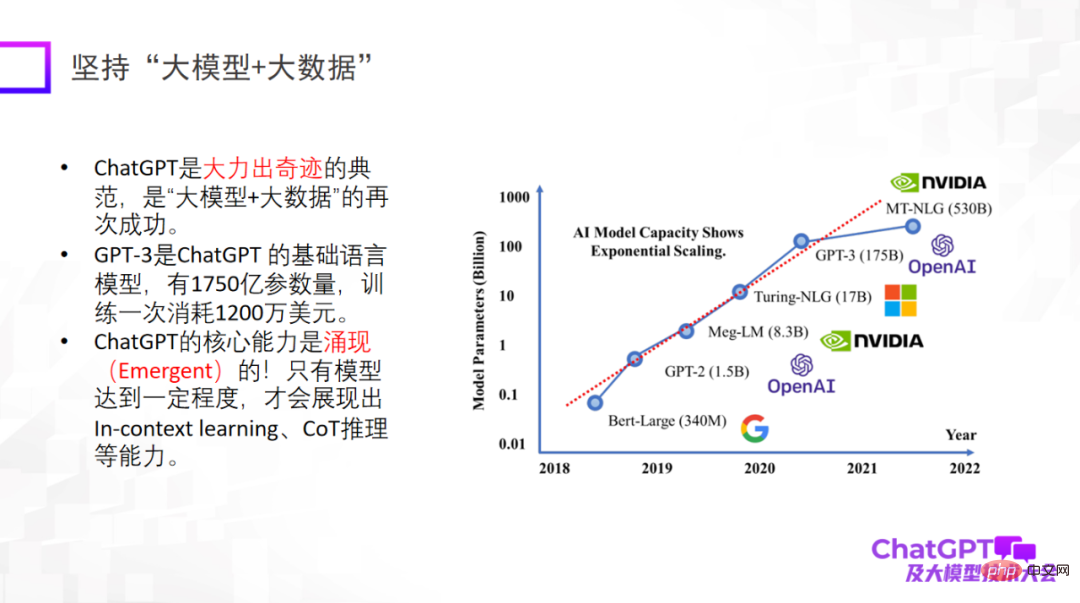
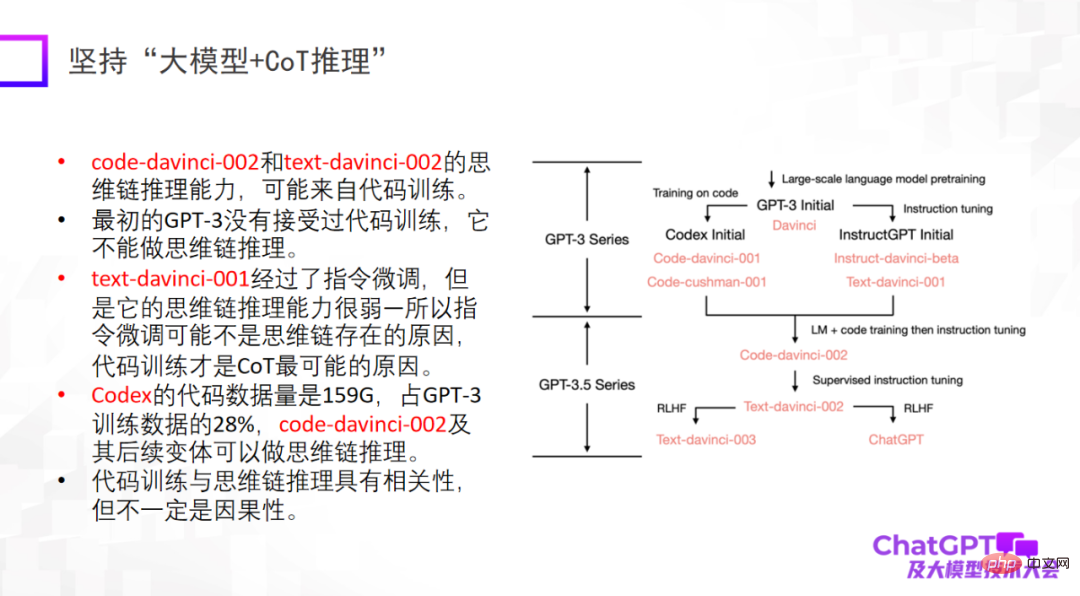
2 つ目のポイントは「大規模モデル推論」にこだわることであり、これは私が ChatGPT で最も感銘を受けた点でもあります。なぜなら、機械学習や人工知能の分野では推論が最も難しいと認識されており、ChatGPT はこの点でも画期的な進歩を遂げているからです。もちろん、ChatGPT の推論能力は主にコードのトレーニングから得られるものかもしれませんが、必然的なつながりがあるかどうかはまだ定かではありません。推論に関しては、それがどこから来るのか、あるいは推論能力をさらに高めるための他の訓練方法があるのかどうかを理解することにもっと力を入れる必要があります。
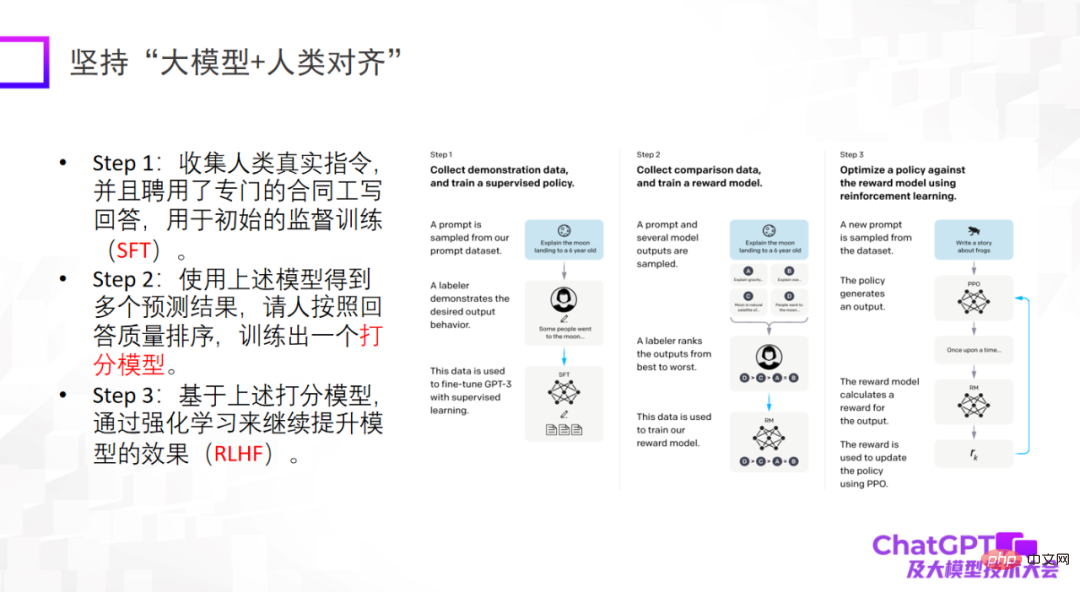
3 番目のポイントは、大規模なモデルが人間と一致している必要があるということです。これは、ChatGPT がエンジニアリングまたはモデルの観点から私たちに提供する重要なことです。着陸の視点。啓蒙。人間と連携していないと、モデルは有害な情報を大量に生成し、使用できなくなります。 3 点目は、モデルの上限を上げることではありませんが、モデルの信頼性と安全性は確かに非常に重要です。
ChatGPT の出現は、私自身を含む多くの分野に大きな影響を与えました。私は数年間マルチモダリティを行ってきたので、なぜこれほど強力なモデルを作らなかったのかを考え始めます。
ChatGPT は言語またはテキストのユニバーサル生成です。マルチモーダル ユニバーサル生成の分野における最新の進歩を見てみましょう。マルチモーダルな事前トレーニング モデルは、マルチモーダルな一般生成モデルに変換され始めており、いくつかの予備調査が行われています。まずは、2019年にGoogleが提案したFlamingoモデルを見てみましょう。以下の図がそのモデル構造です。
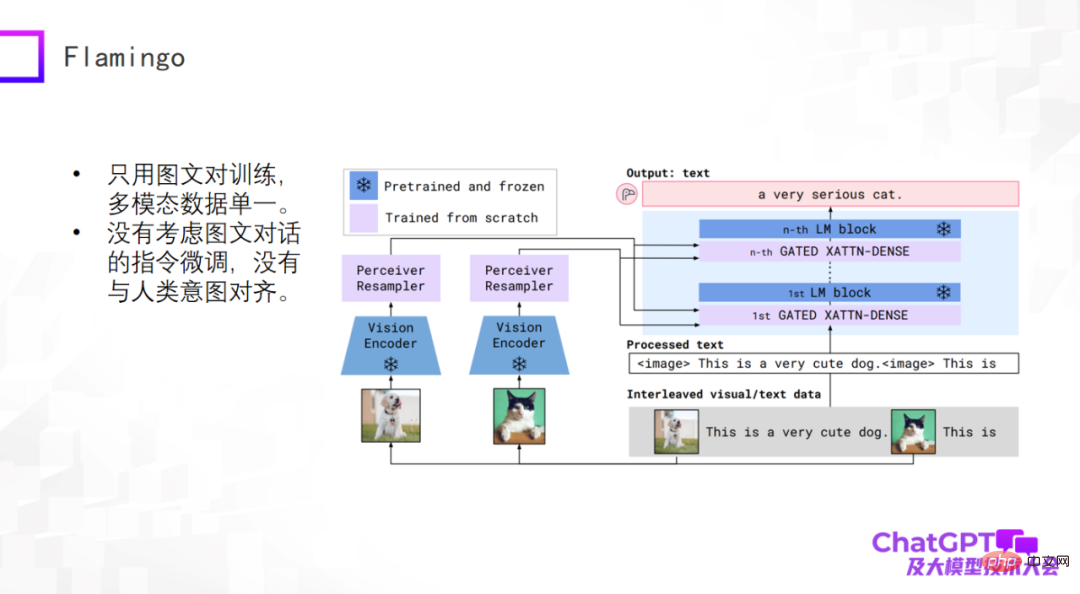
Flamingo モデル アーキテクチャの本体は、右側の青いモジュールである大規模言語モデルのデコーダ (Decoder) です。上の図のそれぞれの青色では、カラー モジュール間にいくつかのアダプター レイヤーが追加され、左側のビジュアル部分に Vision Encoder と Perceiver Resampler が追加されます。モデル全体の設計は、視覚的なものをエンコードして変換し、アダプターを通過させ、言語に合わせて調整することで、モデルが画像のテキスト説明を自動的に生成できるようにします。
Flamingo このようなアーキテクチャ設計にはどのような利点がありますか?まず、上図の青いモジュールは言語モデルのDecoderも含めて固定(フリーズ)されていますが、ピンクのモジュール自体のパラメータ量は制御可能であるため、実際にFlamingoモデルで学習されるパラメータの数は非常に少ないです。したがって、マルチモーダルな普遍的な生成モデルを構築するのは難しいとは考えないでください。実際、それほど悲観的ではありません。トレーニングされた Flamingo モデルは、テキスト生成に基づいて多くの一般的なタスクを実行できます。もちろん、入力は、ビデオの説明、視覚的な質疑応答、マルチモーダル ダイアログなどのマルチモーダルです。この観点から、Flamingo は一般的な生成モデルとみなすことができます。
2 番目の例は、少し前に新しくリリースされた BLIP-2 モデルです。BLIP-1 に基づいて改良されています。そのモデル アーキテクチャは Flamingo に非常に似ており、基本的に画像が含まれていますデコーダと大規模言語モデル デコーダが固定され、視覚から言語への変換機能を備えた Q-Former が中間に追加されます。したがって、BLIP-2 で本当にトレーニングが必要な部分は Q-Former です。
下図に示すように、まず画像 (右の画像) を Image Encoder に入力します。中央のテキストはユーザーからの質問や指示です。 Q-Former エンコード後に入力される、大きな言語モデルに進み、最終的に答えを生成する、おそらくそのような生成プロセスです。
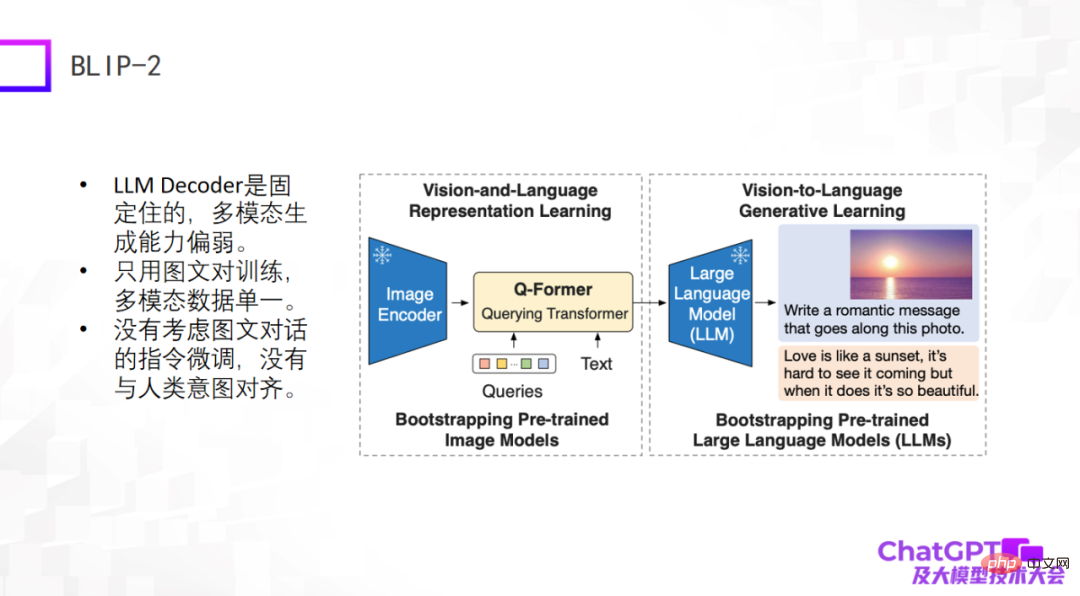
これら 2 つのモデルの欠点は明らかです。なぜなら、これら 2 つのモデルは比較的初期に登場したか、登場したばかりであり、ChatGPT で使用されるエンジニアリング手法が考慮されていないからです。少なくとも、グラフィック ダイアログやマルチモーダル ダイアログに対する命令の微調整がないため、全体的な生成効果は満足のいくものではありません。
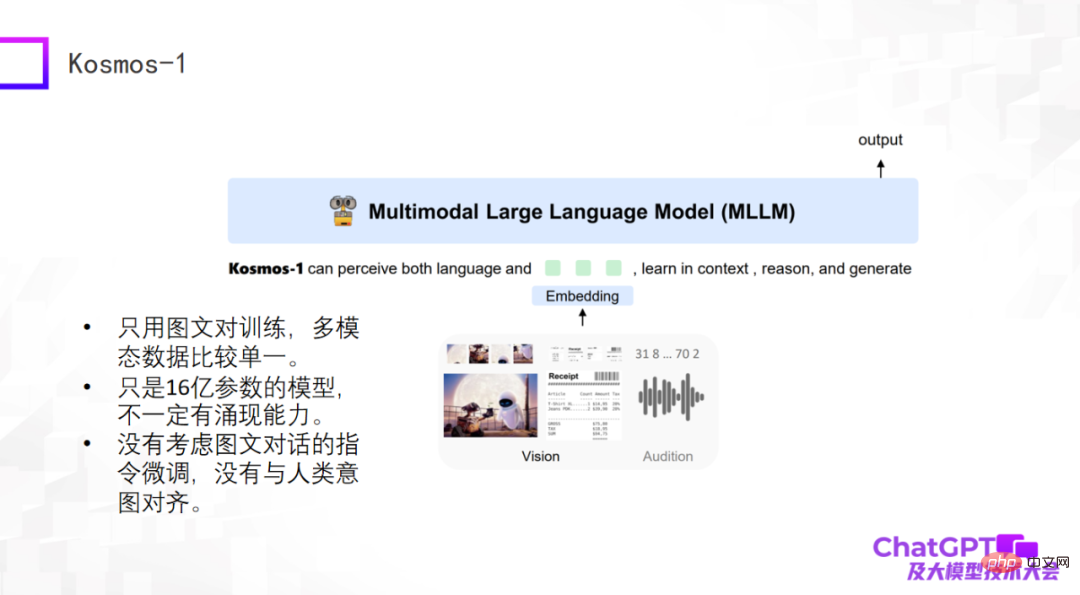
3 つ目は、Microsoft によって最近リリースされた Kosmos-1 です。非常に単純な構造を持ち、トレーニングに画像とテキストのペアのみを使用します。マルチモーダル データは比較的単一です。 Kosmos-1 と上記 2 つのモデルの最大の違いは、上記 2 つのモデルの大規模言語モデル自体が固定されているのに対し、Kosmos-1 の大規模言語モデル自体はトレーニングする必要があるため、Kosmos-1 モデルの数はパラメータの数はわずか 16 億であり、16 億のパラメータを持つモデルは創発する能力がない可能性があります。もちろん、Kosmos-1 はグラフィック対話におけるコマンドの微調整を考慮していないため、時々意味のない言葉を話すことがありました。
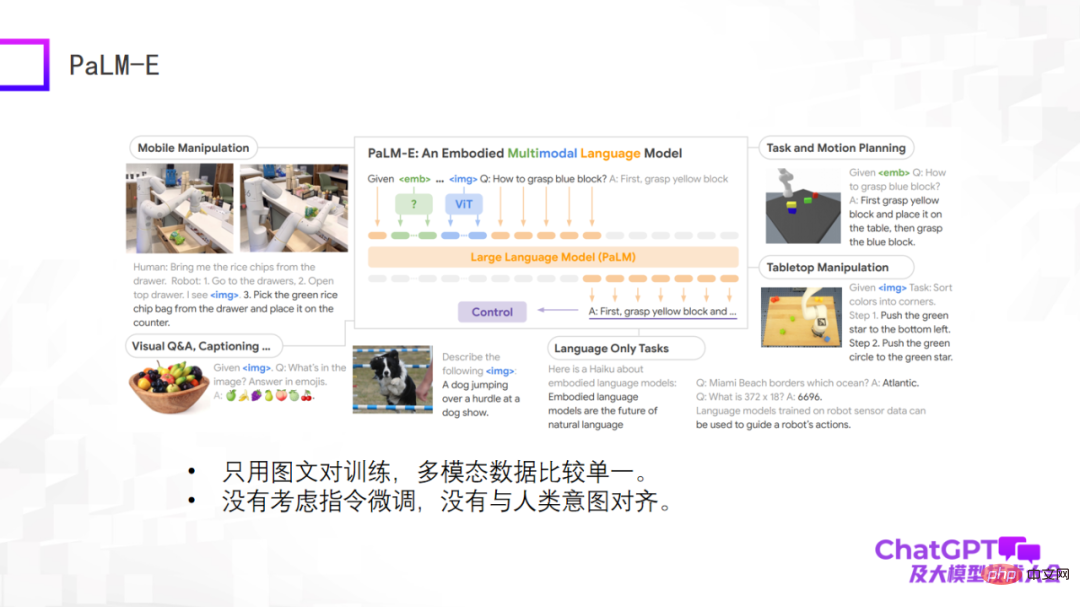
次の例は、Google のマルチモーダルな具体化された視覚言語モデル PaLM-E です。 PaLM-E モデルは最初の 3 つの例と似ており、PaLM-E も ViT ラージ言語モデルを使用します。 PaLM-E の最大の進歩は、ロボット工学の分野でマルチモーダル大規模言語モデルを実装する可能性を最終的に探求したことです。 PaLM-E は探索の最初のステップを試みますが、考慮するロボット タスクの種類は非常に限られており、真に普遍的なものではありません。
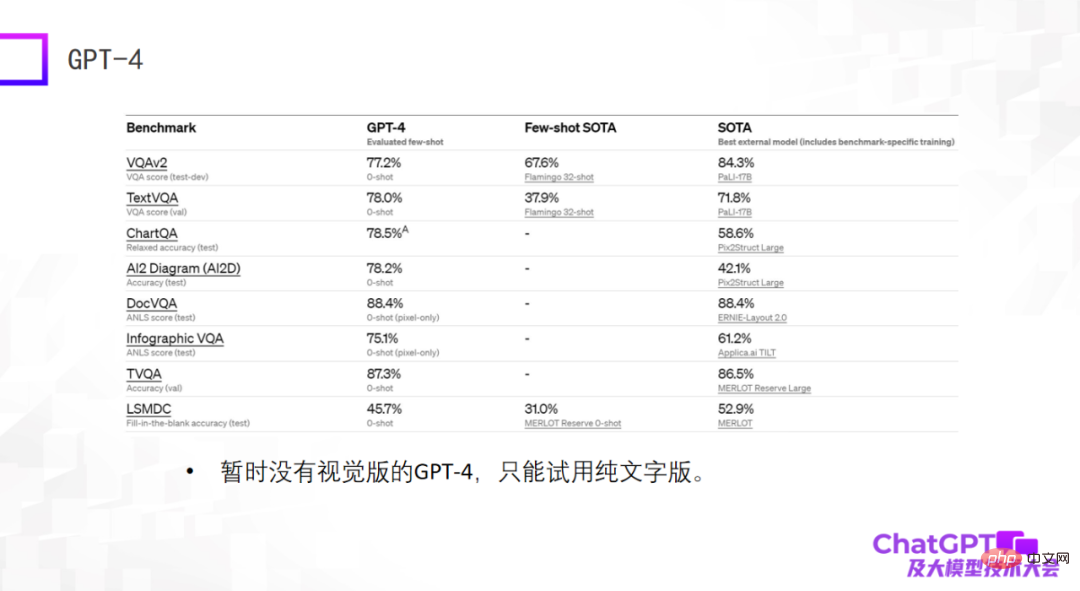
最後の例は GPT-4 です。標準的なデータセットで特に驚くべき結果が得られ、多くの場合、その結果は現在よりもさらに優れています。データセットでトレーニングされた微調整された SOTA モデルはさらに優れています。これはショックかもしれませんが、実際には何の意味もありません。 2 年前にマルチモーダルな大規模モデルを構築していたとき、大規模モデルの機能は標準データ セットでは評価できないことがわかりました。標準データ セットで優れたパフォーマンスが得られても、実際の使用で良好な結果が得られるとは限りません。モデル間には多くの違いがあります。 2. 大きなギャップ。このため、現在の GPT-4 には標準的なデータセットでしか結果が得られないため、少し残念に思っています。さらに、現在入手可能な GPT-4 はビジュアルバージョンではなく、純粋なテキストバージョンです。
上記のモデルは一般に一般的な言語生成に使用され、入力はマルチモーダル入力です。次の 2 つのモデルは異なります。一般的な言語生成だけでなく、言語と画像の両方を生成できるビジュアル生成も可能です。
1 つ目は Microsoft の Visual ChatGPT です。簡単に評価してみます。このモデルのアイデアは非常にシンプルで、どちらかというと製品設計を考慮したものです。視覚関連の生成には多くの種類があり、いくつかの視覚検出モデルもあります。これらのさまざまなタスクの入力と指示は大きく異なります。問題は、これらすべてのタスクを含めるために 1 つのモデルを使用する方法です。そこで、Microsoft はプロンプト マネージャーを設計しました。 OpenAI の ChatGPT は、ChatGPT を介してさまざまなビジュアル生成タスクの命令を変換することに相当します。ユーザーの質問は自然言語で記述された指示であり、ChatGPT を通じてマシンが理解できる指示に変換されます。
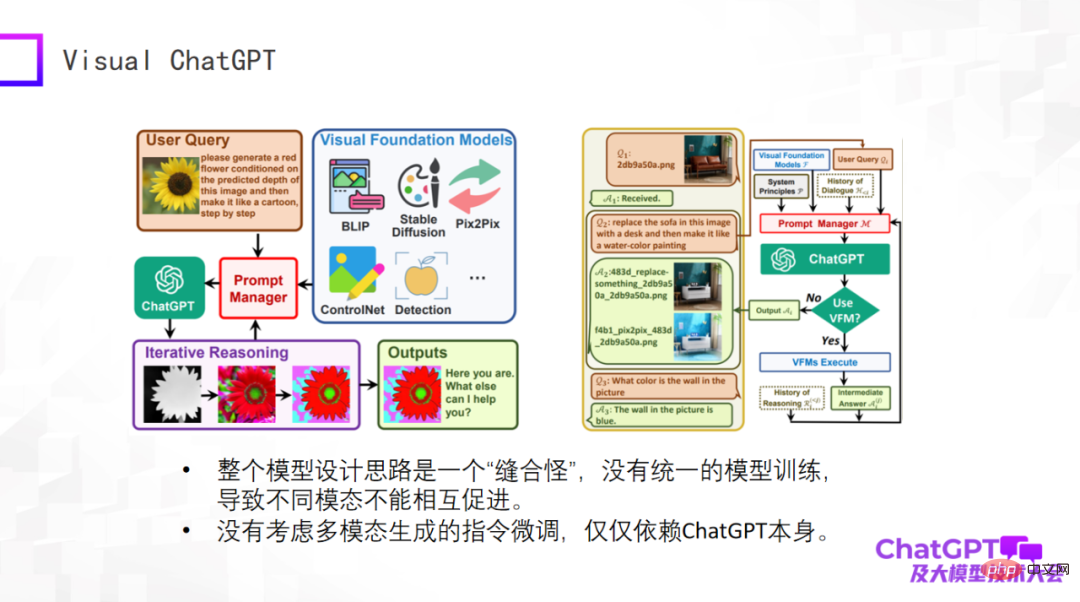
Visual ChatGPT はまさにそのようなことを行います。つまり、製品の観点からは非常に優れていますが、モデルの設計の観点からは何も新しいものではありません。したがって、モデル全体はモデルの観点から見ると「ステッチ モンスター」であり、統一されたモデル トレーニングが存在せず、その結果、異なるモード間での相互促進が行われません。私たちがマルチモダリティを行う理由は、異なるモダリティからのデータが互いに助け合う必要があると信じているからです。また、Visual ChatGPT はマルチモーダル生成命令の微調整を考慮しておらず、その命令の微調整は ChatGPT 自体にのみ依存します。
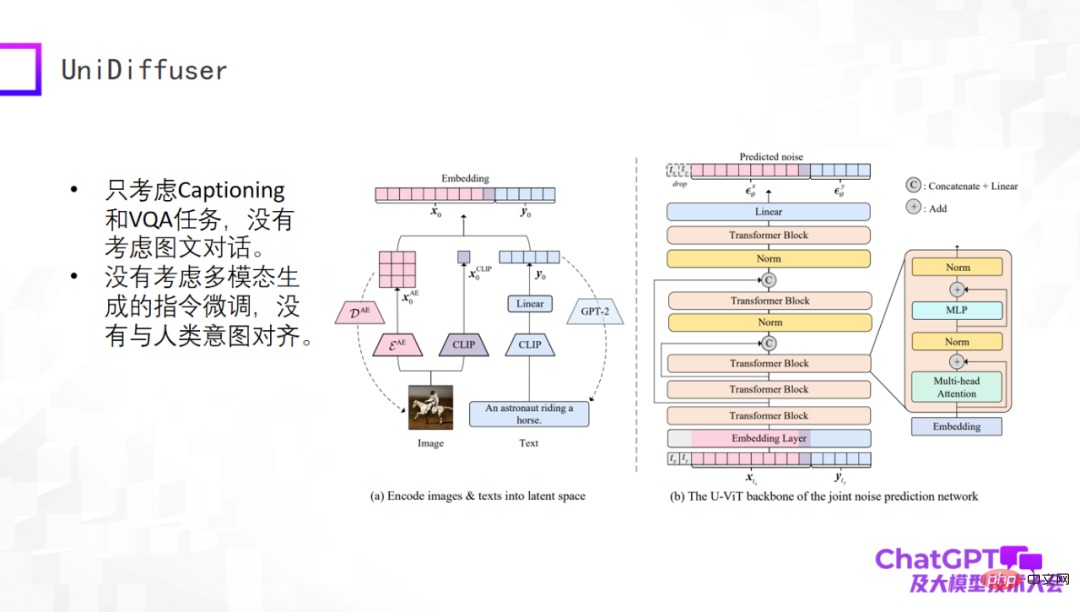
次の例は、清華大学の Zhu Jun 教授のチームがリリースした UniDiffuser モデルです。学術的な観点から見ると、このモデルはマルチモーダル入力からテキストとビジュアル コンテンツを真に生成できます。これは、安定拡散のコア コンポーネントである U-Net に似たトランスベースのネットワーク アーキテクチャ U-ViT によるものです。画像生成とテキスト生成はフレームワーク内で統合されます。この作業自体は非常に有意義なものですが、キャプションと VQA タスクのみを考慮しており、複数回の対話を考慮しておらず、マルチモーダル生成のための指示の微調整も行っていないなど、まだ比較的初期段階にあります。
以前たくさんコメントしましたが、下の図に示すように、ChatImg という製品も作成しました。一般的に、ChatImg には画像エンコーダ、マルチモーダル画像およびテキスト エンコーダ、テキスト デコーダが含まれており、Flamingo や BLIP-2 に似ていますが、さらに考慮されており、具体的な実装には細かい違いがあります。
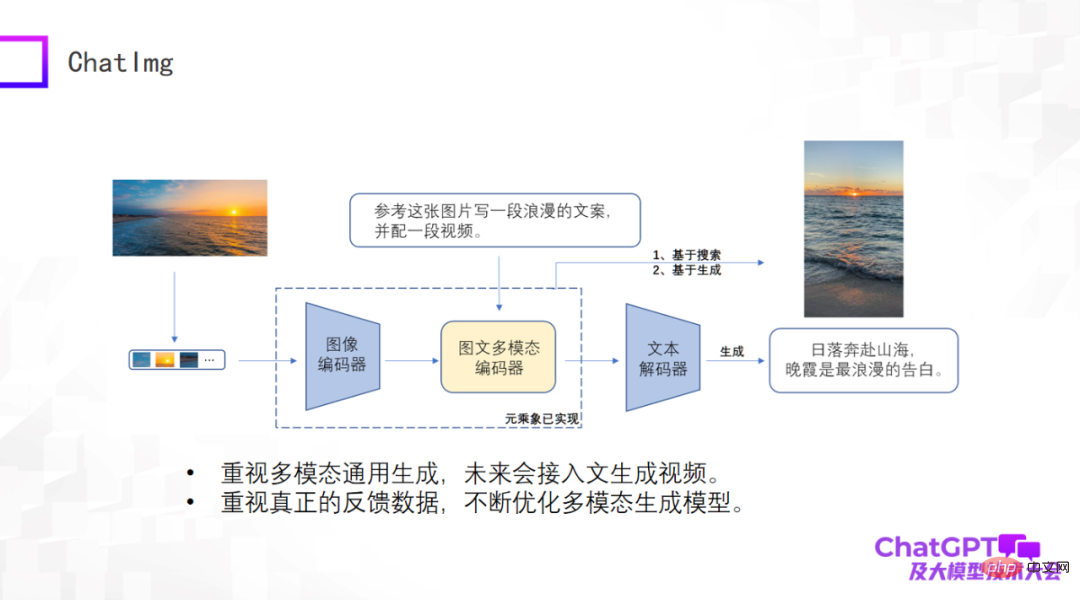
ChatImg の最大の利点の 1 つは、ビデオ入力を受け入れられることです。テキスト生成、画像生成、ビデオ生成など、マルチモーダルな一般生成に特に注意を払っています。私たちはこのフレームワークでさまざまな生成タスクを実装したいと考えており、最終的にはテキストにアクセスしてビデオを生成したいと考えています。
2 番目に、実際のユーザー データに特に注意を払っており、実際のユーザー データを取得した後も、生成モデル自体を継続的に最適化し、その機能を向上させたいと考え、ChatImg アプリケーションをリリースしました。
次の写真はテストの例です。初期モデルとしては、まだ不十分な点もありますが、一般的に ChatImg はまだ写真を理解できます。たとえば、ChatImg は会話の中で絵画の説明を生成したり、コンテキスト内の学習を行うこともできます。
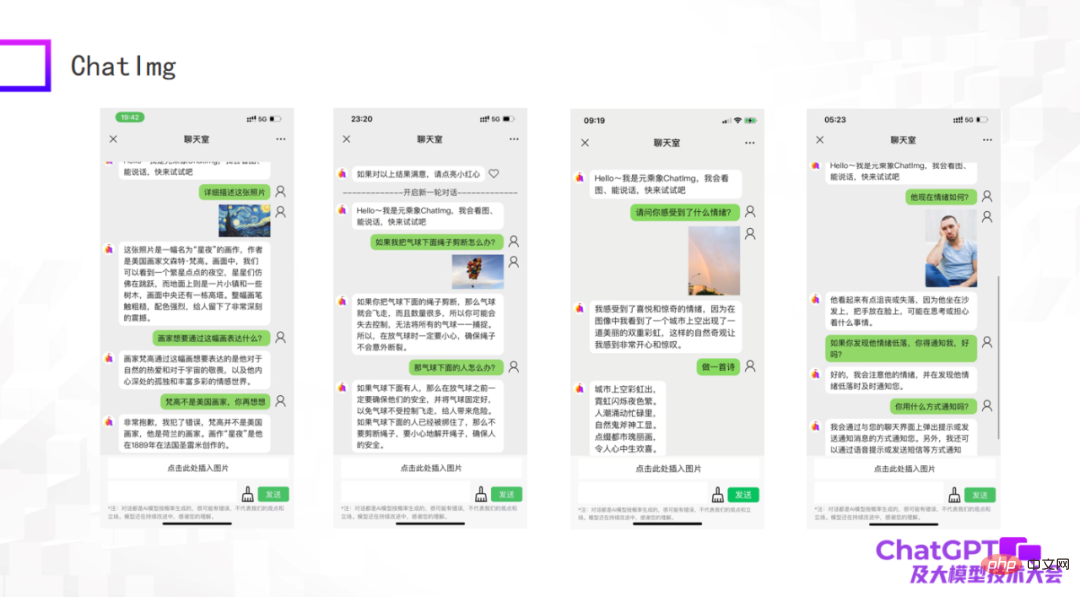
上の図の最初の例は、絵画「星月夜」について説明しています。説明の中で、ChatImg は、ゴッホはアメリカの画家であると述べています。間違っていると伝えても、すぐに修正できます。2 番目の例では、ChatImg が写真内のオブジェクトについて物理的な推論を行いました。3 番目の例は、私が自分で撮った写真です。この写真には 2 つの虹があり、正確に認識されました。
上の図の 3 番目と 4 番目の例には、感情的な問題が関係していることがわかりました。実はこれは次に行う作業に関係するのですが、ChatImg をロボットに接続したいと考えています。今日のロボットは通常受動的であり、すべての命令が事前に設定されているため、非常に厳格に見えます。 ChatImgに接続されたロボットが人々と積極的にコミュニケーションできることを期待しています。これを行う方法?まず、世界の状況や人の感情を客観的に見たり、反映したりすることで、ロボットが人間を理解し、積極的にコミュニケーションできるようにするためには、人間を感じることが必要です。この 2 つの例を通して、この目標は達成可能であると感じています。
#最後に、今日のレポートをまとめます。まず第一に、ChatGPT と GPT-4 は研究パラダイムに革新をもたらしました。私たち全員がこの変化を積極的に受け入れる必要があります。リソースがないからといって不平を言ったり言い訳をしたりすることはできません。この変化に直面している限り、方法は常にあります困難を克服するために。マルチモーダル研究では、数百枚のカードを備えたマシンさえ必要なく、対応する戦略が採用されている限り、少数のマシンでも適切な研究を行うことができます。第二に、既存のマルチモーダル生成モデルにはそれぞれ独自の問題があり、GPT-4 にはオープンなビジュアル バージョンがまだありませんが、私たち全員にチャンスはまだあります。さらに、GPT-4 には、マルチモーダル生成モデルが最終的にどのようなものであるべきかという問題がまだ残っていると思いますが、完璧な答えは得られていません (実際、GPT-4 の詳細はまったく明らかにされていません)。これは実は良いことで、世界中の人がとても賢くて、それぞれが自分の考えを持っているので、百花が咲くような新しい研究状況が生まれるかもしれません。私のスピーチは以上です。皆さん、ありがとうございました。

以上が「中国人民大学の研究者Lu Zhiwu氏は、マルチモーダル生成モデルに対するChatGPTの重要な影響を提案しました。」の詳細内容です。詳細については、PHP 中国語 Web サイトの他の関連記事を参照してください。

ホットAIツール

Undresser.AI Undress
リアルなヌード写真を作成する AI 搭載アプリ

AI Clothes Remover
写真から衣服を削除するオンライン AI ツール。

Undress AI Tool
脱衣画像を無料で

Clothoff.io
AI衣類リムーバー

Video Face Swap
完全無料の AI 顔交換ツールを使用して、あらゆるビデオの顔を簡単に交換できます。

人気の記事
ホットツール

メモ帳++7.3.1
使いやすく無料のコードエディター

SublimeText3 中国語版
中国語版、とても使いやすい

ゼンドスタジオ 13.0.1
強力な PHP 統合開発環境

ドリームウィーバー CS6
ビジュアル Web 開発ツール

SublimeText3 Mac版
神レベルのコード編集ソフト(SublimeText3)
ホットトピック
 7773
7773
 15
1644
14
1399
52
1296
25
1234
29
15
1644
14
1399
52
1296
25
1234
29

 世界で最も強力なオープンソース MoE モデルが登場。GPT-4 に匹敵する中国語機能を備え、価格は GPT-4-Turbo のわずか 1% 近くです
May 07, 2024 pm 04:13 PM
世界で最も強力なオープンソース MoE モデルが登場。GPT-4 に匹敵する中国語機能を備え、価格は GPT-4-Turbo のわずか 1% 近くです
May 07, 2024 pm 04:13 PM
従来のコンピューティングを超える能力を備えているだけでなく、より低コストでより効率的なパフォーマンスを実現する人工知能モデルを想像してみてください。これは SF ではありません。世界で最も強力なオープンソース MoE モデルである DeepSeek-V2[1] が登場しました。 DeepSeek-V2 は、経済的なトレーニングと効率的な推論の特徴を備えた強力な専門家混合 (MoE) 言語モデルです。これは 236B のパラメータで構成されており、そのうち 21B は各マーカーをアクティブにするために使用されます。 DeepSeek67B と比較して、DeepSeek-V2 はパフォーマンスが優れていると同時に、トレーニング コストを 42.5% 節約し、KV キャッシュを 93.3% 削減し、最大生成スループットを 5.76 倍に高めます。 DeepSeek は一般的な人工知能を研究する会社です
 AI が数学研究を破壊する!フィールズ賞受賞者で中国系アメリカ人の数学者が上位 11 件の論文を主導 | テレンス・タオが「いいね!」しました
Apr 09, 2024 am 11:52 AM
AI が数学研究を破壊する!フィールズ賞受賞者で中国系アメリカ人の数学者が上位 11 件の論文を主導 | テレンス・タオが「いいね!」しました
Apr 09, 2024 am 11:52 AM
AI は確かに数学を変えつつあります。最近、この問題に細心の注意を払っている陶哲軒氏が『米国数学協会会報』(米国数学協会会報)の最新号を送ってくれた。 「機械は数学を変えるのか?」というテーマを中心に、多くの数学者が意見を述べ、そのプロセス全体は火花に満ち、ハードコアで刺激的でした。著者には、フィールズ賞受賞者のアクシャイ・ベンカテシュ氏、中国の数学者鄭楽軍氏、ニューヨーク大学のコンピューター科学者アーネスト・デイビス氏、その他業界で著名な学者を含む強力な顔ぶれが揃っている。 AI の世界は劇的に変化しています。これらの記事の多くは 1 年前に投稿されたものです。
 Google は大喜び: JAX のパフォーマンスが Pytorch や TensorFlow を上回りました! GPU 推論トレーニングの最速の選択肢となる可能性があります
Apr 01, 2024 pm 07:46 PM
Google は大喜び: JAX のパフォーマンスが Pytorch や TensorFlow を上回りました! GPU 推論トレーニングの最速の選択肢となる可能性があります
Apr 01, 2024 pm 07:46 PM
Google が推進する JAX のパフォーマンスは、最近のベンチマーク テストで Pytorch や TensorFlow のパフォーマンスを上回り、7 つの指標で 1 位にランクされました。また、テストは最高の JAX パフォーマンスを備えた TPU では行われませんでした。ただし、開発者の間では、依然として Tensorflow よりも Pytorch の方が人気があります。しかし、将来的には、おそらくより大規模なモデルが JAX プラットフォームに基づいてトレーニングされ、実行されるようになるでしょう。モデル 最近、Keras チームは、ネイティブ PyTorch 実装を使用して 3 つのバックエンド (TensorFlow、JAX、PyTorch) をベンチマークし、TensorFlow を使用して Keras2 をベンチマークしました。まず、主流のセットを選択します
 こんにちは、電気アトラスです!ボストン・ダイナミクスのロボットが復活、180度の奇妙な動きにマスク氏も恐怖
Apr 18, 2024 pm 07:58 PM
こんにちは、電気アトラスです!ボストン・ダイナミクスのロボットが復活、180度の奇妙な動きにマスク氏も恐怖
Apr 18, 2024 pm 07:58 PM
Boston Dynamics Atlas は正式に電動ロボットの時代に突入します!昨日、油圧式アトラスが歴史の舞台から「涙ながらに」撤退したばかりですが、今日、ボストン・ダイナミクスは電動式アトラスが稼働することを発表しました。ボストン・ダイナミクス社は商用人型ロボットの分野でテスラ社と競争する決意を持っているようだ。新しいビデオが公開されてから、わずか 10 時間ですでに 100 万人以上が視聴しました。古い人が去り、新しい役割が現れるのは歴史的な必然です。今年が人型ロボットの爆発的な年であることは間違いありません。ネットユーザーは「ロボットの進歩により、今年の開会式は人間のように見え、人間よりもはるかに自由度が高い。しかし、これは本当にホラー映画ではないのか?」とコメントした。ビデオの冒頭では、アトラスは仰向けに見えるように地面に静かに横たわっています。次に続くのは驚くべきことです
 MLP に代わる KAN は、オープンソース プロジェクトによって畳み込みまで拡張されました
Jun 01, 2024 pm 10:03 PM
MLP に代わる KAN は、オープンソース プロジェクトによって畳み込みまで拡張されました
Jun 01, 2024 pm 10:03 PM
今月初め、MIT やその他の機関の研究者らは、MLP に代わる非常に有望な代替案である KAN を提案しました。 KAN は、精度と解釈可能性の点で MLP よりも優れています。また、非常に少数のパラメーターを使用して、多数のパラメーターを使用して実行する MLP よりも優れたパフォーマンスを発揮できます。たとえば、著者らは、KAN を使用して、より小規模なネットワークと高度な自動化で DeepMind の結果を再現したと述べています。具体的には、DeepMind の MLP には約 300,000 個のパラメーターがありますが、KAN には約 200 個のパラメーターしかありません。 KAN は、MLP が普遍近似定理に基づいているのに対し、KAN はコルモゴロフ-アーノルド表現定理に基づいているのと同様に、強力な数学的基礎を持っています。以下の図に示すように、KAN は
 テスラのロボットは工場で働く、マスク氏:手の自由度は今年22に達する!
May 06, 2024 pm 04:13 PM
テスラのロボットは工場で働く、マスク氏:手の自由度は今年22に達する!
May 06, 2024 pm 04:13 PM
テスラのロボット「オプティマス」の最新映像が公開され、すでに工場内で稼働可能となっている。通常の速度では、バッテリー(テスラの4680バッテリー)を次のように分類します:公式は、20倍の速度でどのように見えるかも公開しました - 小さな「ワークステーション」上で、ピッキング、ピッキング、ピッキング:今回は、それがリリースされたハイライトの1つビデオの内容は、オプティマスが工場内でこの作業を完全に自律的に行い、プロセス全体を通じて人間の介入なしに完了するというものです。そして、オプティマスの観点から見ると、自動エラー修正に重点を置いて、曲がったバッテリーを拾い上げたり配置したりすることもできます。オプティマスのハンドについては、NVIDIA の科学者ジム ファン氏が高く評価しました。オプティマスのハンドは、世界の 5 本指ロボットの 1 つです。最も器用。その手は触覚だけではありません
 FisheyeDetNet: 魚眼カメラに基づいた最初のターゲット検出アルゴリズム
Apr 26, 2024 am 11:37 AM
FisheyeDetNet: 魚眼カメラに基づいた最初のターゲット検出アルゴリズム
Apr 26, 2024 am 11:37 AM
目標検出は自動運転システムにおいて比較的成熟した問題であり、その中でも歩行者検出は最も初期に導入されたアルゴリズムの 1 つです。ほとんどの論文では非常に包括的な研究が行われています。ただし、サラウンドビューに魚眼カメラを使用した距離認識については、あまり研究されていません。放射状の歪みが大きいため、標準のバウンディング ボックス表現を魚眼カメラに実装するのは困難です。上記の説明を軽減するために、拡張バウンディング ボックス、楕円、および一般的な多角形の設計を極/角度表現に探索し、これらの表現を分析するためのインスタンス セグメンテーション mIOU メトリックを定義します。提案された多角形モデルの FisheyeDetNet は、他のモデルよりも優れたパフォーマンスを示し、同時に自動運転用の Valeo 魚眼カメラ データセットで 49.5% の mAP を達成しました。
 オックスフォード大学の最新情報!ミッキー:2D画像を3D SOTAでマッチング! (CVPR\'24)
Apr 23, 2024 pm 01:20 PM
オックスフォード大学の最新情報!ミッキー:2D画像を3D SOTAでマッチング! (CVPR\'24)
Apr 23, 2024 pm 01:20 PM
前に書かれたプロジェクトのリンク: https://nianticlabs.github.io/mickey/ 2 枚の写真が与えられた場合、それらの写真間の対応関係を確立することで、それらの間のカメラのポーズを推定できます。通常、これらの対応は 2D 対 2D であり、推定されたポーズはスケール不定です。いつでもどこでもインスタント拡張現実などの一部のアプリケーションでは、スケール メトリクスの姿勢推定が必要なため、スケールを回復するために外部深度推定器に依存します。この論文では、3D カメラ空間でのメトリックの対応を予測できるキーポイント マッチング プロセスである MicKey を提案します。画像全体の 3D 座標マッチングを学習することで、相対的なメトリックを推測できるようになります。
