

Python 時系列データ操作の一般的な方法の概要

時系列データは、一定期間にわたって収集されるデータの一種です。金融、経済、気象学などの分野でよく使用され、時間の経過に伴う傾向やパターンを理解するために分析されることがよくあります。
Pandas は、Python の強力で人気のあるデータ操作ライブラリであり、時系列データの処理に特に適しています。時系列データを簡単にロード、操作、分析するためのツールと機能のセットを提供します。
この記事では、時系列データのインデックス付けとスライス、リサンプリングとローリング ウィンドウの計算、その他の便利な一般的な操作を紹介します。これらは、Pandas を使用して時系列データを操作するための重要なテクニックです。
データ型
Python
Python には、日付を表すための専用の組み込みデータ型はありません。通常の状況では、datetime モジュールによって提供される datetime オブジェクトが日付と時刻の操作に使用されます。
import datetime
t = datetime.datetime.now()
print(f"type: {type(t)} and t: {t}")
#type: <class 'datetime.datetime'> and t: 2022-12-26 14:20:51.278230通常、日付と時刻を保存するには文字列を使用します。したがって、これらの文字列を使用する場合は、日時オブジェクトに変換する必要があります。
通常、時刻文字列の形式は次のとおりです:
- YYYY-MM-DD (例: 2022-01-01)
- YYYY/MM/DD (例: 2022/01/01)
- DD-MM-YYYY (例: 01-01-2022)
- DD/MM/YYYY (例: 01/01/2022)
- MM-DD-YYYY (例: 01-01-2022)
- MM/DD/YYYY (例: 01/01/2022)
- HH:MM:SS (例: 11:30 : 00)
- HH:MM:SS AM/PM (例: 11:30:00 AM)
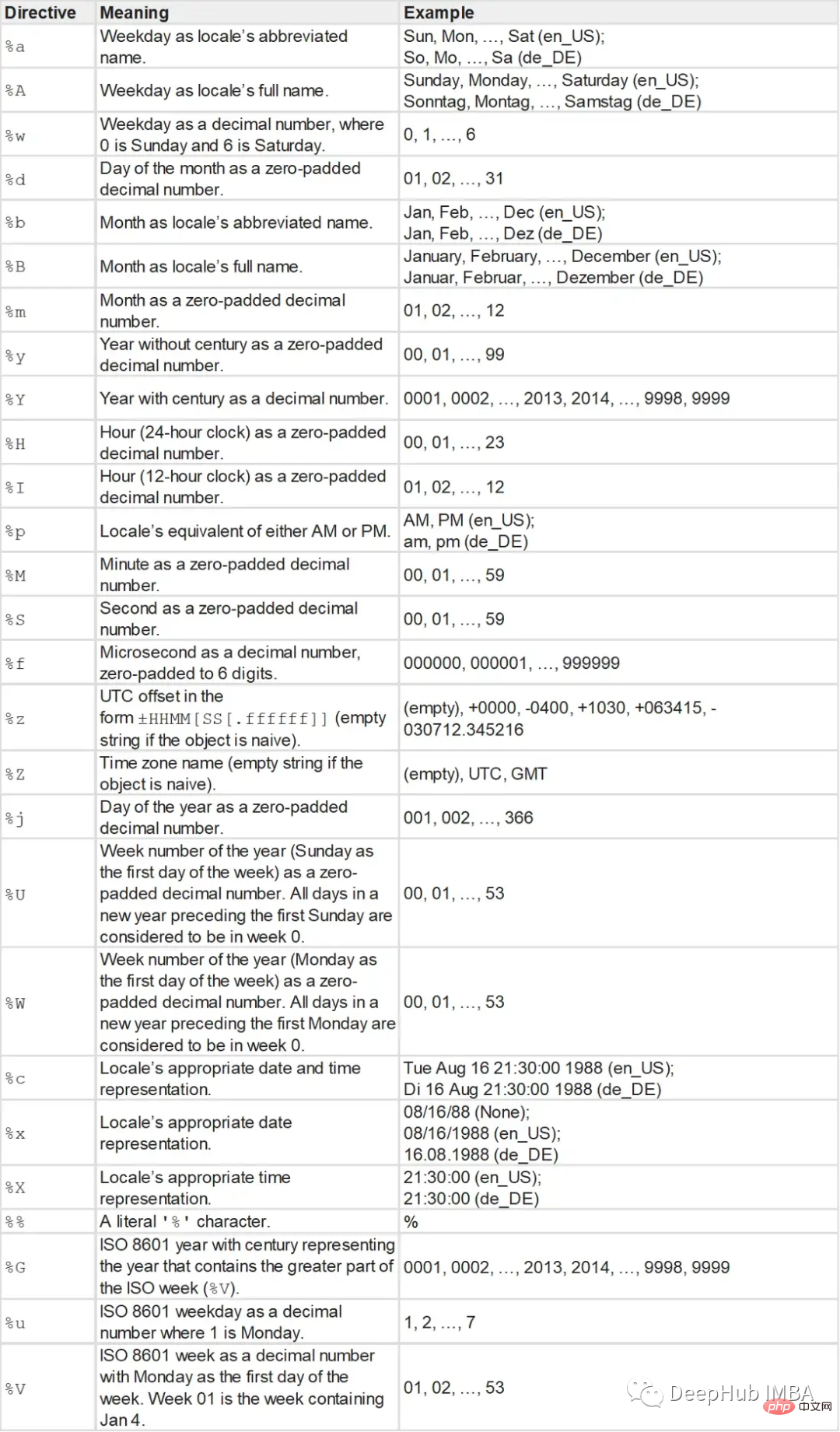
- HH:MM AM/PM (例: 11:30 AM) ##strptime 関数は、文字列と書式文字列をパラメータとして受け取り、日時オブジェクトを返します。
string = '2022-01-01 11:30:09'
t = datetime.datetime.strptime(string, "%Y-%m-%d %H:%M:%S")
print(f"type: {type(t)} and t: {t}")
#type: <class 'datetime.datetime'> and t: 2022-01-01 11:30:09形式文字列は次のとおりです:
 strftime 関数を使用して、日時オブジェクトを特定の形式の文字列表現に変換することもできます。 。
strftime 関数を使用して、日時オブジェクトを特定の形式の文字列表現に変換することもできます。 。
t = datetime.datetime.now()
t_string = t.strftime("%m/%d/%Y, %H:%M:%S")
#12/26/2022, 14:38:47
t_string = t.strftime("%b/%d/%Y, %H:%M:%S")
#Dec/26/2022, 14:39:32Unix 時間 (POSIX 時間またはエポック時間) は、時間を単一の数値として表すシステムです。これは、1970 年 1 月 1 日木曜日の協定世界時 (UTC) 00:00:00 からの経過秒数を表します。
Unix 時間とタイムスタンプは、多くの場合同じ意味で使用されます。 Unix 時間は、タイムスタンプを作成するための標準バージョンです。通常、タイムスタンプと Unix 時間を格納するには、整数または浮動小数点データ型を使用します。
time モジュールの mktime メソッドを使用して、datetime オブジェクトを Unix 時刻整数に変換できます。 datetime モジュールの fromtimestamp メソッドを使用することもできます。
#convert datetime to unix time import time from datetime import datetime t = datetime.now() unix_t = int(time.mktime(t.timetuple())) #1672055277 #convert unix time to datetime unix_t = 1672055277 t = datetime.fromtimestamp(unix_t) #2022-12-26 14:47:57
dateutil モジュールを使用して日付文字列を解析し、datetime オブジェクトを取得します。
from dateutil import parser
date = parser.parse("29th of October, 1923")
#datetime.datetime(1923, 10, 29, 0, 0)Pandas
Pandas は 3 つの日付データ型を提供します:
1、Timestamp または DatetimeIndex: 他のインデックス型と同様に機能しますが、時間に関する関数も備えています シーケンスに特化した関数オペレーション。
t = pd.to_datetime("29/10/1923", dayfirst=True)
#Timestamp('1923-10-29 00:00:00')
t = pd.Timestamp('2019-01-01', tz = 'Europe/Berlin')
#Timestamp('2019-01-01 00:00:00+0100', tz='Europe/Berlin')
t = pd.to_datetime(["04/23/1920", "10/29/1923"])
#DatetimeIndex(['1920-04-23', '1923-10-29'], dtype='datetime64[ns]', freq=None)2. period または PeriodIndex: 開始と終了のある時間間隔。一定の間隔で構成されます。
t = pd.to_datetime(["04/23/1920", "10/29/1923"])
period = t.to_period("D")
#PeriodIndex(['1920-04-23', '1923-10-29'], dtype='period[D]')3. Timedelta または TimedeltaIndex: 2 つの日付の間の時間間隔。
delta = pd.TimedeltaIndex(data =['1 days 03:00:00', '2 days 09:05:01.000030']) """ TimedeltaIndex(['1 days 02:00:00', '1 days 06:05:01.000030'], dtype='timedelta64[ns]', freq=None) """
Pandas では、to_datetime メソッドを使用して、オブジェクトを datetime データ型に変換したり、その他の変換を行うことができます。
import pandas as pd
df = pd.read_csv("dataset.txt")
df.head()
"""
date value
0 1991-07-01 3.526591
1 1991-08-01 3.180891
2 1991-09-01 3.252221
3 1991-10-01 3.611003
4 1991-11-01 3.565869
"""
df.info()
"""
<class 'pandas.core.frame.DataFrame'>
RangeIndex: 204 entries, 0 to 203
Data columns (total 2 columns):
# Column Non-Null Count Dtype
--- ------ -------------- -----
0 date 204 non-null object
1 value 204 non-null float64
dtypes: float64(1), object(1)
memory usage: 3.3+ KB
"""
# Convert to datetime
df["date"] = pd.to_datetime(df["date"], format = "%Y-%m-%d")
df.info()
"""
<class 'pandas.core.frame.DataFrame'>
RangeIndex: 204 entries, 0 to 203
Data columns (total 2 columns):
# Column Non-Null Count Dtype
--- ------ -------------- -----
0 date 204 non-null datetime64[ns]
1 value 204 non-null float64
dtypes: datetime64[ns](1), float64(1)
memory usage: 3.3 KB
"""
# Convert to Unix
df['unix_time'] = df['date'].apply(lambda x: x.timestamp())
df.head()
"""
date value unix_time
0 1991-07-01 3.526591 678326400.0
1 1991-08-01 3.180891 681004800.0
2 1991-09-01 3.252221 683683200.0
3 1991-10-01 3.611003 686275200.0
4 1991-11-01 3.565869 688953600.0
"""
df["date_converted_from_unix"] = pd.to_datetime(df["unix_time"], unit = "s")
df.head()
"""
date value unix_time date_converted_from_unix
0 1991-07-01 3.526591 678326400.0 1991-07-01
1 1991-08-01 3.180891 681004800.0 1991-08-01
2 1991-09-01 3.252221 683683200.0 1991-09-01
3 1991-10-01 3.611003 686275200.0 1991-10-01
4 1991-11-01 3.565869 688953600.0 1991-11-01
"""parse_dates パラメーターを使用して、ファイルが読み込まれるときに日付列を直接宣言することもできます。
df = pd.read_csv("dataset.txt", parse_dates=["date"])
df.info()
"""
<class 'pandas.core.frame.DataFrame'>
RangeIndex: 204 entries, 0 to 203
Data columns (total 2 columns):
# Column Non-Null Count Dtype
--- ------ -------------- -----
0 date 204 non-null datetime64[ns]
1 value 204 non-null float64
dtypes: datetime64[ns](1), float64(1)
memory usage: 3.3 KB
"""単一の時系列データの場合は、日付列をデータ セットのインデックスとして使用するのが最善です。
df.set_index("date",inplace=True)
"""
Value
date
1991-07-01 3.526591
1991-08-01 3.180891
1991-09-01 3.252221
1991-10-01 3.611003
1991-11-01 3.565869
... ...
2008-02-01 21.654285
2008-03-01 18.264945
2008-04-01 23.107677
2008-05-01 22.912510
2008-06-01 19.431740
"""Numpy には独自の日時型 np.Datetime64 もあります。特に大規模なデータセットを扱う場合、ベクトル化は非常に便利なので、最初に使用する必要があります。
import numpy as np
arr_date = np.array('2000-01-01', dtype=np.datetime64)
arr_date
#array('2000-01-01', dtype='datetime64[D]')
#broadcasting
arr_date = arr_date + np.arange(30)
"""
array(['2000-01-01', '2000-01-02', '2000-01-03', '2000-01-04',
'2000-01-05', '2000-01-06', '2000-01-07', '2000-01-08',
'2000-01-09', '2000-01-10', '2000-01-11', '2000-01-12',
'2000-01-13', '2000-01-14', '2000-01-15', '2000-01-16',
'2000-01-17', '2000-01-18', '2000-01-19', '2000-01-20',
'2000-01-21', '2000-01-22', '2000-01-23', '2000-01-24',
'2000-01-25', '2000-01-26', '2000-01-27', '2000-01-28',
'2000-01-29', '2000-01-30'], dtype='datetime64[D]')
"""便利な関数
以下に、時系列に役立ついくつかの関数を示します。
df = pd.read_csv("dataset.txt", parse_dates=["date"])
df["date"].dt.day_name()
"""
0 Monday
1 Thursday
2 Sunday
3 Tuesday
4 Friday
...
199 Friday
200 Saturday
201 Tuesday
202 Thursday
203 Sunday
Name: date, Length: 204, dtype: object
"""DataReader
Pandas_datareader は、pandas ライブラリの補助ライブラリです。多くの一般的な金融時系列データを提供します。
#pip install pandas-datareader from pandas_datareader import wb #GDP per Capita From World Bank df = wb.download(indicator='NY.GDP.PCAP.KD', country=['US', 'FR', 'GB', 'DK', 'NO'], start=1960, end=2019) """ NY.GDP.PCAP.KD country year Denmark 2019 57203.027794 2018 56563.488473 2017 55735.764901 2016 54556.068955 2015 53254.856370 ... ... United States 1964 21599.818705 1963 20701.269947 1962 20116.235124 1961 19253.547329 1960 19135.268182 [300 rows x 1 columns] """
日付範囲
パンダの date_range メソッドを使用して日付範囲を定義できます。
pd.date_range(start="2021-01-01", end="2022-01-01", freq="D")
"""
DatetimeIndex(['2021-01-01', '2021-01-02', '2021-01-03', '2021-01-04',
'2021-01-05', '2021-01-06', '2021-01-07', '2021-01-08',
'2021-01-09', '2021-01-10',
...
'2021-12-23', '2021-12-24', '2021-12-25', '2021-12-26',
'2021-12-27', '2021-12-28', '2021-12-29', '2021-12-30',
'2021-12-31', '2022-01-01'],
dtype='datetime64[ns]', length=366, freq='D')
"""
pd.date_range(start="2021-01-01", end="2022-01-01", freq="BM")
"""
DatetimeIndex(['2021-01-29', '2021-02-26', '2021-03-31', '2021-04-30',
'2021-05-31', '2021-06-30', '2021-07-30', '2021-08-31',
'2021-09-30', '2021-10-29', '2021-11-30', '2021-12-31'],
dtype='datetime64[ns]', freq='BM')
"""
fridays= pd.date_range('2022-11-01', '2022-12-31', freq="W-FRI")
"""
DatetimeIndex(['2022-11-04', '2022-11-11', '2022-11-18', '2022-11-25',
'2022-12-02', '2022-12-09', '2022-12-16', '2022-12-23',
'2022-12-30'],
dtype='datetime64[ns]', freq='W-FRI')
""" timedelta_range メソッドを使用して時系列を作成できます。
timedelta_range メソッドを使用して時系列を作成できます。
t = pd.timedelta_range(0, periods=10, freq="H") """ TimedeltaIndex(['0 days 00:00:00', '0 days 01:00:00', '0 days 02:00:00', '0 days 03:00:00', '0 days 04:00:00', '0 days 05:00:00', '0 days 06:00:00', '0 days 07:00:00', '0 days 08:00:00', '0 days 09:00:00'], dtype='timedelta64[ns]', freq='H') """
フォーマット
dt.strftime メソッドは、日付列のフォーマットを変更します。
df["new_date"] = df["date"].dt.strftime("%b %d, %Y")
df.head()
"""
date value new_date
0 1991-07-01 3.526591 Jul 01, 1991
1 1991-08-01 3.180891 Aug 01, 1991
2 1991-09-01 3.252221 Sep 01, 1991
3 1991-10-01 3.611003 Oct 01, 1991
4 1991-11-01 3.565869 Nov 01, 1991
"""Parsing
日時オブジェクトを解析し、日付の子オブジェクトを取得します。
df["year"] = df["date"].dt.year df["month"] = df["date"].dt.month df["day"] = df["date"].dt.day df["calendar"] = df["date"].dt.date df["hour"] = df["date"].dt.time df.head() """ date value year month day calendar hour 0 1991-07-01 3.526591 1991 7 1 1991-07-01 00:00:00 1 1991-08-01 3.180891 1991 8 1 1991-08-01 00:00:00 2 1991-09-01 3.252221 1991 9 1 1991-09-01 00:00:00 3 1991-10-01 3.611003 1991 10 1 1991-10-01 00:00:00 4 1991-11-01 3.565869 1991 11 1 1991-11-01 00:00:00 """
組み換えることも可能です。
df["date_joined"] = pd.to_datetime(df[["year","month","day"]]) print(df["date_joined"]) """ 0 1991-07-01 1 1991-08-01 2 1991-09-01 3 1991-10-01 4 1991-11-01 ... 199 2008-02-01 200 2008-03-01 201 2008-04-01 202 2008-05-01 203 2008-06-01 Name: date_joined, Length: 204, dtype: datetime64[ns]
フィルター クエリ
loc メソッドを使用してデータフレームをフィルターします。
df = df.loc["2021-01-01":"2021-01-10"]
 truncate は 2 つの時間間隔でデータをクエリできます
truncate は 2 つの時間間隔でデータをクエリできます
df_truncated = df.truncate('2021-01-05', '2022-01-10')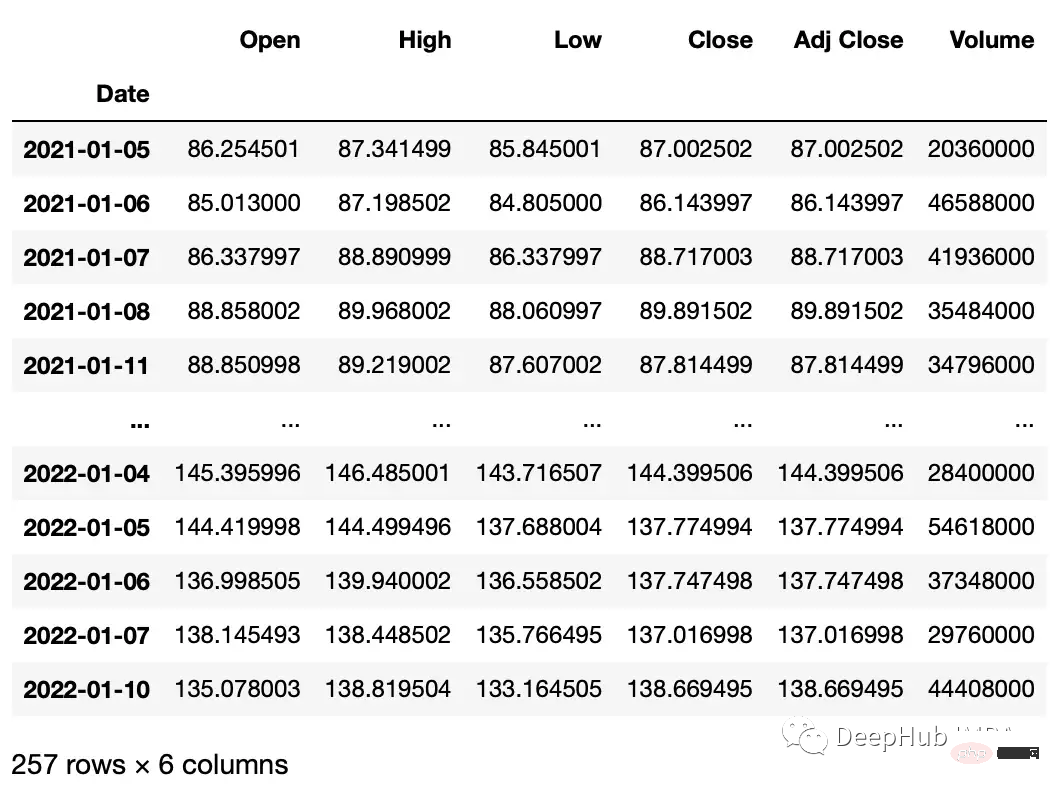 一般的なデータ操作
一般的なデータ操作
次は、時系列データセット内の値に対して操作を実行します。この例では、yfinance ライブラリを使用して株式データセットを作成します。
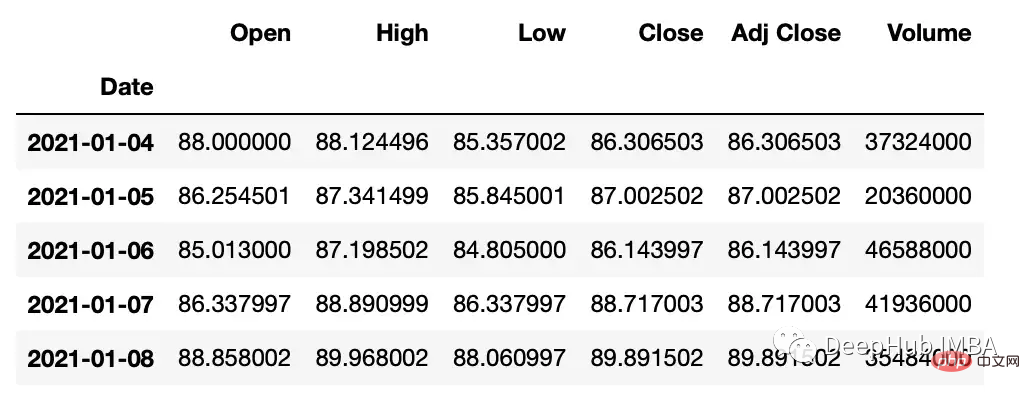
#get google stock price data import yfinance as yf start_date = '2020-01-01' end_date = '2023-01-01' ticker = 'GOOGL' df = yf.download(ticker, start_date, end_date) df.head() """ Date Open High Low Close Adj Close Volume 2020-01-02 67.420502 68.433998 67.324501 68.433998 68.433998 27278000 2020-01-03 67.400002 68.687500 67.365997 68.075996 68.075996 23408000 2020-01-06 67.581497 69.916000 67.550003 69.890503 69.890503 46768000 2020-01-07 70.023003 70.175003 69.578003 69.755501 69.755501 34330000 2020-01-08 69.740997 70.592499 69.631500 70.251999 70.251999 35314000 """
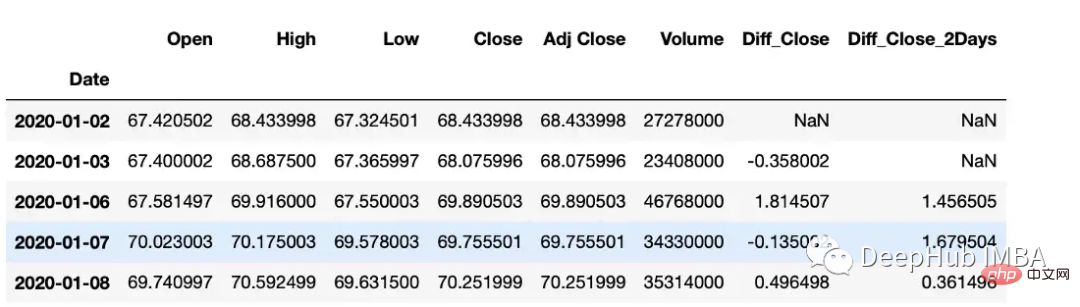
差分の計算
diff 関数は、ある要素と別の要素の間の補間を計算できます。
#subtract that day's value from the previous day df["Diff_Close"] = df["Close"].diff() #Subtract that day's value from the day's value 2 days ago df["Diff_Close_2Days"] = df["Close"].diff(periods=2)
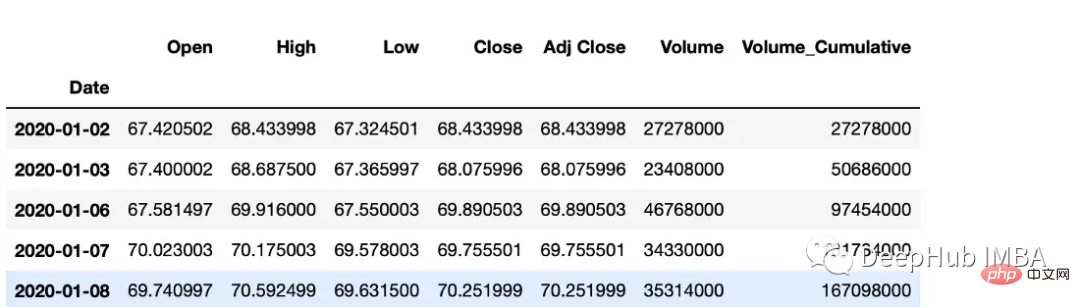
累计总数
df["Volume_Cumulative"] = df["Volume"].cumsum()
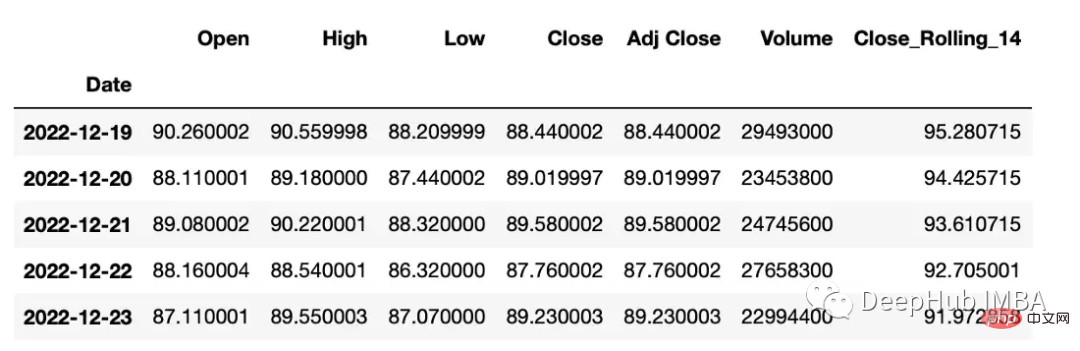
滚动窗口计算
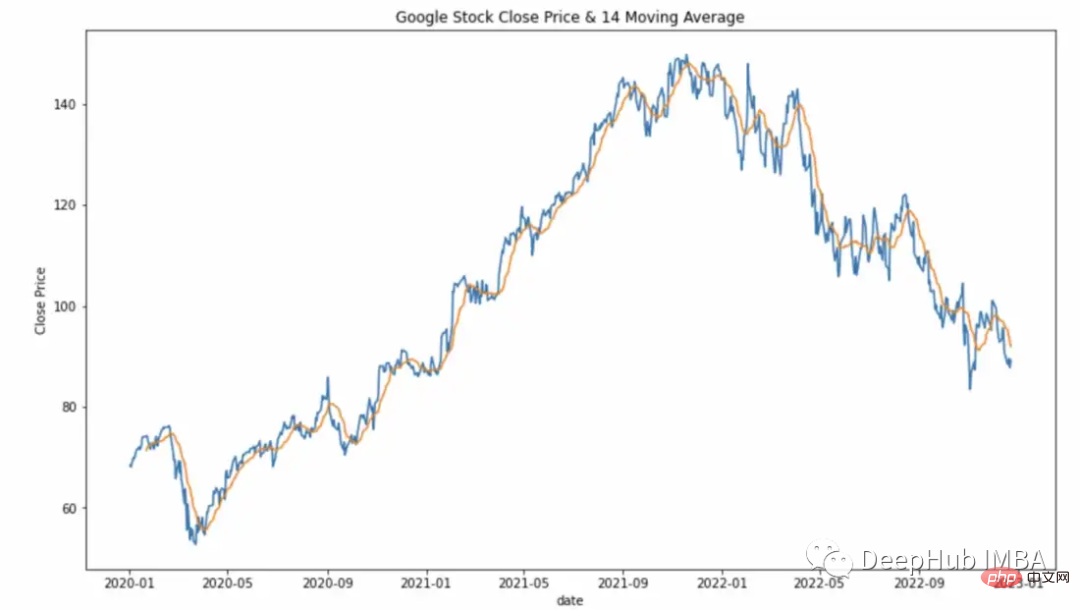
滚动窗口计算(移动平均线)。
df["Close_Rolling_14"] = df["Close"].rolling(14).mean() df.tail()
可以对我们计算的移动平均线进行可视化
常用的参数:
- center:决定滚动窗口是否应以当前观测值为中心。
- min_periods:窗口中产生结果所需的最小观测次数。
s = pd.Series([1, 2, 3, 4, 5]) #the rolling window will be centered on each observation rolling_mean = s.rolling(window=3, center=True).mean() """ 0 NaN 1 2.0 2 3.0 3 4.0 4 NaN dtype: float64 Explanation: first window: [na 1 2] = na second window: [1 2 3] = 2 """ # the rolling window will not be centered, #and will instead be anchored to the left side of the window rolling_mean = s.rolling(window=3, center=False).mean() """ 0 NaN 1 NaN 2 2.0 3 3.0 4 4.0 dtype: float64 Explanation: first window: [na na 1] = na second window: [na 1 2] = na third window: [1 2 3] = 2 """
平移
Pandas有两个方法,shift()和tshift(),它们可以指定倍数移动数据或时间序列的索引。Shift()移位数据,而tshift()移位索引。
#shift the data df_shifted = df.shift(5,axis=0) df_shifted.head(10) #shift the indexes df_tshifted = df.tshift(periods = 4, freq = 'D') df_tshifted.head(10)
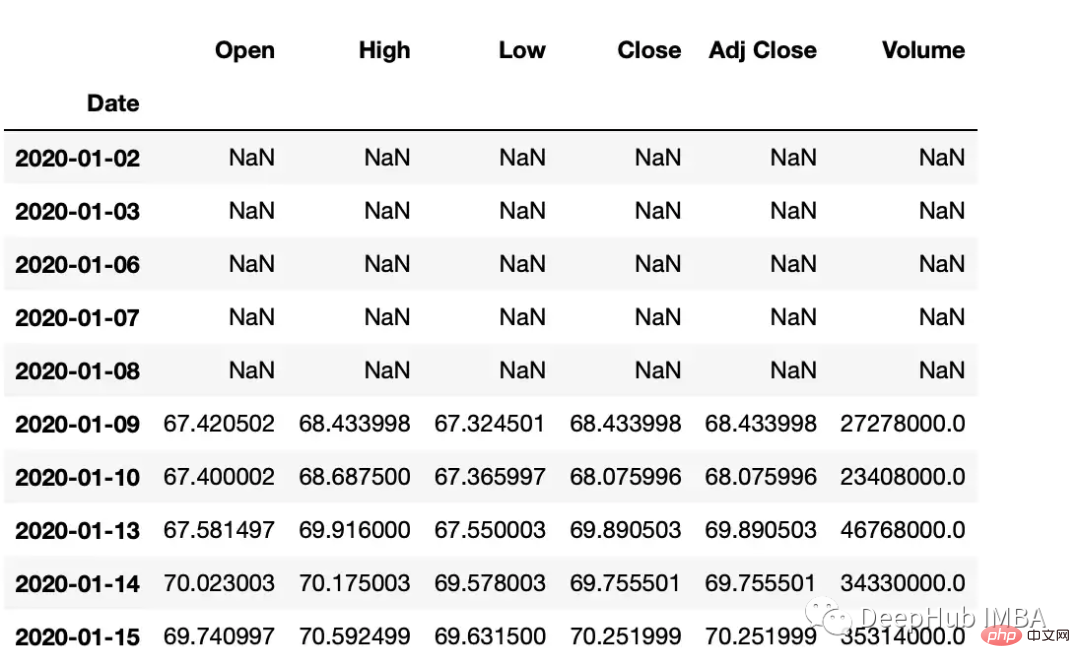
df_shifted
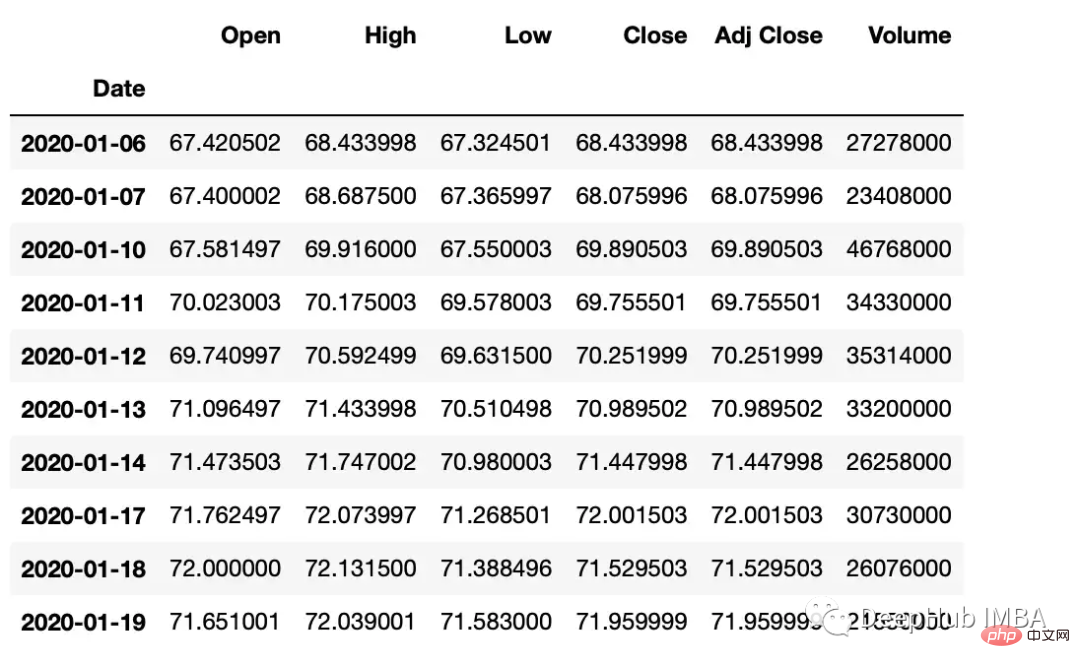
df_tshifted
时间间隔转换
在 Pandas 中,操 to_period 函数允许将日期转换为特定的时间间隔。可以获取具有许多不同间隔或周期的日期
df["Period"] = df["Date"].dt.to_period('W')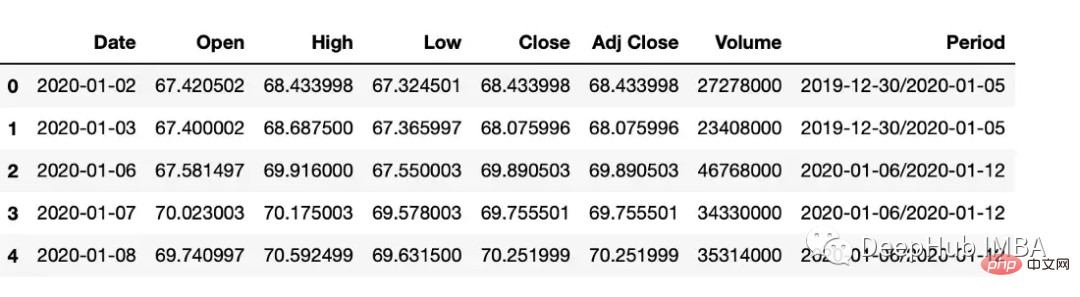
频率
Asfreq方法用于将时间序列转换为指定的频率。
monthly_data = df.asfreq('M', method='ffill')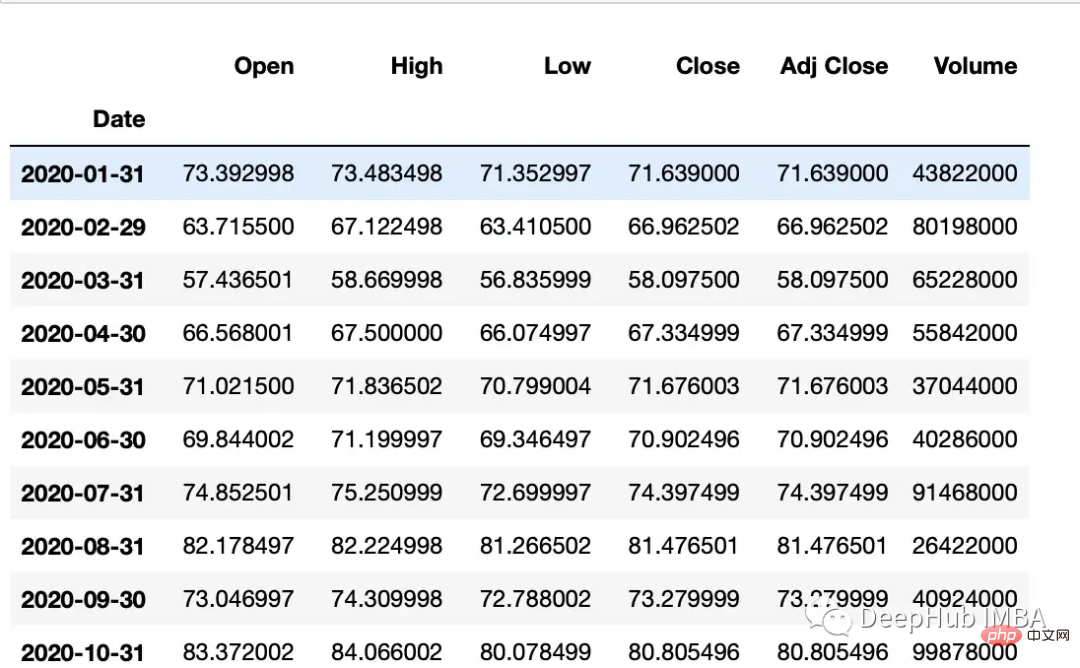
常用参数:
freq:数据应该转换到的频率。这可以使用字符串别名(例如,'M'表示月,'H'表示小时)或pandas偏移量对象来指定。
method:如何在转换频率时填充缺失值。这可以是'ffill'(向前填充)或'bfill'(向后填充)之类的字符串。
采样
resample可以改变时间序列频率并重新采样。我们可以进行上采样(到更高的频率)或下采样(到更低的频率)。因为我们正在改变频率,所以我们需要使用一个聚合函数(比如均值、最大值等)。
resample方法的参数:
rule:数据重新采样的频率。这可以使用字符串别名(例如,'M'表示月,'H'表示小时)或pandas偏移量对象来指定。
#down sample
monthly_data = df.resample('M').mean()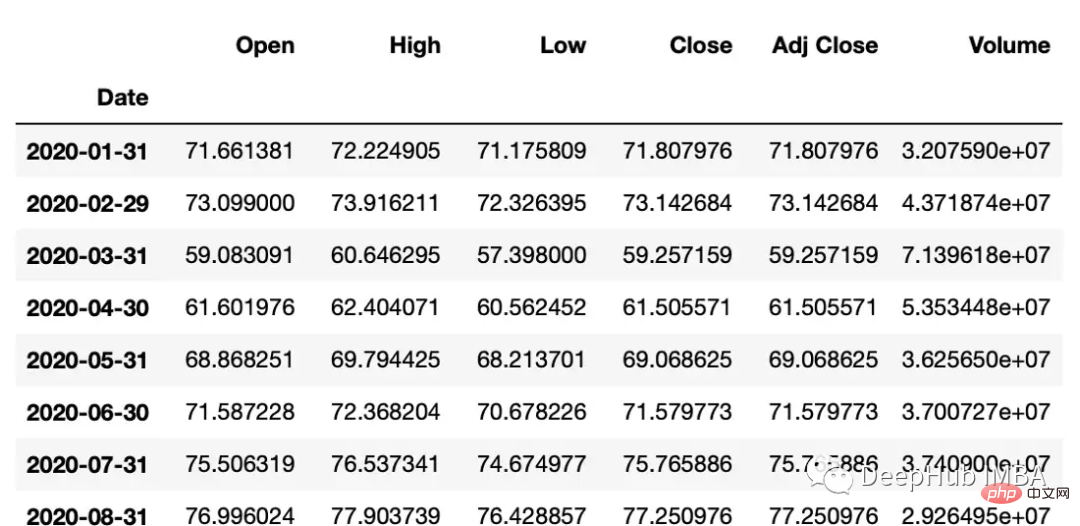
#up sample
minute_data = data.resample('T').ffill()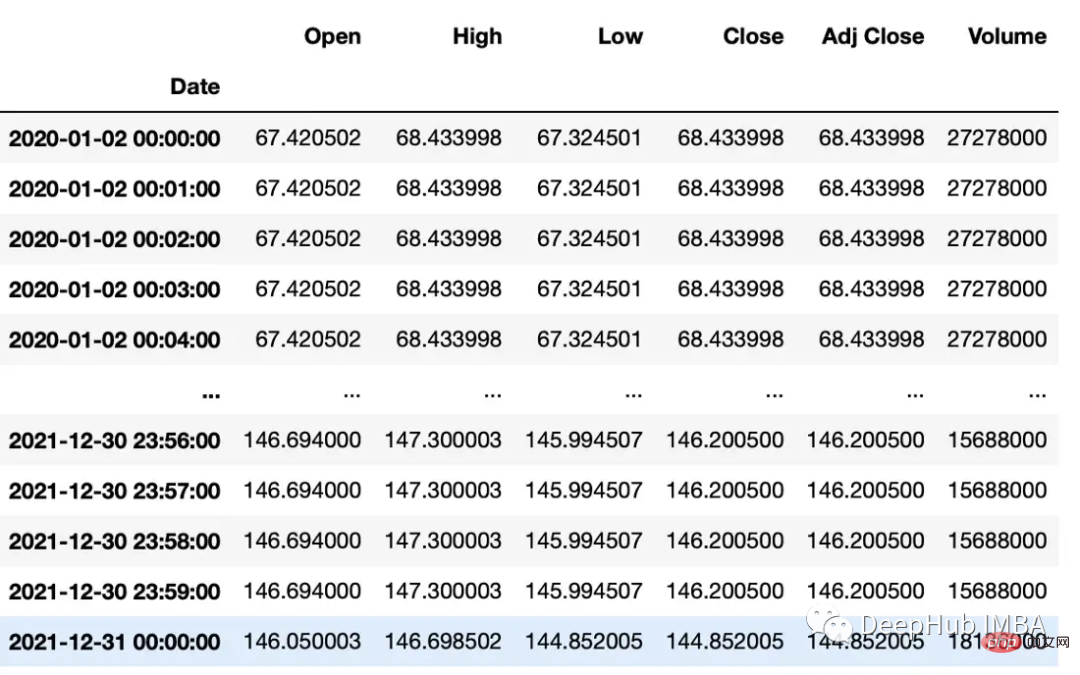
百分比变化
使用pct_change方法来计算日期之间的变化百分比。
df["PCT"] = df["Close"].pct_change(periods=2) print(df["PCT"]) """ Date 2020-01-02 NaN 2020-01-03 NaN 2020-01-06 0.021283 2020-01-07 0.024671 2020-01-08 0.005172 ... 2022-12-19 -0.026634 2022-12-20 -0.013738 2022-12-21 0.012890 2022-12-22 -0.014154 2022-12-23 -0.003907 Name: PCT, Length: 752, dtype: float64 """
总结
在Pandas和NumPy等库的帮助下,可以对时间序列数据执行广泛的操作,包括过滤、聚合和转换。本文介绍的是一些在工作中经常遇到的常见操作,希望对你有所帮助。
以上がPython 時系列データ操作の一般的な方法の概要の詳細内容です。詳細については、PHP 中国語 Web サイトの他の関連記事を参照してください。

ホットAIツール

Undresser.AI Undress
リアルなヌード写真を作成する AI 搭載アプリ

AI Clothes Remover
写真から衣服を削除するオンライン AI ツール。

Undress AI Tool
脱衣画像を無料で

Clothoff.io
AI衣類リムーバー

Video Face Swap
完全無料の AI 顔交換ツールを使用して、あらゆるビデオの顔を簡単に交換できます。

人気の記事
ホットツール

メモ帳++7.3.1
使いやすく無料のコードエディター

SublimeText3 中国語版
中国語版、とても使いやすい

ゼンドスタジオ 13.0.1
強力な PHP 統合開発環境

ドリームウィーバー CS6
ビジュアル Web 開発ツール

SublimeText3 Mac版
神レベルのコード編集ソフト(SublimeText3)
ホットトピック
 7696
7696
 15
1640
14
1393
52
1287
25
1229
29
15
1640
14
1393
52
1287
25
1229
29

 PHPおよびPython:さまざまなパラダイムが説明されています
Apr 18, 2025 am 12:26 AM
PHPおよびPython:さまざまなパラダイムが説明されています
Apr 18, 2025 am 12:26 AM
PHPは主に手順プログラミングですが、オブジェクト指向プログラミング(OOP)もサポートしています。 Pythonは、OOP、機能、手続き上のプログラミングなど、さまざまなパラダイムをサポートしています。 PHPはWeb開発に適しており、Pythonはデータ分析や機械学習などのさまざまなアプリケーションに適しています。
 PHPとPythonの選択:ガイド
Apr 18, 2025 am 12:24 AM
PHPとPythonの選択:ガイド
Apr 18, 2025 am 12:24 AM
PHPはWeb開発と迅速なプロトタイピングに適しており、Pythonはデータサイエンスと機械学習に適しています。 1.PHPは、単純な構文と迅速な開発に適した動的なWeb開発に使用されます。 2。Pythonには簡潔な構文があり、複数のフィールドに適しており、強力なライブラリエコシステムがあります。
 Python vs. JavaScript:学習曲線と使いやすさ
Apr 16, 2025 am 12:12 AM
Python vs. JavaScript:学習曲線と使いやすさ
Apr 16, 2025 am 12:12 AM
Pythonは、スムーズな学習曲線と簡潔な構文を備えた初心者により適しています。 JavaScriptは、急な学習曲線と柔軟な構文を備えたフロントエンド開発に適しています。 1。Python構文は直感的で、データサイエンスやバックエンド開発に適しています。 2。JavaScriptは柔軟で、フロントエンドおよびサーバー側のプログラミングで広く使用されています。
 ターミナルVSCODEでプログラムを実行する方法
Apr 15, 2025 pm 06:42 PM
ターミナルVSCODEでプログラムを実行する方法
Apr 15, 2025 pm 06:42 PM
VSコードでは、次の手順を通じて端末でプログラムを実行できます。コードを準備し、統合端子を開き、コードディレクトリが端末作業ディレクトリと一致していることを確認します。プログラミング言語(pythonのpython your_file_name.pyなど)に従って実行コマンドを選択して、それが正常に実行されるかどうかを確認し、エラーを解決します。デバッガーを使用して、デバッグ効率を向上させます。
 Windows 8でコードを実行できます
Apr 15, 2025 pm 07:24 PM
Windows 8でコードを実行できます
Apr 15, 2025 pm 07:24 PM
VSコードはWindows 8で実行できますが、エクスペリエンスは大きくない場合があります。まず、システムが最新のパッチに更新されていることを確認してから、システムアーキテクチャに一致するVSコードインストールパッケージをダウンロードして、プロンプトとしてインストールします。インストール後、一部の拡張機能はWindows 8と互換性があり、代替拡張機能を探すか、仮想マシンで新しいWindowsシステムを使用する必要があることに注意してください。必要な拡張機能をインストールして、適切に動作するかどうかを確認します。 Windows 8ではVSコードは実行可能ですが、開発エクスペリエンスとセキュリティを向上させるために、新しいWindowsシステムにアップグレードすることをお勧めします。
 Visual StudioコードはPythonで使用できますか
Apr 15, 2025 pm 08:18 PM
Visual StudioコードはPythonで使用できますか
Apr 15, 2025 pm 08:18 PM
VSコードはPythonの書き込みに使用でき、Pythonアプリケーションを開発するための理想的なツールになる多くの機能を提供できます。ユーザーは以下を可能にします。Python拡張機能をインストールして、コードの完了、構文の強調表示、デバッグなどの関数を取得できます。デバッガーを使用して、コードを段階的に追跡し、エラーを見つけて修正します。バージョンコントロールのためにGitを統合します。コードフォーマットツールを使用して、コードの一貫性を維持します。糸くずツールを使用して、事前に潜在的な問題を発見します。
 PHPとPython:彼らの歴史を深く掘り下げます
Apr 18, 2025 am 12:25 AM
PHPとPython:彼らの歴史を深く掘り下げます
Apr 18, 2025 am 12:25 AM
PHPは1994年に発信され、Rasmuslerdorfによって開発されました。もともとはウェブサイトの訪問者を追跡するために使用され、サーバー側のスクリプト言語に徐々に進化し、Web開発で広く使用されていました。 Pythonは、1980年代後半にGuidovan Rossumによって開発され、1991年に最初にリリースされました。コードの読みやすさとシンプルさを強調し、科学的コンピューティング、データ分析、その他の分野に適しています。
 VSCODE拡張機能は悪意がありますか?
Apr 15, 2025 pm 07:57 PM
VSCODE拡張機能は悪意がありますか?
Apr 15, 2025 pm 07:57 PM
VSコード拡張機能は、悪意のあるコードの隠れ、脆弱性の活用、合法的な拡張機能としての自慰行為など、悪意のあるリスクを引き起こします。悪意のある拡張機能を識別する方法には、パブリッシャーのチェック、コメントの読み取り、コードのチェック、およびインストールに注意してください。セキュリティ対策には、セキュリティ認識、良好な習慣、定期的な更新、ウイルス対策ソフトウェアも含まれます。
