この記事では、TPU と GPU を比較します。しかし、本題に入る前に、知っておくべきことがあります。
機械学習と人工知能テクノロジーは、インテリジェントなアプリケーションの開発を加速します。この目的を達成するために、半導体企業は、より複雑なアプリケーションを処理するために、TPU や CPU などのアクセラレータやプロセッサを開発し続けています。
一部のユーザーは、コンピュータ タスクを完了するためにどのような場合に TPU が推奨されるのか、またどのような場合に GPU が使用されるのかを理解するのに苦労しています。
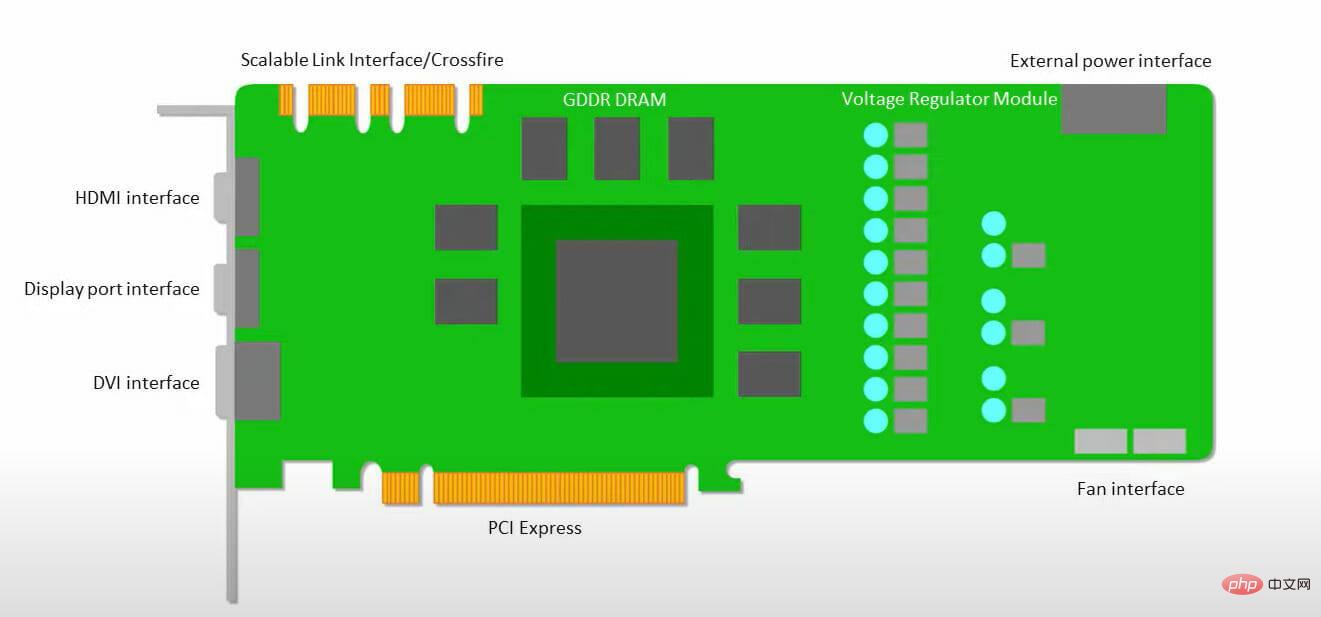
グラフィックス プロセッシング ユニットとも呼ばれる GPU は、視覚的で没入型の PC エクスペリエンスを提供する PC のビデオ カードです。たとえば、PC が GPU を検出しない場合は、簡単な手順に従うことができます。
これらの状況をより深く理解するには、TPU とは何か、また TPU と GPU がどのように比較されるのかを明確にする必要もあります。
TPUとは何ですか?
TPU または Tensor Processing Unit は、特定のアプリケーションに使用される、ASIC (Application Specific Integrated Circuit) とも呼ばれる特定用途向け集積回路 (IC) です。 Google は TPU をゼロから作成し、2015 年に使用を開始し、2018 年に一般公開しました。
#TPU は、マイナー シリコン バージョンまたはクラウド バージョンとして利用できます。 TensorFlow ソフトウェアを使用してニューラル ネットワークの機械学習を加速するために、クラウド TPU は複雑な行列演算とベクトル演算を驚異的な速度で解決します。
Google Brain チームは、TensorFlow を使用して、研究者、開発者、企業が Cloud TPU ハードウェアを使用して AI モデルを構築および運用できるオープンソースの機械学習プラットフォームを開発しました。
複雑で堅牢なニューラル ネットワーク モデルをトレーニングする場合、TPU は正確な値に到達するまでの時間を短縮します。これは、GPU を使用すると、数週間かかる可能性のある深層学習モデルのトレーニングがその時間のほんの一部で済むことを意味します。
TPU と GPU は同じですか?
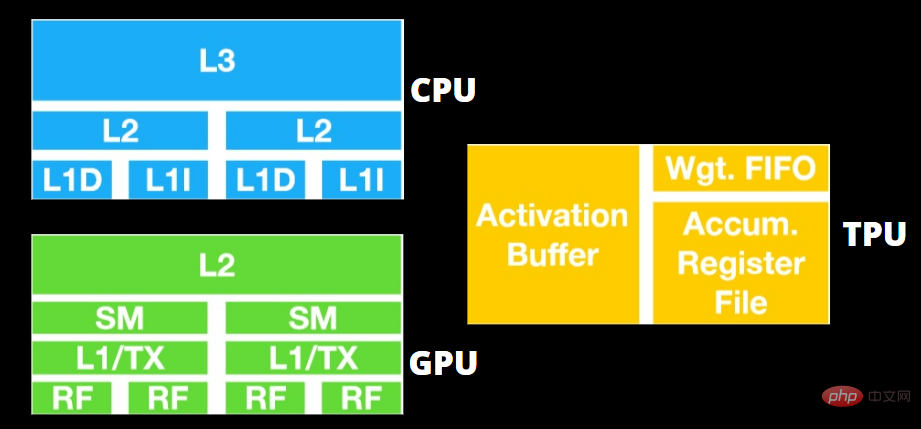
両者はアーキテクチャが大きく異なります。グラフィックス プロセッシング ユニットは、ベクトル化された数値プログラミングにパイプされていますが、それ自体がプロセッサーです。 GPU は実際には次世代の Cray スーパーコンピューターです。
TPU は命令自体を実行しないコプロセッサです。コードは CPU 上で実行され、小さな操作のフローが TPU に提供されます。
TPU をいつ使用する必要がありますか?
クラウド内の TPU は、特定のアプリケーション向けに調整されています。場合によっては、機械学習タスクを実行するために GPU または CPU を使用することを好む場合があります。一般に、次の原則は、TPU がワークロードにとって最適な選択であるかどうかを評価するのに役立ちます。
行列計算がモデルを支配する
モデルのメイン トレーニング ループには、次のものが含まれます。カスタム TensorFlow 操作はありません。
これらは、数週間または数か月かけてトレーニングされたモデルです。
これらは、広範囲の有効なバッチ サイズを持つ大規模なモデルです。
それでは、TPU と GPU の比較に直接移りましょう。
GPU と TPU の違いは何ですか?
TPU と GPU アーキテクチャ
TPU は非常に複雑なハードウェアではなく、従来の X86 派生アーキテクチャというよりは、レーダー アプリケーション用の信号処理エンジンのように感じられます。
行列の乗算や除算はたくさんありますが、GPU というよりはコプロセッサに似ており、ホストが受け取ったコマンドのみを実行します。
行列乗算コンポーネントに入力される重みが非常に多いため、TPU の DRAM は単一ユニットとして並列実行されます。
さらに、TPU は行列演算のみを実行できるため、TPU ボードは CPU ベースのホスト システムに接続され、TPU が処理できないタスクを完了します。
ホストは、TPU へのデータの転送、前処理、およびクラウド ストレージからの詳細の取得を担当します。
#GPU は、低遅延キャッシュにアクセスすることよりも、アプリケーションが動作するために利用可能なコアを確保することを重視します。
複数の SM (ストリーミング マルチプロセッサ) を備えた多くの PC (プロセッサのクラスタ) は、単一の GPU ガジェットになり、それぞれに第 1 レベルの命令キャッシュ層と付随するコアが含まれます。
SM は通常、グローバル GDDR-5 メモリからデータをフェッチする前に、2 つのキャッシュされた共有レイヤーと 1 つのキャッシュされたプライベート レイヤーを使用します。 GPU アーキテクチャはメモリ遅延を許容できます。
GPU は最小数のメモリ キャッシュ レベルで動作します。ただし、GPU には処理専用のトランジスタが多数あるため、メモリ内のデータへのアクセスにかかる時間はあまり気にされません。
GPU は常に十分な計算によって占有されるため、メモリ アクセスの遅延の可能性は隠れます。
TPU と GPU 速度
このオリジナルの TPU は、トレーニングされたモデルではなく学習されたモデルを使用して、ターゲットを絞った推論を生成します。
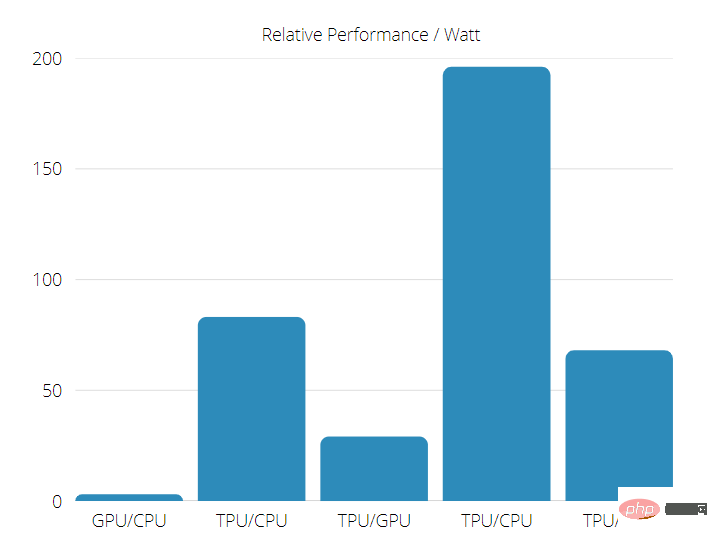
TPU は、ニューラル ネットワーク推論を使用する商用 AI アプリケーションにおいて、現在の GPU や CPU よりも 15 ~ 30 倍高速です。
さらに、TPU は非常にエネルギー効率が高く、TOPS/ワット値は 30 ~ 80 倍に増加します。
専門家によるヒント: 一部の PC の問題は、特にリポジトリが破損している場合や Windows ファイルが見つからない場合に解決が困難です。エラーを修正できない場合は、システムが部分的に破損している可能性があります。マシンをスキャンしてどこに障害があるかを特定できるツール、Restoro をインストールすることをお勧めします。
したがって、TPU と GPU の速度を比較すると、Tensor Processing Unit が有利になる可能性が高くなります。
TPU と GPU のパフォーマンス
TPU は、Tensorflow グラフ計算を高速化するために設計されたテンソル処理マシンです。
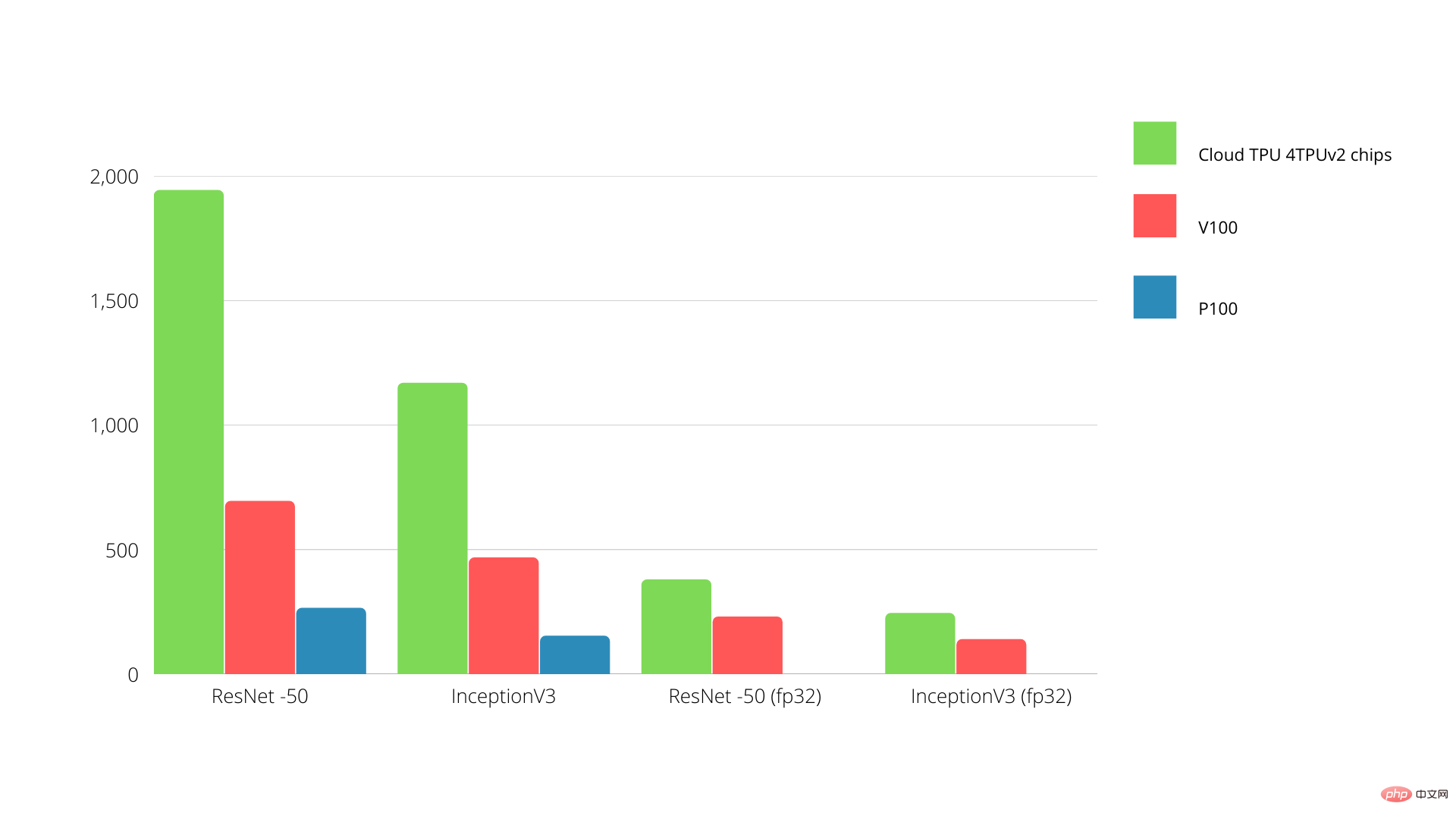
単一ボード上で、各 TPU は最大 64 GB の高帯域幅メモリと 180 テラフロップスの浮動小数点パフォーマンスを提供します。
Nvidia GPU と TPU の比較を以下に示します。 Y 軸は 1 秒あたりの写真の数を表し、X 軸はさまざまなモデルを表します。
#TPU と GPU の機械学習
以下は、異なるバッチ サイズと各エポック反復を使用した CPU と GPU のトレーニング時間です:
反復/エポック数: 100、バッチ サイズ: 1000、合計エポック: 25、パラメーター: 1.84 M、モデル タイプ: Keras Mobilenet V1 (アルファ 0.75)。
アクセラレータ トレーニング精度 (%)
検証精度 (%)
反復あたりの時間 (ミリ秒)
#エポックあたりの時間(秒)
合計時間 (分) 72
##反復/エポック: 1000、バッチ サイズ: 100、合計エポック: 25、パラメーター: 1.84 M、モデル タイプ: Keras Mobilenet V1 (アルファ 0.75)
アクセラレータ
GPU (NVIDIA K80)
熱可塑性ポリウレタン
トレーニング精度 (%)
97.4
96.9
検証精度 (%)
45.2
45.3
反復あたりの時間 (ミリ秒)
185
252
エポックあたりの時間(s)
18
25
合計時間 (分) 16
21
トレーニング時間からわかるように、より小さいバッチ サイズを使用すると、TPU はより長いトレーニング時間を必要とします。ただし、バッチ サイズが増加するにつれて、TPU のパフォーマンスは GPU に近づきます。
したがって、TPU と GPU トレーニングの比較を行うときは、エポックとバッチ サイズが大きく関係します。
TPU と GPU のベンチマーク
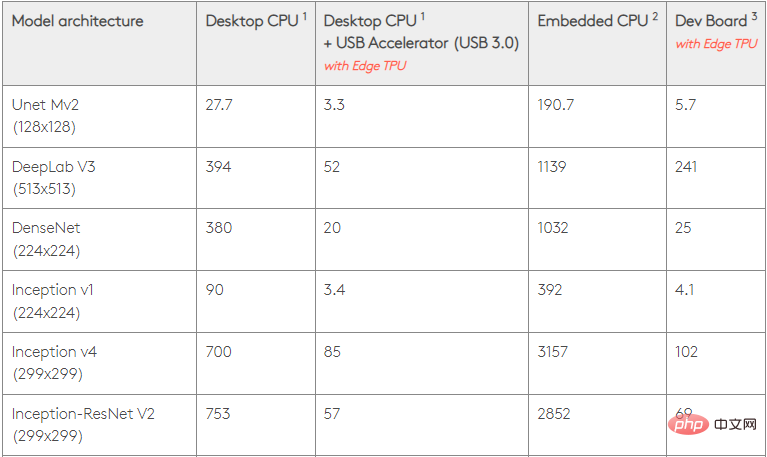
0.5 ワット/TOPS の場合、単一の Edge TPU は 1 秒あたり 4 兆回の操作を実行できます。これがアプリケーションのパフォーマンスにどの程度反映されるかに影響を与える変数がいくつかあります。
ニューラル ネットワーク モデルにはさまざまな要件があり、全体的な出力は USB アクセラレータ デバイスのホスト USB 速度、CPU、およびその他のシステム リソースによって異なります。
これを念頭に置いて、以下のグラフは、さまざまな標準モデルを使用して、Edge TPU で 1 つの推論を実行するのにかかる時間を比較しています。もちろん、比較の目的で、実行されるすべてのモデルは TensorFlow Lite バージョンです。
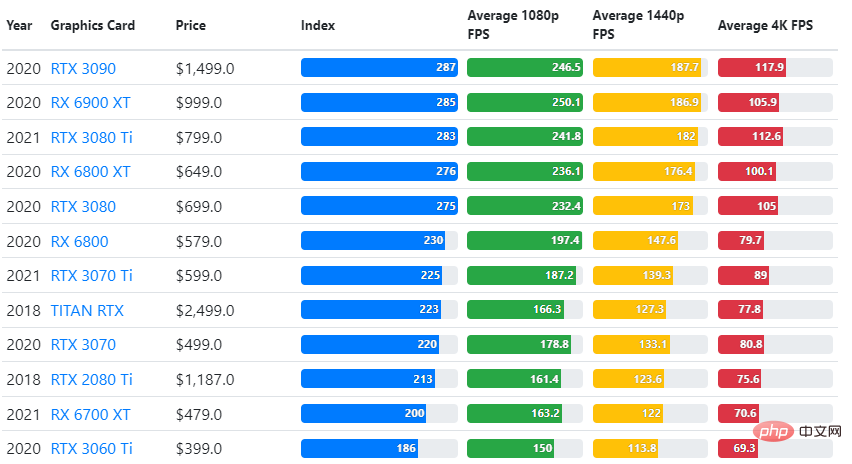
GPU ベンチマークの結果を、ユーザーが期待するゲーム品質設定および解像度と比較します。
70,000 を超えるベンチマークの評価に基づいて、ゲーム パフォーマンスの 90% の信頼できる推定値を生成する高度なアルゴリズムを慎重に構築しました。
グラフィックス カードのパフォーマンスはゲームによって異なりますが、以下の比較表は一部のグラフィックス カードの大まかな評価指標を示しています。
Nvidia Tesla P100 GPU 1 時間あたり 1.46 ドル Google TPU v3 1 時間あたり 8.00 ドル TPUv2 (GCP オンデマンド アクセス付き 1 時間あたり 4.50 ドル#) ##コストの最適化が目標の場合は、GPU より 5 倍の速度でモデルをトレーニングできる場合にのみ TPU を選択する必要があります。
CPU、GPU、TPU の違いは何ですか?
TPU、GPU、CPU の違いは、CPU がコンピュータのすべての計算、ロジック、入出力を処理する非特定用途のプロセッサであることです。
一方、GPU は、グラフィカル インターフェイス (GI) を改善し、ハイエンドのアクティビティを実行するために使用される追加のプロセッサです。 TPU は、TensorFlow などの特定のフレームワークを使用して開発されたプロジェクトを実行するために使用される強力な専用プロセッサです。
これらは次のように分類されます。
中央処理装置 (CPU) – コンピューターのあらゆる側面を制御します。
グラフィックス プロセッシング ユニット (GPU) – コンピューターの機能を向上させます。グラフィックス パフォーマンス
Tensor Processing Unit (TPU) – TensorFlow プロジェクト専用に設計された ASIC
NVIDIA が Google の TPU にどのように対応するのか疑問に思っている人は多いですが、その答えが見つかりました。
NVIDIA は、心配するのではなく、必要に応じて使用できるツールとして TPU を再位置づけすることに成功しましたが、依然として CUDA ソフトウェアと GPU を最前線に保ち続けています。
テクノロジーをオープンソースにすることで、IoT 機械学習導入のコントロール ポイントを維持します。ただし、このアプローチの危険性は、データセンター推論エンジンに関する NVIDIA の長期目標に挑戦する可能性のある概念を伝える可能性があることです。
GPU と TPU のどちらが優れていますか?
結論として、TPU を効率的に使用できるアルゴリズムの開発には追加コストがかかりますが、削減されたトレーニング コストは追加のプログラミング費用を上回ることが多いと言わざるを得ません。
TPU を選択するその他の理由には、v3-128 には Nvidia GPU よりも 8 G のビデオ メモリが搭載されており、NLU および NLP に関連する大規模なデータ セットを処理するには v3-8 がより良い選択肢となるという事実が含まれます。
ベロシティの向上は、開発サイクルの反復の高速化にもつながり、より迅速かつ頻繁なイノベーションにつながり、市場で成功する可能性が高まります。
TPU は、イノベーションの速度、使いやすさ、手頃な価格の点で GPU を上回っています。消費者とクラウド アーキテクトは、ML および AI 計画で TPU を検討する必要があります。
Google の TPU には十分な処理能力があるため、ユーザーはデータ入力を調整して過負荷にならないようにする必要があります。
これで、TPU と GPU の総合比較になります。皆様のご意見、テストを行ったかどうか、TPU と GPU で得られた結果を知りたいと思っています。
Windows 11 用の最高のグラフィック カードを使用すると、没入型の PC エクスペリエンスを楽しむことができることを覚えておいてください。
以上がTPU と GPU: 実際のシナリオにおけるパフォーマンスと速度の比較差の詳細内容です。詳細については、PHP 中国語 Web サイトの他の関連記事を参照してください。




 NVIDIA は TPU を製造していますか?
NVIDIA は TPU を製造していますか? 















![[Web フロントエンド] Node.js クイック スタート](https://img.php.cn/upload/course/000/000/067/662b5d34ba7c0227.png)



