

ノードのバッファーについて詳しく見る


ストリームの章の最後で、次のコードによって出力されるチャンクは何なのかという疑問が残ります。
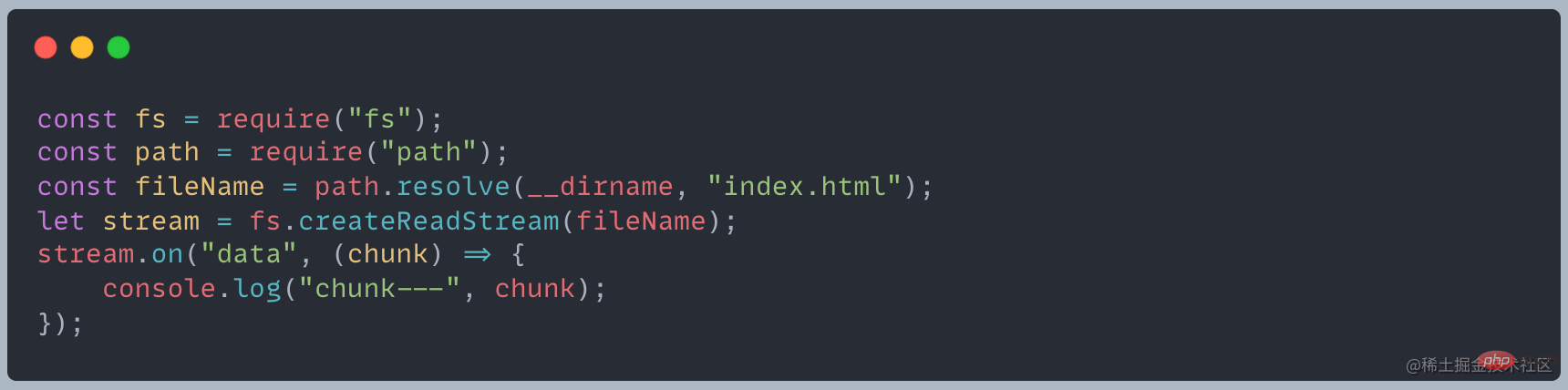
印刷してみると、chunk は Buffer オブジェクトであり、その要素は 16 進数の 2 桁の数値、つまり 0 から 255 までの値であることがわかります。 [関連チュートリアルの推奨事項: nodejs ビデオ チュートリアル 、プログラミング教育 ]

ストリーム内を流れるデータがバッファであることを説明するでは、バッファーの素顔を探ってみましょう!
? なぜ Node に Buffer が導入されたのか?
当初、JS はブラウザ側でのみ動作していました。Unicode でエンコードされた文字列は処理しやすかったのですが、バイナリの場合は非 Unicode エンコーディングの文字列の処理が困難。バイナリはコンピュータの最低レベルのデータ形式であり、ビデオ、オーディオ、プログラム、ネットワークのパケットはすべてバイナリで保存されます。そこで、ノードはバイナリを操作するためのオブジェクトを導入する必要があるため、TCP ストリーム/ファイル システムやバイナリ バイトを処理するその他の操作に使用される Buffer が誕生しました。
Buffer は Node でよく使われるため、Node の起動時に Buffer が導入されており、require() を使用する必要はありません。
ArrayBuffer
何ですか
ArrayBuffer はメモリ内のバイナリ データです。メモリ自体を操作することはできません。TypedArray オブジェクト または DataView を通じて操作する必要があります。バッファ内のデータを特定の形式で表現し、これらの形式を通じてバッファの内容を読み書きします。配列インターフェイスを展開し、配列を使用してデータを操作できます
#TypedArray ビュー最も一般的に使用されるのは TypeArray ビューで、Uint8Array (符号なし 8 ビット整数) 配列ビュー、Int16Array (16 ビット整数) 配列ビューなどの単純な型の ArrayBuffer の読み取りと書き込みに使用されます Buffer との関係NodeJS の Buffer クラスは、実際には Uint8Array の実装です。 バッファ構造バッファは配列に似たオブジェクトですが、主にバイトの操作に使用されますモジュール構造バッファはJSを組み合わせたものですおよび C モジュールのパフォーマンス部分は C で実装され、非パフォーマンス部分は JS で実装されます。
#オブジェクト構造
Buffer オブジェクトは配列に似ており、その要素は 2 桁の 16 進数、つまり 0 から 255 までの値です
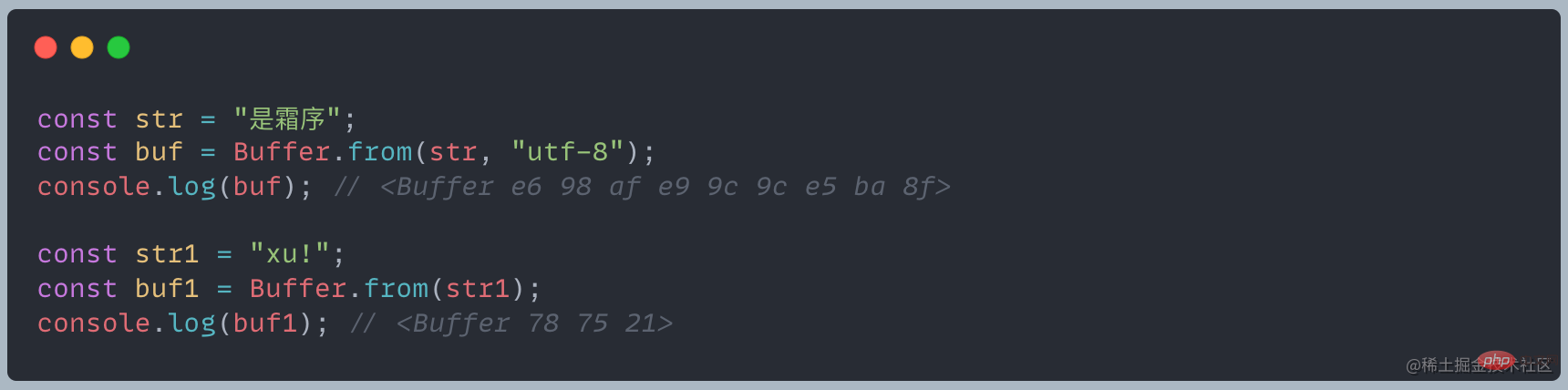 この例から、異なる文字がバッファ内の異なるバイトを占有することがわかります。UTF-8 エンコーディングでは、中国語は 3 バイトを占有し、英語と半角記号は 1 バイトを占有します。
この例から、異なる文字がバッファ内の異なるバイトを占有することがわかります。UTF-8 エンコーディングでは、中国語は 3 バイトを占有し、英語と半角記号は 1 バイトを占有します。
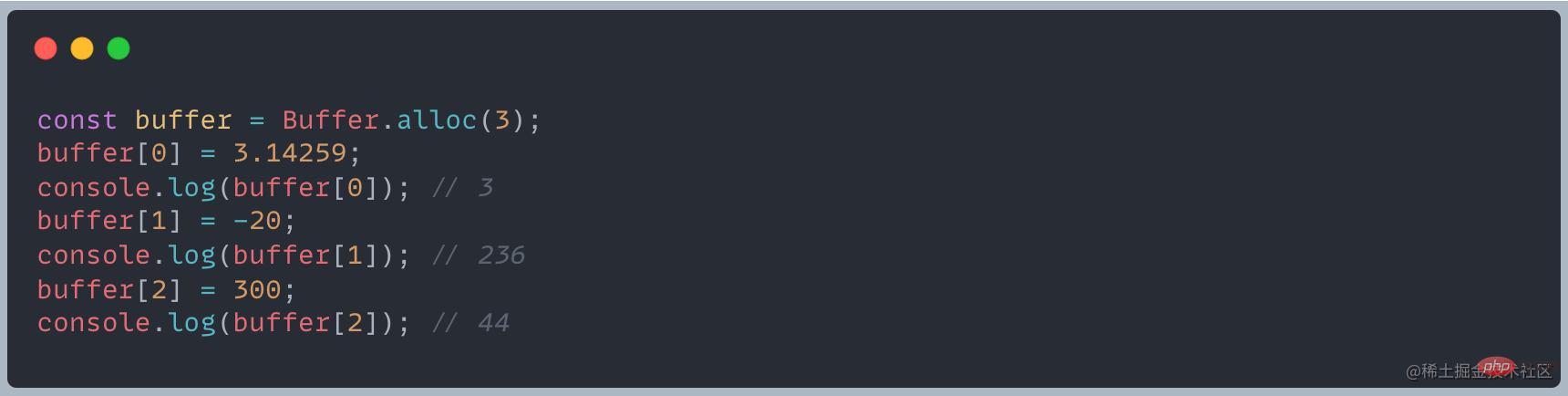 上記の状況の場合、バッファの処理は次のようになります。
上記の状況の場合、バッファの処理は次のようになります。
- 取得した値が 255 より大きい場合は、0 から 255 までの値が得られるまで 256 を 1 つずつ減算します
- 10 進数の場合、整数部分のみが保持されます。
実際には、2 進数はまだメモリに保存されていますが、バッファはメモリを表示しています データは、サイズが 2 バイトの 16 進数の
バッファを使用しています。
00000001 00100011 のように、合計 16 ビットがあります。このように直接表示するのが不便な場合は、16ビットに変換してください Base<buffer></buffer>Bufferの作成
Buffer.allocおよび Buffer.allocUnsafe
固定サイズのバッファを作成
Buffer.alloc(size [, fill [,coding]])
- size 新しいバッファーの必要な長さ
- fill 新しいバッファーを事前に埋めるために使用される値。デフォルト: 0
- encoding fill が文字列の場合、これはその文字エンコーディングです。デフォルト値: utf8

Buffer.allocUnsafe(size)
size バイトのバッファを割り当てます。 allocUnsafe は alloc よりも高速に実行されます。 Buffer.allocのように結果は00に初期化されません。

allocUnsafe呼び出し時に割り当てられるメモリセグメントはまだ初期化されていないため、メモリ割り当て速度は非常に遅くなりますが、割り当てられたメモリセグメントには古いデータが含まれている可能性があります。これらの古いデータが使用中に上書きされない場合、メモリ リークが発生する可能性があります。高速ではありますが、使用は避けてください。
Buffer モジュールは、Buffer.poolSize のサイズで内部 Buffer インスタンスを事前に割り当てます。クイック割り当てメモリ プールとして、allocUnsafe を使用して新しいバッファ インスタンスを作成するために使用されます。
Buffer.from
コンテンツに基づいてバッファを直接作成します。
- Buffer.from( string [, encoding] )
- Buffer.from(array)
- Buffer.from(buffer)

#のメモリメカニズムBuffer.allocUnsafe
適用されたメモリを効率的に使用するために、Node.js では動的管理メカニズムである適用前および割り当て後のスラブ機構を採用しています。指定されたサイズは、固定サイズのメモリ領域に適用されます。スラブには次の 3 つの状態があります。
full: 完全に割り当てられた状態- partial:部分的に割り当てられた状態
- 空: 割り当てられていない状態
- Node.js は、小さなオブジェクトと大きなオブジェクトを区別するために 8 KB を制限として使用します

小さなオブジェクトを割り当てる
割り当てられたオブジェクトが 8KB 未満の場合、ノードはそれを小さなオブジェクトとして割り当てます
バッファ割り当てプロセスでは、主にローカルの変数プールは中間処理オブジェクトとして機能し、割り当てられた状態のすべてのスラブ ユニットはそれを指します。以下は、新しいスラブ ユニットを割り当てる操作です。これにより、新しく適用された SlowBuffer オブジェクトがそのスラブ ユニットを指します
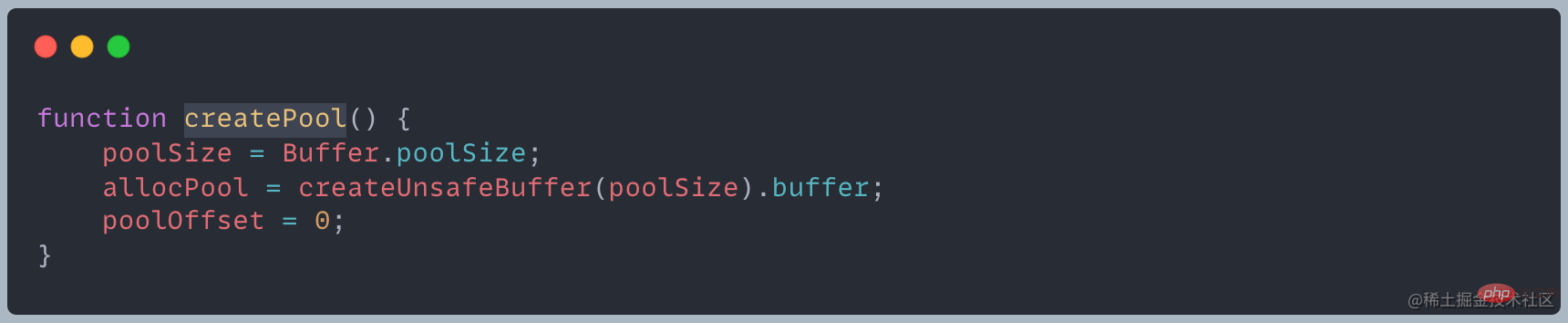 スラブ ユニット
スラブ ユニット
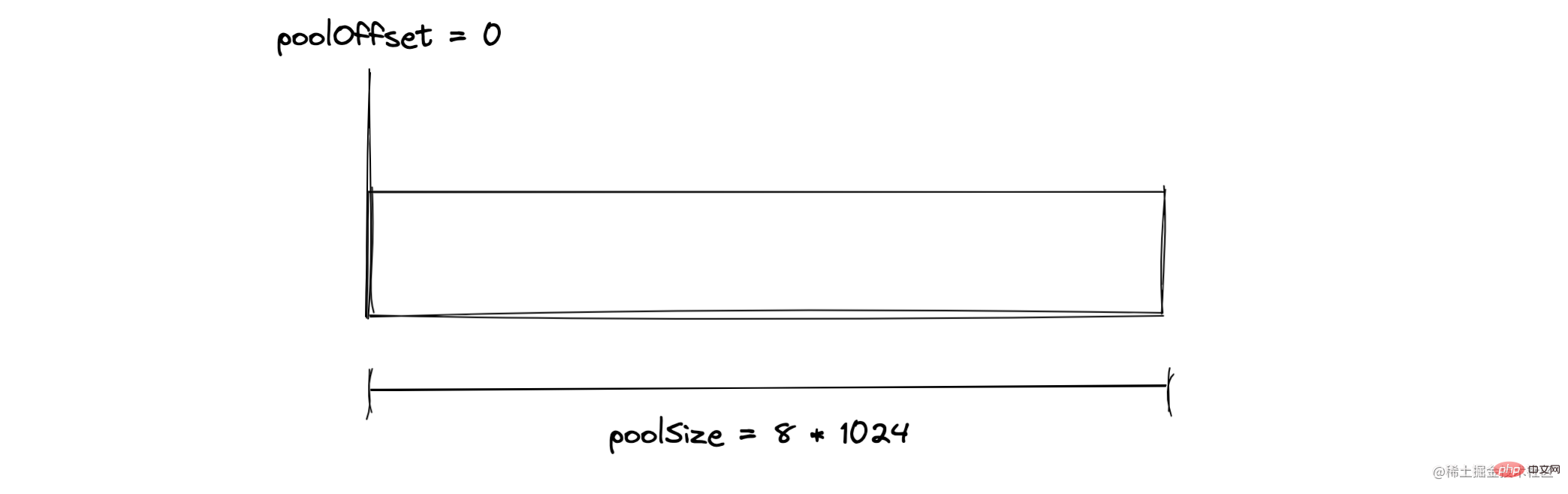 2KB バッファの割り当て
2KB バッファの割り当て
2KB バッファを作成した後、スラブ単位のメモリは次のようになります。
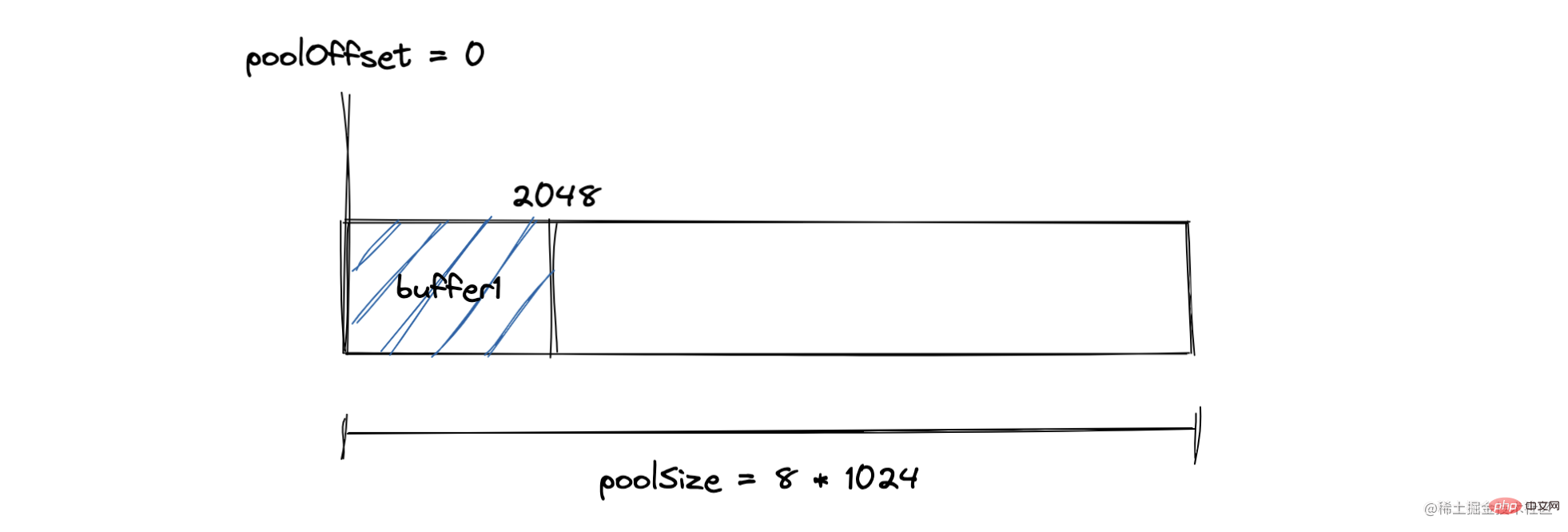 この割り当てプロセスは実行されます。 by assign メソッドが完了しました
この割り当てプロセスは実行されます。 by assign メソッドが完了しました
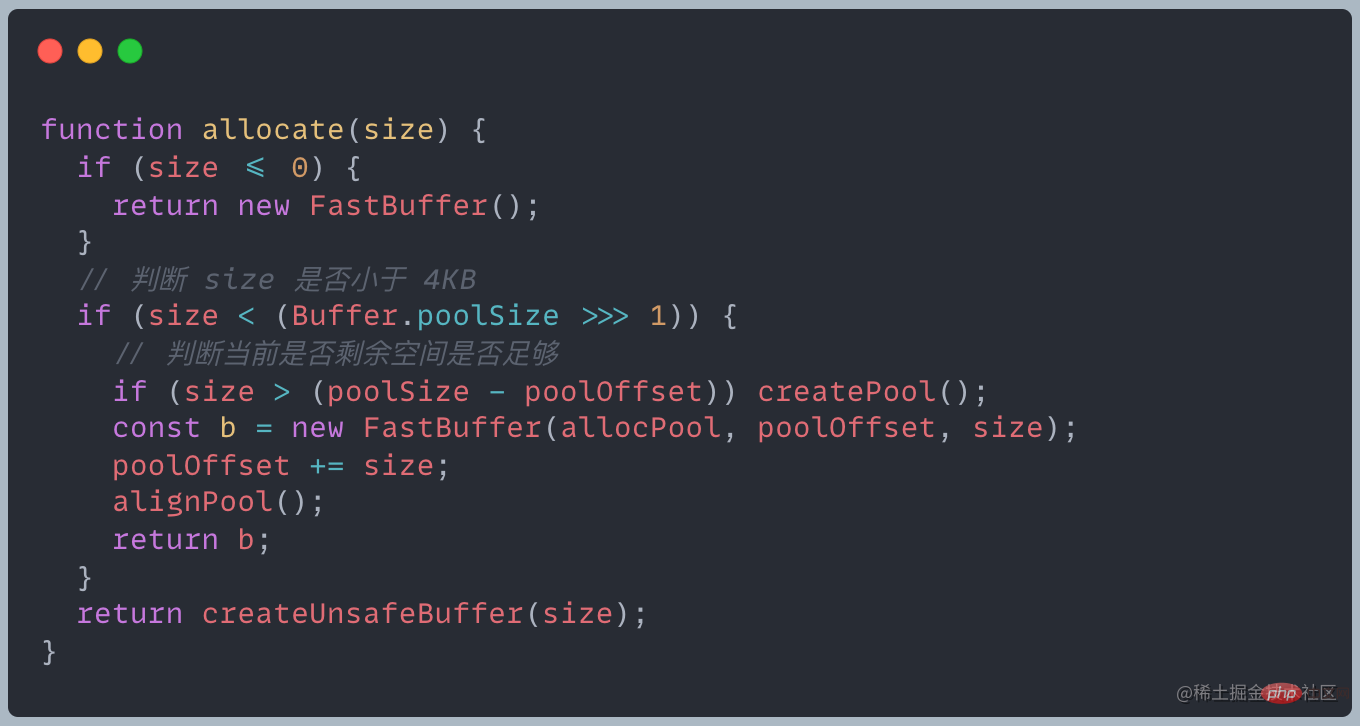 2KB バッファを作成した後、現在のスラブ ステータスは部分的です
2KB バッファを作成した後、現在のスラブ ステータスは部分的です
バッファを再度作成するときに、残りのスラブ ステータスを判断しますスラブサイズ 十分なスペースはありますか?十分な場合は、残りのスペースを使用してスラブ割り当てステータスを更新します
スラブ スペースが十分でない場合は、新しいスラブが構築され、元のスラブの残りのスペースが無駄になります
大きなオブジェクトの割り当て
8KB を超えるバッファがある場合は、直接 creatUnsafeBuffer 関数に進み、スラブ ユニットを割り当てます。このスラブ ユニットは、この大きなバッファ オブジェクトによって排他的に占有されます。
allocate 割り当てメカニズムは図に示すとおりですバッファのメモリ割り当てメカニズム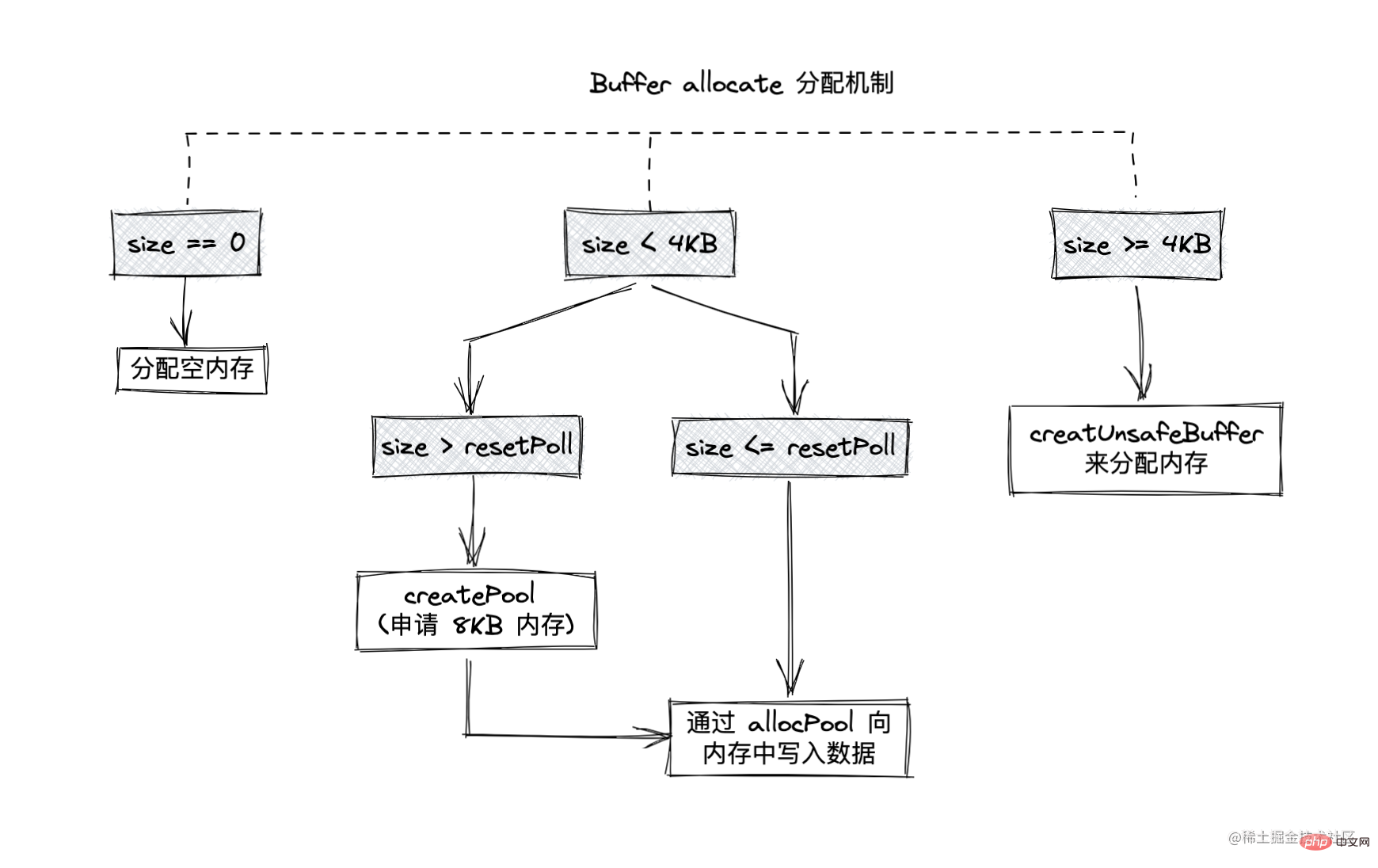
バッファと文字エンコーディング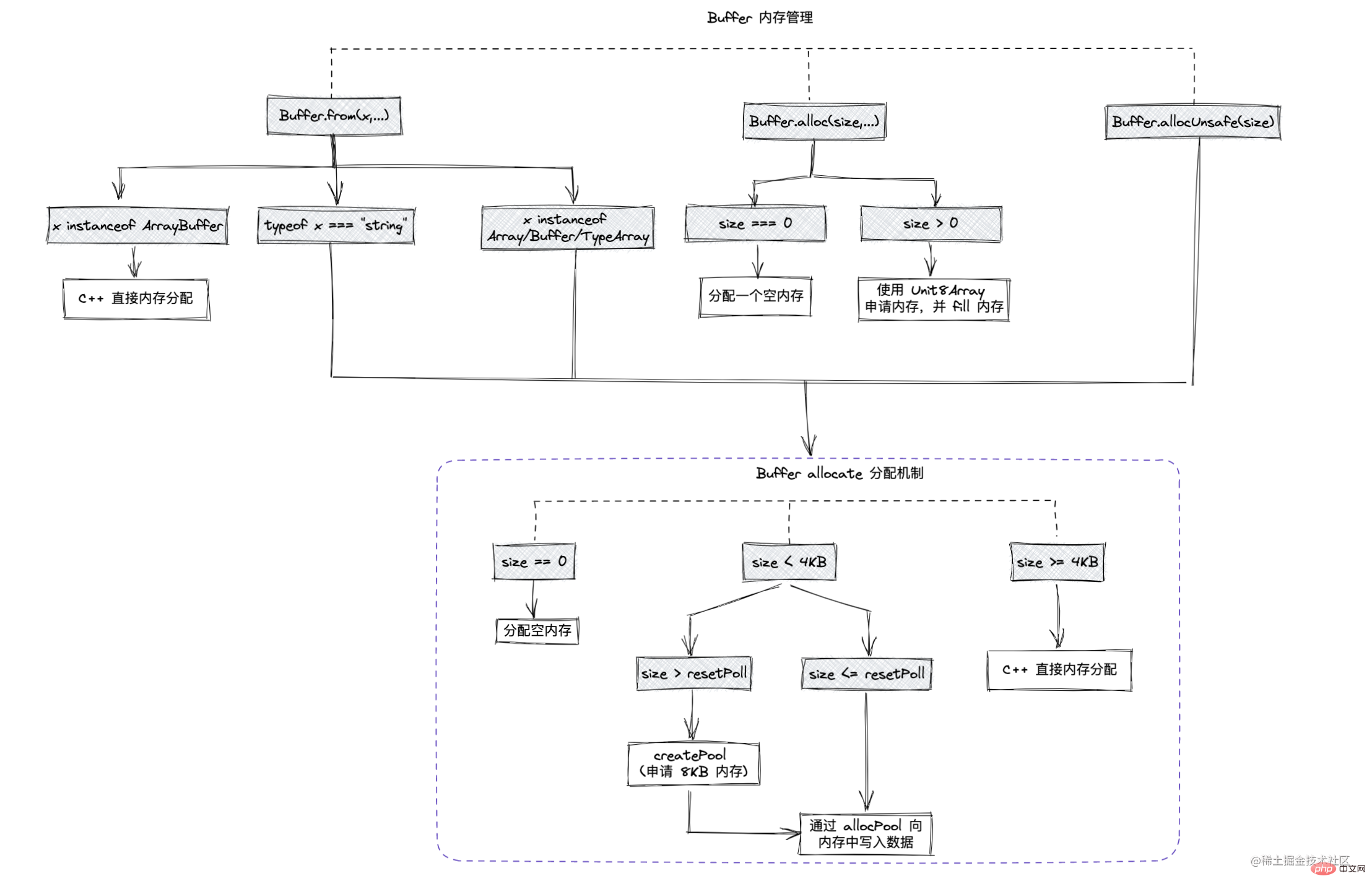
#
Node は現在、utf8、ucs2、utf16le、latin1、ascii、base64、hex、base64Url の 8 つのエンコード方式をサポートしています。異なるエンコーディング スキームごとに、一連の API が実装され、異なる結果が返されます。Node.js は、受信したエンコーディングに応じて異なるオブジェクトを返します##バッファと文字列の変換
Convert string to Buffer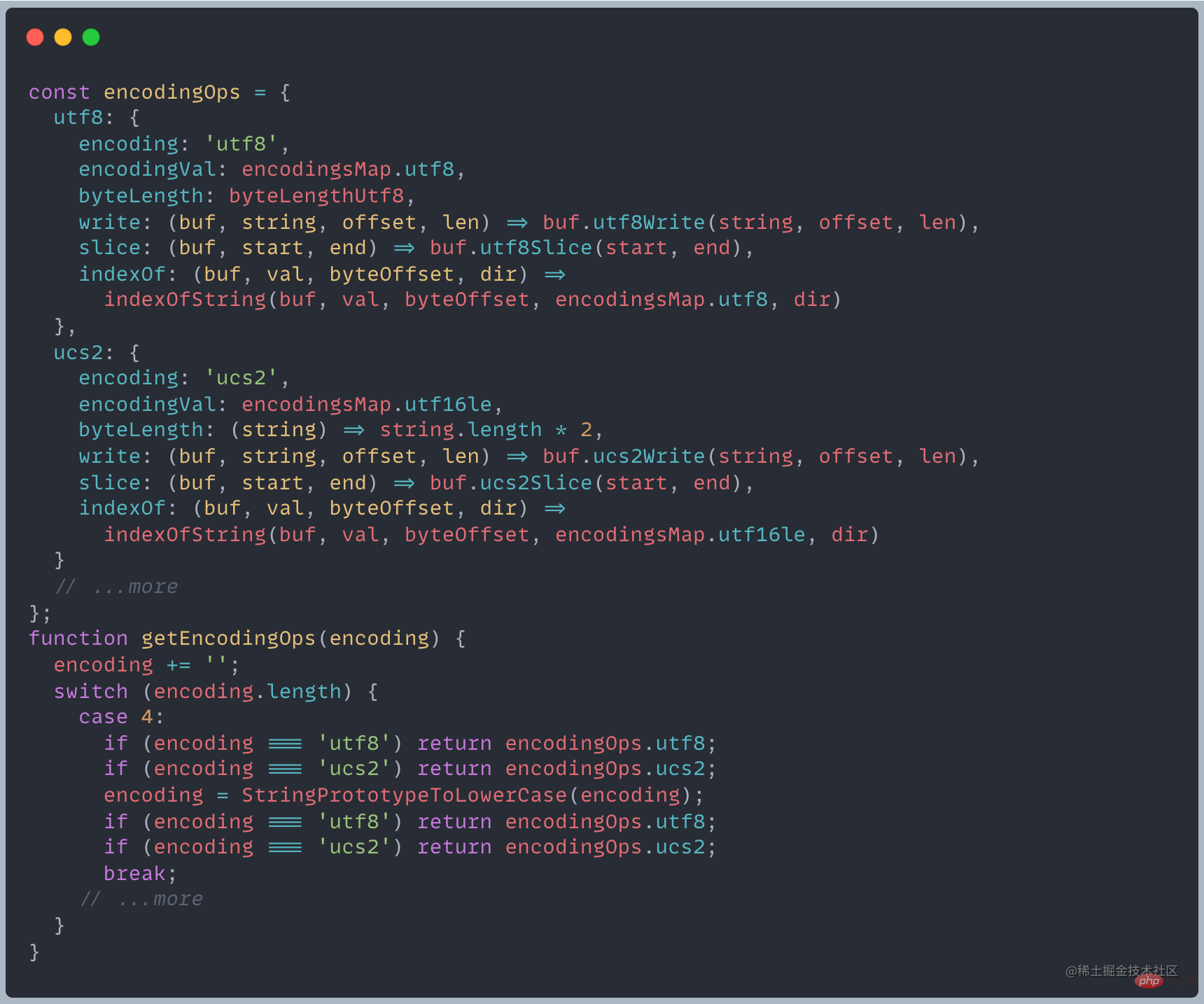 主に前述の Buffer.from メソッドを使用し、デフォルトのエンコード方法は utf-8
主に前述の Buffer.from メソッドを使用し、デフォルトのエンコード方法は utf-8
Buffer to string
? 文字化けが発生するのはなぜですか?この問題を解決するにはどうすればよいでしょうか?
読み取りによると、各読み取りの長さは 4 で、チャンク出力は次のとおりです。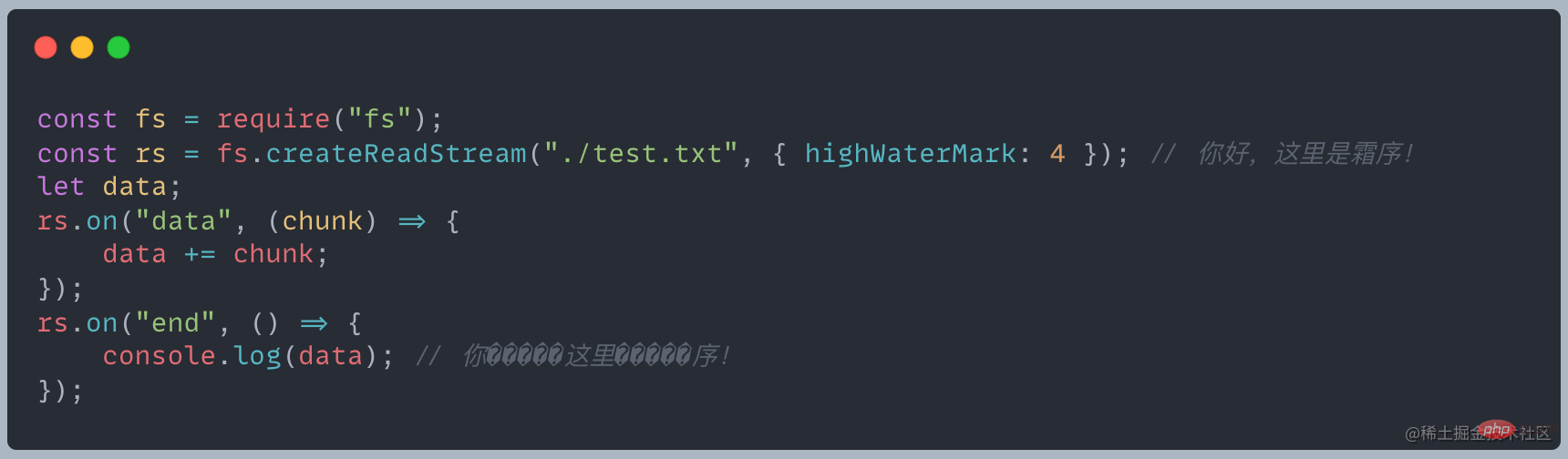
data = chunk の場合は、
data = data.toString chunk.toString
 と同等です。1 つの中国語文字が 3 バイトを占めるため、最初のチャンクの 4 バイト目に文字化けが表示されます。 2 番目のチャンクの 2 番目のバイトはテキストなどを形成できないため、文字化けの問題が表示されます。
と同等です。1 つの中国語文字が 3 バイトを占めるため、最初のチャンクの 4 バイト目に文字化けが表示されます。 2 番目のチャンクの 2 番目のバイトはテキストなどを形成できないため、文字化けの問題が表示されます。
ノード関連の詳細については、nodejs チュートリアル を参照してください。
以上がノードのバッファーについて詳しく見るの詳細内容です。詳細については、PHP 中国語 Web サイトの他の関連記事を参照してください。

ホットAIツール

Undresser.AI Undress
リアルなヌード写真を作成する AI 搭載アプリ

AI Clothes Remover
写真から衣服を削除するオンライン AI ツール。

Undress AI Tool
脱衣画像を無料で

Clothoff.io
AI衣類リムーバー

Video Face Swap
完全無料の AI 顔交換ツールを使用して、あらゆるビデオの顔を簡単に交換できます。

人気の記事
ホットツール

メモ帳++7.3.1
使いやすく無料のコードエディター

SublimeText3 中国語版
中国語版、とても使いやすい

ゼンドスタジオ 13.0.1
強力な PHP 統合開発環境

ドリームウィーバー CS6
ビジュアル Web 開発ツール

SublimeText3 Mac版
神レベルのコード編集ソフト(SublimeText3)
ホットトピック
 7681
7681
 15
1393
52
1209
24
91
11
15
1393
52
1209
24
91
11

 PHP と Vue: フロントエンド開発ツールの完璧な組み合わせ
Mar 16, 2024 pm 12:09 PM
PHP と Vue: フロントエンド開発ツールの完璧な組み合わせ
Mar 16, 2024 pm 12:09 PM
PHP と Vue: フロントエンド開発ツールの完璧な組み合わせ 今日のインターネットの急速な発展の時代において、フロントエンド開発はますます重要になっています。 Web サイトやアプリケーションのエクスペリエンスに対するユーザーの要求がますます高まっているため、フロントエンド開発者は、より効率的で柔軟なツールを使用して、応答性の高いインタラクティブなインターフェイスを作成する必要があります。フロントエンド開発の分野における 2 つの重要なテクノロジーである PHP と Vue.js は、組み合わせることで完璧なツールと見なされます。この記事では、PHP と Vue の組み合わせと、読者がこれら 2 つをよりよく理解し、適用できるようにするための詳細なコード例について説明します。
 フロントエンド開発に Go 言語を使用するにはどうすればよいですか?
Jun 10, 2023 pm 05:00 PM
フロントエンド開発に Go 言語を使用するにはどうすればよいですか?
Jun 10, 2023 pm 05:00 PM
インターネット技術の発展に伴い、フロントエンド開発の重要性がますます高まっています。特にモバイル デバイスの人気により、効率的で安定しており、安全で保守が容易なフロントエンド開発テクノロジーが必要です。 Go 言語は、急速に発展しているプログラミング言語として、ますます多くの開発者によって使用されています。では、フロントエンド開発に Go 言語を使用することは可能でしょうか?次に、この記事ではフロントエンド開発にGo言語を使用する方法を詳しく説明します。まずはフロントエンド開発にGo言語が使われる理由を見てみましょう。多くの人は Go 言語は
 C# 開発経験の共有: フロントエンドとバックエンドの共同開発スキル
Nov 23, 2023 am 10:13 AM
C# 開発経験の共有: フロントエンドとバックエンドの共同開発スキル
Nov 23, 2023 am 10:13 AM
C# 開発者としての私たちの開発作業には、通常、フロントエンドとバックエンドの開発が含まれますが、テクノロジーが発展し、プロジェクトが複雑になるにつれて、フロントエンドとバックエンドの共同開発はますます重要かつ複雑になってきています。この記事では、C# 開発者が開発作業をより効率的に完了できるようにする、フロントエンドとバックエンドの共同開発テクニックをいくつか紹介します。インターフェイスの仕様を決定した後、フロントエンドとバックエンドの共同開発は API インターフェイスの相互作用から切り離せません。フロントエンドとバックエンドの共同開発をスムーズに進めるためには、適切なインターフェース仕様を定義することが最も重要です。インターフェイスの仕様にはインターフェイスの名前が含まれます
 フロントエンドの面接官からよく聞かれる質問
Mar 19, 2024 pm 02:24 PM
フロントエンドの面接官からよく聞かれる質問
Mar 19, 2024 pm 02:24 PM
フロントエンド開発のインタビューでは、HTML/CSS の基本、JavaScript の基本、フレームワークとライブラリ、プロジェクトの経験、アルゴリズムとデータ構造、パフォーマンスの最適化、クロスドメイン リクエスト、フロントエンド エンジニアリング、デザインパターン、新しいテクノロジーとトレンド。面接官の質問は、候補者の技術スキル、プロジェクトの経験、業界のトレンドの理解を評価するように設計されています。したがって、候補者はこれらの分野で自分の能力と専門知識を証明するために十分な準備をしておく必要があります。
 Django はフロントエンドですか、バックエンドですか?それをチェックしてください!
Jan 19, 2024 am 08:37 AM
Django はフロントエンドですか、バックエンドですか?それをチェックしてください!
Jan 19, 2024 am 08:37 AM
Django は、迅速な開発とクリーンなメソッドを重視した Python で書かれた Web アプリケーション フレームワークです。 Django は Web フレームワークですが、Django がフロントエンドなのかバックエンドなのかという質問に答えるには、フロントエンドとバックエンドの概念を深く理解する必要があります。フロントエンドはユーザーが直接対話するインターフェイスを指し、バックエンドはサーバー側プログラムを指し、HTTP プロトコルを通じてデータと対話します。フロントエンドとバックエンドが分離されている場合、フロントエンドとバックエンドのプログラムをそれぞれ独立して開発して、ビジネス ロジックとインタラクティブ効果、およびデータ交換を実装できます。
 Go 言語のフロントエンド テクノロジーの探求: フロントエンド開発の新しいビジョン
Mar 28, 2024 pm 01:06 PM
Go 言語のフロントエンド テクノロジーの探求: フロントエンド開発の新しいビジョン
Mar 28, 2024 pm 01:06 PM
Go 言語は、高速で効率的なプログラミング言語として、バックエンド開発の分野で広く普及しています。ただし、Go 言語をフロントエンド開発と結びつける人はほとんどいません。実際、フロントエンド開発に Go 言語を使用すると、効率が向上するだけでなく、開発者に新たな視野をもたらすことができます。この記事では、フロントエンド開発に Go 言語を使用する可能性を探り、読者がこの分野をよりよく理解できるように具体的なコード例を示します。従来のフロントエンド開発では、ユーザー インターフェイスの構築に JavaScript、HTML、CSS がよく使用されます。
 フロントエンドにインスタントメッセージングを実装する方法
Oct 09, 2023 pm 02:47 PM
フロントエンドにインスタントメッセージングを実装する方法
Oct 09, 2023 pm 02:47 PM
インスタント メッセージングを実装する方法には、WebSocket、ロング ポーリング、サーバー送信イベント、WebRTC などが含まれます。詳細な紹介: 1. クライアントとサーバーの間に永続的な接続を確立してリアルタイムの双方向通信を実現できる WebSocket フロントエンドは WebSocket API を使用して WebSocket 接続を作成し、送受信によるインスタント メッセージングを実現できます。 2. Long Polling(リアルタイム通信を模擬する技術)など
 golang はフロントエンドとして使用できますか?
Jun 06, 2023 am 09:19 AM
golang はフロントエンドとして使用できますか?
Jun 06, 2023 am 09:19 AM
Golang はフロントエンドとして使用できます。Golang は、フロントエンド アプリケーションなど、さまざまなタイプのアプリケーションの開発に使用できる非常に多用途なプログラミング言語です。Golang を使用してフロントエンドを作成することで、 JavaScript などの言語によって引き起こされる一連の問題、たとえば、型安全性の低さ、パフォーマンスの低下、コードの保守の困難などの問題です。
