


皆さんこんにちは、私はブラザーJです。 (記事の最後に記載されています)
データのビジュアライゼーションとは、グラフィックまたはテーブルを使用して、現在のデータ。グラフはデータの性質と、データまたは属性間の関係を明確に表現できるため、グラフの解釈が容易になります。 Exploratory Graph を通じて、ユーザーはデータの特性を理解し、データの傾向を見つけ、データを理解するための敷居を下げることができます。
この章では、Matplotlib モジュールを使用するのではなく、主に Pandas を使用してグラフィックを描画します。実際、Pandas は Matplotlib の描画メソッドを DataFrame に統合しているため、実際のアプリケーションでは、ユーザーは描画作業を完了するために Matplotlib を直接参照する必要はありません。
折れ線グラフは最も基本的なグラフで、さまざまなフィールドの連続データ間の関係を表すために使用できます。折れ線グラフを描画するにはplot.line()メソッドを使用し、色や形状などのパラメータを設定できます。使用に関しては、分割線図を描画するメソッドは Matplotlib の使用法を完全に継承しているため、図 8.4 に示すように、プログラムは最後に plt.show() を呼び出して図を生成する必要もあります。
df_iris[['sepal length (cm)']].plot.line() plt.show() ax = df[['sepal length (cm)']].plot.line(color='green',title="Demo",style='--') ax.set(xlabel="index", ylabel="length") plt.show()
散布図は、さまざまなフィールドの離散データ間の関係を表示するために使用されます。図 8.5 に示すように、散布図は df.plot.scatter() を使用して描画されます。
df = df_iris
df.plot.scatter(x='sepal length (cm)', y='sepal width (cm)')
from matplotlib import cm
cmap = cm.get_cmap('Spectral')
df.plot.scatter(x='sepal length (cm)',
y='sepal width (cm)',
s=df[['petal length (cm)']]*20,
c=df['target'],
cmap=cmap,
title='different circle size by petal length (cm)')
ヒストグラム グラフは通常、連続データの分布を示すために同じ列で使用されます。ヒストグラムは棒グラフであり、図 8.6 に示すように、同じ列を表示するために使用されます。
df[['sepal length (cm)', 'sepal width (cm)', 'petal length (cm)','petal width (cm)']].plot.hist() 2 df.target.value_counts().plot.bar()
円グラフを使用すると、同じ列に各カテゴリの割合を表示できます。図 8.7 に示すように、チャート (ボックス チャート) は、同じフィールドを表示したり、異なるフィールドのデータの分布の違いを比較したりするために使用されます。
df.target.value_counts().plot.pie(legend=True) df.boxplot(column=['target'],figsize=(10,5))
このセクションでは、2 つの実際のデータ セットを使用して、データ探索のいくつかの方法を実際に示します。
アメリカ コミュニティ調査では、毎年約 350 万世帯に、自分たちが誰なのか、どのように暮らしているのかについて詳細な情報を尋ねています。この調査は、祖先、教育、仕事、交通、インターネットの使用、住居などの多くのトピックをカバーしています。
データ ソース: https://www.kaggle.com/census/2013-american-community-survey。
データ名: 2013年アメリカ社会調査。
まず、データの外観と特性、および各フィールドの意味、タイプ、範囲を観察します。
# 读取数据
df = pd.read_csv("./ss13husa.csv")
# 栏位种类数量
df.shape
# (756065,231)
# 栏位数值范围
df.describe()まず、2 つの ss13pusa.csv を接続します。このデータには、SCHL (学校レベル)、PINCP (収入)、ESR (勤務状況) の 3 つのフィールドと合計 300,000 個のデータが含まれています。
pusa = pd.read_csv("ss13pusa.csv") pusb = pd.read_csv("ss13pusb.csv")
# 串接两份数据
col = ['SCHL','PINCP','ESR']
df['ac_survey'] = pd.concat([pusa[col],pusb[col],axis=0)データを学歴別にグループ化し、異なる学歴を持つ数字の割合を観察し、平均収入を計算します。
group = df['ac_survey'].groupby(by=['SCHL']) print('学历分布:' + group.size())
group = ac_survey.groupby(by=['SCHL']) print('平均收入:' +group.mean())ボストン住宅価格データセットには、506 のデータ サンプルと 13 の特徴ディメンションを含む、ボストン地域の住宅に関する情報が含まれています。
データ ソース: https://archive.ics.uci.edu/ml/machine-learning-databases/housing/。
データ名: ボストン住宅価格データセット。
まず、データの外観と特性、および各フィールドの意味、タイプ、範囲を観察します。
住宅価格の分布 (MEDV) は、図 8.8 に示すように、ヒストグラムの形式で描画できます。
df = pd.read_csv("./housing.data")
# 栏位种类数量
df.shape
# (506, 14)
#栏位数值范围df.describe()
import matplotlib.pyplot as plt
df[['MEDV']].plot.hist()
plt.show()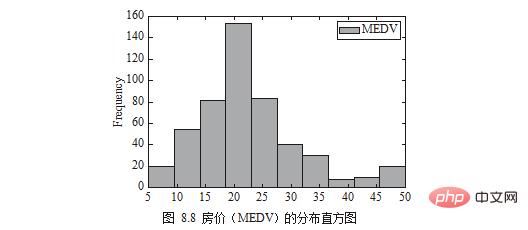
注: 画像内の英語は、コードまたはデータ内で作成者が指定した名前に対応しています。実際には、読者は必要な単語に置き換えることができます。
次に知っておく必要があるのは、どのディメンションが明らかに「住宅価格」に関連しているかということです。まず、図 8.9 に示すように、散布図を使用してそれを観察します。
rreeee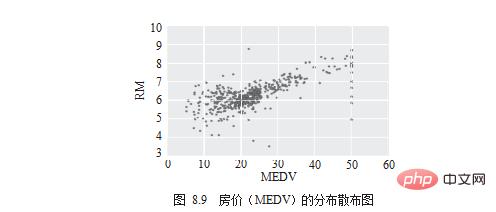
最后,计算相关系数并用聚类热图(Heatmap)来进行视觉呈现,如图 8.10 所示。
# compute pearson correlation corr = df.corr() # drawheatmap import seaborn as sns corr = df.corr() sns.heatmap(corr) plt.show()
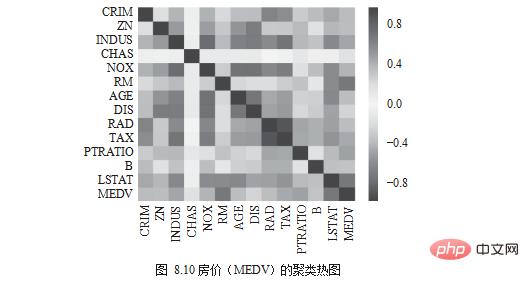
颜色为红色,表示正向关系;颜色为蓝色,表示负向关系;颜色为白色,表示没有关系。RM 与房价关联度偏向红色,为正向关系;LSTAT、PTRATIO 与房价关联度偏向深蓝, 为负向关系;CRIM、RAD、AGE 与房价关联度偏向白色,为没有关系。
声明:本文选自清华大学出版社的《深入浅出python数据分析》一书,略有修改,经出版社授权刊登于此。
以上がPython データ視覚化を学習するための良い例を共有してください。の詳細内容です。詳細については、PHP 中国語 Web サイトの他の関連記事を参照してください。
















![[Web フロントエンド] Node.js クイック スタート](https://img.php.cn/upload/course/000/000/067/662b5d34ba7c0227.png)



