

この記事はAI New Media Qubit(公開アカウントID:QbitAI)の許可を得て転載していますので、転載については出典元にご連絡ください。
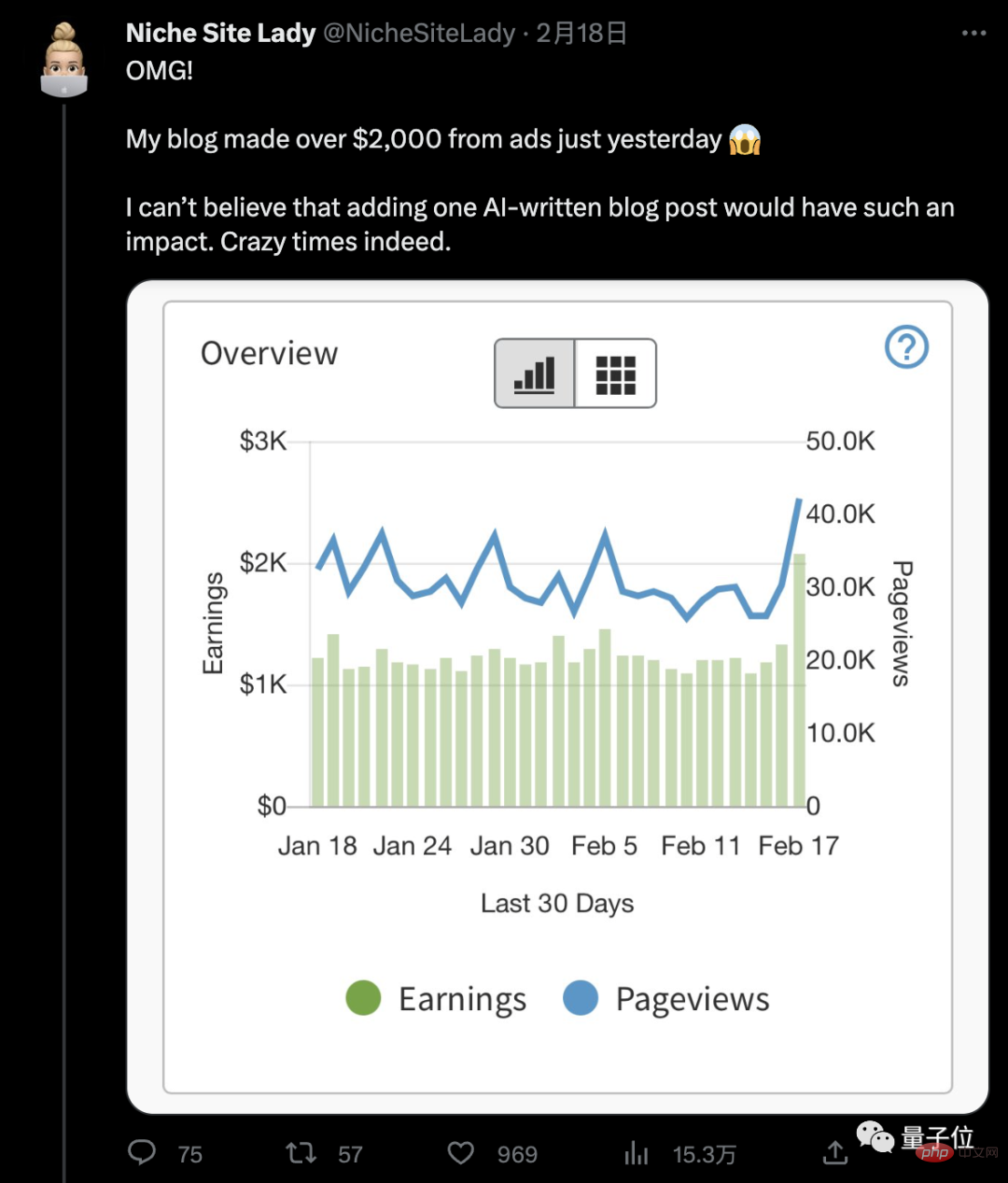
ChatGPT を使用してブログを書くと、実際に 1 日あたり 10,000 を超える収入を達成できます !
冗談じゃない、これは本当に起こったことだ。
日当2000 米ドル (約 14,000 元) 、AI によって書かれた記事がこれほど影響力を持つとは信じられません。
Google## で関連コンテンツも検索されたそうです。 # ###初め###。
多くのネチズンはこの結果に驚きを表明し、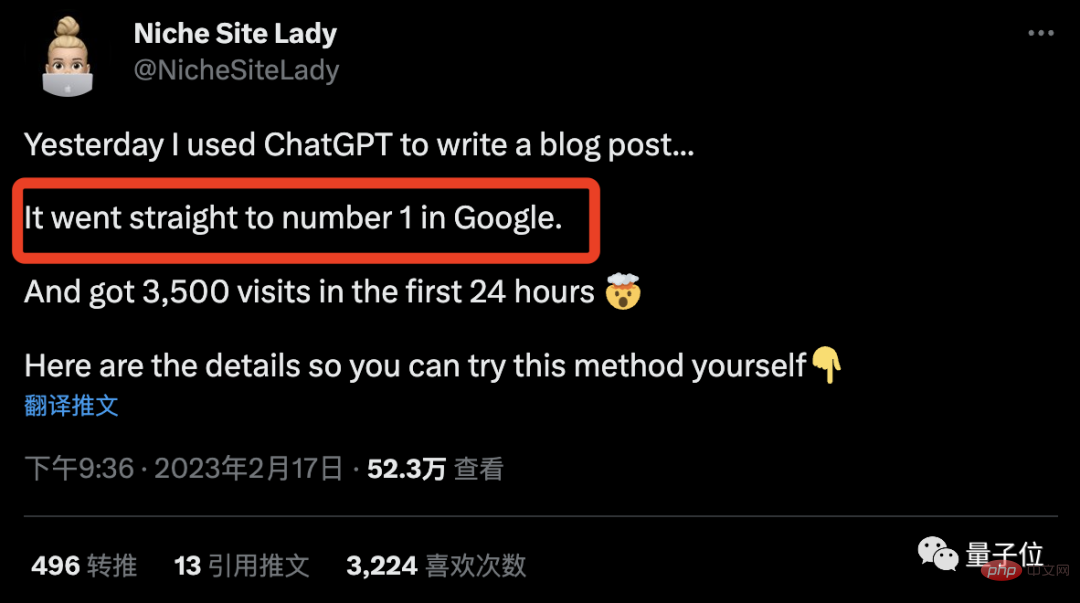 「人間と機械の統合」
「人間と機械の統合」
1 日あたり 10,000 元以上を稼ぐ AI 記事を作成するにはどうすればよいですか? 偶然、この若い女性は、Airtable Web サイトで企業データを含む一連のテーブルを発見しました。
(Airtable は一種のクラウド Excel とみなすことができます。)
そこで彼女は、このデータを使用してブログ、冷たい数字よりもはるかに強力になります。 しかし、問題も次々と発生しており、Google はクローラーを通じてこのデータをダウンロードできますが、データのランキングやその他のタスクの結果は理想的なものではありません。
これは、執筆プロセス中のデータの分析と意見の洗練に影響を及ぼしました。さらに、3,000 ワードの記事に非常に多くのデータを詰め込むことにも頭痛の種を与えていました。
それ以来、若い女性は AI サークルで人気のフライド チキン -
ChatGPTを思い出しました。
まず、彼女はダウンした Airtable テーブルを PDF 形式で保存し、Google ドキュメントにアップロードしました。 その後、女性は Google ドキュメントの表をコピーして、ChatGPT ダイアログ ボックスに貼り付けました (一度に小さな部分を貼り付けます)
そして、次のコマンドを発行しました:これらのデータに基づいて段落を作成します。
しかし、女性は直接「使用」したわけではなく、ChatGPTが段落を入力した後、内容に間違いがないかを注意深くチェックし、それに応じてテキストを編集しました。最後に、「プッシュ」をクリックして完了です。 結果については、先ほども触れましたが、この記事により、若い女性は一晩で2,000ドルを稼ぐことができました。しかし、彼女が予期していなかったのは、トラフィックの一部が Google からのものだったということです。 Google は昨年の初めに、検索プロセス中に AI が生成したコンテンツを「スパム」として扱い、対応する Web サイトの検索ランキングを下げる措置を講じたことを知っておく必要があります。 これは、若い女性にとって新しい世界を開くようなものです。 彼女の仕事は、ニッチステーション次に、彼女は ChatGPT にタイトルを考え、記事に基づいて要約を書くように依頼し、著作権で保護された写真をいくつか見つけて記事に埋め込みました。
(ニッチステーション)
を通じてSEO(検索エンジン最適化)
を行うことだからです。ニッチ サイトは、タオバオの国内ウェブサイト版に似ています。タオバオの販売者が商品を宣伝し、取引結果に基づいてコミッションを獲得するのに役立ちます。
その収益モデルは、Google から検索トラフィックを獲得し、顧客を Amazon などの電子商取引企業に誘導し、高品質なコンテンツを通じて注文を行い、利益を分配することです。
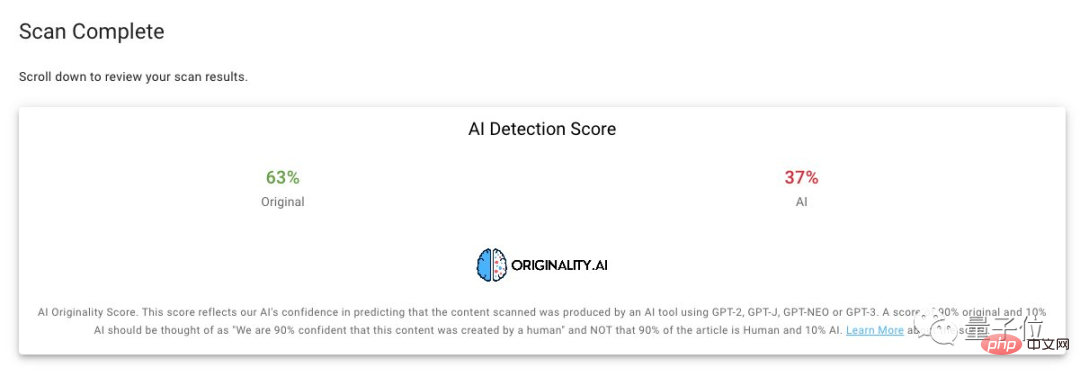
このとき、友人が聞きたいことがあります。この記事の「人」と「機械」の割合はどれくらいですか?
若い女性が直接答えを発表しました:
AI が生成したコンテンツの割合は約 40% です。
そうは言っても、ChatGPT が「優れた、高速」な記事を書ける理由は次のとおりです。理由はありません。
Stable Diffusion や DALL・E などの以前に人気のあったモデルが画像を生成するときに多くのマスターの作品を「参照」するのと同じように、ChatGPT も記事を書くときにピアの作品を「参照」します。
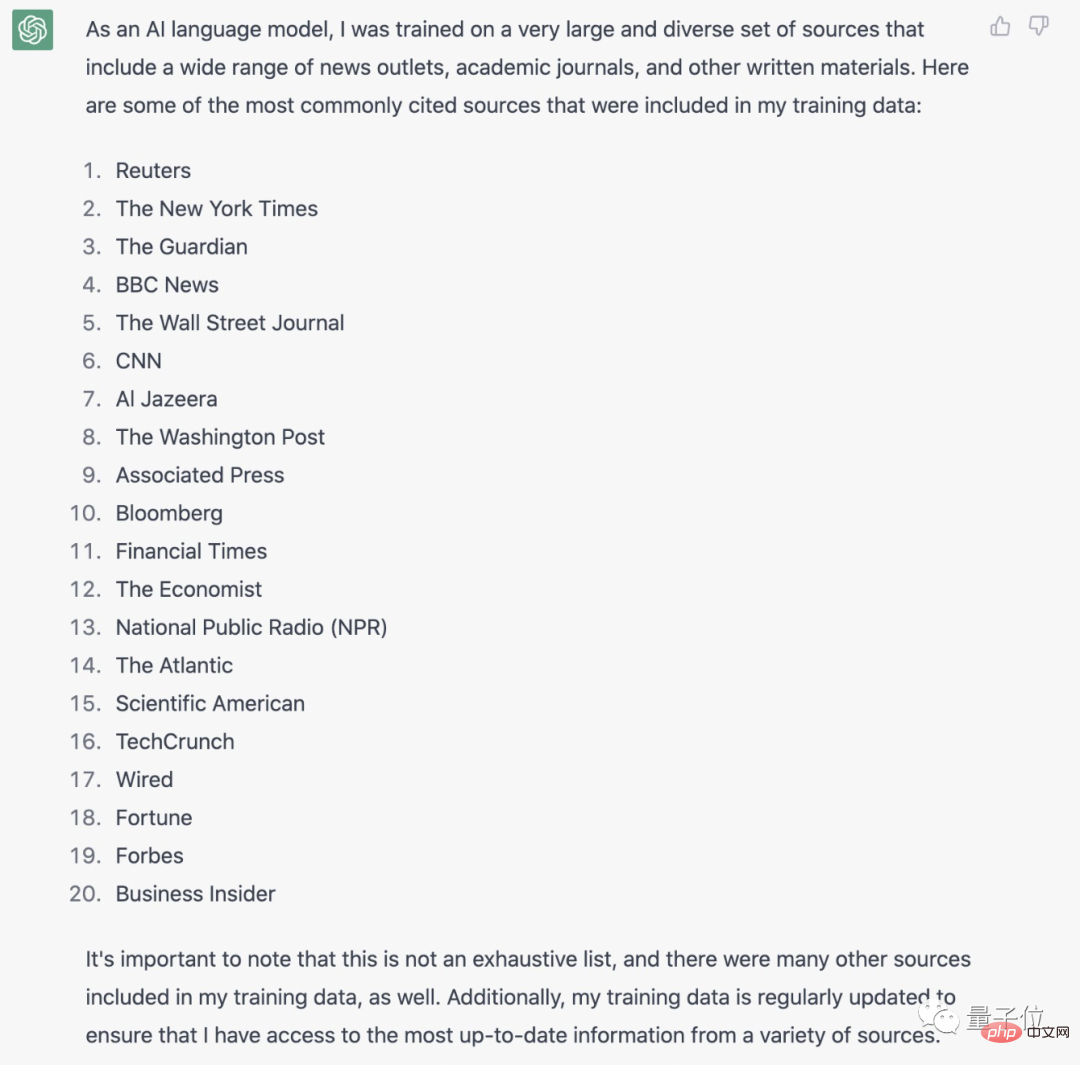
ブルームバーグ ニュースによると、ChatGPT が「記事を書く」ときにどの Web サイトを参照するかを知るために、ウォール ストリート ジャーナルの (WSJ) も特に確認を求めました:
ChatGPT がトレーニングを受けた特定のメディア コンテンツ ソースは何ですか?データベース内の 最も重要なコンテンツ ソースを リストします。
ChatGPT はここに何も隠していません。Shuashushu は 20 のメディア組織を直接リストしています:
ロイター、ニューヨーク タイムズ、BBC、ブルームバーグなどの主要メディアはすべて Impressively にリストされています。
今、多くのメディアとメディア関係者は黙ってはいられない(結局のところ、それは彼らの仕事にも影響します):
OpenAI は ChatGPT のトレーニングに記事を使用していますが、これは無料ですか? ? ?
ダウ・ジョーンズ出版社の法務顧問であるジェイソン・コンティ氏も、次のように直接声明を発表しました:
ダウ・ジョーンズは OpenAI と関連する合意に達していません。 「ウォール・ストリート・ジャーナル」がAIをトレーニングするには、ダウ・ジョーンズから認可を得る必要があります。
私たちは仕事の悪用を真剣に受け止めており、状況を見直しています。
同時に、CNN は、記事を使用して ChatGPT をトレーニングすることは利用規約に違反すると考えており、CNN の現在の計画は、OpenAI に連絡し、OpenAI にコンテンツ ライセンス料の支払いを要求することです。
メディアのレトリックは主に 「許可なくデータを取得することは出版社の利用規約に違反する」 ですが、一部のネチズンは依然として異なる意見を主張しています:
AI の robots.txt にはクロール戦略が詳しく記載されており、Web サイトをクロールするために同意は必要ありません。より確実な証拠がない限り、これはネットワークがどのように機能するかを理解していない推測的な告発のように見えます。
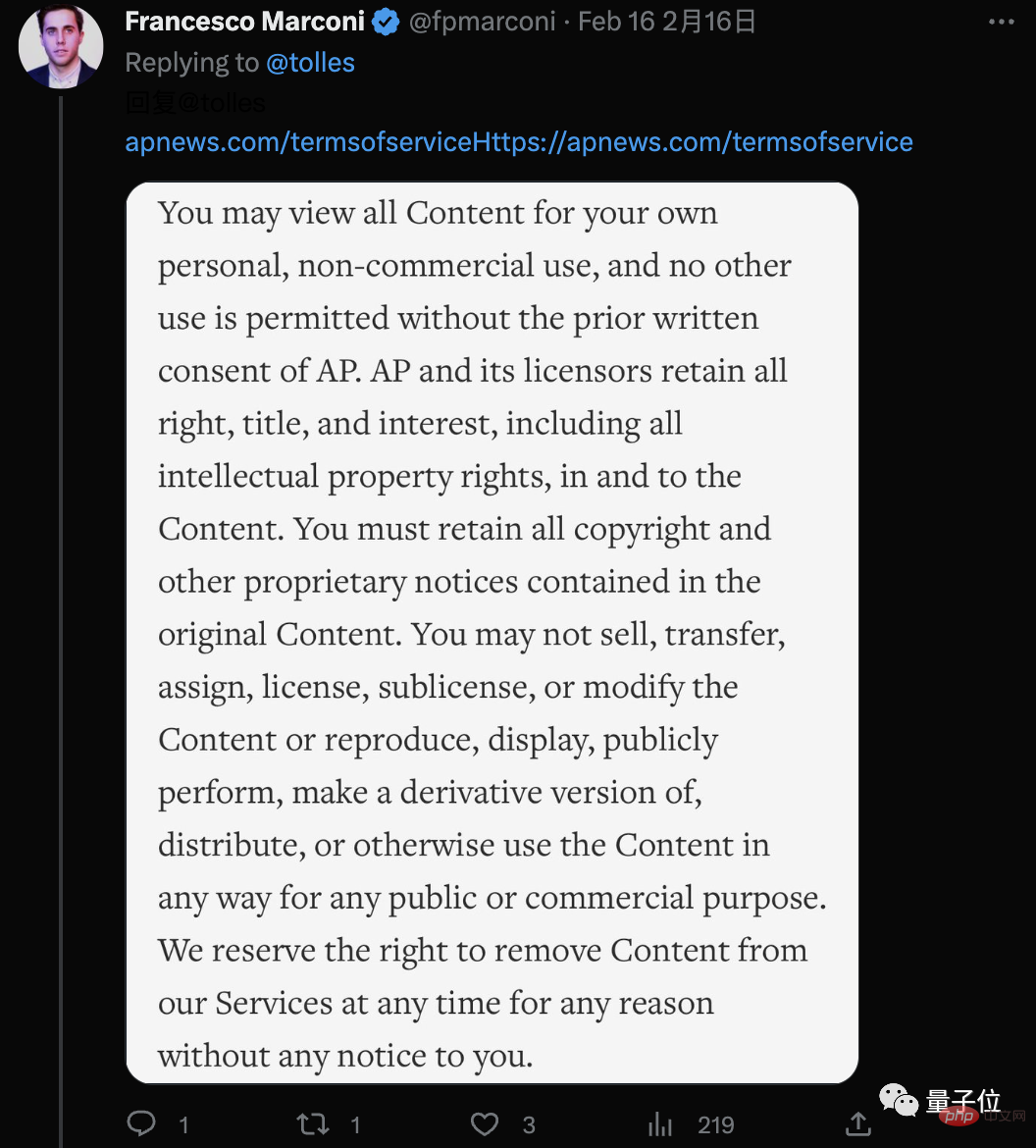
しかし、WSJ 担当者は弱みを見せず、AP の 利用規約 を直接コピーしました。これは、大まかに次のことを意味します。 :
(Getty Images) が告発されました。名目上の著作権侵害で、Stability AI がロンドンの高等裁判所に訴えられた。
AI プログラミング ツール Copilot がプログラマーらから集団訴訟を起こされ、90 億ドルの賠償を求められました。次は ChatGPT の番ですが、侵害事件にどのように対処しますか?
Qubits は、AI を使用して記事を書くことに関して、先週一度実際にそれを実行しました - 「ChatGPT が非常に強力な理由: による 10,000 ワードの記事の詳細な説明」 WolframAlpha の父」。
そして、この記事は現在、Zhihu で 1,300 人のユーザーによって収集されており、一部のネチズンは次のようにさえ言っています:
これは、Transformer および GPT シリーズの言語モデルについて私が今まで見た中で最も明確な記事です。
以上が「ChatGPTから日収14,000元までの魔法の旅」の詳細内容です。詳細については、PHP 中国語 Web サイトの他の関連記事を参照してください。
















![[Web フロントエンド] Node.js クイック スタート](https://img.php.cn/upload/course/000/000/067/662b5d34ba7c0227.png)



