

「安定拡散技術を利用した画像再現、関連研究がCVPRカンファレンスに採択されました」

人工知能があなたの想像力を読み取って、心の中のイメージを現実に変えることができたらどうなるでしょうか?

# これは少しサイバーパンクのように聞こえますが。しかし、最近発表された論文がAI界に波紋を引き起こした。
この論文では、最近非常に人気のある安定拡散を使用して、高解像度の脳活動を高効率で再構築していることがわかりました。高精度な画像。著者らは、これまでの研究とは異なり、これらの画像を作成するために人工知能モデルをトレーニングしたり微調整したりする必要はなかったと書いている。

- 紙のアドレス: https://www 。 biorxiv.org/content/10.1101/2022.11.18.517004v2.full.pdf
- ウェブページのアドレス: https://sites.google.com/view/stablediffusion -with-brain/
この研究では、著者らは安定拡散を使用して、機能的磁気共鳴画像法 (fMRI) によって取得された人間の脳活動の画像を再構成しました。著者はまた、脳関連機能のさまざまな要素(画像 Z の潜在ベクトルなど)を研究することによって、潜在拡散モデルのメカニズムを理解することも役立つと述べました。
この論文は CVPR 2023 にも採択されました。
この研究の主な貢献は次のとおりです:
- シンプルなフレームワークが脳活動から高い意味忠実度でデータを生成できることを実証する以下の図に示すように、特定のコンポーネントをさまざまな脳領域に対応するため、この研究では、神経科学の観点から LDM の各コンポーネントを定量的に説明します。
- この研究では、LDM によって実装されるテキストから画像への変換プロセスが、条件付きテキスト表現のセマンティックをどのように組み合わせるかについて客観的に説明します。元の画像の外観を維持しながら情報を保存します。
- 方法論の概要
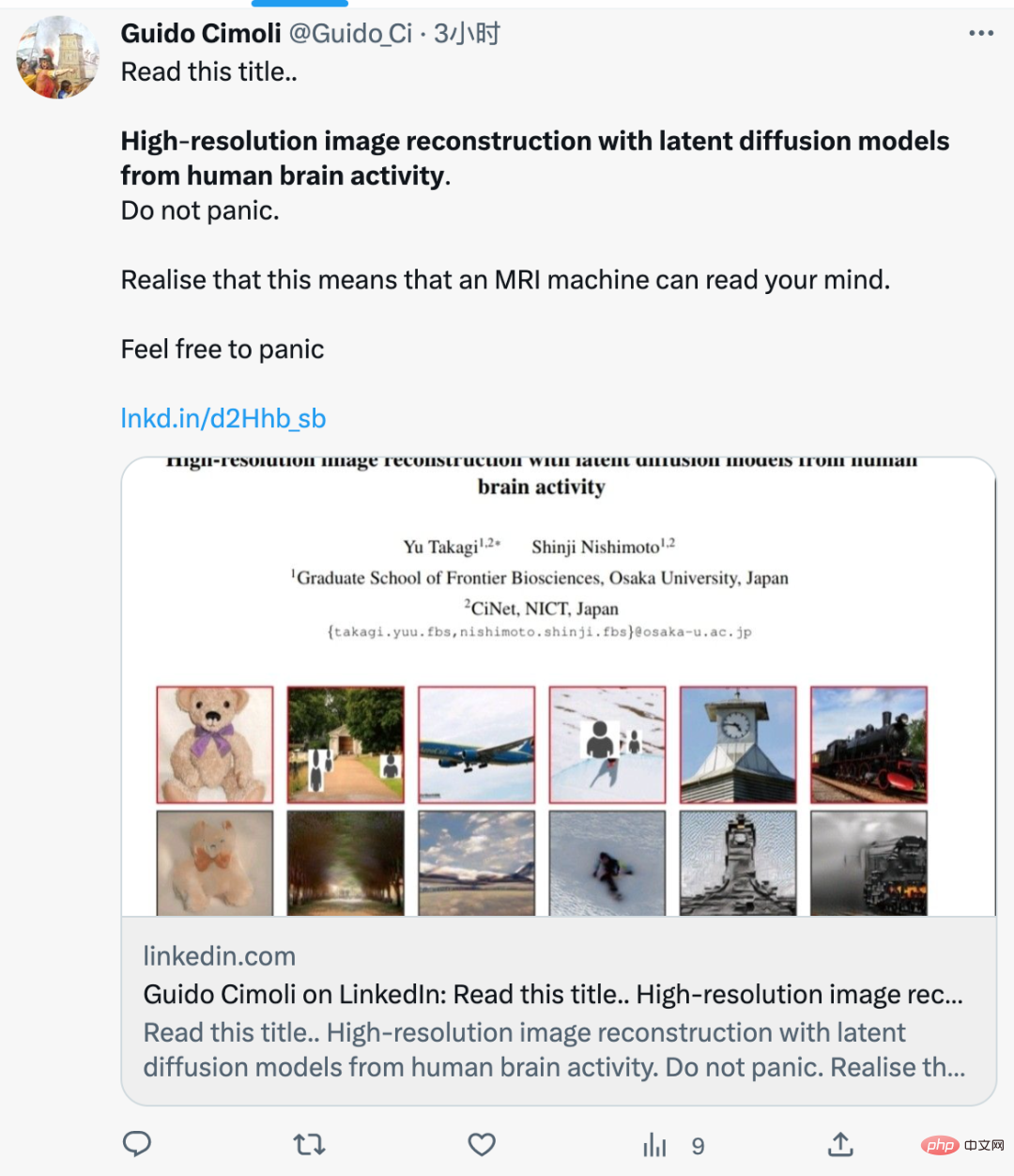
- この研究の全体的な方法論を以下の図 2 に示します。図 2 (上) は、この研究で使用した LDM の概略図です。ε は画像エンコーダ、D は画像デコーダ、τ はテキスト エンコーダ (CLIP) を表します。
図 2 (下) は、この研究のコーディング分析の概略図です。 z、c、z_c などの LDM のさまざまなコンポーネントからの fMRI 信号を予測するためのエンコード モデルを構築しました。
#安定拡散については多くの人がよく知っていると思いますので、ここではあまり紹介しません。
 結果
結果
この研究の視覚的再構成結果を見てみましょう。
デコード
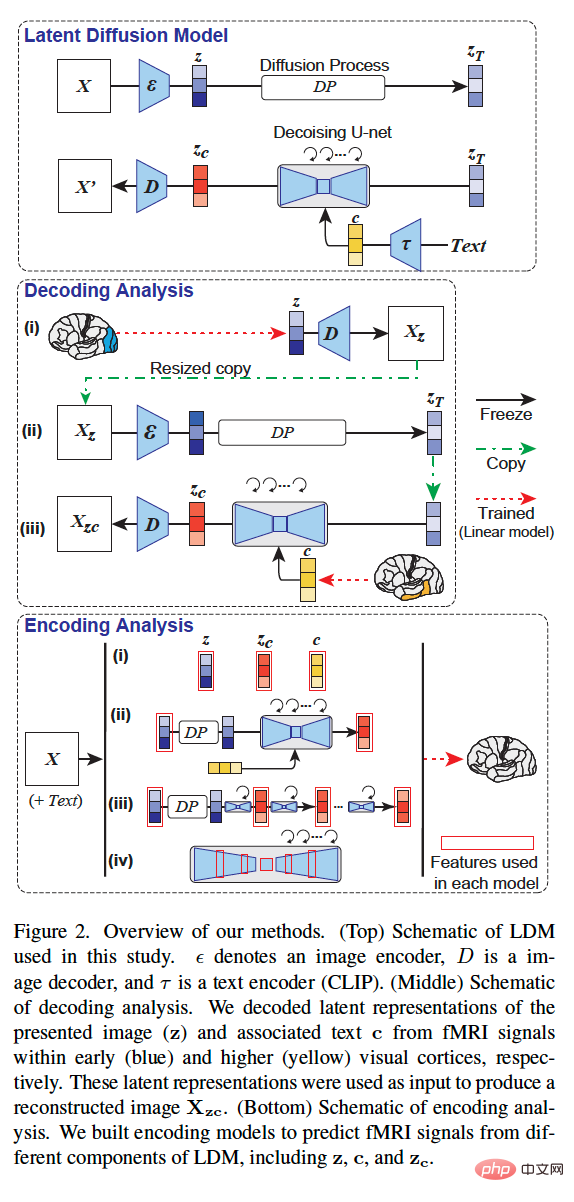
下の図 3 は、被験者 (subj01) の視覚的再構成結果を示しています。各テスト画像に対して 5 つの画像を生成し、PSM が最も高い画像を選択しました。一方で、z のみを使用して再構成された画像は、元の画像と視覚的に一致しますが、その意味的な内容を捉えることができません。一方、c のみを使用して再構成された画像は、意味論的忠実度が高い画像を生成しますが、視覚的には一貫性がありません。最後に、z_c 再構成イメージを使用すると、セマンティック忠実度の高い高解像度イメージを生成できます。

# 図 4 は、すべてのテスターによる同じ画像の再構成を示しています (すべての画像は z_c で生成されました)。全体として、テスター全体の再構成品質は安定していて正確でした。

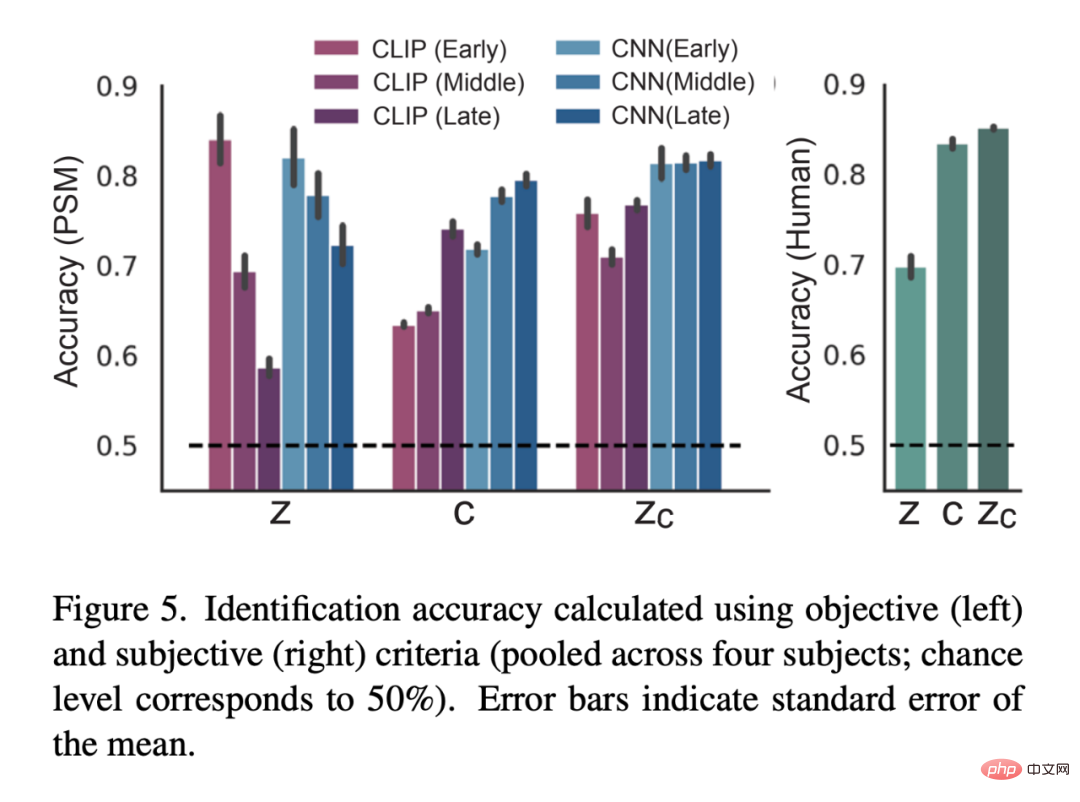
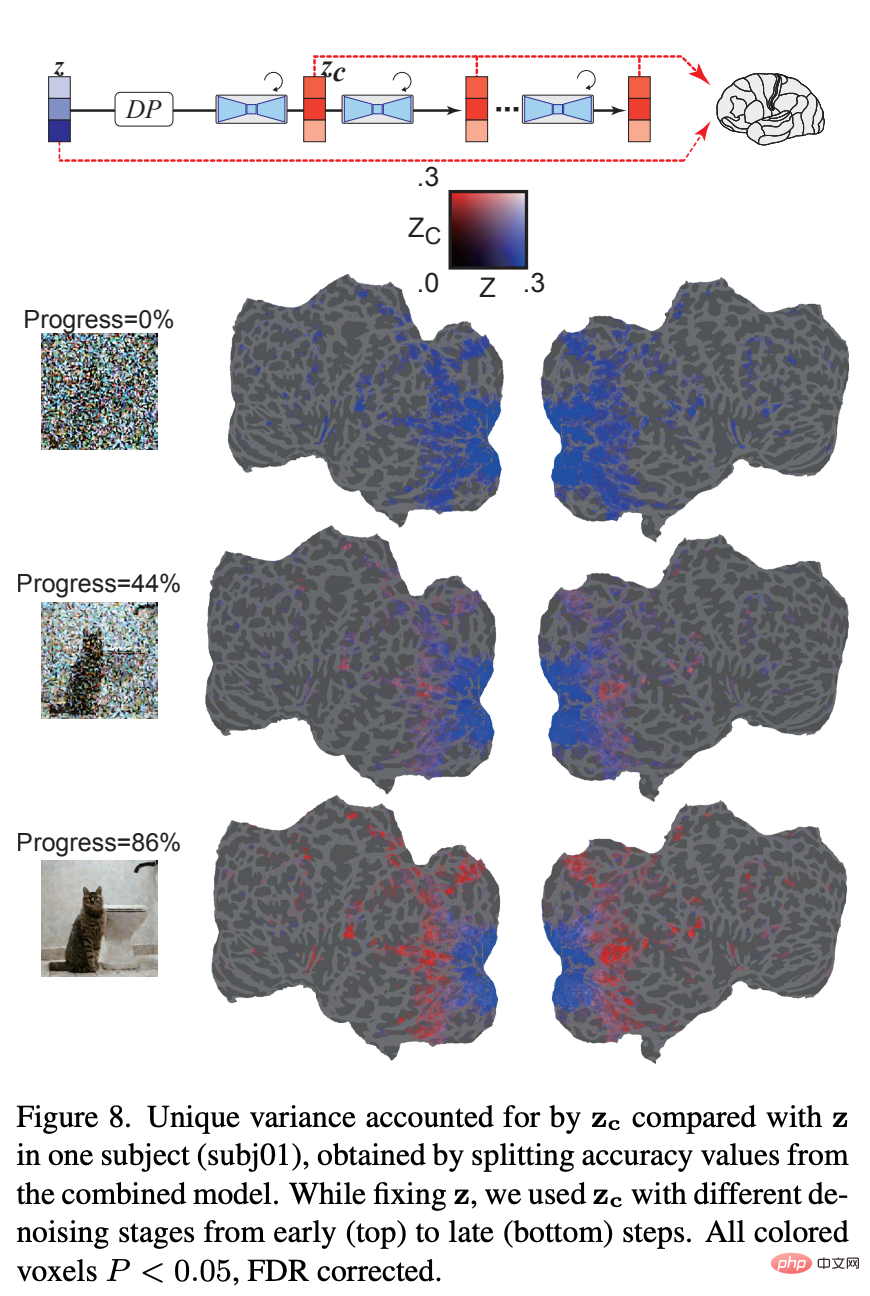
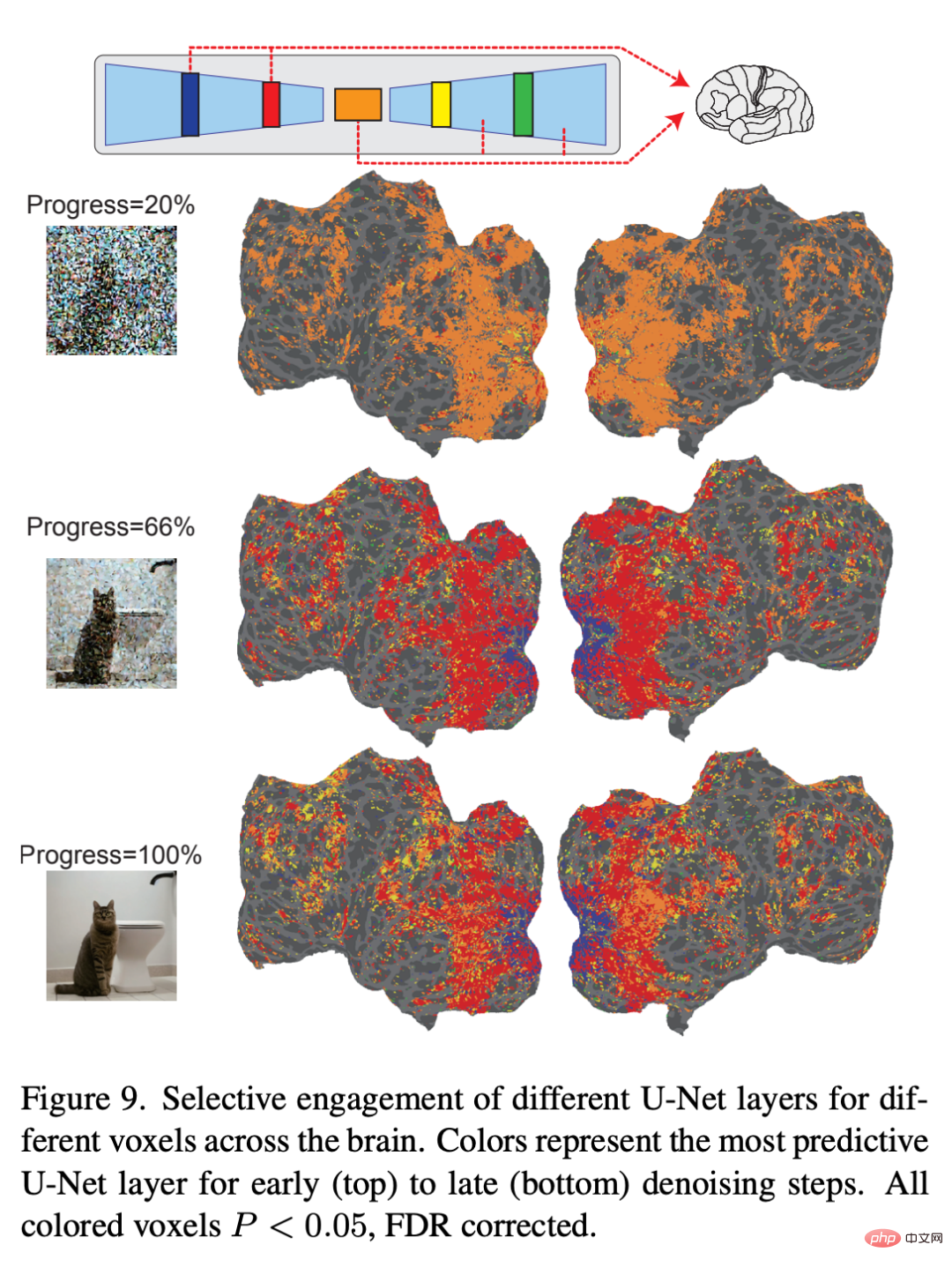
コーディング モデル ## 図 6 は、LDM に関連するコーディング モデルのペアを示しています。 3 つの潜在画像の予測精度: z、元の画像の潜在画像、c、画像テキスト注釈の潜在画像、および z_c、c によるクロスアテンション逆拡散プロセス後の z のノイズを含む潜在画像表現。
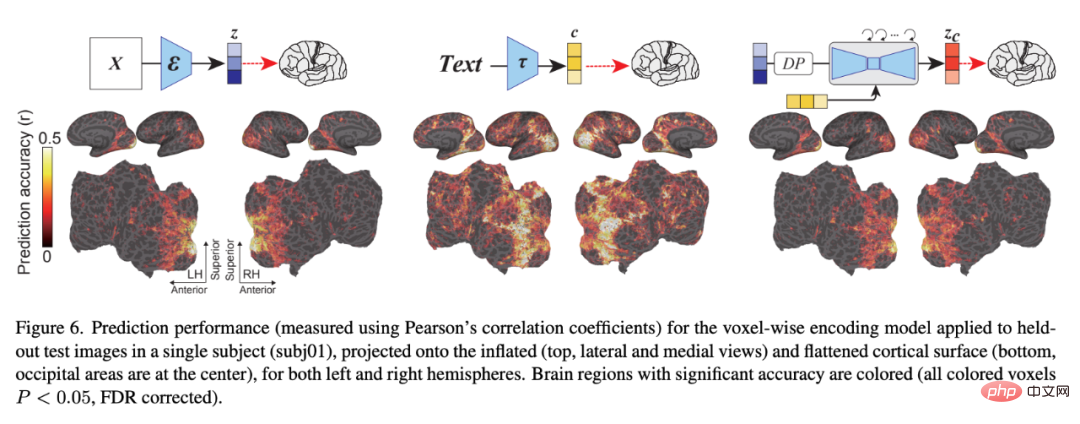 図 7 は、少量のノイズが追加された場合に、z が z_c よりも皮質全体のボクセル活動をより正確に予測することを示しています。興味深いことに、ノイズ レベルを増加すると、z_c は高視覚野のボクセル活動を z よりも正確に予測し、画像の意味内容が徐々に強調されることを示します。
図 7 は、少量のノイズが追加された場合に、z が z_c よりも皮質全体のボクセル活動をより正確に予測することを示しています。興味深いことに、ノイズ レベルを増加すると、z_c は高視覚野のボクセル活動を z よりも正確に予測し、画像の意味内容が徐々に強調されることを示します。

 研究の詳細については、元の論文をご覧ください。
研究の詳細については、元の論文をご覧ください。
以上が「安定拡散技術を利用した画像再現、関連研究がCVPRカンファレンスに採択されました」の詳細内容です。詳細については、PHP 中国語 Web サイトの他の関連記事を参照してください。

ホットAIツール

Undresser.AI Undress
リアルなヌード写真を作成する AI 搭載アプリ

AI Clothes Remover
写真から衣服を削除するオンライン AI ツール。

Undress AI Tool
脱衣画像を無料で

Clothoff.io
AI衣類リムーバー

AI Hentai Generator
AIヘンタイを無料で生成します。

人気の記事
ホットツール

メモ帳++7.3.1
使いやすく無料のコードエディター

SublimeText3 中国語版
中国語版、とても使いやすい

ゼンドスタジオ 13.0.1
強力な PHP 統合開発環境

ドリームウィーバー CS6
ビジュアル Web 開発ツール

SublimeText3 Mac版
神レベルのコード編集ソフト(SublimeText3)
ホットトピック
 7469
7469
 15
1376
52
77
11
19
29
15
1376
52
77
11
19
29

 Windows スポットライトの壁紙画像を PC にダウンロードする方法
Aug 23, 2023 pm 02:06 PM
Windows スポットライトの壁紙画像を PC にダウンロードする方法
Aug 23, 2023 pm 02:06 PM
窓は決して美観を無視するものではありません。 XP の牧歌的な緑の野原から Windows 11 の青い渦巻くデザインに至るまで、デフォルトのデスクトップの壁紙は長年にわたってユーザーの喜びの源でした。 Windows スポットライトを使用すると、ロック画面やデスクトップの壁紙に使用する美しく荘厳な画像に毎日直接アクセスできるようになります。残念ながら、これらの画像は表示されません。 Windows スポットライト画像の 1 つが気に入った場合は、その画像をダウンロードして、しばらく背景として保存できるようにする方法を知りたいと思うでしょう。知っておくべきことはすべてここにあります。 Windowsスポットライトとは何ですか? Window Spotlight は、設定アプリの [個人設定] > から利用できる自動壁紙アップデーターです。
 モデル、データ、フレームワークの詳細: 効率的な大規模言語モデルの 54 ページにわたる徹底的なレビュー
Jan 14, 2024 pm 07:48 PM
モデル、データ、フレームワークの詳細: 効率的な大規模言語モデルの 54 ページにわたる徹底的なレビュー
Jan 14, 2024 pm 07:48 PM
大規模言語モデル (LLM) は、自然言語理解、言語生成、複雑な推論などの多くの重要なタスクにおいて説得力のある能力を実証し、社会に大きな影響を与えてきました。ただし、これらの優れた機能には、大量のトレーニング リソース (左の図に示す) と長い推論時間 (右の図に示す) が必要です。したがって、研究者は効率の問題を解決するための効果的な技術的手段を開発する必要があります。さらに、図の右側からわかるように、Mistral-7B などのいくつかの効率的な LLM (LanguageModel) が、LLM の設計と展開にうまく使用されています。これらの効率的な LLM は、LLaMA1-33B と同様の精度を維持しながら、推論メモリを大幅に削減できます。
 Python で画像セマンティック セグメンテーション テクノロジを使用するにはどうすればよいですか?
Jun 06, 2023 am 08:03 AM
Python で画像セマンティック セグメンテーション テクノロジを使用するにはどうすればよいですか?
Jun 06, 2023 am 08:03 AM
人工知能技術の継続的な発展に伴い、画像セマンティックセグメンテーション技術は画像分析分野で人気の研究方向となっています。画像セマンティック セグメンテーションでは、画像内のさまざまな領域をセグメント化し、各領域を分類して、画像の包括的な理解を実現します。 Python はよく知られたプログラミング言語であり、その強力なデータ分析機能とデータ視覚化機能により、人工知能技術研究の分野で最初に選択されます。この記事では、Python で画像セマンティック セグメンテーション技術を使用する方法を紹介します。 1. 前提知識が深まる
 H100 を粉砕、Nvidia の次世代 GPU が明らかに!最初の 3nm マルチチップ モジュール設計、2024 年に発表
Sep 30, 2023 pm 12:49 PM
H100 を粉砕、Nvidia の次世代 GPU が明らかに!最初の 3nm マルチチップ モジュール設計、2024 年に発表
Sep 30, 2023 pm 12:49 PM
3nmプロセス、H100を超える性能!最近、海外メディア DigiTimes が、Nvidia が人工知能 (AI) およびハイパフォーマンス コンピューティング (HPC) アプリケーション向けの製品として、コードネーム「Blackwell」という次世代 GPU である B100 を開発しているというニュースを伝えました。 , B100はTSMCの3nmプロセスと、より複雑なマルチチップモジュール(MCM)設計を採用し、2024年の第4四半期に登場する予定だ。人工知能 GPU 市場の 80% 以上を独占している Nvidia にとって、B100 を使用して鉄は熱いうちに攻撃し、この AI 導入の波において AMD や Intel などの挑戦者をさらに攻撃することができます。 NVIDIA の推定によると、2027 年までに、この分野の生産額は約
 マルチモーダル大型モデルの最も包括的なレビューがここにあります。 7 人のマイクロソフト研究者が精力的に協力、5 つの主要テーマ、119 ページの文書
Sep 25, 2023 pm 04:49 PM
マルチモーダル大型モデルの最も包括的なレビューがここにあります。 7 人のマイクロソフト研究者が精力的に協力、5 つの主要テーマ、119 ページの文書
Sep 25, 2023 pm 04:49 PM
マルチモーダル大型モデルの最も包括的なレビューがここにあります。マイクロソフトの中国人研究者7名が執筆した119ページで、すでに完成し、現在も最前線にある2種類のマルチモーダル大規模モデル研究の方向性から始まり、視覚理解と視覚生成という5つの具体的な研究テーマを包括的にまとめている。統合ビジュアル モデル LLM によってサポートされるマルチモーダル大規模モデル マルチモーダル エージェントは、マルチモーダル基本モデルが特殊なモデルから汎用的なモデルに移行したという現象に焦点を当てています。 Ps. 著者が論文の冒頭に直接ドラえもんの絵を描いたのはこのためである。このレビュー (レポート) は誰が読むべきですか? Microsoft の原文では次のようになります。プロの研究者でも学生でも、マルチモーダル基本モデルの基礎知識と最新の進歩を学ぶことに興味がある限り、このコンテンツは参加するのに非常に適しています。
 iOS 17: 写真でワンクリックトリミングを使用する方法
Sep 20, 2023 pm 08:45 PM
iOS 17: 写真でワンクリックトリミングを使用する方法
Sep 20, 2023 pm 08:45 PM
iOS 17 の写真アプリを使用すると、Apple は写真を仕様に合わせて簡単にトリミングできるようになります。その方法については、読み続けてください。以前の iOS 16 では、写真アプリで画像をトリミングするにはいくつかの手順が必要でした。編集インターフェイスをタップし、トリミング ツールを選択し、ピンチでズームするジェスチャまたはトリミング ツールの角をドラッグしてトリミングを調整します。 iOS 17 では、Apple がありがたいことにこのプロセスを簡素化し、写真ライブラリで選択した写真を拡大すると、画面の右上隅に新しい切り抜きボタンが自動的に表示されるようになりました。クリックすると、選択したズームレベルで完全なトリミングインターフェイスが表示されるので、画像の好きな部分をトリミングしたり、画像を回転したり、画像を反転したり、画面比率を適用したり、マーカーを使用したりできます。
 Windows で PowerToys を使用して画像のサイズを一括変更する方法
Aug 23, 2023 pm 07:49 PM
Windows で PowerToys を使用して画像のサイズを一括変更する方法
Aug 23, 2023 pm 07:49 PM
日常的に画像ファイルを扱う必要がある人は、プロジェクトや仕事のニーズに合わせて画像ファイルのサイズを変更する必要があることがよくあります。ただし、処理する画像が多すぎる場合、画像を個別にサイズ変更すると、多くの時間と労力がかかる可能性があります。この場合、PowerToys のようなツールは、画像サイズ変更ユーティリティを使用して画像ファイルのサイズをバッチで変更するのに役立ちます。 Image Resizer 設定をセットアップし、PowerToys を使用して画像のバッチ サイズ変更を開始する方法は次のとおりです。 PowerToys を使用して画像のサイズをバッチ変更する方法 PowerToys は、日常業務のスピードアップに役立つさまざまなユーティリティと機能を備えたオールインワン プログラムです。そのユーティリティの 1 つは画像です
 SD コミュニティの I2V アダプター: 設定不要、プラグアンドプレイ、Tusheng ビデオ プラグインと完全に互換性あり
Jan 15, 2024 pm 07:48 PM
SD コミュニティの I2V アダプター: 設定不要、プラグアンドプレイ、Tusheng ビデオ プラグインと完全に互換性あり
Jan 15, 2024 pm 07:48 PM
画像からビデオへの生成 (I2V) タスクは、静止画像を動的なビデオに変換することを目的としたコンピューター ビジョンの分野における課題です。このタスクの難しさは、画像コンテンツの信頼性と視覚的な一貫性を維持しながら、単一の画像から時間次元で動的な情報を抽出して生成することです。既存の I2V 手法では、多くの場合、この目標を達成するために複雑なモデル アーキテクチャと大量のトレーニング データが必要になります。最近、Kuaishou が主導した新しい研究成果「I2V-Adapter: AGeneralImage-to-VideoAdapter for VideoDiffusionModels」が発表されました。この研究では、革新的な画像からビデオへの変換方法を導入し、軽量のアダプター モジュールを提案します。
