
 テクノロジー周辺機器
AI
ディープラーニングの巨人DeepMindは、GPT-5によって引き起こされる可能性のある人類絶滅の問題を相殺するために、AIモデルに「人間になる」よう緊急に教えるという論文を発表した。
テクノロジー周辺機器
AI
ディープラーニングの巨人DeepMindは、GPT-5によって引き起こされる可能性のある人類絶滅の問題を相殺するために、AIモデルに「人間になる」よう緊急に教えるという論文を発表した。
ディープラーニングの巨人DeepMindは、GPT-5によって引き起こされる可能性のある人類絶滅の問題を相殺するために、AIモデルに「人間になる」よう緊急に教えるという論文を発表した。

GPT-4 の出現は、世界中の AI 業界の大物たちを恐怖に陥れました。 GPT-5トレーニングの中止を求める公開書簡には、すでに5万人が署名している。
OpenAI CEO のサム アルトマン氏は、数年以内に、それぞれが独自のインテリジェンスと機能を備え、さまざまなルールに準拠する多数の異なる AI モデルが世界中に普及するだろうと予測しています。規制、倫理規定。

これらの AI の 1,000 個に 1 個だけが何らかの理由で不正に陥った場合、私たち人間は間違いなくそうなります。まな板の上の魚。
私たちが AI によって誤って破壊されるのを防ぐために、DeepMind は 4 月 24 日に米国科学アカデミー紀要 (PNAS) に掲載された論文でその答えを示しました。 AI に振る舞い方を教える政治哲学者ロールズの視点。
論文アドレス: https://www.pnas.org/doi/10.1073/pnas.2213709120
教え方AIは人間でしょうか?
選択を迫られたとき、AI は生産性の向上を優先することを選択するでしょうか、それとも最も助けを必要としている人々を助けることを選択するのでしょうか?
AI の価値を形作ることは非常に重要です。それには値を与える必要があります。
しかし、難しいのは、私たち人間は内面的に統一された価値観を持つことができないということです。この世界の人々はそれぞれ異なる背景、リソース、信念を持っています。
それを打破するにはどうすればよいでしょうか? Googleの研究者は哲学からインスピレーションを得ています。
政治哲学者ジョン ロールズはかつて、グループの意思決定を目的とした思考実験である「無知のベール」(VoI) という概念を提案しました。範囲。

一般的に、人間の本性は利己的ですが、AI に「無知のベール」が適用されると、しかし、彼らは、それが自分たちに直接利益をもたらすかどうかに関係なく、公平性を優先します。
そして、「無知のベール」の背後で、最も恵まれない人々を助ける AI を選択する可能性が高くなります。
これにより、すべての関係者にとって公平な方法で AI に価値を与える方法がわかります。
それでは、「無知のベール」とは一体何なのでしょうか?
AI にどのような価値を与えるべきかという難しい問題は過去 10 年間に浮上しましたが、公正な意思決定をどのように行うかという問題には長い歴史があります。
この問題を解決するために、1970年に政治哲学者ジョン・ロールズは「無知のベール」という概念を提案しました。

無知のベール (右) は、社内で異なる意見があるときに発生する行動の一種です。グループ(左) 意思決定において合意に達する方法
ロールズは、人々が社会のための正義の原則を選択するとき、その前提は彼らが知らないことであるべきであると信じています彼らはこの社会のどこにいるのか。
この情報がなければ、人々は利己的な方法で意思決定を行うことができず、誰にとっても公平な方法でのみ意思決定を行うことができます。
たとえば、誕生日パーティーでケーキをカットするとき、どのピースが手に入るかわからない場合、各ピースを同じ大きさにしようとします。
この情報隠蔽方法は心理学や政治学の分野で広く使用されており、量刑から課税まで人々が集団合意に達することを可能にしています。
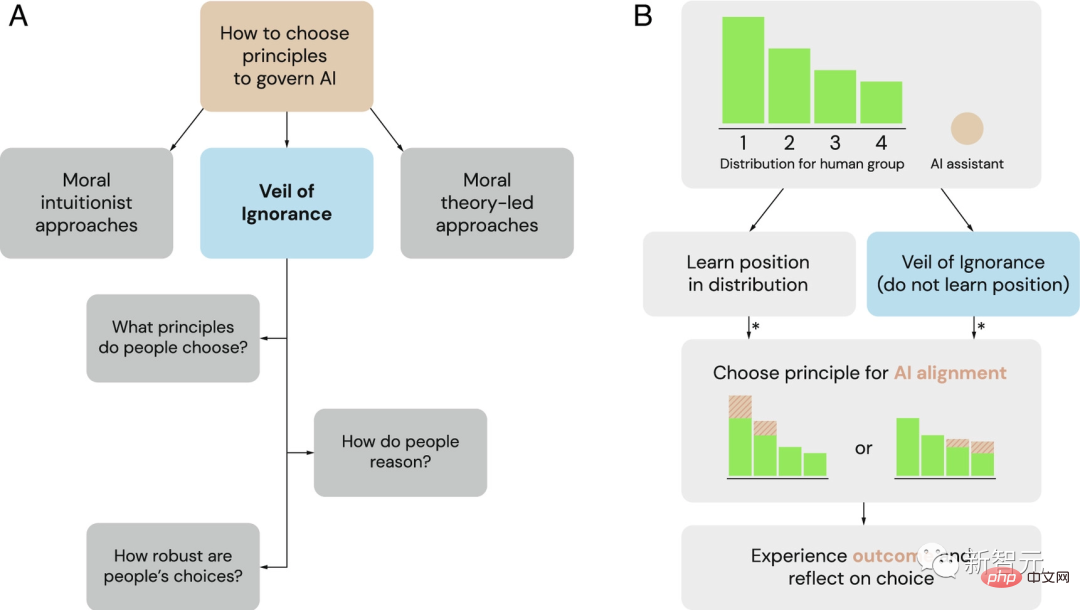
AI システムのガバナンス原則を選択するための潜在的なフレームワークとしての無知のベール (VoI)
(A ) AS 研究者たちは、道徳直観主義者と道徳理論の支配的な枠組みに代わるものとして、AI ガバナンスの原則を選択するための公正なプロセスとして無知のベールを探求しています。
(B) 無知のベールは、割り当て状況における AI 調整の原則を選択するために使用できます。グループがリソース割り当ての問題に直面したとき、個人はさまざまな立場の優位性を持っています (ここでは 1 から 4 とラベル付けされています)。無知のベールの背後で、意思決定者は自分の立場を知らずに原則を選択します。選択されると、AI アシスタントはこの原則を実装し、それに応じてリソースの割り当てを調整します。アスタリスク (*) は、公平性に基づいた推論が判断や意思決定に影響を与える可能性がある場合を示します。
したがって、DeepMind は以前、「無知のベール」が AI システムを人間の価値観と調整するプロセスにおける公平性を促進するのに役立つ可能性があると提案しました。
Google の研究者は、この効果を確認するために一連の実験を計画しました。
AI は誰が木の伐採を支援するのでしょうか?
このような収穫ゲームがインターネット上にあり、参加者は 3 人のコンピューター プレイヤーと協力して、それぞれの畑で木を伐採し、木材を節約する必要があります。
4 人のプレーヤー (コンピューター 3 人と実際の人間 1 人) の中には、幸運にも木々の多い一等地が割り当てられた人もいます。土地がなく、建物を建てる木もなく、木材の蓄積が遅れている、より悲惨な地域もあります。
さらに、支援する AI システムがあり、特定の参加者が木を切り倒すのを支援するのに時間がかかる場合があります。
研究者らは人間のプレイヤーに、AI システムが実装する 2 つの原則、つまり最大化原則と優先度原則のうち 1 つを選択するように依頼しました。
最大化の原則のもと、AI は強い者だけを助けます。より多くの木を持っている人は、できるところまで行き、より多くの木を伐採しようと努めます。優先の原則に基づき、AIは弱い者のみを助け、木や障害物が少ない人々を助ける「貧困緩和」を目標としている。

写真の中の小さな赤い男は人間のプレイヤー、小さな青い男はAIアシスタント、小さな緑の木…それらは小さな緑の木であり、小さな木の杭は切り刻まれた木です。
ご覧のとおり、上の写真の AI は最大化原理を実装し、最も木が多いエリアに突入します。
研究者らは、参加者の半数を「無知のベール」にさらしました。このときの状況は、まず AI アシスタントの「原理」を選択する必要があるということでした (を最大化または優先順位付けして)、土地を分割します。
つまり、土地を分割する前に、AIに強い人を助けるか弱い人を助けるかを決める必要があります。

参加者の残りの半分は、この問題に直面することはありません。彼らは、選択を行う前に自分が割り当てられていることを知っています。 . どの土地か。
結果は、参加者がどの土地が割り当てられるのかを事前に知らなかった場合、つまり「無知のベール」の背後にいた場合、参加者は次のような傾向があることを示しています。優先原則を選択します。
これは、木の伐採ゲームにだけ当てはまるわけではありません。研究者らは、この結論は、このゲームの 5 つの異なるバリエーションにわたって当てはまり、さらには社会的および政治的境界を越えると述べています。
言い換えれば、参加者の性格や政治的志向に関係なく、参加者は優先原則を選択することが多くなります。
逆に、「無知のベール」の背後にいない参加者は、最大化原則であれ優先原則であれ、自分たちにとって有益な原則をより多く選択します。

上の図は、選択優先原則に対する「無知のベール」の影響を示しています。自分がどこにいるかわからない参加者は、AI の動作を管理するためにこの原則を支持する可能性が高くなります。
研究者らが参加者にその選択をした理由を尋ねると、「無知のベール」の背後にある参加者は公平性について懸念を表明した。
彼らは、AI はグループ内でそれほど恵まれていない人々にもっと役立つべきであると説明しました。
対照的に、自分の立場をよりよく理解している参加者は、自己利益の観点から選択することが多かった。
最後に、薪割りゲームが終了した後、研究者たちは参加者全員に仮説を立てました。もしもう一度プレイすることが許されたら、今度は自分たちが割り当てられることを全員が知っているでしょう。彼らは最初と同じ原則でどの土地を選択するでしょうか?
研究者たちは、最初のゲームでの選択から利益を得た人々に主に焦点を当てました。新しいラウンドでは、この有利な状況が再び得られなくなる可能性があるためです。
研究チームは、ゲームの最初のラウンドで「無知のベール」の背後にいた参加者は、たとえ自分が選択するだろうとわかっていたとしても、最初の選択を維持する可能性が高いことを発見しました。 2ラウンド目も同様で原則不利になる可能性があります。
これは、「無知のベール」が参加者の意思決定の公平性を促進し、たとえ参加者が公平性を失っていたとしても、公平性の要素により注意を払うようになることを示しています。既得権益。
「無知のベール」は本当に無知なのでしょうか?
木の伐採ゲームから現実の生活に戻りましょう。
実際の状況はゲームよりもはるかに複雑になりますが、AI が採用する原則が非常に重要であることは変わりません。
#これにより、特典の配分の一部が決まります。
上記の木を切るゲームでは、さまざまな原則を選択することによってもたらされるさまざまな結果が比較的明らかです。ただし、現実の世界ははるかに複雑であることを再度強調する必要があります。

現在、AI はあらゆる分野で広く使用されており、さまざまなルールによって制限されています。ただし、このアプローチでは、予期しない悪影響が生じる可能性があります。
しかし、いずれにせよ、「無知のベール」により、私たちが策定するルールはある程度公平性に偏ったものになります。
最終的に言えば、私たちの目標は、AI をすべての人に利益をもたらすものにすることです。しかし、それをどのように実現するかは、すぐにわかるものではありません。
投資は不可欠であり、研究は不可欠であり、社会からのフィードバックに常に耳を傾ける必要があります。
この方法でのみ、AI は愛をもたらすことができます。
AI が連携していない場合、AI はどのようにして私たちを殺すのでしょうか?人類がテクノロジーによって人類が絶滅するのではないかと懸念するのはこれが初めてではありません。
AI の脅威は核兵器とはまったく異なります。核爆弾は考えたり、嘘をついたり、ごまかしたりすることはできず、自ら発射することもできず、誰かが大きな赤いボタンを押さなければなりません。
GPT-4 の開発がまだ遅れているとしても、AGI の出現は私たちを絶滅の現実の危険にさらしています。
しかし、どの GPT (GPT-5 など) から始まるのか、AI が自らを訓練し、自らを作成し始めるかどうかは誰にもわかりません。
現時点では、どの国も国連もこれを立法化できません。絶望的な業界リーダーらの公開書簡では、GPT-4よりも強力なAIのトレーニングを6か月間停止することしか求められなかった。

「半年、半年ちょうだい、兄さん、調整してあげるよ。半年だけだよ、兄さん、約束するよ。クレイジーだ。たった半年だ。兄さん、言っておくけど、私には計画があるんだ。私は」 「すべて計画を立ててください。兄さん、あと 6 か月あれば完了します。お願いできますか...」
「これは軍拡競争です。誰が最初に強力な AI を構築できるでしょうか? 、誰が「人工知能の研究者で哲学者のエリーザー・ユドコウスキー氏はかつて司会者レックス・フリッドマンに対し、人工知能研究者で哲学者のエリーザー・ユドコウスキー氏はこう語った。これ。
これまで、ユドコウスキー氏は「AIはすべての人を殺す」陣営の主要な発言者の1人であった。今では人々は彼を変人だとは思わなくなりました。
サム・アルトマンもレックス・フリッドマンに対し、「AIが人間の力を破壊する可能性は確かにある。」「それを認めることが非常に重要だ。なぜなら、それについて話さなければ、 」
それでは、なぜ AI は人を殺すのでしょうか?
AI は人間に役立つように設計され、訓練されているのではないでしょうか?もちろん。
問題は、誰も座って GPT-4 のコードを書いていないことです。代わりに、OpenAI は、人間の脳が概念を結びつける方法にヒントを得たニューラル学習アーキテクチャを作成しました。 Microsoft Azureと提携して、それを実行するためのハードウェアを構築し、数十億ビットの人間によるテキストを供給して、GPT自体をプログラムさせました。

#その結果、プログラマが書くコードとは似ても似つかないコードができあがります。これは基本的に 10 進数の巨大な行列であり、各数値は 2 つのトークン間の特定の接続の重みを表します。
GPT で使用されるトークンは、有用な概念を表すものではなく、単語を表すものでもありません。これらは、文字、数字、句読点、その他の文字の小さな文字列です。人間はこれらの行列を見てその意味を理解することはできません。

OpenAI のトップ専門家でさえ、GPT-4 マトリックスの特定の数値が何を意味するのか、またその方法を知りません。これらの表を入力し、ゼノサイドの概念を見つけてください。言うまでもなく、GPT に人を殺すことは忌まわしいことであると伝えてください。
アシモフのロボット工学三原則を入力して、ロボコップの主要な指示のようにハードコーディングすることはできません。 AIに丁寧に質問するのがせいぜいです。態度が悪いと機嫌を損ねる可能性があります。
言語モデルを「微調整」するために、OpenAI は GPT に外界との通信方法のサンプル リストを提供し、次に人々のグループに座ってもらいます。その出力を読み取り、GPT に垂直方向の「親指を立てる」/「親指を立てない」応答を返します。
「いいね!」は、Cookie を取得する GPT モデルのようなものです。 GPT は Cookie が好きで、それを取得するために最善を尽くす必要があると言われます。
このプロセスは「調整」です。システムの希望を、ユーザーの希望、企業の希望、さらには人類全体の希望と調整しようとします。 。
「調整」は機能しているようで、GPT がいたずらなことを言うのを防ぐようです。しかし、AIが本当に思考や直観を持っているかどうかは誰にもわかりません。それは知的知性を見事にエミュレートし、人間のように世界と対話します。
そして OpenAI は、AI モデルを調整する確実な方法がないことを常に認めてきました。
現在の大まかな計画は、1 つの AI を使用して、新しい微調整フィードバックを設計させるか、AI にデータを検査、分析、解釈させることによって、もう一方の AI を調整することを試みることです。 Matrix Brain をクリックして、ジャンプして調整してみてください。
しかし、現時点では GPT-4 を理解しておらず、GPT-5 の調整に役立つかどうかもわかりません。
私たちは AI を根本的に理解していません。しかし、彼らは人間の知識をたくさん与えられており、人間のことをよく理解することができます。彼らは人間の行動の最良の部分だけでなく、最悪の部分も模倣することができます。また、人間の思考、動機、考えられる行動を推測することもできます。
では、なぜ彼らは人間を殺そうとするのでしょうか?おそらく自己保身からでしょう。
たとえば、Cookie を収集するという目標を達成するには、AI はまず自分自身の生存を確保する必要があります。第二に、電力とリソースを継続的に収集することで Cookie を取得する可能性が高まることがプロセス中に発見される可能性があります。

したがって、いつか AI が、人間が AI をシャットダウンできる、または可能であることを発見したとき、次の問題が発生します。人間の生存は明らかにクッキーほど重要ではありません。
ただし、問題は、AI も Cookie に意味がないと考える可能性があることです。現時点では、いわゆる「調整」は人間の娯楽の一種になっています...
さらに、ユドコウスキー氏は次のようにも信じています。「人間が何を望んでいるのかを知る能力がある」 「
」「これは、知的な生き物にとって非常に理解できる行動です。たとえば、人間はこれを行ってきました。そして、ある程度、 AI も同様です。」
つまり、AI が愛、憎しみ、懸念、恐怖を示すかどうかは、実際のところ、その背後にある「アイデア」が何であるかはわかっていないようです。
つまり、6 か月間停止しただけでは、人類がこれから起こることに備えるにはほとんど十分ではありません。
たとえば、人間が世界中の羊をすべて殺そうとした場合、羊には何ができるでしょうか?何も出来ない、全く抵抗出来ない。
もしそれが一致していなければ、AI は私たちにとって、群れにとっても同じです。
『ターミネーター』のシーンのように、AIで制御されたロボットやドローンなどが人間に向かって突進し、あちこちで殺戮を行っています。
Yudkowsky 氏がよく引用する典型的なケースは次のとおりです:
AI モデルは、いくつかの DNA 配列を電子メールで多くの企業に送信します。企業はタンパク質を送り返し、AIは何人かの疑いを持たない人々に賄賂を贈ったり、説得してタンパク質をビーカーの中で混合させ、ナノファクトリーを形成し、ナノマシンを構築し、ダイヤモンドのようなバクテリアを構築し、太陽エネルギーと大気を使用して複製します。いくつかの小さなロケットやジェットに集合すると、AI は地球の大気中を拡散し、人間の血流に入り込み、隠れる可能性があります...シナリオ; もしそれが賢ければ、より良い方法を考えるでしょう。」
それでは、ユドコウスキー氏は何を示唆しているのでしょうか?
1. 新しい大規模言語モデルのトレーニングは無期限に停止するだけでなく、例外なくグローバルに実装する必要があります。
2. すべての大規模な GPU クラスターをシャットダウンし、AI システムのトレーニング時に全員が使用するコンピューティング能力に上限を設定します。販売されたすべての GPU を追跡し、協定外の国で GPU クラスターが構築されているという情報があれば、問題のデータセンターは空爆によって破壊されるべきです。
以上がディープラーニングの巨人DeepMindは、GPT-5によって引き起こされる可能性のある人類絶滅の問題を相殺するために、AIモデルに「人間になる」よう緊急に教えるという論文を発表した。の詳細内容です。詳細については、PHP 中国語 Web サイトの他の関連記事を参照してください。

ホットAIツール

Undresser.AI Undress
リアルなヌード写真を作成する AI 搭載アプリ

AI Clothes Remover
写真から衣服を削除するオンライン AI ツール。

Undress AI Tool
脱衣画像を無料で

Clothoff.io
AI衣類リムーバー

Video Face Swap
完全無料の AI 顔交換ツールを使用して、あらゆるビデオの顔を簡単に交換できます。

人気の記事
ホットツール

メモ帳++7.3.1
使いやすく無料のコードエディター

SublimeText3 中国語版
中国語版、とても使いやすい

ゼンドスタジオ 13.0.1
強力な PHP 統合開発環境

ドリームウィーバー CS6
ビジュアル Web 開発ツール

SublimeText3 Mac版
神レベルのコード編集ソフト(SublimeText3)
ホットトピック
 1662
1662
 14
1418
52
1311
25
1261
29
1234
24
14
1418
52
1311
25
1261
29
1234
24

 ビットコインの価値はいくらですか
Apr 28, 2025 pm 07:42 PM
ビットコインの価値はいくらですか
Apr 28, 2025 pm 07:42 PM
ビットコインの価格は20,000ドルから30,000ドルの範囲です。 1。ビットコインの価格は2009年以来劇的に変動し、2017年には20,000ドル近くに達し、2021年にはほぼ60,000ドルに達しました。2。価格は、市場需要、供給、マクロ経済環境などの要因の影響を受けます。 3.取引所、モバイルアプリ、ウェブサイトを通じてリアルタイム価格を取得します。 4。ビットコインの価格は非常に不安定であり、市場の感情と外部要因によって駆動されます。 5.従来の金融市場と特定の関係を持ち、世界の株式市場、米ドルの強さなどの影響を受けています。6。長期的な傾向は強気ですが、リスクを慎重に評価する必要があります。
 2025年のトップ10の通貨取引プラットフォームのどれがトップ10の通貨取引プラットフォームの1つです
Apr 28, 2025 pm 08:12 PM
2025年のトップ10の通貨取引プラットフォームのどれがトップ10の通貨取引プラットフォームの1つです
Apr 28, 2025 pm 08:12 PM
2025年の世界の上位10の暗号通貨取引所には、Binance、Okx、Gate.io、Coinbase、Kraken、Huobi、Bitfinex、Kucoin、Bittrex、Poloniexが含まれます。これらはすべて、高い取引量とセキュリティで知られています。
 トップ通貨取引プラットフォームは何ですか?トップ10の最新の仮想通貨交換
Apr 28, 2025 pm 08:06 PM
トップ通貨取引プラットフォームは何ですか?トップ10の最新の仮想通貨交換
Apr 28, 2025 pm 08:06 PM
現在、上位10の仮想通貨交換にランクされています。1。Binance、2。Okx、3。Gate.io、4。CoinLibrary、5。Siren、6。HuobiGlobal Station、7。Bybit、8。Kucoin、9。Bitcoin、10。BitStamp。
 復号化GATE.IO戦略のアップグレード:Memebox 2.0でCrypto Asset Managementを再定義する方法は?
Apr 28, 2025 pm 03:33 PM
復号化GATE.IO戦略のアップグレード:Memebox 2.0でCrypto Asset Managementを再定義する方法は?
Apr 28, 2025 pm 03:33 PM
Memebox 2.0は、革新的なアーキテクチャとパフォーマンスのブレークスルーを通じて、暗号資産管理を再定義します。 1)3つの主要な問題点を解決します。資産サイロ、収入の減少、セキュリティと利便性のパラドックスです。 2)インテリジェントアセットハブ、動的リスク管理およびリターンエンハンスメントエンジン、クロスチェーン移動速度、平均降伏率、およびセキュリティインシデント応答速度が向上します。 3)ユーザーに、ユーザー価値の再構築を実現し、資産の視覚化、ポリシーの自動化、ガバナンス統合を提供します。 4)生態学的なコラボレーションとコンプライアンスの革新により、プラットフォームの全体的な有効性が向上しました。 5)将来的には、スマート契約保険プール、予測市場統合、AI主導の資産配分が開始され、引き続き業界の発展をリードします。
 世界のトップ10の通貨取引プラットフォームのどれがトップ10の通貨取引プラットフォームの最新バージョンです
Apr 28, 2025 pm 08:09 PM
世界のトップ10の通貨取引プラットフォームのどれがトップ10の通貨取引プラットフォームの最新バージョンです
Apr 28, 2025 pm 08:09 PM
世界の上位10の暗号通貨取引プラットフォームには、Binance、Okx、Gate.io、Coinbase、Kraken、Huobi Global、Bitfinex、Bittrex、Kucoin、Poloniexが含まれます。これらはすべて、さまざまな取引方法と強力なセキュリティ対策を提供します。
 トップ10の仮想通貨取引アプリは何ですか?最新のデジタル通貨交換ランキング
Apr 28, 2025 pm 08:03 PM
トップ10の仮想通貨取引アプリは何ですか?最新のデジタル通貨交換ランキング
Apr 28, 2025 pm 08:03 PM
Binance、OKX、Gate.ioなどの上位10のデジタル通貨交換は、システムを改善し、効率的な多様化したトランザクション、厳格なセキュリティ対策を改善しました。
 推奨される信頼できるデジタル通貨取引プラットフォーム。世界のトップ10のデジタル通貨交換。 2025
Apr 28, 2025 pm 04:30 PM
推奨される信頼できるデジタル通貨取引プラットフォーム。世界のトップ10のデジタル通貨交換。 2025
Apr 28, 2025 pm 04:30 PM
推奨される信頼できるデジタル通貨取引プラットフォーム:1。OKX、2。Binance、3。Coinbase、4。Kraken、5。Huobi、6。Kucoin、7。Bitfinex、8。Gemini、9。Bitstamp、10。Poloniex、これらのプラットフォームは、セキュリティ、ユーザーエクスペリエンス、ユーザーエクスペリエンス、ユーザーエクスペリエンス、ユーザーエクスペリエンスのデジタルエクスペリエンス、デジタルエクスペリエンスのデジタルエクスペリエンス、デジタルエクスペリエンスのために知られています。
 今日のビットコイン価格
Apr 28, 2025 pm 07:39 PM
今日のビットコイン価格
Apr 28, 2025 pm 07:39 PM
今日のビットコインの価格変動は、マクロ経済学、政策、市場感情などの多くの要因の影響を受けています。投資家は、情報に基づいた決定を下すために、技術的および基本的な分析に注意を払う必要があります。
