

Google は視覚伝達モデルのパラメータを 220 億まで拡張し、ChatGPT が普及して以来研究者が集団的な行動をとった

自然言語処理と同様に、事前トレーニングされたビジュアル バックボーンの転送により、さまざまなビジュアル タスクにおけるモデルのパフォーマンスが向上します。大規模なデータセット、スケーラブルなアーキテクチャ、および新しいトレーニング方法はすべて、モデルのパフォーマンスの向上を推進しました。
しかし、視覚モデルは依然として言語モデルに大きく遅れをとっています。具体的には、これまで最大のビジョン モデルである ViT のパラメーターは 4B のみですが、エントリーレベルの言語モデルは 10B パラメーターを超えることがよくあり、ましてや 540B パラメーターを持つ大規模な言語モデルは言うまでもありません。
AI モデルのパフォーマンスの限界を調査するために、Google Research は最近 CV の分野で研究を実施し、ビジョン トランスフォーマーのパラメータ サイズを 22B に拡大し、ViT を提案しました。前回と同様の-22Bであり、モデルパラメータ量4Bと比較すると、これまでで最大の高密度ViTモデルと言えます。

#論文アドレス: https://arxiv.org/pdf/2302.05442.pdf
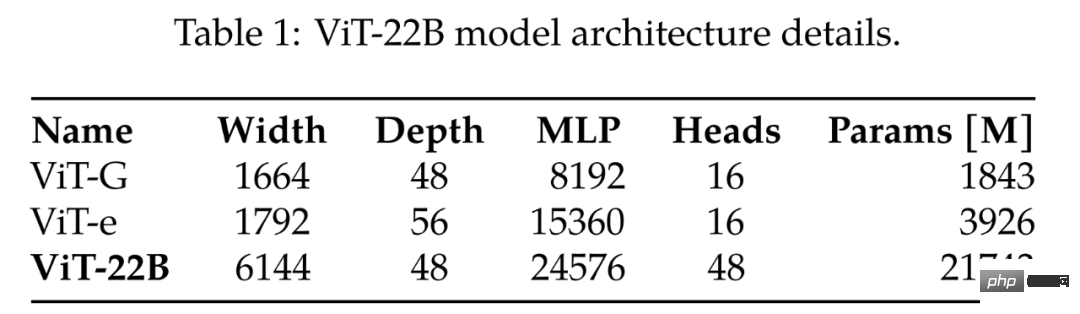
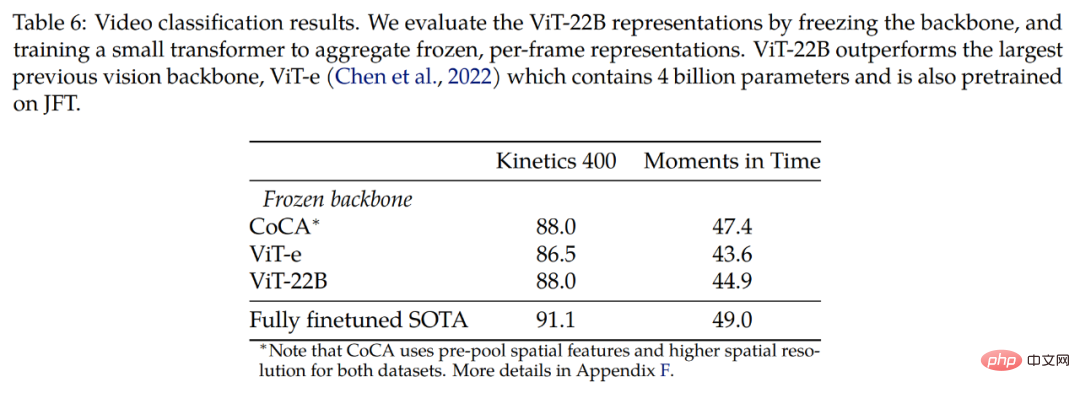
#従来最大のViT-GとViT-eを比較した結果が表1にありますが、以下の表からViT-22Bは主にモデル幅を拡大していることがわかります。 、パラメーターを作成します。ViT-G よりもボリュームが大きく、深さは同じです。
としてこの Zhihu ネチズンは、もしかしたら Google は ChatGPT でラウンドに敗れ、CV 分野で競争することになるのではないか、と述べています。 ###########################どうやってするの?研究の初期段階で、ViT の拡張中にトレーニングの不安定性が発生し、アーキテクチャの変更につながる可能性があることが判明しました。その後、研究者たちはモデルを慎重に設計し、前例のない効率で並行してトレーニングしました。 ViT-22B の品質は、(数ショットの) 分類から高密度の出力タスクに至るまで、現在の SOTA レベルを満たしているか、それを超えている包括的な一連のタスクを通じて評価されました。たとえば、ViT-22B は、凍結された視覚特徴抽出器として使用された場合でも、ImageNet 上で 89.5% の精度を達成しました。これらの視覚的特徴に一致するようにテキスト タワーをトレーニングすることにより、ImageNet 上で 85.9% のゼロショット精度を達成します。さらに、モデルを教師とみなし、蒸留ターゲットとして使用することもでき、研究者らは ViT-B 学生モデルをトレーニングし、ImageNet 上で 88.6% の精度を達成し、この規模のモデルでは SOTA レベルに達しました。
モデル アーキテクチャ
ViT-22B は、オリジナルの Vision Transformer アーキテクチャに似た Transformer ベースのエンコーダ モデルですが、効率と安定性を向上させるために次の 3 つの主要な変更が含まれています。大規模トレーニング: 並列レイヤー、クエリ/キー (QK) 正規化、バイアスの省略。

これは達成できます。 MLP の線形投影とアテンション ブロックを組み合わせて追加の並列化を実現します。特に、クエリ/キー/値射影の行列乗算と MLP の最初の線形層は、アテンション外射影と MLP の 2 番目の線形層の場合と同様、単一の演算に融合されています。
QK 正規化。大規模なモデルをトレーニングする際の難点の 1 つはモデルの安定性であり、研究者らは ViT を拡張する過程で、数千ラウンドのステップ後にトレーニング損失が発散することを発見しました。この現象は、8B パラメータ モデルで特に顕著です。モデルトレーニングを安定させるために、研究者らはGilmerらの手法を採用し、ドット積アテンション計算の前にクエリとキーにLayerNorm正規化演算を適用してトレーニングの安定性を向上させた。具体的には、注目の重みは次のように計算されます:
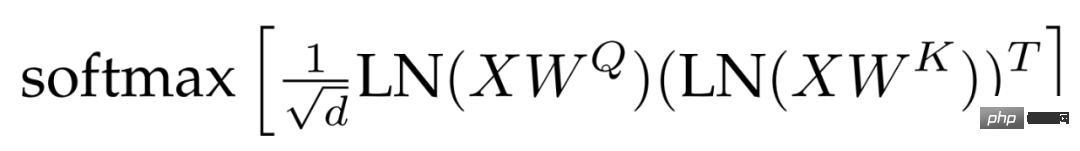
#偏見を省略しました。 PaLM の後、QKV 投影からバイアス項が削除され、すべてのレイヤーノルムがバイアスなしで適用され、その結果、品質を劣化させることなくアクセラレータの利用率が向上 (3%) しました。ただし、PaLM とは異なり、研究者らは MLP 高密度層にバイアス項を使用しましたが、それでも、このアプローチは品質を考慮しながら速度を犠牲にすることはありませんでした。
図 2 は、ViT-22B エンコーダ ブロックを示しています。埋め込み層は、元の ViT に基づいてパッチ抽出、線形投影、追加位置の埋め込みなどの操作を実行します。研究者らは、マルチヘッド アテンション プーリングを使用して、ヘッド内の各トークン表現を集約しました。

トレーニング インフラストラクチャと効率
ViT-22B は、JAX として実装され、Scenic に組み込まれた FLAX ライブラリを使用します。モデルとデータの両方の並列処理を利用します。特に、研究者らは、すべての中間物 (重みやアクティベーションなど) のシャーディングとチップ間通信の明示的な制御を提供する jax.xmap API を使用しました。研究者らはチップをサイズ t × k の 2D 論理グリッドに編成しました。ここで、t はデータ平行軸のサイズ、k はモデル軸のサイズです。次に、t グループのそれぞれについて、k 個のデバイスが同じバッチの画像を取得します。各デバイスは 1/k のアクティベーションのみを保持し、すべての線形層出力の 1/k を計算する責任を負います (詳細は以下を参照)。
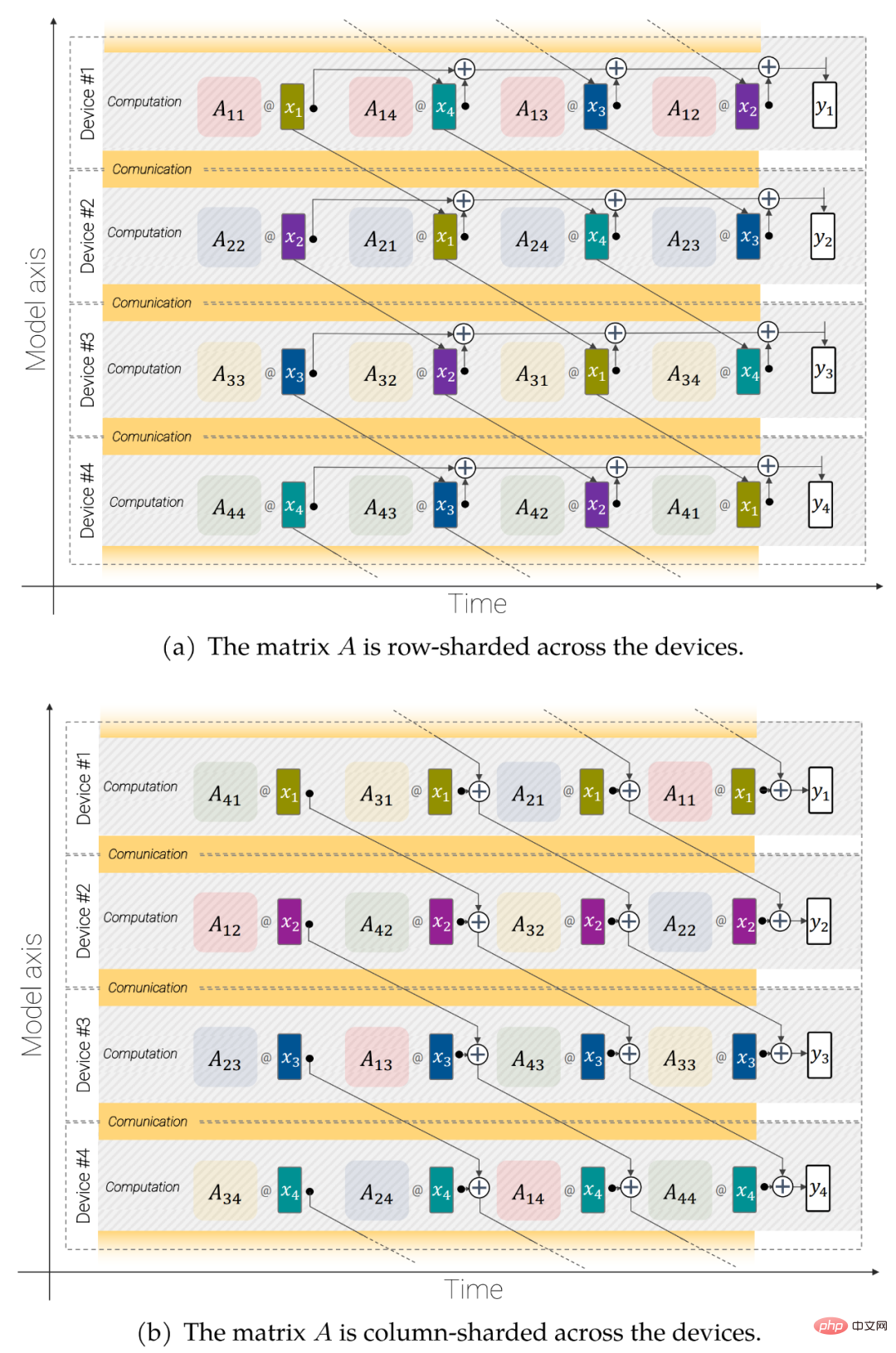
図 3: 非同期並列線形演算 (y = Ax): デバイス間での通信と計算のオーバーラップ モデル並列行列乗算用。
非同期並列線形操作。スループットを最大化するには、計算と通信を考慮する必要があります。つまり、これらの操作を非シャードの場合と分析的に同等にしたい場合は、通信をできる限り少なくする必要があり、理想的には行列乗算ユニット (FLOP の容量の大部分が存在する) を維持できるようにそれらの操作をオーバーラップさせます。いつも忙しい。パラメータのシャーディング。モデルは最初の軸に並列したデータです。各パラメータをこの軸上で完全に複製することも、各デバイスをその一部として保存することもできます。研究者らは、より大きなモデルとバッチ サイズに適合できるように、モデル パラメーターからいくつかの大きなテンソルを分割することを選択しました。
これらの手法を使用して、ViT-22B は TPUv4 でのトレーニング中にコアあたり 1 秒あたり 1.15k トークンを処理します。 ViT-22B のモデル フロップ使用率 (MFU) は 54.9% であり、ハードウェアが非常に効率的に使用されていることを示しています。 PaLM は 46.2% の MFU を報告しているのに対し、研究者らは同じハードウェア上で ViT-e (データ並列処理のみ) の MFU を 44.0% と測定したことに注意してください。
実験結果
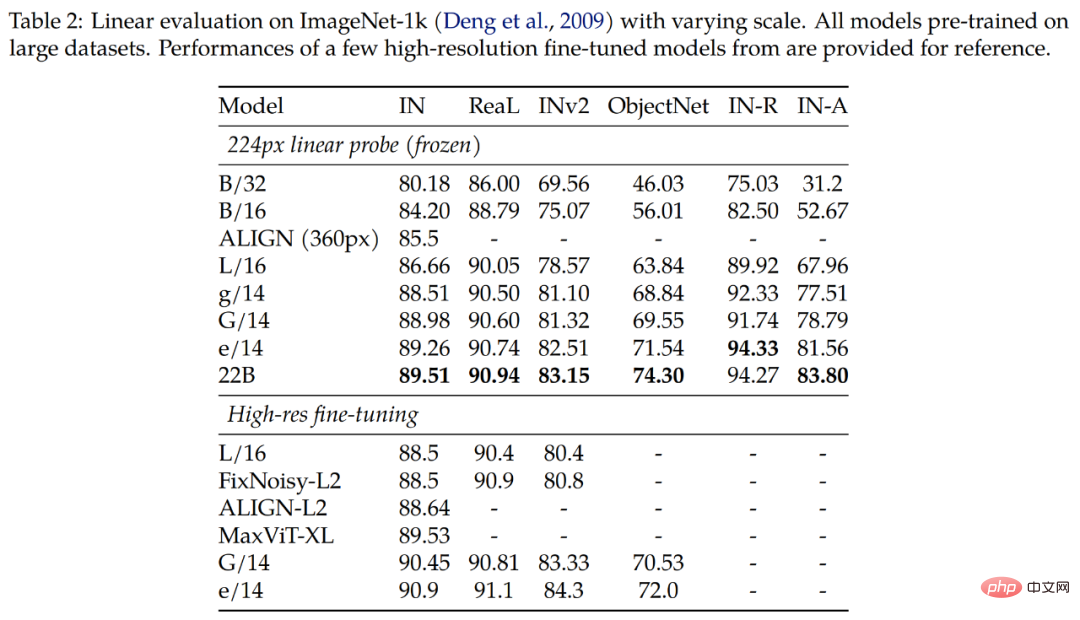
実験では、画像分類における ViT-22B の評価結果を調査します。表 2 の結果は、ViT-22B がさまざまな指標において依然として大幅な改善を示していることを示しています。さらに、ViT-22B のような大型モデルの線形プローブは、高分解能の小型モデルの完全な微調整パフォーマンスに近づくか、それを超えることが研究で示されており、多くの場合、より安価で簡単に行うことができます。
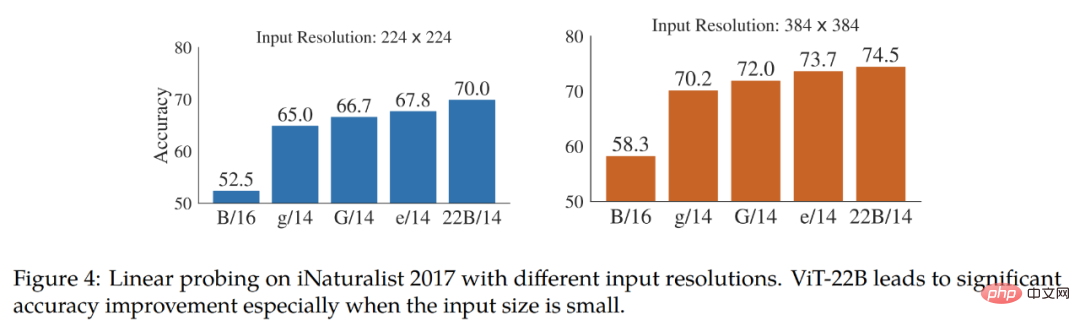
#表 3 は、CLIP、ALIGN、BASIC、CoCa、および LiT モデルに対する ViT-22B のゼロサンプル マイグレーション結果を示しています。表 3 の下部では、3 つの ViT モデルの性能を比較しています。
ViT-22B は、すべての ImageNet テスト セットで同等以上の結果を達成します。特に、ObjectNet テスト セットのゼロ ショットの結果は、ViT モデルのサイズと高度に相関しています。最大の ViT-22B は、困難な ObjectNet テスト セットに新しい最先端技術を導入します。

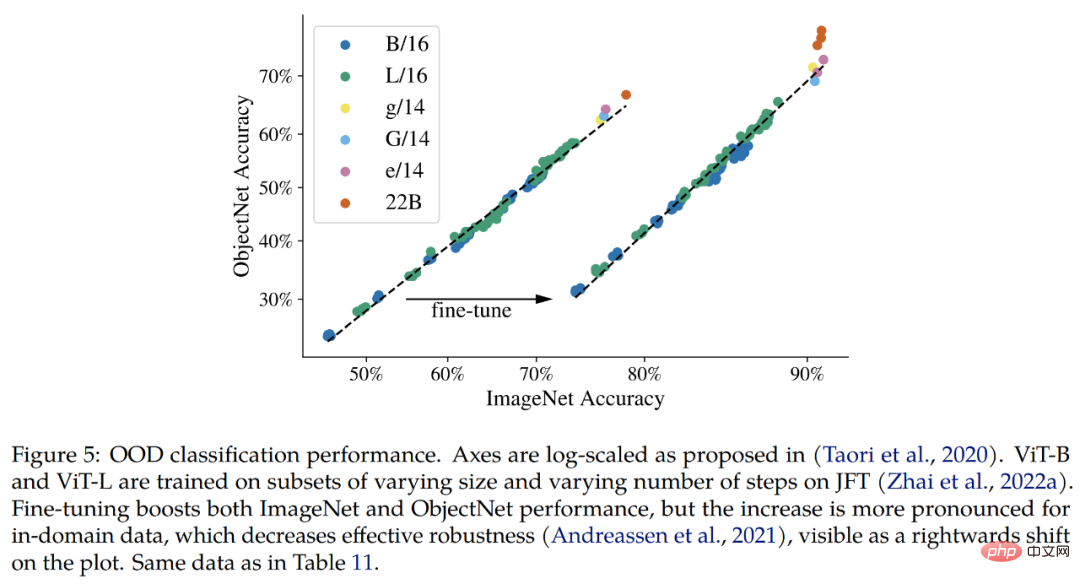
配布外 (OOD)。この研究では、JFT から ImageNet へのラベル マッピング、および ImageNet からさまざまな配布外データセット (つまり、ObjectNet、ImageNet-v2、ImageNet-R、および ImageNet-A) へのラベル マッピングを構築します。
これまでに確認できた結果は、ImageNet の改善と一致して、拡張モデルによって配布外のパフォーマンスが向上しているということです。これは、JFT イメージのみを参照したモデルや、ImageNet で微調整されたモデルに対して機能します。どちらの場合も、ViT-22B は大型モデルで OOD パフォーマンスが向上する傾向を継続しています (図 5、表 11)。
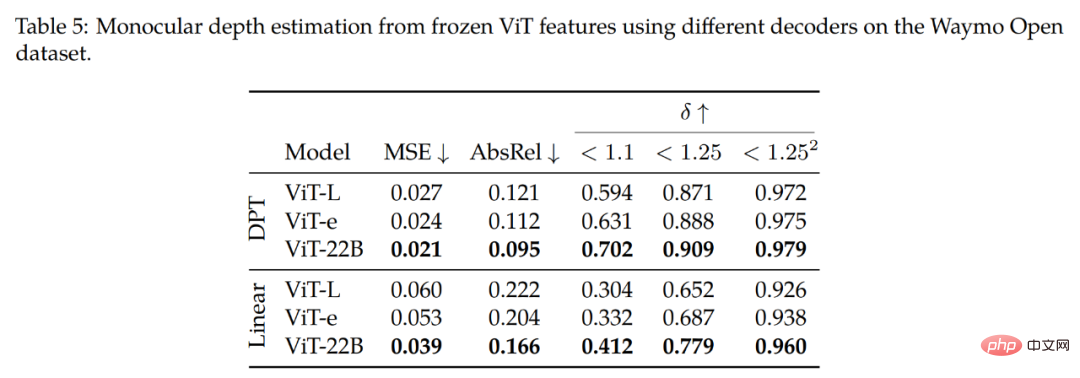
さらに、研究者らは、セマンティック セグメンテーションと単眼深度推定でキャプチャされた ViT-22B モデルのパフォーマンスも研究しました。幾何学的および空間的情報の品質。
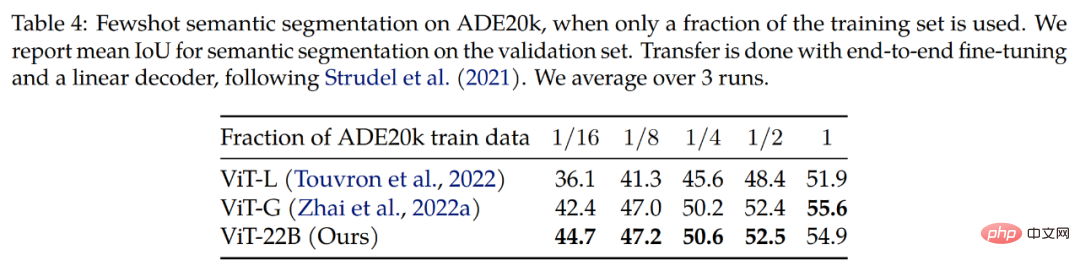
セマンティック セグメンテーション。研究者らは、ADE20K、Pascal Context、Pascal VOC の 3 つのベンチマークで ViT-22B をセマンティック セグメンテーション バックボーンとして評価しました。表 4 からわかるように、ViT-22B バックボーンの移行は、セグメンテーション マスクが少数しか見られない場合に、より適切に機能します。
さらに、ViT-e バックボーンを ViT-L (ViT-e と同様のアーキテクチャですが、トレーニング データが少ない) と比較した研究では、これらの改善も次の点から得られることがわかりました。拡張機能 トレーニング前のデータ。これらの調査結果は、大規模なモデルと大規模なデータセットの両方がパフォーマンスの向上に役立つことを示唆しています。
最終調査では、完全なエンドツーエンドの微調整を通じてさらに改善の余地があることが判明しました。
以上がGoogle は視覚伝達モデルのパラメータを 220 億まで拡張し、ChatGPT が普及して以来研究者が集団的な行動をとったの詳細内容です。詳細については、PHP 中国語 Web サイトの他の関連記事を参照してください。

ホットAIツール

Undresser.AI Undress
リアルなヌード写真を作成する AI 搭載アプリ

AI Clothes Remover
写真から衣服を削除するオンライン AI ツール。

Undress AI Tool
脱衣画像を無料で

Clothoff.io
AI衣類リムーバー

AI Hentai Generator
AIヘンタイを無料で生成します。

人気の記事
ホットツール

メモ帳++7.3.1
使いやすく無料のコードエディター

SublimeText3 中国語版
中国語版、とても使いやすい

ゼンドスタジオ 13.0.1
強力な PHP 統合開発環境

ドリームウィーバー CS6
ビジュアル Web 開発ツール

SublimeText3 Mac版
神レベルのコード編集ソフト(SublimeText3)
ホットトピック
 7461
7461
 15
1376
52
77
11
17
17
15
1376
52
77
11
17
17


 DeepSeekを検索する方法
Feb 19, 2025 pm 05:39 PM
DeepSeekを検索する方法
Feb 19, 2025 pm 05:39 PM
DeepSeekは、特定のデータベースまたはシステムでのみ検索する独自の検索エンジンであり、より速く、より正確です。それを使用する場合、ユーザーはドキュメントを読み、さまざまな検索戦略を試し、ユーザーエクスペリエンスに関するヘルプを求めてフィードバックを求めて、利点を最大限に活用することをお勧めします。
 セサミオープンドア交換Webページ登録リンクゲートトレーディングアプリ登録Webサイト最新
Feb 28, 2025 am 11:06 AM
セサミオープンドア交換Webページ登録リンクゲートトレーディングアプリ登録Webサイト最新
Feb 28, 2025 am 11:06 AM
この記事では、SESAME Open Exchange(gate.io)Webバージョンの登録プロセスとGate Tradingアプリを詳細に紹介します。 Web登録であろうとアプリの登録であろうと、公式Webサイトまたはアプリストアにアクセスして、本物のアプリをダウンロードし、ユーザー名、パスワード、電子メール、携帯電話番号、その他の情報を入力し、電子メールまたは携帯電話の確認を完了する必要があります。
 Bybit Exchangeリンクを直接ダウンロードしてインストールできないのはなぜですか?
Feb 21, 2025 pm 10:57 PM
Bybit Exchangeリンクを直接ダウンロードしてインストールできないのはなぜですか?
Feb 21, 2025 pm 10:57 PM
Bybit Exchangeリンクを直接ダウンロードしてインストールできないのはなぜですか? BYBITは、ユーザーにトレーディングサービスを提供する暗号通貨交換です。 Exchangeのモバイルアプリは、次の理由でAppStoreまたはGooglePlayを介して直接ダウンロードすることはできません。1。AppStoreポリシーは、AppleとGoogleがApp Storeで許可されているアプリケーションの種類について厳しい要件を持つことを制限しています。暗号通貨交換アプリケーションは、金融サービスを含み、特定の規制とセキュリティ基準を必要とするため、これらの要件を満たしていないことがよくあります。 2。法律と規制のコンプライアンス多くの国では、暗号通貨取引に関連する活動が規制または制限されています。これらの規制を遵守するために、BYBITアプリケーションは公式Webサイトまたはその他の認定チャネルを通じてのみ使用できます
 セサミオープンドアトレーディングプラットフォームダウンロードモバイルバージョンgateioトレーディングプラットフォームのダウンロードアドレス
Feb 28, 2025 am 10:51 AM
セサミオープンドアトレーディングプラットフォームダウンロードモバイルバージョンgateioトレーディングプラットフォームのダウンロードアドレス
Feb 28, 2025 am 10:51 AM
アプリをダウンロードしてアカウントの安全を確保するために、正式なチャネルを選択することが重要です。
 セサミオープンドアエクスチェンジウェブページログイン最新バージョンgateio公式ウェブサイトの入り口
Mar 04, 2025 pm 11:48 PM
セサミオープンドアエクスチェンジウェブページログイン最新バージョンgateio公式ウェブサイトの入り口
Mar 04, 2025 pm 11:48 PM
ログインステップやパスワード回復プロセスなど、セサミオープンエクスチェンジWebバージョンのログイン操作の詳細な紹介も、ログイン障害、ページを開くことができず、プラットフォームにスムーズにログインするのに役立つ検証コードを受信できません。
 gate.io交換公式登録ポータル
Feb 20, 2025 pm 04:27 PM
gate.io交換公式登録ポータル
Feb 20, 2025 pm 04:27 PM
Gate.ioは、幅広い暗号資産と取引ペアを提供する主要な暗号通貨交換です。 gate.ioの登録は非常に簡単です。公式ウェブサイトにアクセスするか、「登録」をクリックし、登録フォームに入力し、電子メールを確認し、2因子検証(2FA)を設定する必要があります。登録を完了します。 gate.ioを使用すると、ユーザーは安全で便利な暗号通貨取引体験を楽しむことができます。
 Binance Binance公式Webサイト最新バージョンログインポータル
Feb 21, 2025 pm 05:42 PM
Binance Binance公式Webサイト最新バージョンログインポータル
Feb 21, 2025 pm 05:42 PM
Binance Webサイトログインポータルの最新バージョンにアクセスするには、これらの簡単な手順に従ってください。公式ウェブサイトに移動し、右上隅の[ログイン]ボタンをクリックします。既存のログインメソッドを選択してください。「登録」してください。登録済みの携帯電話番号または電子メールとパスワードを入力し、認証を完了します(モバイル検証コードやGoogle Authenticatorなど)。検証が成功した後、Binance公式WebサイトLogin Portalの最新バージョンにアクセスできます。
