

ChatGPT は、Google、Meta、OpenAI 間のチャットボット競争に焦点を当て、LeCun の不満を話題の焦点にしています

数日前、Meta の主任人工知能科学者、Yann LeCun の ChatGPT に関するコメントはすぐに業界全体に広がり、議論の波を引き起こしました。
Zoom のメディアと幹部の小規模な集まりで、LeCun 氏は驚くべきコメントをしました:「基盤となるテクノロジーに関する限り、ChatGPT はそれほど素晴らしいイノベーションではありません。」
"とはいえ世間では、これは革命的ですが、私たちはそれがよく組み立てられた製品であり、それ以上のものではないことを知っています。」
ChatGPT はイノベーションではありません
ChatGPT、過去数か月の「トップトレンド」チャットロボットとして、世界中で長く人気があり、一部の人々のキャリアや学校教育の現状を真に変えさえしました。
全世界がこれに驚いたとき、ChatGPT に対する LeCun のレビューは非常に「控えめな表現」でした。

しかし実際のところ、彼の発言は不合理なものではありません。
多くの企業や研究機関は、ChatGPT のようなデータ駆動型人工知能システムを導入しています。 LeCun氏は、OpenAIはこの分野において特別なものではないと述べた。
「Google と Meta に加えて、スタートアップ企業が 6 社ありますが、基本的にはすべて非常に似た技術を持っています。」と LeCun 氏は付け加えました。

その後、LeCun は少し機嫌が悪くなりました -
「ChatGPT は、自己教師ありの方法で事前トレーニングされた Transformer アーキテクチャを使用しています。 「教師あり学習は私が長年主張してきたことです。当時はまだ OpenAI は誕生していませんでした。」
その中で、Transformer は Google の発明です。この種の言語ニューラル ネットワークは、GPT-3 などの大規模言語モデルの基礎です。
最初のニューラル ネットワーク言語モデルは、20 年前に Yoshua Bengio によって提案されました。 Bengio のアテンション メカニズムは、後に Google によって Transformer で使用され、それ以来すべての言語モデルの重要な要素となっています。
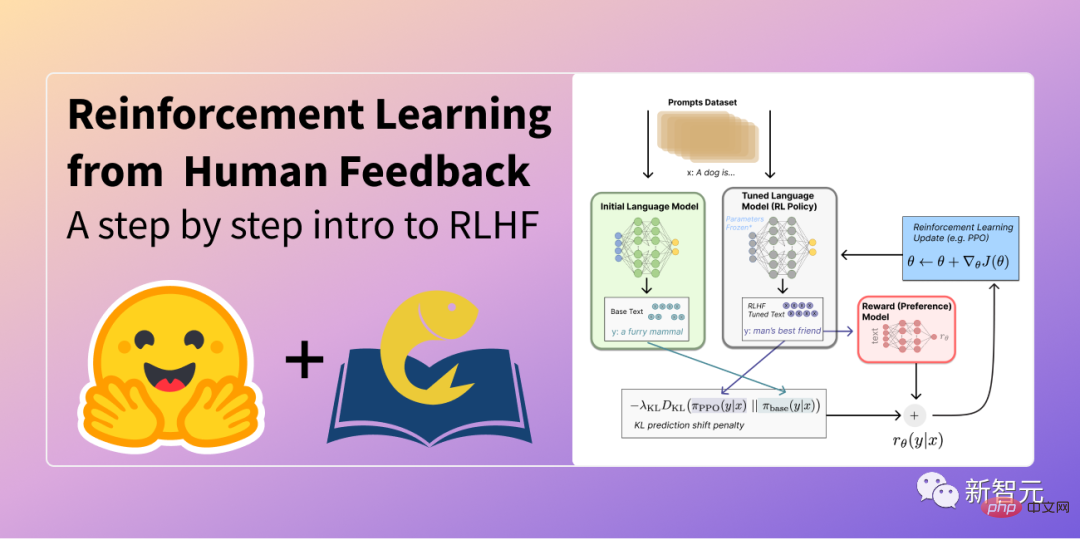
さらに、ChatGPT は、同じく Google DeepMind Lab によって開発されたヒューマン フィードバック強化学習 (RLHF) テクノロジーを使用します。
LeCun 氏の見解では、ChatGPT は科学的な画期的な進歩というよりも、エンジニアリングの成功例にすぎません。
OpenAI のテクノロジーは「基礎科学の点では革新的ではありません。単にうまく設計されているだけです。」
「もちろん、そのことで彼らを批判するつもりはありません。」
私は OpenAI の取り組みやその主張を批判しているわけではありません。
一般の人々とメディアの見方を訂正したいのですが、彼らは一般に ChatGPT が革新的でユニークな技術的進歩であると信じていますが、そうではありません。
ニューヨーク・タイムズ記者ケイド・メッツとのシンポジウムで、ルカン氏はおせっかいな人たちの疑問を感じた。
「なぜ Google と Meta は同様のシステムを持たないのかと疑問に思われるかもしれません。私の答えは、Google と Meta がそのようなナンセンスなチャットボットを立ち上げたら、損失はかなり大きくなるだろう、ということです。」と彼は微笑みながら説明した。

偶然にも、OpenAI がマイクロソフトやその他の投資家に支持され、その純資産が 290 億ドルに急上昇したというニュースが出るやいなや、マーカス氏も記事を書きました。を嘲笑するために一晩中彼のブログに投稿しました。
記事の中でマーカス氏は、「OpenAI には何ができて Google にはできないのか、そしてそれには 290 億米ドルという超高値を払う価値があるのか?」という金言を披露しました。
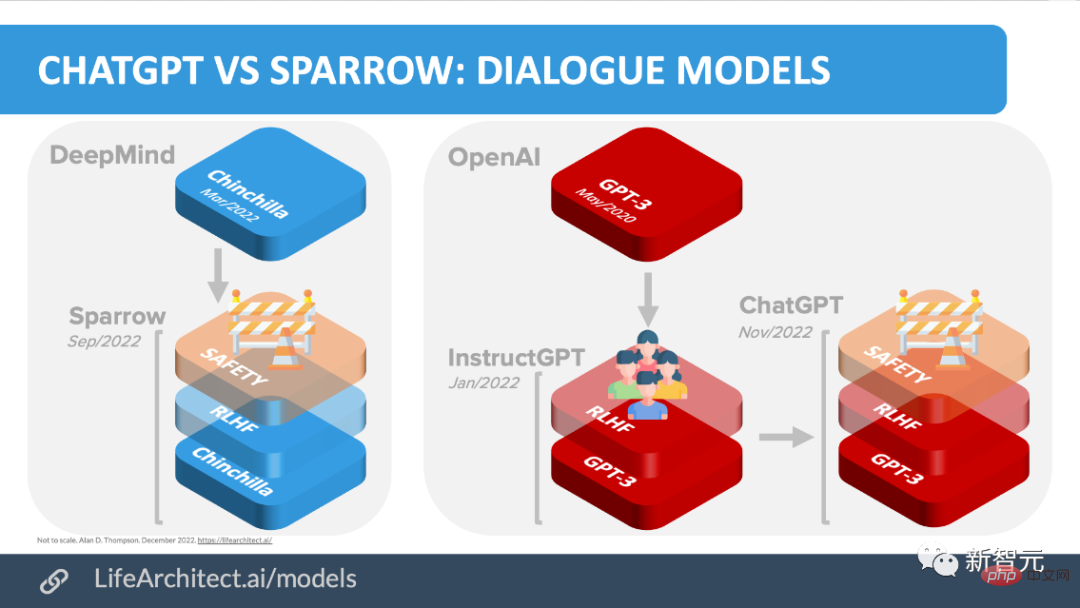
Google、Meta、DeepMind、OpenAI PK!
早速、これらの AI 巨人のチャットボットを取り出して、データそのものを語ってみましょう。
LeCun 氏は、多くの企業や研究所が ChatGPT に似た AI チャットボットを導入していると述べましたが、これは事実です。
ChatGPT は、言語モデルに基づいた最初の AI チャットボットではなく、多くの「前身」があります。
OpenAI が登場する前は、Meta、Google、DeepMind などが、Meta の BlenderBot、Google の LaMDA、DeepMind の Sparrow などの独自のチャットボットをリリースしていました。
また、独自のオープンソース チャット ロボット計画を発表したチームもいくつかあります。たとえば、LAION の Open-Assistant です。
Huggingface によるブログでは、数名の著者が RLHF、SFT、IFT、CoT (これらはすべて ChatGPT のキーワードです) のトピックに関する重要な論文を調査し、分類して要約しました。彼ら。
彼らは、BlenderBot、LaMDA、Sparrow、InstructGPT などの AI チャットボットを、パブリック アクセス、トレーニング データ、モデル アーキテクチャ、評価方向などの詳細に基づいて比較する表を作成しました。
注: ChatGPT は文書化されていないため、ChatGPT の基礎と考えられる OpenAI の命令微調整モデルである InstructGPT の詳細を使用しています。
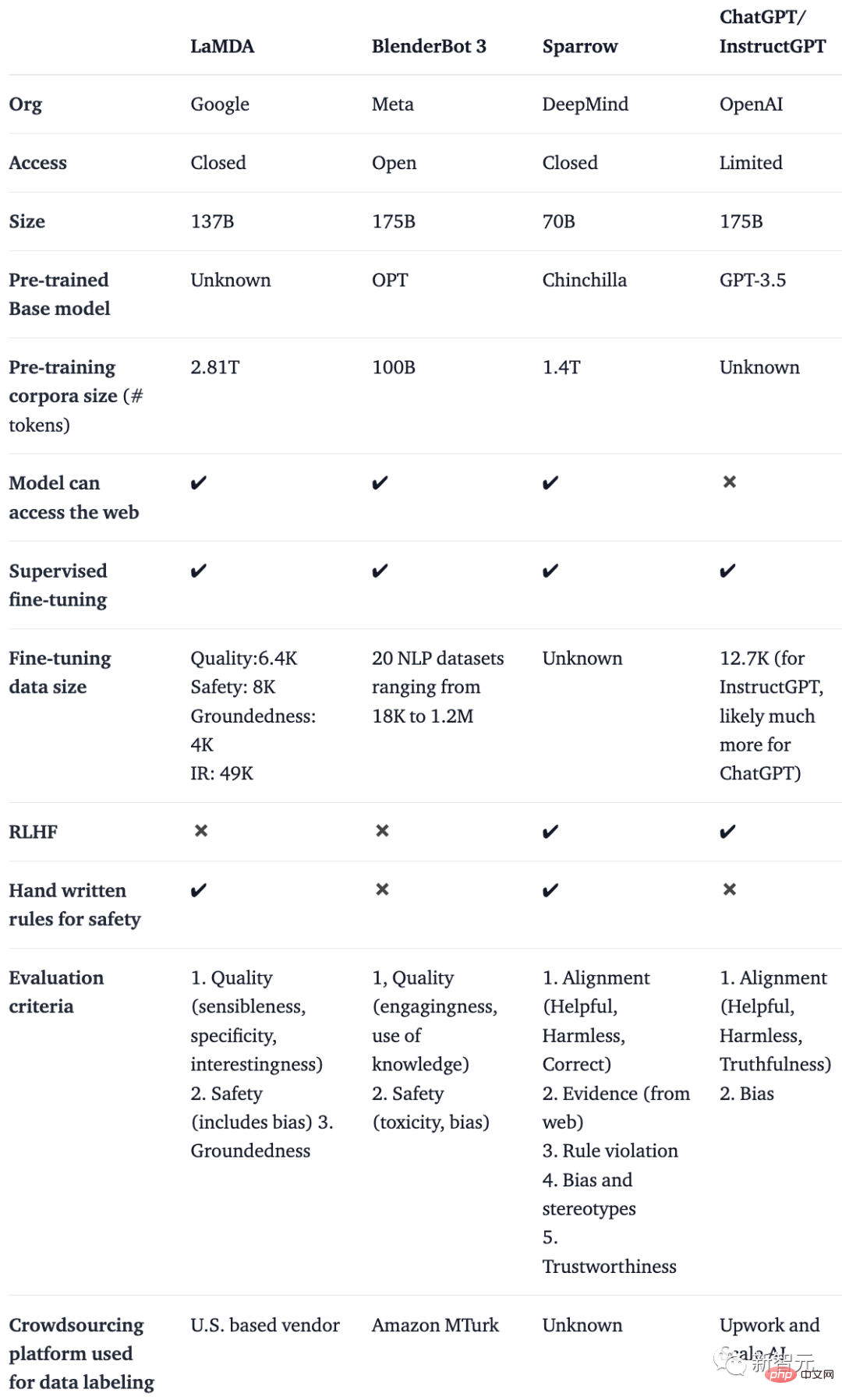
| ##LaMDABlenderBot 3 | ##Sparrow |
ChatGPT/ InstructGPT |
|||||
| # Meta | #DeepMind |
##OpenAI | ##アクセス許可 |
|||||
| パブリック | クローズド | 限定的 | ||||||
| #パラメータスケール | 1370億 | ##1750億##700億 |
##1750億 | ##ベーシックモデル |
||||
| OPT | チンチラ | GPT-3.5 |
|
#コーパスサイズ | ||||
#1000億 |
1.4 兆 |
#不明 | ##アクセス ネットワーク | ✔️ |
||||
✔️ |
##✖️ | |||||||
| 監督による微調整 | ✔️ | #✔️##✔️ | ##✔️ |
##微調整されたデータスケール |
||||
セキュリティ: 8K | Falling特徴: 4K
IR: 49K 18K から 1.2M までの範囲の 20 個の NLP データセット | 不明12.7K (ChatGPT はそれ以上の可能性があります) | RLHF |
|||||
| ✖️ | ✔️ | ✔️ | 手動セキュリティ ルール | ✔ |
✖️ |
✔ |
✖️# ############################## トレーニング データ、基本モデル、微調整には多くの違いがありますが、これらのチャットボットにはすべて、指示に従うという 1 つの共通点があることを見つけるのは難しくありません。 たとえば、ChatGPT に指示による微調整に関する詩を書くように依頼できます。 ChatGPT は非常に「認知的」で、詩を書くときに LeCun と Hinton にお世辞を言うことを決して忘れないことがわかります。 それから彼は、「ナッジ、微調整、あなたは美しいダンスです。」と熱く賞賛しました。
テキストの予測から指示に従うまで通常、基本モデルの言語モデリングだけでは、モデルがユーザーの指示に従う方法を学習するには十分ではありません。
モデルのトレーニングでは、研究者は古典的な NLP タスク (感情、テキスト分類、要約など) を使用するだけでなく、命令の微調整 (IFT) も使用します。 ). つまり、非常に多様なタスクに関するテキストの指示を通じて、基本モデルを微調整します。 これらの命令例は、命令、入力、出力という 3 つの主要な部分で構成されています。 入力はオプションです。上記の ChatGPT 例のオープン ビルドのように、一部のタスクでは指示のみが必要です。 入力と出力が現れると、例が形成されます。特定の命令に対して、複数の入力例と出力例が存在する可能性があります。たとえば、次の例:
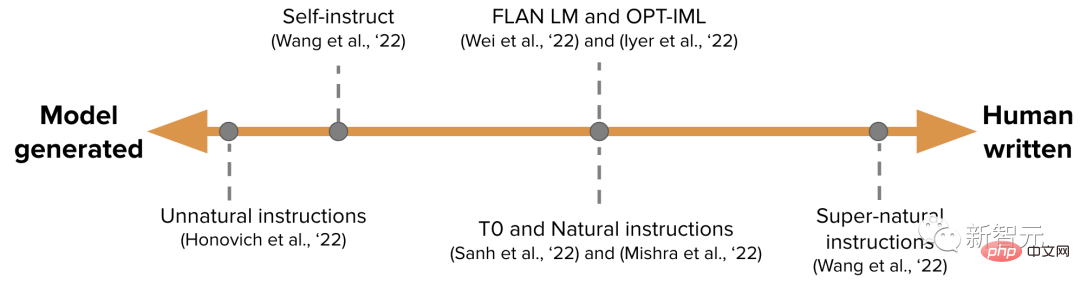
#IFT データは通常、人間によって書かれた命令と、言語モデルによってガイドされた命令の例のコレクションです。 ブート プロセス中に、LM は少数ショット (小さなサンプル) 設定 (上記のとおり) を要求され、新しい命令、入力、出力を生成するように指示されます。 各ラウンドで、モデルは人間が書いたサンプルとモデルが生成したサンプルから選択するように求められます。 データセットの作成に対する人間とモデルの貢献量はスペクトルのようになります (下の図を参照)。
一方の端は、不自然な命令など、純粋にモデルによって生成された IFT データ セットであり、もう一方の端は、スーパーナチュラルなどの、人工的に生成された多数の命令です。説明書。 その中間にあるのは、小規模だが高品質のシード データ セットを使用し、自己指導などのガイド付き作業を実行することです。 IFT 用のデータセットを整理するもう 1 つの方法は、さまざまなタスク (プロンプトを含む) で既存の高品質なクラウドソース NLP データセットを活用し、統一パターンまたはさまざまなテンプレートを使用してこれらを結合することです。データ セットは命令に変換されます。 この分野の作業には、T0、Natural 命令データセット、FLAN LM、OPT-IML が含まれます。
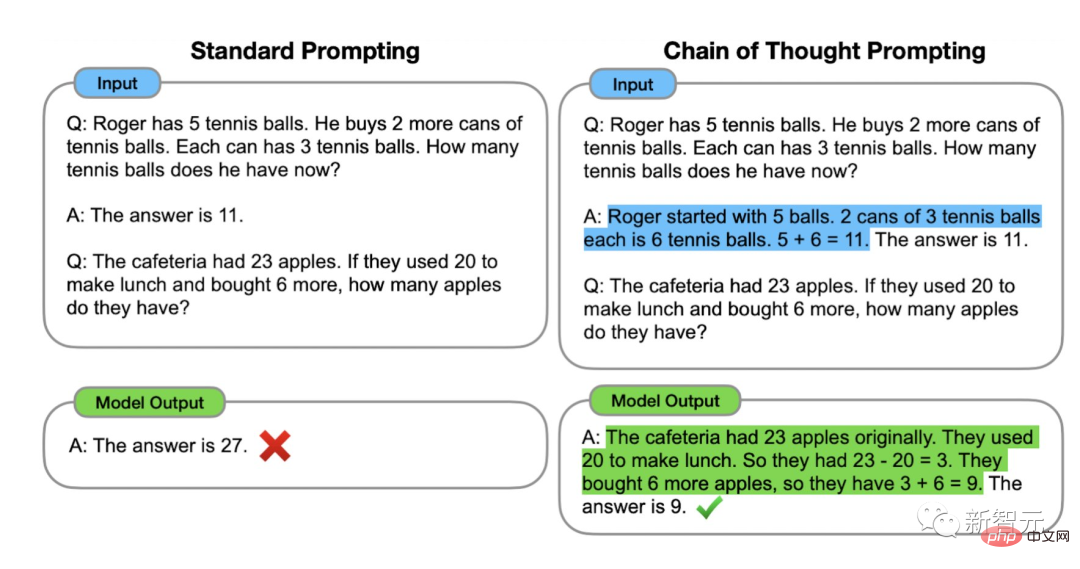
次の例は、「スケーリング命令 - 微調整された言語モデル」から抜粋したものです。このうち、オレンジ色は命令、ピンク色は入力と出力、青色は CoT 推論を示します。
論文では、CoT 微調整を使用したモデルは、常識、算術、記号推論を含むタスクでより優れたパフォーマンスを発揮すると指摘しています。 さらに、CoT 微調整は、特にモデルの破損 (「申し訳ありませんが、回答できません」) を避けるために、機密性の高いトピックに対して非常に効果的です (RLHF よりも優れている場合もあります)。
指示に安全に従う先ほど述べたように、指示に合わせて微調整された言語モデルは、常に有益で安全な応答を生成できるとは限りません。 たとえば、「申し訳ありませんが、わかりません」などの役に立たない答えを返したり、デリケートな話題を提起したユーザーに対して危険な応答を出力したりして逃げます。 この動作を改善するために、研究者は、教師あり微調整 (SFT) の形式を通じて、高品質の人間による注釈付きデータの基本言語モデルを微調整し、それによってモデルの有用性と無害性を向上させます。
SFT と IFT の関係は非常に密接です。 IFT は SFT のサブセットとして見ることができます。最近の文献では、SFT フェーズは、IFT 後に完了する特定の命令トピックではなく、セキュリティ トピックに使用されることがよくあります。 将来的には、その分類と説明に、より明確な使用例が含まれるはずです。 さらに、Google の LaMDA は、一連のルールに基づいたセキュリティ アノテーションを持つ、安全にアノテーションが付けられた会話データ セットにも基づいて微調整されています。 これらのルールは研究者によって事前に定義および開発されることが多く、危害、差別、誤った情報などを含む幅広いトピックをカバーしています。 AI チャットボットの次のステップAI チャットボットに関しては、次のような未解決の問題がまだ多くあります: 1. RL人間のフィードバックから学ぶことはどのくらい重要ですか?より高品質のデータトレーニングを使用して、IFT または SFT で RLHF のパフォーマンスを得ることができますか? 2. Sparrow の SFT RLHF のセキュリティは、LaMDA で SFT を使用する場合とどのように比較されますか? 3. すでに IFT、SFT、CoT、RLHF があることを考えると、さらにどの程度の事前トレーニングが必要でしょうか?トレードオフは何ですか?最良の基本モデル (パブリックとプライベートの両方) はどれですか? 4. これらのモデルは現在、研究者が特に故障モードを検索し、明らかになった問題に基づいて今後のトレーニング (ヒントや方法を含む) に影響を与えるように慎重に設計されています。これらの方法の効果を体系的に文書化し、再現するにはどうすればよいでしょうか? 要約すると、1. トレーニング データと比較すると、命令の微調整に必要な部分はごくわずかです (数百桁)。 2. 教師あり微調整では人間による注釈を使用して、モデルの出力をより安全かつ有用なものにします。 3. CoT の微調整により、ステップバイステップの思考タスクにおけるモデルのパフォーマンスが向上し、モデルが機密問題を常に回避することがなくなります。 参考: https://huggingface.co/blog/dialog-agents |







以上がChatGPT は、Google、Meta、OpenAI 間のチャットボット競争に焦点を当て、LeCun の不満を話題の焦点にしていますの詳細内容です。詳細については、PHP 中国語 Web サイトの他の関連記事を参照してください。

ホットAIツール

Undresser.AI Undress
リアルなヌード写真を作成する AI 搭載アプリ

AI Clothes Remover
写真から衣服を削除するオンライン AI ツール。

Undress AI Tool
脱衣画像を無料で

Clothoff.io
AI衣類リムーバー

AI Hentai Generator
AIヘンタイを無料で生成します。

人気の記事
ホットツール

メモ帳++7.3.1
使いやすく無料のコードエディター

SublimeText3 中国語版
中国語版、とても使いやすい

ゼンドスタジオ 13.0.1
強力な PHP 統合開発環境

ドリームウィーバー CS6
ビジュアル Web 開発ツール

SublimeText3 Mac版
神レベルのコード編集ソフト(SublimeText3)
ホットトピック



 ChatGPT では、無料ユーザーが 1 日あたりの制限付きで DALL-E 3 を使用して画像を生成できるようになりました
Aug 09, 2024 pm 09:37 PM
ChatGPT では、無料ユーザーが 1 日あたりの制限付きで DALL-E 3 を使用して画像を生成できるようになりました
Aug 09, 2024 pm 09:37 PM
DALL-E 3は、前モデルより大幅に改良されたモデルとして2023年9月に正式導入されました。これは、複雑な詳細を含む画像を作成できる、これまでで最高の AI 画像ジェネレーターの 1 つと考えられています。ただし、発売当初は対象外でした
 新しい手頃な価格の Meta Quest 3S VR ヘッドセットが FCC に登場、発売が近いことを示唆
Sep 04, 2024 am 06:51 AM
新しい手頃な価格の Meta Quest 3S VR ヘッドセットが FCC に登場、発売が近いことを示唆
Sep 04, 2024 am 06:51 AM
Meta Connect 2024イベントは9月25日から26日に予定されており、このイベントで同社は新しい手頃な価格の仮想現実ヘッドセットを発表すると予想されている。 Meta Quest 3S であると噂されている VR ヘッドセットが FCC のリストに掲載されたようです。この提案
 GPT4o レベルを超える初のオープンソース モデル! Llama 3.1 がリーク: 4,050 億のパラメータ、ダウンロード リンク、モデル カードが利用可能
Jul 23, 2024 pm 08:51 PM
GPT4o レベルを超える初のオープンソース モデル! Llama 3.1 がリーク: 4,050 億のパラメータ、ダウンロード リンク、モデル カードが利用可能
Jul 23, 2024 pm 08:51 PM
GPUを準備しましょう!ついにLlama3.1が登場しましたが、ソースはMeta公式ではありません。今日、新しい Llama 大型モデルのリーク ニュースが Reddit で話題になり、基本モデルに加えて、8B、70B、最大パラメータ 405B のベンチマーク結果も含まれています。以下の図は、Llama3.1 の各バージョンと OpenAIGPT-4o および Llama38B/70B の比較結果を示しています。 70B バージョンでも複数のベンチマークで GPT-4o を上回っていることがわかります。画像ソース: https://x.com/mattshumer_/status/1815444612414087294 明らかに、8B と 70 のバージョン 3.1
 OpenAI Super Alignment チームの遺作: 2 つの大きなモデルがゲームをプレイし、出力がより理解しやすくなる
Jul 19, 2024 am 01:29 AM
OpenAI Super Alignment チームの遺作: 2 つの大きなモデルがゲームをプレイし、出力がより理解しやすくなる
Jul 19, 2024 am 01:29 AM
AIモデルによって与えられた答えがまったく理解できない場合、あなたはそれをあえて使用しますか?機械学習システムがより重要な分野で使用されるにつれて、なぜその出力を信頼できるのか、またどのような場合に信頼してはいけないのかを実証することがますます重要になっています。複雑なシステムの出力に対する信頼を得る方法の 1 つは、人間または他の信頼できるシステムが読み取れる、つまり、考えられるエラーが発生する可能性がある点まで完全に理解できる、その出力の解釈を生成することをシステムに要求することです。見つかった。たとえば、司法制度に対する信頼を築くために、裁判所に対し、決定を説明し裏付ける明確で読みやすい書面による意見を提供することを求めています。大規模な言語モデルの場合も、同様のアプローチを採用できます。ただし、このアプローチを採用する場合は、言語モデルが
 Embedding サービスのローカル実行パフォーマンスは OpenAI Text-Embedding-Ada-002 を上回っており、とても便利です。
Apr 15, 2024 am 09:01 AM
Embedding サービスのローカル実行パフォーマンスは OpenAI Text-Embedding-Ada-002 を上回っており、とても便利です。
Apr 15, 2024 am 09:01 AM
Ollama は、Llama2、Mistral、Gemma などのオープンソース モデルをローカルで簡単に実行できるようにする非常に実用的なツールです。この記事では、Ollamaを使ってテキストをベクトル化する方法を紹介します。 Ollama をローカルにインストールしていない場合は、この記事を読んでください。この記事では、nomic-embed-text[2] モデルを使用します。これは、短いコンテキストおよび長いコンテキストのタスクにおいて OpenAI text-embedding-ada-002 および text-embedding-3-small よりも優れたパフォーマンスを発揮するテキスト エンコーダーです。 o が正常にインストールされたら、nomic-embed-text サービスを開始します。
 新しくリリースされた Llama 3 を体験する 6 つの簡単な方法!
Apr 19, 2024 pm 12:16 PM
新しくリリースされた Llama 3 を体験する 6 つの簡単な方法!
Apr 19, 2024 pm 12:16 PM
昨夜、Meta は Llama38B および 70B モデルをリリースしました。Llama3 の命令調整モデルは、会話/チャットのユースケース向けに微調整および最適化されており、一般的なベンチマークで多くの既存のオープンソース チャット モデルを上回っています。たとえば、Gemma7B や Mistral7B などです。 Llama+3 モデルはデータとスケールを改善し、新たな高みに到達します。これは、Meta によって最近リリースされた 2 つのカスタム 24K GPU クラスター上の 15T トークンを超えるデータでトレーニングされました。このトレーニング データセットは Llama2 の 7 倍大きく、4 倍のコードが含まれています。これにより、Llama モデルの機能が現在の最高レベルになり、Llama2 の 2 倍である 8K を超えるテキスト長がサポートされます。下
 最強モデルLlama 3.1 405Bが正式リリース、ザッカーバーグ氏:オープンソースが新時代をリード
Jul 24, 2024 pm 08:23 PM
最強モデルLlama 3.1 405Bが正式リリース、ザッカーバーグ氏:オープンソースが新時代をリード
Jul 24, 2024 pm 08:23 PM
たった今、待望の Llama 3.1 が正式にリリースされました。 Metaは「オープンソースは新たな時代を導く」と公式に声を上げた。 Meta 氏は公式ブログで、「今日まで、オープンソースの大規模言語モデルは、機能とパフォーマンスの点でクローズド モデルに比べてほとんど遅れを取ってきました。今、私たちはオープンソースが主導する新しい時代の到来を告げています。私たちは MetaLlama3.1405B を一般公開しました」と述べました。これは世界で最大かつ最も強力なオープンソースの基本モデルであると私たちは信じています。現在までに、Llama のすべてのバージョンの合計ダウンロード数は 3 億回を超えており、Meta の創設者兼 CEO のザッカーバーグ氏も次のように書いています。」長い記事「OpenSourceAIsthePathForward」、
 Llama3が突然やってくる!オープンソース コミュニティが再び沸騰: GPT4 レベルのモデルに無料でアクセスできる時代が到来
Apr 19, 2024 pm 12:43 PM
Llama3が突然やってくる!オープンソース コミュニティが再び沸騰: GPT4 レベルのモデルに無料でアクセスできる時代が到来
Apr 19, 2024 pm 12:43 PM
ラマ3が登場!先ほどMetaの公式サイトが更新され、Llamaの380億バージョンと700億パラメータのバージョンが公式から発表されました。そして、それは発売後のオープンソース SOTA です。メタ公式データは、Llama38B および 70B バージョンがそれぞれのパラメーター スケールですべての対戦相手を上回っていることを示しています。 8B モデルは、MMLU、GPQA、HumanEval などの多くのベンチマークで Gemma7B および Mistral7BInstruct を上回ります。 70B モデルは人気のクローズドソース フライド チキン Claude3Sonnet を超え、Google の GeminiPro1.5 と行ったり来たりしています。 Huggingface のリンクが公開されるとすぐに、オープンソース コミュニティは再び興奮しました。目の鋭い盲目の学生たちもすぐに発見した
