

DeepMind 氏「AI モデルは減量する必要があり、自己回帰が主流になる」

Transformer を中心とした自己回帰的注意プログラムは、規模の難しさを克服するのが常に困難でした。この目的を達成するために、DeepMind/Google は最近、そのようなプログラムを効果的にスリム化するための良い方法を提案する新しいプロジェクトを設立しました。
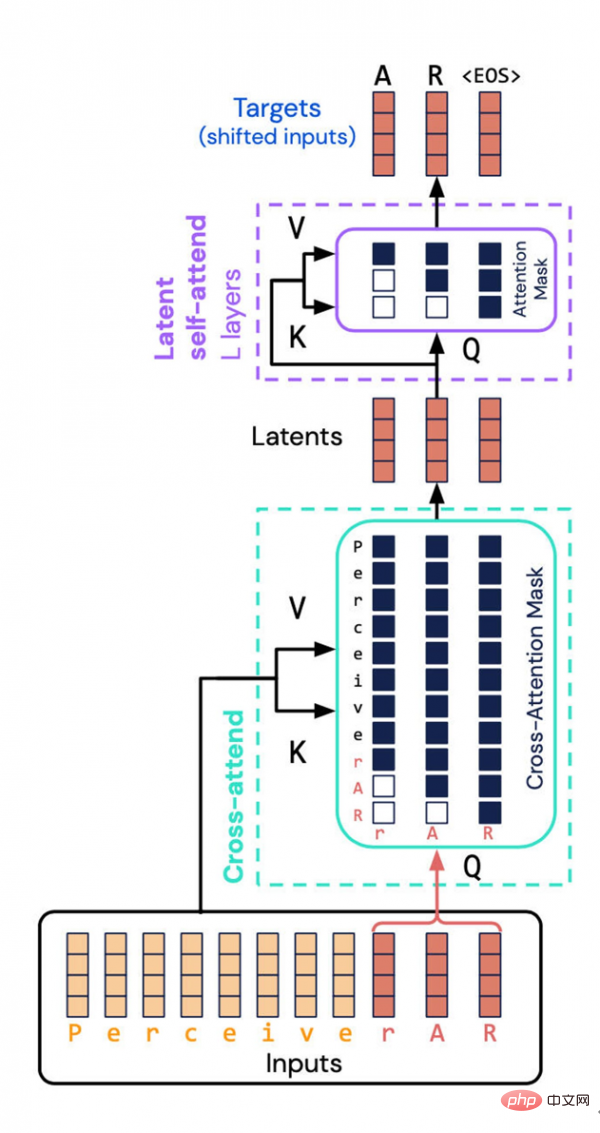
DeepMind と Google Brain によって作成された Perceiver AR アーキテクチャは、潜在空間への入力と出力の組み合わせプロパティを計算するという、リソースを大量に消費するタスクを回避します。代わりに、彼らは潜在空間に「因果マスキング」を導入し、それによって典型的な Transformer の自己回帰順序を実現しました。
人工知能/ディープラーニングの分野における最も印象的な開発トレンドの 1 つは、モデルのサイズがますます大きくなっているということです。この分野の専門家らは、規模は業績に直接関係していることが多いため、この規模拡大の波は今後も続く可能性が高いと述べている。
しかし、プロジェクトの規模はますます大きくなり、消費されるリソースも当然増加するため、ディープラーニングは社会的および倫理的レベルで新たな問題を引き起こすようになりました。このジレンマは、ネイチャーなどの主流科学誌の注目を集めています。
このため、AI プログラムという古い言葉「効率」に立ち返る必要があるかもしれませんが、さらなる効率化の余地はあるのでしょうか?
DeepMind 部門と Google Brain 部門の科学者たちは、コンピューティング リソースの使用効率を向上させることを期待して、昨年発売したニューラル ネットワーク Perceiver を最近修正しました。
新しいプログラムの名前は Perceiver AR です。ここでの AR は「自己回帰」に由来しており、これは今日ますます増えている深層学習プログラムのもう 1 つの開発方向でもあります。自己回帰は、マシンが出力をプログラムへの新しい入力として使用できるようにする手法であり、再帰的な操作により、複数の要素が相互に関連するアテンション マップを形成します。
Google が 2017 年に発売した人気のニューラル ネットワーク Transformer にも、この自己回帰特性があります。実際、後の GPT-3 と Perceiver の最初のバージョンでは、自己回帰的な技術的路線が継続されました。
Perceiver AR が登場する前は、今年 3 月に発売された Perceiver IO が Perceiver の 2 番目のバージョンで、さらに遡ると昨年の今頃リリースされた Perceiver の最初のバージョンでした。
Perceiver の最初の革新は、Transformer を使用し、テキスト、音声、画像などのさまざまな入力を柔軟に吸収できるように調整し、特定の種類の入力への依存から脱却することです。これにより、研究者は複数の入力タイプを使用してニューラル ネットワークを開発できるようになります。
時代の流れの一員として、Perceiver は他のモデル プロジェクトと同様に、異なる入力モードと異なるタスク ドメインを混合するために自己回帰注意メカニズムを使用し始めました。このようなユースケースには、Google の Pathways、DeepMind の Gato、Meta の data2vec も含まれます。
今年の 3 月、Perceiver の最初のバージョンの作成者である Andrew Jagle と彼の同僚チームは、「IO」バージョンをリリースしました。新しいバージョンでは、Perceiver でサポートされる出力タイプが強化され、テキスト言語、オプティカル フロー フィールド、オーディオビジュアル シーケンス、さらには順序のないシンボルのセットなど、さまざまな構造を含む多数の出力が可能になります。 Perceiver IO は、ゲーム「StarCraft 2」の操作命令を生成することもできます。
この最新の論文では、Perceiver AR は長いコンテキストに対する一般的な自己回帰モデリングを実装することができました。しかし、研究中に、Jaegle と彼のチームは、さまざまなマルチモーダル入出力タスクを処理するときにモデルをどのようにスケールするかという新しい課題にも遭遇しました。
問題は、Transformer の自己回帰品質、および同様に入力から出力へのアテンション マップを構築するプログラムでは、最大数十万要素という大規模な配布サイズが必要であることです。
これは、注意メカニズムの致命的な弱点です。より正確には、アテンション マップの確率分布を構築するには、すべてに注意を払う必要があります。
#Jagle と彼のチームが論文で述べたように、入力内で相互に比較する必要があるものの数が増加するにつれて、モデルによるコンピューティング リソースの消費量はますます誇張されます。 #この種の長いコンテキスト構造と Transformer の計算の性質の間には矛盾があります。トランスフォーマーは入力に対してセルフアテンション操作を繰り返し実行するため、計算要件は入力の長さに対して二次関数的に、またモデルの深さに対して線形的に増加します。入力データが増えるほど、観測されたデータ内容に対応する入力タグも多くなり、入力データのパターンはより微妙で複雑になり、生成されたパターンをモデル化するにはより深い層を使用する必要があります。コンピューティング能力が限られているため、Transformer ユーザーはモデル入力を切り詰めるか (より遠くのパターンの観察を防ぐ)、またはモデルの深さを制限する (その結果、複雑なパターンをモデル化する表現力が失われます) ことを余儀なくされます。 実際、Perceiver の最初のバージョンでは、Transformer の効率を向上させることも試みました。つまり、アテンションを直接実行するのではなく、入力の潜在的な表現に対してアテンションを実行することでした。このようにして、大規模な入力配列を処理するための計算能力要件を、「大規模なディープ ネットワークに対応する計算能力要件から (切り離す)」ことができます。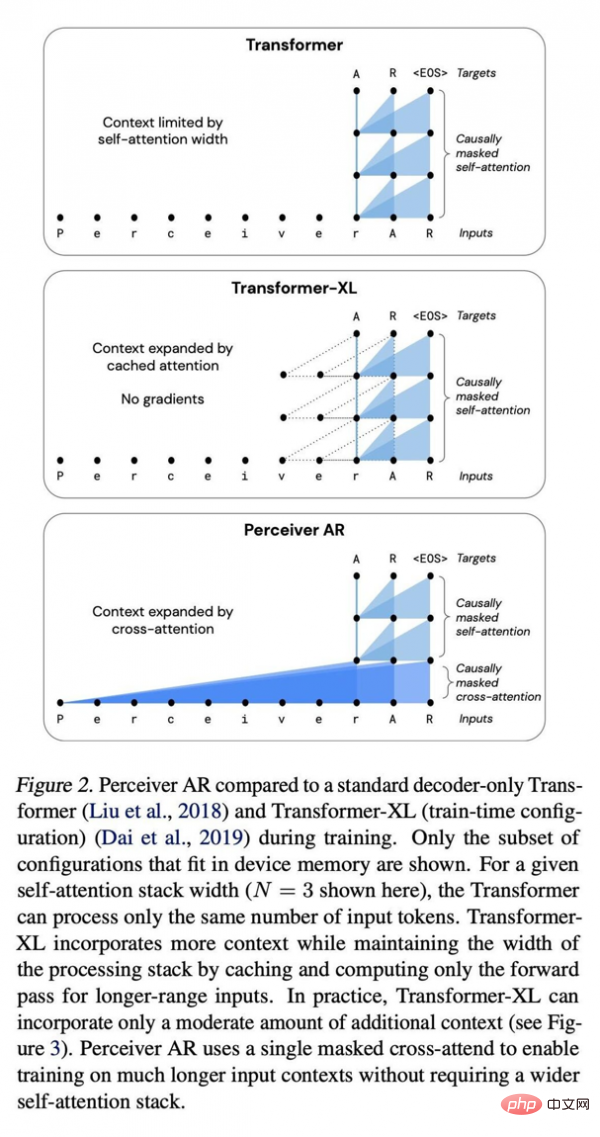
潜在部分では、入力表現が圧縮されるため、より効率的な注意エンジンになります。このようにして、「ディープネットワークでは、計算のほとんどが実際にセルフアテンションスタック上で行われ」、無数の入力を操作する必要がなくなります。
しかし、基礎となる表現には順序の概念がないため、Perceiver は Transformer のような出力を生成できないため、課題はまだ存在します。自己回帰では順序が重要であり、各出力は、後の積ではなく、その前の入力の積である必要があります。
しかし、各潜在モデルは位置に関係なくすべての入力に注意を払うため、「各モデルの出力が以前の入力にのみ依存する必要がある自己回帰生成の場合」、Perceiver は直接適用できないと研究者らは書いています。 ."
Perceiver AR に関しては、研究チームはさらに一歩進んで、自動回帰を可能にするためにシーケンスを Perceiver に挿入しました。
ここで重要なのは、入力と潜在表現に対していわゆる「因果マスキング」を実行することです。入力側では、因果マスキングは「クロスアテンション」を実行しますが、基礎となる表現側では、プログラムが指定されたシンボルの前にあるもののみに注意を払うように強制されます。この方法では、Transformer の方向性が復元され、それでも総計算量を大幅に削減できます。
その結果、Perceiver AR は、より多くの入力に基づいて Transformer に匹敵するモデリング結果を達成できますが、パフォーマンスは大幅に向上しています。
彼らは、「Perceiver AR は、合成コピー タスクにおいて、少なくとも 100,000 トークン離れた長いコンテキスト パターンを完全に識別して学習できます。」と書いていますが、それに比べて、Transformer には 2048 トークンというハード リミットがあります。 、コンテキストが長くなり、プログラム出力がより複雑になります。
純粋なデコーダを広く使用する Transformer および Transformer-XL アーキテクチャと比較して、Perceiver AR はより効率的であり、ターゲットの予算に応じてテスト中に使用される実際のコンピューティング リソースを柔軟に変更できます。
論文では、同じ注意条件下では、Perceiver AR の計算にかかる実時間は大幅に短縮され、同じ計算能力バジェットの下でより多くのコンテキスト (つまり、より多くの入力シンボル) を吸収できると書いています。
Transformer のコンテキストの長さは 2048 トークンに制限されています。これは、6 つのレイヤーのみをサポートすることに相当します。これは、より大きなモデルとより長いコンテキストには大量のメモリが必要となるためです。同じ 6 層構成を使用して、Transformer-XL メモリのコンテキストの合計長を 8192 トークンまで拡張できます。 Perceiver AR はコンテキストの長さを 65k マーカーまで拡張でき、さらに最適化すると 100k を超えることも予想されます。
これらすべてにより、コンピューティングがより柔軟になります。「テスト中に特定のモデルが生成する計算量をより適切に制御できるため、速度とパフォーマンスの安定したバランスを実現できます。」
また、Jaegle らは、このアプローチは単語記号に限定されず、あらゆる入力タイプに有効であると書いています。たとえば、画像内のピクセルをサポートできます。
因果関係マスキング手法が適用されている限り、並べ替え可能な入力に対して同じプロセスが機能します。たとえば、画像の RGB チャネルは、シーケンス内の各ピクセルの R、G、B カラー チャネルを順番または順不同でデコードすることにより、ラスター スキャン順序で並べ替えることができます。
著者らは Perceiver に大きな可能性を見出し、論文で「Perceiver AR はロングコンテキストの汎用自己回帰モデルの理想的な候補です。」と書いています。計算効率が高くなると、別の追加の不安定要因に対処する必要があります。著者らは、研究コミュニティが最近、「スパース性」(つまり、一部の入力要素に割り当てられる重要性を制限するプロセス)を通じて自己回帰的注意の計算要件を削減しようとしていると指摘しています。
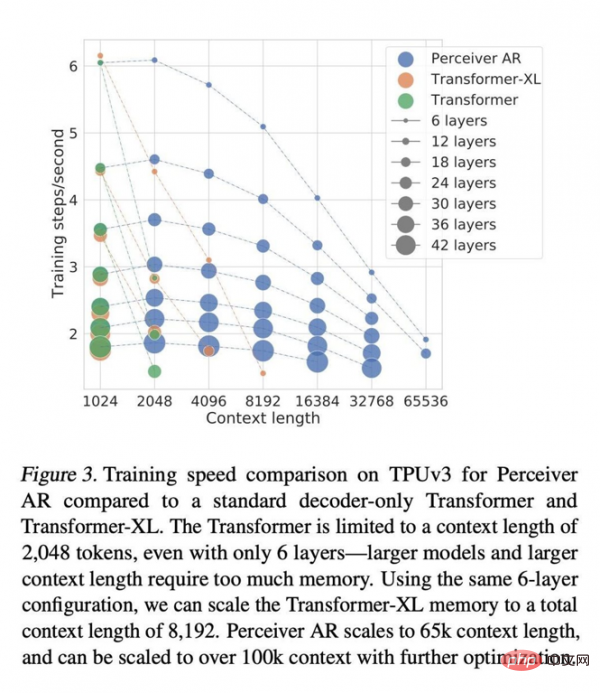
同じ実測時間内で、Perceiver AR は同じレイヤー数でより多くの入力を実行できます。 . シンボルを実行するか、同じ数の入力シンボルの実行で計算時間を大幅に短縮します。著者らは、この優れた柔軟性が大規模ネットワークの一般的な効率向上手法につながる可能性があると考えています。
しかし、スパーシティには独自の欠点もあります。主な欠点は、柔軟性が高すぎることです。この論文では、「スパース手法を使用する欠点は、このスパース性を手動調整またはヒューリスティック手法で作成する必要があることです。これらのヒューリスティックは特定のフィールドにのみ適用できることが多く、調整が難しいことがよくあります。」と述べています。 2017年にリリースされたプロジェクトはまばらなプロジェクトです。
彼らは次のように説明しました。「対照的に、私たちの仕事では、アテンション層でスパースパターンを手動で作成する必要はありませんが、どのロングコンテキスト入力がより多くの注意を必要とし、通過する必要があるかをネットワークが自律的に学習できるようになります。ネットワークは伝播します。」
論文はまた、「最初のクロスアテンション操作はシーケンス内の位置の数を減らし、スパース学習の一種とみなすことができます。」
と付け加えています。この方法で学習されたスパース性自体は、今後数年間で深層学習モデル ツールキットの別の強力なツールになる可能性があります。
以上がDeepMind 氏「AI モデルは減量する必要があり、自己回帰が主流になる」の詳細内容です。詳細については、PHP 中国語 Web サイトの他の関連記事を参照してください。

ホットAIツール

Undresser.AI Undress
リアルなヌード写真を作成する AI 搭載アプリ

AI Clothes Remover
写真から衣服を削除するオンライン AI ツール。

Undress AI Tool
脱衣画像を無料で

Clothoff.io
AI衣類リムーバー

Video Face Swap
完全無料の AI 顔交換ツールを使用して、あらゆるビデオの顔を簡単に交換できます。

人気の記事
ホットツール

メモ帳++7.3.1
使いやすく無料のコードエディター

SublimeText3 中国語版
中国語版、とても使いやすい

ゼンドスタジオ 13.0.1
強力な PHP 統合開発環境

ドリームウィーバー CS6
ビジュアル Web 開発ツール

SublimeText3 Mac版
神レベルのコード編集ソフト(SublimeText3)
ホットトピック
 7773
7773
 15
1644
14
1399
52
1296
25
1234
29
15
1644
14
1399
52
1296
25
1234
29

 WorldCoin(WLD)価格予測2025-2031:WLDは2031年までに4ドルに達しますか?
Apr 21, 2025 pm 02:42 PM
WorldCoin(WLD)価格予測2025-2031:WLDは2031年までに4ドルに達しますか?
Apr 21, 2025 pm 02:42 PM
WorldCoin(WLD)は、独自の生体認証とプライバシー保護メカニズムを備えた暗号通貨市場で際立っており、多くの投資家の注目を集めています。 WLDは、特にOpenai人工知能技術と組み合わせて、革新的なテクノロジーを備えたAltcoinsの間で驚くほど演奏しています。しかし、デジタル資産は今後数年間でどのように振る舞いますか? WLDの将来の価格を一緒に予測しましょう。 2025年のWLD価格予測は、2025年にWLDで大幅に増加すると予想されています。市場分析は、平均WLD価格が1.31ドルに達する可能性があり、最大1.36ドルであることを示しています。ただし、クマ市場では、価格は約0.55ドルに低下する可能性があります。この成長の期待は、主にWorldCoin2によるものです。
 ビットコイン完成品構造の分析チャートは何ですか?描く方法は?
Apr 21, 2025 pm 07:42 PM
ビットコイン完成品構造の分析チャートは何ですか?描く方法は?
Apr 21, 2025 pm 07:42 PM
ビットコイン構造分析チャートを描画する手順には、次のものが含まれます。1。図面の目的と視聴者を決定します。2。適切なツールを選択します。3。フレームワークを設計し、コアコンポーネントを入力します。4。既存のテンプレートを参照してください。完全な手順チャートが正確で理解しやすいことを確認してください。
 なぜ仮想通貨価格の上昇または下落があるのですか?なぜ仮想通貨価格の上昇または下落があるのですか?
Apr 21, 2025 am 08:57 AM
なぜ仮想通貨価格の上昇または下落があるのですか?なぜ仮想通貨価格の上昇または下落があるのですか?
Apr 21, 2025 am 08:57 AM
仮想通貨価格の上昇の要因には、次のものが含まれます。1。市場需要の増加、2。供給の減少、3。刺激された肯定的なニュース、4。楽観的な市場感情、5。マクロ経済環境。衰退要因は次のとおりです。1。市場需要の減少、2。供給の増加、3。ネガティブニュースのストライキ、4。悲観的市場感情、5。マクロ経済環境。
 クロスチェーントランザクションとはどういう意味ですか?クロスチェーントランザクションとは何ですか?
Apr 21, 2025 pm 11:39 PM
クロスチェーントランザクションとはどういう意味ですか?クロスチェーントランザクションとは何ですか?
Apr 21, 2025 pm 11:39 PM
クロスチェーントランザクションをサポートする交換:1。Binance、2。Uniswap、3。Sushiswap、4。CurveFinance、5。Thorchain、6。1inchExchange、7。DLNTrade、これらのプラットフォームはさまざまな技術を通じてマルチチェーン資産トランザクションをサポートします。
 通貨サークル市場に関するリアルタイムデータの上位10の無料プラットフォーム推奨事項がリリースされます
Apr 22, 2025 am 08:12 AM
通貨サークル市場に関するリアルタイムデータの上位10の無料プラットフォーム推奨事項がリリースされます
Apr 22, 2025 am 08:12 AM
初心者に適した暗号通貨データプラットフォームには、Coinmarketcapと非小さいトランペットが含まれます。 1。CoinMarketCapは、初心者と基本的な分析のニーズに合わせて、グローバルなリアルタイム価格、市場価値、取引量のランキングを提供します。 2。小さい引用は、中国のユーザーが低リスクの潜在的なプロジェクトをすばやくスクリーニングするのに適した中国フレンドリーなインターフェイスを提供します。
 カーネルエアドロップ報酬を獲得する方法バイナンスフルプロセス戦略
Apr 21, 2025 pm 01:03 PM
カーネルエアドロップ報酬を獲得する方法バイナンスフルプロセス戦略
Apr 21, 2025 pm 01:03 PM
暗号通貨の賑やかな世界では、新しい機会が常に現れます。現在、Kerneldao(Kernel)Airdropアクティビティは多くの注目を集め、多くの投資家の注目を集めています。それで、このプロジェクトの起源は何ですか? BNBホルダーはそれからどのような利点を得ることができますか?心配しないでください、以下はあなたのためにそれを一つ一つ明らかにします。
 Aavenomicsは、Aaveプロトコルトークンを変更し、Tokenの買戻しを導入するための推奨事項です。
Apr 21, 2025 pm 06:24 PM
Aavenomicsは、Aaveプロトコルトークンを変更し、Tokenの買戻しを導入するための推奨事項です。
Apr 21, 2025 pm 06:24 PM
Aavenomicsは、Aaveプロトコルトークンを変更し、Aavedaoの定足数を実装したToken Reposを導入する提案です。 Aave Project Chain(ACI)の創設者であるMarc Zellerは、これをXで発表し、契約の新しい時代をマークしていることに注目しました。 Aave Chain Initiative(ACI)の創設者であるMarc Zellerは、Aavenomicsの提案にAave Protocolトークンの変更とトークンリポジトリの導入が含まれていると発表しました。 Zellerによると、これは契約の新しい時代を告げています。 Aavedaoのメンバーは、水曜日の週に100でした。
 Rexas Finance(RXS)は、2025年にSolana(Sol)、Cardano(ADA)、XRP、Dogecoin(Doge)を上回ることができます
Apr 21, 2025 pm 02:30 PM
Rexas Finance(RXS)は、2025年にSolana(Sol)、Cardano(ADA)、XRP、Dogecoin(Doge)を上回ることができます
Apr 21, 2025 pm 02:30 PM
不安定な暗号通貨市場では、投資家は人気のある通貨を超えた代替品を探しています。 Solana(Sol)、Cardano(ADA)、XRP、Dogecoin(DOGE)などのよく知られた暗号通貨も、市場の感情、規制の不確実性、スケーラビリティなどの課題に直面しています。ただし、新しい新興プロジェクトであるRexasFinance(RXS)が出現しています。それは有名人の効果や誇大広告に依存するのではなく、現実世界の資産(RWA)とブロックチェーン技術を組み合わせて投資家に革新的な投資方法を提供することに焦点を当てています。この戦略により、2025年の最も成功したプロジェクトの1つになることを望んでいます。Rexasfi
