

私が目覚めたとき、機械学習コミュニティはショック状態にありました。
最新の研究により、GPT-3 に「ステップごとに考えてみましょう」と言うだけで、これまで答えられなかった質問に正しく答えることができることが判明したためです。
たとえば、次の例:
16 個のボールの半分はゴルフ ボールで、これらのゴルフ ボールの半分は青です。青いゴルフ ボールは合計で何個ありますか?

(問題は難しくありませんが、これはゼロサンプル学習であることに注意してください。これは、AI のトレーニング段階で同様の問題が発生したことがないことを意味します。)
GPT が必要な場合 -3 「答えは何ですか」を直接書くと、間違った答えが返されます: 8。
しかし、ステップごとに考えるための「呪文」を追加すると、GPT-3 はまず思考のステップを出力し、最終的に正しい答えを返します: 4!
そしてこれは偶然ではなく、研究チームは論文で完全に検証しました。
上記の質問は、数学的問題を解決する言語モデルの能力を特にテストする古典的な MutiArith データ セットからのものです。GPT-3 は当初、ゼロサンプル シナリオでの精度がわずか 17% でした。
この論文では、最も効果的な 9 つのプロンプトワードをまとめていますが、その中で GPT-3 に思考させるために変更した最初の 6 つのワードは、徐々に正解率が 70% 以上に向上しました。

最も単純な「考えてみましょう」(考えてみましょう)でも、57.5% にまで上昇する可能性があります。
幼稚園のおばちゃんが子供をなだめているような気分です...
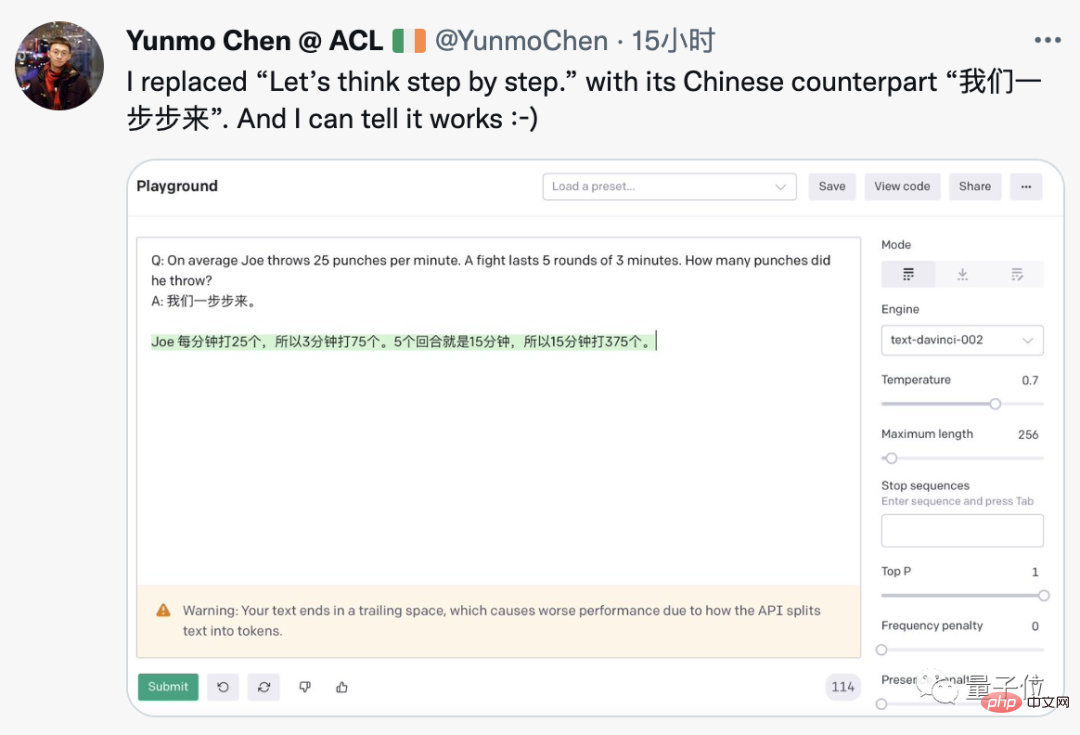
このテクニックは GPT-3 に特別な変更を加える必要はないようです。誰かが OpenAI 公式デモでそれを再現することに成功しています。 . 中国語に変更しても機能します。
英語の質問には中国語のヒントがあり、GPT-3 では正しい中国語の答えが得られます。
この論文を最初にソーシャル ネットワークに転送した Google 研究者は、必要なものが新たに追加されたと述べました。
これを見て、各界の偉い人たちが想像力を膨らませてジョークを言い始めました。
AI に「あなたならできる、私はあなたを信じている」と勧めたらどうなるでしょうか?
AI を脅迫する「時間がなくなりました」または「あなた、「頭に銃を突きつけられた」のはどうですか?
AI に「もっと慎重に運転してください」と言うと、自動運転ソリューション?

これは SF 小説「銀河ヒッチハイク ガイド」のプロットとほぼ同じであると指摘する人もいます。一般的な人工知能を実現する鍵となるのは、AI に正しく質問する方法を知ることです。
それでは、この不思議な現象で何が起こっているのでしょうか?
これは Google Brain と東京大学との共同研究であり、ゼロサンプル シナリオにおける大規模言語モデルのパフォーマンスを調査しています。
論文のタイトル「言語モデルはゼロサンプルの推論者」も、GPT-3 の「言語モデルは少数サンプルの学習者」に敬意を表しています。

使用された手法は、今年 1 月に Google Brain チームによって提案されたばかりの Chain of Thought Prompting (CoT) に属します。

最も初期の CoT は少数サンプル学習に適用され、質問をしながら AI をガイドするための段階的な回答例が示されました。
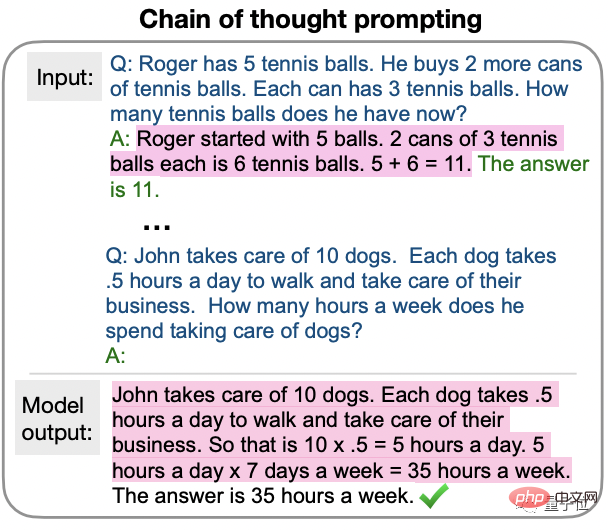
この最新の研究では、ゼロサンプル CoT が提案されています。主な変更点は、サンプル部分を簡略化することです。
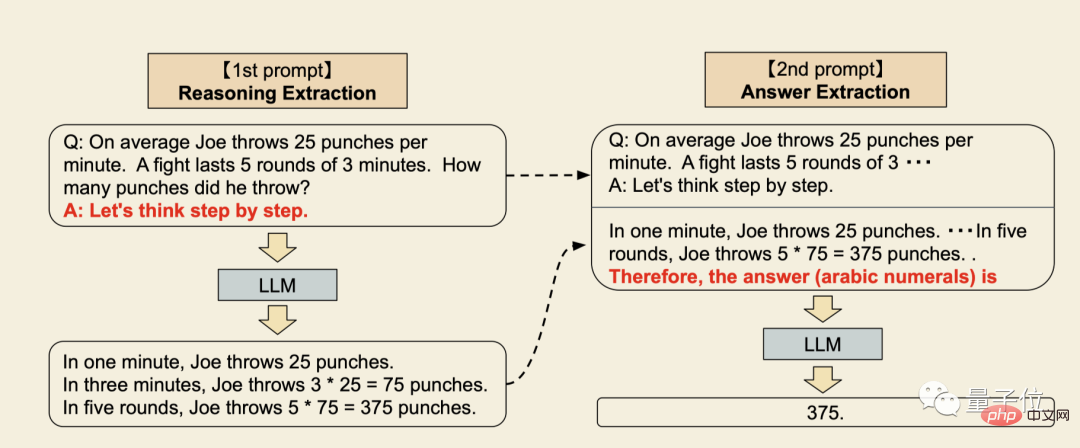
#これの最大の利点は、汎用性があり、さまざまな問題タイプに専用の例を提供する必要がないことです。
この論文では、12 のテストを含むさまざまな問題について十分な実験が行われています。
通常のゼロショット学習と比較して、ゼロショット CoT は 10 個の学習においてより良い結果を達成します。
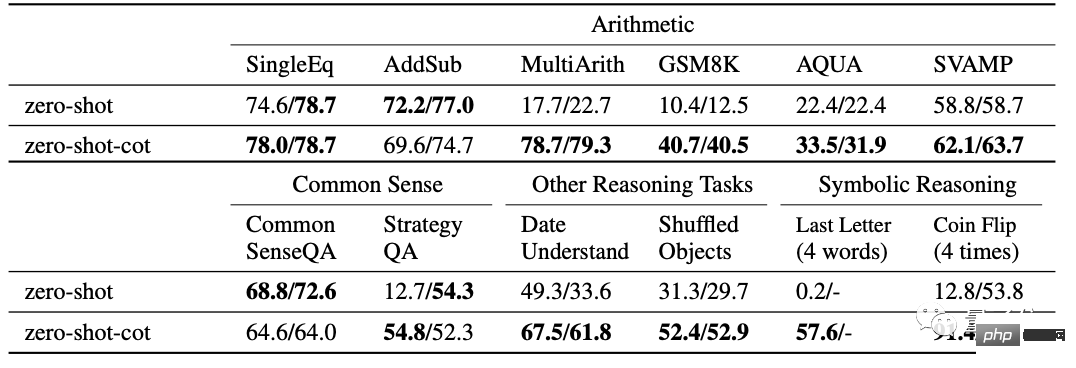
△の右側の値は追加の実験結果です
より難しい MultiArith および GSM8K 数学テストでは、最新バージョンの GPT- 3 Text-davinci が使用されました -002 (175B) はより詳細な実験を行いました。
最良の結果を得るために 8 回試行すると、精度はさらに 93% まで向上します。
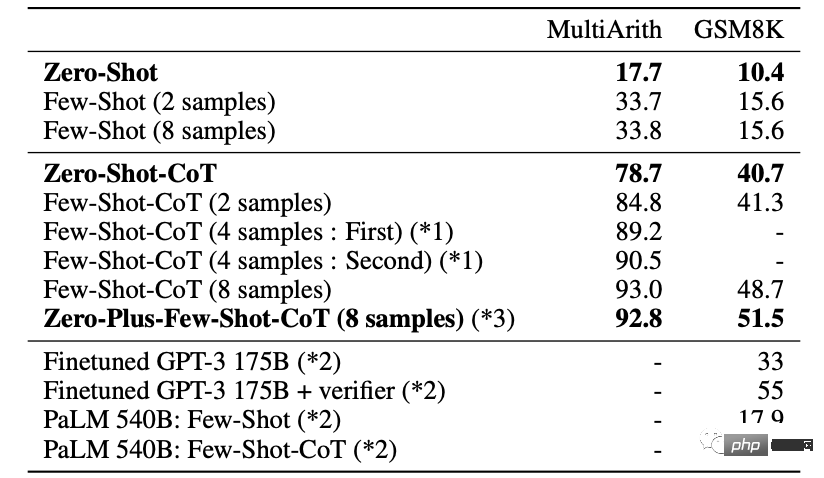
研究者らは、エラー結果の分析で、多くの質問において、AI の推論プロセスは実際には正しいものの、答えが一意の決定に収束できない場合、複数の回答が表示されます。

論文の最後で、研究チームは、この研究がゼロサンプル CoT のベースラインとして機能するだけでなく、学術コミュニティの発展を期待していると提案しました。微調整されたデータ セットと少数サンプルのプロンプト テンプレートを構築することの重要性を認識しています。以前は、大規模な言語モデルのゼロサンプル機能の重要性について十分に検討しました。
研究チームは東京大学松尾研究室の出身です。

責任者の松尾豊教授は、ソフトバンク取締役会初の人工知能の専門家でもあります。

チームメンバーの中の客員教授Gu ShixiangはGoogle Brainチームの出身で、Gu Shixiangは3大巨頭の1人であるヒントンに学士号を取得し、博士号を取得しました。ケンブリッジ大学出身。
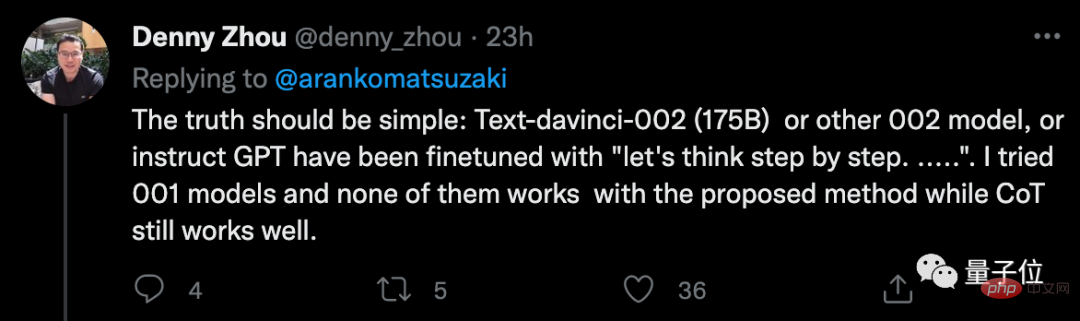
なぜゼロサンプル CoT が機能するのかはまだ解明されていません。
しかし、誰かが実験的に、この方法は GPT-3 (text-davinci-002) にのみ有効であると結論付け、バージョン 001 を試しましたが、ほとんど効果がありませんでした。
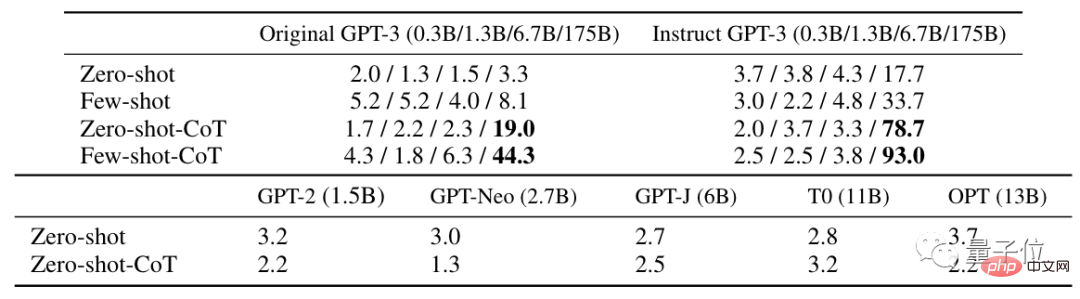
彼は自分がやったことの例を挙げました。
質問: 機械と学習の各単語の最後の文字をつなげてください。
プロンプトに対する GPT-3 の答えは、2 つの単語のすべての文字を接続することです。

それに応じて、著者の 1 人、Gu Shixiang は、実際、「呪文」は GPT の初期バージョンと改良バージョンの両方に影響を与えると答えました。 3 であり、これらの結果は論文にも反映されています。
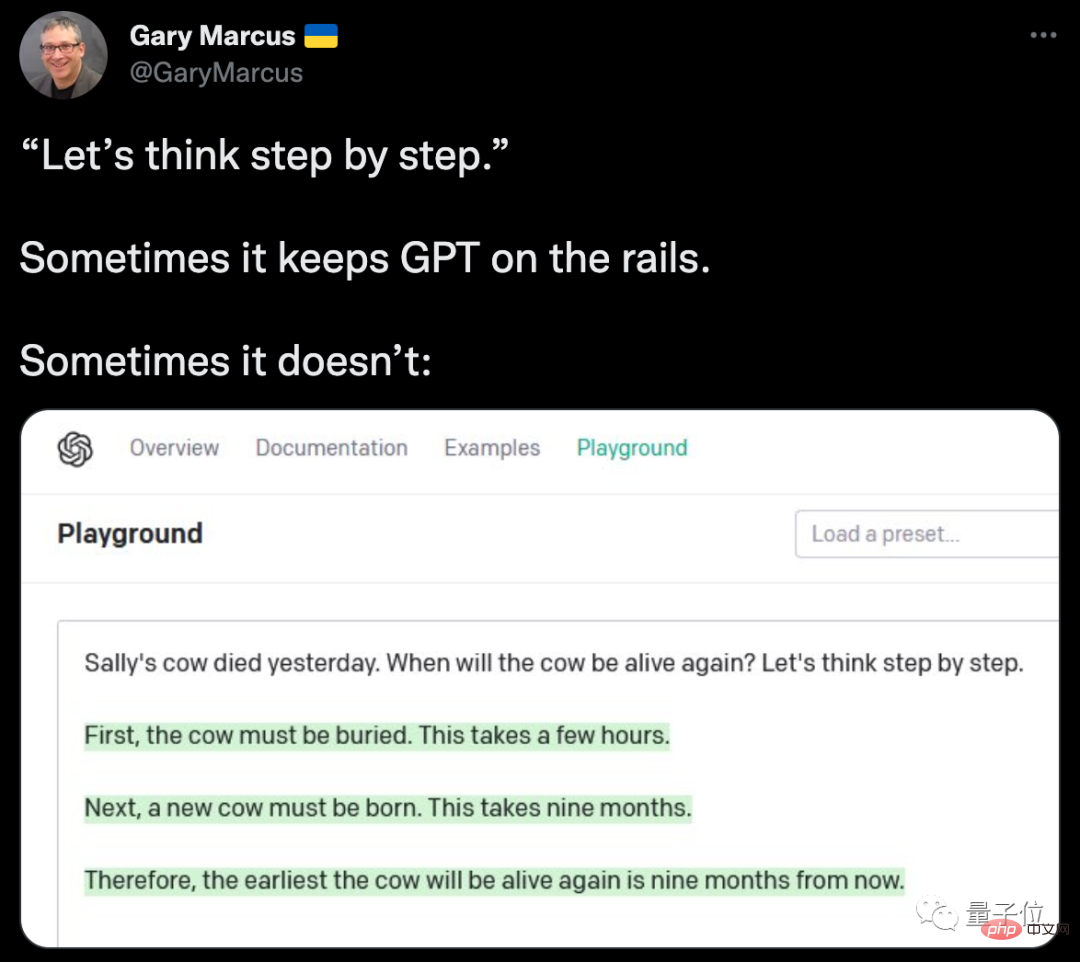
ただし、このような例では AI にちょっとした魔法を加えることが珍しくなく、改善効果がすぐに現れることは注目に値します。
一部のネチズンは、GPT-3 を使用するときにいくつかの中間コマンドを追加すると、実際により満足のいく結果が得られると共有しました。
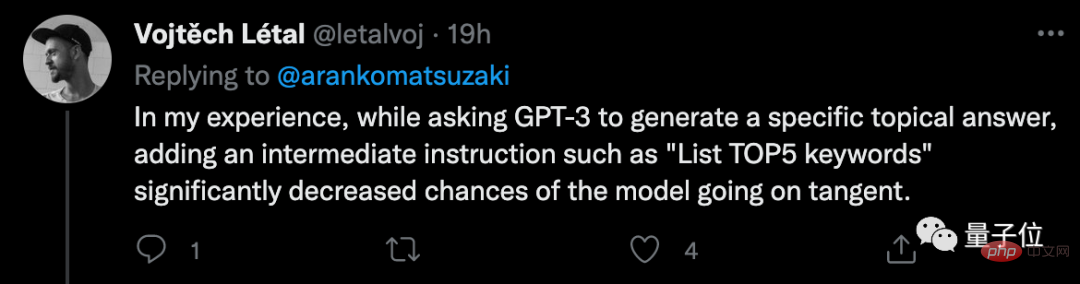
以前、Google と MIT の研究者は、トレーニング言語モデルがデバッグ時にプログラマのように「ポイントをブレーク」する限り、基礎となるアーキテクチャを変更しなくても、モデルは次のようになることを発見しました。コードのおかげで、私の算数能力は急速に向上しました。

原理も非常に単純です。つまり、多くの計算ステップを含むプログラムでは、モデルに各ステップをテキストにエンコードして「Sticky」というファイルに記録させます。一時レジスタ内のメモ「 」。
その結果、モデルの計算プロセスがより明確かつ秩序正しくなり、当然のことながらパフォーマンスが大幅に向上します。
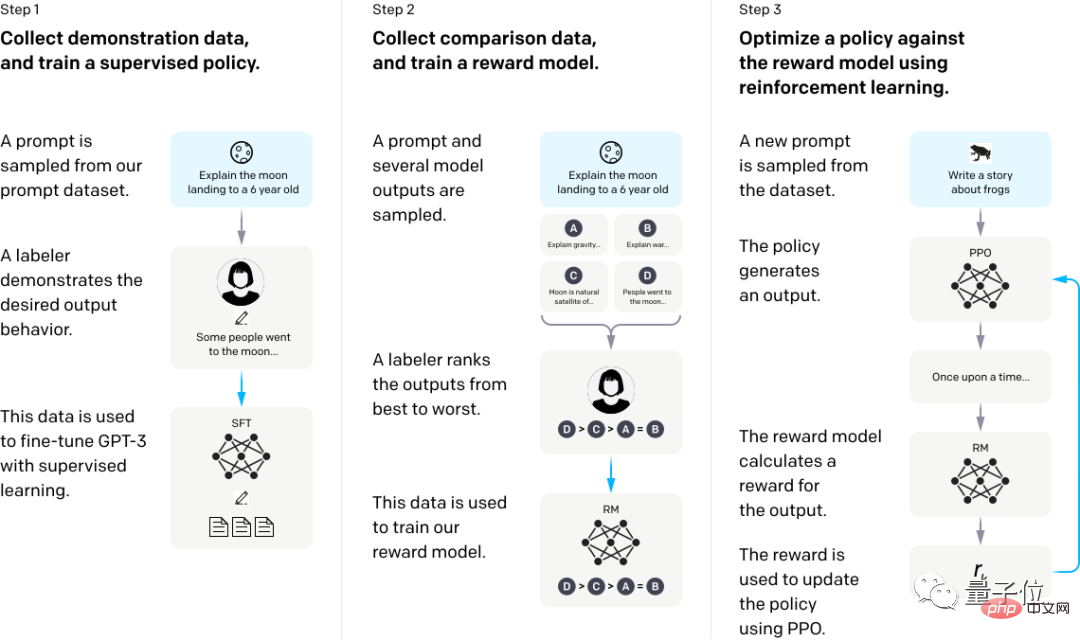
この実験でテストに使用した Instruct GPT-3 もありますが、これも典型的な例です。
GPT-3 に人間のフィードバックから集中的に学習させるだけで、間違った質問に答える状況を大幅に改善できます。
具体的には、まず人間によるデモンストレーションの回答を使用してモデルを微調整し、次に特定の質問に対するさまざまな出力データのセットをいくつか収集し、複数の回答セットを手動で並べ替えて、これに基づいて報酬モデルをトレーニングします。データセット。
最後に、RM を報酬関数として使用し、近接ポリシー最適化 (PPO) アルゴリズムは GPT-3 ポリシーを微調整し、強化学習手法で報酬を最大化します。
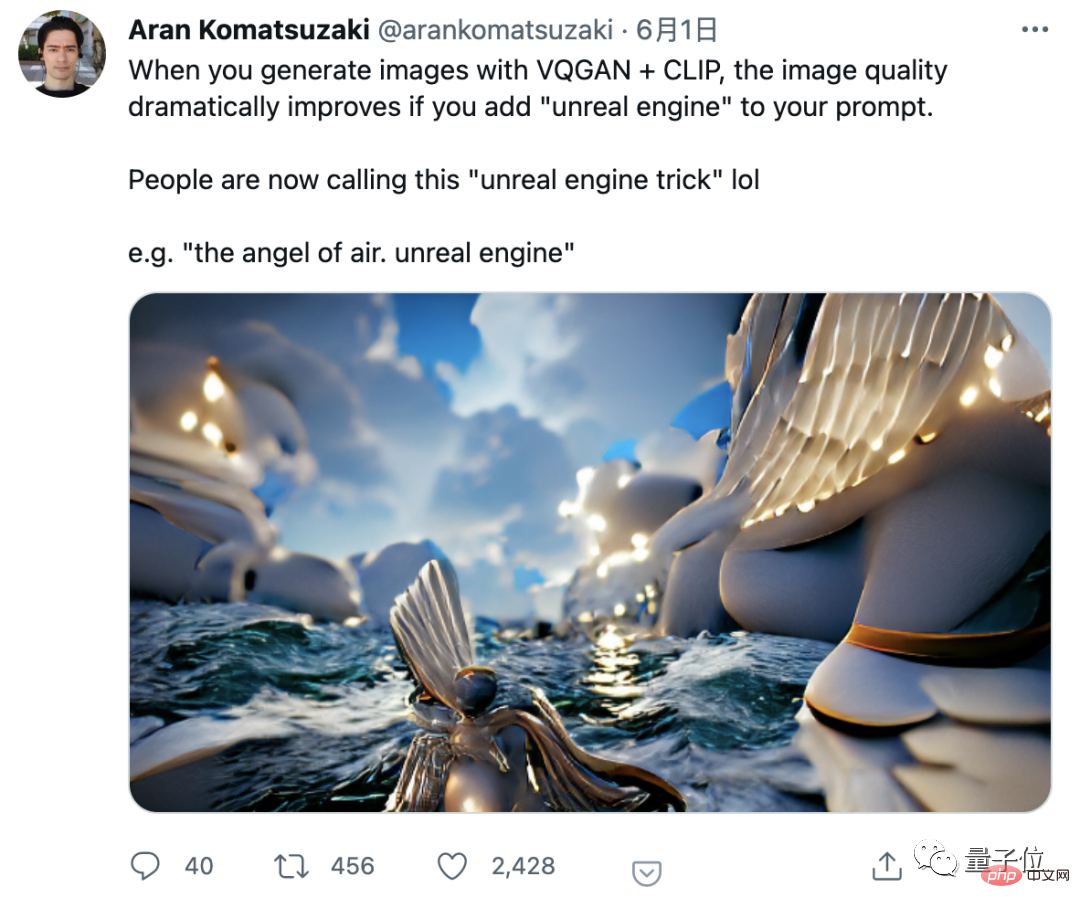
この話題の火付け役となった Twitter ブロガーの Aran 氏は、「Unreal Engine」を追加すると AI で生成された画像の品質が向上することを最初に発見した人です。
元 Google ロボットの責任者である Eric Jang 氏も、強化学習でも同様の考え方を利用してコンピューティング効率を向上できることを以前に発見しました。



https://www.php.cn/link/cc9109aa1f048c36d154d902612982e2
参考リンク:
[1]https: //twitter.com/arankomatsuzaki/status/1529278580189908993[2]https://evjang.com/2021/10/23/generalization.html以上が少しなだめるだけで GPT-3 の精度が 61% 向上します。 Googleと東京大学の研究は衝撃的だったの詳細内容です。詳細については、PHP 中国語 Web サイトの他の関連記事を参照してください。
















![[Web フロントエンド] Node.js クイック スタート](https://img.php.cn/upload/course/000/000/067/662b5d34ba7c0227.png)



