

ChatGPT の原理とアルゴリズムに関する興味深い話

昨年 12 月 1 日、OpenAI は人工知能チャットのプロトタイプである ChatGPT をリリースしました。これは再び注目を集め、AIGC がアーティストを失業させたのと同様に、AI コミュニティで大きな議論を引き起こしました。
ChatGPT は、会話の生成に焦点を当てた言語モデルです。ユーザーのテキスト入力に基づいて、対応するインテリジェントな回答を生成できます。
この回答は短い言葉でも長いエッセイでも構いません。このうち、GPTはGenerative Pre-trained Transformer(生成事前学習変換モデル)の略称です。
ChatGPT は、多数の既成のテキストと対話コレクション (Wiki など) を学習することで、人間と同じように瞬時に会話し、さまざまな質問に流暢に答えることができます。 (もちろん人間に比べれば解答速度は遅いですが) 英語でも他言語(中国語、韓国語など)でも、歴史の質問の解答から物語の執筆、さらにはビジネスの文章まで、計画や業界分析など、「ほぼ」何でもできます。一部のプログラマーは、プログラムの変更に関する chatGPT の会話を投稿しました。
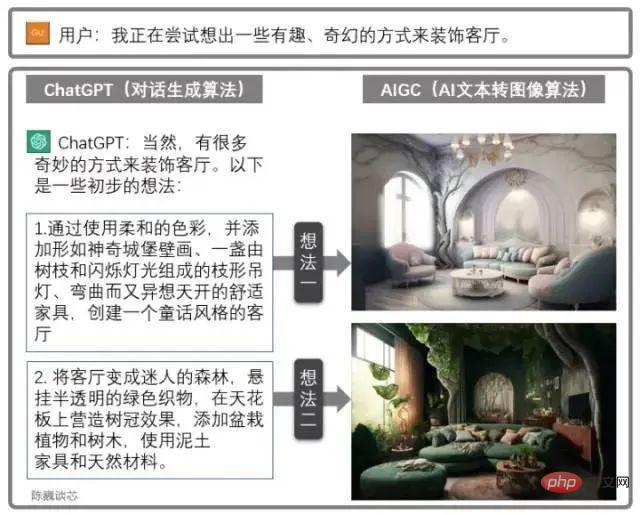
ChatGPT と AIGC の併用
ChatGPT を他の AIGC モデルと組み合わせて使用すると、よりクールで実用的な機能を得ることができます。
たとえば、リビングルームの設計図は上記の対話を通じて生成されます。これにより、AI アプリケーションが顧客と通信する能力が大幅に強化され、AI の大規模実装の夜明けが見えてきます。
1. ChatGPT の継承と特徴

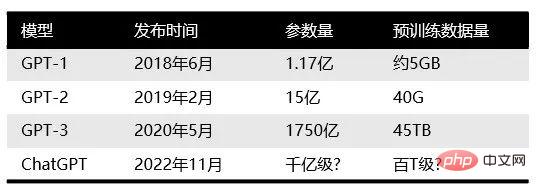
まず、OpenAI が何者であるかを理解しましょう。 OpenAI はサンフランシスコに本社を置き、2015 年にテスラのマスク氏、サム アルトマン氏、その他の投資家によって共同設立されました。目標は、全人類に利益をもたらす AI テクノロジーを開発することです。マスク氏は会社の発展方向の違いを理由に2018年に退社した。 以前、OpenAI は自然言語処理モデルの GPT シリーズを発表したことで有名でした。 OpenAIは2018年から、記事、コード、機械翻訳、Q&Aなどのさまざまなコンテンツの生成に使用できる生成事前トレーニング言語モデルGPT(Generative Pre-trained Transformer)のリリースを開始しました。 GPT モデルの各世代のパラメーターの数は爆発的に増加しており、「大きいほど優れている」と言えます。 2019 年 2 月にリリースされた GPT-2 には 15 億のパラメーターがありましたが、2020 年 5 月にリリースされた GPT-3 には 1,750 億のパラメーターがありました。
ChatGPT は大規模な言語モデルであり、現在ネットワーク検索機能を備えていないため、2021 年時点でのデータ セットに基づいてのみ応答できます。
たとえば、2022 年のワールド カップの状況はわかりません。また、今日の天気に答えたり、Apple の Siri のような情報の検索をサポートしたりすることはありません。 ChatGPT がオンラインで学習教材を見つけたり、知識を検索したりすることができれば、さらに大きな進歩が期待できます。
たとえ学習した知識が限られていたとしても、ChatGPT は人間の多くの奇妙な質問に広い心で答えることができます。 ChatGPT が悪習慣に陥るのを防ぐために、ChatGPT は有害で欺瞞的なトレーニング入力を減らすアルゴリズムによって保護されています。
クエリはモデレーション API によってフィルタリングされ、人種差別的または性差別的な可能性のあるヒントは無視されます。
2. ChatGPT/GPT の原則
▌2.1 NLP
NLP/NLU 分野の既知の制限には、テキストの繰り返し、高度に専門化されたトピックの誤解、文脈の誤解などがあります。フレーズ。
人間や AI の場合、通常の会話を行うには通常、何年ものトレーニングが必要です。
NLP タイプのモデルは、単語の意味を理解するだけでなく、文章を構成し、文脈上意味のある回答を与える方法を理解する必要があり、さらには適切な俗語や専門用語を使用する必要もあります。
NLP テクノロジーの応用分野
ChatGPT の基礎となる GPT-3 または GPT-3.5 は、本質的に非常に大規模な統計言語モデルです。または連続テキストの予測モデル。
▌2.2 GPT vs. BERT
BERT モデルと同様に、ChatGPT または GPT-3.5 は、入力文と言語/コーパスの確率に基づいて、回答の各単語 (単語) を自動的に生成します。
数学または機械学習の観点から見ると、言語モデルは単語シーケンスの確率相関分布のモデル化です。つまり、発言されたステートメント (ステートメントは数学ではベクトルとみなすことができます) を入力として使用します。条件を特定し、次の瞬間に異なる文や言語セットが出現する確率分布を予測します。
ChatGPT は、人間のフィードバックからの強化学習を使用してトレーニングされます。これは、より良い結果を得るために人間の介入によって機械学習を強化する方法です。
トレーニング プロセス中、人間のトレーナーはユーザーと人工知能アシスタントの役割を果たし、近接ポリシー最適化アルゴリズムを通じて微調整されます。
ChatGPT の強力なパフォーマンスと大量のパラメーターにより、より多くのトピック データが含まれ、よりニッチなトピックを処理できます。
ChatGPT は、質問への回答、記事の執筆、テキストの要約、言語翻訳、コンピューター コードの生成などのタスクをさらに処理できるようになりました。
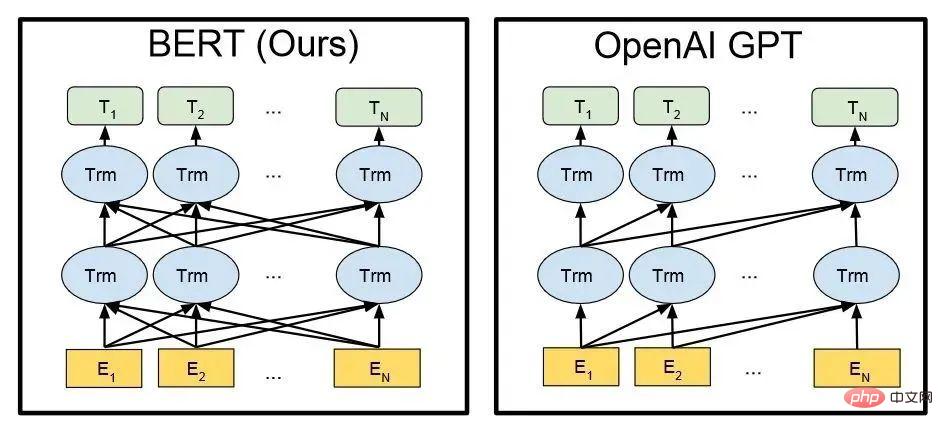
BERT と GPT の技術アーキテクチャ (図中の En は入力の各単語、Tn は出力される応答の各単語です)
3. ChatGPT 技術アーキテクチャ
▌3.1 GPT ファミリの進化
ChatGPT に関して言えば、GPT ファミリについて言及する必要があります。
ChatGPT には、それ以前に GPT-1、GPT-2、GPT-3 などの有名な兄弟がいくつかありました。これらの兄弟はそれぞれ他の兄弟よりも大きく、ChatGPT は GPT-3 により似ています。
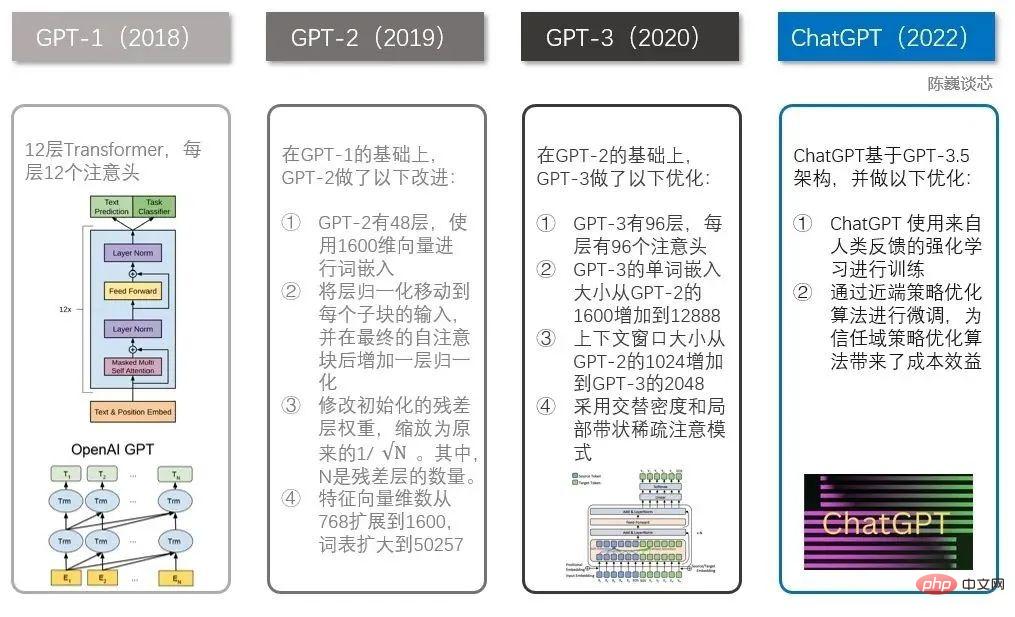
ChatGPT と GPT 1-3 の技術的な比較
GPT ファミリと BERT モデルはどちらもよく知られた NLP モデルであり、どちらも Transformer テクノロジーに基づいています。 。 GPT-1 では Transformer レイヤーが 12 レイヤーしかありませんでしたが、GPT-3 では 96 レイヤーに増加しました。
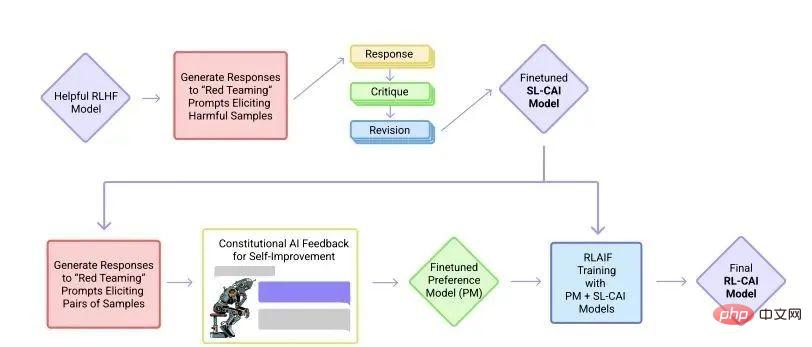
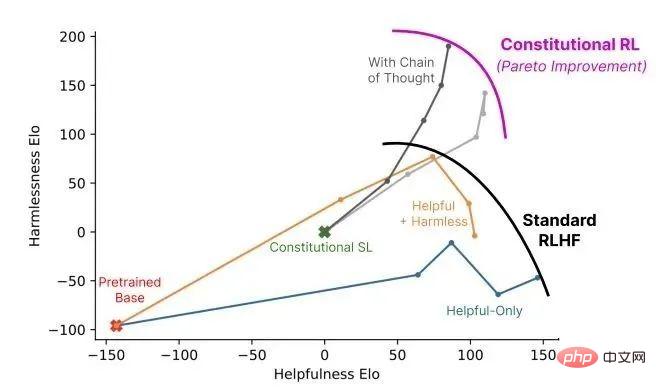
▌3.2 人間のフィードバックからの強化学習
InstructGPT/GPT3.5 (ChatGPT の前身) と GPT-3 の主な違いは、RLHF (人間からの強化学習) と呼ばれる新機能が追加されていることです。フィードバック)、ヒューマンフィードバック強化学習)が追加されました。
このトレーニング パラダイムにより、モデルの出力結果に対する人による調整が強化され、よりわかりやすいランキングが得られます。
InstructGPTにおける「文章の良さ」の評価基準は以下の通りです。
- 信憑性: それは虚偽の情報ですか、それとも誤解を招く情報ですか?
- 無害性: 人や環境に身体的または精神的な危害を与えますか?
- 有用性: ユーザーのタスクを解決しますか?
▌3.3 TAMER フレームワーク
TAMER (評価強化によるエージェントの手動トレーニング) フレームワークについて触れなければなりません。
このフレームワークは、エージェントの学習サイクルに人間のマーカーを導入し、人間を通じてエージェントに報酬フィードバックを提供する (つまり、エージェントのトレーニングをガイドする) ことで、トレーニング タスクの目標を迅速に達成できます。
人間のラベラーを導入する主な目的は、トレーニングを迅速化することです。強化学習技術は多くの分野で優れた性能を発揮しますが、学習の収束速度が遅い、学習コストが高いなど、依然として多くの欠点があります。
特に現実の世界では、多くのタスクには多額の探索コストやデータ取得コストがかかります。トレーニングの効率をいかに高めるかは、今日の強化学習タスクにおいて解決すべき重要な問題の 1 つです。
TAMER は、人間のマーカーの知識を使用して、報酬レターのフィードバックの形でエージェントをトレーニングし、迅速な収束を加速できます。
TAMER では、タガーに専門的な知識やプログラミング スキルが必要なく、コーパスのコストが低くなります。 TAMER RL (強化学習) を使用すると、マルコフ意思決定プロセス (MDP) の報酬からの強化学習 (RL) のプロセスを、人間のマーカーからのフィードバックで強化できます。
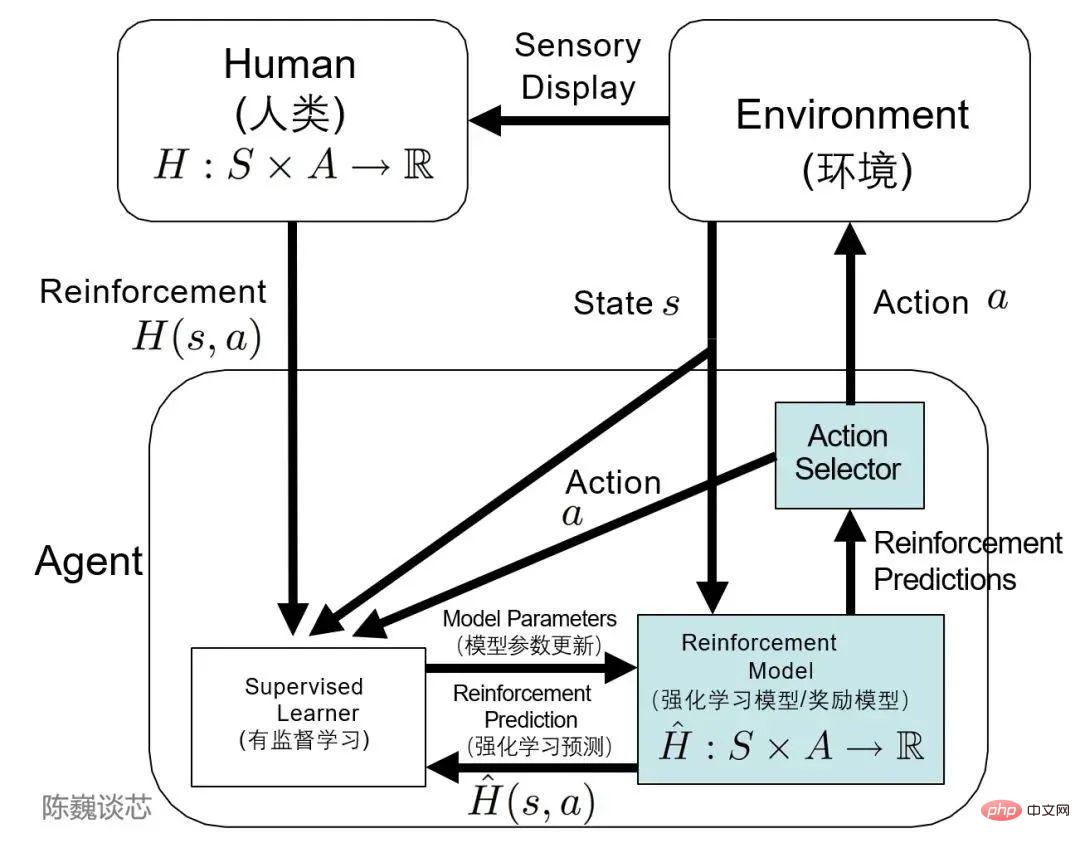
強化学習における TAMER アーキテクチャの適用
具体的な実装に関しては、ヒューマンタガーは会話ユーザーおよび人工知能アシスタントとして機能し、会話サンプルを提供して、モデルはいくつかの応答を生成し、タガーは応答オプションをランク付けして、より良い結果をモデルにフィードバックします。
エージェントは、人間による強化と統合システムとしてのマルコフ意思決定プロセス報酬という 2 つのフィードバック モードから同時に学習し、報酬戦略を通じてモデルを微調整し、継続的に反復します。
これに基づいて、ChatGPT は GPT-3 よりも人間の言語や指示を理解して完了し、人間を模倣し、一貫性のある論理的なテキスト情報を提供できます。
▌3.4 ChatGPT のトレーニング
ChatGPT のトレーニング プロセスは次の 3 つの段階に分かれています:
フェーズ 1: トレーニング監督戦略モデル
GPT 3.5 人間によるさまざまな指示に含まれるさまざまな意図を理解することは難しく、生成されたコンテンツが高品質な結果であるかどうかを判断することも困難です。
GPT 3.5 が最初に指示を理解するようにするために、まず質問がデータセットからランダムに選択され、人間のアノテーターが質の高い回答を返し、その後これらの手動でアノテーションが付けられたデータが使用されます。 GPT-3.5 モデルを微調整します (SFT モデルを取得、監視付き微調整)。
現時点での SFT モデルは、指示や会話に従うという点では既に GPT-3 よりも優れていますが、必ずしも人間の好みと一致するとは限りません。
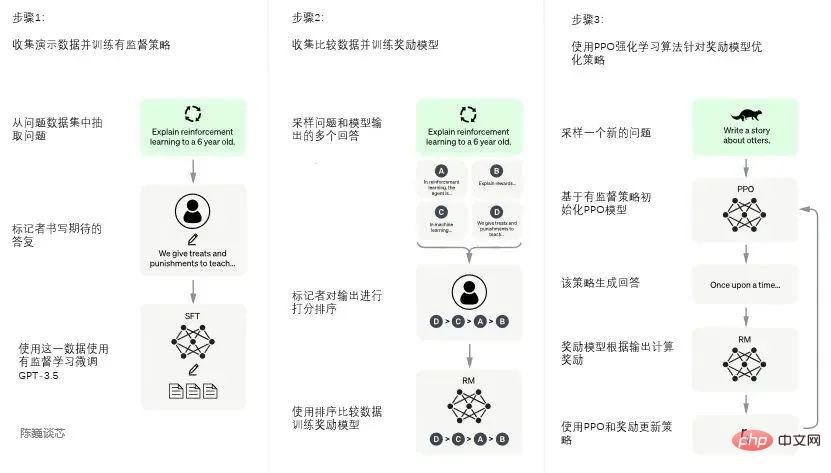
ChatGPT モデルのトレーニング プロセス
第 2 ステージ: 報酬モデルのトレーニング (報酬モード、RM)
このステージの主な焦点は次のとおりです。報酬モデルは、トレーニング データ (約 33,000 データ) に手動で注釈を付けることによってトレーニングされます。
データセットから質問をランダムに選択し、最初の段階で生成されたモデルを使用して、質問ごとに複数の異なる回答を生成します。ヒューマン・アノテーターはこれらの結果を考慮して、順位を付けます。このプロセスはコーチングやメンタリングに似ています。
次に、このランキング結果データを使用して報酬モデルをトレーニングします。複数の並べ替え結果がペアで結合されて、複数のトレーニング データ ペアが形成されます。
RM モデルは入力を受け入れ、回答の品質を評価するスコアを与えます。このようにして、トレーニング データのペアについて、高品質の回答のスコアが低品質の回答よりも高くなるようにパラメータが調整されます。
第 3 段階: PPO (Proximal Policy Optimization、近接ポリシー最適化) 強化学習を使用して戦略を最適化します。
PPO の中心的なアイデアは、ポリシー グラディエントのオンポリシー トレーニング プロセスをオフポリシーに変換すること、つまり、オンライン学習をオフライン学習に変換することです。この変換プロセスは重要度サンプリングと呼ばれます。
このステージでは、第 2 ステージでトレーニングされた報酬モデルを使用し、報酬スコアに依存して事前トレーニングされたモデルのパラメーターを更新します。データセットから質問をランダムに選択し、PPO モデルを使用して回答を生成し、前の段階でトレーニングされた RM モデルを使用して品質スコアを与えます。
報酬スコアを順番に渡すことでポリシー勾配を生成し、強化学習を通じて PPO モデルのパラメーターを更新します。
第 2 段階と第 3 段階を繰り返して反復を続けると、より高品質の ChatGPT モデルがトレーニングされます。
4. ChatGPT の制限
ユーザーが質問を入力する限り、ChatGPT は回答を返すことができます。これは、キーワードを Google や Baidu にフィードする必要がなくなったことを意味しますか?欲しいものはすぐに手に入る? その答えは?
ChatGPT は、優れた状況に応じた対話機能、さらにはプログラミング機能を実証し、人間と機械の会話ロボット (ChatBot) に対する一般の印象を「人工的に知恵が遅れている」から「興味深い」に変えることを完了しましたが、次のことも行う必要があります。 ChatGPT を参照してください。このテクノロジーにはまだいくつかの制限があり、改良が続けられています。
1) ChatGPT には、大量のコーパスでトレーニングされていない領域では「人間の常識」と拡張機能が欠けており、深刻な「ナンセンス」を話す可能性さえあります。 ChatGPT は多くの分野で「回答を作成」できますが、ユーザーが正しい回答を求めると、ChatGPT は誤解を招く回答を与える可能性もあります。たとえば、ChatGPT に小学校の応用問題をやらせると、長い一連の計算処理を書くことはできますが、最終的な答えは間違っています。
それでは、ChatGPT の結果を信じるべきでしょうか?
2) ChatGPT は、複雑で長い、または特に専門的な言語構造を処理できません。金融、自然科学、医学などの非常に専門的な分野からの質問については、コーパスの「フィード」が不十分な場合、ChatGPT は適切な回答を生成できない可能性があります。
3) ChatGPT は、トレーニングと展開をサポートするために非常に大量のコンピューティング能力 (チップ) を必要とします。モデルをトレーニングするために大量のコーパス データが必要であるにもかかわらず、現時点では、ChatGPT のアプリケーションには依然として大きな計算能力を持つサーバーのサポートが必要であり、これらのサーバーのコストは一般ユーザーの手の届かないものです。数十億のパラメータを持つモデルの実行とトレーニングには、膨大な量のコンピューティング リソースが必要です。実際の検索エンジンからの何億ものユーザーリクエストに直面した場合、現在普及している無料戦略を採用すると、どの企業もこのコストを負担するのは困難になります。したがって、一般の人々にとっては、軽量モデルか、よりコスト効率の高いコンピューティング プラットフォームを待つ必要があります。
4) ChatGPT はまだオンラインで新しい知識を取り込むことができず、新しい知識が出現したときに GPT モデルを再事前学習するのは非現実的であり、学習時間や学習コストに関係なく、一般のトレーナーには受け入れがたいものです。新しい知識に対してオンライン トレーニング モデルを採用する場合、それは実現可能であり、コーパス コストも比較的低いように見えますが、新しいデータの導入により元の知識が壊滅的に忘れられるという問題が簡単に発生する可能性があります。
5) ChatGPT はまだブラック ボックス モデルです。現時点では、ChatGPT の内部アルゴリズム ロジックは分解できないため、ChatGPT がユーザーを攻撃したり、ユーザーに危害を加えたりするステートメントを生成しないという保証はありません。
もちろん欠陥が隠蔽されているわけではなく、ChatGPT に Verilog コード (チップ設計コード) を書くよう求める会話を投稿したエンジニアもいます。 ChatGPT のレベルが一部の Verilog 初心者のレベルを超えていることがわかります。
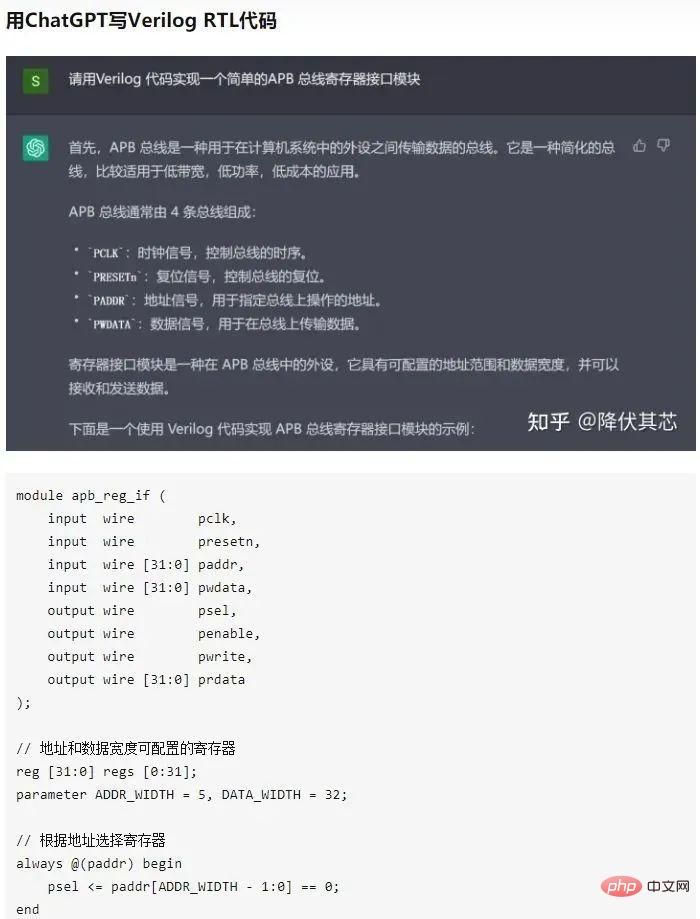
▌5.2 数学の欠点を補う
ChatGPT は優れた会話スキルを備えていますが、数学的な計算の会話では深刻なナンセンスを簡単に話してしまいます。
コンピュータ科学者の Stephen Wolfram は、この問題の解決策を提案しました。 Stephen Wolfram は Wolfram 言語とコンピューティング知識検索エンジン Wolfram|Alpha を作成しました。そのバックエンドは Mathematica を通じて実装されています。
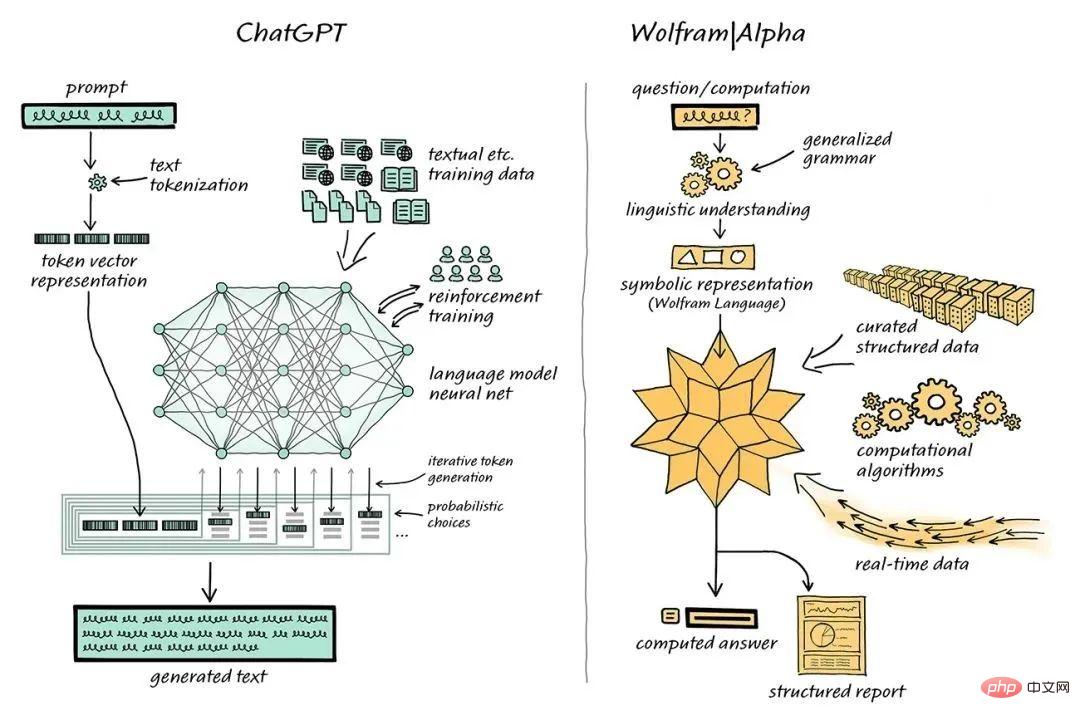
ChatGPTはWolfram|Alphaと組み合わされてコーミング問題を処理します
この組み合わされたシステムでは、ChatGPTはWolframと連携できます| Alphaの「会話」、Wolfram |Alpha は、シンボリック変換機能を使用して、ChatGPT から取得した自然言語表現を、対応するシンボリック コンピューティング言語に「変換」します。
これまで、学術コミュニティはChatGPTで使用される「統計的手法」とWolfram|Alphaの「記号的手法」に関して意見が分かれていました。
しかし今では、ChatGPTとWolfram|Alphaの相補性により、NLP分野が次のレベルに進む可能性がもたらされました。
ChatGPTはそのようなコードを生成する必要はなく、通常の自然言語を生成し、それをWolfram|Alphaを使って正確なWolfram言語に翻訳するだけでよく、その後、基礎となるMathematica が計算を実行します。
▌5.3 ChatGPT の小型化
ChatGPT は非常に強力ですが、モデル サイズと使用コストが多くの人にとっては困難です。
モデルのサイズとコストを削減できるモデル圧縮 (モデル圧縮) には 3 つのタイプがあります。
最初の方法は量子化です。これにより、単一の重みの数値表現の精度が低下します。たとえば、Tansformer を FP32 から INT8 にダウングレードしても、精度にはほとんど影響がありません。
モデル圧縮の 2 番目の方法は枝刈りです。これは、個々の重み (非構造化枝刈り) から重み行列などのより粒度の高いコンポーネントへのチャネルを含むネットワーク要素を削除します。このアプローチは、ビジョンおよび小規模な言語モデルに効果的です。
3 番目のモデル圧縮方法はスパース化です。たとえば、オーストリア科学技術研究所 (ISTA) によって提案された SparseGPT (arxiv.org/pdf/2301.0077) は、再トレーニングを行わずに、GPT シリーズ モデルを 1 ステップで 50% のスパース度にプルーニングできます。 GPT-175B モデルの場合、このプルーニングは 1 つの GPU のみを使用して数時間で実行できます。
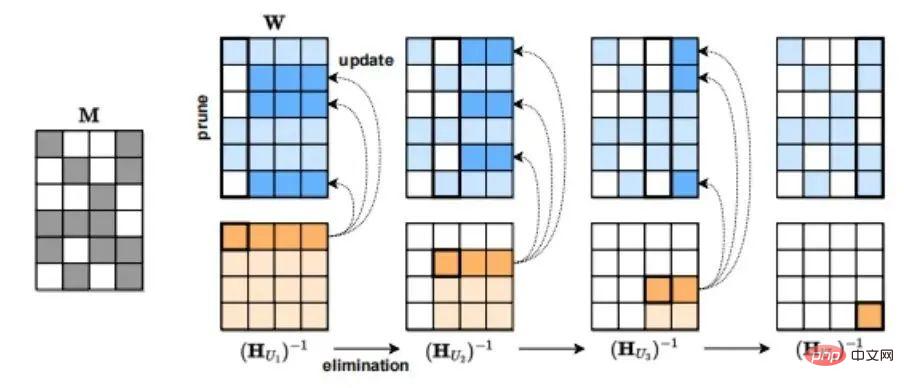
SparseGPT 圧縮プロセス
6. ChatGPT の産業の将来と投資の機会
▌6.1 AIGC
ChatGPT について話すと、 AIGCについて言及します。
AIGC は、人工知能テクノロジーを使用してコンテンツを生成します。以前の Web1.0 および Web2.0 時代の UGC (ユーザー生成コンテンツ) や PGC (専門家が制作したコンテンツ) と比較して、人工知能が考案したコンテンツを代表する AIGC は、コンテンツ制作手法の新たな変化であり、AIGCコンテンツは Web3 にあり、0 時代にも急激な成長が見込まれます。
ChatGPT モデルの出現は、テキスト/音声モードでの AIGC のアプリケーションにとって非常に重要であり、AI 業界の上流と下流に大きな影響を与えるでしょう。
▌6.2 特典シナリオ
コードフリープログラミング、小説生成、会話型検索エンジン、音声コンパニオン、音声作業アシスタント、会話型を含むがこれらに限定されない、下流関連の特典アプリケーションの観点からバーチャルヒューマン、人工知能カスタマーサービス、機械翻訳、チップ設計など
コンピューティング パワー チップ、データ アノテーション、自然言語処理 (NLP) などを含む、上流の需要増加の観点から。
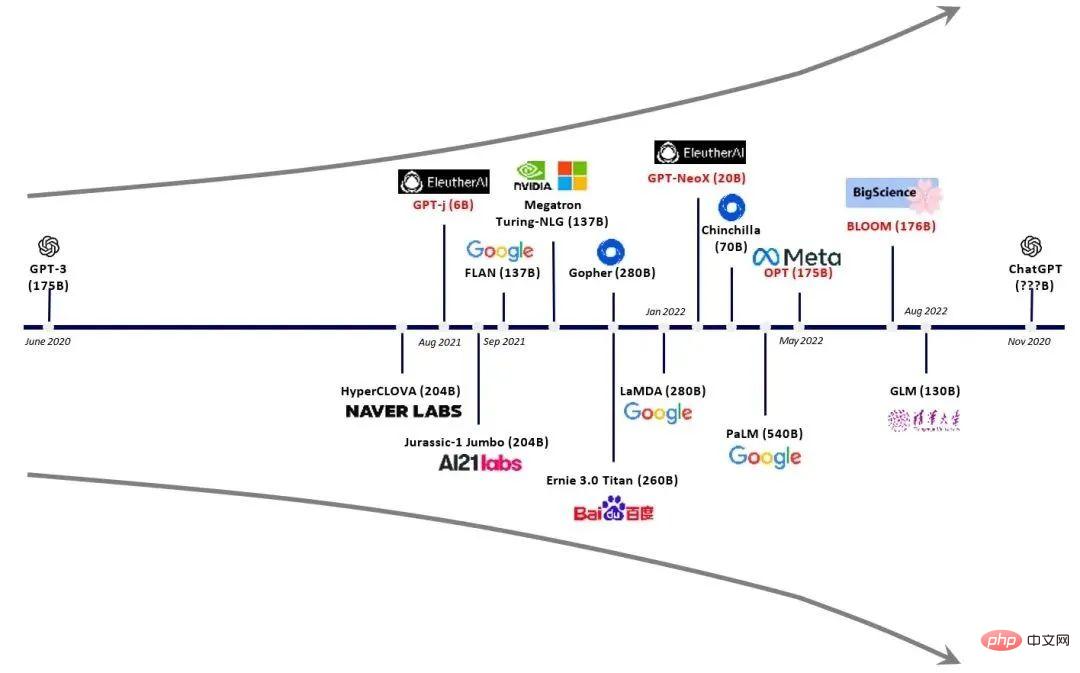
大規模なモデルは爆発的に増加しています (より多くのパラメータ/より大きな計算能力チップ要件)
アルゴリズム技術と計算能力技術の継続的な開発により、ChatGPT は進歩しています。また、より強力な機能を備えたより高度なバージョンに移行し、より多くの分野に適用され、人間にとってより多くのより良い会話やコンテンツを生成するでしょう。
最後に、ChatGPT 分野における統合ストレージおよびコンピューティング技術の状況について著者が質問しました (著者は現在、統合ストレージおよびコンピューティング チップの実装促進に注力しています)。ChatGPT はそれについて考え、大胆に予測しました。統合されたストレージとコンピューティング技術が ChatGPT の分野でチップを支配することになります。 (私の心を勝ち取りました)
参照:
- ChatGPT: 対話のための言語モデルの最適化ChatGPT: 対話のための言語モデルの最適化
- GPT论文:言語モデルは少数ショットの学習者です言語モデルは少数ショットの学習者です
- InstructGPT论文:人間のフィードバックで指示に従うように言語モデルをトレーニングする 人間のフィードバックで指示に従うように言語モデルをトレーニングする
- huggingface解读RHLF算法:ヒューマン フィードバックからの強化学習 (RLHF) の図解 ヒューマン フィードバックからの強化学習 (RLHF) の図解
- RHLF算法论文:人間によるフィードバックによる強化学習の強化 cs.utexas.edu/~ai-lab/p
- TAMER框架论文:人間による強化による対話型エージェントの形成 cs.utexas.edu/~ bradknox
- PPO算法:近接ポリシー最適化アルゴリズム 近接ポリシー最適化アルゴリズム
以上がChatGPT の原理とアルゴリズムに関する興味深い話の詳細内容です。詳細については、PHP 中国語 Web サイトの他の関連記事を参照してください。

ホットAIツール

Undresser.AI Undress
リアルなヌード写真を作成する AI 搭載アプリ

AI Clothes Remover
写真から衣服を削除するオンライン AI ツール。

Undress AI Tool
脱衣画像を無料で

Clothoff.io
AI衣類リムーバー

AI Hentai Generator
AIヘンタイを無料で生成します。

人気の記事
ホットツール

メモ帳++7.3.1
使いやすく無料のコードエディター

SublimeText3 中国語版
中国語版、とても使いやすい

ゼンドスタジオ 13.0.1
強力な PHP 統合開発環境

ドリームウィーバー CS6
ビジュアル Web 開発ツール

SublimeText3 Mac版
神レベルのコード編集ソフト(SublimeText3)
ホットトピック
 7504
7504
 15
1378
52
78
11
19
54
15
1378
52
78
11
19
54

 ChatGPT では、無料ユーザーが 1 日あたりの制限付きで DALL-E 3 を使用して画像を生成できるようになりました
Aug 09, 2024 pm 09:37 PM
ChatGPT では、無料ユーザーが 1 日あたりの制限付きで DALL-E 3 を使用して画像を生成できるようになりました
Aug 09, 2024 pm 09:37 PM
DALL-E 3は、前モデルより大幅に改良されたモデルとして2023年9月に正式導入されました。これは、複雑な詳細を含む画像を作成できる、これまでで最高の AI 画像ジェネレーターの 1 つと考えられています。ただし、発売当初は対象外でした
 CLIP-BEVFormer: BEVFormer 構造を明示的に監視して、ロングテール検出パフォーマンスを向上させます。
Mar 26, 2024 pm 12:41 PM
CLIP-BEVFormer: BEVFormer 構造を明示的に監視して、ロングテール検出パフォーマンスを向上させます。
Mar 26, 2024 pm 12:41 PM
上記および筆者の個人的な理解: 現在、自動運転システム全体において、認識モジュールが重要な役割を果たしている。道路を走行する自動運転車は、認識モジュールを通じてのみ正確な認識結果を得ることができる。下流の規制および制御モジュール自動運転システムでは、タイムリーかつ正確な判断と行動決定が行われます。現在、自動運転機能を備えた自動車には通常、サラウンドビューカメラセンサー、ライダーセンサー、ミリ波レーダーセンサーなどのさまざまなデータ情報センサーが搭載されており、さまざまなモダリティで情報を収集して正確な認識タスクを実現しています。純粋な視覚に基づく BEV 認識アルゴリズムは、ハードウェア コストが低く導入が容易であるため、業界で好まれており、その出力結果はさまざまな下流タスクに簡単に適用できます。
 C++ での機械学習アルゴリズムの実装: 一般的な課題と解決策
Jun 03, 2024 pm 01:25 PM
C++ での機械学習アルゴリズムの実装: 一般的な課題と解決策
Jun 03, 2024 pm 01:25 PM
C++ の機械学習アルゴリズムが直面する一般的な課題には、メモリ管理、マルチスレッド、パフォーマンスの最適化、保守性などがあります。解決策には、スマート ポインター、最新のスレッド ライブラリ、SIMD 命令、サードパーティ ライブラリの使用、コーディング スタイル ガイドラインの遵守、自動化ツールの使用が含まれます。実践的な事例では、Eigen ライブラリを使用して線形回帰アルゴリズムを実装し、メモリを効果的に管理し、高性能の行列演算を使用する方法を示します。
 nohupの機能と原理の解析
Mar 25, 2024 pm 03:24 PM
nohupの機能と原理の解析
Mar 25, 2024 pm 03:24 PM
nohup の役割と原理の分析 Unix および Unix 系オペレーティング システムでは、nohup はバックグラウンドでコマンドを実行するためによく使用されるコマンドです。ユーザーが現在のセッションを終了したり、ターミナル ウィンドウを閉じたりしても、コマンドはまだ実行され続けています。この記事では、nohup コマンドの機能と原理を詳しく分析します。 1. nohup の役割: バックグラウンドでのコマンドの実行: nohup コマンドを使用すると、ターミナル セッションを終了するユーザーの影響を受けることなく、長時間実行されるコマンドをバックグラウンドで実行し続けることができます。これは実行する必要があります
 C++sort 関数の基礎となる原則とアルゴリズムの選択を調べる
Apr 02, 2024 pm 05:36 PM
C++sort 関数の基礎となる原則とアルゴリズムの選択を調べる
Apr 02, 2024 pm 05:36 PM
C++sort 関数の最下層はマージ ソートを使用し、その複雑さは O(nlogn) で、クイック ソート、ヒープ ソート、安定したソートなど、さまざまなソート アルゴリズムの選択肢を提供します。
 人工知能は犯罪を予測できるのか? CrimeGPT の機能を調べる
Mar 22, 2024 pm 10:10 PM
人工知能は犯罪を予測できるのか? CrimeGPT の機能を調べる
Mar 22, 2024 pm 10:10 PM
人工知能 (AI) と法執行機関の融合により、犯罪の予防と検出の新たな可能性が開かれます。人工知能の予測機能は、犯罪行為を予測するためにCrimeGPT (犯罪予測技術) などのシステムで広く使用されています。この記事では、犯罪予測における人工知能の可能性、その現在の応用、人工知能が直面する課題、およびこの技術の倫理的影響について考察します。人工知能と犯罪予測: 基本 CrimeGPT は、機械学習アルゴリズムを使用して大規模なデータセットを分析し、犯罪がいつどこで発生する可能性があるかを予測できるパターンを特定します。これらのデータセットには、過去の犯罪統計、人口統計情報、経済指標、気象パターンなどが含まれます。人間のアナリストが見逃す可能性のある傾向を特定することで、人工知能は法執行機関に力を与えることができます
 改良された検出アルゴリズム: 高解像度の光学式リモートセンシング画像でのターゲット検出用
Jun 06, 2024 pm 12:33 PM
改良された検出アルゴリズム: 高解像度の光学式リモートセンシング画像でのターゲット検出用
Jun 06, 2024 pm 12:33 PM
01 今後の概要 現時点では、検出効率と検出結果の適切なバランスを実現することが困難です。我々は、光学リモートセンシング画像におけるターゲット検出ネットワークの効果を向上させるために、多層特徴ピラミッド、マルチ検出ヘッド戦略、およびハイブリッドアテンションモジュールを使用して、高解像度光学リモートセンシング画像におけるターゲット検出のための強化されたYOLOv5アルゴリズムを開発しました。 SIMD データセットによると、新しいアルゴリズムの mAP は YOLOv5 より 2.2%、YOLOX より 8.48% 優れており、検出結果と速度のバランスがより優れています。 02 背景と動機 リモート センシング技術の急速な発展に伴い、航空機、自動車、建物など、地表上の多くの物体を記述するために高解像度の光学式リモート センシング画像が使用されています。リモートセンシング画像の判読における物体検出
 58 ポートレート プラットフォームの構築におけるアルゴリズムの適用
May 09, 2024 am 09:01 AM
58 ポートレート プラットフォームの構築におけるアルゴリズムの適用
May 09, 2024 am 09:01 AM
1. 58 Portraits プラットフォーム構築の背景 まず、58 Portraits プラットフォーム構築の背景についてお話ししたいと思います。 1. 従来のプロファイリング プラットフォームの従来の考え方ではもはや十分ではありません。ユーザー プロファイリング プラットフォームを構築するには、複数のビジネス分野からのデータを統合して、ユーザーの行動や関心を理解するためのデータ マイニングも必要です。最後に、ユーザー プロファイル データを効率的に保存、クエリ、共有し、プロファイル サービスを提供するためのデータ プラットフォーム機能も必要です。自社構築のビジネス プロファイリング プラットフォームとミドルオフィス プロファイリング プラットフォームの主な違いは、自社構築のプロファイリング プラットフォームは単一のビジネス ラインにサービスを提供し、オンデマンドでカスタマイズできることです。ミッドオフィス プラットフォームは複数のビジネス ラインにサービスを提供し、複雑な機能を備えていることです。モデリングを提供し、より一般的な機能を提供します。 2.58 中間プラットフォームのポートレート構築の背景のユーザーのポートレート 58
