

Google は拡散モデルを最適化しており、Samsung の携帯電話は Stable Diffusion を実行し、12 秒で画像を生成します。

安定拡散は、画像生成の分野では、会話大規模モデルの ChatGPT と同じくらいよく知られています。任意の入力テキストのリアルな画像を数十秒で作成できます。 Stable Diffusion には 10 億を超えるパラメータがあり、デバイス上のコンピューティング リソースとメモリ リソースが限られているため、このモデルは主にクラウドで実行されます。
慎重な設計と実装を行わないと、デバイス上でこれらのモデルを実行すると、反復的なノイズ除去プロセスと過剰なメモリ消費により遅延が増加する可能性があります。
デバイス上で安定拡散を実行する方法は、誰もが研究に興味を持っています。以前、一部の研究者は安定拡散を使用して iPhone 14 Pro 上で画像を生成するアプリケーションを開発しました。所要時間は 1 分で、約 2GiB のアプリケーション メモリを使用します。
Apple もこれまでにいくつかの最適化を行っており、iPhone、iPad、Mac、その他のデバイスで 512x512 の解像度の画像を 30 分で生成できます。クアルコムもそれに続き、Android スマートフォンで Stable Diffusion v1.5 を実行し、15 秒以内に解像度 512x512 の画像を生成しました。
最近、Google が公開した論文「必要なのは速度だけ: GPU 対応の最適化による大規模拡散モデルのオンデバイス アクセラレーション」で、GPU 駆動のStable Diffusion 1.4 がデバイス上で実行され、SOTA 推論レイテンシ パフォーマンスを実現します (Samsung S23 Ultra では、20 回の反復で 512 × 512 の画像を生成するのにわずか 11.5 秒かかります)。さらに、この研究は 1 つのデバイスに特化したものではなく、すべての潜在的な拡散モデルの改善に適用できる一般的なアプローチです。
この研究により、データ接続やクラウド サーバーを使用せずに、携帯電話上で生成 AI をローカルに実行するための多くの可能性が開かれます。 Stable Diffusion は昨年の秋にリリースされたばかりですが、すでにデバイスに接続して現在実行できることから、この分野の発展の速さがわかります。

論文アドレス: https://arxiv.org/pdf/2304.11267.pdf ##この生成速度を達成するために、Google はいくつかの最適化案を提案しています。Google がどのように最適化を行っているかを見てみましょう。
手法の紹介
本研究は、大規模拡散モデルのビンセント図の速度を向上させるための最適化手法を提案することを目的としています。最適化の提案は、他の大規模な拡散モデルにも適しています。
まず、安定拡散の主なコンポーネントを見てみましょう。テキスト エンベッダー (テキスト エンベッダー)、ノイズ生成 (ノイズ生成)、ノイズ除去ニューラル ネットワーク (ノイズ除去ニューラル ネットワーク)、および画像デコーダ (以下の図 1 に示す画像デコーダ。
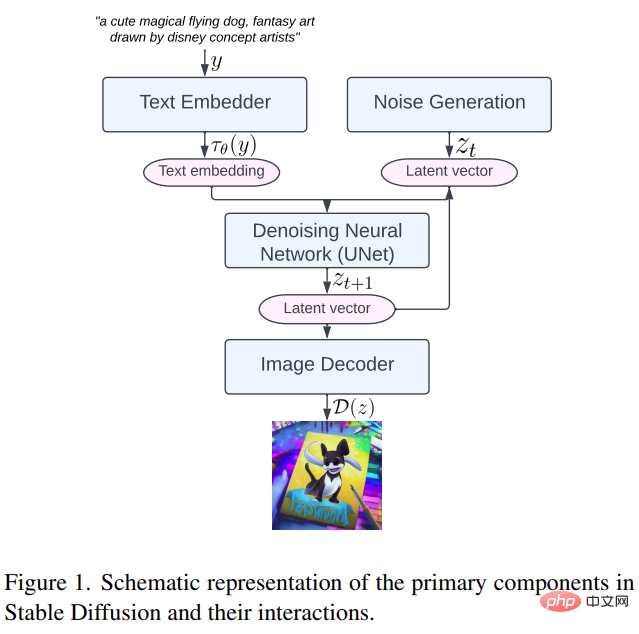 ##次に、提案されている 3 つの問題を詳しく見てみましょう。最適化手法
##次に、提案されている 3 つの問題を詳しく見てみましょう。最適化手法
特殊なカーネル: Group Norm と GELU
Group Normalization (GN)方法の動作原理は、特徴マップのチャネルをより小さなグループに分割し、各グループを個別に正規化することで、GN のバッチ サイズへの依存性が低くなり、さまざまなバッチ サイズやネットワーク アーキテクチャにより適したものになります。 、および正規化操作を順番に行うため、この研究では、中間の Tensor を使用せずに、これらすべての操作を 1 つの GPU コマンドで実行できる独自の GPU シェーダー形式のカーネルを設計しました。
ガウス誤差線形単位 (GELU) ) は一般的に使用されるモデルの活性化関数として、乗算、加算、ガウス誤差関数などの数値計算が多数含まれていますが、本研究では専用のシェーダを使用してこれらの数値計算とそれに伴う分割および乗算の演算を統合し、単一の AI ペイント呼び出しで実行できます。
#アテンション モジュールの効率の向上
安定拡散のテキストから画像への変換機能は、テキストから画像への生成タスクにとって重要な条件付き分布のモデル化に役立ちます。ただし、セルフ/クロスアテンション メカニズムは、メモリの複雑さと時間の複雑さにより、長いシーケンスを処理する際に困難に直面します。これに基づいて、本研究では計算ボトルネックを軽減するための 2 つの最適化手法を提案します。 一方で、大きな行列に対してソフトマックス計算全体を実行することを避けるために、この研究では GPU シェーダーを使用して計算操作を削減し、メモリ フットプリントと全体的なメモリ フットプリントを大幅に削減します。中間テンソルのレイテンシ具体的な方法を以下の図 2 に示します。 
一方、この研究では、IO 対応の正確な注意アルゴリズムである FlashAttendant [7] を使用しています。高帯域幅メモリ (HBM) は、標準のアテンション メカニズムよりも必要なアクセスが少なく、全体的な効率が向上します。
Winograd 畳み込み
Winograd 畳み込みは、畳み込み演算を一連の行列乗算に変換します。この方法により、多くの乗算演算が削減され、計算効率が向上します。ただし、これにより、特に大きなタイルを使用する場合、メモリ消費と数値エラーも増加します。
安定拡散のバックボーンは 3x3 畳み込み層に大きく依存しており、特に画像デコーダでは 90% を占めます。この研究では、3 × 3 カーネル コンボリューションでさまざまなタイル サイズで Winograd を使用することの潜在的な利点を調査するために、この現象を詳細に分析します。研究の結果、計算効率とメモリ使用率のバランスが最適となる 4 × 4 のタイル サイズが最適であることがわかりました。
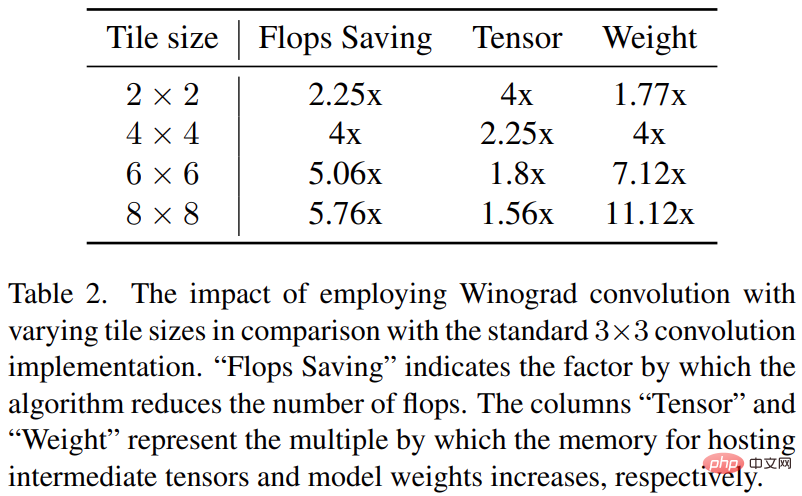
この調査では、Samsung S23 Ultra (Adreno 740) および iPhone 14 Pro Max などのさまざまなデバイスでベンチマークが行われました。 (A16)。ベンチマーク結果を以下の表 1 に示します。
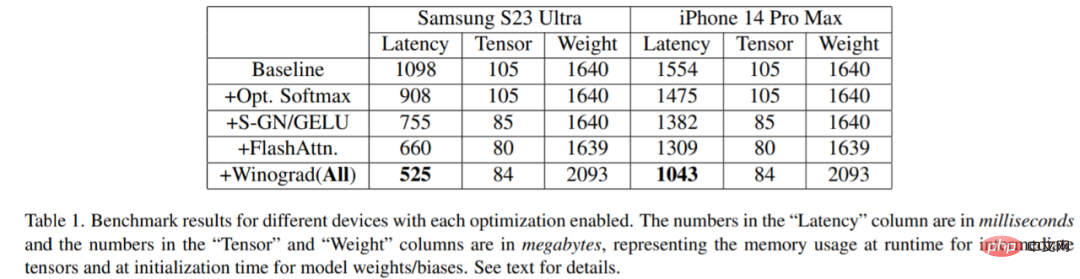
#各最適化がアクティブになるにつれて、レイテンシが徐々に長くなるのは明らかです。 (画像生成にかかる時間が短縮されていることが分かります)具体的には、ベースラインと比較して、Samsung S23 Ultra では 52.2% の遅延削減、iPhone 14 Pro Max では 32.9% の遅延削減です。さらに、この研究では、Samsung S23 Ultra のエンドツーエンドの遅延も評価し、20 回のノイズ除去反復ステップ内で 512 × 512 ピクセルの画像を生成し、12 秒未満で SOTA 結果を達成しました。
小型デバイスは独自の生成人工知能モデルを実行できます。これは将来に何を意味しますか?波が期待できます。
以上がGoogle は拡散モデルを最適化しており、Samsung の携帯電話は Stable Diffusion を実行し、12 秒で画像を生成します。の詳細内容です。詳細については、PHP 中国語 Web サイトの他の関連記事を参照してください。

ホットAIツール

Undresser.AI Undress
リアルなヌード写真を作成する AI 搭載アプリ

AI Clothes Remover
写真から衣服を削除するオンライン AI ツール。

Undress AI Tool
脱衣画像を無料で

Clothoff.io
AI衣類リムーバー

AI Hentai Generator
AIヘンタイを無料で生成します。

人気の記事
ホットツール

メモ帳++7.3.1
使いやすく無料のコードエディター

SublimeText3 中国語版
中国語版、とても使いやすい

ゼンドスタジオ 13.0.1
強力な PHP 統合開発環境

ドリームウィーバー CS6
ビジュアル Web 開発ツール

SublimeText3 Mac版
神レベルのコード編集ソフト(SublimeText3)
ホットトピック
 7454
7454
 15
1375
52
77
11
14
9
15
1375
52
77
11
14
9


 DeepSeekを検索する方法
Feb 19, 2025 pm 05:39 PM
DeepSeekを検索する方法
Feb 19, 2025 pm 05:39 PM
DeepSeekは、特定のデータベースまたはシステムでのみ検索する独自の検索エンジンであり、より速く、より正確です。それを使用する場合、ユーザーはドキュメントを読み、さまざまな検索戦略を試し、ユーザーエクスペリエンスに関するヘルプを求めてフィードバックを求めて、利点を最大限に活用することをお勧めします。
 セサミオープンドア交換Webページ登録リンクゲートトレーディングアプリ登録Webサイト最新
Feb 28, 2025 am 11:06 AM
セサミオープンドア交換Webページ登録リンクゲートトレーディングアプリ登録Webサイト最新
Feb 28, 2025 am 11:06 AM
この記事では、SESAME Open Exchange(gate.io)Webバージョンの登録プロセスとGate Tradingアプリを詳細に紹介します。 Web登録であろうとアプリの登録であろうと、公式Webサイトまたはアプリストアにアクセスして、本物のアプリをダウンロードし、ユーザー名、パスワード、電子メール、携帯電話番号、その他の情報を入力し、電子メールまたは携帯電話の確認を完了する必要があります。
 Bybit Exchangeリンクを直接ダウンロードしてインストールできないのはなぜですか?
Feb 21, 2025 pm 10:57 PM
Bybit Exchangeリンクを直接ダウンロードしてインストールできないのはなぜですか?
Feb 21, 2025 pm 10:57 PM
Bybit Exchangeリンクを直接ダウンロードしてインストールできないのはなぜですか? BYBITは、ユーザーにトレーディングサービスを提供する暗号通貨交換です。 Exchangeのモバイルアプリは、次の理由でAppStoreまたはGooglePlayを介して直接ダウンロードすることはできません。1。AppStoreポリシーは、AppleとGoogleがApp Storeで許可されているアプリケーションの種類について厳しい要件を持つことを制限しています。暗号通貨交換アプリケーションは、金融サービスを含み、特定の規制とセキュリティ基準を必要とするため、これらの要件を満たしていないことがよくあります。 2。法律と規制のコンプライアンス多くの国では、暗号通貨取引に関連する活動が規制または制限されています。これらの規制を遵守するために、BYBITアプリケーションは公式Webサイトまたはその他の認定チャネルを通じてのみ使用できます
 セサミオープンドアトレーディングプラットフォームダウンロードモバイルバージョンgateioトレーディングプラットフォームのダウンロードアドレス
Feb 28, 2025 am 10:51 AM
セサミオープンドアトレーディングプラットフォームダウンロードモバイルバージョンgateioトレーディングプラットフォームのダウンロードアドレス
Feb 28, 2025 am 10:51 AM
アプリをダウンロードしてアカウントの安全を確保するために、正式なチャネルを選択することが重要です。
 gate.io交換公式登録ポータル
Feb 20, 2025 pm 04:27 PM
gate.io交換公式登録ポータル
Feb 20, 2025 pm 04:27 PM
Gate.ioは、幅広い暗号資産と取引ペアを提供する主要な暗号通貨交換です。 gate.ioの登録は非常に簡単です。公式ウェブサイトにアクセスするか、「登録」をクリックし、登録フォームに入力し、電子メールを確認し、2因子検証(2FA)を設定する必要があります。登録を完了します。 gate.ioを使用すると、ユーザーは安全で便利な暗号通貨取引体験を楽しむことができます。
 Binance Binance公式Webサイト最新バージョンログインポータル
Feb 21, 2025 pm 05:42 PM
Binance Binance公式Webサイト最新バージョンログインポータル
Feb 21, 2025 pm 05:42 PM
Binance Webサイトログインポータルの最新バージョンにアクセスするには、これらの簡単な手順に従ってください。公式ウェブサイトに移動し、右上隅の[ログイン]ボタンをクリックします。既存のログインメソッドを選択してください。「登録」してください。登録済みの携帯電話番号または電子メールとパスワードを入力し、認証を完了します(モバイル検証コードやGoogle Authenticatorなど)。検証が成功した後、Binance公式WebサイトLogin Portalの最新バージョンにアクセスできます。
 セサミオープンドアエクスチェンジウェブページログイン最新バージョンgateio公式ウェブサイトの入り口
Mar 04, 2025 pm 11:48 PM
セサミオープンドアエクスチェンジウェブページログイン最新バージョンgateio公式ウェブサイトの入り口
Mar 04, 2025 pm 11:48 PM
ログインステップやパスワード回復プロセスなど、セサミオープンエクスチェンジWebバージョンのログイン操作の詳細な紹介も、ログイン障害、ページを開くことができず、プラットフォームにスムーズにログインするのに役立つ検証コードを受信できません。
