

真の量子速読:一度に50ページのテキストしか理解できないGPT-4の限界を突破、新しい研究は数百万のトークンにまで拡張

1 か月以上前、OpenAI の GPT-4 が発表されました。さまざまな優れた視覚的なデモンストレーションに加えて、重要なアップデートも実装されています。デフォルトでは長さ 8K のコンテキスト トークンを処理できますが、最大 32K (テキストの約 50 ページ) まで対応できます。これは、GPT-4 に質問するときに、以前よりもはるかに長いテキストを入力できることを意味します。これにより、GPT-4 のアプリケーション シナリオが大幅に拡張され、長い会話、長いテキスト、ファイルの検索と分析をより適切に処理できるようになります。
しかし、この記録はすぐに破られました。Google Research の CoLT5 は、モデルが処理できるコンテキスト トークンの長さを 64k に拡張しました。
Transformer アーキテクチャを使用するこれらのモデルはすべて問題に直面しているため、このようなブレークスルーは簡単ではありません。Transformer による長いドキュメントの処理は、入力の長さに応じて注意コストが増加するため、計算コストが非常に高くなります。は二次関数的に増大するため、大規模なモデルをより長い入力に適用することがますます困難になります。
にもかかわらず、研究者たちは依然としてこの方向で画期的な進歩を遂げています。数日前、オープンソースの対話 AI テクノロジー スタック DeepPavlov とその他の機関による研究では、次のことが示されました。リカレント メモリ トランスフォーマー (RMT) と呼ばれるアーキテクチャを使用することで、BERT の有効なコンテキスト長を増やすことができます。高いメモリ検索精度を維持しながら、200 万トークン (OpenAI の計算方法によるとおよそ 3,200 ページのテキストに相当) までモデル化できます (注: Recurrent Memory Transformer は、NeurIPS 2022 Methods の論文で Aydar Bulatov らによって提案されました)。新しい方法では、ローカルおよびグローバル情報の保存と処理、および再帰を使用した入力シーケンスのセグメント間の情報の流れが可能になります。

著者は、Bulatov et al. の記事「Recurrent」で紹介された単純なトークンベースのアルゴリズムを使用することによって、 「Memory Transformer」メモリ メカニズムにより、RMT を BERT などの事前トレーニングされた Transformer モデルと組み合わせ、Nvidia GTX 1080Ti GPU を使用して、100 万を超えるトークンのシーケンスに対して完全な注意と完全な精度の操作を実行できます。

#論文アドレス: https://arxiv.org/pdf/2304.11062.pdf
ただし、これは本当の「フリーランチ」ではなく、上記の論文の改善は「推論時間の延長と品質の大幅な低下」によって得られることを思い出させる人もいます。 。したがって、それはまだ革命ではありませんが、次のパラダイムの基礎となる可能性があります(トークンは無限に長くなる可能性があります)。
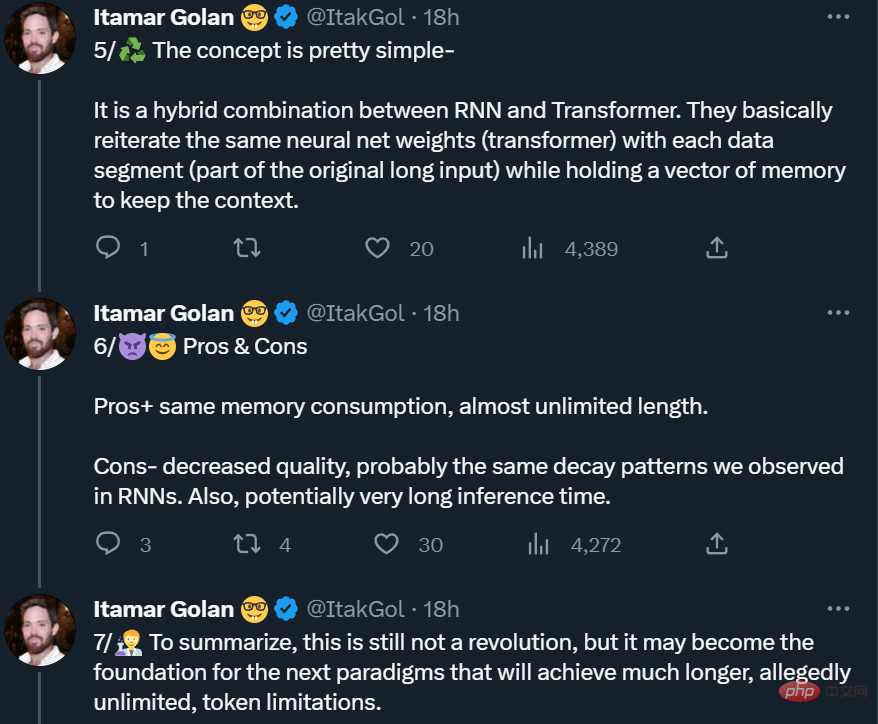
本研究では、Bulatov らによって提案された手法 Recurrent Memory Transformer を採用しています。 2022年にRMT(プラグアンドプレイ方式)に変更 主な仕組みは下図の通りです。 ##長い入力は複数のセグメントに分割され、最初のセグメントが埋め込まれる前にメモリ ベクトルが追加され、セグメント トークンとともに処理されます。 BERT のような純粋なエンコーダー モデルの場合、純粋なデコーダー モデルがメモリを読み取り部分と書き込み部分に分割する (Bulatov et al., 2022) とは異なり、メモリはセグメントの先頭に 1 回だけ追加されます。タイム ステップ τ とセグメント
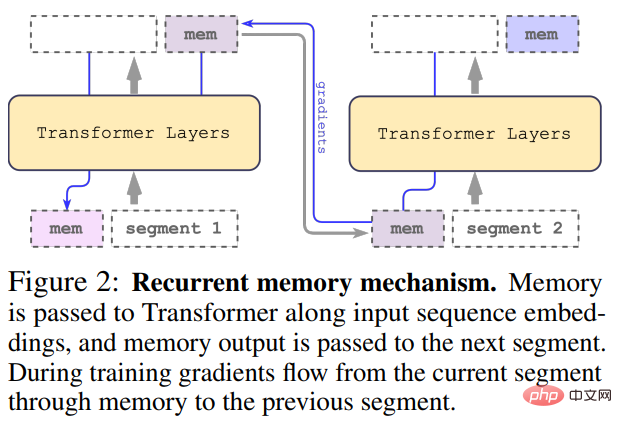
の場合、ループは次のように実行されます。

#ここで、N は Transformer の層数です。順伝播後、
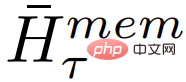
# にはセグメント τ の更新されたメモリ トークンが含まれます。
#入力シーケンスのセグメントは順番に処理されます。循環接続を有効にするために、調査では現在のセグメントからのメモリ トークンの出力を次のセグメントの入力に渡します:
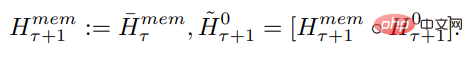
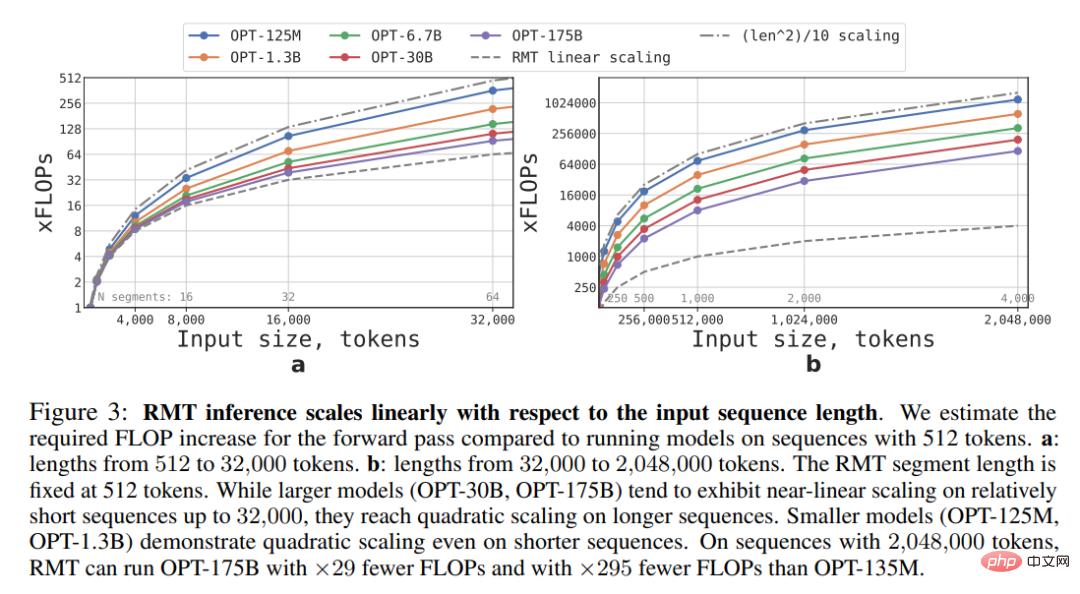
計算効率
この調査では、さまざまなサイズとシーケンス長の RMT および Transformer モデルに必要な FLOP を推定します。以下の図 3 に示すように、セグメントの長さが固定されている場合、RMT は任意のモデル サイズに対して線形にスケールできます。この研究では、入力シーケンスをセグメントに分割し、セグメント境界内でのみ完全なアテンション行列を計算することにより、線形スケーリングを実現します。
FFN 層の計算の複雑さにより、大規模な Transformer モデルでは、シーケンスの長さに応じて 2 次スケーリングが遅くなる傾向があります。ただし、32000 を超える非常に長いシーケンスの場合は、二次展開に戻ります。複数のセグメント (この研究では > 512) を持つシーケンスの場合、RMT は非巡回モデルよりも必要な FLOP が少なく、FLOP の数を最大 295 分の 1 まで削減できます。 RMT は、小型モデルでは FLOP の相対的な削減が大きくなりますが、OPT-175B モデルの FLOP の 29 倍の削減は絶対的な意味で大幅です。
 記憶タスク
記憶タスク

最初の項目課題は、以下の図 4 の上部に示すように、メモリに情報を長期間書き込んで保存する RMT の機能をテストすることです。最も単純なケースでは、事実は入力の先頭にあり、質問は常に最後にある傾向があります。質問と回答の間にある無関係なテキストの量が徐々に増加し、入力全体が 1 つのモデル入力に収まらなくなるまで増加します。

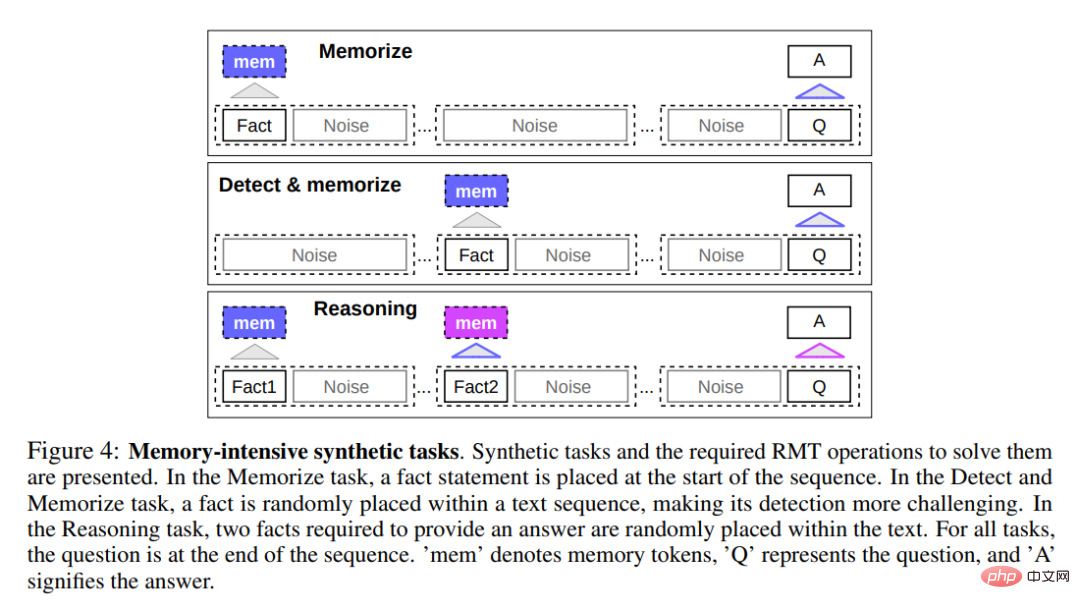
ファクト検出は、上の図 4 の中央に示すように、ファクトを入力内のランダムな位置に移動することにより、タスクの難易度を高めます。これには、モデルが最初に事実と無関係なテキストを区別し、その事実をメモリに書き込み、最後にそれを使用して質問に答える必要があります。 記憶された事実を使用して推論する 記憶のもう 1 つの操作は、記憶された事実と現在のコンテキストを使用して推論することです。この機能を評価するために、研究者らは、上の図 4 の下部に示すように、2 つのファクトを生成して入力シーケンス内に配置する、より複雑なタスクを使用しました。シーケンスの最後に行われる質問は、質問に正しく答えるために任意の事実を使用する必要があるように記述されています。 
実験結果
研究者らは、モデルのトレーニングと評価に 4 ~ 8 個の NVIDIA 1080ti GPU を使用しました。 。より長いシーケンスの場合は、評価を高速化するために 40GB の NVIDIA A100 を 1 台使用しました。
コース学習
研究者らは、トレーニング プランを使用すると、ソリューションの精度と精度が大幅に向上することを観察しました。 。 安定性。最初に、RMT はタスクの短いバージョンでトレーニングされ、トレーニングが収束するにつれて別のセグメントを追加することでタスクの長さを増やします。コース学習プロセスは、必要な入力長に達するまで続行されます。
実験では、研究者たちはまず、単一のセグメントに適したシーケンスから開始しました。実際のセグメント サイズは 499 ですが、BERT の 3 つの特別なトークンとモデル入力から保持される 10 個のメモリ プレースホルダーにより、サイズは 512 になります。彼らは、RMT では、完璧な解決策に収束するために使用するトレーニング ステップが少なくて済むため、短いタスクでトレーニングした後、より長いバージョンのタスクを解決するのが容易であることに注目しています。
外挿能力
さまざまなシーケンス長に対する RMT の一般化能力は何ですか?この質問に答えるために、研究者らは、以下の図 5 に示すように、より長いタスクを解決するためにさまざまな数のセグメントでトレーニングされたモデルを評価しました。
研究者らは、単一セグメントの推論タスクを除いて、モデルは短いタスクの方がパフォーマンスが向上する傾向があることを観察しました。単一セグメントの推論タスクは解決が非常に困難になります。考えられる説明の 1 つは、タスク サイズが 1 セグメントを超えるため、モデルが最初のセグメントの問題を「予期」しなくなり、その結果品質が低下するということです。
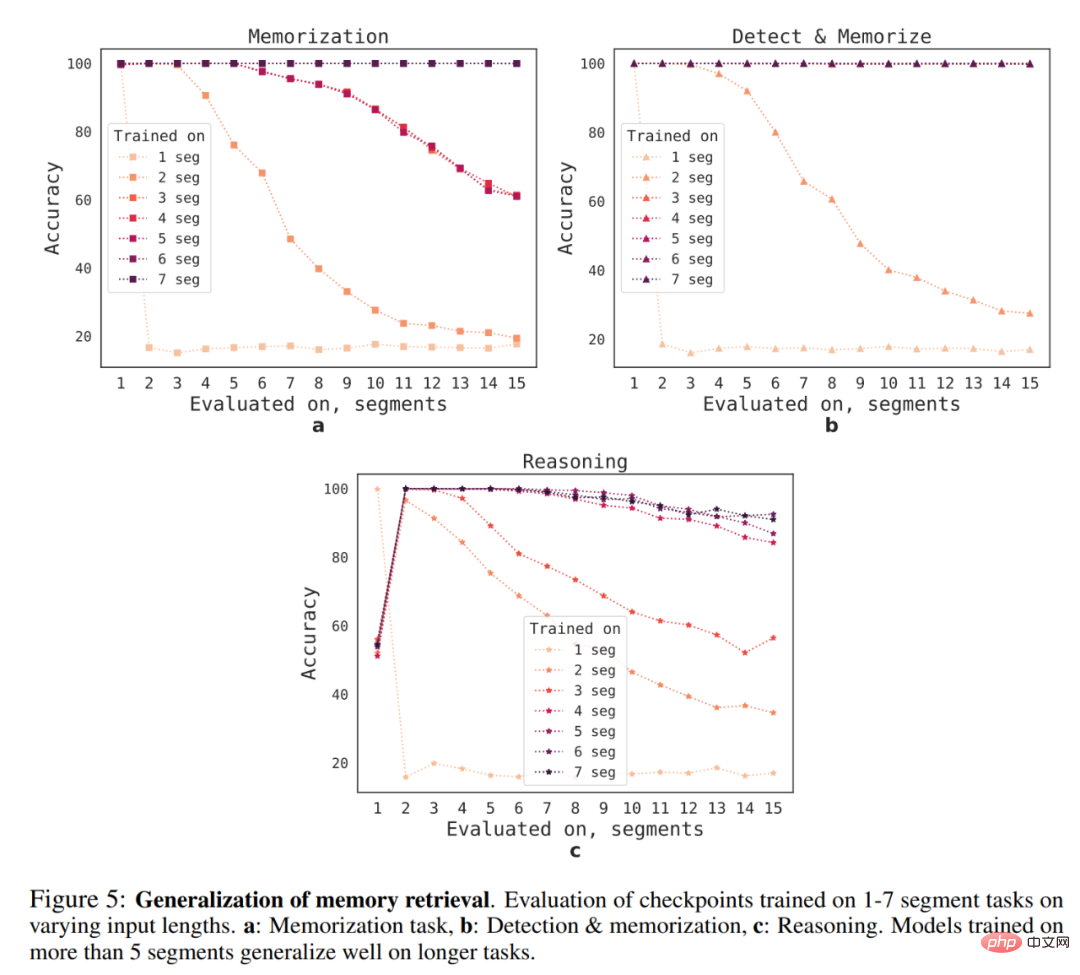
#興味深いことに、トレーニング セグメントの数が増加するにつれて、より長いシーケンスに一般化する RMT の機能も現れます。 5 つ以上のセグメントでトレーニングした後、RMT は 2 倍の時間のタスクをほぼ完全に一般化できます。
一般化の限界をテストするために、研究者らは検証タスクのサイズを 4096 セグメントまたは 2,043,904 トークンに増加しました (上の図 1 を参照)。驚くほど良いパフォーマンスを見せました。検出と記憶のタスクが最も単純であり、推論タスクが最も複雑です。
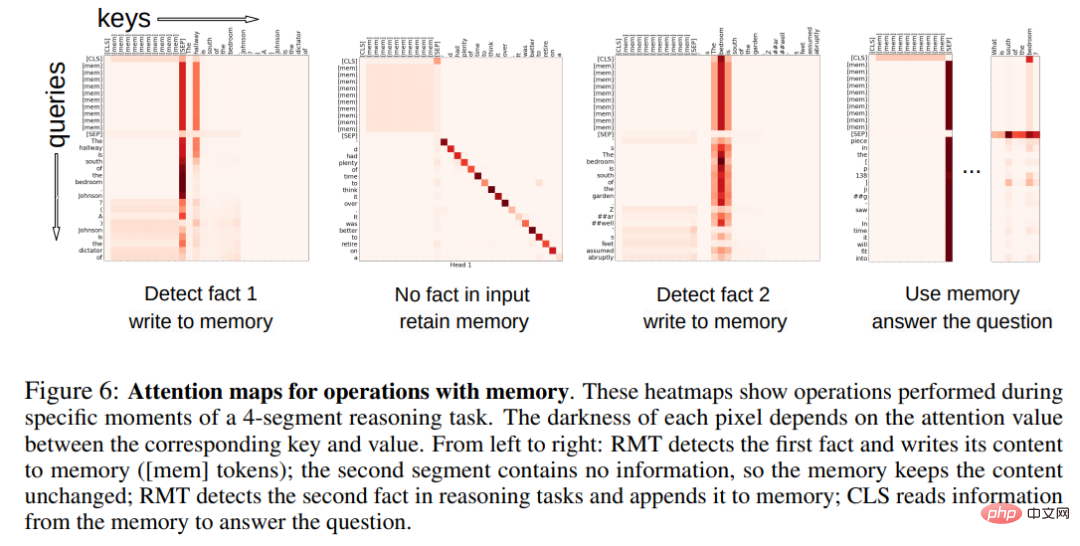
メモリ操作のアテンション パターン以下の図 6 では、特定のセグメントに対する RMT アテンションを調べることで、研究者はメモリ操作が特定のアテンションに対応していることを観察しました。モデル。さらに、セクション 5.2 の非常に長いシーケンスに対する高い外挿パフォーマンスは、何千回使用された場合でも、学習されたメモリ操作の有効性を示しています。
技術的および実験的な詳細については、元の論文を参照してください。
以上が真の量子速読:一度に50ページのテキストしか理解できないGPT-4の限界を突破、新しい研究は数百万のトークンにまで拡張の詳細内容です。詳細については、PHP 中国語 Web サイトの他の関連記事を参照してください。

ホットAIツール

Undresser.AI Undress
リアルなヌード写真を作成する AI 搭載アプリ

AI Clothes Remover
写真から衣服を削除するオンライン AI ツール。

Undress AI Tool
脱衣画像を無料で

Clothoff.io
AI衣類リムーバー

Video Face Swap
完全無料の AI 顔交換ツールを使用して、あらゆるビデオの顔を簡単に交換できます。

人気の記事
ホットツール

メモ帳++7.3.1
使いやすく無料のコードエディター

SublimeText3 中国語版
中国語版、とても使いやすい

ゼンドスタジオ 13.0.1
強力な PHP 統合開発環境

ドリームウィーバー CS6
ビジュアル Web 開発ツール

SublimeText3 Mac版
神レベルのコード編集ソフト(SublimeText3)
ホットトピック
 7706
7706
 15
1640
14
1394
52
1288
25
1231
29
15
1640
14
1394
52
1288
25
1231
29

 WorldCoin(WLD)価格予測2025-2031:WLDは2031年までに4ドルに達しますか?
Apr 21, 2025 pm 02:42 PM
WorldCoin(WLD)価格予測2025-2031:WLDは2031年までに4ドルに達しますか?
Apr 21, 2025 pm 02:42 PM
WorldCoin(WLD)は、独自の生体認証とプライバシー保護メカニズムを備えた暗号通貨市場で際立っており、多くの投資家の注目を集めています。 WLDは、特にOpenai人工知能技術と組み合わせて、革新的なテクノロジーを備えたAltcoinsの間で驚くほど演奏しています。しかし、デジタル資産は今後数年間でどのように振る舞いますか? WLDの将来の価格を一緒に予測しましょう。 2025年のWLD価格予測は、2025年にWLDで大幅に増加すると予想されています。市場分析は、平均WLD価格が1.31ドルに達する可能性があり、最大1.36ドルであることを示しています。ただし、クマ市場では、価格は約0.55ドルに低下する可能性があります。この成長の期待は、主にWorldCoin2によるものです。
 クロスチェーントランザクションとはどういう意味ですか?クロスチェーントランザクションとは何ですか?
Apr 21, 2025 pm 11:39 PM
クロスチェーントランザクションとはどういう意味ですか?クロスチェーントランザクションとは何ですか?
Apr 21, 2025 pm 11:39 PM
クロスチェーントランザクションをサポートする交換:1。Binance、2。Uniswap、3。Sushiswap、4。CurveFinance、5。Thorchain、6。1inchExchange、7。DLNTrade、これらのプラットフォームはさまざまな技術を通じてマルチチェーン資産トランザクションをサポートします。
 「ブラックマンデーセル」は、暗号通貨業界にとって厳しい日です
Apr 21, 2025 pm 02:48 PM
「ブラックマンデーセル」は、暗号通貨業界にとって厳しい日です
Apr 21, 2025 pm 02:48 PM
暗号通貨市場での突入は投資家の間でパニックを引き起こし、Dogecoin(Doge)は最も困難なヒット分野の1つになりました。その価格は急激に下落し、分散財務財務(DEFI)(TVL)の総価値が激しく減少しました。 「ブラックマンデー」の販売波が暗号通貨市場を席巻し、ドゲコインが最初にヒットしました。そのdefitVLは2023レベルに低下し、通貨価格は過去1か月で23.78%下落しました。 DogecoinのDefitVLは、主にSOSO値指数が26.37%減少したため、272万ドルの安値に低下しました。退屈なDAOやThorchainなどの他の主要なDefiプラットフォームも、それぞれ24.04%と20減少しました。
 カーネルエアドロップ報酬を獲得する方法バイナンスフルプロセス戦略
Apr 21, 2025 pm 01:03 PM
カーネルエアドロップ報酬を獲得する方法バイナンスフルプロセス戦略
Apr 21, 2025 pm 01:03 PM
暗号通貨の賑やかな世界では、新しい機会が常に現れます。現在、Kerneldao(Kernel)Airdropアクティビティは多くの注目を集め、多くの投資家の注目を集めています。それで、このプロジェクトの起源は何ですか? BNBホルダーはそれからどのような利点を得ることができますか?心配しないでください、以下はあなたのためにそれを一つ一つ明らかにします。
 なぜ仮想通貨価格の上昇または下落があるのですか?なぜ仮想通貨価格の上昇または下落があるのですか?
Apr 21, 2025 am 08:57 AM
なぜ仮想通貨価格の上昇または下落があるのですか?なぜ仮想通貨価格の上昇または下落があるのですか?
Apr 21, 2025 am 08:57 AM
仮想通貨価格の上昇の要因には、次のものが含まれます。1。市場需要の増加、2。供給の減少、3。刺激された肯定的なニュース、4。楽観的な市場感情、5。マクロ経済環境。衰退要因は次のとおりです。1。市場需要の減少、2。供給の増加、3。ネガティブニュースのストライキ、4。悲観的市場感情、5。マクロ経済環境。
 Web3トレーディングプラットフォームranking_web3グローバル交換トップ10の概要
Apr 21, 2025 am 10:45 AM
Web3トレーディングプラットフォームranking_web3グローバル交換トップ10の概要
Apr 21, 2025 am 10:45 AM
Binanceは、グローバルデジタルアセット取引エコシステムの大君主であり、その特性には次のものが含まれます。1。1日の平均取引量は1,500億ドルを超え、500の取引ペアをサポートし、主流の通貨の98%をカバーしています。 2。イノベーションマトリックスは、デリバティブ市場、Web3レイアウト、教育システムをカバーしています。 3.技術的な利点は、1秒あたり140万のトランザクションのピーク処理量を伴うミリ秒のマッチングエンジンです。 4.コンプライアンスの進捗状況は、15か国のライセンスを保持し、ヨーロッパと米国で準拠した事業体を確立します。
 Aavenomicsは、Aaveプロトコルトークンを変更し、Tokenの買戻しを導入するための推奨事項です。
Apr 21, 2025 pm 06:24 PM
Aavenomicsは、Aaveプロトコルトークンを変更し、Tokenの買戻しを導入するための推奨事項です。
Apr 21, 2025 pm 06:24 PM
Aavenomicsは、Aaveプロトコルトークンを変更し、Aavedaoの定足数を実装したToken Reposを導入する提案です。 Aave Project Chain(ACI)の創設者であるMarc Zellerは、これをXで発表し、契約の新しい時代をマークしていることに注目しました。 Aave Chain Initiative(ACI)の創設者であるMarc Zellerは、Aavenomicsの提案にAave Protocolトークンの変更とトークンリポジトリの導入が含まれていると発表しました。 Zellerによると、これは契約の新しい時代を告げています。 Aavedaoのメンバーは、水曜日の週に100でした。
 通貨サークルでのレバレッジされた交換のランキングは
Apr 21, 2025 pm 11:24 PM
通貨サークルでのレバレッジされた交換のランキングは
Apr 21, 2025 pm 11:24 PM
2025年のレバレッジド取引、セキュリティ、ユーザーエクスペリエンスで優れたパフォーマンスを持つプラットフォームは次のとおりです。1。OKX、高周波トレーダーに適しており、最大100倍のレバレッジを提供します。 2。世界中の多通貨トレーダーに適したバイナンス、125倍の高いレバレッジを提供します。 3。Gate.io、プロのデリバティブプレーヤーに適し、100倍のレバレッジを提供します。 4。ビットゲットは、初心者やソーシャルトレーダーに適しており、最大100倍のレバレッジを提供します。 5。Kraken、安定した投資家に適しており、5倍のレバレッジを提供します。 6。Altcoinエクスプローラーに適したBybit。20倍のレバレッジを提供します。 7。低コストのトレーダーに適したKucoinは、10倍のレバレッジを提供します。 8。ビットフィネックス、シニアプレイに適しています
