

ビッグデータAI分野におけるプライバシーコンピューティングの応用実践

#01 プライバシー コンピューティングの背景と現状
1. プライバシー コンピューティングの背景
プライバシー コンピューティングは今や必需品となっています。一方で、個人ユーザーのプライバシーや情報セキュリティに対する要求はますます強くなっています。一方で、欧州連合のGDPR、米国のCCPA、国内の個人情報保護法など、プライバシーやセキュリティに関連する法令が数多く発布され、規制や政策は緩やかなものから厳格なものへと徐々に変化してきています。 、主に権利利益、実施範囲、執行力等に反映されます。 GDPRを例に挙げると、2018年に発効して以来、1,000件を超える事件が発生し、罰金総額は110億を超え、単一の罰金の最高額は50億を超えている(Amazon)。


#これに関連して、データ セキュリティはオプションから必須に変わりました。これにより、多数の企業、投資、新興企業、専門家がセキュリティとプライバシー技術のエコシステムに投資するようになり、学術界は業界のニーズに応えて多くの将来を見据えた調査を実施してきました。これらの要因は、近年のセキュリティおよびプライバシーのテクノロジとエコシステムの精力的な発展に貢献しており、その中で、差分プライバシー、信頼できる実行環境、準同型暗号化、安全なマルチパーティ コンピューティング、フェデレーテッド ラーニングなどのテクノロジはすべて大きな進歩を遂げています。 Gartner もこの分野の発展に楽観的であり、将来的には数百億、さらには数千億の価値がある市場になると信じています。
 ##02
##02
ビッグデータ AI プライバシー コンピューティング1. ビッグデータ AI の背景
ビッグデータ AI の背景に戻り、業界のマクロな視点からビッグデータを説明します。このフレームワークとテクノロジーは商品化され、大規模に普及しています。私たちは常にビッグ データ テクノロジーを使用しているかもしれませんが、プログラムやモデルのトレーニングが数千、さらには数万のノードと大規模なデータからなるサーバー クラスター上で実行されているとは感じません。近年、この分野の開発方向には 2 つの新しい傾向があります。1 つは使いやすさの向上、もう 1 つは応用方向の洗練です。前者はビッグ データ テクノロジの使用の敷居を大幅に下げましたが、後者はデータ レイクなどの新たなニーズや問題に対する新しいソリューションを提供し続けています。
#AI フレームワークとの組み合わせという観点から見ると、ビッグデータと AI エコシステムは密接に統合されています。 AI モデルの場合、データ量が多く、品質が高いほどモデルの学習効果が高まるため、ビッグデータと AI の 2 つの分野は自然に組み合わされます。
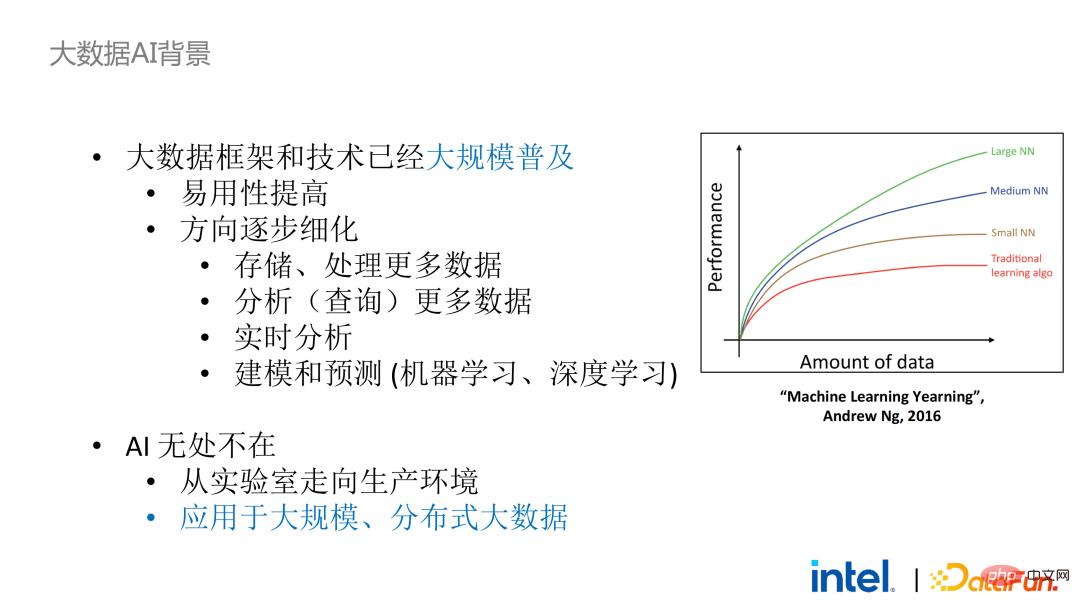 ##しかし、それでもビッグデータフレームワークとAIフレームワークの統合は簡単ではありません。アプリケーション開発、データ取得、クリーニング、分析、展開のプロセスでは、多くのビッグデータと AI フレームワークが関係します。主要なプロセスでデータのセキュリティとプライバシーを確保する必要がある場合、さまざまなセキュリティ テクノロジ、暗号化テクノロジ、キー管理テクノロジなど、多くのリンクとフレームワークが関係するため、変換と移行のコストが大幅に増加します。
##しかし、それでもビッグデータフレームワークとAIフレームワークの統合は簡単ではありません。アプリケーション開発、データ取得、クリーニング、分析、展開のプロセスでは、多くのビッグデータと AI フレームワークが関係します。主要なプロセスでデータのセキュリティとプライバシーを確保する必要がある場合、さまざまなセキュリティ テクノロジ、暗号化テクノロジ、キー管理テクノロジなど、多くのリンクとフレームワークが関係するため、変換と移行のコストが大幅に増加します。
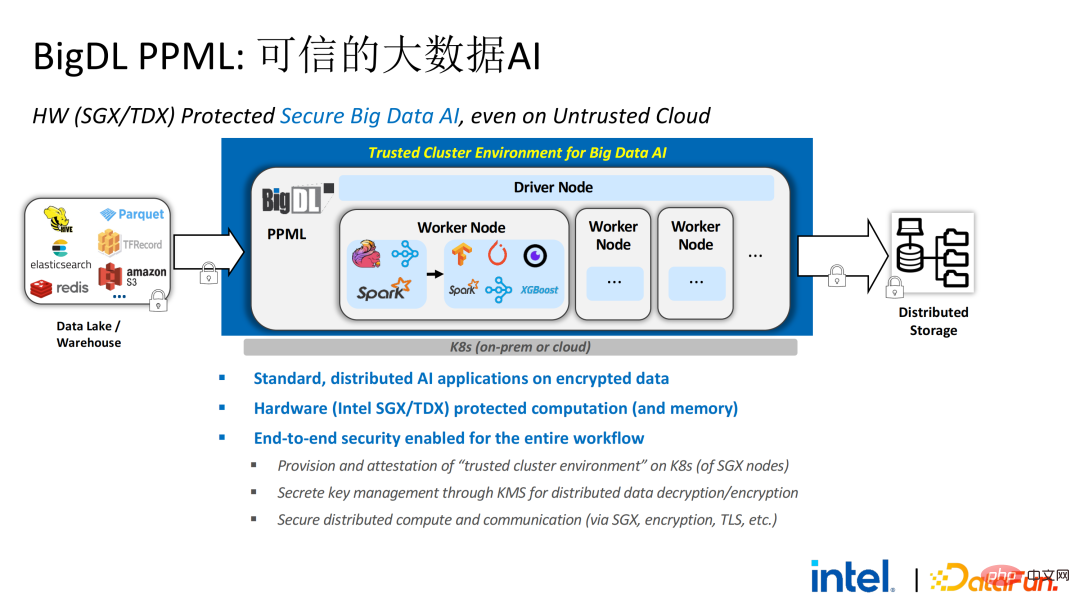
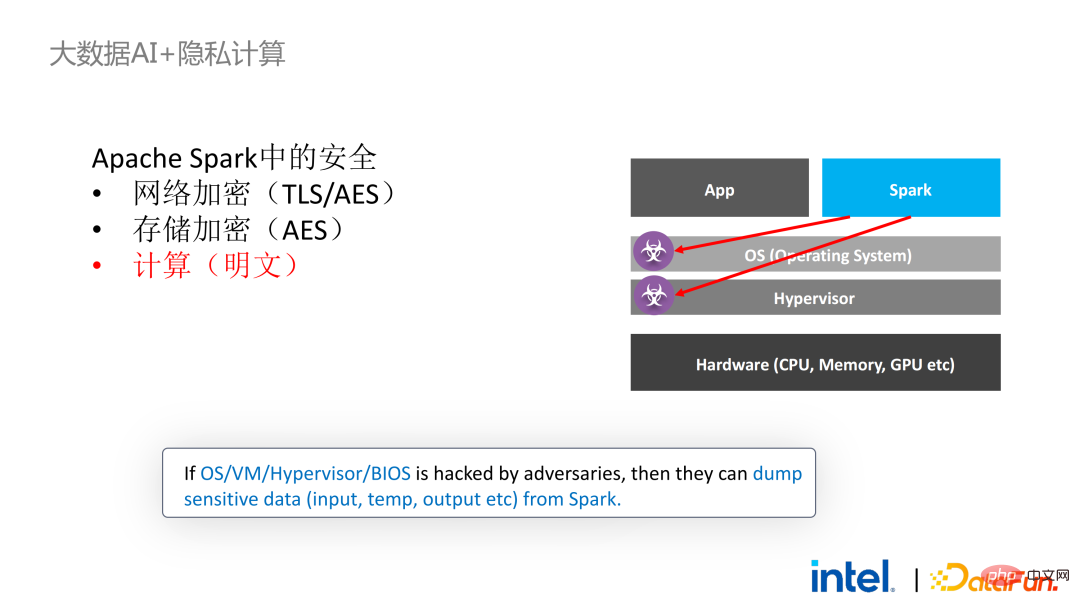
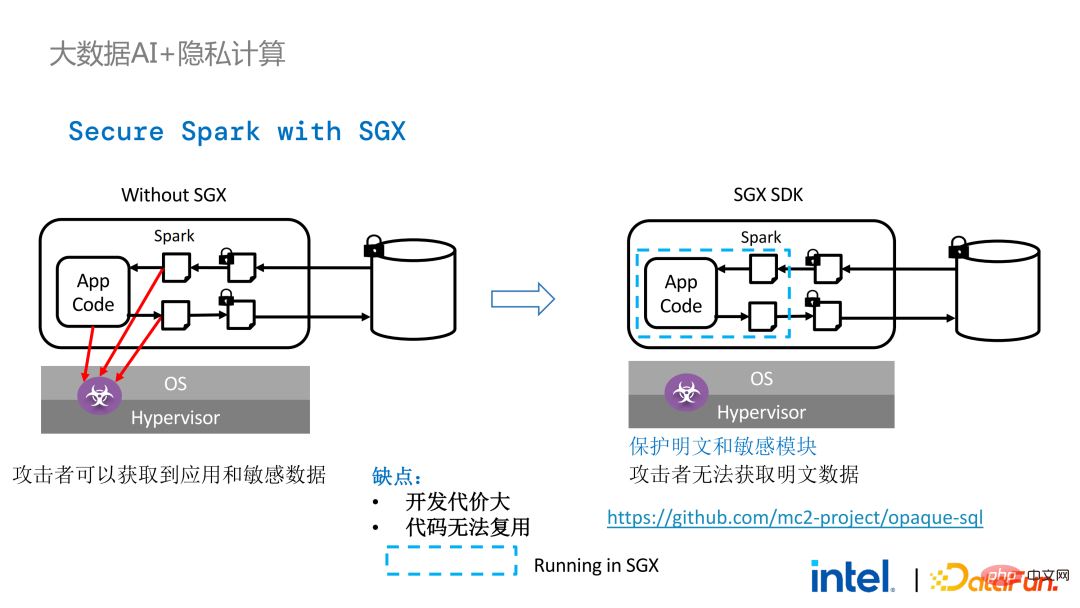
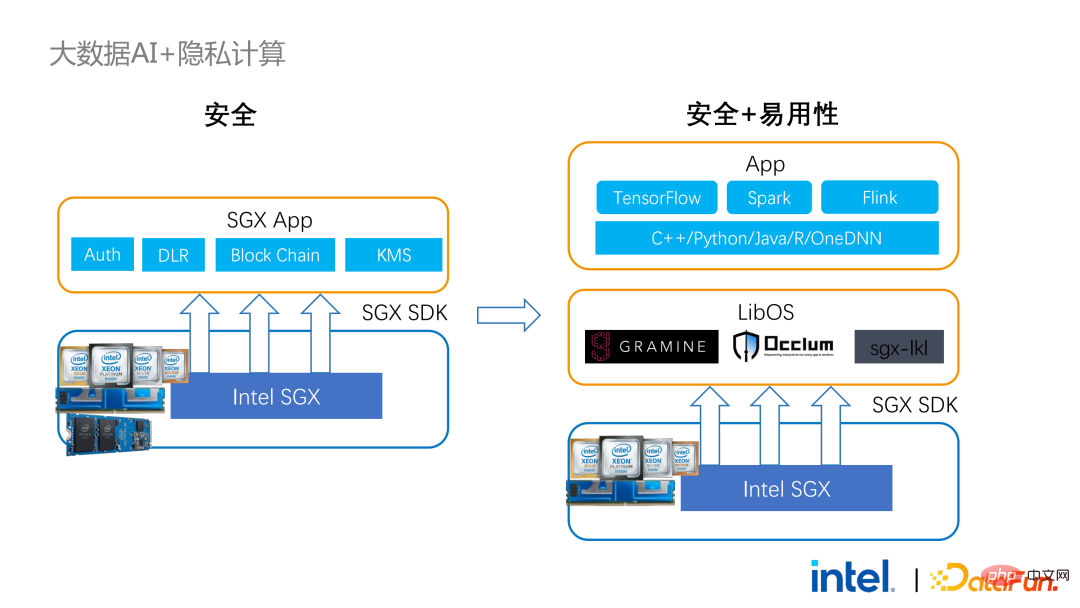
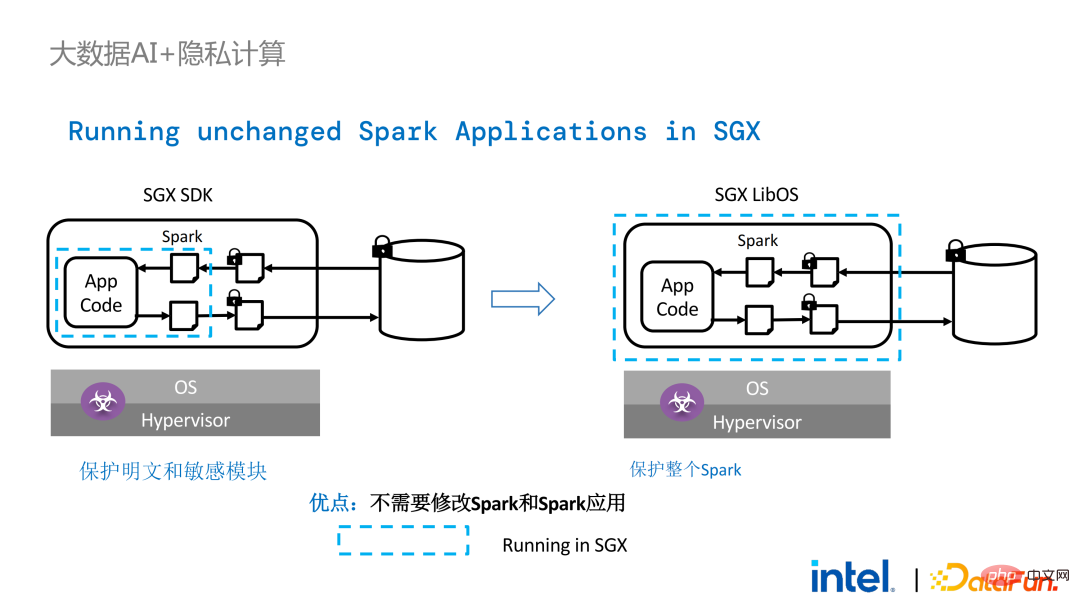
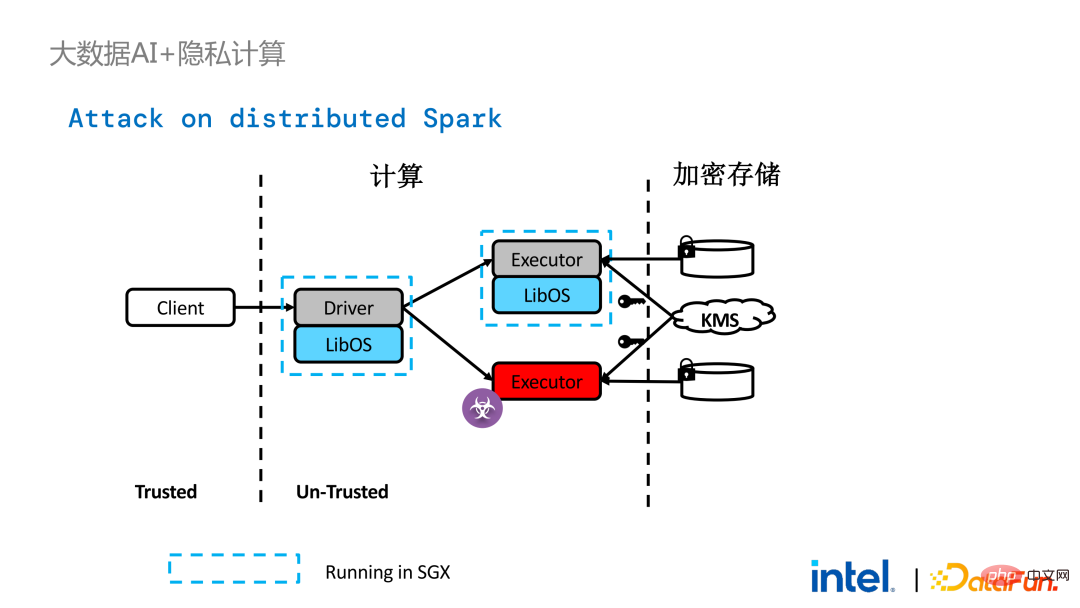
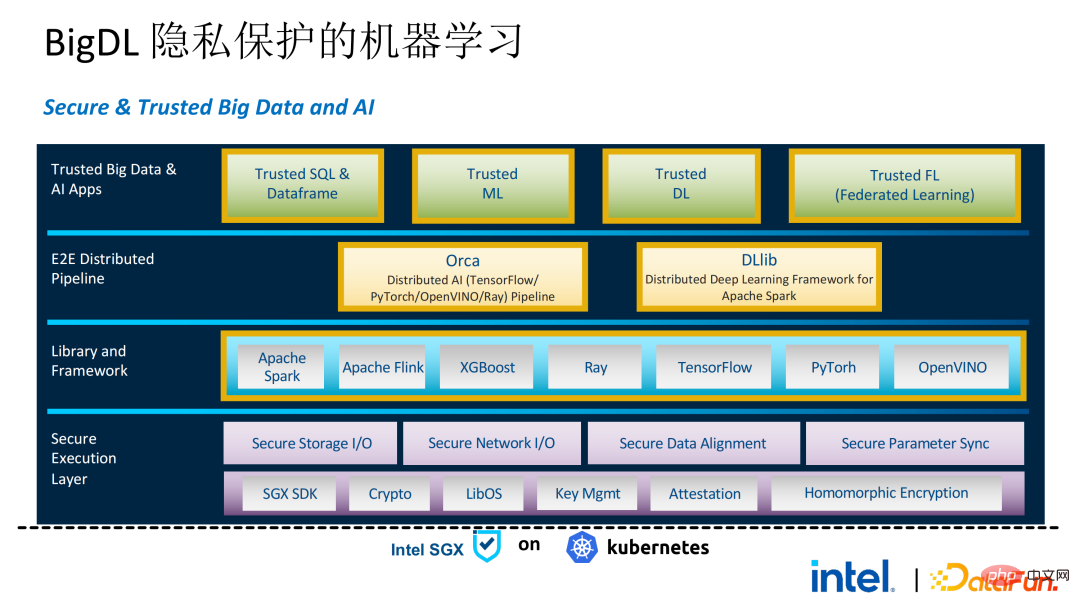
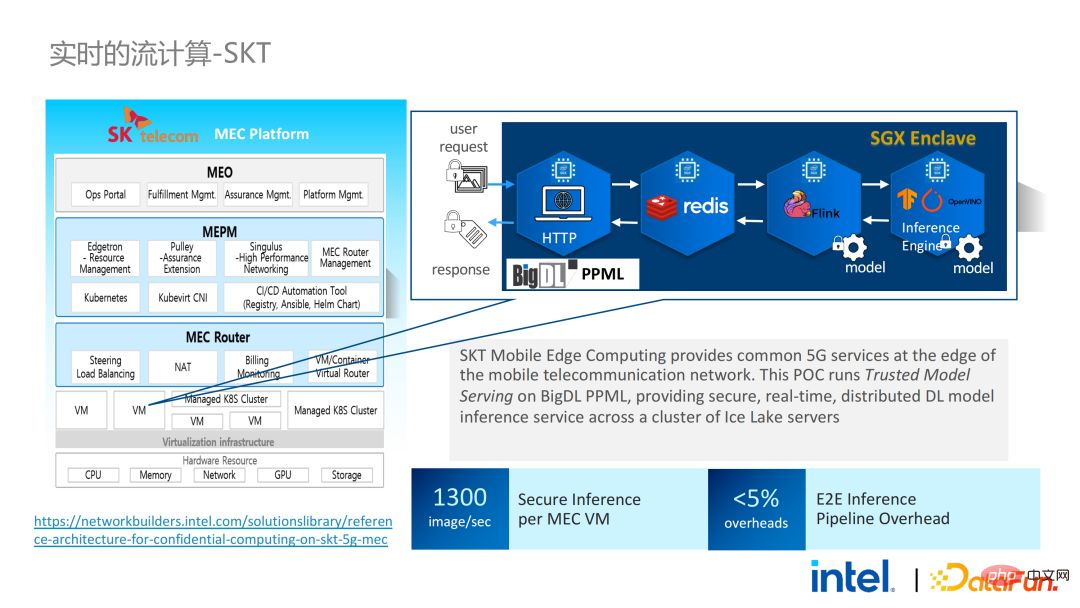
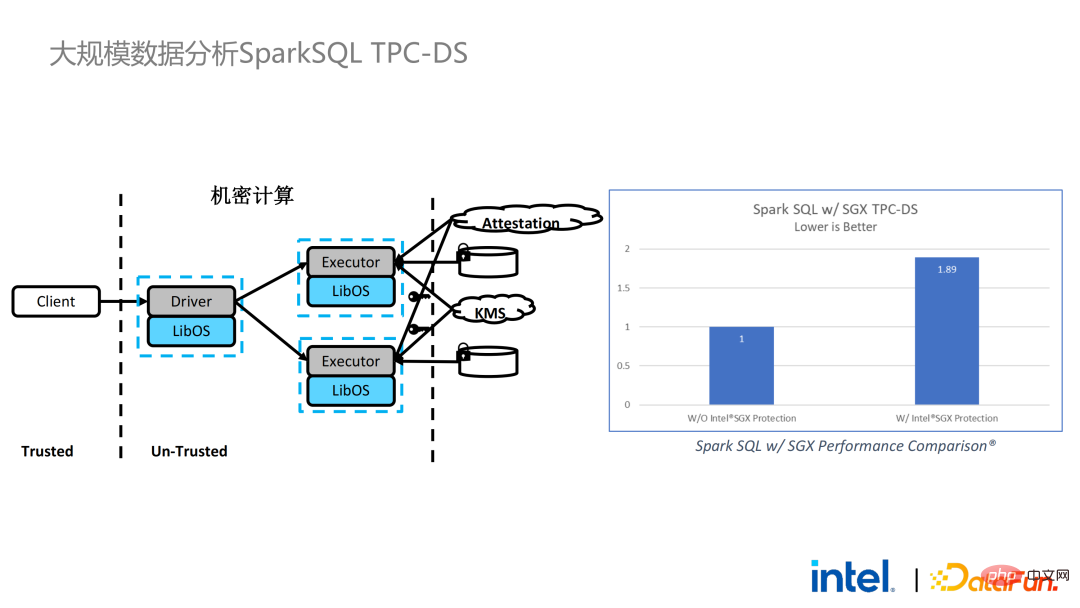
2 年前、業界のビッグ データと AI アプリケーションに関連する顧客とのコミュニケーションの過程で、ユーザーの問題点をいくつか収集しました。一般的なパフォーマンスの問題に加えて、ほとんどのお客様が最初に懸念するのは互換性の問題です。たとえば、一部の顧客はすでに数千、さらには数万のノードを持つクラスターを所有していますが、一部のモジュールやリンクを安全に処理し、プライバシー コンピューティング テクノロジを適用してプライバシー保護機能を実現する必要がある場合は、既存のアプリケーションに変更を加える必要がある場合があります。 、あるいはまったく新しいフレームワークやインフラストラクチャを導入することさえありますが、これらの影響は、お客様が考慮する必要がある主な問題です。第二に、顧客はデータ規模がセキュリティ技術に与える影響を考慮し、導入された新しいフレームワークや技術が大規模データの計算をサポートし、高い計算効率を実現できることを期待します。最後に、顧客はフェデレーテッド ラーニング テクノロジーがデータ アイランドの問題を解決できるかどうかを検討します。 調査から得られたお客様のニーズに基づいて、 BigDL PPML ソリューションを開始しました 、 主な目標は、従来の標準的なビッグデータおよび AI ソリューションを安全な環境で実行できるようにして、エンドツーエンドのセキュリティを確保することです。この目的のために、コンピューティング プロセスは SGX (ハードウェア レベル TEE) によって保護される必要があります。同時に、ストレージとネットワークが暗号化されていることを確認する必要があり、計算の機密性と整合性を確保するためにリンク全体がリモートで証明される必要があります (リモート署名とも呼ばれます)。 #次は、Apache Spark を使用します。データ フレームワークは、このソリューションの必要性を詳しく説明する例として使用されます#。 Apache Sparkは、ビッグデータAI分野でよく使われる分散コンピューティングフレームワークであり、ネットワークの暗号化や認証、TLSやAESによる通信やRPCの保護、主にストレージなどのセキュリティ関連の機能を既に備えています。ローカル シャッフル ストレージも AES によって保護されていますが、最新バージョンの Spark でも平文計算しか実行できないため、計算に大きな問題があります。コンピューティング環境またはノードが侵害されると、大量の機密データが取得される可能性があります。 ハードウェア レベルの信頼性を備えています。情報実行環境 左側はコンピューティング環境が保護されていない状況を示しており、たとえ暗号化されたストレージを利用していても、平文計算の段階で攻撃を受ける限り、被害を受けるリスクがあります。データ漏洩。右側は Spark コミュニティによるいくつかの試みを示しています。SparkSQL に関連するいくつかの重要な手順を抽出し、ロジックのこの部分を SGX SDK で書き直すことで、パフォーマンスを最大化し、攻撃対象領域を最小限に抑えることができます。しかしながら、この方法の欠点も明らかであり、開発コストが高すぎ、コストが高すぎる。 SparkSQL のコア ロジックを再構築するには、Spark を明確に理解する必要がありますが、同時にコードを他のプロジェクトで再利用することはできません。 上記の欠点を解決するために、 LibOS ソリューションを使用します 、つまり、LibOS の中間層を通じて、開発と移行の困難さを軽減し、システム API 呼び出しを SGX SDK で認識できる形式に変換することで、一部の従来のアプリケーションのシームレスな移行を実現します。一般的な LibOS ソリューションには、Ant Group の Occlum、Intel の Gramine、Imperial College の sgx-lkl ソリューションなどがあります。上記の LibOS にはそれぞれ独自の機能と利点があり、SGX の使いやすさと移植性の問題をさまざまな方法で解決します。 LibOS では、Spark を書き直す必要はありません。 Spark や既存のアプリケーションを変更することなく、LibOS を通じて Spark 全体を SGX に組み込むことができます。 Spark の分散コンピューティングでは、次のことができます。配布はそれぞれ LibOS と SGX で保護され、ストレージ側はキー管理と暗号化ストレージを構成でき、実行者は暗号文データを取得し、SGX で復号化および計算します。プロセス全体は開発者にとって比較的影響を受けず、既存のアプリケーションへの影響はほとんどありません。 #ただし、スタンドアロン アプリケーションと比較すると、分散アプリケーションのセキュリティ問題もより複雑になります。攻撃者は、一部のオペレーティング ノードを侵害したり、リソース管理ノードと共謀して、SGX 環境を悪意のあるオペレーティング環境に置き換える可能性があります。このようにして、鍵や暗号化されたデータが不正に取得され、最終的には個人データが漏洩する可能性があります。 リモート認証技術を適用する必要があります。簡単に言うと、SGX で実行されるアプリケーションは証明書を提供でき、証明書は改ざんできません。証明書は、アプリケーションが SGX で実行されているかどうか、アプリケーションが改ざんされているかどうか、プラットフォームがセキュリティ標準を満たしているかどうかを検証できます。 。左側は比較的完全ですが大幅に変更されたソリューションで、ドライバー側とエグゼキューター側でリモート構成証明を実行するには、Spark をある程度変更する必要があります。もう 1 つの解決策は、サードパーティのリモート認証サーバーを通じて集中リモート認証を実装し、変更不可能な証明書を使用して攻撃者が制御するモジュールがデータを取得するのをブロックすることです。 2 番目のオプションでは、アプリケーションを変更する必要はありませんが、起動スクリプトの一部を変更するだけで済みます。 LibOS を使用すると、Spark を SGX で実行できますが、Spark を LibOS および SGX に適応させるには、やはり一定の時間がかかります。 . 人件費と時間コスト。 ワークフローの観点から見ると、このソリューションにはもう 利点があります。つまり、データ サイエンティストは根本的な変更を認識できず、クラスター管理者のみが SGX の展開と準備に参加する必要があります。データ サイエンティストは、基盤となる環境が変化したことを意識することなく、通常どおりモデリングとクエリ作業を実行できます。これにより、既存のアプリケーションの互換性と移行の問題を十分に解決でき、データ サイエンティストや開発者の日常業務が妨げられることはありません。 以下は、PPML ソリューション全体の概要です。お客様のさまざまなニーズに応えるため、PPML がサポートする機能は過去 2 年間で継続的に拡張されてきました。たとえば、中間層のライブラリとフレームワークでは、Spark、Flink、Ray などの一般的なコンピューティング フレームワークがすべてサポートされていると同時に、PPML は機械学習、ディープ ラーニング、フェデレーテッド ラーニング機能もサポートしており、暗号化ストレージと準同型暗号化をサポートし、エンドツーエンドの完全なリンク セキュリティを確保します。 次はいくつかのお客様のアプリケーション実践事例のうち、より有名なものは昨年の Tianchi Competition です。昨年のサブコンペでは、参加者はトレーニングとモデル推論のプロセスが SGX によって完全に保護されることを期待していましたが、PPML が提供する Flink 機能と Ant Group の LibOS プロジェクト Occlum を組み合わせることで、トレーニングとモデル推論を非表示にすることができました。アプリケーションレベルで。最終的には、コンテスト全体に 4,000 を超えるチームが参加し、数百台のサーバーが使用され、PPML が大規模な商用利用をサポートできることが証明されました。全体として、オペレーターは大きな変化を認識しませんでした。 ##同年の 9 月から 10 月にかけて、Korea Telecom はエンドツー エンド サービスを構築したいと考えていました。 BigDL と Flink に基づく安全なリアルタイム モデル推論環境には、より厳しいパフォーマンス要件があります。 Tianchi の経験を経て、Flink と SGX に基づく BigDL のリアルタイム モデル推論ソリューションはさらに成熟し、エンドツーエンドのパフォーマンス損失は 5% 未満であり、スループットも韓国通信の基本ニーズを満たしています。
前述のように、2 年以上にわたるお客様とのコミュニケーションと協力の中で、私たちは次のことを発見しました。私たちはプライバシー コンピューティングとビッグ データ AI に関連するいくつかの問題点に到達しました。これらの問題点は、SGX などのセキュリティ テクノロジによって解決できます。その中で、LibOS は互換性の問題を解決でき、SGX はセキュリティ環境とパフォーマンスの問題を解決でき、Spark または Flink のサポートはビッグ データと移行の問題を解決でき、フェデレーション ラーニングはデータ アイランドの問題を解決できます。 BigDL PPML は、上記のサービスを統合したワンストップのプライバシー コンピューティング ソリューションです。 SGX と TEE の生態系は現在急速に発展しています。近い将来、TEE は使いやすさ、セキュリティ、パフォーマンスの点で大幅に改善されるでしょう。たとえば、Intel の次世代 TDX は OS サポートを直接提供でき、アプリケーションの互換性の問題を根本的に解決できます。オープンソース コミュニティも改善されています。機密コンテナのサポートにより、コンテナのセキュリティが確保され、アプリケーションの移行コストが大幅に削減されます。セキュリティの観点から見ると、TEE エコシステムのセキュリティをさらに強化するためのマイクロカーネルなどの取り組みも登場するでしょう。スケーラビリティの観点から、インテルとコミュニティはアクセラレータと IO デバイスのサポートも推進しており、それらを信頼できるドメインに組み込んでデータ フローのパフォーマンスのオーバーヘッドを削減します。 
2. ビッグ データ AI プライバシー コンピューティング

 SGX テクノロジー
SGX テクノロジー
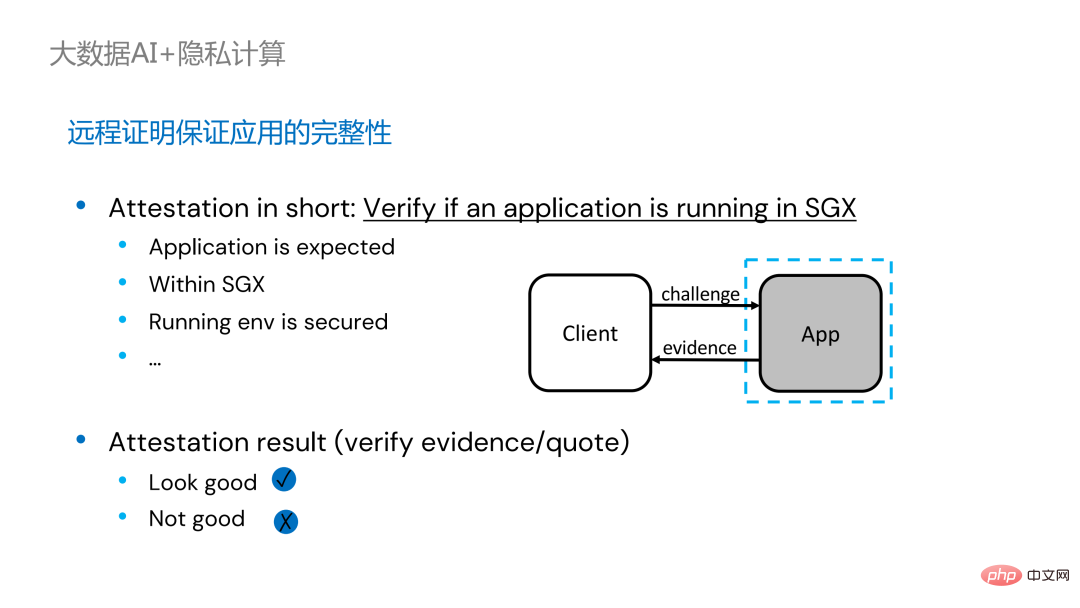 #分散アプリケーションのリモート構成証明を実装するには 2 つの方法があります
#分散アプリケーションのリモート構成証明を実装するには 2 つの方法があります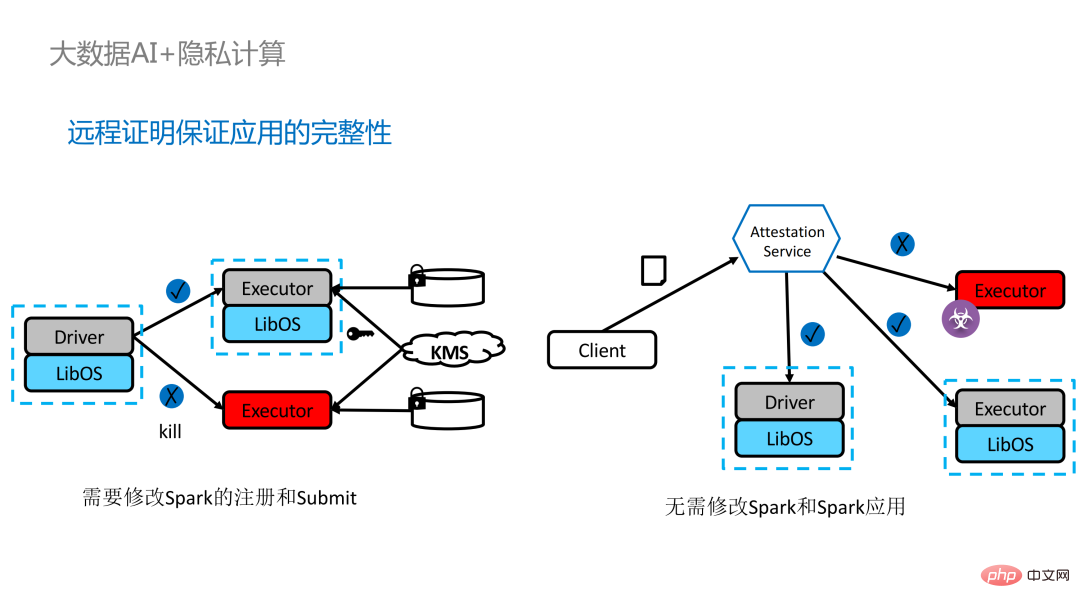 この目的を達成するために、私たちは PPML
この目的を達成するために、私たちは PPML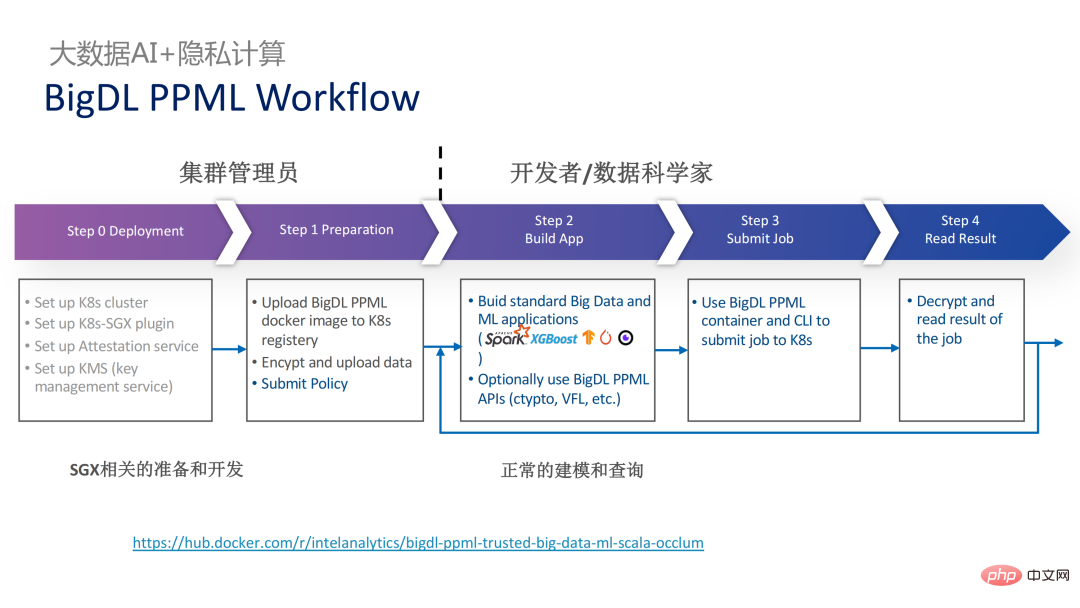
##03 アプリケーションの実践

 #ビッグデータ アプリケーションのシームレスな移行を実現した後、一部のお客様とフェデレーテッド ラーニングも試しました。 SGX は安全な環境を提供するため、フェデレーテッド ラーニング プロセスにおける最も重要なサーバーとローカル データのセキュリティ問題を解決できます。 BigDL が提供するフェデレーテッド ラーニング ソリューションと一般的なソリューションの間には大きな違いがあります。つまり、ソリューション全体が本質的に大規模データ用のフェデレーテッド ラーニング ソリューションです。このうち、各ワーカーの作業負荷やデータサイズは比較的大きく、各ワーカーは小さなクラスターに相当します。私たちは一部のお客様に対してこのソリューションの実現可能性と有効性を検証しました。
#ビッグデータ アプリケーションのシームレスな移行を実現した後、一部のお客様とフェデレーテッド ラーニングも試しました。 SGX は安全な環境を提供するため、フェデレーテッド ラーニング プロセスにおける最も重要なサーバーとローカル データのセキュリティ問題を解決できます。 BigDL が提供するフェデレーテッド ラーニング ソリューションと一般的なソリューションの間には大きな違いがあります。つまり、ソリューション全体が本質的に大規模データ用のフェデレーテッド ラーニング ソリューションです。このうち、各ワーカーの作業負荷やデータサイズは比較的大きく、各ワーカーは小さなクラスターに相当します。私たちは一部のお客様に対してこのソリューションの実現可能性と有効性を検証しました。
04 概要と展望


以上がビッグデータAI分野におけるプライバシーコンピューティングの応用実践の詳細内容です。詳細については、PHP 中国語 Web サイトの他の関連記事を参照してください。

ホットAIツール

Undresser.AI Undress
リアルなヌード写真を作成する AI 搭載アプリ

AI Clothes Remover
写真から衣服を削除するオンライン AI ツール。

Undress AI Tool
脱衣画像を無料で

Clothoff.io
AI衣類リムーバー

AI Hentai Generator
AIヘンタイを無料で生成します。

人気の記事
ホットツール

メモ帳++7.3.1
使いやすく無料のコードエディター

SublimeText3 中国語版
中国語版、とても使いやすい

ゼンドスタジオ 13.0.1
強力な PHP 統合開発環境

ドリームウィーバー CS6
ビジュアル Web 開発ツール

SublimeText3 Mac版
神レベルのコード編集ソフト(SublimeText3)
ホットトピック
 7555
7555
 15
1382
52
83
11
28
96
15
1382
52
83
11
28
96

 Centosシャットダウンコマンドライン
Apr 14, 2025 pm 09:12 PM
Centosシャットダウンコマンドライン
Apr 14, 2025 pm 09:12 PM
Centos Shutdownコマンドはシャットダウンし、構文はシャットダウン[オプション]時間[情報]です。オプションは次のとおりです。-hシステムをすぐに停止します。 -pシャットダウン後に電源をオフにします。 -r再起動; -t待機時間。時間は、即時(現在)、数分(分)、または特定の時間(HH:mm)として指定できます。追加の情報をシステムメッセージに表示できます。
 Centosのgitlabのバックアップ方法は何ですか
Apr 14, 2025 pm 05:33 PM
Centosのgitlabのバックアップ方法は何ですか
Apr 14, 2025 pm 05:33 PM
Centosシステムの下でのGitlabのバックアップと回復ポリシーデータセキュリティと回復可能性を確保するために、Gitlab on Centosはさまざまなバックアップ方法を提供します。この記事では、いくつかの一般的なバックアップ方法、構成パラメーター、リカバリプロセスを詳細に紹介し、完全なGitLabバックアップと回復戦略を確立するのに役立ちます。 1.手動バックアップGitlab-RakeGitlabを使用:バックアップ:コマンドを作成して、マニュアルバックアップを実行します。このコマンドは、gitlabリポジトリ、データベース、ユーザー、ユーザーグループ、キー、アクセスなどのキー情報をバックアップします。デフォルトのバックアップファイルは、/var/opt/gitlab/backupsディレクトリに保存されます。 /etc /gitlabを変更できます
 CentOS HDFS構成をチェックする方法
Apr 14, 2025 pm 07:21 PM
CentOS HDFS構成をチェックする方法
Apr 14, 2025 pm 07:21 PM
CENTOSシステムでHDFS構成をチェックするための完全なガイドこの記事では、CENTOSシステム上のHDFSの構成と実行ステータスを効果的に確認する方法をガイドします。次の手順は、HDFSのセットアップと操作を完全に理解するのに役立ちます。 Hadoop環境変数を確認します。最初に、Hadoop環境変数が正しく設定されていることを確認してください。端末では、次のコマンドを実行して、Hadoopが正しくインストールおよび構成されていることを確認します。HDFS構成をチェックするHDFSファイル:HDFSのコア構成ファイルは/etc/hadoop/conf/ディレクトリにあります。使用
 CentosのPytorchのGPUサポートはどのようにサポートされていますか
Apr 14, 2025 pm 06:48 PM
CentosのPytorchのGPUサポートはどのようにサポートされていますか
Apr 14, 2025 pm 06:48 PM
Pytorch GPUアクセラレーションを有効にすることで、CentOSシステムでは、PytorchのCUDA、CUDNN、およびGPUバージョンのインストールが必要です。次の手順では、プロセスをガイドします。CUDAおよびCUDNNのインストールでは、CUDAバージョンの互換性が決定されます。NVIDIA-SMIコマンドを使用して、NVIDIAグラフィックスカードでサポートされているCUDAバージョンを表示します。たとえば、MX450グラフィックカードはCUDA11.1以上をサポートする場合があります。 cudatoolkitのダウンロードとインストール:nvidiacudatoolkitの公式Webサイトにアクセスし、グラフィックカードでサポートされている最高のCUDAバージョンに従って、対応するバージョンをダウンロードしてインストールします。 cudnnライブラリをインストールする:
 Centosはmysqlをインストールします
Apr 14, 2025 pm 08:09 PM
Centosはmysqlをインストールします
Apr 14, 2025 pm 08:09 PM
CentOSにMySQLをインストールするには、次の手順が含まれます。適切なMySQL Yumソースの追加。 yumを実行して、mysql-serverコマンドをインストールして、mysqlサーバーをインストールします。ルートユーザーパスワードの設定など、MySQL_SECURE_INSTALLATIONコマンドを使用して、セキュリティ設定を作成します。必要に応じてMySQL構成ファイルをカスタマイズします。 MySQLパラメーターを調整し、パフォーマンスのためにデータベースを最適化します。
 Dockerの原則の詳細な説明
Apr 14, 2025 pm 11:57 PM
Dockerの原則の詳細な説明
Apr 14, 2025 pm 11:57 PM
DockerはLinuxカーネル機能を使用して、効率的で孤立したアプリケーションランニング環境を提供します。その作業原則は次のとおりです。1。ミラーは、アプリケーションを実行するために必要なすべてを含む読み取り専用テンプレートとして使用されます。 2。ユニオンファイルシステム(UnionFS)は、違いを保存するだけで、スペースを節約し、高速化する複数のファイルシステムをスタックします。 3.デーモンはミラーとコンテナを管理し、クライアントはそれらをインタラクションに使用します。 4。名前空間とcgroupsは、コンテナの分離とリソースの制限を実装します。 5.複数のネットワークモードは、コンテナの相互接続をサポートします。これらのコア概念を理解することによってのみ、Dockerをよりよく利用できます。
 Centos8はsshを再起動します
Apr 14, 2025 pm 09:00 PM
Centos8はsshを再起動します
Apr 14, 2025 pm 09:00 PM
SSHサービスを再起動するコマンドは次のとおりです。SystemCTL再起動SSHD。詳細な手順:1。端子にアクセスし、サーバーに接続します。 2。コマンドを入力します:SystemCtl RestArt SSHD; 3.サービスステータスの確認:SystemCTLステータスSSHD。
 CentosでPytorchの分散トレーニングを操作する方法
Apr 14, 2025 pm 06:36 PM
CentosでPytorchの分散トレーニングを操作する方法
Apr 14, 2025 pm 06:36 PM
Pytorchの分散トレーニングでは、Centosシステムでトレーニングには次の手順が必要です。Pytorchのインストール:PythonとPipがCentosシステムにインストールされていることです。 CUDAバージョンに応じて、Pytorchの公式Webサイトから適切なインストールコマンドを入手してください。 CPUのみのトレーニングには、次のコマンドを使用できます。PipinstalltorchtorchtorchvisionTorchaudioGPUサポートが必要な場合は、CUDAとCUDNNの対応するバージョンがインストールされ、インストールに対応するPytorchバージョンを使用してください。分散環境構成:分散トレーニングには、通常、複数のマシンまたは単一マシンの複数GPUが必要です。場所
