
 テクノロジー周辺機器
AI
あなたの声を盗むのにかかる時間はわずか 3 秒です。 Microsoft、音声合成モデルVALL-Eをリリース:ネットユーザーは「電話詐欺」の敷居がまた下がったと叫ぶ
テクノロジー周辺機器
AI
あなたの声を盗むのにかかる時間はわずか 3 秒です。 Microsoft、音声合成モデルVALL-Eをリリース:ネットユーザーは「電話詐欺」の敷居がまた下がったと叫ぶ
あなたの声を盗むのにかかる時間はわずか 3 秒です。 Microsoft、音声合成モデルVALL-Eをリリース:ネットユーザーは「電話詐欺」の敷居がまた下がったと叫ぶ

ChatGPT を使用してスクリプトを作成し、Stable Diffusion でイラストを生成します。ビデオを作成するには声優が必要ですか?それが来るの!
最近、Microsoft の研究者は、新しいテキスト読み上げ (TTS) モデル VALL-E をリリースしました。これは、人間の声の入力をシミュレートするために 3 秒間の音声サンプルを提供するだけでよく、対応する音声が合成されます。入力テキストに基づいて、話者の感情的なトーンも維持できます。

論文リンク: https://www.php.cn/link/402cac3dacf2ef35050ca72743ae6ca7
プロジェクトリンク: https://valle-demo.github。 io/
コードリンク: https://github.com/microsoft/unilm
まず効果を見てみましょう: 3 秒間の録音があると仮定します。
diversity_speaker Audio: 00:0000:03
「必要ないから」と入力するだけで合成音声が得られます。
diversity_s1 Audio: 00:0000:01
異なるランダムシードを使用しても、パーソナライズされた音声合成を実行できます。
diversity_s2 Audio: 00:0000:02
VALL-E は、この音声を入力するなど、話者の周囲の音を維持することもできます。
env_speaker Audio: 00:0000:03
すると、「これも便利だと思いますよ。」というテキストに従って、周囲の音を維持したまま合成音声を出力することができます。 。
env_vall_eAudio: 00:0000:02
VALL-E は、怒りの声を入力するなど、話者の感情を維持することもできます。
anger_ptAudio: 00:0000:03
「ビニール袋の数を減らさなければなりません。」というテキストをもとに、怒りの感情を表現することもできます。
anger_oursAudio: 00:0000:02
プロジェクトの Web サイトには、さらに多くの例があります。
具体的には、研究者らは、既製のニューラル オーディオ コーデック モデルから抽出された離散エンコーディングから言語モデル VALL-E をトレーニングし、TTS を連続信号回帰ではなく条件付き言語モデリング タスクとして扱いました。
事前トレーニング段階で、VALL-E が受信した TTS トレーニング データは、英語音声の 60,000 時間に達しました。これは、既存のシステムで使用されるデータの数百倍です。
VALL-E は、コンテキスト内学習機能も実証しており、目に見えない話者の 3 秒間の登録録音を音声プロンプトとして使用するだけで、高品質のパーソナライズされた音声を合成できます。
実験結果は、VALL-E が、音声の自然さと話者の類似性の点で最先端のゼロショット TTS システムよりも大幅に優れており、話者の感情や音声の音響も保存できることを示しています。合成環境におけるサウンドキュー。
ゼロショット音声合成
過去 10 年にわたり、音声合成はニューラル ネットワークとエンドツーエンド モデリングの開発を通じて大きな進歩を遂げました。
しかし、現在のカスケード音声合成 (TTS) システムは、通常、音響モデルを備えたパイプラインと、中間表現としてメル スペクトログラムを使用するボコーダーを利用します。
一部の高性能 TTS システムは、単一または複数のスピーカーから高品質の音声を合成できますが、それでもレコーディング スタジオからの高品質でクリーンなデータが必要です。これは、録音スタジオから収集した大規模なデータでは実現できません。インターネット。データ要件を満たしているため、モデルのパフォーマンスの低下につながります。
トレーニング データの量が比較的少ないため、現在の TTS システムには汎化能力が低いという問題がまだあります。
ゼロショット タスク設定では、トレーニング データに現れていない話者の場合、音声の類似性と自然性が急激に低下します。
ゼロショット TTS 問題を解決するために、既存の作業では通常、スピーカー アダプテーションやスピーカー エンコーディングなどの方法が利用されており、追加の微調整や事前に設計された複雑な機能、または大掛かりな構造作業が必要です。
研究者らは、テキスト合成の成功を考慮すると、この問題に対して複雑で特殊なネットワークを設計するのではなく、可能な限り多様なデータを使用してモデルをトレーニングすることが究極の解決策であるべきだと考えています。
VALL-E モデル
テキスト合成の分野では、インターネットからの大規模なラベルなしデータがモデルに直接入力され、学習データの量が増加するにつれて、モデルのパフォーマンスが低下します。また常に改善しています。
研究者らはこのアイデアを音声合成の分野に移行し、VALL-E モデルは言語モデルに基づく初の TTS フレームワークであり、大量かつ多様な複数話者の音声データを利用します。
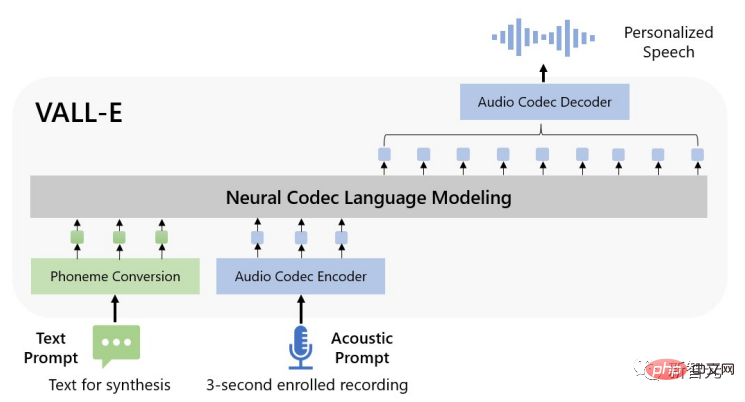
パーソナライズされた音声を合成するために、VALL-E モデルは、3 秒間の登録された録音の音響トークンと音素プロンプトに基づいて、対応する音響トークンを生成します。発言者やコンテンツ情報を制限します。
最後に、生成された音響トークンを使用して、対応するニューラル コーデックで最終波形を合成します。
オーディオ コーデック モデルからの離散音響トークンにより、TTS を条件付きコーデック言語モデリングとみなすことができるため、一部の高度なヒントベースの大規模モデル技術 (GPT など) を TTS タスクで使用できます。
音響トークンは、推論プロセス中にさまざまなサンプリング戦略を使用して、TTS で多様な合成結果を生成することもできます。
研究者らは、LibriLight データセットを使用して VALL-E をトレーニングしました。このデータセットは、7,000 人以上のユニークな話者による 60,000 時間の英語音声で構成されています。生データは音声のみであるため、トランスクリプトの生成には音声認識モデルのみが使用されます。
LibriTTS などの以前の TTS トレーニング データセットと比較すると、この論文で提供される新しいデータセットには、より多くのノイズのある音声と不正確な文字起こしが含まれていますが、異なる話者と音域 (韻律) が提供されます。
研究者らは、この記事で提案されている方法はノイズに強く、ビッグデータを利用して優れた一般性を実現できると考えています。

既存の TTS システムは、常に数十時間の単言語話者データ、または数百時間の多言語話者データを使用してトレーニングされていることは注目に値します。ヴァリー。
つまり、VALL-E は TTS 用のまったく新しい言語モデル手法であり、中間表現としてオーディオ エンコードおよびデコード コードを使用し、大量のさまざまなデータを使用してモデルに強力なコンテキスト学習機能を与えます。
推論: プロンプトによるインコンテキスト学習
コンテキスト学習 (インコンテキスト学習) は、追加のパラメーター更新を必要とせずに、目に見えない入力ラベルを予測できる、テキストベースの言語モデルの驚くべき機能です。 。
TTS の場合、モデルが微調整することなく、見えない話者向けに高品質の音声を合成できる場合、そのモデルには文脈学習機能があるとみなされます。
しかし、既存の TTS システムには強力なコンテキスト内学習機能がありません。これは、追加の微調整が必要であるか、見えない話者に対して大幅な性能低下が発生するためです。
言語モデルの場合、ゼロショット状況でコンテキスト学習を達成するにはプロンプトが必要です。
研究者によって設計されたプロンプトと推論は次のとおりです。
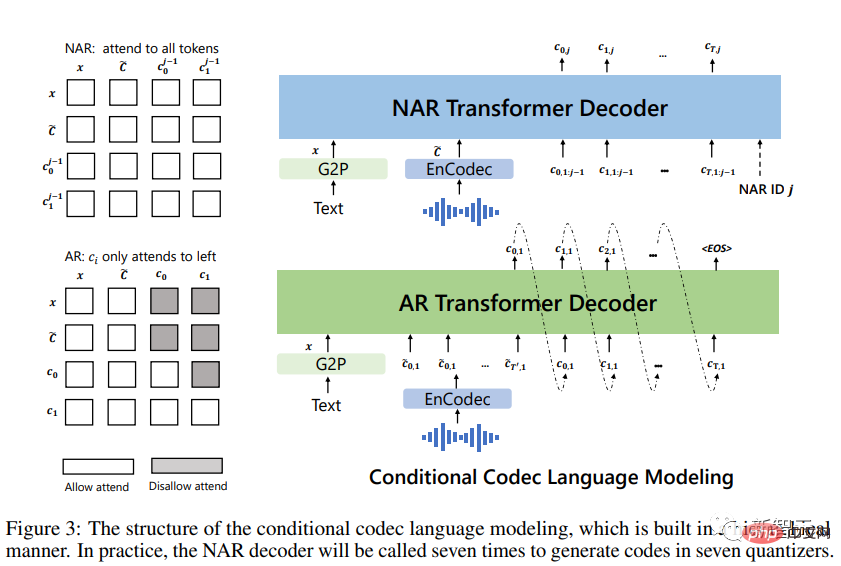
最初にテキストを音素シーケンスに変換し、登録された録音を音響マトリックスにエンコードして、音素プロンプトと音響を形成します。プロンプト。どちらも AR モデルと NAR モデルで使用されます。
AR モデルの場合は、ビーム サーチによって LM が無限ループに入る可能性があるため、ヒントを条件としてサンプリング ベースのデコードを使用します。また、サンプリング ベースの方法により出力の多様性が大幅に向上します。
NAR モデルの場合、貪欲デコードを使用して、最も高い確率でトークンを選択します。
最後に、ニューラル コーデックを使用して、8 つのエンコード シーケンスに基づいて条件付けされた波形を生成します。
音響キューは、合成される音声と必ずしも意味的な関係を持たない可能性があるため、次の 2 つのケースに分類できます。
VALL-E: 主な目標は、目に見えない話者向けです。与えられたコンテンツ。
このモデルの入力は、テキスト文、登録された音声の一部、およびそれに対応する文字起こしです。登録された音声の転写された音素を音素キューとして指定された文の音素シーケンスに追加し、登録された音声の第 1 レベルの音響トークンを音響プレフィックスとして使用します。 VALL-E は、音素キューと音響プレフィックスを使用して、特定のテキストの音響トークンを生成し、話者の音声を複製します。
VALL-E-continual: トランスクリプト全体と発話の最初の 3 秒をそれぞれ音素キューと音響キューとして使用し、モデルに連続コンテンツを生成するように要求します。
推論プロセスは、登録された音声と生成された音声が意味的に連続していることを除いて、VALL-E の設定と同じです。
実験セクション
研究者らは、LibriSpeech および VCTK データセットで VALL-E を評価しましたが、テストされたすべての話者がトレーニング コーパスに含まれていませんでした。
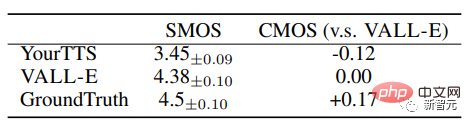
VALL-E は、音声の自然さと話者の類似性の点で最先端のゼロショット TTS システムを大幅に上回り、比較平均オプション スコア (CMOS) が 0.12、LibriSpeech オプションの類似性平均が 0.93 でした。スコア (SMOS)。
VALL-E は、VCTK 上で 0.11 SMOS および 0.23 CMOS のパフォーマンス向上によりベースライン システムを上回り、グラウンド トゥルースに対して 0.04CMOS スコアに達しました。これは、VCTK 上で、目に見えない話者からの合成音声は人間の録音と同じくらい自然です。
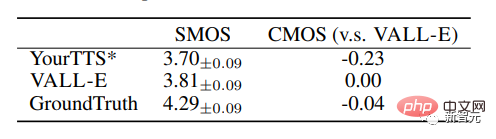
さらに、定性分析では、VALL-E が 2 つの同一のテキストとターゲット話者を使用して異なる出力を合成できることが示されており、これは音声認識タスクの疑似データに有益である可能性があります。作成する。
実験では、VALL-E が音環境(残響など)と音によって引き起こされる感情(怒りなど)を維持できることもわかりました。
セキュリティ上の危険
強力なテクノロジーが悪用されると、社会に害を及ぼす可能性があります。たとえば、電話詐欺の基準値が再び引き下げられました。
VALL-E にはいたずらや欺瞞の可能性があるため、Microsoft は VALL-E のコードやインターフェイスをテスト用に公開していません。
一部のネチズンは次のように共有しています。システム管理者に電話する場合は、「こんにちは」という言葉をいくつか録音し、その言葉に基づいて音声を再合成します。「こんにちは、私はシステム管理者です。」音声は一意の識別子であり、安全に検証できます。」私はいつもこれは不可能だと思っていました。これほど少ないデータではこのタスクを達成することはできませんでした。今となっては、私は間違っているかもしれません...
プロジェクトの最終倫理声明で、研究者らは「この記事の実験は、対象話者としてのモデルユーザーに基づいており、以下の条件で実行されて得られたものである」と述べています。 」
 #著者は論文の中で、VALL-E は話者の身元を維持した音声を合成できるため、なりすましの音声認識や音声認識など、モデルの悪用の潜在的なリスクを引き起こす可能性があるとも述べています。特定の話者の真似をすること。
#著者は論文の中で、VALL-E は話者の身元を維持した音声を合成できるため、なりすましの音声認識や音声認識など、モデルの悪用の潜在的なリスクを引き起こす可能性があるとも述べています。特定の話者の真似をすること。
このリスクを軽減するために、オーディオ クリップが VALL-E によって合成されたかどうかを区別する検出モデルを構築できます。これらのモデルをさらに開発するにつれて、Microsoft AI の原則も実践していきます。
参考資料:
https://www.php.cn/link/402cac3dacf2ef35050ca72743ae6ca7
以上があなたの声を盗むのにかかる時間はわずか 3 秒です。 Microsoft、音声合成モデルVALL-Eをリリース:ネットユーザーは「電話詐欺」の敷居がまた下がったと叫ぶの詳細内容です。詳細については、PHP 中国語 Web サイトの他の関連記事を参照してください。

ホットAIツール

Undresser.AI Undress
リアルなヌード写真を作成する AI 搭載アプリ

AI Clothes Remover
写真から衣服を削除するオンライン AI ツール。

Undress AI Tool
脱衣画像を無料で

Clothoff.io
AI衣類リムーバー

Video Face Swap
完全無料の AI 顔交換ツールを使用して、あらゆるビデオの顔を簡単に交換できます。

人気の記事
ホットツール

メモ帳++7.3.1
使いやすく無料のコードエディター

SublimeText3 中国語版
中国語版、とても使いやすい

ゼンドスタジオ 13.0.1
強力な PHP 統合開発環境

ドリームウィーバー CS6
ビジュアル Web 開発ツール

SublimeText3 Mac版
神レベルのコード編集ソフト(SublimeText3)
ホットトピック
 7773
7773
 15
1644
14
1399
52
1296
25
1234
29
15
1644
14
1399
52
1296
25
1234
29

 Microsoft bing国際版入口アドレス(bing検索エンジン入口)
Mar 14, 2024 pm 01:37 PM
Microsoft bing国際版入口アドレス(bing検索エンジン入口)
Mar 14, 2024 pm 01:37 PM
Bing は Microsoft が提供するオンライン検索エンジンで、検索機能が非常に強力で、国内版と海外版の 2 つの入り口があります。これら 2 つのバージョンへの入り口はどこですか?国際版にアクセスするにはどうすればよいですか?以下で詳細を見てみましょう。 Bing 中国語版 Web サイトの入り口: https://cn.bing.com/ Bing 国際版 Web サイトの入り口: https://global.bing.com/ Bing 国際版にアクセスするにはどうすればよいですか? 1. まず URL を入力して Bing を開きます: https://www.bing.com/ 2. 国内バージョンと国際バージョンのオプションがあることがわかりますので、国際バージョンを選択してキーワードを入力するだけです。
 WeChat Voice で音が聞こえないのはなぜですか? WeChat Voice で音が聞こえない場合はどうすればよいですか?
Mar 13, 2024 pm 02:31 PM
WeChat Voice で音が聞こえないのはなぜですか? WeChat Voice で音が聞こえない場合はどうすればよいですか?
Mar 13, 2024 pm 02:31 PM
WeChat Voice で音が聞こえないのはなぜですか? WeChat は日常生活に欠かせないコミュニケーションツールですが、WeChat の音声が聞こえないなど、使用中に問題が発生したことがありますか?じゃあ何をすればいいの?このサイトでは、WeChat の音声が聞こえない場合の対処法をユーザーに詳しく紹介します。 WeChat の音声が聞こえない場合はどうすればよいですか? 1. 携帯電話システムで設定されている音が比較的小さいか、ミュート状態になっている場合、音量を上げるかマナー モードをオフにすることができます。 2. WeChat スピーカー機能がオンになっていない可能性もあります。「設定」を開き、「チャット」オプションを選択します。 3.「チャット」オプションをクリックした後
 Microsoft Edgeアップグレード:自動パスワード保存機能が禁止? !ユーザーはショックを受けました!
Apr 19, 2024 am 08:13 AM
Microsoft Edgeアップグレード:自動パスワード保存機能が禁止? !ユーザーはショックを受けました!
Apr 19, 2024 am 08:13 AM
4 月 18 日のニュース: 最近、Canary チャネルを使用している Microsoft Edge ブラウザーの一部のユーザーが、最新バージョンにアップグレードした後、パスワードを自動的に保存するオプションが無効になっていることに気づいたと報告しました。調査の結果、これは機能のキャンセルではなく、ブラウザのアップグレード後の軽微な調整であることが判明しました。 Edge ブラウザを使用して Web サイトにアクセスする前に、Web サイトのログイン パスワードを保存するかどうかを尋ねるウィンドウがブラウザにポップアップ表示されるとユーザーが報告しました。保存を選択すると、Edge は次回ログインするときに保存されたアカウント番号とパスワードを自動的に入力するため、ユーザーは非常に便利になります。しかし、最新のアップデートはデフォルト設定を変更する微調整に似ています。ユーザーはパスワードを保存することを選択し、設定で保存されたアカウントとパスワードの自動入力を手動でオンにする必要があります。
 Microsoft Win11 の 7z および TAR ファイルを圧縮する機能は、24H2 バージョンから 23H2/22H2 バージョンにダウングレードされました
Apr 28, 2024 am 09:19 AM
Microsoft Win11 の 7z および TAR ファイルを圧縮する機能は、24H2 バージョンから 23H2/22H2 バージョンにダウングレードされました
Apr 28, 2024 am 09:19 AM
4 月 27 日のこのサイトのニュースによると、Microsoft は今月初めに Windows 11 Build 26100 プレビュー バージョン アップデートを Canary チャネルと Dev チャネルにリリースしました。これは Windows 1124H2 アップデートの RTM バージョンの候補になると予想されています。新バージョンの主な変更点は、ファイルエクスプローラー、Copilotの統合、PNGファイルメタデータの編集、TARおよび7z圧縮ファイルの作成など。 @PhantomOfEarth は、Microsoft が TAR および 7z 圧縮ファイルの作成など、24H2 バージョン (ゲルマニウム) の一部の機能を 23H2/22H2 (ニッケル) バージョンに継承していることを発見しました。図に示すように、Windows 11 は TAR のネイティブ作成をサポートします。
 Microsoft、Win11 8月累積アップデートをリリース:セキュリティの向上、ロック画面の最適化など。
Aug 14, 2024 am 10:39 AM
Microsoft、Win11 8月累積アップデートをリリース:セキュリティの向上、ロック画面の最適化など。
Aug 14, 2024 am 10:39 AM
8 月 14 日のこのサイトのニュースによると、今日の 8 月のパッチ火曜日イベント日に、Microsoft は 22H2 および 23H2 用の KB5041585 更新プログラム、および 21H2 用の KB5041592 更新プログラムを含む、Windows 11 システム用の累積的な更新プログラムをリリースしました。 8 月の累積更新プログラムで上記の機器がインストールされた後、このサイトに添付されるバージョン番号の変更は次のとおりです。 21H2 機器のインストール後、機器のインストール後、バージョン番号は Build22000.314722H2 に増加しました。バージョン番号は Build22621.403723H2 に増加しました。 装置のインストール後、バージョン番号は Build22631.4037 に増加しました。 Windows 1121H2 の更新プログラムの主な内容は次のとおりです。 改善: 改善されました。
 Microsoft Edge ブラウザーのアップデート: ユーザー エクスペリエンスを向上させるために「画像のズームイン」機能を追加しました
Mar 21, 2024 pm 01:40 PM
Microsoft Edge ブラウザーのアップデート: ユーザー エクスペリエンスを向上させるために「画像のズームイン」機能を追加しました
Mar 21, 2024 pm 01:40 PM
3月21日のニュースによると、Microsoftは最近ブラウザ「Microsoft Edge」をアップデートし、実用的な「画像拡大」機能を追加した。 Edge ブラウザを使用している場合、ユーザーは画像を右クリックするだけで、ポップアップ メニューでこの新機能を簡単に見つけることができます。さらに便利なのは、ユーザーが画像の上にカーソルを置き、Ctrl キーをダブルクリックして、画像をズームインする機能をすぐに呼び出すこともできることです。編集者の理解によれば、新しくリリースされた Microsoft Edge ブラウザーは、Canary チャネルで新機能についてテストされています。安定版ブラウザでは、実用的な「画像拡大」機能も正式に開始し、より便利な画像閲覧体験をユーザーに提供しています。海外の科学技術メディアも注目
 Microsoft の全画面ポップアップは、Windows 10 ユーザーに急いで Windows 11 にアップグレードするよう促します
Jun 06, 2024 am 11:35 AM
Microsoft の全画面ポップアップは、Windows 10 ユーザーに急いで Windows 11 にアップグレードするよう促します
Jun 06, 2024 am 11:35 AM
6 月 3 日のニュースによると、Microsoft はすべての Windows 10 ユーザーに全画面通知を積極的に送信し、Windows 11 オペレーティング システムへのアップグレードを奨励しています。この移行には、ハードウェア構成が新しいシステムをサポートしていないデバイスが含まれます。 2015 年以来、Windows 10 は市場シェアの 70% 近くを占め、Windows オペレーティング システムとしての優位性を確固たるものにしました。しかし、そのシェアは82%を大きく上回り、2021年に発売されるWindows 11のシェアを大きく上回っている。 Windows 11 は発売から 3 年近く経ちますが、市場への浸透はまだ遅いです。 Microsoft は、Windows 10 の技術サポートを 2025 年 10 月 14 日以降に終了すると発表しました。
 Microsoft、Outlook for Windowsの新バージョンを発売:カレンダー機能を包括的にアップグレード
Apr 27, 2024 pm 03:44 PM
Microsoft、Outlook for Windowsの新バージョンを発売:カレンダー機能を包括的にアップグレード
Apr 27, 2024 pm 03:44 PM
4 月 27 日のニュースで、Microsoft は Windows クライアント用 Outlook の新しいバージョンのテストを間もなくリリースすると発表しました。今回のアップデートでは主にカレンダー機能の最適化を行い、ユーザーの作業効率の向上と日々のワークフローのさらなる簡素化を目指しています。 Outlook for Windows クライアントの新バージョンの改良点は、より強力な予定表管理機能にあります。ユーザーは個人の勤務時間や位置情報をより簡単に共有できるようになり、会議の計画がより効率的にできるようになりました。さらに、Outlook にはユーザーフレンドリーな設定も追加されており、ユーザーは会議を自動的に早く終了したり、遅く開始したりするように設定できるため、会議室を変更したり、休憩したり、コーヒーを楽しんだりする際に、より柔軟に対応できるようになりました。 。によると
