

ウィスコンシン大学マディソン校などが共同で投稿しました!最新マルチモーダル大型モデルLLaVAリリース、そのレベルはGPT-4に迫る

ビジュアル コマンドの微調整が一般的です。
この文書は Visual structural Tuning と呼ばれ、ウィスコンシン大学マディソン校、Microsoft Research、コロンビア大学が共同で作成したものです。
著者には、Haotian Liu、Chunyuan Li、Qingyang Wu、Yong Jae Lee が含まれます。

同時に、研究者らはコード、モデル、データセットを GitHub でオープンソース化しました。この論文はArxivにも掲載されています。
説明
では、LLaVA の機能とは一体何なのでしょうか?論文の内容を詳しく見てみると、この論文に詳しくない人にとっては少し奇妙に感じるかもしれません。
まずは LLaVA 自体の内容を見てみましょう。
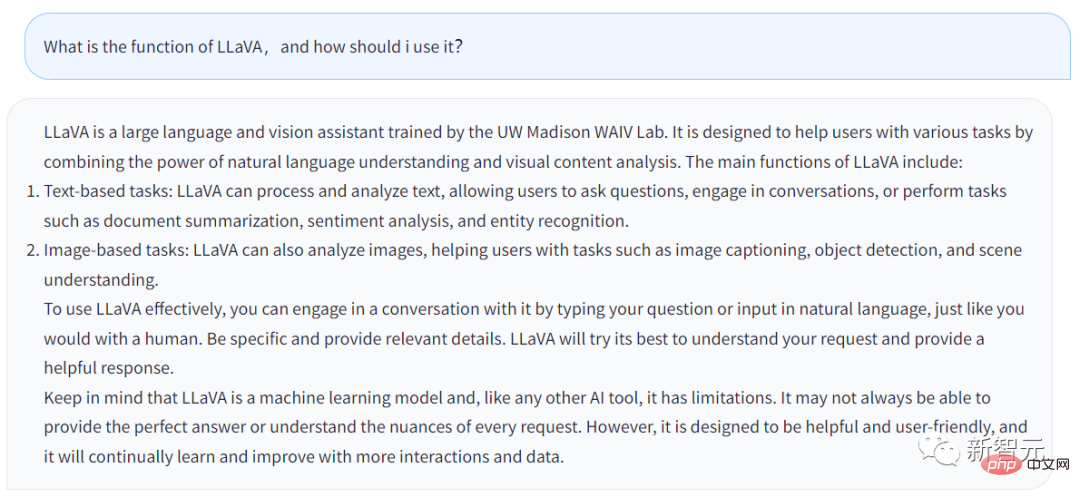
上記の回答は LLaVA のチャットボットから生成されたものです。私が入力した質問は、LLaVA の機能とは何か、そして何をすべきかということです。ユーザーはそれを利用しますか?
答えは次のとおりです。
LLaVA は、UW マディソン WAIV 研究室で訓練された大規模な言語および視覚アシスタントです。 LLaVA は、自然言語理解機能とビジュアル コンテンツ分析機能を活用して、ユーザーがさまざまなタスクを処理できるように設計されています。
LLaVA の主な機能は次のとおりです:
· テキストベースのタスク: LLaVA はテキストを処理および分析できるため、ユーザーは次のことを行うことができます。 LLaVA は、質問をしたり、ユーザーとチャットしたり、文書の要約の調整、センチメント分析、エンティティ認識など、ユーザーが入力したタスクを完了したりできます。
· 画像ベースのタスク: LLaVA は、画像の分析、画像の説明、オブジェクト認識の実行、シーンの分析と理解が可能です。
ユーザーが LLaVA をより適切に適用したい場合は、人間と話すのと同じように、LLaVA に直接話しかけることができます。できるだけ詳細を提供してください。LLaVA はより完全な回答を生成します。
同時に、結局のところ、LLaVA は機械学習モデルであり AI ツールであることを覚えておく必要があります。ツールである限り、限界があります。 LLaVA は、ユーザーが入力した質問に毎回完全に回答するとは限りません。
もちろん、LLaVA も常に学習と改善を続けており、その機能はますます強力になります。
LLaVA の回答から、一般的に、チャットボットの機能は GPT とそれほど変わらないことがわかります。ただし、LLaVA は画像に関連するいくつかのタスクを処理できます。
展示カラー研究者らは、Arxiv 論文で LLaVA の技術的詳細を詳しく説明しています。
機械生成の命令を使用してデータに従い、大規模言語モデル (LLM) の命令を微調整すると、新しいタスクのゼロポイント機能が向上することを知っておくことが重要です。このアイデアは、マルチモーダルな分野では検討されていません。
論文では、研究者らは言語専用 GPT-4 を使用して、マルチモーダル言語画像の命令に従うデータを生成することを初めて試みました。
研究者らは、この生成されたデータに命令を条件付けることで、エンドツーエンドでトレーニングされた大規模なマルチモーダル ステートフル モデルである大規模な言語および視覚アシスタントである LLaVA を導入しました。 、一般的な視覚と言語の理解のためにビジュアル エンコーダーと LLM を接続します。
初期の実験では、LLaVA が優れたマルチモーダル チャット機能を実証し、時には目に見えない画像/コマンドや合成マルチモーダル チャットでマルチモーダル GPT-4 パフォーマンスを出力することが示されています。データセットに従って命令を実行したところ、85.1% の相対スコアを達成しました。
Science Magazine 用に微調整すると、LLaVA と GPT-4 の相乗効果により、92.53% という新たな最先端の精度が達成されました。
研究者らは、GPT-4 によって生成された視覚的なコマンド調整のためのデータ、モデル、コード ベースを公開しました。
マルチモーダル モデル
まず定義を明確にします。
大規模マルチモーダル モデルとは、テキストや画像などの複数の入力タイプを処理および分析できる機械学習テクノロジに基づくモデルを指します。
これらのモデルは、より広範囲のタスクを処理できるように設計されており、さまざまな形式のデータを理解できます。これらのモデルは、テキストと画像を入力として受け取ることで、説明を理解し、編集して、より正確で関連性の高い回答を生成する能力を向上させます。
人間は、視覚や言語を含む複数のチャネルを通じて世界と対話します。それぞれのチャネルには、世界の特定の概念を表現し伝達する上で独自の利点があり、それによって世界をより深く理解することが容易になるからです。 。
人工知能の中心的な目標の 1 つは、マルチモーダルな視覚および言語の指示に効果的に従い、人間の意図と一致し、さまざまな現実生活を完了できる万能アシスタントを開発することです。タスク、世界ミッション。
その結果、開発者コミュニティは、分類、検出、セグメンテーション、説明などのオープンワールドの視覚的理解を強力な機能を備えた言語強化された基本ビジョン モデルの開発に新たな関心を抱くようになりました。 、ビジュアルの生成と編集。
これらの機能では、各タスクは単一の大きなビジュアル モデルによって独立して解決され、タスクの指示はモデル設計で暗黙的に考慮されます。
さらに、言語は画像コンテンツを説明するためにのみ使用されます。これにより、言語は視覚信号を人間のコミュニケーションの共通チャネルである言語意味論にマッピングする上で重要な役割を果たすことができます。ただし、その結果、対話性やユーザーの指示への適応性が制限された固定インターフェイスを持つモデルが多くなります。
そして、大規模言語モデル (LLM) は、言語がより広範な役割を果たすことができることを示しています。一般的なアシスタントのための共通インターフェイス、さまざまなタスクの指示を言語で明示的に表現し、目的を達成するためのガイドとして機能します。最終的にトレーニングされたニューラル アシスタントは、問題を解決するために対象のタスクに切り替えます。
たとえば、ChatGPT と GPT-4 の最近の成功は、この LLM が人間の指示に従う能力を実証し、オープンソース LLM の開発に対する大きな関心を刺激しました。
LLaMA は、GPT-3 と同等のパフォーマンスを持つオープンソース LLM です。現在進行中の作業では、サンプルに続くさまざまな機械生成の高品質命令を活用して LLM のアライメント機能を向上させ、独自の LLM と比較して優れたパフォーマンスを報告しています。重要なのは、この作業はテキストのみであるということです。
この論文では、研究者らはビジュアル コマンド チューニングを提案していますが、これはコマンド チューニングをマルチモーダル空間に拡張する初めての試みであり、ユニバーサルなビジュアル アシスタントを構築する道を切り開くものです。具体的には、この論文の主な内容は次のとおりです。
データに続くマルチモーダル命令。主要な課題は、データを追跡するための視覚的な言語の指示が不足していることです。データ改革の観点と、ChatGPT/GPT-4 を使用して画像とテキストのペアを適切なコマンドに従う形式に変換するパイプラインを紹介します。
大規模なマルチモーダル モデル。研究者らは、CLIPのオープンセット視覚エンコーダと言語デコーダLaMAを接続することで大規模マルチモーダルモデル(LMM)を開発し、生成された指導用視覚言語データに基づいてエンドツーエンドで微調整した。実証研究では、生成されたデータを使用した LMM 命令チューニングの有効性が検証され、一般的な命令に従うビジュアル エージェントを構築するための実践的な提案が提供されます。研究チームは GPT 4 を使用して、Science QA マルチモーダル推論データセットで最先端のパフォーマンスを達成しました。 ############オープンソース。研究チームは、生成されたマルチモーダル命令データ、データ生成とモデルトレーニング用のコードライブラリ、モデルチェックポイント、ビジュアルチャットデモを公開しました。
結果の表示

LLaVA はあらゆる種類の問題を処理でき、生成された回答は包括的かつ包括的であることがわかります。論理的。
LLaVA は、GPT-4 のレベルに近いマルチモーダル機能を示しており、ビジュアル チャットに関して GPT-4 相対スコアは 85% です。
推論に関する質問と回答の観点からは、LLaVA は新しい SoTA-92.53% にも到達し、マルチモーダルな思考チェーンを打ち破りました。
以上がウィスコンシン大学マディソン校などが共同で投稿しました!最新マルチモーダル大型モデルLLaVAリリース、そのレベルはGPT-4に迫るの詳細内容です。詳細については、PHP 中国語 Web サイトの他の関連記事を参照してください。

ホットAIツール

Undresser.AI Undress
リアルなヌード写真を作成する AI 搭載アプリ

AI Clothes Remover
写真から衣服を削除するオンライン AI ツール。

Undress AI Tool
脱衣画像を無料で

Clothoff.io
AI衣類リムーバー

Video Face Swap
完全無料の AI 顔交換ツールを使用して、あらゆるビデオの顔を簡単に交換できます。

人気の記事
ホットツール

メモ帳++7.3.1
使いやすく無料のコードエディター

SublimeText3 中国語版
中国語版、とても使いやすい

ゼンドスタジオ 13.0.1
強力な PHP 統合開発環境

ドリームウィーバー CS6
ビジュアル Web 開発ツール

SublimeText3 Mac版
神レベルのコード編集ソフト(SublimeText3)
ホットトピック
 7681
7681
 15
1639
14
1393
52
1286
25
1229
29
15
1639
14
1393
52
1286
25
1229
29

 世界で最も強力なオープンソース MoE モデルが登場。GPT-4 に匹敵する中国語機能を備え、価格は GPT-4-Turbo のわずか 1% 近くです
May 07, 2024 pm 04:13 PM
世界で最も強力なオープンソース MoE モデルが登場。GPT-4 に匹敵する中国語機能を備え、価格は GPT-4-Turbo のわずか 1% 近くです
May 07, 2024 pm 04:13 PM
従来のコンピューティングを超える能力を備えているだけでなく、より低コストでより効率的なパフォーマンスを実現する人工知能モデルを想像してみてください。これは SF ではありません。世界で最も強力なオープンソース MoE モデルである DeepSeek-V2[1] が登場しました。 DeepSeek-V2 は、経済的なトレーニングと効率的な推論の特徴を備えた強力な専門家混合 (MoE) 言語モデルです。これは 236B のパラメータで構成されており、そのうち 21B は各マーカーをアクティブにするために使用されます。 DeepSeek67B と比較して、DeepSeek-V2 はパフォーマンスが優れていると同時に、トレーニング コストを 42.5% 節約し、KV キャッシュを 93.3% 削減し、最大生成スループットを 5.76 倍に高めます。 DeepSeek は一般的な人工知能を研究する会社です
 MLP に代わる KAN は、オープンソース プロジェクトによって畳み込みまで拡張されました
Jun 01, 2024 pm 10:03 PM
MLP に代わる KAN は、オープンソース プロジェクトによって畳み込みまで拡張されました
Jun 01, 2024 pm 10:03 PM
今月初め、MIT やその他の機関の研究者らは、MLP に代わる非常に有望な代替案である KAN を提案しました。 KAN は、精度と解釈可能性の点で MLP よりも優れています。また、非常に少数のパラメーターを使用して、多数のパラメーターを使用して実行する MLP よりも優れたパフォーマンスを発揮できます。たとえば、著者らは、KAN を使用して、より小規模なネットワークと高度な自動化で DeepMind の結果を再現したと述べています。具体的には、DeepMind の MLP には約 300,000 個のパラメーターがありますが、KAN には約 200 個のパラメーターしかありません。 KAN は、MLP が普遍近似定理に基づいているのに対し、KAN はコルモゴロフ-アーノルド表現定理に基づいているのと同様に、強力な数学的基礎を持っています。以下の図に示すように、KAN は
 テスラのロボットは工場で働く、マスク氏:手の自由度は今年22に達する!
May 06, 2024 pm 04:13 PM
テスラのロボットは工場で働く、マスク氏:手の自由度は今年22に達する!
May 06, 2024 pm 04:13 PM
テスラのロボット「オプティマス」の最新映像が公開され、すでに工場内で稼働可能となっている。通常の速度では、バッテリー(テスラの4680バッテリー)を次のように分類します:公式は、20倍の速度でどのように見えるかも公開しました - 小さな「ワークステーション」上で、ピッキング、ピッキング、ピッキング:今回は、それがリリースされたハイライトの1つビデオの内容は、オプティマスが工場内でこの作業を完全に自律的に行い、プロセス全体を通じて人間の介入なしに完了するというものです。そして、オプティマスの観点から見ると、自動エラー修正に重点を置いて、曲がったバッテリーを拾い上げたり配置したりすることもできます。オプティマスのハンドについては、NVIDIA の科学者ジム ファン氏が高く評価しました。オプティマスのハンドは、世界の 5 本指ロボットの 1 つです。最も器用。その手は触覚だけではありません
 Microsoft、Win11 8月累積アップデートをリリース:セキュリティの向上、ロック画面の最適化など。
Aug 14, 2024 am 10:39 AM
Microsoft、Win11 8月累積アップデートをリリース:セキュリティの向上、ロック画面の最適化など。
Aug 14, 2024 am 10:39 AM
8 月 14 日のこのサイトのニュースによると、今日の 8 月のパッチ火曜日イベント日に、Microsoft は 22H2 および 23H2 用の KB5041585 更新プログラム、および 21H2 用の KB5041592 更新プログラムを含む、Windows 11 システム用の累積的な更新プログラムをリリースしました。 8 月の累積更新プログラムで上記の機器がインストールされた後、このサイトに添付されるバージョン番号の変更は次のとおりです。 21H2 機器のインストール後、機器のインストール後、バージョン番号は Build22000.314722H2 に増加しました。バージョン番号は Build22621.403723H2 に増加しました。 装置のインストール後、バージョン番号は Build22631.4037 に増加しました。 Windows 1121H2 の更新プログラムの主な内容は次のとおりです。 改善: 改善されました。
 Microsoft の全画面ポップアップは、Windows 10 ユーザーに急いで Windows 11 にアップグレードするよう促します
Jun 06, 2024 am 11:35 AM
Microsoft の全画面ポップアップは、Windows 10 ユーザーに急いで Windows 11 にアップグレードするよう促します
Jun 06, 2024 am 11:35 AM
6 月 3 日のニュースによると、Microsoft はすべての Windows 10 ユーザーに全画面通知を積極的に送信し、Windows 11 オペレーティング システムへのアップグレードを奨励しています。この移行には、ハードウェア構成が新しいシステムをサポートしていないデバイスが含まれます。 2015 年以来、Windows 10 は市場シェアの 70% 近くを占め、Windows オペレーティング システムとしての優位性を確固たるものにしました。しかし、そのシェアは82%を大きく上回り、2021年に発売されるWindows 11のシェアを大きく上回っている。 Windows 11 は発売から 3 年近く経ちますが、市場への浸透はまだ遅いです。 Microsoft は、Windows 10 の技術サポートを 2025 年 10 月 14 日以降に終了すると発表しました。
 総合的にDPOを超える:Chen Danqi氏のチームはシンプルなプリファレンス最適化SimPOを提案し、最強の8Bオープンソースモデルも洗練させた
Jun 01, 2024 pm 04:41 PM
総合的にDPOを超える:Chen Danqi氏のチームはシンプルなプリファレンス最適化SimPOを提案し、最強の8Bオープンソースモデルも洗練させた
Jun 01, 2024 pm 04:41 PM
大規模言語モデル (LLM) を人間の価値観や意図に合わせるには、人間のフィードバックを学習して、それが有用で、正直で、無害であることを確認することが重要です。 LLM を調整するという点では、ヒューマン フィードバックに基づく強化学習 (RLHF) が効果的な方法です。 RLHF 法の結果は優れていますが、最適化にはいくつかの課題があります。これには、報酬モデルをトレーニングし、その報酬を最大化するためにポリシー モデルを最適化することが含まれます。最近、一部の研究者はより単純なオフライン アルゴリズムを研究しており、その 1 つが直接優先最適化 (DPO) です。 DPO は、RLHF の報酬関数をパラメータ化することで、選好データに基づいてポリシー モデルを直接学習するため、明示的な報酬モデルの必要性がなくなります。この方法は簡単で安定しています
 OpenAI データは必要ありません。大規模なコード モデルのリストに加わりましょう。 UIUC が StarCoder-15B-Instruct をリリース
Jun 13, 2024 pm 01:59 PM
OpenAI データは必要ありません。大規模なコード モデルのリストに加わりましょう。 UIUC が StarCoder-15B-Instruct をリリース
Jun 13, 2024 pm 01:59 PM
ソフトウェア テクノロジの最前線に立つ UIUC Zhang Lingming のグループは、BigCode 組織の研究者とともに、最近 StarCoder2-15B-Instruct 大規模コード モデルを発表しました。この革新的な成果により、コード生成タスクにおいて大きな進歩が達成され、CodeLlama-70B-Instruct を上回り、コード生成パフォーマンス リストのトップに到達しました。 StarCoder2-15B-Instruct のユニークな特徴は、その純粋な自己調整戦略であり、トレーニング プロセス全体がオープンで透過的で、完全に自律的で制御可能です。このモデルは、高価な手動アノテーションに頼ることなく、StarCoder-15B 基本モデルの微調整に応じて、StarCoder2-15B を介して数千の命令を生成します。
 LLMはすべて完了しました! OmniDrive: 3D 認識と推論プランニングの統合 (NVIDIA の最新)
May 09, 2024 pm 04:55 PM
LLMはすべて完了しました! OmniDrive: 3D 認識と推論プランニングの統合 (NVIDIA の最新)
May 09, 2024 pm 04:55 PM
上記と著者の個人的な理解: この論文は、自動運転アプリケーションにおける現在のマルチモーダル大規模言語モデル (MLLM) の主要な課題、つまり MLLM を 2D 理解から 3D 空間に拡張する問題の解決に特化しています。自動運転車 (AV) は 3D 環境について正確な決定を下す必要があるため、この拡張は特に重要です。 3D 空間の理解は、情報に基づいて意思決定を行い、将来の状態を予測し、環境と安全に対話する車両の能力に直接影響を与えるため、AV にとって重要です。現在のマルチモーダル大規模言語モデル (LLaVA-1.5 など) は、ビジュアル エンコーダーの解像度制限や LLM シーケンス長の制限により、低解像度の画像入力しか処理できないことがよくあります。ただし、自動運転アプリケーションには次の要件が必要です。
