

GPT-3 から始まり、Transformer の巨大な家系図を書き続ける

最近、言語モデルの大規模な兵器戦争が友達の輪のほとんどのスペースを占めており、これらのモデルに何ができるか、またその商業的価値は何かについて議論する記事がたくさんあります。しかし、長年人工知能の分野に没頭してきた若い研究者として、私はこの軍拡競争の背後にある技術原理と、人類に利益をもたらすためにこれらのモデルがどのように設計されているかのほうに関心があります。これらのモデルがどのように収益を上げ、より多くの人々に利益をもたらすように設計できるかということよりも、私が探求したいのは、この現象の背後にある理由と、AIが人間に取って代わる前に「AIに取って代わられる」ために私たち研究者が何ができるかということです。それなら名誉ある引退をしてください」と言って、それについて何かをしてください。
3 年前、GPT-3 がテクノロジーの世界で大騒動を引き起こしたとき、私は GPT の背後にある巨大なグループを歴史的な方法で分析しようとしました。 GPT の背後にある技術的背景を時系列に整理し (図 1)、GPT の成功の背後にある技術原則を説明しようとしました。今年、GPT-3 の次男である ChatGPT はより賢くなったようで、チャットを通じて人々とコミュニケーションをとることができ、より多くの人が自然言語処理の分野における最新の進歩を知ることになります。この歴史的な瞬間に、AI の歴史家として、私たちは近年何が起こったのかを少し振り返ってみる必要があるかもしれません。最初の記事は GPT-3 を出発点として使用しているため、このシリーズは実際にはポスト GPT 時代の記録 (ポスト GPT 本) です。GPT ファミリーの変遷を探索しているうちに、ほとんどの話が関連していることに気づきました。したがって、この記事の名前はトランスフォーマーファミリーです。
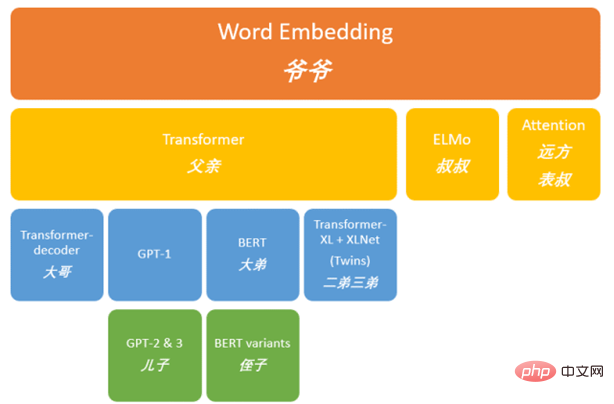
#図 1. GPT の古い系図
前のレビューTransformer ファミリの正式な紹介を始める前に、図 1 に従って過去に何が起こったかを振り返ってみましょう。 Word Embedding [1,2] から始まり、ベクトル (数字の文字列) には、奇妙だが効果的な方法でテキストの意味論が含まれています。図 2 は、この表現を図示しています: 数字で表されます (王様 - 男性 女性 = 女王) )。これに基づいて、この巨大な NLP (自然言語処理) ファミリーが作成されました。
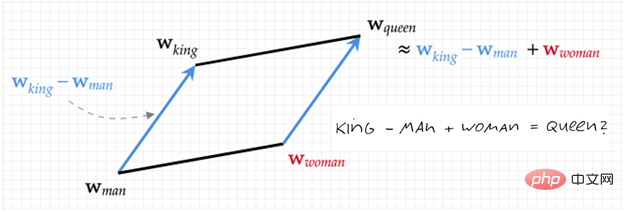
図 2. Word2Vec ダイアグラム (キング - 男性 女性 = クイーン)
この後、彼の長男 ELMo [3] は、次の 2 つの文のような文脈の重要性を発見しました:「ああ! あなたは私のお気に入りのピザを買ってくれました、私はあなたをとても愛しています」 !"
「ああ、本当に愛してます! 私の大好きなピザを地面にこすりつけましたか?」
「」の意味とても愛しています」は明らかに違います。 ELMo は、「モデルに単語の文字列を与え、モデルに次の単語と前の単語 (コンテキスト) を予測するよう依頼する」ことで、この問題を解決することに成功しました。
同時に、Word Embedding の遠い親戚が別の問題を発見しました - 人は文を理解するとき、いくつかの単語に注目します。1 つは非常に明白です。現象は次のとおりです。私たちは母国語を読んでいると、多くのタイプミスは簡単に無視されてしまいますが、これは文章を理解するときにそれに注意を払っていないためです。そこで彼は Attend メカニズム [4] を提案しましたが、この時点の Attend メカニズムは非常に初期のものであり、単体では動作できず、RNN や LSTM などのシーケンス モデルに付加することしかできませんでした。図 3 は、アテンション メカニズムと RNN の組み合わせプロセスを示しており、アテンション自体が単独で動作できない理由も説明しています。 NLP モデルの作業プロセスについて簡単に説明します。まず、「中国を愛しています」などの文があります。これは 5 つの文字であり、図 3 の x_1 ~ x_5 に変換できます。埋め込まれた単語 (数字の文字列) は図 3 の h_1 ~ h_5 であり、最終的には「私は中国が大好きです」(翻訳タスク) などの出力になります。これは図 3 の x_1' ~ x_3' です。図 3 。図 3 の残りの部分はアテンション メカニズムであり、図 3 の A です。これは、各 h に重みを割り当てることと同じなので、現在の単語を変換するときにどの単語がより重要であるかを知ることができます。具体的な詳細については、私が最初に書いた記事を参照してください (word2vec から始まり、GPT の巨大な家系図について話しています)。ここでのデジタル表現がタスク全体の基礎であることがわかります。これが、アテンション メカニズムが単独で機能できない理由です。
図 3. 初期の写真 - アテンションと RNN の強力な組み合わせ (出典: アテンション for RNN Seq2Seq モデル (1.25 倍の速度を推奨) - YouTube) 現時点では、王室の誇り高き直系親戚として、トランスフォーマーは他者への依存を認めていません。 「(アテンションメカニズムだけで十分です)」は、[5]で独自の独立した方法を提案し、「アテンションメカニズム」に単語を追加して「セルフアテンションメカニズム」に変えました。アテンションメカニズムのみが文字列番号を生成できます。私たちはこの変化を伝統的な漢方薬を使って説明します。最初の注意メカニズムは各物質の投与量であると言えますが、最終的に薬を取りに行くとき、薬はRNNやLSTMのようなメディシンピッカーの手に渡ります。薬局に基づいています (RNN、LSTM にはどのような薬がありますか)。 Transformer が行うことは、薬を収集する権利を取り戻し (値マトリクスを追加)、薬の処方方法を変更するだけです (キー マトリクスとクエリ マトリクスを追加)。このとき、Source は漢方薬店の保管箱とみなすことができ、保管箱内の医薬品はアドレス Key (薬剤名) と値 (薬剤) で構成され、現在 Key=Query のクエリがあります。 (処方箋)、目的は、対応する値(薬)を保管箱から取り出すことであり、これが注意値です。アドレス指定は、クエリと保管箱内の要素 Key のアドレスの類似性を比較することによって行われます。ソフト アドレス指定と呼ばれる理由は、保管箱から 1 つの薬剤を見つけるだけでなく、それも見つけることができることを意味します。各Keyから内容を取得します。アドレスから内容を取得します。QueryとKeyの類似度に基づいて、取得した内容の重要度(量)を判定します。その後、Valueに重み付けをして合計し、最終的なValue値(漢方薬のペア)、つまり注意値を取得することができます。したがって、多くの研究者は、アテンション メカニズムをソフト アドレス指定の特殊なケースとみなしていますが、これも非常に合理的です [6]。 それ以来、トランスフォーマーは正式に家族を繁栄に導き始めました。 実際、図 1 から、トランスフォーマーはおじいちゃんの家族の中で最も裕福な子孫であることがわかります。これはまた、「注目はこのトピックは実に合理的で、十分な根拠があります。彼が提案したセルフ・アテンション・メカニズムがどのようなものかについてお話しましたが、transformer の進化の過程については、すでに前の記事 (word2vec から始まる GPT の巨大な系図の話) で詳しく述べています。新入生向けに、変圧器のアーキテクチャが何であるかを見てみましょう。 簡単に言うと、トランスフォーマーを「アクター」と考えることができます。この「アクター」にとって、エンコーダーはアクターのメモリのようなもので、ラインを中間的なものに変換する責任があります。デコーダは俳優の演技のようなもので、頭の中での理解をスクリーン上の表示に変換する責任があります。ここで最も重要な自己注意メカニズムは俳優の集中として機能し、さまざまな位置で俳優の注意を自動的に調整することができ、それによってすべてのセリフをよりよく理解し、さまざまな状況でより自然かつスムーズに演技できるようになります。 より具体的に言うと、Transformer は大規模な「言語処理工場」と考えることができます。このファクトリーでは、各ワーカー (エンコーダー) は、入力シーケンス (単語など) 内の位置を処理し、それを処理して変換し、それを次のワーカー (エンコーダー) に渡す責任を負います。各ワーカーには、現在の場所からの入力を処理する方法と、以前の場所との関連付けを確立する方法を詳細に記した詳細なジョブ記述 (自己注意メカニズム) があります。この工場では、各作業者が同時に自分の作業を行うことができるため、工場全体で大量の入力データを効率的に処理できます。 トランスフォーマーが登場したとき、彼はその強力な強さと2人の野心的な息子(BERTとGPT)のおかげで、直接的には何の不安もなく王座を獲得しました。 BERT (Bidirectional Encoder Representations from Transformers) [1] は、Transformer のエンコーダ部分を継承し、競争の前半を勝ち取りましたが、その制限により汎用性の点で GPT に敗れました。正直な GPT (Generative Pre-trained Transformer) [7-10] は Decoder 部分を引き継ぎ、正直にゼロから学習し、人間のコミュニケーション方法を学習し、ついに後半で追い越しを達成しました。 もちろん、Transformer の野心はそれだけではありません。「必要なのは注意力だけ」という言葉は、NLP 分野だけを指しているわけではありません。 GPTとBERTの間の恨みや恨みを紹介する前に、まず彼らの父親が何をしたかを見てみましょう。 「父よ、時代は変わりました。私の努力のおかげで、私たちの家族は真の栄光を手に入れることができます。」 ——トランスフォーマー トランスフォーマーの仕組みを理解した上で、トランスフォーマーの強力な発展とともにトランスフォーマーファミリーがどこまで発展してきたかを見てみましょう(新系譜)。 。前述の「アクター」の例からわかるように、Transformer は人間のロジックと一致する学習方法を表すため、テキストだけでなく画像も処理できます。図 2 は、Transformer ファミリーの強力な家族背景をまとめたものです。 GPT と BERT が元の NLP (自然言語処理) 分野で継続的に画期的な進歩を遂げることを可能にすることに加えて、Transformer はコンピューター ビジョンの分野にも関与し始めています。その後輩たち(Googleが提唱するViTなど)もこの分野で輝いている。 2021 年、Vision Transformer は大爆発を引き起こし、Vision Transformer に基づく多数の作品がコンピュータ ビジョンのタスクを席巻しました。当然、トランスフォーマー一家は家族として常にコミュニケーションをとるようになり、文字と画像(AIペイント)を繋ぐCLIPが誕生した。 2022 年末時点では、ChatGPT が登場する前に安定拡散が非常に人気がありました。さらに、CLIP は、Transformer ファミリのマルチモダリティへの新しい扉も開きます。言葉や映像だけでなく、言葉でも音楽を奏でたり、絵を描いたりできるのでしょうか?マルチモーダルかつマルチタスクのトランスフォーマーも登場しました。つまり、どの分野も王子であり、NLP分野でゼロからスタートしたトランスフォーマーは、努力の末に王子たちを託せる「周の王」となった。 世は王子が多く存在する繁栄の時代。 ## 図 4. ますます繁栄する Transformer ファミリーの家系図 GPT について話す前に、トランスフォーマーによる最初の大胆な試みについて話さなければなりません。履歴書フィールド。まずは次男の人生を見てみましょう: 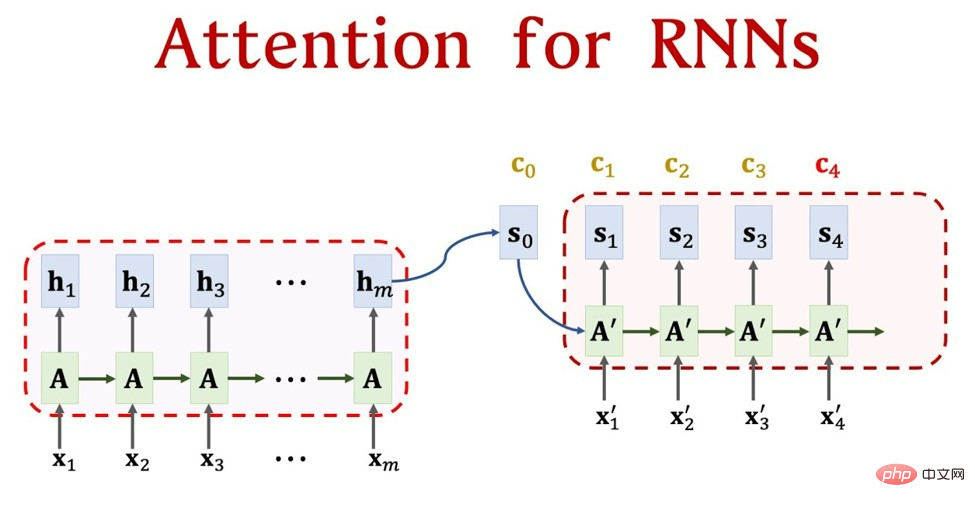
トランスフォーマーの継承
新しい系譜 - 多くの王子たち

図 5. ViT による画像の処理方法 (出典: Are Transformers better than CNN's)画像認識で? | Arjun Sarkar 著 | データ サイエンスに向けて)
その後、さまざまな Transformer ベースのモデルが際限なく出現し、それらは対応に非常に効果的でした。全員が CNN を超える成果を上げています。では、Transformer の利点は何でしょうか? 映画の例に戻って、Transformer と CNN の違いを見てみましょう:あなたが監督であると想像してください。映画を撮影するには、俳優を配置し、さまざまな要素を適切な場所に配置する必要があります。たとえば、俳優を適切な背景に配置します。適切な光を使用して全体を作ります。写真は調和して美しく見えます。 CNN の場合、これはプロの写真家が各フレームをピクセルごとにキャプチャし、エッジやテクスチャなどの低レベルの特徴を抽出するようなものです。次に、これらの特徴を組み合わせて、顔、アクションなどのより高いレベルの特徴を形成し、最終的にフレームを取得します。映画が進行するにつれて、CNN は映画全体が撮影されるまでこのプロセスを繰り返します。 ViTではアートディレクターのような存在で、背景、光、色などを考慮しながら画面全体を捉え、各俳優をアサインしていきます。適切な位置と角度で完璧な写真が作成されます。 ViT はこの情報をベクトルに集約し、多層パーセプトロンを使用して処理し、フレームを生成します。フィルムが進行するにつれて、ViT はフィルム全体が作成されるまでこのプロセスを繰り返します。 画像処理タスクに戻り、224x224 ピクセルの猫の写真があり、ニューラル ネットワークを使用してそれを分類したいとします。従来の畳み込みニューラル ネットワークを使用する場合、複数の畳み込み層とプーリング層を採用して画像のサイズを徐々に縮小し、最終的により小さな特徴ベクトルを取得し、完全接続層を通じて分類します。この方法の問題は、畳み込みとプーリングのプロセス中に、すべてのピクセル間の関係を同時に考慮することができないため、画像内の情報が徐々に失われることです。また、畳み込み層とプーリング層の順序制限により、グローバルな情報交換を行うことができません。対照的に、Transformer とセルフ アテンション メカニズムを使用してこの画像を処理すると、画像全体をシーケンスとして直接扱い、それに対してセルフ アテンションの計算を実行できます。この方法では、ピクセル間の関係が失われず、グローバルな情報の相互作用が可能になります。 #さらに、セルフアテンションの計算は並列化できるため、画像全体を同時に処理でき、計算が大幅に高速化されます 。たとえば、「アイスクリームを食べるのが好きです」という文があり、これには 6 つの単語が含まれているとします。この文を理解するためにセルフ アテンション メカニズムに基づくモデルを使用していると仮定すると、Transformer は次のことができます。 ただし、ViT がその可能性を最大限に発揮するには大規模なデータセットと高解像度の画像が必要であるため、ビジョン トランスフォーマーは CV の分野で優れていますが、CNN は CV の分野で優れたパフォーマンスを発揮します。コンピュータビジョンの分野では、その応用と研究はさらに広範であり、ターゲットの検出やセグメンテーションなどのタスクに利点があります。 しかし、それは問題ではありません。あなたは十分にうまくやりました。あなたの父親が CV に参加するという当初の意図は CNN に代わることではなく、もっと野心的な目標があったのです。 この目標の根拠となるのが、先ほどお話しした「さらに」です。 前にも言ったように、Transformer にはより野心的な目標があります。それは「ビッグモデル」、つまり超超ビッグモデルです。前回の記事で述べたトランスフォーマーはグローバル情報をより適切に取得できることに加えて、計算の複雑さの軽減と並列処理の向上が、大規模なモデルをサポートするための基礎となっています。 2021 年、Vision Transformer の大きな進歩に加えて、GPT チームは依然として GPT3.5 に向けて集中的に準備を進めています。休むことのできないモデルワーカーの Transformer は、新たな目標を導き出しました。クライマックス - テキストと画像を接続します。このクライマックスは、NLP の分野外での「ビッグモデル」プロジェクトの最初の火種ともなりました。現時点では、視覚タスクにおける Transformer の欠点が、ここでは利点に変わりました。 「ViT が最大限の可能性を発揮するには、大規模なデータ セットと高解像度の画像が必要です。」言い換えれば、「ViT は大規模なデータ セットと高解像度の画像を処理できます。」 古いルールですが、まず CLIP とは何かについて話しましょう。 CLIP の正式名称は Contrastive Language-Image Pre-Training で、その基本的な考え方は明らかに従来の CV 分野における対比学習です。新しい知識を学ぶとき、私たちはさまざまな本や記事を読んで多くの情報を入手します。しかし、私たちはすべての本や記事にあるすべての単語や文章をただ暗記するわけではありません。代わりに、この情報間の類似点と相違点を見つけようとします。たとえば、トピックの説明方法や提示されている主要な概念は本によって異なる場合がありますが、説明されている概念は本質的に同じであることに気づく場合があります。類似点と相違点を見つけるこの方法は、対照学習の基本的な考え方の 1 つです。それぞれの本や記事は異なるサンプルとして考えることができ、同じトピックに関する本や記事は同じカテゴリの異なるインスタンスとして考えることができます。対照学習では、これらの異なるカテゴリのサンプルを区別してそれらの類似点と相違点を学習する方法を学習するようにモデルをトレーニングします。 次に、もう少し学術的に、自動車のブランドを識別するモデルをトレーニングしたいとします。 「Mercedes-Benz」、「BMW」、「Audi」などのブランド ラベルが付いた車のラベル付き画像のセットを作成できます。従来の教師あり学習では、画像とブランド ラベルを一緒にモデルにフィードし、モデルに正しいブランド ラベルを予測する方法を学習させます。 しかし、対照学習では、ラベルのない画像を使用してモデルをトレーニングできます。ラベルのない一連の車の画像があるとします。これらの画像をポジティブ サンプルとネガティブ サンプルの 2 つのグループに分けることができます。ポジティブ サンプルは同じブランドを異なる角度から見た画像であり、ネガティブ サンプルは異なるブランドの画像です。次に、対照学習を使用してモデルをトレーニングし、同じブランドのポジティブ サンプルが互いに近くなり、異なるブランドのネガティブ サンプルが互いに遠ざかるようにすることができます。このようにして、モデルは、各画像のブランド ラベルを明示的に伝えることなく、画像からブランド固有の特徴を抽出する方法を学習できます。 明らかに、これは自己教師あり学習モデルです。CLIP も同様の自己教師あり学習モデルですが、目的が言語と画像を結び付けてコンピューターが理解できるようにすることである点が異なります。文字と画像の関係。 各単語の定義と対応するイメージが含まれる一連の語彙リストを学習していると想像してください。それぞれの単語とそれに対応する画像をペアとして考えることができます。あなたの仕事は、これらの単語と画像の間の相関関係、つまり、どの単語がどの画像に一致し、どの単語が一致しないかを見つけることです。 図 6 に示すように、対比学習アルゴリズムの場合、これらの単語と画像のペアは、いわゆる「アンカー」(アンカー サンプル) と「ポジティブ」(ポジティブ サンプル) です。 「アンカー」は学習したいオブジェクトを指し、「ポジティブ」は「アンカー」に一致するサンプルを指します。その反対は「ネガティブ」(ネガティブサンプル)、つまり「アンカー」と一致しないサンプルです。 対照学習では、「アンカー」と「ポジティブ」をペアにして区別しようとします。また、「アンカー」と「ネガティブ」をペアにして区別してみます。このプロセスは、「アンカー」と「ポジティブ」の類似点を探し、「アンカー」と「ネガティブ」の類似点を除外するものとして理解できます。 #図 6. 対照学習の図解 [14]。アンカーは元の画像です。ポジは通常、トリミングおよび回転された元の画像、または同じカテゴリの既知の画像です。ネガは、未知の画像 (おそらく同じカテゴリ) または既知の画像として単純かつ大まかに定義できます。画像のさまざまなカテゴリ。 この目標を達成するために、CLIP はまず大量の画像とテキストを事前トレーニングし、次に事前トレーニングされたモデルを分類、検索、生成などの下流タスクに使用します。 CLIP モデルは、テキストと画像を同時に処理し、トレーニングを通じてそれらを接続する方法を学習する新しい自己教師あり学習方法を使用します。テキストと画像の間で注意メカニズムを共有し、調整可能なパラメーターの単純なセットを使用してこのマッピングを学習します。トランスフォーマー ベースのテキスト エンコーダーと CNN ベースの画像エンコーダーを使用して、画像とテキストの埋め込み間の類似性を計算します。 CLIP は、データ内に存在する画像とテキストのペア間の一貫性を最大化し、ランダムにサンプリングされた画像とテキストのペア間の一貫性を最小限に抑える対照的な学習目標を使用して、画像とテキストの関連付けを学習します。 #図 7. クリップの図 [13]。図 6 と比較すると、図 6 のポジティブとネガティブが両方ともテキストであることが簡単に理解できます。 たとえば、CLIP を使用して写真が「赤いビーチ」かどうかを識別したい場合、このテキストの説明と写真を入力すると、CLIP は次のようにします。それらの接続を表すベクトルのペアを生成します。このベクトルのペア間の距離が非常に小さい場合、その写真は「赤いビーチ」である可能性があり、その逆も同様です。このアプローチにより、CLIP は画像分類や画像検索などのタスクを可能にします。 正式名称に戻ると、CLIP の最後の言葉は pretraining であるため、その本質は依然として事前トレーニング モデルですが、画像と画像のマッチングを含むさまざまな下流タスクに使用できます。画像などのテキスト 分類、ゼロショット学習、画像記述生成などたとえば、CLIP を使用すると、「犬の写真」や「風景」など、自然言語ラベルによって与えられたカテゴリに画像を分類できます。 CLIP は、CLIP によって抽出された画像の特徴に基づいて条件付けされた言語モデルを使用して、画像のキャプションを生成するためにも使用できます。さらに、CLIP を使用すると、CLIP によって抽出されたテキストの特徴に条件付けされた生成モデルを使用して、テキストから画像を生成できます。 CLIP の助けを借りて、新しい王子が立ち上がりました - 彼の名前は AIGC (AI 生成コンテンツ) です。実際、ChatGPT は本質的に AIGC の一種ですが、このセクションでは主に AI ペイントについて説明します。まず、AI ペイントの小さなファミリーの開発の歴史を見てみましょう: オリジナルの DALL-E については、あなたが画家であり、DALL-E がツールボックスであると仮定します。このたとえでは、ツールボックスには 2 つの主要なツールがあります。1 つはブラシで、もう 1 つはパレットです。 Brush は、指定されたテキストの説明を画像に変換する DALL-E のデコーダーです。パレットは DALL-E のエンコーダーで、あらゆるテキスト記述を特徴ベクトルに変換できます。 テキストの説明を取得したら、まずカラー パレットを使用して特徴ベクトルを生成します。次に、絵筆を取り、特徴ベクトルを使用して、説明に一致する画像を生成できます。細部が必要な場合は細かいブラシを使用し、そうでない場合は粗いブラシを使用します。 ペインターとは異なり、DALL-E はブラシやパレットの代わりにニューラル ネットワークを使用します。このニューラルネットワークはImage Transformer Networkと呼ばれる構造を使用しています。画像を生成するとき、DALL-E は前述の GPT-3 モデルを使用して、テキストの説明に対応する CLIP 画像埋め込みを生成します。次に、DALL-E はビーム検索アルゴリズムを使用して、入力テキストの説明に一致する一連の可能な画像を生成し、それらをデコーダーに供給して最終画像を生成します。この埋め込みベクトルは、類似の画像とテキストを隣接する空間に埋め込み、より簡単に結合できるようにする対照学習と呼ばれる手法を使用してトレーニングされます。 ここでの DALLE には CLIP が直接含まれていないことに注意してください。ただし、CLIP のテキストと画像の埋め込みを使用して、トランスフォーマーと VAE をトレーニングします。 画像生成のプロセスで使用されるビームサーチアルゴリズムについては、実際には、限られた候補のセットから最適なシーケンスを見つけることができる貪欲な探索アルゴリズムです。ビーム探索の基本的な考え方は、現在のシーケンスが拡張されるたびに、最も高い確率を持つ k 個の候補だけが保持され (k はビーム幅と呼ばれます)、他の低確率の候補は破棄されるというものです。これにより、検索スペースが削減され、効率と精度が向上します。ビーム検索を使用して DALLE で画像を生成する具体的な手順は次のとおりです。 同じ絵でも安定した拡散を描くには?芸術作品を描きたいときは、通常、優れた構図と、それを構築するためのいくつかの特定の要素が必要です。安定拡散は、画像生成プロセスを拡散プロセスと再構成プロセスの 2 つの部分に分割する画像生成方法です。拡散プロセスは、散らばったブラシ、絵の具、キャンバスを混ぜ合わせて、キャンバス上に徐々に多くの要素を作成することだと考えてください。このプロセスでは、最終的な画像がどのようなものになるのか、各要素の最終的な位置を決定することもできませんでした。ただし、絵画全体が完成するまで、これらの要素を徐々に追加および調整できます。次に、入力されたテキストの説明は、描きたい作品の大まかな説明のようなもので、ビーム検索アルゴリズムを使用して、テキストの説明と生成された画像の間の精密な一致が実行されます。このプロセスは、希望する画像に合わせて要素を常に変更および調整するようなものです。最終的に、結果として得られる画像はテキストの説明と厳密に一致し、私たちが想像した芸術作品をレンダリングします。 図 8 に示すように、ここでの拡散モデルは、データに徐々にノイズを追加し、元のデータを復元するプロセスを逆にすることによってデータの分布を学習する生成モデルです。安定拡散では、事前トレーニングされた変分オートエンコーダー (VAE) を使用して画像を低次元の潜在ベクトルにエンコードし、トランスフォーマーベースの拡散モデルを使用して潜在ベクトルから画像を生成します。安定した拡散では、フリーズされた CLIP テキスト エンコーダも使用して、テキスト キューを画像埋め込みに変換し、拡散モデルを調整します。 図 8. 安定した拡散プロセス。 1つ目は上の矢印で、画像にノイズが追加され続けて最終的に純粋なノイズ画像になり、次に下の矢印で徐々にノイズを除去し、元の画像を再構成します。 (出典: DALL・E から安定拡散へ: テキストから画像への生成モデルはどのように機能しますか? | Tryolabs) 安定拡散における拡散プロセスはランダムなプロセスであるため、たとえ同じテキスト記述であっても、生成される画像は毎回異なることに注意してください。このランダム性により、生成される画像がより多様になり、アルゴリズムの不確実性も高まります。生成された画像をより安定させるために、安定拡散では、拡散プロセス中に徐々に増加するノイズを追加したり、複数の再構成プロセスを使用して画質をさらに向上させたりするなど、いくつかの技術が使用されます。 安定拡散は DALL-E に基づいて大きな進歩を遂げました: これが、DALL-E-2 がモデルに拡散モデルを追加した理由です。 他の王子たちが改革を本格化させる中その頃、GPTチームも黙々と頑張っていました。冒頭でも述べたように、GPT-3はリリース当初からすでに強力な性能を持っていましたが、その使用方法がそれほど「非技術的」ではなかったため、それが引き起こした波紋はすべてあまり熱心ではなかった技術界にありました。そもそも、手数料が高いため、ますます消え去っています。 トランスフォーマーは非常に不満があり、GPTが考えて改革しました! 改革の要求に応え、最初の一歩を踏み出したのは GPT 3.5 でした: # # 「私はバカなので、良い改革方法が思いつきません。まずはしっかりと基礎を固めましょう。」 つまり、GPT3.5 は、 GPT-3 では、テキスト コードと呼ばれるトレーニング データの一種を使用します。これはテキスト データに基づいており、いくつかのプログラミング コード データが追加されます。簡単に言えば、より大きなデータセットが使用されます。これにより、モデルがコードをより深く理解して生成できるようになり、モデルの多様性と創造性が向上します。テキスト コードは、OpenAI によって Web から収集および整理されたテキストおよびコードベースのトレーニング データです。これは、テキストとコードの 2 つの部分で構成されます。テキストとは、記事、コメント、会話など、自然言語で記述されたコンテンツです。コードとは、Python、Java、HTML などのプログラミング言語で書かれたものです。
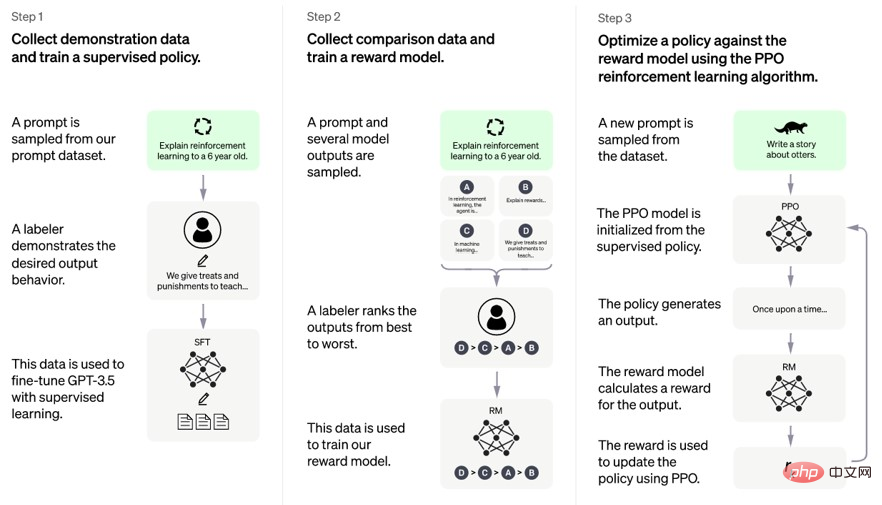
#電話に 2 番目に応答したのは Instruct GPT で、新しい問題を発見しました: その結果、有名な新しい対外援助が登場しました。それがRLHFの訓練戦略です。 RLHF は強化学習に基づいたトレーニング戦略であり、正式名称は Reinforcement Learning from Human Feedback です。その中心となるアイデアは、トレーニング プロセス中にモデルに何らかの指示を与え、モデルの出力に基づいて報酬またはペナルティを与えることです。これにより、モデルが指示に従うことが可能になり、モデルの制御性と信頼性が向上します。実はGPT-3.5には人間によるフィードバックも含まれているのですが、強化学習(強化学習)を加えたことでどのような変化が起こったのでしょうか? #言い換えると、必要な人的投資は少なくて済みますが、モデルにより大きなメリットがもたらされます。
##写真 9 . RLHF プロセス (出典: GPT-4 (openai.com)) 図 9 に示すように、RLHF トレーニング戦略は 2 つの段階に分かれています。 - トレーニングと微調整。事前トレーニング段階では、モデルは言語の基本的な知識とルールを学習する教師なし学習用の GPT-3 と同じデータセットを使用します。微調整フェーズでは、モデルは強化学習のために手動でラベル付けされたデータを使用し、指示に基づいて適切な出力を生成する方法を学習します。 手動でラベル付けされたデータは、指示とフィードバックの 2 つの部分で構成されます。指示は、「春についての詩を書いてください」や「犬についてのジョークを言ってください」など、自然言語で記述されたタスクです。フィードバックは、悪い場合は「1」、優れている場合は「5」などの数値評価です。フィードバックは、モデルの出力に基づいてヒューマン アノテーターによって与えられ、モデルの出力の品質と妥当性を反映します。 微調整フェーズでは、モデルは強化学習に Actor-Critic と呼ばれるアルゴリズムを使用します。 Actor-Critic アルゴリズムは、Actor と Critic の 2 つの部分で構成されます。アクターは、命令に基づいて出力を生成するジェネレーターです。 Critic は、フィードバックに基づいて出力報酬値を評価する評価者です。俳優と批評家は互いに協力して競争し、パラメータを常に更新して報酬値を増やします。 RLHF トレーニング戦略により、モデルが指示に従うようになり、モデルの制御性と信頼性が向上します。たとえば、ライティングタスクでは、モデルは指示に従ってさまざまなスタイルやテーマのテキストを生成でき、テキストは高い一貫性とロジックを備えています。会話タスクでは、モデルは指示に基づいてさまざまな感情や口調の応答を生成でき、その応答は関連性が高く丁寧です。 ついに、前任者の改革と蓄積を経て、GPT ファミリーのより柔軟な末っ子である ChatGPT がその時が来たと感じ、この傾向を利用して、 Instruct GPT に基づいた人間のコミュニケーション方法により近い対話モードは、人間社会 (数億のユーザー) に直接大きな波を引き起こし、無料です。数年間の休止期間を経て、最終的に GPT ファミリーが誕生しました。大ヒット作となり、トランスフォーマー一家の王子様として最も支持され、後継者争いに直接飛び込み、一等賞を獲得して王子様となる。 同時に、ChatGPT にとって、王子様がすべてではありません。ChatGPT は、Transformer の大きな野望を継承しています: 「現状「あまりにも混沌としています。強力な王朝にはそれほど多くの王子は必要ありません。今こそ彼らを統一する時です。」 GPT-4 「これは、時代は大型模型の時代だ、と私は言いました」(節) 現在の ChatGPT はすでに GPT-4 に基づいています。 GPT-4は競合他社の迅速な対応を恐れているため、技術的な詳細のほとんどは実際には公開されていない。しかし、その機能からは様々な王子を統一しようとするGPTファミリーの野望が見て取れ、GPT-4にはテキスト対話に加えてAIマッピング機能も追加されている。 GPTファミリーは、ここ数年の眠っていた経験から「ビッグモデルは正義」という真実に気づき、この真実を様々な分野に広げていきたいと考えています。 この原則の背後にある理由をさらに深く掘り下げると、それは大規模なモデルをトレーニングする方法になる可能性があります。 GPT-3 は現在最大の言語モデルの 1 つであり、そのパラメータ数は 1,750 億個で、前世代の GPT-2 の 100 倍、以前の最大の同様の NLP モデルの 10 倍に達します。大きな予測モデルか。 それでは、まず、GPT-3 のモデル アーキテクチャとトレーニング方法がどのようにしてこのようなスケールとパフォーマンスを達成するのかを見てみましょう: 「大規模なモデルは確かに現在のトレンドですが、競争のためだけに盲目的にスケールを追求すべきではありません。大規模なモデルをトレーニングする前に、安定して効率的に実行できることを確認するために、より多くの詳細と技術的な課題を検討する必要があります。有用な結果。" "まず、適切なトレーニング ハイパーパラメータとモデルの初期化を選択することが非常に重要です。学習率、バッチ サイズ、反復数などのハイパーパラメータの選択が重要です。モデルの収束に大きな影響を与える速度、安定性、パフォーマンスに大きな影響を与えるモデルの初期化はトレーニング開始前の重み値を決定し、最終結果の品質に影響しますこれらのパラメーターは経験的実験や経験に基づいて慎重に調整する必要がありますモデルの最高のパフォーマンスを保証するための理論的分析。」 「第 2 に、高いスループットを実現し、ボトルネックを回避するには、ハードウェア構成、ネットワーク帯域幅、データ読み込み速度、モデル アーキテクチャなど、トレーニング プロセスのさまざまな側面を最適化する必要があります。これらの側面の最適化モデルの処理速度と効率を大幅に向上させることができます。たとえば、より高速なストレージ デバイスまたはデータ形式を使用すると、データの読み込み時間を短縮できます。より大きなバッチ サイズまたは勾配累積を使用すると、通信オーバーヘッドを削減できます。より単純なモデルまたはよりスパースなモデルを使用すると、通信オーバーヘッドを削減できます。計算時間など。" "最後に、大規模なモデルをトレーニングすると、数値エラー、過剰適合、ハードウェア障害、データ品質の問題など、さまざまな不安定性や障害状況が発生する可能性があります。これらの問題を回避または回復するには、モデルの動作とパフォーマンスを注意深く監視し、デバッグ ツールとテクニックを使用してエラーや欠陥を特定して修正する必要があります。さらに、さまざまな安全対策を使用することもできます。クリッピング、正則化、破棄、ノイズ挿入、データ フィルタリング、データ拡張などの保護メカニズムにより、モデルの堅牢性と信頼性が向上します。" "この時代では「大規模なモデルは確かに重要ですが、単に規模を追求するだけでは、モデルが有用な結果を生み出すことはできません。思慮深いトレーニングと最適化を通じてのみ、大規模なモデルがその可能性を真に実現し、人間により多くの価値をもたらすことができます。」 王子の言うことは正しい。 結局のところ、痩せたラクダは馬よりも大きいです。BERT は最近 GPT の影に隠れてきましたが、依然としてGPT の止まらない発展のもとで、BERT は依然として独自の領地を保持しています。自然言語処理モデルについて話すとき、BERT (Transformers からの双方向エンコーダー表現) は、多くのタスクで非常に優れたパフォーマンスを発揮したため、かつては非常に人気のあるモデルでした。最初にリリースされたとき、それはほとんど無敵であり、GPT よりもさらに成功しました。これは、BERT が GPT とは異なる目標と利点を持って設計されているためです。 BERT の目標は、コンテキスト モデリングの機能をまったく新しいレベルに押し上げ、テキスト分類や質問応答などの下流タスクをより適切にサポートすることです。この目標は、双方向の Transformer エンコーダをトレーニングすることで達成されます。このエンコーダーは入力シーケンスの左側と右側の両方を考慮できるため、コンテキスト表現が向上します。そのため、BERT はコンテキストをより適切にモデル化でき、ダウンストリーム タスクでのモデルのパフォーマンスが向上します。 しかし、時間の経過とともに、GPT シリーズ モデルの登場により、GPT-3 は複数のタスクで BERT を超えることが可能になりました。考えられる理由の 1 つは、GPT シリーズのモデルがテキスト生成や対話システムなどの生成タスクに重点を置くように設計されているのに対し、BERT は分類や質疑応答タスクに重点を置いているということです。さらに、GPT シリーズ モデルは、トレーニングにより大きなパラメーターとより多くのデータを使用するため、より幅広いタスクでより優れたパフォーマンスを達成することもできます。 もちろん、BERT は、特にテキストの分類や質問への回答が必要な一部のタスクでは、依然として非常に役立つモデルです。 GPT シリーズのモデルは、テキスト生成や対話システムなどの生成タスクにより適しています。全体として、どちらのモデルにも独自の利点と制限があるため、特定のタスクのニーズに基づいて適切なモデルを選択する必要があります。 前述の通り、兄貴分のGPTが黙々と頑張っている一方で、モデルワーカーのトランスフォーマーは CV フィールド (ViT) とマルチモーダル フィールド (CLIP) で大騒ぎになりましたが、最終的には二人とも経験豊富な赤ちゃんとなり、老父トランスフォーマーから寵臣 GPT 王子に教えを受け、最終的にはいわゆる GPT-4 を達成しました。 骨の髄までトランスフォーマーの血が流れているViTとCLIPは、きっと満足していません。 「私たち? 私たちも彼から学ぶことができます。」 「しかし、NLP の分野では彼はあまりにも強力です。私たちは新しい戦場を見つける必要があります。」 そこで、SAM が誕生しました。公式ウェブサイトでは、このように説明されています: Segment Anything Model (SAM): あらゆる画像内のあらゆるオブジェクトを「切り出す」ことができる Meta AI の新しい AI モデル。ワンクリックで 簡単に言えば、SAM は、さまざまな入力プロンプトを通じて画像内のさまざまなオブジェクトを正確に識別してセグメント化できる効率的な「画像編集マスター」と考えることができます。たとえば、画像内の点をマウスでクリックすると、SAM は経験豊富な画家のように、その点が位置するオブジェクトを自動的に切り出します。「猫」という単語を入力すると、SAM は探偵のように賢く動作します。では、画像内のすべての猫を自動的に見つけて切り出します。SAM にターゲット検出フレームを与えると、SAM は熟練した外科医のようにフレーム内のオブジェクトを正確に切り出します。 SAM の ゼロサンプル汎化機能 ## により、SAM は真の「ユニバーサル編集マスター」となります。これは、車、木、建物などの一般的な物体であっても、恐竜、宇宙人、魔法の杖などの珍しい物体であっても、SAM はそれらを識別して簡単に切断できることを意味します。この強力な機能は、高度なモデル設計と大規模なデータセットに由来しています。 SAM で何ができるかを説明するために、元の論文 (図 10) から 4 つの非常に複雑なシーンの例を選択しました。 図 10. SAM の効果の例。画像内のすべての色を編集して抽出することができ、効率的な PS マスター (画像編集マスター) に相当します。 簡単に言うと、他の人が興奮して私たちのところに要求をしてくるとき、私たちはいつも「ちょっと待ってください、どんなデータを提供してもらえますか?」と無力に尋ねなければなりませんでした。今は必要ありません。少なくとも CV 分野では、AI についての非技術者層の理解に近いです。。 上記の強力な機能を実現するために、ViT と CLIP がどのように大声で共謀したかを見てみましょう: ViT:以前は主に画像分類タスクを行っていましたが、私のアーキテクチャは画像のセグメンテーションにも適しています。Transformer アーキテクチャを使用して画像を一連のブロックに分解し、それらを並列処理しているためです。私の利点を統合すると、SAM は継承できます私の並列処理とグローバル アテンションの利点により、効率的な画像セグメンテーションが達成されます。" クリップ: "わかりました。では、私の共同トレーニング方法を使って投資します。このアイデアに基づいて、SAM は次のことができます。また、さまざまなタイプの入力プロンプト (質問プロンプトと視覚的プロンプト) も処理します。" そこで、SAM モデル アーキテクチャが形成され (図 11)、ViT が画像エンコーダとして使用されました (画像エンコーダ)、およびプロンプト情報をエンコードする CLIP。アイデアは良いですが、それを実行する方法は、もちろん兄から学びましょう。 「テキスト プロンプト (プロンプト) を使用して言語モデルにテキストを生成または予測させるのと同じように、画像セグメンテーション タスクに事前トレーニングされた言語モデルを使用したいと考えています。CLIP を使用すると、ヒントが得られます。これは、いくつかのポイント、ボックス、マスク、およびテキストであり、言語モデルに画像内で何をセグメント化するかを指示します。私たちの目標は、任意のプロンプトに対して、有効なセグメンテーション マスク (セグメント化結果) を取得できることです。有効なマスクとは、たとえプロンプトがあいまいであっても (たとえば、シャツや人)、出力はオブジェクトの 1 つに対して適切なマスクである必要があることを意味します。これは、兄貴分の GPT (言語モデル) が提供できるものと似ています。曖昧なプロンプトに対する一貫した応答。このタスクを選択したのは、自然な方法で言語モデルを事前トレーニングし、プロンプトを介してさまざまなセグメンテーション タスクへのゼロショット転送を達成できるためです。" 図 11. SAM モデル アーキテクチャ 結果については、前述の強力な機能により実現可能性が確認されました。このアイデアの。ただし、SAM はモデルを再トレーニングする必要がなくなりましたが、chatGPT が最初に起動されたときと同様に、依然としていくつかの制限があることに注意する必要があります。この論文の「制限」セクションでは、著者ページが、詳細、接続性、境界などの欠陥や、インタラクティブなセグメンテーション、リアルタイム、テキスト プロンプトなどのタスクにおける欠陥など、SAM のいくつかの制限と欠点を明確に指摘しています。 、セマンティクス、パノラマ セグメンテーションなどの課題に対処する一方で、いくつかのドメイン固有のツールの利点も認識しています。 たとえば、デモでは 2 つの簡単なテストを行いました: 1 つは医療画像の分野での病変検出 (病変は小さすぎて検出が難しいため)、2 つ目はポートレートのカットです。一見すると良いのですが、髪はまだあまり自然ではなく、よく見ると切断跡がまだ見えます。 もちろん、これは良いスタートです。まだ起業したばかりで、まだ頑張っているこの 2 人は、どんな自転車を望んでいますか?それでは、この家宝がどのような結末を迎えるのか、楽しみに待ちましょう! Transformer の巨大なファミリーについては、明らかにこの記事では説明できません。Transformer に基づいた結果に関して言えば、進歩がわかります。継続的なイノベーション: Vision Transformer (ViT) は、コンピューター ビジョンの分野での Transformer の応用の成功を実証します。これにより、手動の特徴エンジニアリングを行わずに画像ピクセル データを直接処理できます。 DALL-E と CLIP は、Transformer を画像生成および画像分類タスクに適用し、視覚的な意味理解における優れたパフォーマンスを実証しました。 Stable Diffusion は、画像のセグメンテーションや生成などのタスクに適用できる確率分布をモデル化できる安定した拡散プロセスを提案します。これらの結果は、Transformer モデルの広範な応用の見通しを明らかにしており、将来、「必要なのは注意力だけ」になることを認めざるを得ません。 つまり、これらの結果から、人工知能分野における継続的なイノベーションの活力がわかります。 GPT や BERT、ビジョン トランスフォーマー、DALL-E、CLIP、安定拡散など、これらの成果は人工知能の分野における最新の進歩を表しています。 大きな試験(ChatGPT)については、現状はおそらく次のような状況でしょう。 トップ学者の皆さん、今学期はしっかり授業を受けて、本を開くと、そのクラスでこの知識ポイントについて話したときの先生の声と笑顔を思い出し、次の学期の学習計画を立て始めることさえできます。 疑似学問の達人たちは毎日授業に来て最前列を占め、教科書を開くと混乱し、悪い生徒たちを「一冊一冊」と追いかけ始める。唯一の違いは、教科書が新品ではなく、教科書の内容をまだ少し覚えていることですが、これは完全に新しい知識を学んだとは言えません。 本当のクズ野郎は… 「知識はやってくる、知識はやってくる、知識はあらゆる方向からやってくる」 #実際のところ、あなたが偽物の学業マスターであろうと、クソ野郎であろうと、期末試験の前では落ち着いて、今学期に教えられたことを見直し、学者のノートを借りるべきだと思います。修士号を取得したり、「試験を延期」を選択したりすることもできます。一流の学者にとって、スピードは自然なものです。インチキ学者やクズ野郎にとって、スピードは有害だ。 人工知能分野の競争では、継続的なイノベーションが重要です。したがって、研究者として、私たちはこの分野の最新の発展に細心の注意を払い、謙虚でオープンな心を維持して人工知能分野の継続的な進歩を促進する必要があります。
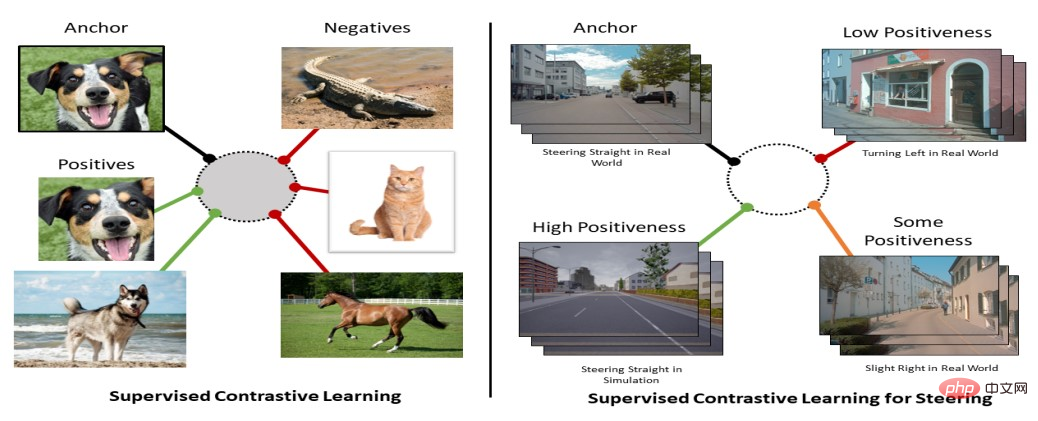
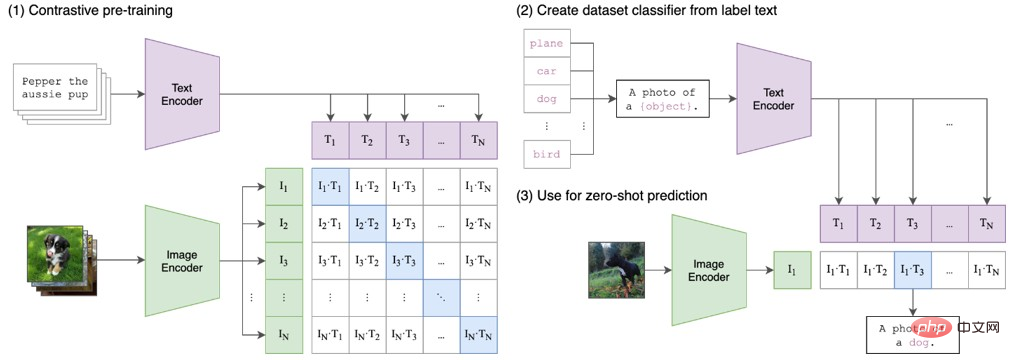
長兄の CLIP は画像とテキストを結び付け、双子の弟 DALL-E はこれを機にテキストという仕事を提案しました。画像。このタスクを改善するために、遠い親戚である安定拡散が画像生成アルゴリズムを改良し、最終的に DALL-E-2 が相互に学習し、GPT-3、CLIP、安定拡散の利点を組み合わせて独自の AI を完成させました。ペイントシステム。

潜在的実力者-GPT3.5 [18]
& GPTを指導する [19]
強力な王子の衰退 - BERT
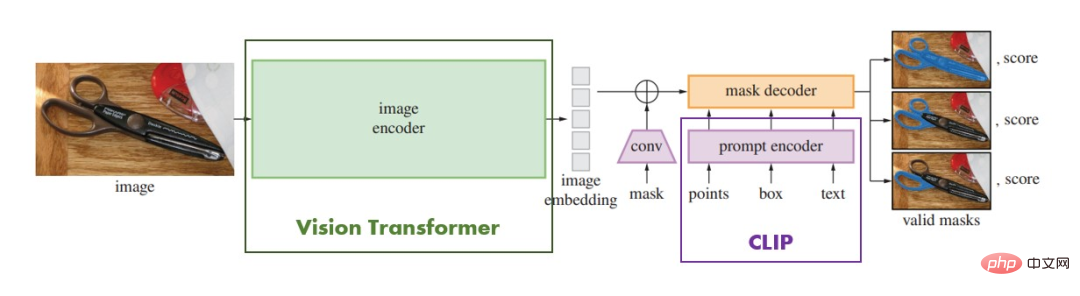
直系子孫を巡る戦い 脅威のセグメント・エニシング・モデル(SAM) [20]

概要
以上がGPT-3 から始まり、Transformer の巨大な家系図を書き続けるの詳細内容です。詳細については、PHP 中国語 Web サイトの他の関連記事を参照してください。

ホットAIツール

Undresser.AI Undress
リアルなヌード写真を作成する AI 搭載アプリ

AI Clothes Remover
写真から衣服を削除するオンライン AI ツール。

Undress AI Tool
脱衣画像を無料で

Clothoff.io
AI衣類リムーバー

AI Hentai Generator
AIヘンタイを無料で生成します。

人気の記事
ホットツール

メモ帳++7.3.1
使いやすく無料のコードエディター

SublimeText3 中国語版
中国語版、とても使いやすい

ゼンドスタジオ 13.0.1
強力な PHP 統合開発環境

ドリームウィーバー CS6
ビジュアル Web 開発ツール

SublimeText3 Mac版
神レベルのコード編集ソフト(SublimeText3)
ホットトピック
 7467
7467
 15
1376
52
77
11
19
20
15
1376
52
77
11
19
20

 Bytedance Cutting が SVIP スーパー メンバーシップを開始: 継続的な年間サブスクリプションは 499 元で、さまざまな AI 機能を提供
Jun 28, 2024 am 03:51 AM
Bytedance Cutting が SVIP スーパー メンバーシップを開始: 継続的な年間サブスクリプションは 499 元で、さまざまな AI 機能を提供
Jun 28, 2024 am 03:51 AM
このサイトは6月27日、JianyingはByteDanceの子会社であるFaceMeng Technologyによって開発されたビデオ編集ソフトウェアであり、Douyinプラットフォームに依存しており、基本的にプラットフォームのユーザー向けに短いビデオコンテンツを作成すると報告しました。 Windows、MacOS、その他のオペレーティング システム。 Jianyingは会員システムのアップグレードを正式に発表し、インテリジェント翻訳、インテリジェントハイライト、インテリジェントパッケージング、デジタルヒューマン合成などのさまざまなAIブラックテクノロジーを含む新しいSVIPを開始しました。価格的には、クリッピングSVIPの月額料金は79元、年会費は599元(当サイト注:月額49.9元に相当)、継続月額サブスクリプションは月額59元、継続年間サブスクリプションは、年間499元(月額41.6元に相当)です。さらに、カット担当者は、ユーザーエクスペリエンスを向上させるために、オリジナルのVIPに登録している人は、
 Rag と Sem-Rag を使用したコンテキスト拡張 AI コーディング アシスタント
Jun 10, 2024 am 11:08 AM
Rag と Sem-Rag を使用したコンテキスト拡張 AI コーディング アシスタント
Jun 10, 2024 am 11:08 AM
検索強化生成およびセマンティック メモリを AI コーディング アシスタントに組み込むことで、開発者の生産性、効率、精度を向上させます。 JanakiramMSV 著者の EnhancingAICodingAssistantswithContextUsingRAGandSEM-RAG から翻訳。基本的な AI プログラミング アシスタントは当然役に立ちますが、ソフトウェア言語とソフトウェア作成の最も一般的なパターンに関する一般的な理解に依存しているため、最も適切で正しいコードの提案を提供できないことがよくあります。これらのコーディング アシスタントによって生成されたコードは、彼らが解決する責任を負っている問題の解決には適していますが、多くの場合、個々のチームのコーディング標準、規約、スタイルには準拠していません。これにより、コードがアプリケーションに受け入れられるように修正または調整する必要がある提案が得られることがよくあります。
 GenAI および LLM の技術面接に関する 7 つのクールな質問
Jun 07, 2024 am 10:06 AM
GenAI および LLM の技術面接に関する 7 つのクールな質問
Jun 07, 2024 am 10:06 AM
AIGC について詳しくは、51CTOAI.x コミュニティ https://www.51cto.com/aigc/Translator|Jingyan Reviewer|Chonglou を参照してください。これらの質問は、インターネット上のどこでも見られる従来の質問バンクとは異なります。既成概念にとらわれずに考える必要があります。大規模言語モデル (LLM) は、データ サイエンス、生成人工知能 (GenAI)、および人工知能の分野でますます重要になっています。これらの複雑なアルゴリズムは人間のスキルを向上させ、多くの業界で効率とイノベーションを推進し、企業が競争力を維持するための鍵となります。 LLM は、自然言語処理、テキスト生成、音声認識、推奨システムなどの分野で幅広い用途に使用できます。 LLM は大量のデータから学習することでテキストを生成できます。
 微調整によって本当に LLM が新しいことを学習できるようになるのでしょうか: 新しい知識を導入すると、モデルがより多くの幻覚を生成する可能性があります
Jun 11, 2024 pm 03:57 PM
微調整によって本当に LLM が新しいことを学習できるようになるのでしょうか: 新しい知識を導入すると、モデルがより多くの幻覚を生成する可能性があります
Jun 11, 2024 pm 03:57 PM
大規模言語モデル (LLM) は巨大なテキスト データベースでトレーニングされ、そこで大量の現実世界の知識を取得します。この知識はパラメータに組み込まれており、必要なときに使用できます。これらのモデルの知識は、トレーニングの終了時に「具体化」されます。事前トレーニングの終了時に、モデルは実際に学習を停止します。モデルを調整または微調整して、この知識を活用し、ユーザーの質問により自然に応答する方法を学びます。ただし、モデルの知識だけでは不十分な場合があり、モデルは RAG を通じて外部コンテンツにアクセスできますが、微調整を通じてモデルを新しいドメインに適応させることが有益であると考えられます。この微調整は、ヒューマン アノテーターまたは他の LLM 作成物からの入力を使用して実行され、モデルは追加の実世界の知識に遭遇し、それを統合します。
 新しい科学的で複雑な質問応答ベンチマークと大規模モデルの評価システムを提供するために、UNSW、アルゴンヌ、シカゴ大学、およびその他の機関が共同で SciQAG フレームワークを立ち上げました。
Jul 25, 2024 am 06:42 AM
新しい科学的で複雑な質問応答ベンチマークと大規模モデルの評価システムを提供するために、UNSW、アルゴンヌ、シカゴ大学、およびその他の機関が共同で SciQAG フレームワークを立ち上げました。
Jul 25, 2024 am 06:42 AM
編集者 |ScienceAI 質問応答 (QA) データセットは、自然言語処理 (NLP) 研究を促進する上で重要な役割を果たします。高品質の QA データ セットは、モデルの微調整に使用できるだけでなく、大規模言語モデル (LLM) の機能、特に科学的知識を理解し推論する能力を効果的に評価することもできます。現在、医学、化学、生物学、その他の分野をカバーする多くの科学 QA データ セットがありますが、これらのデータ セットにはまだいくつかの欠点があります。まず、データ形式は比較的単純で、そのほとんどが多肢選択式の質問であり、評価は簡単ですが、モデルの回答選択範囲が制限され、科学的な質問に回答するモデルの能力を完全にテストすることはできません。対照的に、自由回答型の Q&A
 あなたが知らない機械学習の 5 つの流派
Jun 05, 2024 pm 08:51 PM
あなたが知らない機械学習の 5 つの流派
Jun 05, 2024 pm 08:51 PM
機械学習は人工知能の重要な分野であり、明示的にプログラムしなくてもコンピューターにデータから学習して能力を向上させる機能を提供します。機械学習は、画像認識や自然言語処理から、レコメンデーションシステムや不正行為検出に至るまで、さまざまな分野で幅広く応用されており、私たちの生活様式を変えつつあります。機械学習の分野にはさまざまな手法や理論があり、その中で最も影響力のある 5 つの手法は「機械学習の 5 つの流派」と呼ばれています。 5 つの主要な学派は、象徴学派、コネクショニスト学派、進化学派、ベイジアン学派、およびアナロジー学派です。 1. 象徴主義は、象徴主義とも呼ばれ、論理的推論と知識の表現のためのシンボルの使用を強調します。この学派は、学習は既存の既存の要素を介した逆演繹のプロセスであると信じています。
 SOTA パフォーマンス、厦門マルチモーダルタンパク質-リガンド親和性予測 AI 手法、初めて分子表面情報を結合
Jul 17, 2024 pm 06:37 PM
SOTA パフォーマンス、厦門マルチモーダルタンパク質-リガンド親和性予測 AI 手法、初めて分子表面情報を結合
Jul 17, 2024 pm 06:37 PM
編集者 | KX 医薬品の研究開発の分野では、タンパク質とリガンドの結合親和性を正確かつ効果的に予測することが、医薬品のスクリーニングと最適化にとって重要です。しかし、現在の研究では、タンパク質とリガンドの相互作用における分子表面情報の重要な役割が考慮されていません。これに基づいて、アモイ大学の研究者らは、初めてタンパク質の表面、3D 構造、配列に関する情報を組み合わせ、クロスアテンション メカニズムを使用して異なるモダリティの特徴を比較する、新しいマルチモーダル特徴抽出 (MFE) フレームワークを提案しました。アライメント。実験結果は、この方法がタンパク質-リガンド結合親和性の予測において最先端の性能を達成することを実証しています。さらに、アブレーション研究は、この枠組み内でのタンパク質表面情報と多峰性特徴の位置合わせの有効性と必要性を実証しています。 「S」で始まる関連研究
 AIなどの市場を開拓するグローバルファウンドリーズがタゴール・テクノロジーの窒化ガリウム技術と関連チームを買収
Jul 15, 2024 pm 12:21 PM
AIなどの市場を開拓するグローバルファウンドリーズがタゴール・テクノロジーの窒化ガリウム技術と関連チームを買収
Jul 15, 2024 pm 12:21 PM
7月5日のこのウェブサイトのニュースによると、グローバルファウンドリーズは今年7月1日にプレスリリースを発行し、自動車とインターネットでの市場シェア拡大を目指してタゴール・テクノロジーのパワー窒化ガリウム(GaN)技術と知的財産ポートフォリオを買収したことを発表した。モノと人工知能データセンターのアプリケーション分野で、より高い効率とより優れたパフォーマンスを探求します。生成 AI などのテクノロジーがデジタル世界で発展を続ける中、窒化ガリウム (GaN) は、特にデータセンターにおいて、持続可能で効率的な電力管理のための重要なソリューションとなっています。このウェブサイトは、この買収中にタゴール・テクノロジーのエンジニアリングチームがGLOBALFOUNDRIESに加わり、窒化ガリウム技術をさらに開発するという公式発表を引用した。 G
