

樹状図を使用したクラスターの視覚化

一般に、クラスタリングを視覚化するために散布図を使用しますが、一部のクラスタリング アルゴリズムの視覚化には散布図は理想的ではないため、この記事では樹状図 (デンドログラム) を使用してクラスタリング結果を視覚化する方法を紹介します。
ツリーマップ
ツリーマップは、オブジェクト、グループ、または変数間の階層関係を示す図です。樹状図は、同様の特性を持つ観測値のグループを表すノードまたはクラスターで接続された枝で構成されます。枝の高さまたはノード間の距離は、グループがどの程度異なっているか、または類似しているかを示します。つまり、枝が長くなるほど、またはノード間の距離が長くなるほど、グループの類似性は低くなります。枝が短いほど、またはノード間の距離が小さいほど、グループは類似します。
デンドグラムは、複雑なデータ構造を視覚化し、同様の特性を持つデータのサブグループまたはクラスターを識別するのに役立ちます。これらは、生物学、遺伝学、生態学、社会科学、および類似性や相関性に基づいてデータをグループ化できるその他の分野で一般的に使用されます。
背景知識:
「デンドログラム」という言葉は、ギリシャ語の「dendron」(木)と「gramma」(描画)に由来しています。 1901 年、英国の数学者で統計学者のカール ピアソンは、樹形図を使用して、さまざまな植物種間の関係を示しました。彼はこのグラフを「クラスター グラフ」と呼びました。これは樹状図の最初の使用と考えられます。
データの準備
クラスタリングには複数の企業の実際の株価を使用します。簡単にアクセスできるように、データは Alpha Vantage が提供する無料 API を使用して収集されます。 Alpha Vantage は無料 API とプレミアム API の両方を提供しています。API 経由でアクセスするにはキーが必要です。Alpha Vantage の Web サイトを参照してください。
import pandas as pd
import requests
companies={'Apple':'AAPL','Amazon':'AMZN','Facebook':'META','Tesla':'TSLA','Alphabet (Google)':'GOOGL','Shell':'SHEL','Suncor Energy':'SU',
'Exxon Mobil Corp':'XOM','Lululemon':'LULU','Walmart':'WMT','Carters':'CRI','Childrens Place':'PLCE','TJX Companies':'TJX',
'Victorias Secret':'VSCO','MACYs':'M','Wayfair':'W','Dollar Tree':'DLTR','CVS Caremark':'CVS','Walgreen':'WBA','Curaleaf':'CURLF'}テクノロジー、小売、石油・ガス、その他の業界から 20 社が選ばれました。
import time
all_data={}
for key,value in companies.items():
# Replace YOUR_API_KEY with your Alpha Vantage API key
url = f'https://www.alphavantage.co/query?function=TIME_SERIES_DAILY_ADJUSTED&symbol={value}&apikey=<YOUR_API_KEY>&outputsize=full'
response = requests.get(url)
data = response.json()
time.sleep(15)
if 'Time Series (Daily)' in data and data['Time Series (Daily)']:
df = pd.DataFrame.from_dict(data['Time Series (Daily)'], orient='index')
print(f'Received data for {key}')
else:
print("Time series data is empty or not available.")
df.rename(columns = {'1. open':key}, inplace = True)
all_data[key]=df[key]上記のコードは、頻繁にブロックされないように、API 呼び出し間に 15 秒の一時停止を設定します。
# find common dates among all data frames common_dates = None for df_key, df in all_data.items(): if common_dates is None: common_dates = set(df.index) else: common_dates = common_dates.intersection(df.index) common_dates = sorted(list(common_dates)) # create new data frame with common dates as index df_combined = pd.DataFrame(index=common_dates) # reindex each data frame with common dates and concatenate horizontally for df_key, df in all_data.items(): df_combined = pd.concat([df_combined, df.reindex(common_dates)], axis=1)
上記のデータを必要な DF に統合すると、それを直接使用できます
階層型クラスタリング
階層型クラスタリング クラスタリング) は、機械学習とデータ分析で使用されるクラスタリング アルゴリズム。ネストされたクラスターの階層を使用して、類似性に基づいて類似したオブジェクトをクラスターにグループ化します。このアルゴリズムは、単一のオブジェクトから開始してそれらをクラスターにマージする凝集型と、大きなクラスターから開始してそれをより小さなクラスターに再帰的に分割する分割型のいずれかになります。
すべてのクラスタリング手法が階層クラスタリング手法であるわけではなく、樹状図はいくつかのクラスタリング アルゴリズムでのみ使用できることに注意してください。
クラスタリング アルゴリズム scipy モジュールで提供される階層的クラスタリングを使用します。
1. トップダウン クラスタリング
import numpy as np
import scipy.cluster.hierarchy as sch
import matplotlib.pyplot as plt
# Convert correlation matrix to distance matrix
dist_mat = 1 - df_combined.corr()
# Perform top-down clustering
clustering = sch.linkage(dist_mat, method='complete')
cuts = sch.cut_tree(clustering, n_clusters=[3, 4])
# Plot dendrogram
plt.figure(figsize=(10, 5))
sch.dendrogram(clustering, labels=list(df_combined.columns), leaf_rotation=90)
plt.title('Dendrogram of Company Correlations (Top-Down Clustering)')
plt.xlabel('Companies')
plt.ylabel('Distance')
plt.show()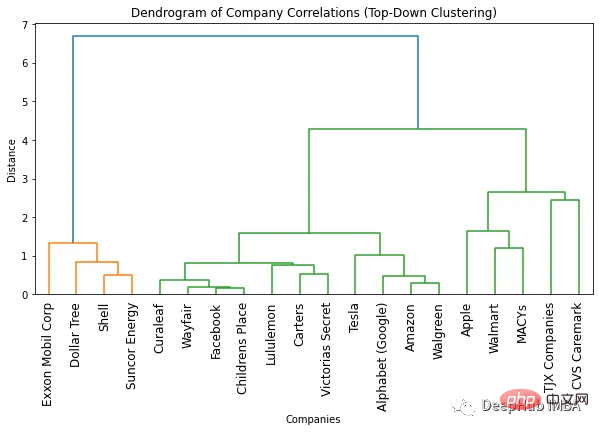
樹状図に基づいて最適なものを決定する方法番号クラスターの数
最適なクラスター数を見つける最も簡単な方法は、結果の樹状図で使用されている色の数を確認することです。最適なクラスターの数は、色の数から 1 つ少ない数です。したがって、上記の樹状図によれば、最適なクラスター数は 2 です。
最適なクラスター数を見つける別の方法は、クラスター間の距離が突然変化するポイントを特定することです。これは「変曲点」または「エルボ点」と呼ばれ、データの変動を最もよく捉えるクラスターの数を決定するために使用できます。上の図では、異なる数のクラスター間の最大距離変化は 1 クラスターと 2 クラスターの間で発生することがわかります。したがって、繰り返しになりますが、最適なクラスター数は 2 です。
樹状図から任意の数のクラスターを取得
樹状図を使用する利点の 1 つは、樹状図を確認することでオブジェクトを任意の数のクラスターにクラスター化できることです。たとえば、2 つのクラスターを見つける必要がある場合は、樹状図の一番上の垂直線を見て、クラスターを決定します。たとえば、この例では、2 つのクラスターが必要な場合、最初のクラスターには 4 社が存在し、2 番目のクラスターには 16 社が存在します。 3 つのクラスターが必要な場合は、2 番目のクラスターをさらに 11 社と 5 社に分割できます。さらに必要な場合は、この例に従ってください。
2. ボトムアップ クラスタリング
import numpy as np
import scipy.cluster.hierarchy as sch
import matplotlib.pyplot as plt
# Convert correlation matrix to distance matrix
dist_mat = 1 - df_combined.corr()
# Perform bottom-up clustering
clustering = sch.linkage(dist_mat, method='ward')
# Plot dendrogram
plt.figure(figsize=(10, 5))
sch.dendrogram(clustering, labels=list(df_combined.columns), leaf_rotation=90)
plt.title('Dendrogram of Company Correlations (Bottom-Up Clustering)')
plt.xlabel('Companies')
plt.ylabel('Distance')
plt.show()
ボトムアップ クラスタリングを行っています 得られた樹状図クラスによる方法は、トップダウン クラスタリングに似ています。最適なクラスター数は依然として 2 です (色数と「変曲点」法に基づく)。しかし、より多くのクラスターが必要な場合は、いくつかの微妙な違いが観察されるでしょう。使用される方法が異なるため、結果にわずかな違いが生じるのは正常です。
概要
デンドログラムは、複雑なデータ構造を視覚化し、同様の特性を持つデータのサブグループまたはクラスターを識別するのに便利なツールです。この記事では、階層的クラスタリング手法を使用して、樹状図を作成する方法と、最適なクラスター数を決定する方法を示します。データ ツリー図は、さまざまな企業間の関係を理解するのに役立ちますが、データの階層構造を理解するために他のさまざまな分野でも使用できます。
以上が樹状図を使用したクラスターの視覚化の詳細内容です。詳細については、PHP 中国語 Web サイトの他の関連記事を参照してください。

ホットAIツール

Undresser.AI Undress
リアルなヌード写真を作成する AI 搭載アプリ

AI Clothes Remover
写真から衣服を削除するオンライン AI ツール。

Undress AI Tool
脱衣画像を無料で

Clothoff.io
AI衣類リムーバー

AI Hentai Generator
AIヘンタイを無料で生成します。

人気の記事
ホットツール

メモ帳++7.3.1
使いやすく無料のコードエディター

SublimeText3 中国語版
中国語版、とても使いやすい

ゼンドスタジオ 13.0.1
強力な PHP 統合開発環境

ドリームウィーバー CS6
ビジュアル Web 開発ツール

SublimeText3 Mac版
神レベルのコード編集ソフト(SublimeText3)
ホットトピック
 7569
7569
 15
1386
52
87
11
28
107
15
1386
52
87
11
28
107

 おすすめのAI支援プログラミングツール4選
Apr 22, 2024 pm 05:34 PM
おすすめのAI支援プログラミングツール4選
Apr 22, 2024 pm 05:34 PM
この AI 支援プログラミング ツールは、急速な AI 開発のこの段階において、多数の有用な AI 支援プログラミング ツールを発掘しました。 AI 支援プログラミング ツールは、開発効率を向上させ、コードの品質を向上させ、バグ率を減らすことができます。これらは、現代のソフトウェア開発プロセスにおける重要なアシスタントです。今日は Dayao が 4 つの AI 支援プログラミング ツールを紹介します (すべて C# 言語をサポートしています)。皆さんのお役に立てれば幸いです。 https://github.com/YSGStudyHards/DotNetGuide1.GitHubCopilotGitHubCopilot は、より少ない労力でより迅速にコードを作成できるようにする AI コーディング アシスタントであり、問題解決とコラボレーションにより集中できるようになります。ギット
 どのAIプログラマーが一番優れているでしょうか? Devin、Tongyi Lingma、SWE エージェントの可能性を探る
Apr 07, 2024 am 09:10 AM
どのAIプログラマーが一番優れているでしょうか? Devin、Tongyi Lingma、SWE エージェントの可能性を探る
Apr 07, 2024 am 09:10 AM
世界初の AI プログラマー Devin の誕生から 1 か月も経たない 2022 年 3 月 3 日、プリンストン大学の NLP チームはオープンソース AI プログラマー SWE-agent を開発しました。 GPT-4 モデルを利用して、GitHub リポジトリの問題を自動的に解決します。 SWE ベンチ テスト セットにおける SWE エージェントのパフォーマンスは Devin と同様で、平均 93 秒かかり、問題の 12.29% を解決しました。専用端末と対話することで、SWE エージェントはファイルの内容を開いて検索したり、自動構文チェックを使用したり、特定の行を編集したり、テストを作成して実行したりできます。 (注: 上記の内容は元の内容を若干調整したものですが、原文の重要な情報は保持されており、指定された文字数制限を超えていません。) SWE-A
 最も人気のある 5 つの Go 言語ライブラリの概要: 開発に不可欠なツール
Feb 22, 2024 pm 02:33 PM
最も人気のある 5 つの Go 言語ライブラリの概要: 開発に不可欠なツール
Feb 22, 2024 pm 02:33 PM
最も人気のある 5 つの Go 言語ライブラリの概要: 特定のコード例が必要な、開発に不可欠なツール Go 言語は、その誕生以来、広く注目され、応用されてきました。新しい効率的で簡潔なプログラミング言語としての Go の急速な開発は、豊富なオープンソース ライブラリのサポートと切り離すことができません。この記事では、Go 言語ライブラリの中で最も人気のある 5 つを紹介します. これらのライブラリは Go 開発において重要な役割を果たし、開発者に強力な機能と便利な開発エクスペリエンスを提供します。同時に、これらのライブラリの用途と機能をよりよく理解するために、具体的なコード例を示して説明します。
 Go 言語を使用してモバイル アプリケーションを開発する方法を学ぶ
Mar 28, 2024 pm 10:00 PM
Go 言語を使用してモバイル アプリケーションを開発する方法を学ぶ
Mar 28, 2024 pm 10:00 PM
Go 言語開発モバイル アプリケーション チュートリアル モバイル アプリケーション市場が活況を続ける中、ますます多くの開発者が Go 言語を使用してモバイル アプリケーションを開発する方法を検討し始めています。シンプルで効率的なプログラミング言語として、Go 言語はモバイル アプリケーション開発でも大きな可能性を示しています。この記事では、Go 言語を使用してモバイル アプリケーションを開発する方法を詳しく紹介し、読者がすぐに始めて独自のモバイル アプリケーションの開発を開始できるように、具体的なコード例を添付します。 1. 準備 始める前に、開発環境とツールを準備する必要があります。頭
 Kafkaを探索するための可視化ツール5選
Feb 01, 2024 am 08:03 AM
Kafkaを探索するための可視化ツール5選
Feb 01, 2024 am 08:03 AM
Kafka 視覚化ツールの 5 つのオプション ApacheKafka は、大量のリアルタイム データを処理できる分散ストリーム処理プラットフォームです。これは、リアルタイム データ パイプライン、メッセージ キュー、イベント駆動型アプリケーションの構築に広く使用されています。 Kafka の視覚化ツールは、ユーザーが Kafka クラスターを監視および管理し、Kafka データ フローをより深く理解するのに役立ちます。以下は、5 つの人気のある Kafka 視覚化ツールの紹介です。 ConfluentControlCenterConfluent
 Android 開発に最適な Linux ディストリビューションはどれですか?
Mar 14, 2024 pm 12:30 PM
Android 開発に最適な Linux ディストリビューションはどれですか?
Mar 14, 2024 pm 12:30 PM
Android 開発は多忙で刺激的な仕事であり、開発に適した Linux ディストリビューションを選択することが特に重要です。数多くある Linux ディストリビューションの中で、Android 開発に最適なのはどれでしょうか?この記事では、この問題をいくつかの側面から検討し、具体的なコード例を示します。まず、現在人気のある Linux ディストリビューション (Ubuntu、Fedora、Debian、CentOS など) をいくつか見てみましょう。これらにはそれぞれ独自の利点と特徴があります。
 Go 言語のフロントエンド テクノロジーの探求: フロントエンド開発の新しいビジョン
Mar 28, 2024 pm 01:06 PM
Go 言語のフロントエンド テクノロジーの探求: フロントエンド開発の新しいビジョン
Mar 28, 2024 pm 01:06 PM
Go 言語は、高速で効率的なプログラミング言語として、バックエンド開発の分野で広く普及しています。ただし、Go 言語をフロントエンド開発と結びつける人はほとんどいません。実際、フロントエンド開発に Go 言語を使用すると、効率が向上するだけでなく、開発者に新たな視野をもたらすことができます。この記事では、フロントエンド開発に Go 言語を使用する可能性を探り、読者がこの分野をよりよく理解できるように具体的なコード例を示します。従来のフロントエンド開発では、ユーザー インターフェイスの構築に JavaScript、HTML、CSS がよく使用されます。
 VSCode について: このツールは何に使用されますか?
Mar 25, 2024 pm 03:06 PM
VSCode について: このツールは何に使用されますか?
Mar 25, 2024 pm 03:06 PM
「VSCode について: このツールは何に使用されますか?」 》初心者でも経験豊富な開発者でも、プログラマーとしてはコード編集ツールを使わずにはいられません。数ある編集ツールの中でも、Visual Studio Code (略して VSCode) は、オープンソースで軽量かつ強力なコード エディターとして開発者の間で非常に人気があります。では、VSCode は正確に何に使用されるのでしょうか?この記事では、VSCode の機能と使用法を詳しく説明し、読者に役立つ具体的なコード例を提供します。
