

Windows 11で音声認識を無効にする方法

Microsoft の最新オペレーティング システムである Windows 11 も、Windows 10 と同様の音声認識オプションを提供します。
音声認識はオフラインでもインターネット接続経由でも使用できることに注目してください。音声認識を使用すると、音声を使用して特定のアプリケーションを制御したり、Word 文書にテキストを書き込むことができます。
Microsoft の音声認識サービスでは、すべての機能が提供されるわけではありません。興味のあるユーザーは、PC にダウンロードして高度な機能を楽しむことができるいくつかの最高の音声認識アプリに関するチュートリアルをチェックしてください。
この機能の精度を向上させるにはトレーニングが必要であり、多くの人はそのパフォーマンスが満足のいくものではないことに注意してください。このため、これを無効にすることをお勧めします。
Windows 11 で音声認識を無効にする方法については、このチュートリアルに従ってください。
最も一般的な音声コマンドは何ですか?
理由に関係なく、Windows 11 PC で音声認識を無効にする前に、このアクセシビリティ機能がユーザー エクスペリエンスを向上させるように設計されていることを知っておく必要があります。
PC で音声入力ツールを使用する方法をお探しの場合は、Windows 11 で音声入力ツールを使用する方法に関する専用のチュートリアルをご覧ください。
マイクへのアクセスを許可した後、以下にリストされているいくつかの一般的な音声コマンドを参照し、それらを使用して PC のハンズフリー使用を容易にすることができます。
- [検索を開く]: Windows を押すと表示されます S
- 項目を選択します: [コンピューター] をクリックして、ファイル名 ([ファイル] の代わりに) をクリックしますと表示されます。名前はファイルの正確な名前を示します)
- Scroll: 上にスクロール、下にスクロール、左にスクロール、右にスクロールすることを示します
- 該当するコマンドのリストを表示# ##: 何と言えばいい?
- 新しい行を挿入: 新しい行を言う
- 特定の単語の前にカーソルを置きます: 単語に移動 (代わりに特定の単語を読みます)単語)
- 次の単語の前にスペースを挿入しないでください: スペースを入れないでください
- 単語の最初の文字を大文字にしてください: 大文字で答えてくださいword (word の代わりに 特定の単語を言います)
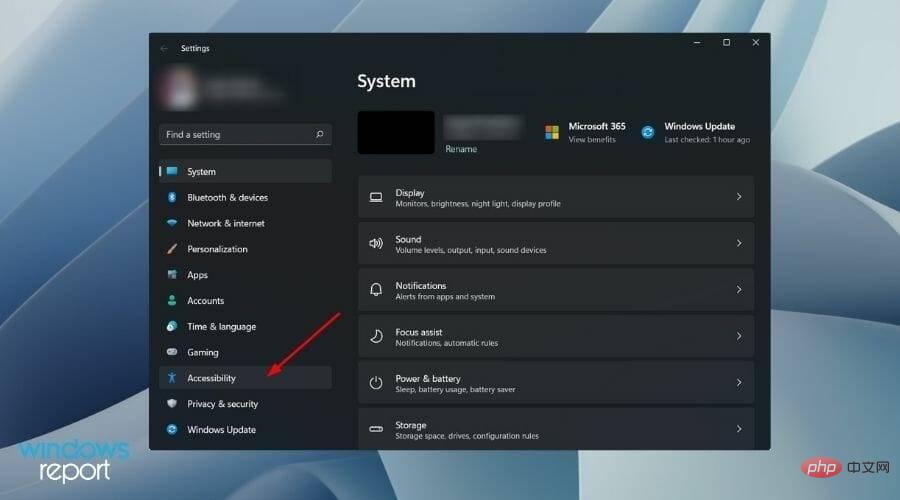
- [スタート]メニュー ボタンを右クリックし、[設定]を選択します。 左ペインから
- アクセシビリティを選択します。
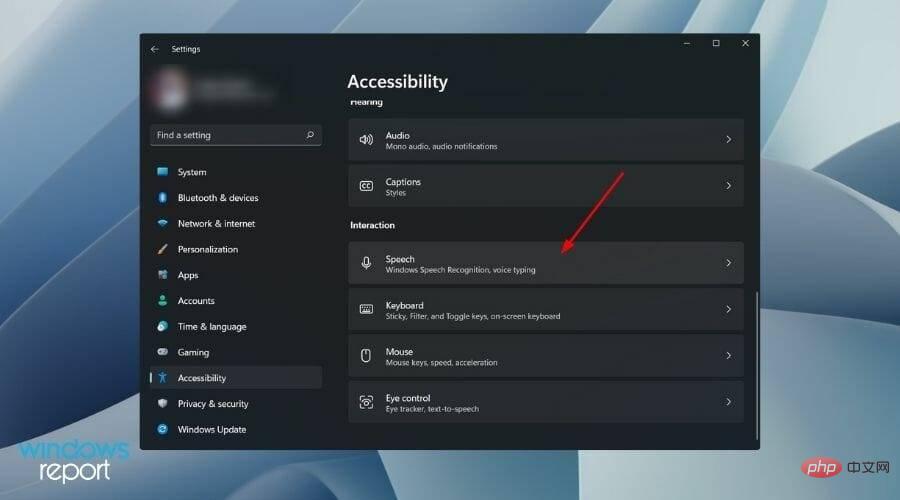
 次に、右側から下にスクロールし、[インタラクション] セクションで [
次に、右側から下にスクロールし、[インタラクション] セクションで [ - Voice] をクリックします。 [
- Windows 音声認識] オプションの横にあるスイッチをオフにするだけです。
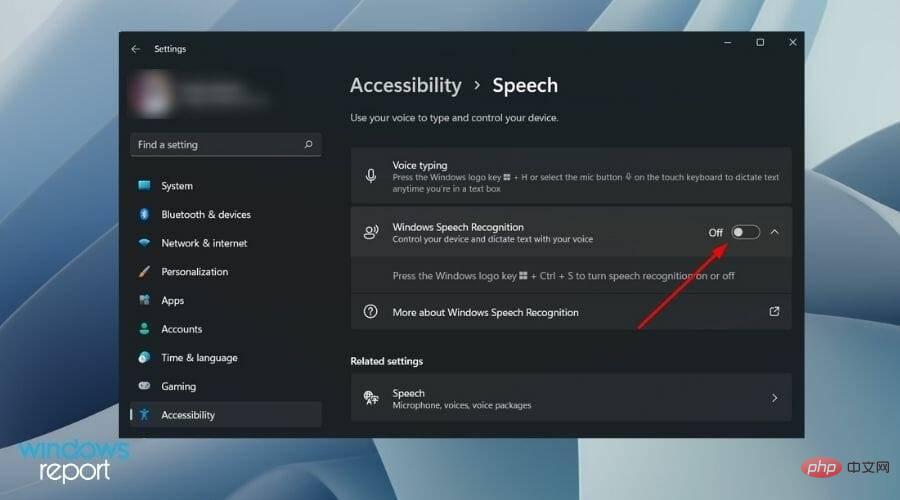
Windows Ctrl S
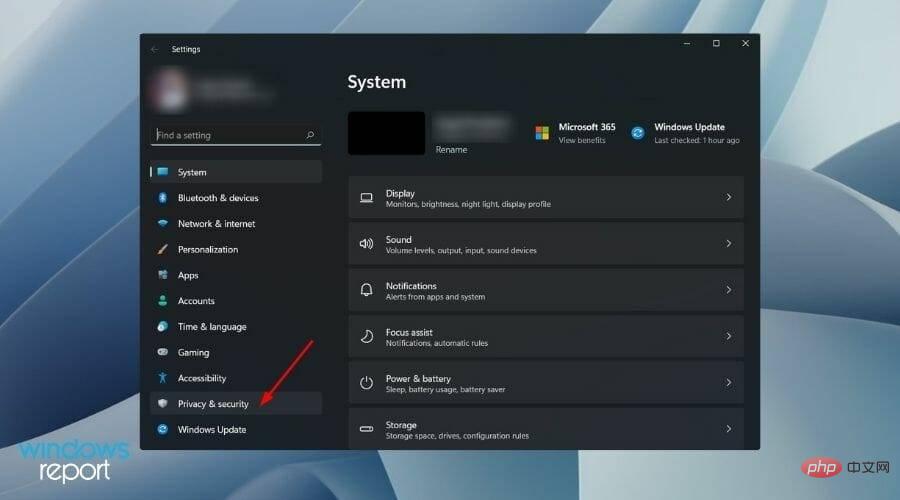
2. オンライン音声を無効にする
- スタートメニュー ボタンを右クリックし、[設定]を選択します。
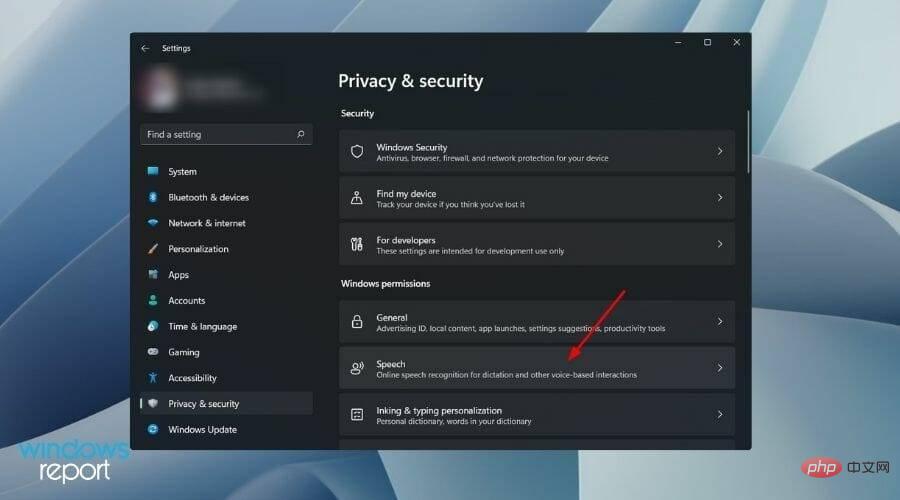
- 左ペインからプライバシーとセキュリティを選択する必要があります。
- [Windows アクセス許可] セクションで、Speech をクリックします。
-
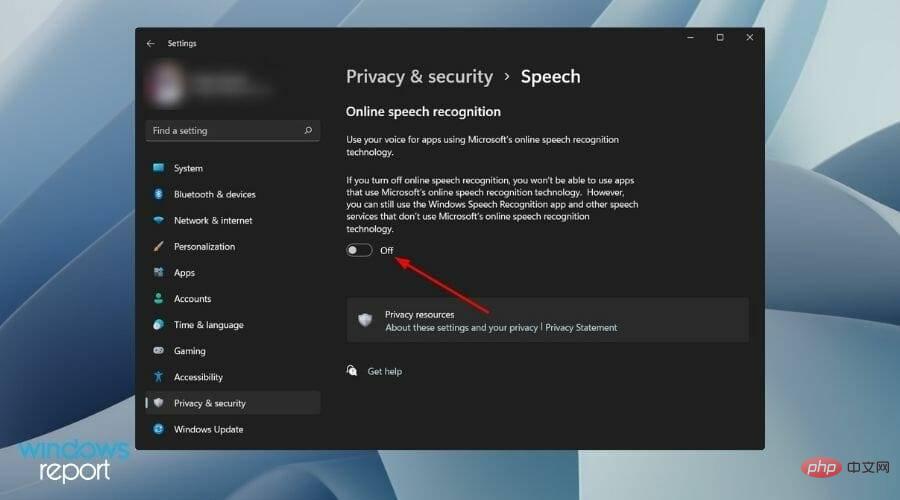
オンライン音声認識オプション スイッチを閉じます。
さらに、さらに一歩進んで、レジストリ設定を使用してオンライン音声認識サービスを永久に無効にすることもできます。
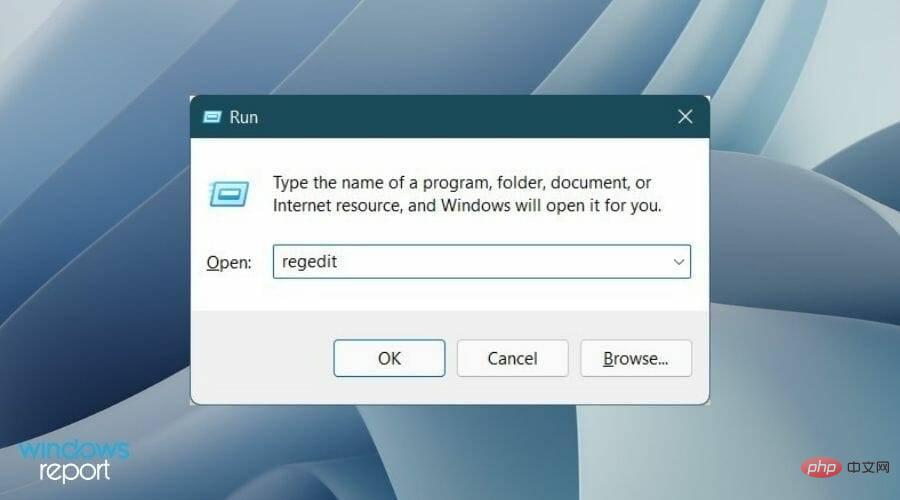
レジストリ エディターの調整は危険ではありませんが、間違って行うと PC 上の一部の重要なサービスが停止する可能性があることに注意してください。- ボタンを同時に押すと、「実行」 ダイアログ ボックスが開きます。 Windows R
- 「regedit」と入力し、Enter を押します。
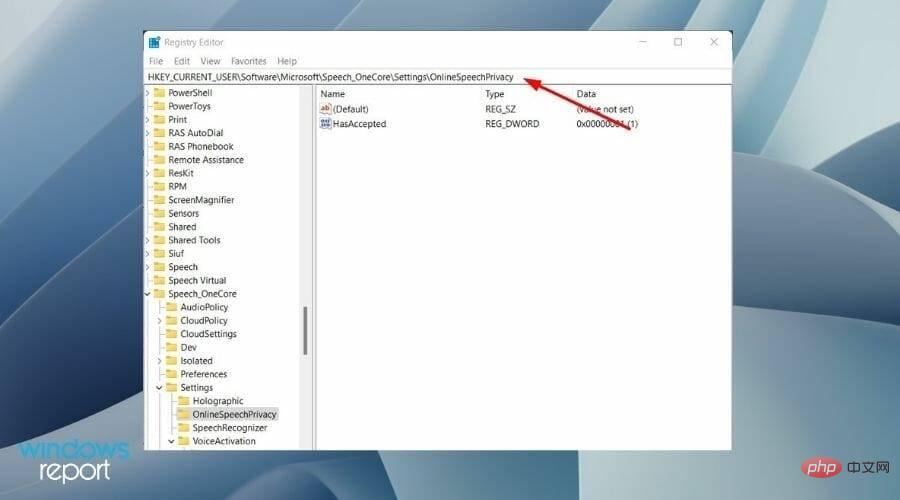
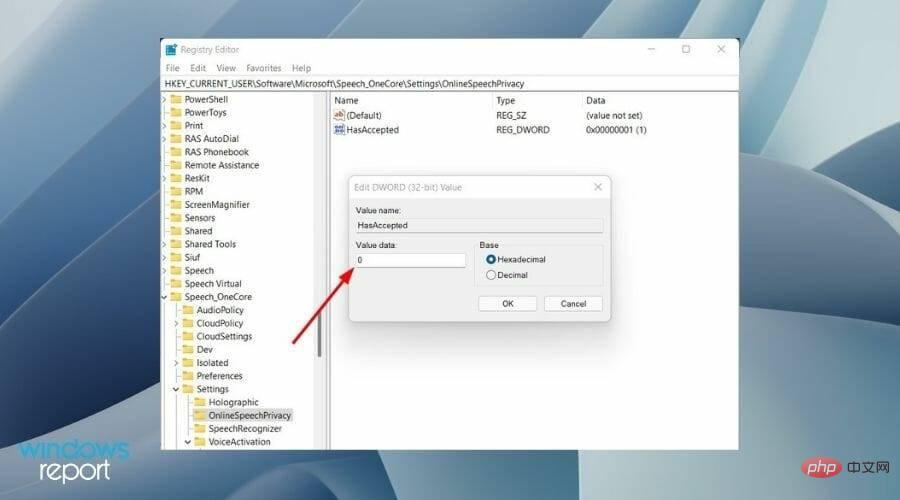
- レジストリ エディターのアドレス バーに次のパスを貼り付け、Enter を押します。
HKEY_CURRENT_USER\Software\Microsoft\Speech_OneCore\Settings\OnlineSpeechPrivacy
- 右側の [HasAccepted] をダブルクリックし、値 を ## に変更します。 #0 。
- OK を押して、レジストリ エディタを閉じます。 PC を再起動すると、オンライン音声認識サービスが完全に無効になります。
- Windows 音声認識を有効に戻すには、
以上がWindows 11で音声認識を無効にする方法の詳細内容です。詳細については、PHP 中国語 Web サイトの他の関連記事を参照してください。

ホットAIツール

Undresser.AI Undress
リアルなヌード写真を作成する AI 搭載アプリ

AI Clothes Remover
写真から衣服を削除するオンライン AI ツール。

Undress AI Tool
脱衣画像を無料で

Clothoff.io
AI衣類リムーバー

AI Hentai Generator
AIヘンタイを無料で生成します。

人気の記事
ホットツール

メモ帳++7.3.1
使いやすく無料のコードエディター

SublimeText3 中国語版
中国語版、とても使いやすい

ゼンドスタジオ 13.0.1
強力な PHP 統合開発環境

ドリームウィーバー CS6
ビジュアル Web 開発ツール

SublimeText3 Mac版
神レベルのコード編集ソフト(SublimeText3)
ホットトピック
 7456
7456
 15
1376
52
77
11
17
10
15
1376
52
77
11
17
10

 Windows 11で音声認識を無効にする方法
May 01, 2023 am 09:13 AM
Windows 11で音声認識を無効にする方法
May 01, 2023 am 09:13 AM
<p>Microsoft の最新オペレーティング システムである Windows 11 も、Windows 10 と同様の音声認識オプションを提供します。 </p><p>音声認識はオフラインでも、インターネット接続経由でも使用できることに注目してください。音声認識を使用すると、音声を使用して特定のアプリケーションを制御したり、Word 文書にテキストを書き込むことができます。 </p><p>Microsoft の音声認識サービスは、完全な機能セットを提供するわけではありません。興味のあるユーザーは、当社の最高の音声認識アプリをいくつかチェックしてください。
 Windows 11 でテキスト読み上げおよび音声認識テクノロジを使用するにはどうすればよいですか?
Apr 24, 2023 pm 03:28 PM
Windows 11 でテキスト読み上げおよび音声認識テクノロジを使用するにはどうすればよいですか?
Apr 24, 2023 pm 03:28 PM
Windows 10 と同様、Windows 11 コンピューターにはテキスト読み上げ機能があります。 TTS としても知られるテキスト読み上げ機能を使用すると、自分の声で書くことができます。マイクに向かって話すと、コンピュータはテキスト認識と音声合成を組み合わせて画面上にテキストを書き込みます。これは、話しながら意識の流れを実行できるため、読み書きが難しい場合に最適なツールです。この便利なツールを使用すると、ライターの障害を克服できます。 TTS は、ビデオのナレーション スクリプトを生成したり、特定の単語の発音を確認したり、Microsoft ナレーターを通じてテキストを読み上げたりする場合にも役立ちます。さらに、このソフトウェアは適切な句読点を追加することに優れているため、適切な文法も学ぶことができます。声
 動画切り出しで音声を自動認識して字幕を生成する方法 字幕を自動生成する方法の紹介
Mar 14, 2024 pm 08:10 PM
動画切り出しで音声を自動認識して字幕を生成する方法 字幕を自動生成する方法の紹介
Mar 14, 2024 pm 08:10 PM
このプラットフォームに音声字幕を生成する機能を実装するにはどうすればよいですか? ビデオを作成するとき、質感を高めるため、またはストーリーをナレーションするときに、誰もが情報をよりよく理解できるように字幕を追加する必要があります。上のビデオの一部。表現にも役割を果たしますが、多くのユーザーは自動音声認識と字幕生成にあまり慣れていません。どこにいても、さまざまな面でより良い選択を簡単に行うことができます。機能的なスキルなどをゆっくり理解する必要があります。急いでエディターで確認してください。お見逃しなく。
 WebSocket と JavaScript を使用してオンライン音声認識システムを実装する方法
Dec 17, 2023 pm 02:54 PM
WebSocket と JavaScript を使用してオンライン音声認識システムを実装する方法
Dec 17, 2023 pm 02:54 PM
WebSocket と JavaScript を使用してオンライン音声認識システムを実装する方法 はじめに: 技術の継続的な発展により、音声認識技術は人工知能の分野の重要な部分になりました。 WebSocket と JavaScript をベースとしたオンライン音声認識システムは、低遅延、リアルタイム、クロスプラットフォームという特徴があり、広く使用されるソリューションとなっています。この記事では、WebSocket と JavaScript を使用してオンライン音声認識システムを実装する方法を紹介します。
 WIN10システムで音声認識をオフにする詳細な方法
Mar 27, 2024 pm 02:36 PM
WIN10システムで音声認識をオフにする詳細な方法
Mar 27, 2024 pm 02:36 PM
1. コントロール パネルに入り、[音声認識] オプションを見つけてオンにします。 2. 音声認識ページが表示されたら、[音声詳細オプション]を選択します。 3. 最後に、音声のプロパティ画面のユーザー設定欄にある「起動時に音声認識を実行する」のチェックを外します。
 音声認識における音声品質の問題
Oct 08, 2023 am 08:28 AM
音声認識における音声品質の問題
Oct 08, 2023 am 08:28 AM
音声音声認識における音質の問題には、特定のコード例が必要ですが、近年、人工知能技術の急速な発展に伴い、音声音声認識(Automatic Speech Recognition、ASR)が広く利用され、研究されています。ただし、実際のアプリケーションでは、ASR アルゴリズムの精度とパフォーマンスに直接影響するオーディオ品質の問題に直面することがよくあります。この記事では、音声認識における音質の問題に焦点を当て、具体的なコード例を示します。音声通話のオーディオ品質
 音声性別認識における話者変動の問題
Oct 08, 2023 pm 02:22 PM
音声性別認識における話者変動の問題
Oct 08, 2023 pm 02:22 PM
音声性別認識における話者変動の問題には、特定のコード例が必要です 音声技術の急速な発展に伴い、音声性別認識はますます重要な分野になっています。電話カスタマー サービス、音声アシスタントなど、多くのアプリケーション シナリオで広く使用されています。ただし、音声の性別認識では、話者の多様性という課題に遭遇することがよくあります。話者のバリエーションとは、さまざまな個人の声の音声特性の違いを指します。なぜなら、個人の声の特性は、性別、年齢、声などのさまざまな要因の影響を受けるからです。
 OpenAI の Whisper モデルを使用した音声認識
Apr 12, 2023 pm 05:28 PM
OpenAI の Whisper モデルを使用した音声認識
Apr 12, 2023 pm 05:28 PM
音声認識は、コンピューターが人間の音声を理解してテキストに変換できるようにする人工知能の分野です。この技術はAlexaなどのデバイスやさまざまなチャットボットアプリケーションで使用されています。私たちが行う最も一般的なことは音声文字起こしであり、文字起こしや字幕に変換できます。 wav2vec2、Conformer、Hubert などの最先端モデルの最近の開発により、音声認識の分野は大幅に進歩しました。これらのモデルは、データに手動でラベルを付けることなく生の音声から学習する技術を採用しており、ラベルのない音声の大規模なデータセットを効率的に使用できます。また、学術的な監督データセットで使用されるよりもはるかに多い、最大 1,000,000 時間のトレーニング データを使用できるように拡張されました。