
 テクノロジー周辺機器
AI
写真と音声が数秒でビデオに変わります。西安交通大学のオープンソース SadTalker: 超自然的な頭と唇の動き、中国語と英語のバイリンガル、歌うこともできる
テクノロジー周辺機器
AI
写真と音声が数秒でビデオに変わります。西安交通大学のオープンソース SadTalker: 超自然的な頭と唇の動き、中国語と英語のバイリンガル、歌うこともできる
写真と音声が数秒でビデオに変わります。西安交通大学のオープンソース SadTalker: 超自然的な頭と唇の動き、中国語と英語のバイリンガル、歌うこともできる

デジタル ピープルの概念の普及と生成技術の継続的な発展により、音声入力に応じて写真内のキャラクターを動かすことはもはや問題ではなくなりました。
しかし、「顔画像と音声を組み合わせてしゃべるアバター動画を生成する」には、 不自然な頭の動きや歪んだ表情など、まだまだ多くの問題点があります。ビデオと写真の中の人物の顔が違いすぎる などの問題があります。
最近、西安交通大学などの研究者らは、3 次元スポーツ場で学習して 3DMM の 3D 運動係数を生成する SadTalker モデル を提案しました。 (頭) をオーディオから抽出し、ポーズ、表情)、新しい 3D フェイシャル レンダラーを使用して頭の動きを生成します。

# 論文リンク: https://arxiv.org/pdf/2211.12194.pdf
プロジェクトのホームページ: https://sadtalker.github.io/
#音声は 英語、中国語、歌 、ビデオのキャラクターも 点滅頻度 を制御できます!
リアルな動き係数を学習するために、研究者らは音声とさまざまな種類の動き係数の間の関係を個別に明示的にモデル化しました。抽出された係数と 3D レンダリングされた顔を通じて、音声から正確な顔の表情を学習します。条件付き VAE を通じて PoseVAE を設計し、さまざまなスタイルの頭の動きを合成します。
最後に、生成された 3 次元モーション係数が顔レンダリングの教師なし 3 次元キーポイント空間にマッピングされ、最終的なビデオが合成されます。
最後に、この方法がモーション同期とビデオ品質の点で最先端のパフォーマンスを達成することが実験で実証されました。
現在のstable-diffusion-webuiプラグインもリリースされました。
Photo Audio=Videoデジタルヒューマン制作やビデオ会議など多くの分野で「音声を使って静止画をアニメーション化する」技術が必要ですが、現状ではまだ非常にやりがいのある仕事です。
これまでの研究では、唇の動きと音声の関係が最も強いため、「唇の動き」を生成することに主に焦点を当ててきました。他の研究では、他の関連する動き (頭の動きなど) も生成しようとしています。 ).顔のポーズ)、しかし、結果として得られるビデオの品質は依然として非常に不自然であり、好みのポーズ、ぼかし、アイデンティティの修正、および顔の歪みによって制限されます。
もう 1 つの一般的な手法は、潜在ベースのフェイシャル アニメーションであり、主に会話型フェイシャル アニメーションの特定カテゴリのモーションに焦点を当てています。モデルには、顔上のさまざまな位置のモーション軌跡を個別に学習するために使用できる高度に分離された表現が含まれていますが、不正確な表現や不自然なモーション シーケンスが依然として生成されます。
上記の観察に基づいて、研究者らは、暗黙的な 3 次元係数変調による様式化されたオーディオ駆動型ビデオ生成システムである SadTalker (Stylized Audio-Driven Talking-head) を提案しました。
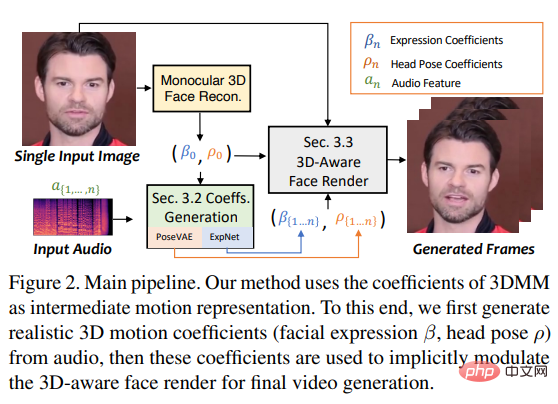
# この目標を達成するために、研究者らは 3DMM の運動係数を中間表現として扱い、タスクを次のように分割しました。 2 つの主要な部分 (表情とポーズ) は、オーディオからより現実的な動作係数 (頭のポーズ、唇の動き、まばたきなど) を生成し、各動作を個別に学習して不確実性を軽減することを目的としています。
最後に、face-vid2vid からインスピレーションを得た 3D 対応の顔レンダリングを通じてソース イメージを駆動します。
3D 顔
現実のビデオは 3 次元環境で撮影されるため、生成されるビデオの信頼性を向上させるには 3 次元情報が重要です。ただし、以前の作品では 1 つの平面しか考慮されていなかったため、3 次元空間はほとんど考慮されていませんでした。オリジナルの 3 次元まばらな画像を取得することは難しく、高品質の顔レンダラーを設計することは困難です。
最近の単一画像深度 3D 再構成手法にヒントを得て、研究者らは、予測された 3 次元変形モデル (3DMM) の空間を中間表現として使用しました。
3DMM では、3 次元の顔の形状 S は次のように分離できます。
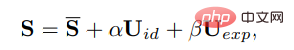
ここで、Sは 3 次元の人間の顔の平均形状、Uid と Uexp は LSFM モーファブル モデルのアイデンティティと表現の正規化です。係数 α (80 次元) と β (64 次元) はキャラクターのアイデンティティと表現を表しますそれぞれ;姿勢の違いを維持するために、係数 r と t はそれぞれ頭の回転と平行移動を表します;単位に依存しない係数生成を達成するために、動きのパラメータのみが {β, r, t} としてモデル化されます。
つまり、頭のポーズ ρ = [r, t] と表現係数 β は、駆動されるオーディオから個別に学習され、これらの動き係数は、顔のレンダリングを暗黙的に調整するために使用されます。最終的なビデオ合成。
オーディオによるモーション スパース生成
3 次元モーション係数には、頭部のポーズと表情が含まれます。ポーズはグローバルな動きですが、表情は比較的ローカルであるため、頭の姿勢と音声の関係は比較的弱いのに対し、唇の動きは音声と高い相関があるため、すべての係数を完全に学習するとネットワークに大きな不確実性が生じます。
そこで、SadTalker は次の PoseVAE と ExpNet を使用して、頭の姿勢と表情の動きをそれぞれ生成します。
ExpNet
「音声から正確な表現係数を生成する」ことができる一般的なモデルを学習することは非常に役立ちます。 2 つの理由で難しい:
1) 音声から表現への変換は、さまざまな文字に対する 1 対 1 のマッピング タスクではありません。
2) 表現係数には音声関連のアクションが含まれており、予測の精度に影響します。
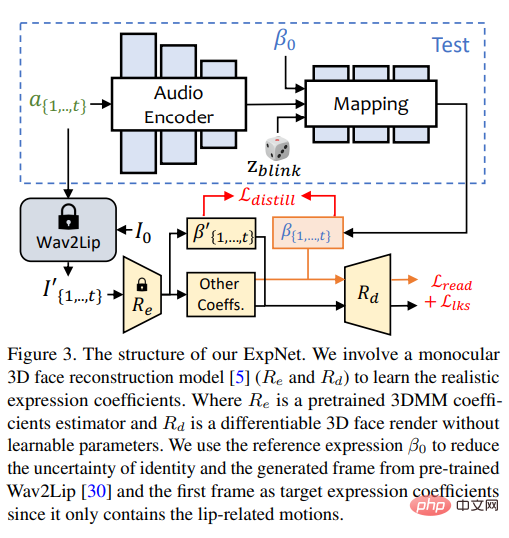
ExpNet の設計目標は、これらの不確実性を軽減することです。文字の同一性の問題に関しては、研究者は式を次の式の係数によって移動させました。特定の人物に関連付けられた最初のフレーム。
自然な会話における他の顔コンポーネントのモーションの重みを軽減するために、Wav2Lip と Wav2Lip の事前トレーニング済みネットワークを通じて、唇のモーション係数 (唇のモーションのみ) のみが係数ターゲットとして使用されます。ディープ3D再構成。
その他の微妙な顔の動き (まばたきなど) などについては、レンダリングされたイメージ上の追加のランドマークの損失に導入される可能性があります。
PoseVAE
研究者らは、会話ビデオで実際のアイデンティティ関連の画像を学習するための VAE ベースのモデルを設計しました (アイデンティティを意識した)様式化された頭の動き。
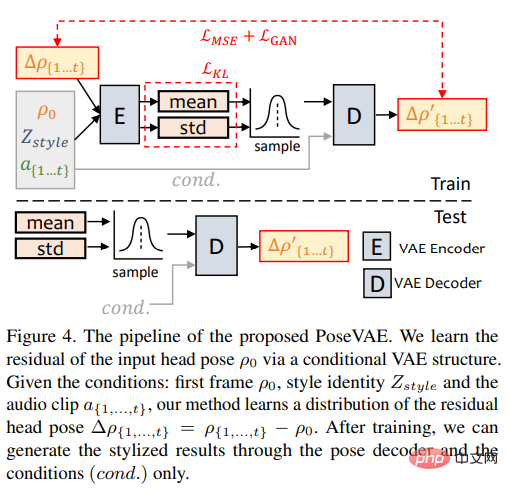
#トレーニングでは、ポーズ VAE は、エンコーダー/デコーダー ベースの構造を使用して、固定 n フレームでトレーニングされます。エンコーダとデコーダは両方とも 2 層 MLP であり、入力にはガウス分布に埋め込まれた連続 t フレーム ヘッド ポーズが含まれています。デコーダでは、ネットワークがサンプリング分布から t フレーム ポーズを生成することを学習します。
PoseVAE はポーズを直接生成するのではなく、最初のフレームの条件付きポーズの残差を学習することに注意してください。これにより、このメソッドはテストの最初のフレームの条件下でより長い長さを生成することもできます。 、より安定した継続的なヘッドの動き。
CVAE によれば、対応するオーディオ機能とスタイル識別子も、リズム認識とアイデンティティ スタイルの条件として PoseVAE に追加されます。
モデルは、KL ダイバージェンスを使用して生成されたモーションの分布を測定し、平均二乗損失と敵対的損失を使用して生成の品質を保証します。
3D 対応の顔のレンダリング
リアルな 3 次元運動係数を生成した後、研究者は慎重に設計された最終ビデオをレンダリングする 3D 画像アニメーター。
最近提案された画像アニメーション手法 face-vid2vid は、単一の画像から 3D 情報を暗黙的に学習できますが、この手法にはアクションを駆動する信号として実際のビデオが必要であり、この論文では顔のレンダリングを行っています。で提案されているものは、3DMM 係数によって駆動できます。
研究者らは、明示的な 3DMM モーション係数 (頭のポーズと表情) と暗黙的な教師なし 3D キーポイントの間の関係を学習するために、mappingNet を提案しました。
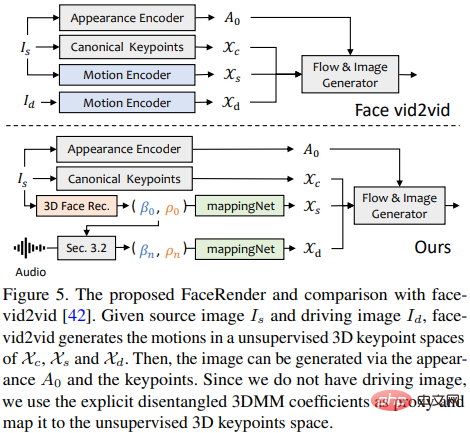
#mappingNet は、複数の 1 次元畳み込み層を通じて構築され、PIRenderer と同様に平滑化に時間ウィンドウの時間係数を使用します。違いは次のとおりです。研究者らは、PIRenderer の顔に合わせたモーション係数がオーディオ駆動ビデオ生成における動きの自然さに大きく影響することを発見しました。そのため、mappingNet は表情と頭のポーズにのみ係数を使用します。
トレーニング フェーズは 2 つのステップで構成されます: 最初に元の論文に従い、自己教師付きの方法で face-vid2vid をトレーニングします。次に、外観エンコーダー、標準キーポイント推定器、および画像ジェネレーターをフリーズします。すべてのパラメータ、mappingNet は、微調整のために再構築された方法でグラウンド トゥルース ビデオの 3DMM 係数に基づいてトレーニングされます。
教師なしキーポイントの領域で教師ありトレーニングに L1 損失を使用し、元の実装に従って最終的に生成されたビデオを提供します。
実験結果この方法の優位性を証明するために、研究者らは、Frechet Inception Distance (FID) および Cumulative Probability Blur Detection (CPBD) 指標を選択しました。画像の評価品質。FID は主に生成されたフレームの信頼性を評価し、CPBD は生成されたフレームの鮮明さを評価します。
アイデンティティ保持の程度を評価するには、ArcFace を使用して画像のアイデンティティ埋め込みを抽出し、次にソース画像と画像の間のアイデンティティ埋め込みのコサイン類似度 (CSIM) を抽出します。生成されたフレームが計算されます。
唇の同期と唇の形状を評価するために、研究者らは、距離スコア (LSE-D) と信頼スコア (LSE-C) を含む、Wav2Lip との唇の形状の知覚的な違いを評価しました。
頭部動作の評価では、生成されたフレームから Hopenet によって抽出された頭部動作特徴埋め込みの標準偏差を使用して、生成された頭部動作の多様性が計算され、Beat Align が計算されます。音声と生成された頭の動きの一貫性を評価します。
比較方法では、MakeItTalk、Audio2Head、音声から表情への生成方法 (Wav2Lip、PC-AVS) など、いくつかの最先端のトーキング アバター生成方法が選択されました。 public Checkpoint の重みが評価されます。
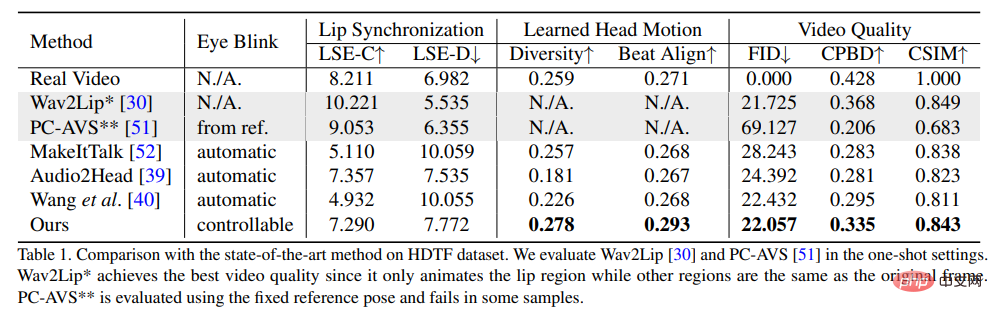
実験結果から、この記事で提案されている方法により、全体的なビデオ品質とヘッダーが向上していることがわかります。頭部ポーズの多様性を実現しながら、口唇同期メトリクスの点で他の完全に話す頭部生成方法と同等のパフォーマンスを示します。
研究者らは、これらのリップシンク指標は音声に敏感すぎるため、不自然な唇の動きがより良いスコアを獲得する可能性があると考えていますが、記事で提案されている方法は実際のビデオと同様のスコアを達成しました。もこの方法の利点を示します。

さまざまな方法で生成された視覚的な結果からわかるように、この方法の視覚的な品質は元のターゲットビデオと非常に似ています。と予想と違いました 姿勢もよく似ています。
他の方法と比較すると、Wav2Lip はぼやけた半顔を生成します。PC-AVS と Audio2Head はソース画像のアイデンティティを保持することが困難です。Audio2Head は正面から話している顔しか生成できません。MakeItTalk と Audio2Head は、 2D 歪みにより、歪んだ顔ビデオが生成されます。
以上が写真と音声が数秒でビデオに変わります。西安交通大学のオープンソース SadTalker: 超自然的な頭と唇の動き、中国語と英語のバイリンガル、歌うこともできるの詳細内容です。詳細については、PHP 中国語 Web サイトの他の関連記事を参照してください。

ホットAIツール

Undresser.AI Undress
リアルなヌード写真を作成する AI 搭載アプリ

AI Clothes Remover
写真から衣服を削除するオンライン AI ツール。

Undress AI Tool
脱衣画像を無料で

Clothoff.io
AI衣類リムーバー

Video Face Swap
完全無料の AI 顔交換ツールを使用して、あらゆるビデオの顔を簡単に交換できます。

人気の記事
ホットツール

メモ帳++7.3.1
使いやすく無料のコードエディター

SublimeText3 中国語版
中国語版、とても使いやすい

ゼンドスタジオ 13.0.1
強力な PHP 統合開発環境

ドリームウィーバー CS6
ビジュアル Web 開発ツール

SublimeText3 Mac版
神レベルのコード編集ソフト(SublimeText3)
ホットトピック
 7683
7683
 15
1639
14
1393
52
1286
25
1229
29
15
1639
14
1393
52
1286
25
1229
29

 Win11でオーディオバランスを調整するにはどうすればよいですか? (Win11では左右のチャンネルの音量を調整します)
Feb 11, 2024 pm 05:57 PM
Win11でオーディオバランスを調整するにはどうすればよいですか? (Win11では左右のチャンネルの音量を調整します)
Feb 11, 2024 pm 05:57 PM
Win11 コンピューターで音楽を聴いたり、映画を見たりするときに、スピーカーまたはヘッドフォンの音がアンバランスに聞こえる場合は、ユーザーは必要に応じてバランス レベルを手動で調整できます。では、どうやって調整すればよいのでしょうか?この問題に対応して、編集者は皆様のお役に立ちたいと考えて、詳細な操作チュートリアルを提供しました。 Windows 11 で左右のオーディオ チャンネルのバランスをとるにはどうすればよいですか?方法 1: 設定アプリを使用してキーをタップし、[設定] をクリックします。 Windows では、「システム」をクリックし、「サウンド」を選択します。さらにサウンド設定を選択します。スピーカー/ヘッドフォンをクリックし、[プロパティ]を選択します。 「レベル」タブに移動し、「バランス」をクリックします。 「左」であることを確認し、
 Bose Soundbar Ultra の発売体験: 箱から出してすぐにホームシアター?
Feb 06, 2024 pm 05:30 PM
Bose Soundbar Ultra の発売体験: 箱から出してすぐにホームシアター?
Feb 06, 2024 pm 05:30 PM
私は物心ついた頃から、家に大きなフロアスタンディングスピーカーを 2 台置いていて、テレビは完全なサウンドシステムを備えていてこそテレビと呼べるものだと常々信じてきました。しかし、私が働き始めた頃は、プロ仕様のホームオーディオを買う余裕がありませんでした。製品の位置づけを検討し理解した結果、音質、サイズ、価格のすべての点で私のニーズを満たしているサウンドバーというカテゴリーが私にとって非常に適していることがわかりました。そこで、サウンドバーを導入することにしました。慎重に選んだ結果、2024 年初頭にボーズが発売したこのパノラマ サウンドバー製品、ボーズ ホーム エンターテイメント スピーカー ウルトラを選択しました。 (写真出典: Lei Technology 撮影) 一般に、「本来の」ドルビーアトモス効果を体験したい場合は、測定および校正されたサラウンドサウンド + 天井を自宅に設置する必要があります。
 小紅書で公開するときに写真が自動的に保存される問題を解決するにはどうすればよいですか?投稿時に自動保存された画像はどこにありますか?
Mar 22, 2024 am 08:06 AM
小紅書で公開するときに写真が自動的に保存される問題を解決するにはどうすればよいですか?投稿時に自動保存された画像はどこにありますか?
Mar 22, 2024 am 08:06 AM
ソーシャルメディアの継続的な発展に伴い、Xiaohongshu はますます多くの若者が自分たちの生活を共有し、美しいものを発見するためのプラットフォームとなっています。多くのユーザーは、画像を投稿する際の自動保存の問題に悩まされています。では、この問題をどうやって解決すればよいでしょうか? 1.小紅書で公開するときに写真が自動的に保存される問題を解決するにはどうすればよいですか? 1. キャッシュをクリアする まず、Xiaohongshu のキャッシュ データをクリアしてみます。手順は次のとおりです: (1) 小紅書を開いて右下隅の「マイ」ボタンをクリックします。 (2) 個人センター ページで「設定」を見つけてクリックします。 (3) 下にスクロールして「」を見つけます。 「キャッシュをクリア」オプションを選択し、「OK」をクリックします。キャッシュをクリアした後、Xiaohongshu を再起動し、写真を投稿して、自動保存の問題が解決されるかどうかを確認します。 2. 小紅書バージョンを更新して、小紅書が正しく動作することを確認します。
 TikTokのコメントに写真を投稿するにはどうすればよいですか?コメント欄の写真への入り口はどこですか?
Mar 21, 2024 pm 09:12 PM
TikTokのコメントに写真を投稿するにはどうすればよいですか?コメント欄の写真への入り口はどこですか?
Mar 21, 2024 pm 09:12 PM
Douyin のショートビデオの人気により、コメント エリアでのユーザーのやり取りがより多彩になりました。ユーザーの中には、自分の意見や感情をよりよく表現するために、コメントで画像を共有したいと考えている人もいます。では、TikTokのコメントに写真を投稿するにはどうすればよいでしょうか?この記事では、この質問に詳しく答え、関連するヒントと注意事項をいくつか紹介します。 1.Douyinのコメントに写真を投稿するにはどうすればよいですか? 1. Douyinを開く: まず、Douyin APPを開いてアカウントにログインする必要があります。 2. コメントエリアを見つける:短いビデオを閲覧または投稿するときに、コメントしたい場所を見つけて「コメント」ボタンをクリックします。 3. コメントの内容を入力します: コメント領域にコメントの内容を入力します。 4. 写真の送信を選択します。コメント内容を入力するインターフェースに「写真」ボタンまたは「+」ボタンが表示されます。
 Windows 11でサウンド設定をリセットする7つの方法
Nov 08, 2023 pm 05:17 PM
Windows 11でサウンド設定をリセットする7つの方法
Nov 08, 2023 pm 05:17 PM
Windows ではコンピューター上のサウンドを管理できますが、オーディオの問題や不具合が発生した場合に備えて、サウンド設定をリセットする必要がある場合があります。ただし、Microsoft が Windows 11 で行った外観上の変更により、これらの設定に焦点を合わせることがより困難になりました。そこで、Windows 11 でこれらの設定を見つけて管理する方法、または問題が発生した場合にリセットする方法について詳しく見ていきましょう。 Windows 11 のサウンド設定を 7 つの簡単な方法でリセットする方法 ここでは、直面している問題に応じて、Windows 11 のサウンド設定をリセットする 7 つの方法を紹介します。はじめましょう。方法 1: アプリのサウンドと音量の設定をリセットする キーボードのボタンを押して、設定アプリを開きます。今すぐクリック
 iPhone で写真をより鮮明にする 6 つの方法
Mar 04, 2024 pm 06:25 PM
iPhone で写真をより鮮明にする 6 つの方法
Mar 04, 2024 pm 06:25 PM
Apple の最近の iPhone は、鮮明なディテール、彩度、明るさで思い出を捉えます。ただし、場合によっては、画像が鮮明に見えなくなる問題が発生することがあります。 iPhone カメラのオートフォーカスは大きく進歩し、写真をすばやく撮影できるようになりましたが、状況によってはカメラが誤って間違った被写体に焦点を合わせ、不要な領域で写真がぼやけてしまうことがあります。 iPhone 上の写真の焦点が合っていない場合、または全体的に鮮明さが欠けている場合は、次の投稿を参照して写真を鮮明にすることができます。 iPhone で写真を鮮明にする方法 [6 つの方法] ネイティブの写真アプリを使用して写真をクリーンアップしてみることができます。さらに多くの機能やオプションが必要な場合
 PPT画像を1枚ずつ表示させる方法
Mar 25, 2024 pm 04:00 PM
PPT画像を1枚ずつ表示させる方法
Mar 25, 2024 pm 04:00 PM
PowerPoint では、画像を 1 枚ずつ表示するのが一般的な手法ですが、これはアニメーション効果を設定することで実現できます。このガイドでは、基本的なセットアップ、画像の挿入、アニメーションの追加、アニメーションの順序とタイミングの調整など、この手法を実装する手順について詳しく説明します。さらに、トリガーの使用、アニメーションの速度と順序の調整、アニメーション効果のプレビューなど、高度な設定と調整が提供されます。これらの手順とヒントに従うことで、ユーザーは PowerPoint で次々に表示される画像を簡単に設定できるため、プレゼンテーションの視覚的な効果が高まり、聴衆の注意を引くことができます。
 Web ページ上の画像を読み込めない場合はどうすればよいですか? 6つのソリューション
Mar 15, 2024 am 10:30 AM
Web ページ上の画像を読み込めない場合はどうすればよいですか? 6つのソリューション
Mar 15, 2024 am 10:30 AM
一部のネチズンは、ブラウザの Web ページを開いたときに、Web ページ上の画像が長時間読み込めないことに気づきました。何が起こったのでしょうか?ネットワークは正常であることを確認しましたが、どこに問題があるのでしょうか?以下のエディタでは、Web ページの画像が読み込めない問題に対する 6 つの解決策を紹介します。 Web ページの画像を読み込めない: 1. インターネット速度の問題 Web ページに画像が表示されません。これは、コンピュータのインターネット速度が比較的遅く、コンピュータ上で開いているソフトウェアが多いためと考えられます。また、アクセスする画像が比較的大きいため、読み込みタイムアウトが原因である可能性があります。その結果、画像が表示されません。ネットワーク速度をより多く消費するソフトウェアをオフにすることができます。タスク マネージャーに移動して確認できます。 2. 訪問者が多すぎる Web ページに写真が表示されない場合は、訪問した Web ページが同時に訪問されたことが原因である可能性があります。
