

テイクアウト広告向けの大規模深層学習モデルのエンジニアリング実践

著者: 亚廼英梁陈龙 他
はじめに
美団のフードデリバリー事業が発展し続ける中、フードデリバリー 広告エンジンチームは複数の分野でエンジニアリングの探索と実践を実施し、一定の成果を上げてきました。連載形式で共有していきますが、その内容は主に、①ビジネスプラットフォーム化の実践、②大規模ディープラーニングモデルエンジニアリングの実践、③ニアラインコンピューティングの探索と実践、④大規模なディープラーニングモデルエンジニアリングの実践です。 -スケールインデックスの構築とオンライン検索サービス; ⑤ 機構エンジニアリングプラットフォームの実践。少し前に、当社はビジネス プラットフォーム化の実践を公開しました (詳細については、「##美団テイクアウト広告プラットフォーム化の検討と実践 ##」を参照してください) #>> 1つ)。この記事は、一連の記事の 2 番目であり、フル リンク レベルでの大規模ディープ モデルによってもたらされる課題に焦点を当て、オンライン レイテンシとオフライン効率の 2 つの側面から始めて、大規模な広告エンジニアリングについて説明します。スケールディープモデル. 練習して、皆さんに何らかの助けやインスピレーションをもたらすことを願っています。 1 背景
検索、レコメンデーション、広告などのインターネットの中核的なビジネス シナリオ (以下、検索プロモーション ) 、データマイニングと関心が行われます モデリングとユーザーに高品質のサービスを提供することは、ユーザーエクスペリエンスを向上させるための重要な要素となっています。近年、検索およびプロモーション ビジネスでは、データの配当とハードウェア テクノロジーの恩恵を受けてディープ ラーニング モデルが業界で広く導入されており、同時に CTR シナリオでは、業界は単純な DNN 小規模から徐々に移行しています。モデルから大規模なモデルまで、数兆のパラメータを持つ埋め込みモデル、または超大規模なモデルまで。テイクアウト広告ビジネスラインは主に「LR浅いモデル(ツリーモデル)」→「深層学習モデル」→「大規模深層学習モデル」という進化過程を経験してきました。進化全体の傾向は、人工的な特徴に基づく単純なモデルから、データを中心とした複雑な深層学習モデルへと徐々に移行しています。大型モデルの採用により、モデルの表現力が大幅に向上し、需要側と供給側のマッチングがより正確になり、その後のビジネス展開の可能性が広がりました。しかし、モデルとデータの規模が増加し続けると、効率と次のような関係があることがわかります。 上の図に示すように、データの規模とモデルの規模が増加すると、対応する「期間」はどんどん長くなっていきます。この「期間」は、効率に反映されるオフライン レベルに対応し、レイテンシに反映されるオンライン レベルに対応します。そして私たちの仕事は、この「期間」の最適化を中心に行われます。 
通常の小規模モデルと比較して、大規模モデルの中核的な問題は次のとおりです。データ量とモデルの規模が数十倍に増加するためです。たとえ 100 回であっても、リンク全体のストレージ、通信、コンピューティングなどは新たな課題に直面し、アルゴリズムのオフライン反復効率に影響を及ぼします。オンライン遅延の制約など一連の問題をどうやって突破するのか?以下に示すように、まずリンク全体を分析してみましょう:
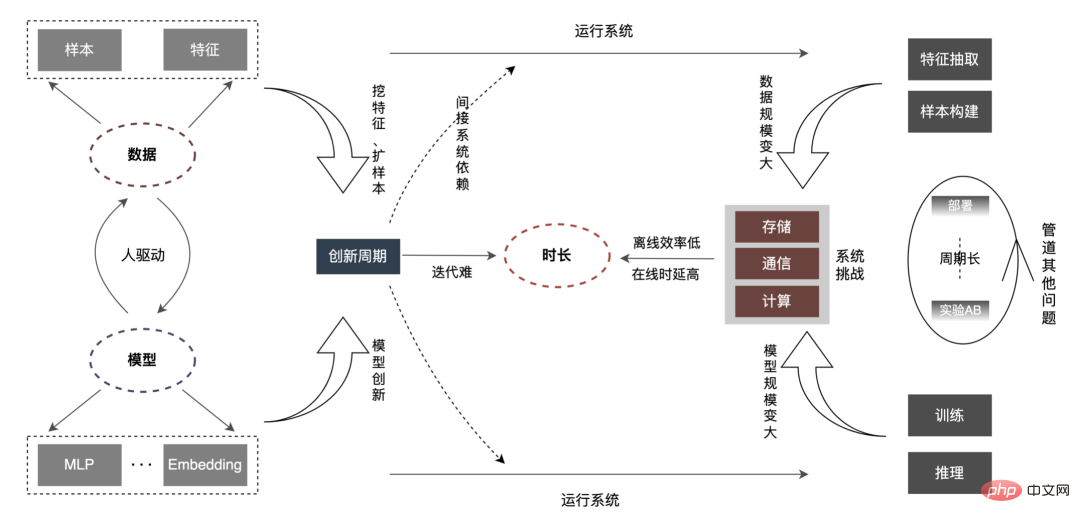
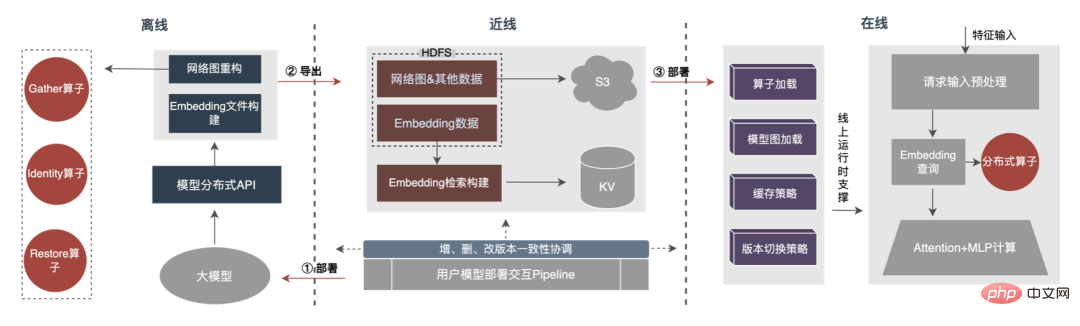
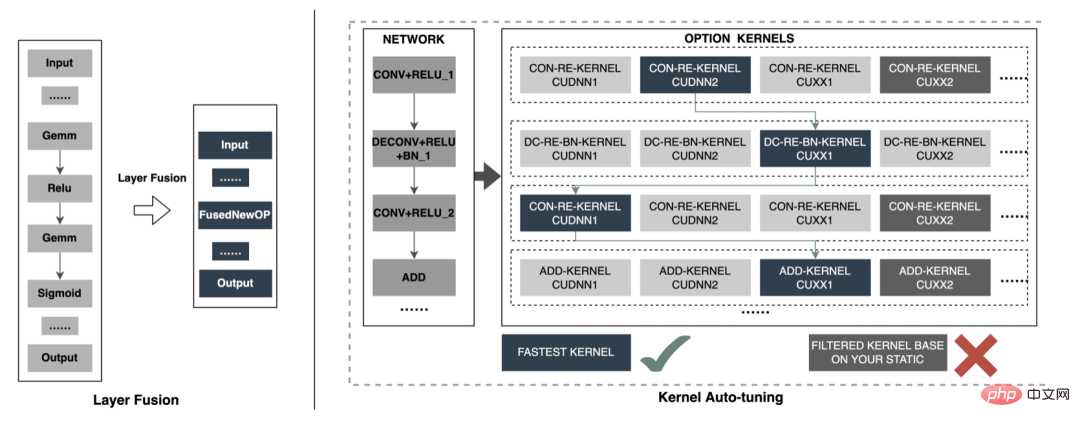
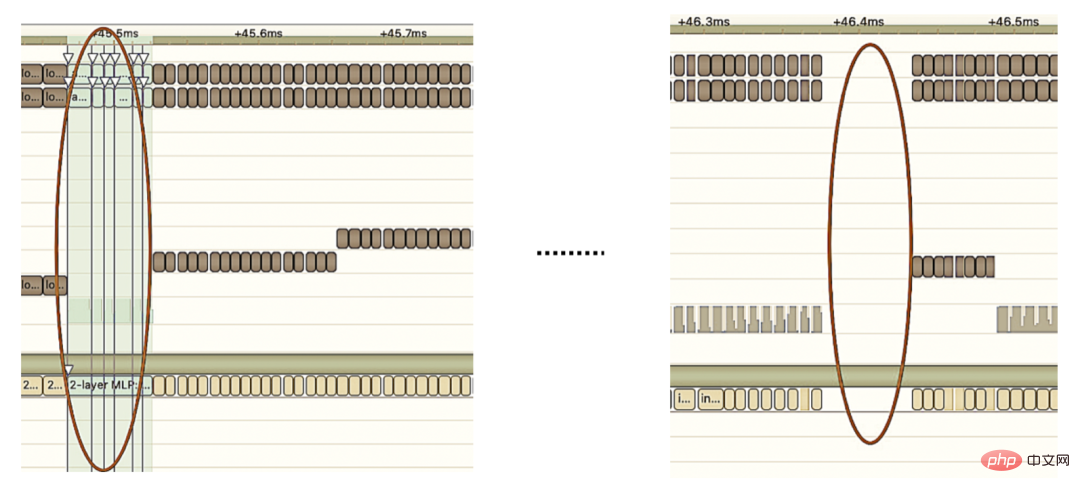
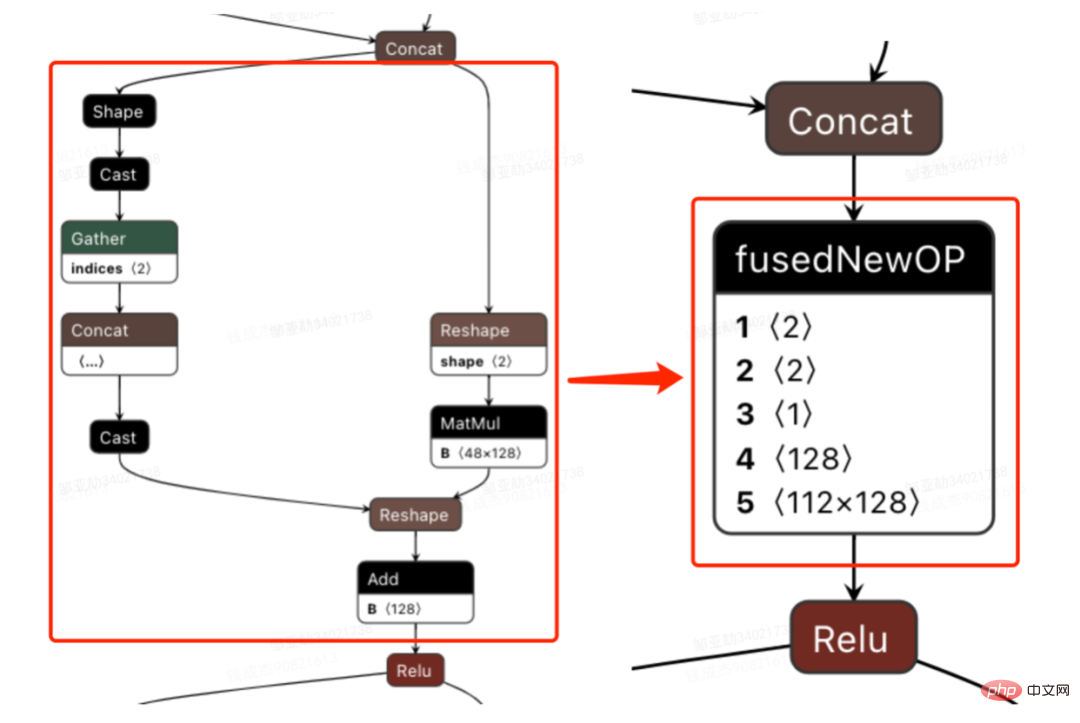
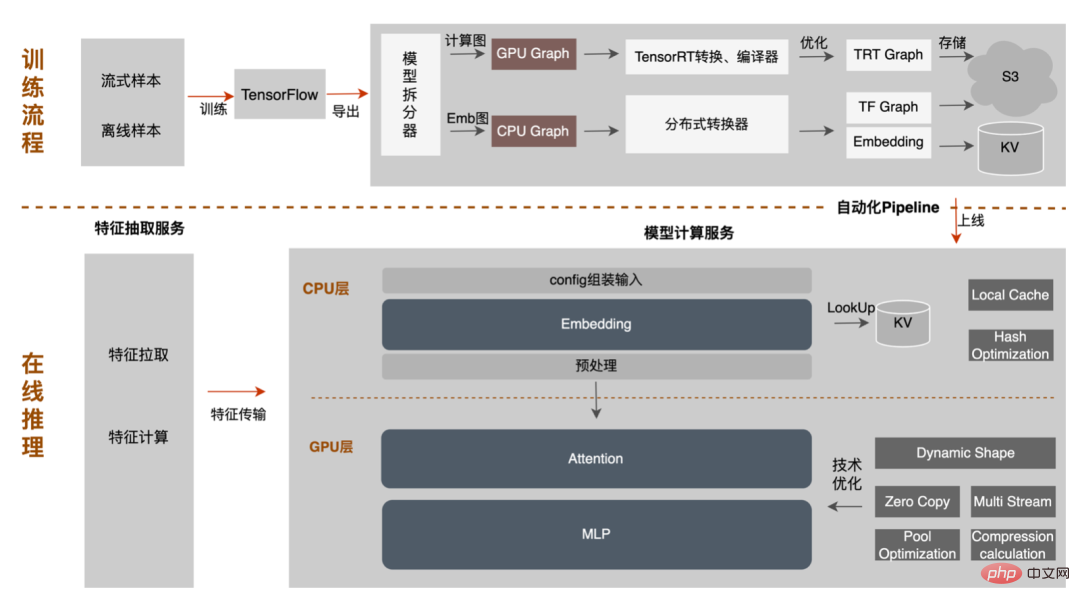
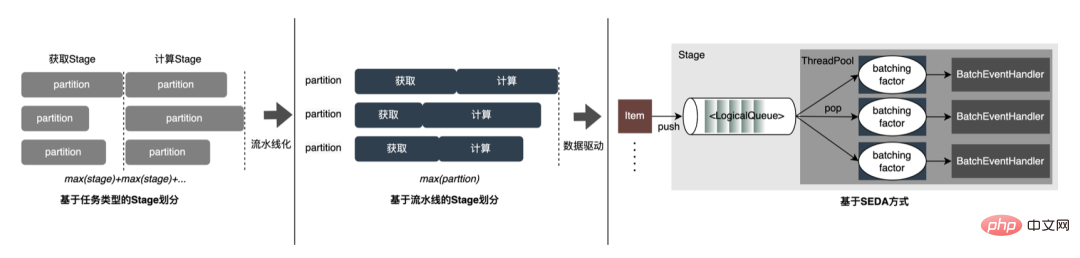
モデル推論、機能サービス)、オフライン効率 () に焦点を当てています。サンプル構築とデータ準備の 2 つの側面から実施されます。)、大規模なディープ モデルでの広告のエンジニアリング実践を段階的に説明します。 「期間」を最適化する方法とその他の関連する問題については、後続の章で説明しますので、お楽しみに。 3 モデル推論 3.1 分散 したがって、モデル パラメーターのスケールが大きくなるという問題を解決する鍵は、スパース パラメーターを単一コンピューターのストレージから分散ストレージに変換することです。変換方法には 2 つの部分が含まれます。 ① モデルネットワーク構造変換;② スパースパラメータをエクスポートします。 業界では、分散パラメータを取得するには大きく 2 つの方法があります。外部サービスが事前にパラメータを取得し、それを外部サービスに渡すことです。推定サービス ; 推定サービスは、TF (TensorFlow) 演算子を変換することにより、分散ストレージからパラメータを内部的に取得します。アーキテクチャ変更のコストを削減し、既存のモデル構造への侵入を減らすために、TF オペレーターを変更して分散パラメーターを取得することを選択しました。 通常の状況では、TF モデルはネイティブ オペレーターを使用してスパース パラメーターを読み取ります。コア オペレーターは GatherV2 オペレーターです。オペレーターの入力は主に 2 つの部分で構成されます: ① 必要なクエリ ID list; ② Sparseパラメータを格納する埋め込みテーブル。 演算子の機能は、ID リストのインデックスに対応する Embedding データを Embedding テーブルから読み取って返すことであり、本質的にはハッシュ クエリの処理です。このうち、Embedding テーブルに格納される Sparse パラメータは、単機モデルではすべて単機メモリに格納されます。 TF オペレーターの変換は本質的にモデル ネットワーク構造の変換であり、変換の核心は主に 2 つの部分で構成されます: ① ネットワーク グラフの再構築、② カスタム分散オペレーター。 1. ネットワーク ダイアグラムの再構築: モデル ネットワーク構造を変換し、ネイティブ TF オペレーターをカスタム分散オペレーターに置き換え、ネイティブ エンベディング テーブルの変更を実行します。同時に固まります。 全体的なプロセスは次の図に示されており、オフラインの分散モデル構造変換、ニアライン データの一貫性保証、オンライン ホットスポット データを通じて数百ギガバイトのデータを保証します。キャッシュ: モデルの通常の反復要件。 #分散ストレージによって使用されるストレージは外部 KV 機能であり、より効率的で柔軟な機能に置き換えられることがわかります。将来的には管理が容易な埋め込みサービス。 モデル自体の最適化方法に加えて、主に一般的な CPU アクセラレーション方法が 2 つあります。 ① AVX2 を使用した命令セットの最適化。 , AVX512命令セット; ②アクセラレーションライブラリ(TVM、OpenVINO)を使用します。 以下では、CPU アクセラレーションに OpenVINO を使用した実際の経験の一部に焦点を当てます。 OpenVINO は、Intel が発表した深層学習ベースのコンピューティング アクセラレーション最適化フレームワークのセットで、圧縮の最適化、アクセラレーション コンピューティング、および機械学習モデルのその他の機能をサポートします。 OpenVINO の高速化原理は、線形演算子融合とデータ精度校正の 2 つの部分に簡単に要約されます。 #CPU アクセラレーションにより、通常、固定バッチ候補キューの推論が高速化されますが、検索プロモーション シナリオでは、候補キューは動的であることがよくあります。これは、モデル推論の前に、バッチ マッチング操作を追加する必要があることを意味します。つまり、要求された動的バッチ候補キューは、それに最も近いバッチ モデルにマップされますが、これには N 個のマッチング モデルを構築する必要があり、結果としてメモリ使用量が N 倍になります。 。現在のモデルの容量は数百ギガバイトに達しており、メモリが非常に不足しています。したがって、高速化のために合理的なネットワーク構造を選択することは、考慮する必要がある重要な問題です。次の図は、全体的な動作アーキテクチャです: 現在、OpenVINO に基づく CPU アクセラレーション ソリューションは実稼働環境で良好な結果を達成しています。CPU がベースラインと同じ場合、サービス スループットは 1 倍向上します。 40%、平均遅延は 15% 減少します。 CPU レベルで高速化を行いたい場合は、OpenVINO が良い選択です。 ビジネスの発展に伴い、ビジネス形態はますます豊富になり、トラフィックはますます増大し、モデルはますます増加しています。消費電力が急激に増加する一方で、広告シーンでは主に DNN モデルが使用され、多数のスパースな特徴の埋め込みとニューラル ネットワークの浮動小数点演算が含まれます。メモリ アクセスとコンピューティング集約型のオンライン サービスとして、可用性を確保しながら低遅延と高スループットの要件を満たす必要がありますが、これは単一マシンのコンピューティング能力に対する課題でもあります。コンピューティング リソース要件とスペースの間の矛盾がうまく解決されないと、ビジネス開発が大幅に制限されてしまいます。モデルが拡張され深化される前は、純粋な CPU 推論サービスでかなりのスループットを提供できますが、モデルが拡張され深化されると、計算は次のようになります。高可用性を確保するには、大量のマシン リソースを消費する必要があるため、大規模なモデルをオンラインで大規模に適用できなくなります。現在、業界で一般的な解決策は GPU を使用してこの問題を解決することであり、GPU 自体はコンピューティング集約型のタスクにより適しています。 GPU を使用するには、可用性と低遅延を確保しながら、使いやすさと汎用性も考慮しながら、可能な限り高いスループットを達成する方法という課題を解決する必要があります。この目的を達成するために、TensorFlow-GPU、TensorFlow-TensorRT、TensorRT などの GPU についても多くの実践的な作業を行ってきました。TF の柔軟性と TensorRT の加速効果を考慮するために、 TensorFlow と TensorRT の独立した 2 段階のアーキテクチャ設計。 、融合最適化、 について詳しく紹介します。エンジンの最適化 いくつかの作業が完了しました。 3.3.3 モデルの最適化 1. 計算と送信の重複排除: 推論中、同じバッチには 1 つのユーザー情報のみが含まれます。したがって、推論前にユーザー情報をバッチ サイズから 1 に削減し、実際に推論が必要なときに拡張して、データ送信のコピーと反復計算のコストを削減できます。次の図に示すように、推論前にユーザー クラスの機能情報を 1 回だけクエリし、ユーザー関連のサブネットワークのみでその情報をプルーニングし、関連付けを計算する必要があるときに展開することができます。 #2. データ精度の最適化 : 原因学習時は勾配更新のためバックプロパゲーションが必要となり高いデータ精度が要求されますが、モデル推論時は勾配更新を行わずに順推論のみを行うため、効果を確保することを前提にFP16や混合精度を使用します。メモリ領域を節約するための最適化に使用され、送信オーバーヘッドが削減され、推論パフォーマンスとスループットが向上します。 #3. 計算プッシュダウン オンライン モデル推論中、各層の計算操作は GPU によって完了します。実際には、CPU は異なる CUDA カーネルを起動することによって計算を完了します。CUDA カーネルテンソルの計算は非常に高速ですが、CUDA カーネルの起動と各層の入出力テンソルの読み取りと書き込みに多くの時間が浪費されることが多く、メモリ帯域幅のボトルネックと GPU リソースの無駄が発生します。ここでは主に TensorRT の 自動最適化 と 手動最適化 の部分を紹介します。 1. 自動最適化: TensorRT は、ディープ ラーニング アプリケーションに低レイテンシー、高スループットの推論展開を提供できる、高性能のディープ ラーニング推論オプティマイザーです。 TensorRT を使用すると、非常に大規模なモデル、組み込みプラットフォーム、自動運転プラットフォームの推論を高速化できます。 TensorRT は、TensorFlow、Caffe、MXNet、PyTorch などのほぼすべての深層学習フレームワークをサポートできるようになり、TensorRT と NVIDIA GPU を組み合わせることで、ほぼすべてのフレームワークでの高速かつ効率的なデプロイと推論が可能になります。また、一部のレイヤー融合やカーネル自動チューニングなど、一部の最適化ではユーザーの参加をあまり必要としません。 2. 手動最適化: ご存知のとおり、GPU は計算集約型の用途に適しています。他のタイプの演算子 (軽量計算演算子、論理演算演算子など ) はあまり使いやすいものではありません。 GPU 計算を使用する場合、各操作は通常、CPU が GPU にビデオ メモリを割り当てる -> CPU が GPU にデータを送信する -> CPU が CUDA カーネルを開始する -> CPU がデータを取得する -> CPU が GPU ビデオ メモリを解放するという複数のプロセスを経ます。スケジューリング、カーネルの起動、メモリ アクセスなどのオーバーヘッドを削減するには、ネットワークの統合が必要です。 CTR大規模モデルは柔軟で変更可能な構造のため、ネットワーク融合手法を統一することが難しく、特定の問題のみを詳細に分析できます。例えば、垂直方向には Cast、Unsqueeze、Less が融合され、TensorRT 内部の Conv、BN、Relu が融合され、水平方向には同じ次元の入力演算子が融合されます。この目的を達成するために、NVIDIA 関連のパフォーマンス分析ツール (NVIDIA Nsight Systems、NVIDIA Nsight Compute など ) を使用して、実際のオンライン ビジネス シナリオに基づいて特定の問題を分析します。これらのパフォーマンス分析ツールをオンライン推論環境に統合して、推論プロセス中に GPU プロフィング ファイルを取得します。 Profing ファイルを通じて、推論プロセスを明確に確認できます。図に示すように、推論全体における一部の演算子のカーネル起動限界現象が深刻で、一部の演算子間のギャップが大きく、最適化の余地があることがわかりました。次の図: そのためには、パフォーマンス分析ツールと変換されたモデルに基づいてネットワーク全体を分析し、TensorRT が最適化した部分を見つけて、最適化できるネットワーク内の他の部分構造に対してネットワーク統合を実行します。また、この下部構造がネットワーク全体で一定の割合を占めることを保証し、融合後にコンピューティング密度がある程度まで増加することを保証します。どのようなネットワーク統合手法を使用するかについては、シナリオに応じて柔軟に利用できますが、統合前と統合後の部分構造図の比較は次の図のようになります。 #3.3 .5 エンジンの最適化 Dynamic Shape : GPU アクセラレーション エンジンのパフォーマンスをさらに調査するため、埋め込みデータをクエリします。この操作は、マルチレベル PS: GPU メモリ キャッシュ -> CPU メモリ キャッシュ -> ローカル SSD/分散 KV を通じて実行できます。その中で、ホットスポット データは GPU メモリにキャッシュでき、キャッシュされたデータはデータ ホットスポットの移行、昇格、削除などのメカニズムを通じて動的に更新され、GPU の並列計算能力とメモリ アクセス機能を最大限に活用して効率的なクエリを実行できます。 。オフライン テスト後、GPU キャッシュのクエリ パフォーマンスは CPU キャッシュの 10 倍です。GPU キャッシュのミス データについては、CPU キャッシュにアクセスしてクエリできます。2 レベルのキャッシュはデータ アクセスの 90% を満たすことができます。ロングテール リクエストの場合、データ取得のために Access 分散 KV を渡す必要があります。具体的な構造は次のとおりです。 #パイプラインの構築には、オフライン モデルの分割と変換プロセス、およびオンライン モデル デプロイメント プロセスの 2 つの部分が含まれます。
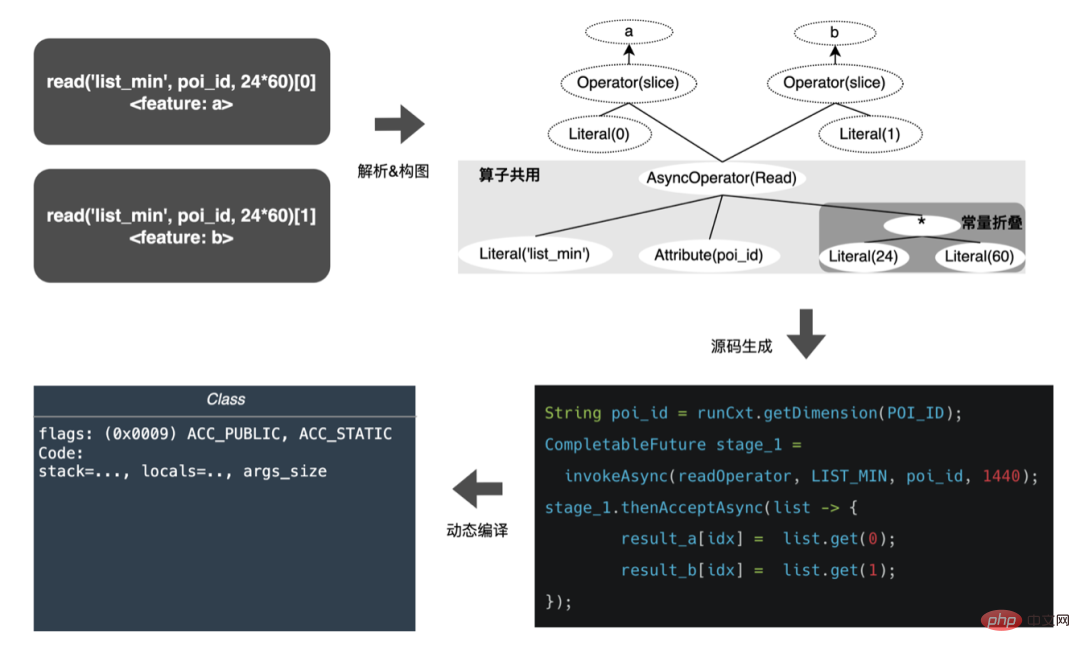
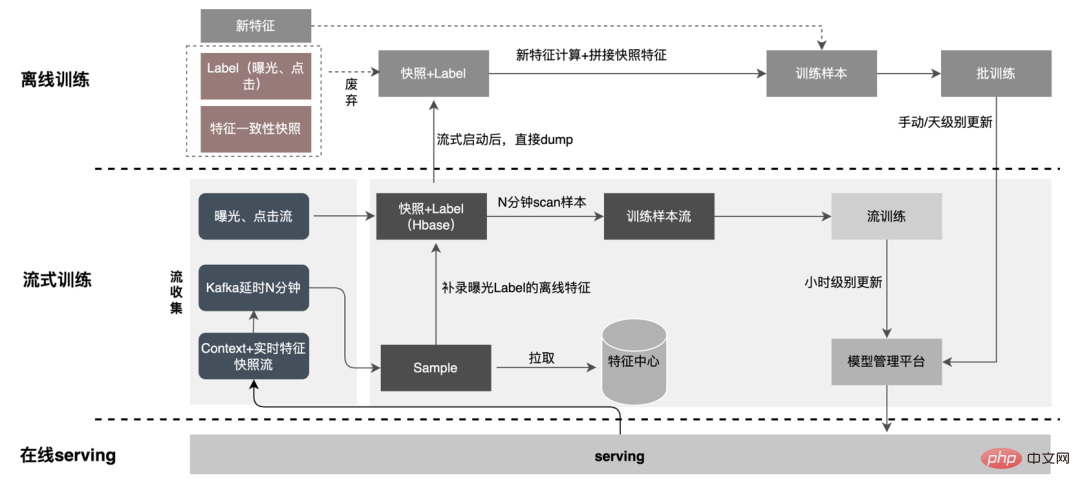
美団テイクアウト特徴プラットフォームの構築と実践 では、モデル特徴自己記述MFDLに基づく特徴計算について説明しました。このプロセスは、オンライン推定およびオフライン トレーニング中にサンプルの一貫性を確保するように構成されています。ビジネスの反復が急速に進むにつれて、モデルの特徴の数は増加し続けており、特に多数の個別の特徴を導入する大規模なモデルでは、計算量が 2 倍になります。この目的を達成するために、特徴抽出レイヤーにいくつかの最適化を行い、スループットと消費時間の大幅な向上を達成しました。 4.1 フルプロセス CodeGen の最適化
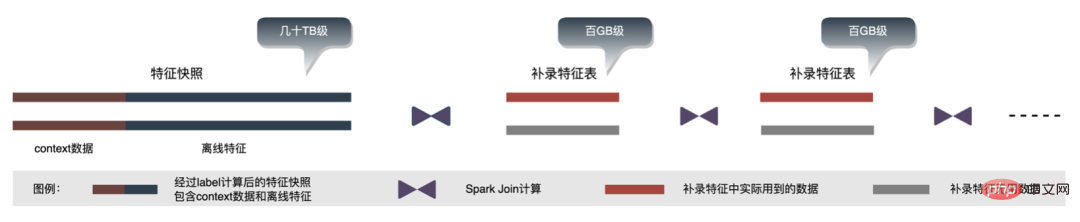
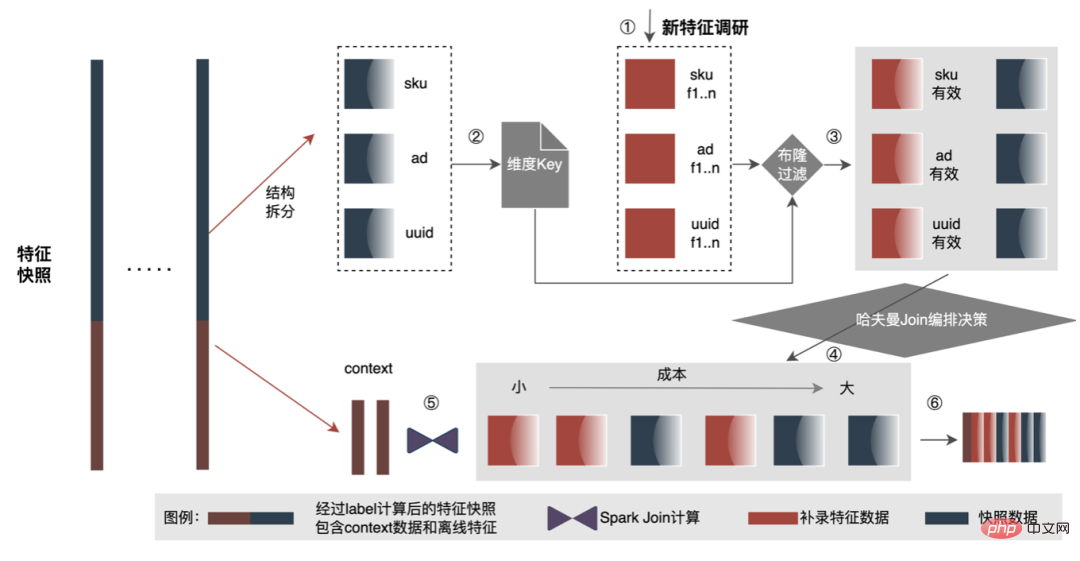
Spark の WholeStageCodeGen を利用する私たちの目標は、特徴計算 DSL 全体を実行可能なメソッドにコンパイルし、それによってコード実行時のパフォーマンスの損失を軽減することです。コンパイル プロセス全体は、フロントエンド (FrontEnd)、オプティマイザー (Optimizer)、およびバックエンド (BackEnd) に分けることができます。フロントエンドは主に、ターゲット DSL の解析とソース コードの AST または IR への変換を担当します。オプティマイザは、フロントエンドに基づいて取得した中間コードを最適化し、コードをより効率的にします。バックエンドは、最適化された中間コードを変換します。コードをそれぞれのプラットフォームのネイティブ コードに変換します。具体的な実装は次のとおりです。 最適化後のノード DAG グラフの変換、つまりバックエンド コードの実装によって、最終的なパフォーマンスが決まります。困難の 1 つは、既存のオープンソース式エンジンを直接使用できない理由でもあります。特徴計算 DSL は純粋な計算式ではありません。読み取り演算子と変換演算子の組み合わせにより、特徴の取得と処理のプロセスを記述することができます。 したがって、実際の実装では、さまざまな種類のタスクのスケジュールを考慮し、マシン リソースの使用率を最大化し、時間のかかるプロセス全体を最適化する必要があります。業界調査と独自の実践を組み合わせて、次の 3 つの実装が実行されました: CodeGen ソリューションは完璧ではありません。動的に生成されたコードはコードの可読性を低下させ、デバッグのコストを増加させます。ただし、CodeGen をアダプテーション レイヤーとして使用すると、より詳細なソリューションも提供されます。最適化によりスペースが広がります。 CodeGen と非同期ノンブロッキング実装に基づいて、時間のかかる特徴量計算を削減する一方で、CPU 負荷を大幅に軽減し、システム スループットを向上させるなど、オンラインでの優れたメリットが得られています。今後も CodeGen を活用し、ハードウェア命令 (SIMD など) やヘテロジニアス コンピューティング (## など) の組み合わせを検討するなど、バックエンドのコンパイル プロセスで的を絞った最適化を実行していきます。 #GPU など) を使用して、より詳細な最適化を行います。 オンライン予測サービスは全体として 2 層のアーキテクチャを持ち、特徴抽出層はモデルのルーティングと特徴の計算を担当し、モデル計算層はモデルの計算を担当します。本来のシステムの処理は、特徴量計算の結果を M (予測バッチ サイズ ) × N (サンプル幅 ) の行列に結合し、シリアル化して計算に送信することです。層です。この理由は、一方では歴史的な理由です。多くの初期の非 DNN 単純モデルの入力形式は行列です。ルーティング層が結合された後は、コンピューティング層は変換せずに直接使用できます。他方では、 、配列形式は比較的コンパクトで、ネットワーク送信の時間を節約できます。 上記の問題を解決するために、最適化されたプロセスでは、伝送層の上に変換層を追加し、MDFL の構成に従って、計算されたモデルの特徴を必要な特徴に変換します。 . オフラインで使用するための Tensor、行列、CSV 形式などの形式。 離散特徴と系列特徴を Sparse 特徴に統合でき、特徴処理段階では元の特徴をハッシュ処理しますID クラスの機能に変わりました。数千億次元の機能に直面すると、文字列の連結とハッシュのプロセスでは、式スペースとパフォーマンスの観点から要件を満たすことができません。業界調査に基づいて、スロットコーディングに基づく特徴エンコード形式を設計して適用しました。 その中で、feature_hash は、ハッシュ後の元の特徴値です。後の値。整数特徴は直接埋めることができます。非整数特徴または交差特徴は、最初にハッシュされてから埋められます。数値が 44 ビットを超える場合、切り捨てられます。スロット コーディング スキームの導入後、オンライン特徴計算のパフォーマンスが向上しただけでなく、モデル効果も大幅に向上しました。 オンラインとオフラインの一貫性の問題を解決するために、業界は一般に、オンライン ダンプのリアルタイム スコアリングで使用されるフィーチャ データはフィーチャ スナップショットと呼ばれます。この方法では、単純なオフライン ラベル スプライシングとフィーチャ バックフィルによってサンプルを構築するのではなく、大きなデータの不整合が発生します。元のアーキテクチャを次の図に示します。 機能の規模が大きくなり、反復シナリオがますます複雑になるにつれて、このソリューションは次のようになります。最大の問題は、オンライン特徴抽出サービスが大きなプレッシャーにさらされていること、そして第二に、データ ストリーム全体を収集するコストが高すぎることです。このサンプル収集スキームには次の問題があります。 上記の問題を解決するために、業界には 2 つの一般的なソリューションがあります。①Flink リアルタイム ストリーム処理。 ②KVキャッシュ二次処理。具体的なプロセスを次の図に示します。 無効な計算を減らすという観点から、要求されたすべてのデータが公開されるわけではありません。この戦略では公開データに対する需要が高まるため、日レベルの処理をストリーム処理に転送することで、データの準備時間を大幅に短縮できます。次に、データの内容から言えば、リクエストレベルの変更データと日レベルの変更データが特徴的であり、リンクにより両者の処理を柔軟に分離することで、リソースの使用率を大幅に向上させることができます。具体的な計画は次の図の通りです。 #1. データ分割: データ転送量が大きい問題を解決します (フィーチャ スナップショット フローの問題#) ##)、予測ラベル リアルタイム データを 1 つずつ照合すると、リフロー中にオフライン データに 2 回アクセスできるため、リンク データ ストリームのサイズを大幅に削減できます。 2. 遅延消費結合方式 : 大量のメモリ使用量の問題を解決します。 #3. 機能の再記録のサンプル : Label's Join を通じて、ここに追加された機能リクエストの数はオンラインの 20% 未満です遅延読み取り、露出とのスプライシング、露出モデル サービス リクエスト (コンテキスト リアルタイム機能) のフィルタリング、次にすべてのオフライン機能の記録、完全なサンプル データの形成、HBase への書き込み。 ビジネスが繰り返されるにつれて、フィーチャー スナップショット内のフィーチャーの数はますます増加し、1 つのビジネスでフィーチャー スナップショット全体が数十に達します。シナリオ。TB レベル/日。ストレージの観点から見ると、複数日間にわたる単一ビジネスの特徴的なスナップショットはすでに PB レベルに達しており、広告アルゴリズムのストレージしきい値にほぼ達しており、ストレージの負荷が高いです。コンピューティングの観点からは、コンピューティング エンジン (Spark) のリソース制限により、元の計算プロセスを使用します (shuffle が使用され、シャッフル書き込みフェーズのデータはディスクに書き込まれます)。割り当てられたメモリが不十分な場合、複数のディスク書き込みと外部ソートが発生します )、計算を効果的に完了するには、独自のデータと同じサイズのメモリとより多くのコンピューティング CU が必要です。 大量のメモリを占有します。サンプル構築プロセスの中心となるプロセスを次の図に示します。 フィーチャを再記録すると、次の問題が発生します: #サンプル構築効率が遅いという問題を解決するために、短期的にはデータ構造の管理から開始します。詳細なプロセスは次の図に示すとおりです。 データのオフライン ストレージ リソースが 80% 節約され、サンプル構築効率が 200% 向上しました。現在、サンプル データ全体も、データレイクを利用してデータ効率をさらに向上させます。 プラットフォームには、機能、サンプル、モデルなどの貴重なコンテンツが大量に蓄積されており、これらのデータ資産を再利用することで戦略担当者を支援したいと考えています。 . ビジネスの繰り返しを改善し、より良いビジネス上の利益を達成します。特徴の最適化は、アルゴリズム スタッフがモデルの効果を向上させるために使用するすべての手法の 40% を占めていますが、従来の特徴マイニング手法には、長時間かかる、マイニング効率が低い、特徴マイニングが繰り返されるなどの問題がありました。機能の次元、ビジネス。機能の効果を検証し、最終的な効果指標をユーザーに推奨するための自動化された実験プロセスがあれば、間違いなく戦略担当者が大幅な時間を節約するのに役立ちます。全体のリンク構築が完了したら、さまざまな特徴候補セットを入力するだけで、対応する効果指標が出力されます。この目的を達成するために、プラットフォームは、特徴とサンプルの「加算」、「減算」、「乗算」、「除算」のためのインテリジェントなメカニズムを構築しました。 機能の推奨はモデルのテスト方法に基づいており、機能を他のビジネスラインの既存のモデルに再利用し、新しいサンプルとモデルを構築します。新しいモデルと基本モデルのオフライン効果を確認し、新機能の利点を活用して、関連するビジネス リーダーに自動的にプッシュします。特定の機能の推奨プロセスを次の図に示します。 広告に機能レコメンデーションが実装され、一定の収益が得られたらが達成されたら、機能強化レベルでいくつかの新しい調査を行います。モデルの継続的な最適化により、機能拡張の速度が非常に速くなり、モデル サービスのリソース消費量が急激に増加するため、冗長な機能を削除してモデルを「スリム化」することが不可欠です。したがって、プラットフォームは一連のエンドツーエンドの機能スクリーニング ツールを構築しました。 6.3 「乗算」を行う
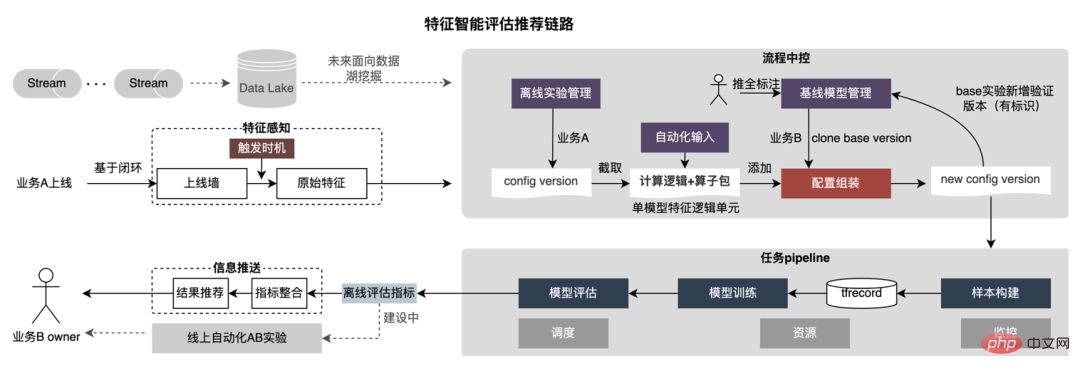
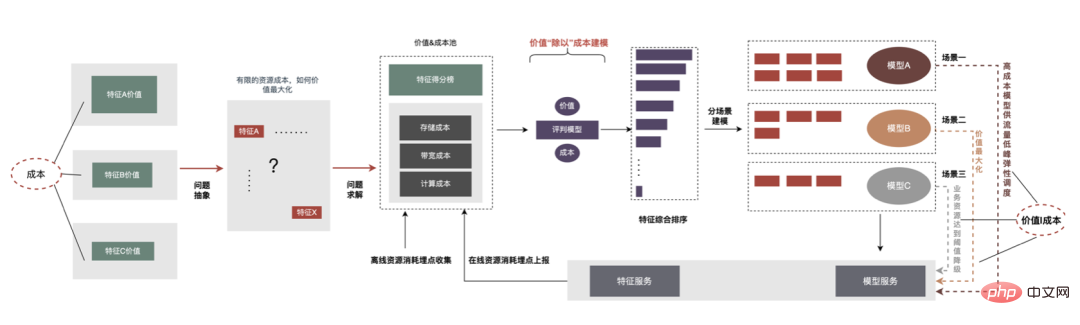
当社は、他の事業分野を借りて増分サンプルを生成できるユニバーサル サンプル共有プラットフォームを確立しました。 。また、大規模および小規模のビジネス統合を実現するための共通の組み込み共有アーキテクチャを構築します。以下は広告以外のサンプルを広告事業で再利用する例で、具体的な方法は以下のとおりです。 たとえば、広告以外のサンプルを広告内のビジネスに再利用することで、サンプル数が数倍に増加しました。転移学習アルゴリズムと組み合わせることで、オフライン AUC第 4 に、オンライン化後は CPM が 1% 増加します。また、各事業者が生成したサンプルデータを一元管理し(Unified Metadata)、統一したサンプルテーマ分類をユーザーに公開し、迅速な登録・検索・再利用を可能にする広告サンプルテーマデータベースの構築も進めています。最下層の統合ストレージにより、ストレージとコンピューティング リソースが節約され、データ結合が削減され、適時性が向上します。 特徴量の「減算」により、プラスの効果を持たないいくつかの特徴量を削除できますが、観察すると、いくつかの特徴量が存在することがわかります。モデル特性にはほとんど価値のない機能がまだ多くあります。したがって、価値とコストの両方を総合的に考慮することでさらに一歩進んで、リンク全体のコストベースの制約の下で、入出力の少ない機能を排除し、リソースの消費を削減することができます。このコスト制約のもとで解く過程を「分割」と定義し、その全体過程を下図に示します。 #オフライン次元では、特徴量のコストと価値を与える特徴量評価システムを確立しました。オンライン推論。情報は、トラフィックの劣化、特徴の弾力性の計算、その他の操作を実行するために使用されます。「分割」の主な手順は次のとおりです: Yajie、Yingliang、Chen Long、Chengjie、Dengfeng、Dongkui、Tongye、Simin、Lebin 、など、すべて Meituan の食品配達技術チームから来ています。
モデル推論レベルでは、テイクアウト広告は、ニッチ スケールをサポートする DNN モデルに代表される 1.0 時代から、 2.0 時代では、高効率かつ低コードでマルチサービスの反復をサポートしていましたが、3.0 時代では、ディープラーニング DNN のコンピューティング能力と大規模ストレージのニーズに徐々に直面しています。主な進化の傾向を次の図に示します。
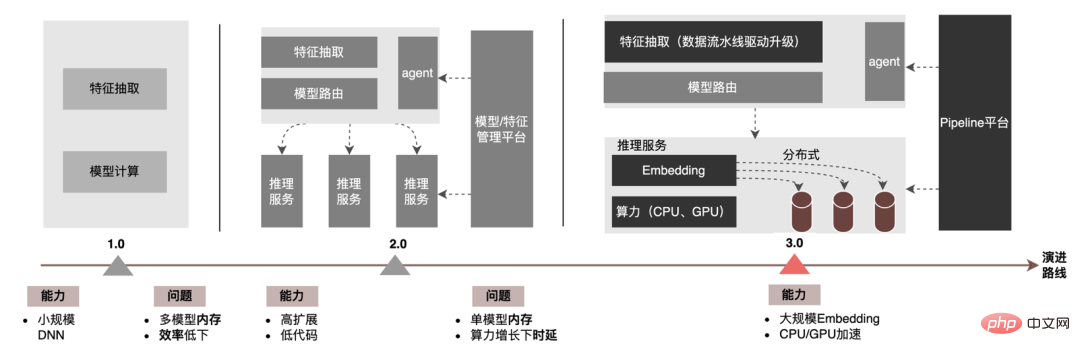 大規模なモデル推論シナリオに直面すると、3.0 アーキテクチャによって解決される 2 つの中心的な問題は、「ストレージの問題」と「パフォーマンス」です。問題"。もちろん、N数百Gのモデルをどのように反復するか、計算負荷が数十倍に増加した場合にオンラインの安定性をどのように確保するか、パイプラインをどのように強化するかなどもプロジェクトが直面する課題です。以下では、Model Inference 3.0 アーキテクチャが「分散」を通じて大規模なモデル ストレージの問題をどのように解決するか、また CPU/GPU アクセラレーションを通じてパフォーマンスとスループットの問題を解決する方法に焦点を当てます。
大規模なモデル推論シナリオに直面すると、3.0 アーキテクチャによって解決される 2 つの中心的な問題は、「ストレージの問題」と「パフォーマンス」です。問題"。もちろん、N数百Gのモデルをどのように反復するか、計算負荷が数十倍に増加した場合にオンラインの安定性をどのように確保するか、パイプラインをどのように強化するかなどもプロジェクトが直面する課題です。以下では、Model Inference 3.0 アーキテクチャが「分散」を通じて大規模なモデル ストレージの問題をどのように解決するか、また CPU/GPU アクセラレーションを通じてパフォーマンスとスループットの問題を解決する方法に焦点を当てます。 大規模モデルのパラメータは主に、疎パラメータと密パラメータの 2 つの部分に分かれています。
3.1.1 モデルネットワーク構造の変換
 2. カスタム分散演算子: ID リストに基づいてクエリを変換するプロセスは、ローカルの Embedding テーブルからのクエリから分散 KV からのクエリに変更されます。
2. カスタム分散演算子: ID リストに基づいてクエリを変換するプロセスは、ローカルの Embedding テーブルからのクエリから分散 KV からのクエリに変更されます。
3.1.2 スパース パラメーター エクスポート
3.2 CPU アクセラレーション
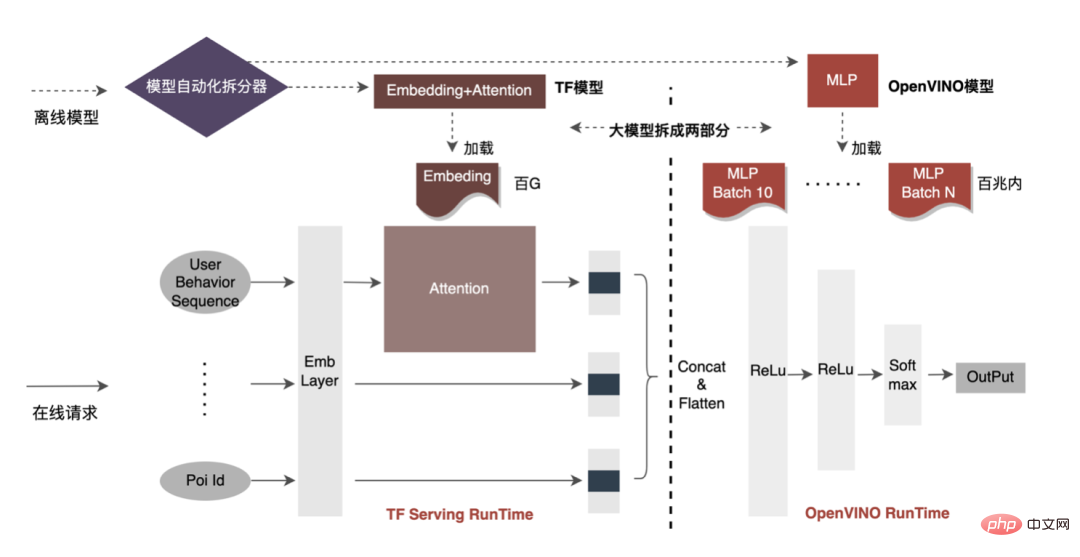
3.3 GPU アクセラレーション
3.3.1 加速分析
モデル最適化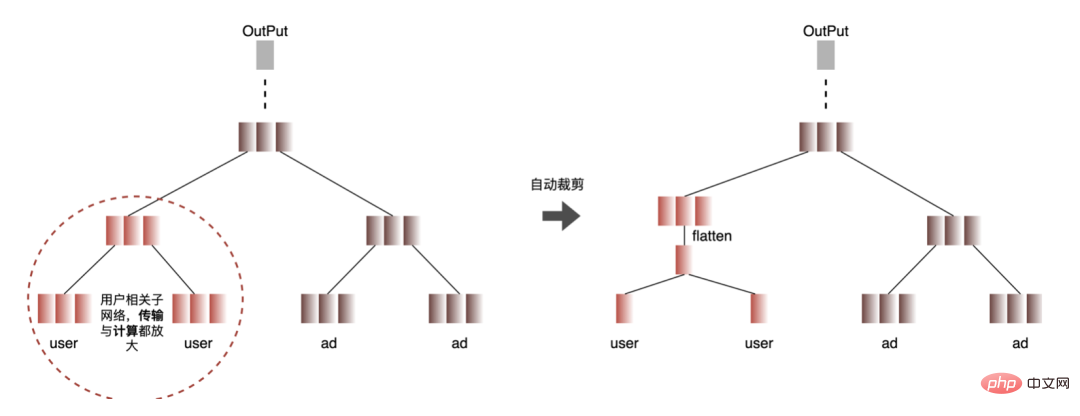
3.3.4 Fusion Optimization
複数のモデル
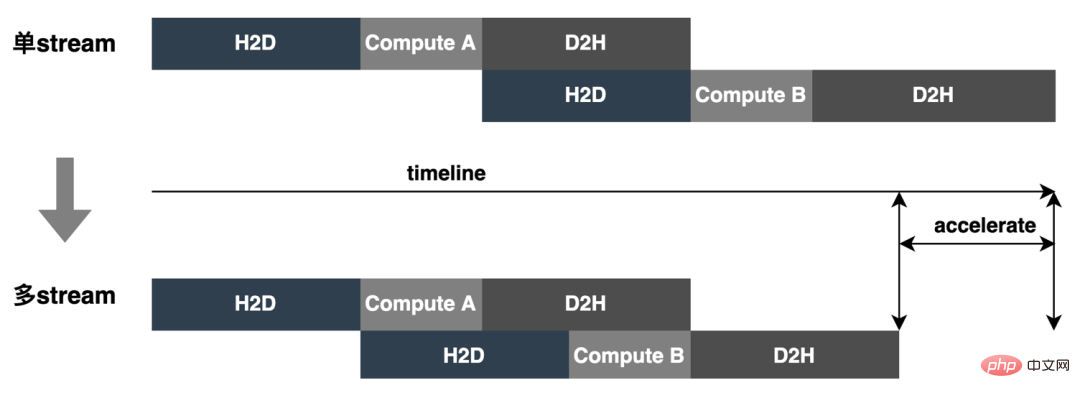
: 入力バッチが不確実なシナリオでの不必要なデータ パディングに対処し、同時にモデルの数を減らし、ビデオ メモリなどのリソースの無駄を削減するために、Dynamic Shape が導入されました。実際の入力データに基づいて推論を実行し、データ パディングと不要なコンピューティング リソースの無駄を削減し、最終的にパフォーマンスの最適化とスループットの向上という目的を達成します。
マルチレベル PS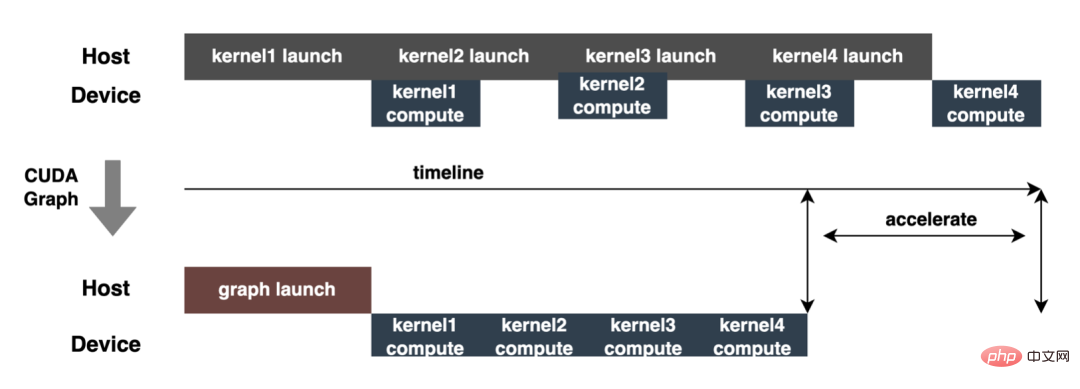
#Pipeline は、構成とワンクリック機能の構築を通じてモデルの反復効率を大幅に向上させ、アルゴリズムとエンジニアリングの学生が自分の仕事により集中できるようにしました。次の図は、純粋な CPU 推論と比較して、GPU の実践で得られる全体的な利点を示しています。 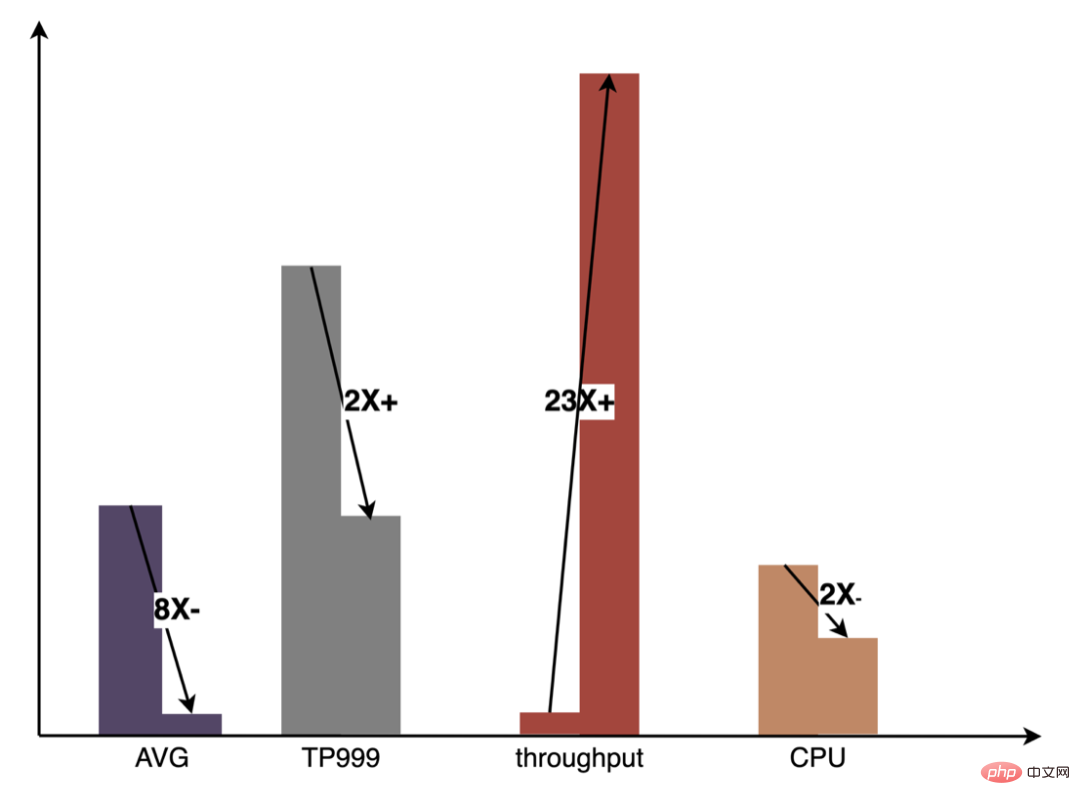 4 機能サービス CodeGen の最適化
4 機能サービス CodeGen の最適化
 しかし、モデルの反復開発により、DNN モデルが徐々に主流になってきており、行列伝送の欠点も非常に明白です:
しかし、モデルの反復開発により、DNN モデルが徐々に主流になってきており、行列伝送の欠点も非常に明白です:
 実際のオンライン モデルのほとんどは TF モデルです。伝送消費をさらに節約するために、プラットフォームは各 Tensor 行列を保存する Tensor Sequence 形式を設計しました。その中で、r_flag は、それがあるかどうかをマークするために使用されます。は項目クラスの特徴です。長さは項目特徴の長さを表します。値は M (項目の数 ) × NF (特徴の長さ ) です。データは、実際の特徴値、アイテム特徴の場合、M 特徴値はフラットに格納され、リクエスト タイプの特徴は直接埋められます。コンパクトな Tensor Sequence 形式に基づいて、データ構造がよりコンパクトになり、ネットワーク上で送信されるデータ量が削減されます。最適化された伝送フォーマットにより、オンラインでも良好な結果が得られ、コンピューティング層を呼び出すルーティング層のリクエスト サイズが 50% 削減され、ネットワーク伝送時間が大幅に短縮されました。
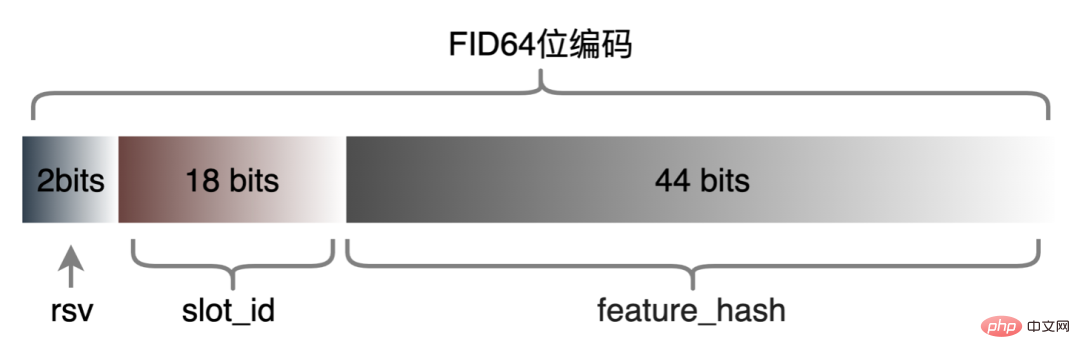
実際のオンライン モデルのほとんどは TF モデルです。伝送消費をさらに節約するために、プラットフォームは各 Tensor 行列を保存する Tensor Sequence 形式を設計しました。その中で、r_flag は、それがあるかどうかをマークするために使用されます。は項目クラスの特徴です。長さは項目特徴の長さを表します。値は M (項目の数 ) × NF (特徴の長さ ) です。データは、実際の特徴値、アイテム特徴の場合、M 特徴値はフラットに格納され、リクエスト タイプの特徴は直接埋められます。コンパクトな Tensor Sequence 形式に基づいて、データ構造がよりコンパクトになり、ネットワーク上で送信されるデータ量が削減されます。最適化された伝送フォーマットにより、オンラインでも良好な結果が得られ、コンピューティング層を呼び出すルーティング層のリクエスト サイズが 50% 削減され、ネットワーク伝送時間が大幅に短縮されました。 4.3 高次元 ID 特徴エンコーディング
5 サンプルの構築
5.1 ストリーミング サンプル

5.1.1 一般的なソリューション
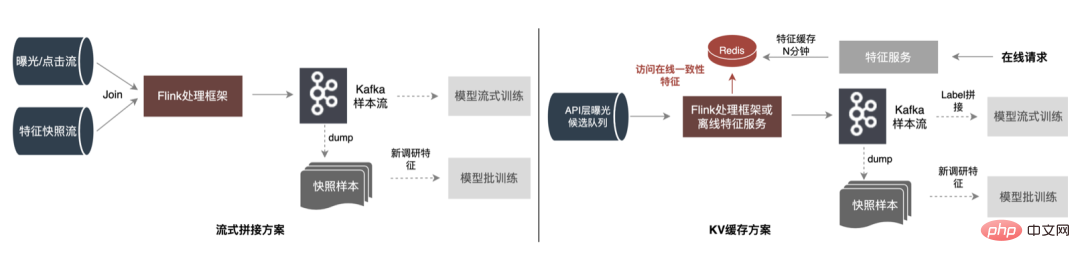
5.1.2 改善と最適化
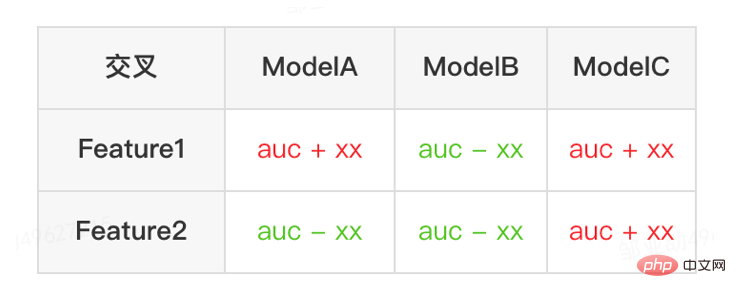
6.2 「引き算」を行う

データバンク
)の構築を提案します。具体的には、以下の図に示すとおりです。
6.4 「除算」を行う
7 概要と展望上記は、大規模な深層学習プロジェクトにおける「増加」防止の実践方法です。ビジネスコストを削減し、効率を向上させます。将来的には、次の側面の探求と実践を続けていきます:
8 この記事の著者
以上がテイクアウト広告向けの大規模深層学習モデルのエンジニアリング実践の詳細内容です。詳細については、PHP 中国語 Web サイトの他の関連記事を参照してください。

ホットAIツール

Undresser.AI Undress
リアルなヌード写真を作成する AI 搭載アプリ

AI Clothes Remover
写真から衣服を削除するオンライン AI ツール。

Undress AI Tool
脱衣画像を無料で

Clothoff.io
AI衣類リムーバー

AI Hentai Generator
AIヘンタイを無料で生成します。

人気の記事
ホットツール

メモ帳++7.3.1
使いやすく無料のコードエディター

SublimeText3 中国語版
中国語版、とても使いやすい

ゼンドスタジオ 13.0.1
強力な PHP 統合開発環境

ドリームウィーバー CS6
ビジュアル Web 開発ツール

SublimeText3 Mac版
神レベルのコード編集ソフト(SublimeText3)
ホットトピック
 7488
7488
 15
1377
52
77
11
19
40
15
1377
52
77
11
19
40

 世界で最も強力なオープンソース MoE モデルが登場。GPT-4 に匹敵する中国語機能を備え、価格は GPT-4-Turbo のわずか 1% 近くです
May 07, 2024 pm 04:13 PM
世界で最も強力なオープンソース MoE モデルが登場。GPT-4 に匹敵する中国語機能を備え、価格は GPT-4-Turbo のわずか 1% 近くです
May 07, 2024 pm 04:13 PM
従来のコンピューティングを超える能力を備えているだけでなく、より低コストでより効率的なパフォーマンスを実現する人工知能モデルを想像してみてください。これは SF ではありません。世界で最も強力なオープンソース MoE モデルである DeepSeek-V2[1] が登場しました。 DeepSeek-V2 は、経済的なトレーニングと効率的な推論の特徴を備えた強力な専門家混合 (MoE) 言語モデルです。これは 236B のパラメータで構成されており、そのうち 21B は各マーカーをアクティブにするために使用されます。 DeepSeek67B と比較して、DeepSeek-V2 はパフォーマンスが優れていると同時に、トレーニング コストを 42.5% 節約し、KV キャッシュを 93.3% 削減し、最大生成スループットを 5.76 倍に高めます。 DeepSeek は一般的な人工知能を研究する会社です
 Meituanの持ち帰りカウンターの入手方法
Apr 08, 2024 pm 03:41 PM
Meituanの持ち帰りカウンターの入手方法
Apr 08, 2024 pm 03:41 PM
1. 配達員が食事をキャビネットに入れると、テキスト メッセージ、電話、または Meituan メッセージを通じて、顧客に食事を受け取るように通知します。 2. 顧客は WeChat または Meituan APP を通じて食品キャビネットの QR コードをスキャンして、スマート食品キャビネット アプレットに入ることができます。 3. ピックアップコードを入力するか、「ワンクリックキャビネットオープン」機能を使用して、簡単にキャビネットのドアを開けてテイクアウトを取り出すことができます。
 AI が数学研究を破壊する!フィールズ賞受賞者で中国系アメリカ人の数学者が上位 11 件の論文を主導 | テレンス・タオが「いいね!」しました
Apr 09, 2024 am 11:52 AM
AI が数学研究を破壊する!フィールズ賞受賞者で中国系アメリカ人の数学者が上位 11 件の論文を主導 | テレンス・タオが「いいね!」しました
Apr 09, 2024 am 11:52 AM
AI は確かに数学を変えつつあります。最近、この問題に細心の注意を払っている陶哲軒氏が『米国数学協会会報』(米国数学協会会報)の最新号を送ってくれた。 「機械は数学を変えるのか?」というテーマを中心に、多くの数学者が意見を述べ、そのプロセス全体は火花に満ち、ハードコアで刺激的でした。著者には、フィールズ賞受賞者のアクシャイ・ベンカテシュ氏、中国の数学者鄭楽軍氏、ニューヨーク大学のコンピューター科学者アーネスト・デイビス氏、その他業界で著名な学者を含む強力な顔ぶれが揃っている。 AI の世界は劇的に変化しています。これらの記事の多くは 1 年前に投稿されたものです。
 こんにちは、電気アトラスです!ボストン・ダイナミクスのロボットが復活、180度の奇妙な動きにマスク氏も恐怖
Apr 18, 2024 pm 07:58 PM
こんにちは、電気アトラスです!ボストン・ダイナミクスのロボットが復活、180度の奇妙な動きにマスク氏も恐怖
Apr 18, 2024 pm 07:58 PM
Boston Dynamics Atlas は正式に電動ロボットの時代に突入します!昨日、油圧式アトラスが歴史の舞台から「涙ながらに」撤退したばかりですが、今日、ボストン・ダイナミクスは電動式アトラスが稼働することを発表しました。ボストン・ダイナミクス社は商用人型ロボットの分野でテスラ社と競争する決意を持っているようだ。新しいビデオが公開されてから、わずか 10 時間ですでに 100 万人以上が視聴しました。古い人が去り、新しい役割が現れるのは歴史的な必然です。今年が人型ロボットの爆発的な年であることは間違いありません。ネットユーザーは「ロボットの進歩により、今年の開会式は人間のように見え、人間よりもはるかに自由度が高い。しかし、これは本当にホラー映画ではないのか?」とコメントした。ビデオの冒頭では、アトラスは仰向けに見えるように地面に静かに横たわっています。次に続くのは驚くべきことです
 MLP に代わる KAN は、オープンソース プロジェクトによって畳み込みまで拡張されました
Jun 01, 2024 pm 10:03 PM
MLP に代わる KAN は、オープンソース プロジェクトによって畳み込みまで拡張されました
Jun 01, 2024 pm 10:03 PM
今月初め、MIT やその他の機関の研究者らは、MLP に代わる非常に有望な代替案である KAN を提案しました。 KAN は、精度と解釈可能性の点で MLP よりも優れています。また、非常に少数のパラメーターを使用して、多数のパラメーターを使用して実行する MLP よりも優れたパフォーマンスを発揮できます。たとえば、著者らは、KAN を使用して、より小規模なネットワークと高度な自動化で DeepMind の結果を再現したと述べています。具体的には、DeepMind の MLP には約 300,000 個のパラメーターがありますが、KAN には約 200 個のパラメーターしかありません。 KAN は、MLP が普遍近似定理に基づいているのに対し、KAN はコルモゴロフ-アーノルド表現定理に基づいているのと同様に、強力な数学的基礎を持っています。以下の図に示すように、KAN は
 Google は大喜び: JAX のパフォーマンスが Pytorch や TensorFlow を上回りました! GPU 推論トレーニングの最速の選択肢となる可能性があります
Apr 01, 2024 pm 07:46 PM
Google は大喜び: JAX のパフォーマンスが Pytorch や TensorFlow を上回りました! GPU 推論トレーニングの最速の選択肢となる可能性があります
Apr 01, 2024 pm 07:46 PM
Google が推進する JAX のパフォーマンスは、最近のベンチマーク テストで Pytorch や TensorFlow のパフォーマンスを上回り、7 つの指標で 1 位にランクされました。また、テストは最高の JAX パフォーマンスを備えた TPU では行われませんでした。ただし、開発者の間では、依然として Tensorflow よりも Pytorch の方が人気があります。しかし、将来的には、おそらくより大規模なモデルが JAX プラットフォームに基づいてトレーニングされ、実行されるようになるでしょう。モデル 最近、Keras チームは、ネイティブ PyTorch 実装を使用して 3 つのバックエンド (TensorFlow、JAX、PyTorch) をベンチマークし、TensorFlow を使用して Keras2 をベンチマークしました。まず、主流のセットを選択します
 美団の支払いパスワードを忘れた場合の回復方法_美団の支払いパスワードを忘れた場合の回復方法
Mar 28, 2024 pm 03:29 PM
美団の支払いパスワードを忘れた場合の回復方法_美団の支払いパスワードを忘れた場合の回復方法
Mar 28, 2024 pm 03:29 PM
1. まず、Meituan ソフトウェアに入り、[マイ メニュー] ページで [設定] を見つけ、クリックして [設定] に入ります。 2. 次に、設定ページで支払い設定を見つけ、クリックして支払い設定を入力します。 3. 支払いセンターに入り、支払いパスワード設定を見つけて、クリックして支払いパスワード設定を入力します。 4. 支払いパスワード設定ページで、支払いパスワードの取得を見つけ、クリックしてページ オプションを入力します。 5. 取得したい支払いパスワード情報を入力し、「確認」をクリックすると、パスワードを通過すると支払いパスワードを取得できます。
 テスラのロボットは工場で働く、マスク氏:手の自由度は今年22に達する!
May 06, 2024 pm 04:13 PM
テスラのロボットは工場で働く、マスク氏:手の自由度は今年22に達する!
May 06, 2024 pm 04:13 PM
テスラのロボット「オプティマス」の最新映像が公開され、すでに工場内で稼働可能となっている。通常の速度では、バッテリー(テスラの4680バッテリー)を次のように分類します:公式は、20倍の速度でどのように見えるかも公開しました - 小さな「ワークステーション」上で、ピッキング、ピッキング、ピッキング:今回は、それがリリースされたハイライトの1つビデオの内容は、オプティマスが工場内でこの作業を完全に自律的に行い、プロセス全体を通じて人間の介入なしに完了するというものです。そして、オプティマスの観点から見ると、自動エラー修正に重点を置いて、曲がったバッテリーを拾い上げたり配置したりすることもできます。オプティマスのハンドについては、NVIDIA の科学者ジム ファン氏が高く評価しました。オプティマスのハンドは、世界の 5 本指ロボットの 1 つです。最も器用。その手は触覚だけではありません
