

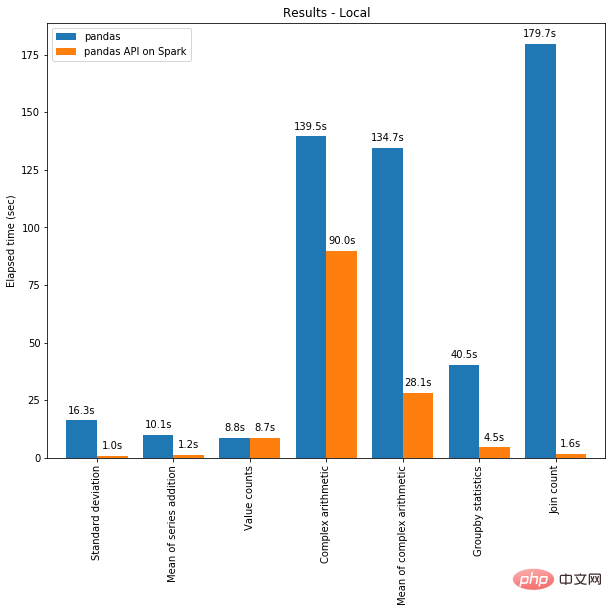
Pandas と PySpark が連携して、機能性と速度の両方を実現します。

データ処理に Python を使用するデータ サイエンティストやデータ実務者は、データ サイエンス パッケージ pandas に馴染みがあり、Yun Duojun のような pandas のヘビー ユーザーもいます。コードの最初の行のほとんどはプロジェクトの開始時に書かれています。パンダを pd としてインポートします。 Pandas はデータ処理の yyds と言えます。欠点も非常に明白で、パンダは 1 台のマシンでしか処理できず、データ量に応じて線形に拡張できません。たとえば、パンダがマシンの利用可能なメモリよりも大きいデータ セットを読み取ろうとすると、メモリ不足により失敗します。
さらに、pandas は大規模なデータの処理が非常に遅いため、データ処理速度を最適化して向上させるための Dask や Vaex などのライブラリは他にもありますが、Spark という神フレームワークの前では朝飯前です。ビッグデータ処理。
幸いなことに、新しい Spark 3.2 バージョンでは、新しい Pandas API が登場し、ほとんどの pandas 関数が PySpark に統合されています。Spark には Pandas API が Spark を使用しているため、pandas インターフェイスを使用すると、Spark を使用できます。バックグラウンドで強力な協力の効果を達成できるため、非常に強力で非常に便利であると言えます。
すべては Spark AI Summit 2019 から始まりました。 Koalas は、Spark 上で Pandas を使用するオープンソース プロジェクトです。当初は Pandas の機能のほんの一部しかカバーしていませんでしたが、徐々に規模が大きくなっていきました。新しい Spark 3.2 バージョンでは、Koalas が PySpark に統合されました。
Spark に Pandas API が統合されたため、Spark 上で Pandas を実行できるようになりました。変更する必要があるコードは 1 行だけです:
import pyspark.pandas as ps
これにより、多くの利点が得られます:
- Python と Pandas の使用には慣れているが、Spark には詳しくない場合、複雑さを省略できますので、学習プロセスにすぐに PySpark を使い始めてください。
- 小規模データとビッグデータ、単一マシンと分散マシンなど、すべてに 1 つのコード ベースを使用できます。
- Spark 分散フレームワークでは、Pandas コードをより速く実行できます。
# import Pandas-on-Spark import pyspark.pandas as ps # 使用 Pandas-on-Spark 创建一个 DataFrame ps_df = ps.DataFrame(range(10)) # 将 Pandas-on-Spark Dataframe 转换为 Pandas Dataframe pd_df = ps_df.to_pandas() # 将 Pandas Dataframe 转换为 Pandas-on-Spark Dataframe ps_df = ps.from_pandas(pd_df)
# 使用 Pandas-on-Spark 创建一个 DataFrame ps_df = ps.DataFrame(range(10)) # 将 Pandas-on-Spark Dataframe 转换为 Spark Dataframe spark_df = ps_df.to_spark() # 将 Spark Dataframe 转换为 Pandas-on-Spark Dataframe ps_df_new = spark_df.to_pandas_on_spark()
>>> sdf = spark.createDataFrame([ ... (1, Decimal(1.0), 1., 1., 1, 1, 1, datetime(2020, 10, 27), "1", True, datetime(2020, 10, 27)), ... ], 'tinyint tinyint, decimal decimal, float float, double double, integer integer, long long, short short, timestamp timestamp, string string, boolean boolean, date date') >>> sdf
DataFrame[tinyint: tinyint, decimal: decimal(10,0), float: float, double: double, integer: int, long: bigint, short: smallint, timestamp: timestamp, string: string, boolean: boolean, date: date]
psdf = sdf.pandas_api() psdf.dtypes
tinyintint8 decimalobject float float32 doublefloat64 integer int32 longint64 short int16 timestampdatetime64[ns] string object booleanbool date object dtype: object
当你看完如下内容后,你会发现,即使您不熟悉 Spark,也可以通过 Pandas API 轻松使用。
导入库
# 运行Spark
from pyspark.sql import SparkSession
spark = SparkSession.builder
.appName("Spark")
.getOrCreate()
# 在Spark上运行Pandas
import pyspark.pandas as ps读取数据
以 old dog iris 数据集为例。
# SPARK
sdf = spark.read.options(inferSchema='True',
header='True').csv('iris.csv')
# PANDAS-ON-SPARK
pdf = ps.read_csv('iris.csv')选择
# SPARK
sdf.select("sepal_length","sepal_width").show()
# PANDAS-ON-SPARK
pdf[["sepal_length","sepal_width"]].head()删除列
# SPARK
sdf.drop('sepal_length').show()# PANDAS-ON-SPARK
pdf.drop('sepal_length').head()删除重复项
# SPARK sdf.dropDuplicates(["sepal_length","sepal_width"]).show() # PANDAS-ON-SPARK pdf[["sepal_length", "sepal_width"]].drop_duplicates()
筛选
# SPARK sdf.filter( (sdf.flower_type == "Iris-setosa") & (sdf.petal_length > 1.5) ).show() # PANDAS-ON-SPARK pdf.loc[ (pdf.flower_type == "Iris-setosa") & (pdf.petal_length > 1.5) ].head()
计数
# SPARK sdf.filter(sdf.flower_type == "Iris-virginica").count() # PANDAS-ON-SPARK pdf.loc[pdf.flower_type == "Iris-virginica"].count()
唯一值
# SPARK
sdf.select("flower_type").distinct().show()
# PANDAS-ON-SPARK
pdf["flower_type"].unique()排序
# SPARK
sdf.sort("sepal_length", "sepal_width").show()
# PANDAS-ON-SPARK
pdf.sort_values(["sepal_length", "sepal_width"]).head()分组
# SPARK
sdf.groupBy("flower_type").count().show()
# PANDAS-ON-SPARK
pdf.groupby("flower_type").count()替换
# SPARK
sdf.replace("Iris-setosa", "setosa").show()
# PANDAS-ON-SPARK
pdf.replace("Iris-setosa", "setosa").head()连接
#SPARK sdf.union(sdf) # PANDAS-ON-SPARK pdf.append(pdf)
transform 和 apply 函数应用
有许多 API 允许用户针对 pandas-on-Spark DataFrame 应用函数,例如:
DataFrame.transform() DataFrame.apply() DataFrame.pandas_on_spark.transform_batch() DataFrame.pandas_on_spark.apply_batch() Series.pandas_on_spark.transform_batch()
每个 API 都有不同的用途,并且在内部工作方式不同。
transform 和 apply
DataFrame.transform()和DataFrame.apply()之间的主要区别在于,前者需要返回相同长度的输入,而后者不需要。
# transform
psdf = ps.DataFrame({'a': [1,2,3], 'b':[4,5,6]})
def pandas_plus(pser):
return pser + 1# 应该总是返回与输入相同的长度。
psdf.transform(pandas_plus)
# apply
psdf = ps.DataFrame({'a': [1,2,3], 'b':[5,6,7]})
def pandas_plus(pser):
return pser[pser % 2 == 1]# 允许任意长度
psdf.apply(pandas_plus)在这种情况下,每个函数采用一个 pandas Series,Spark 上的 pandas API 以分布式方式计算函数,如下所示。
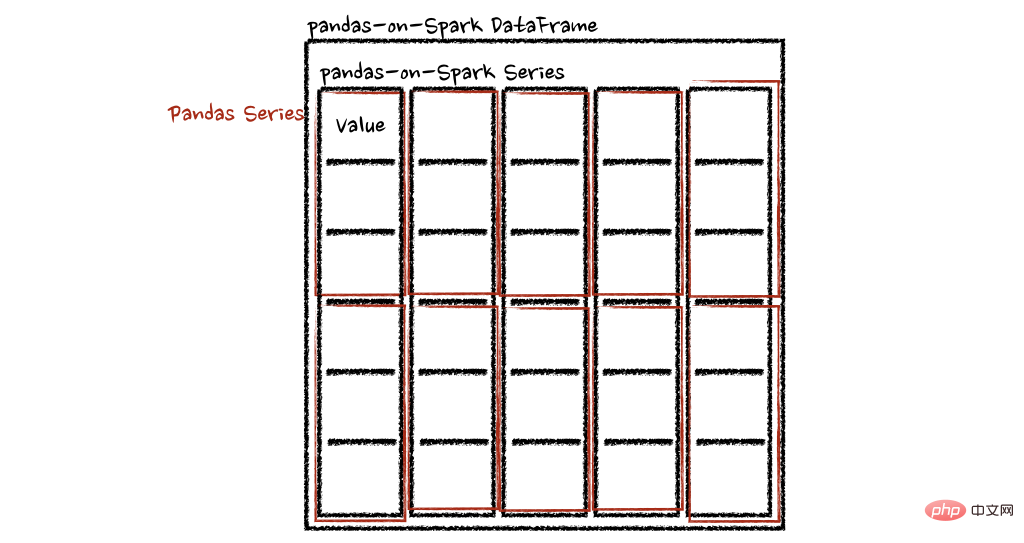
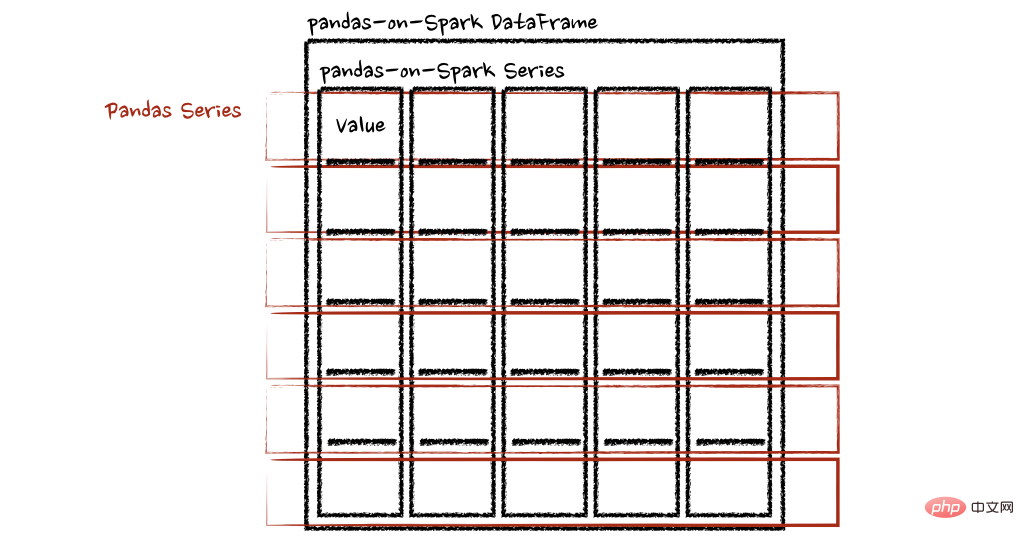
在“列”轴的情况下,该函数将每一行作为一个熊猫系列。
psdf = ps.DataFrame({'a': [1,2,3], 'b':[4,5,6]})
def pandas_plus(pser):
return sum(pser)# 允许任意长度
psdf.apply(pandas_plus, axis='columns')上面的示例将每一行的总和计算为pands Series
pandas_on_spark.transform_batch和pandas_on_spark.apply_batch
batch 后缀表示 pandas-on-Spark DataFrame 或 Series 中的每个块。API 对 pandas-on-Spark DataFrame 或 Series 进行切片,然后以 pandas DataFrame 或 Series 作为输入和输出应用给定函数。请参阅以下示例:
psdf = ps.DataFrame({'a': [1,2,3], 'b':[4,5,6]})
def pandas_plus(pdf):
return pdf + 1# 应该总是返回与输入相同的长度。
psdf.pandas_on_spark.transform_batch(pandas_plus)
psdf = ps.DataFrame({'a': [1,2,3], 'b':[4,5,6]})
def pandas_plus(pdf):
return pdf[pdf.a > 1]# 允许任意长度
psdf.pandas_on_spark.apply_batch(pandas_plus)两个示例中的函数都将 pandas DataFrame 作为 pandas-on-Spark DataFrame 的一个块,并输出一个 pandas DataFrame。Spark 上的 Pandas API 将 pandas 数据帧组合为 pandas-on-Spark 数据帧。
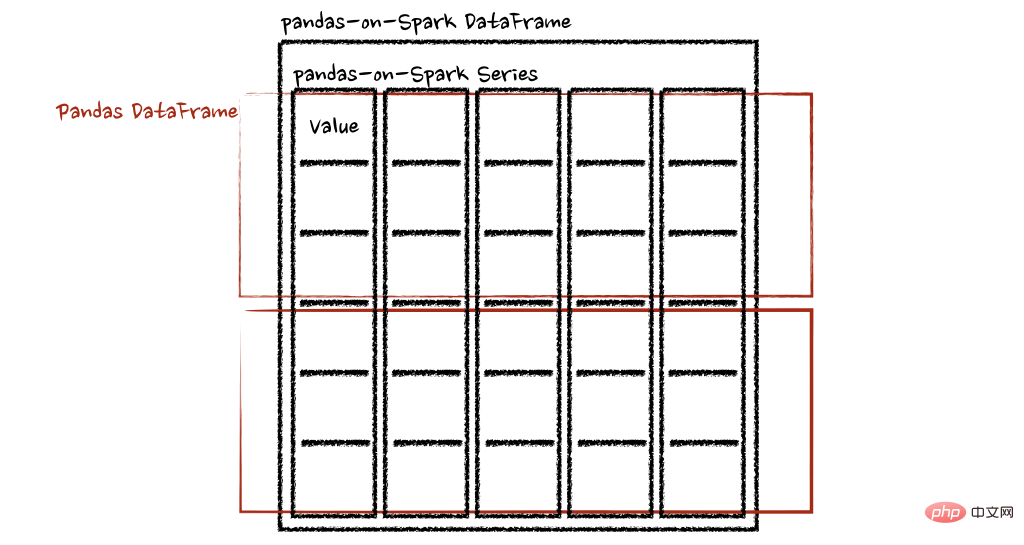
在 Spark 上使用 pandas API的注意事项
避免shuffle
某些操作,例如sort_values在并行或分布式环境中比在单台机器上的内存中更难完成,因为它需要将数据发送到其他节点,并通过网络在多个节点之间交换数据。
避免在单个分区上计算
另一种常见情况是在单个分区上进行计算。目前, DataFrame.rank 等一些 API 使用 PySpark 的 Window 而不指定分区规范。这会将所有数据移动到单个机器中的单个分区中,并可能导致严重的性能下降。对于非常大的数据集,应避免使用此类 API。
不要使用重复的列名
不允许使用重复的列名,因为 Spark SQL 通常不允许这样做。Spark 上的 Pandas API 继承了这种行为。例如,见下文:
import pyspark.pandas as ps
psdf = ps.DataFrame({'a': [1, 2], 'b':[3, 4]})
psdf.columns = ["a", "a"]Reference 'a' is ambiguous, could be: a, a.;
此外,强烈建议不要使用区分大小写的列名。Spark 上的 Pandas API 默认不允许它。
import pyspark.pandas as ps
psdf = ps.DataFrame({'a': [1, 2], 'A':[3, 4]})Reference 'a' is ambiguous, could be: a, a.;
但可以在 Spark 配置spark.sql.caseSensitive中打开以启用它,但需要自己承担风险。
from pyspark.sql import SparkSession
builder = SparkSession.builder.appName("pandas-on-spark")
builder = builder.config("spark.sql.caseSensitive", "true")
builder.getOrCreate()
import pyspark.pandas as ps
psdf = ps.DataFrame({'a': [1, 2], 'A':[3, 4]})
psdfaA 013 124
使用默认索引
pandas-on-Spark 用户面临的一个常见问题是默认索引导致性能下降。当索引未知时,Spark 上的 Pandas API 会附加一个默认索引,例如 Spark DataFrame 直接转换为 pandas-on-Spark DataFrame。
如果计划在生产中处理大数据,请通过将默认索引配置为distributed或distributed-sequence来使其确保为分布式。
有关配置默认索引的更多详细信息,请参阅默认索引类型[3]。
在 Spark 上使用 pandas API
尽管 Spark 上的 pandas API 具有大部分与 pandas 等效的 API,但仍有一些 API 尚未实现或明确不受支持。因此尽可能直接在 Spark 上使用 pandas API。
例如,Spark 上的 pandas API 没有实现__iter__(),阻止用户将所有数据从整个集群收集到客户端(驱动程序)端。不幸的是,许多外部 API,例如 min、max、sum 等 Python 的内置函数,都要求给定参数是可迭代的。对于 pandas,它开箱即用,如下所示:
>>> import pandas as pd >>> max(pd.Series([1, 2, 3])) 3 >>> min(pd.Series([1, 2, 3])) 1 >>> sum(pd.Series([1, 2, 3])) 6
Pandas 数据集存在于单台机器中,自然可以在同一台机器内进行本地迭代。但是,pandas-on-Spark 数据集存在于多台机器上,并且它们是以分布式方式计算的。很难在本地迭代,很可能用户在不知情的情况下将整个数据收集到客户端。因此,最好坚持使用 pandas-on-Spark API。上面的例子可以转换如下:
>>> import pyspark.pandas as ps >>> ps.Series([1, 2, 3]).max() 3 >>> ps.Series([1, 2, 3]).min() 1 >>> ps.Series([1, 2, 3]).sum() 6
pandas 用户的另一个常见模式可能是依赖列表推导式或生成器表达式。但是,它还假设数据集在引擎盖下是本地可迭代的。因此,它可以在 pandas 中无缝运行,如下所示:
import pandas as pd data = [] countries = ['London', 'New York', 'Helsinki'] pser = pd.Series([20., 21., 12.], index=countries) for temperature in pser: assert temperature > 0 if temperature > 1000: temperature = None data.append(temperature ** 2) pd.Series(data, index=countries)
London400.0 New York441.0 Helsinki144.0 dtype: float64
但是,对于 Spark 上的 pandas API,它的工作原理与上述相同。上面的示例也可以更改为直接使用 pandas-on-Spark API,如下所示:
import pyspark.pandas as ps import numpy as np countries = ['London', 'New York', 'Helsinki'] psser = ps.Series([20., 21., 12.], index=countries) def square(temperature) -> np.float64: assert temperature > 0 if temperature > 1000: temperature = None return temperature ** 2 psser.apply(square)
London400.0 New York441.0 Helsinki144.0
减少对不同 DataFrame 的操作
Spark 上的 Pandas API 默认不允许对不同 DataFrame(或 Series)进行操作,以防止昂贵的操作。只要有可能,就应该避免这种操作。
写在最后
到目前为止,我们将能够在 Spark 上使用 Pandas。这将会导致Pandas 速度的大大提高,迁移到 Spark 时学习曲线的减少,以及单机计算和分布式计算在同一代码库中的合并。
参考资料
[1]PySpark 指南: https://spark.apache.org/docs/latest/api/python/user_guide/pandas_on_spark/pandas_pyspark.html
[2]PySpark 指南: https://spark.apache.org/docs/latest/api/python/user_guide/pandas_on_spark/types.html
[3]默认索引类型: https://spark.apache.org/docs/latest/api/python/user_guide/pandas_on_spark/options.html#default-index-type
以上がPandas と PySpark が連携して、機能性と速度の両方を実現します。の詳細内容です。詳細については、PHP 中国語 Web サイトの他の関連記事を参照してください。

ホットAIツール

Undresser.AI Undress
リアルなヌード写真を作成する AI 搭載アプリ

AI Clothes Remover
写真から衣服を削除するオンライン AI ツール。

Undress AI Tool
脱衣画像を無料で

Clothoff.io
AI衣類リムーバー

AI Hentai Generator
AIヘンタイを無料で生成します。

人気の記事
ホットツール

メモ帳++7.3.1
使いやすく無料のコードエディター

SublimeText3 中国語版
中国語版、とても使いやすい

ゼンドスタジオ 13.0.1
強力な PHP 統合開発環境

ドリームウィーバー CS6
ビジュアル Web 開発ツール

SublimeText3 Mac版
神レベルのコード編集ソフト(SublimeText3)
ホットトピック
 7461
7461
 15
1376
52
77
11
17
17
15
1376
52
77
11
17
17

 一般的なパンダのインストール問題の解決: インストール エラーの解釈と解決策
Feb 19, 2024 am 09:19 AM
一般的なパンダのインストール問題の解決: インストール エラーの解釈と解決策
Feb 19, 2024 am 09:19 AM
Pandas インストール チュートリアル: 一般的なインストール エラーとその解決策の分析、特定のコード サンプルが必要です はじめに: Pandas は、データ クリーニング、データ処理、およびデータ視覚化で広く使用されている強力なデータ分析ツールであるため、この分野で高く評価されていますデータサイエンスのただし、環境構成と依存関係の問題により、パンダのインストール時に問題やエラーが発生する可能性があります。この記事では、パンダのインストール チュートリアルを提供し、いくつかの一般的なインストール エラーとその解決策を分析します。 1.パンダをインストールする
 Pythonパンダのインストール方法
Nov 22, 2023 pm 02:33 PM
Pythonパンダのインストール方法
Nov 22, 2023 pm 02:33 PM
Python は、pip を使用するか、conda を使用するか、ソース コードから、および IDE 統合パッケージ管理ツールを使用してパンダをインストールできます。詳細な紹介: 1. pip を使用し、ターミナルまたはコマンド プロンプトで pip install pandas コマンドを実行してパンダをインストールします; 2. conda を使用し、ターミナルまたはコマンド プロンプトで conda install pandas コマンドを実行してパンダをインストールします; 3. ソース コードからインストールなど。
 CSV ファイルを読み取り、pandas を使用してデータ分析を実行する
Jan 09, 2024 am 09:26 AM
CSV ファイルを読み取り、pandas を使用してデータ分析を実行する
Jan 09, 2024 am 09:26 AM
Pandas は、さまざまな種類のデータ ファイルを簡単に読み取り、処理できる強力なデータ分析ツールです。その中でも、CSV ファイルは最も一般的でよく使用されるデータ ファイル形式の 1 つです。この記事では、Pandas を使用して CSV ファイルを読み取り、データ分析を実行する方法と、具体的なコード例を紹介します。 1. 必要なライブラリをインポートする まず、以下に示すように、Pandas ライブラリと必要になる可能性のあるその他の関連ライブラリをインポートする必要があります。 importpandasaspd 2. Pan を使用して CSV ファイルを読み取ります。
 Pythonでパンダをインストールする方法
Dec 04, 2023 pm 02:48 PM
Pythonでパンダをインストールする方法
Dec 04, 2023 pm 02:48 PM
Python でパンダをインストールする手順: 1. ターミナルまたはコマンド プロンプトを開きます; 2. 「pip install pandas」コマンドを入力してパンダ ライブラリをインストールします; 3. インストールが完了するまで待ちます。パンダ ライブラリをインポートして使用できるようになりますPython スクリプト内; 4. 使用する 特定の仮想環境です。パンダをインストールする前に、対応する仮想環境をアクティブにしてください; 5. 統合開発環境を使用している場合は、「import pandas as pd」コードをパンダライブラリをインポートします。
 pandasを使用してtxtファイルを正しく読み取る方法
Jan 19, 2024 am 08:39 AM
pandasを使用してtxtファイルを正しく読み取る方法
Jan 19, 2024 am 08:39 AM
pandas を使用して txt ファイルを正しく読み取る方法には、特定のコード サンプルが必要です。パンダは、広く使用されている Python データ分析ライブラリです。CSV ファイル、Excel ファイル、SQL データベースなど、さまざまな種類のデータの処理に使用できます。同時に、txt ファイルなどのテキスト ファイルを読み取るために使用することもできます。ただし、txt ファイルを読み取るときに、エンコードの問題や区切り文字の問題など、いくつかの問題が発生することがあります。この記事ではパンダを使ってtxtを正しく読む方法を紹介します。
 pandas を使用して txt ファイルを読み取るための実践的なヒント
Jan 19, 2024 am 09:49 AM
pandas を使用して txt ファイルを読み取るための実践的なヒント
Jan 19, 2024 am 09:49 AM
pandas を使用して txt ファイルを読み取るための実践的なヒント、具体的なコード例が必要です データ分析とデータ処理では、txt ファイルは一般的なデータ形式です。 pandas を使用して txt ファイルを読み取ると、高速で便利なデータ処理が可能になります。この記事では、パンダをより効果的に使用して txt ファイルを読み取るのに役立ついくつかの実践的なテクニックを、具体的なコード例とともに紹介します。区切り文字付きの txt ファイルの読み取りパンダを使用して区切り文字付きの txt ファイルを読み取る場合は、read_c を使用できます。
 Pandas は SQL データベースからデータを簡単に読み取ります
Jan 09, 2024 pm 10:45 PM
Pandas は SQL データベースからデータを簡単に読み取ります
Jan 09, 2024 pm 10:45 PM
データ処理ツール: Pandas は SQL データベース内のデータを読み取り、特定のコード サンプルが必要です。データ量が増加し続け、その複雑さが増すにつれて、データ処理は現代社会の重要な部分となっています。データ処理プロセスにおいて、Pandas は多くのデータ アナリストや科学者にとって好まれるツールの 1 つとなっています。この記事では、Pandas ライブラリを使用して SQL データベースからデータを読み取る方法を紹介し、いくつかの具体的なコード例を示します。 Pandas は、Python をベースにした強力なデータ処理および分析ツールです。
 Pandas の効率的なデータ重複排除方法を明らかに: 重複データをすばやく削除するためのヒント
Jan 24, 2024 am 08:12 AM
Pandas の効率的なデータ重複排除方法を明らかに: 重複データをすばやく削除するためのヒント
Jan 24, 2024 am 08:12 AM
Pandas 重複排除メソッドの秘密: データを重複排除するための高速かつ効率的な方法 (特定のコード例が必要) データの分析と処理のプロセスでは、データの重複が頻繁に発生します。データが重複すると分析結果が誤解される可能性があるため、重複排除は非常に重要な手順です。強力なデータ処理ライブラリである Pandas では、データ重複排除を実現するためのさまざまな方法が提供されています。この記事では、一般的に使用されるいくつかの重複排除方法を紹介し、具体的なコード例を添付します。単一列に基づく重複排除の最も一般的なケースは、特定の列の値が重複しているかどうかに基づいています。
