

Javaでプロセスオーケストレーションフレームワークを実装する方法

プロセス登録
先ほど、yml、プロパティ、xml、json、インターフェイスの形式でプロセス モデルの登録をサポートする必要があると述べました。 , 形式を使用する必要があります 解析ロジックは独立して処理されます 拡張開発と変更クロージャの原則を反映するために , まずインターフェイスのセットを定義し、次に対応する実装ロジックを提供しますファクトリ モデルを使用します。ここでのファクトリは、ユーザーがインターフェイスを通じて特定の実装を呼び出します。ここでの実装はプロバイダであり、戦略パターンのセットでもあります。
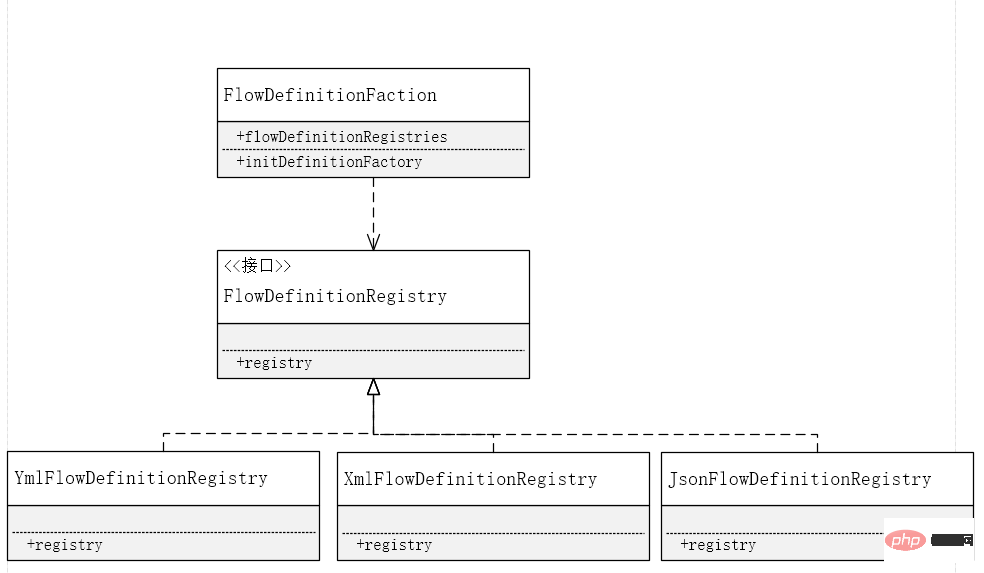
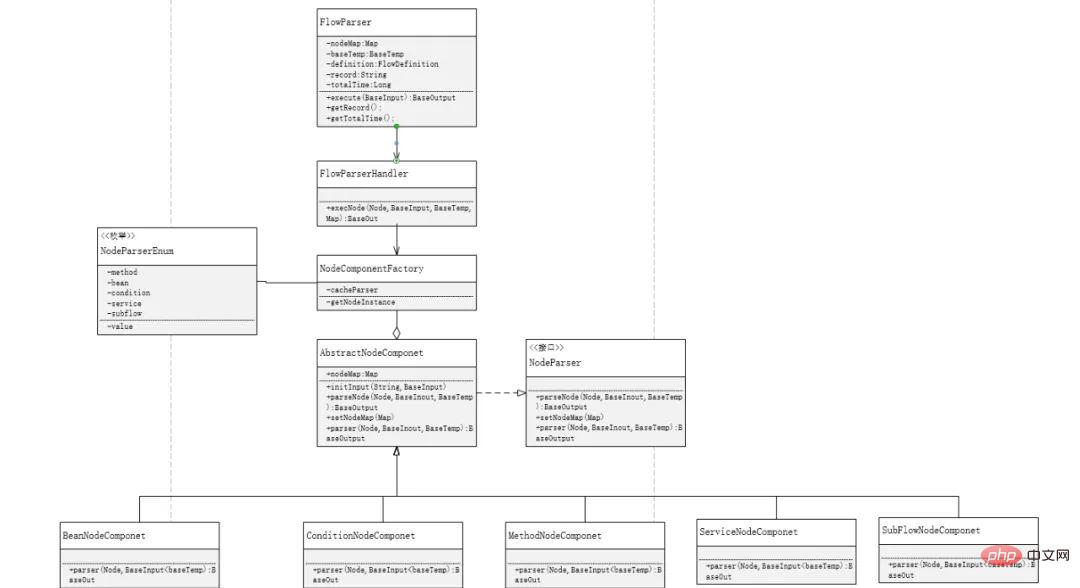
ファクトリー モードを使用する必要があることは明らかです。 # #外部拡張開発は変更のため終了しています。ノードを追加するとき、他のコード ロジックに触れる必要はありません。ファクトリ関数にノード パーサーを追加するだけで済みます。同時に、Map コレクションを定義します。ここでは、ファクトリ関数をロードするときに解析オブジェクトを使用します。解析するたびにパーサーを作成する代わりに、不要なメモリを削減するために作成します。コードは次のとおりです:
<code>public class NodeComponentFactory {<br><br> private final static Map<string> cacheParser = new HashMap();<br><br> static {<br> cacheParser.put(NodeParserEnum.method.name(),new MethodNodeComponent());<br> cacheParser.put(NodeParserEnum.bean.name(),new BeanNodeComponent());<br> cacheParser.put(NodeParserEnum.condition.name(),new ConditionNodeComponent());<br> cacheParser.put(NodeParserEnum.service.name(),new ServiceNodeComponent());<br> cacheParser.put(NodeParserEnum.subflow.name(),new SubFlowNodeComponent());<br> }<br><br> public static NodeParser getNodeInstance(String nodeName){<br> return cacheParser.get(nodeName);<br> }<br>}<br></string></code>When we find各ノードの解析タイプはパーサー インターフェイスを実装する必要があり、各ノードには同様の手順があるため、ここでは抽象ファクトリーの使用を検討する必要があり、これは
Dependency Inversion の設計原則にも準拠しています。依存関係インターフェイスを介して次のモジュールが抽象化クラスを継承し、インターフェイス呼び出しを行うために Strategy Pattern も使用します。実装の論理プロセスでは、パラメーターの初期化など、多くの手順が繰り返されることがわかります。レコードを実行するため、繰り返しのコンテンツを抽象クラスに置きます。テンプレート モードを介して、プロセス ノードは解析レベルのみに焦点を当てます。<code>public abstract class AbstractNodeComponent implements NodeParser{<br><br> public Map<string node> nodeMap;<br><br><br> /**<br> * 初始化参数<br> * @param inputUrl<br> * @param baseInput<br> * @return<br> */<br> public BaseInput initInput(String inputUrl, BaseInput baseInput){<br> BaseInput baseInputTarget = ClassUtil.newInstance(inputUrl, BaseInput.class);<br> BeanUtils.copyProperties(baseInput,baseInputTarget);<br> return baseInputTarget;<br> }<br><br><br> /**<br> * 解析节点信息<br> * @param node 节点信息<br> * @param baseInput 请求参数<br> * @param baseTemp 临时上下文<br> * @return<br> */<br> public BaseOutput parserNode(Node node, BaseInput baseInput, BaseTemp baseTemp){<br> baseTemp.setFlowRecord(baseTemp.getFlowRecord().append(FlowConstants.NODEKEY+FlowConstants.NODE+FlowConstants.COLON+node.getId()));<br> BaseOutput baseOutput = parser(node, baseInput, baseTemp);<br> return baseOutput;<br> };<br><br> @Override<br> public void setNodeMap(Map<string node> nodeMap) {<br> this.nodeMap = nodeMap;<br> }<br><br> @Override<br> public abstract BaseOutput parser(Node node, BaseInput baseInput, BaseTemp baseTemp);<br><br>}</string></string></code>
プロセスの実行にはコンポーネントを非常に細かく分割する必要があり、できれば機能を独立して実装するクラスをコンポーネントに分割し、
単一責任原則を体現する必要があります。プロセス実行の各プロセスで柔軟に組み合わせることができます; 以下のフローチャートでは、いくつかのコンポーネントを見ると、最初のコンポーネントはプロセスを統合して実行するための入り口であり、2 か所で使用されます。 、2番目はサブプロセス実行の入り口、2番目のコンポーネントは管理コンポーネントを均一にロードするノードであり、前述のファクトリクラスです、3番目は各コンポーネント独自のパーサーであり、操作の実装に使用されます設計プロセスでは、プロセス、管理、およびノード間の関係を知る必要があります。コンポーネント間の境界により結合が軽減されるため、異なるコンポーネントを柔軟に構成できます。
以上がJavaでプロセスオーケストレーションフレームワークを実装する方法の詳細内容です。詳細については、PHP 中国語 Web サイトの他の関連記事を参照してください。

ホットAIツール

Undresser.AI Undress
リアルなヌード写真を作成する AI 搭載アプリ

AI Clothes Remover
写真から衣服を削除するオンライン AI ツール。

Undress AI Tool
脱衣画像を無料で

Clothoff.io
AI衣類リムーバー

Video Face Swap
完全無料の AI 顔交換ツールを使用して、あらゆるビデオの顔を簡単に交換できます。

人気の記事
ホットツール

メモ帳++7.3.1
使いやすく無料のコードエディター

SublimeText3 中国語版
中国語版、とても使いやすい

ゼンドスタジオ 13.0.1
強力な PHP 統合開発環境

ドリームウィーバー CS6
ビジュアル Web 開発ツール

SublimeText3 Mac版
神レベルのコード編集ソフト(SublimeText3)
ホットトピック
 7704
7704
 15
1640
14
1394
52
1288
25
1231
29
15
1640
14
1394
52
1288
25
1231
29


 Java Springのインタビューの質問
Aug 30, 2024 pm 04:29 PM
Java Springのインタビューの質問
Aug 30, 2024 pm 04:29 PM
この記事では、Java Spring の面接で最もよく聞かれる質問とその詳細な回答をまとめました。面接を突破できるように。
 Java 8 Stream Foreachから休憩または戻ってきますか?
Feb 07, 2025 pm 12:09 PM
Java 8 Stream Foreachから休憩または戻ってきますか?
Feb 07, 2025 pm 12:09 PM
Java 8は、Stream APIを導入し、データ収集を処理する強力で表現力のある方法を提供します。ただし、ストリームを使用する際の一般的な質問は次のとおりです。 従来のループにより、早期の中断やリターンが可能になりますが、StreamのForeachメソッドはこの方法を直接サポートしていません。この記事では、理由を説明し、ストリーム処理システムに早期終了を実装するための代替方法を調査します。 さらに読み取り:JavaストリームAPIの改善 ストリームを理解してください Foreachメソッドは、ストリーム内の各要素で1つの操作を実行する端末操作です。その設計意図はです
 Java での日付までのタイムスタンプ
Aug 30, 2024 pm 04:28 PM
Java での日付までのタイムスタンプ
Aug 30, 2024 pm 04:28 PM
Java での日付までのタイムスタンプに関するガイド。ここでは、Java でタイムスタンプを日付に変換する方法とその概要について、例とともに説明します。
 カプセルの量を見つけるためのJavaプログラム
Feb 07, 2025 am 11:37 AM
カプセルの量を見つけるためのJavaプログラム
Feb 07, 2025 am 11:37 AM
カプセルは3次元の幾何学的図形で、両端にシリンダーと半球で構成されています。カプセルの体積は、シリンダーの体積と両端に半球の体積を追加することで計算できます。このチュートリアルでは、さまざまな方法を使用して、Javaの特定のカプセルの体積を計算する方法について説明します。 カプセルボリュームフォーミュラ カプセルボリュームの式は次のとおりです。 カプセル体積=円筒形の体積2つの半球体積 で、 R:半球の半径。 H:シリンダーの高さ(半球を除く)。 例1 入力 RADIUS = 5ユニット 高さ= 10単位 出力 ボリューム= 1570.8立方ユニット 説明する 式を使用してボリュームを計算します。 ボリューム=π×R2×H(4
 PHP対Python:違いを理解します
Apr 11, 2025 am 12:15 AM
PHP対Python:違いを理解します
Apr 11, 2025 am 12:15 AM
PHP and Python each have their own advantages, and the choice should be based on project requirements. 1.PHPは、シンプルな構文と高い実行効率を備えたWeb開発に適しています。 2。Pythonは、簡潔な構文とリッチライブラリを備えたデータサイエンスと機械学習に適しています。
 PHP:Web開発の重要な言語
Apr 13, 2025 am 12:08 AM
PHP:Web開発の重要な言語
Apr 13, 2025 am 12:08 AM
PHPは、サーバー側で広く使用されているスクリプト言語で、特にWeb開発に適しています。 1.PHPは、HTMLを埋め込み、HTTP要求と応答を処理し、さまざまなデータベースをサポートできます。 2.PHPは、ダイナミックWebコンテンツ、プロセスフォームデータ、アクセスデータベースなどを生成するために使用され、強力なコミュニティサポートとオープンソースリソースを備えています。 3。PHPは解釈された言語であり、実行プロセスには語彙分析、文法分析、編集、実行が含まれます。 4.PHPは、ユーザー登録システムなどの高度なアプリケーションについてMySQLと組み合わせることができます。 5。PHPをデバッグするときは、error_reporting()やvar_dump()などの関数を使用できます。 6. PHPコードを最適化して、キャッシュメカニズムを使用し、データベースクエリを最適化し、組み込み関数を使用します。 7
 未来を創る: まったくの初心者のための Java プログラミング
Oct 13, 2024 pm 01:32 PM
未来を創る: まったくの初心者のための Java プログラミング
Oct 13, 2024 pm 01:32 PM
Java は、初心者と経験豊富な開発者の両方が学習できる人気のあるプログラミング言語です。このチュートリアルは基本的な概念から始まり、高度なトピックに進みます。 Java Development Kit をインストールしたら、簡単な「Hello, World!」プログラムを作成してプログラミングを練習できます。コードを理解したら、コマンド プロンプトを使用してプログラムをコンパイルして実行すると、コンソールに「Hello, World!」と出力されます。 Java の学習はプログラミングの旅の始まりであり、習熟が深まるにつれて、より複雑なアプリケーションを作成できるようになります。
