

Python で loguru ログ ライブラリを使用する方法

1. 概要
pythonlogging のログ ライブラリは log4j に似ていますが、通常、設定はより複雑です。構築ログ サーバーも不便です。標準ライブラリ logging の代わりとなるのは loguru で、より簡単に使用できます。
デフォルトの出力形式は、時間、レベル、モジュール、行番号、ログの内容です。 loguru logger を手動で作成する必要はなく、すぐに使用でき、logging よりもはるかに使いやすく、さらにログ出力カラー機能と非カラー機能が組み込まれています。コントロールは非常に便利で、よりフレンドリーです。
は非標準ライブラリなので、事前にインストールする必要があります。コマンドは **pip3 install loguru**** です。 **インストール後の最も簡単な使用例は次のとおりです: <div class="code" style="position:relative; padding:0px; margin:0px;"><pre class='brush:php;toolbar:false;'>from loguru import logger
logger.debug(&#39;hello, this debug loguru&#39;)
logger.info(&#39;hello, this is info loguru&#39;)
logger.warning(&#39;hello, this is warning loguru&#39;)
logger.error(&#39;hello, this is error loguru&#39;)
logger.critical(&#39;hello, this is critical loguru&#39;)</pre><div class="contentsignin">ログイン後にコピー</div></div>上記のコード出力:
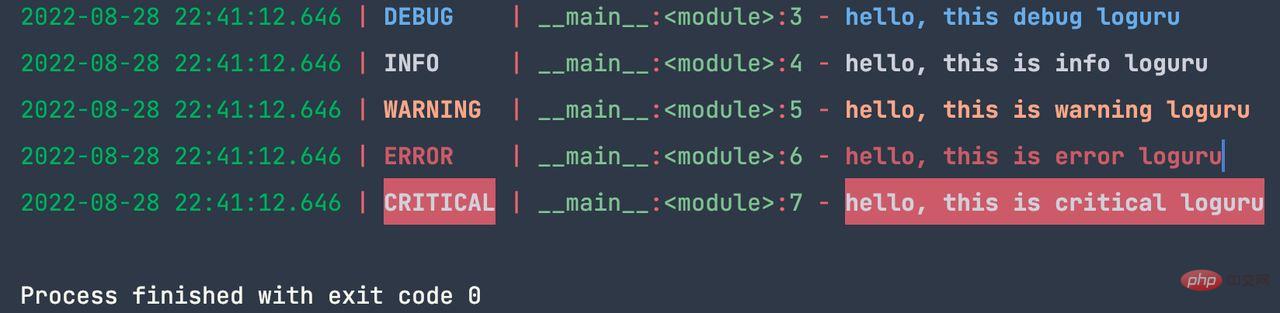 ファイルへのログ出力の使用法も非常に便利です。単純なコードは次のとおりです。
ファイルへのログ出力の使用法も非常に便利です。単純なコードは次のとおりです。
from loguru import logger logger.add('myloguru.log') logger.debug('hello, this debug loguru') logger.info('hello, this is info loguru') logger.warning('hello, this is warning loguru') logger.error('hello, this is error loguru') logger.critical('hello, this is critical loguru')
上記のコードを実行すると、コンソールまたはファイルに出力できます。
#2. 一般的な使用法
loguru
デフォルトの形式は、時間、レベル、 name モジュールとログの内容、name モジュールはハードコーディングされており、現在のファイルの__name__ 変数です。この変数は変更しないことをお勧めします。 プロジェクトがより複雑な場合、モジュール名をカスタマイズすると非常に便利です。これにより、定義と配置が簡単になり、詳細に行き詰まることがなくなります。 logger.configure
import sys
from loguru import logger
logger.configure(handlers=[
{
"sink": sys.stderr,
"format": "{time:YYYY-MM-DD HH:mm:ss.SSS} |<lvl>{level:8}</>| {name} : {module}:{line:4} | <cyan>mymodule</> | - <lvl>{message}</>",
"colorize": True
},
])
logger.debug('this is debug')
logger.info('this is info')
logger.warning('this is warning')
logger.error('this is error')
logger.critical('this is critical'): ログ出力ハンドルまたは出力先を示し、sys.stderr
、端末への出力を意味します。はコマンド ライン ターミナルへの出力を示します。"sink": sys.stderrはログのフォーマットを意味します。
"format":
{level:8} は、ログレベルに応じて色を表示することを意味します。 8 は、出力幅が 8 文字であることを意味します。"colorize":True
**: 表示色を示します。上記のコードの出力は次のとおりです:
 ここではモジュール名がハードコーディングされており、非常に面倒です。このように各ログを設定します。異なるモジュール名を指定する方法を以下に説明します。
ここではモジュール名がハードコーディングされており、非常に面倒です。このように各ログを設定します。異なるモジュール名を指定する方法を以下に説明します。
ログは通常、永続化する必要があり、コマンド ライン ターミナルに出力するだけでなく、ファイルに書き込む必要もあります。標準ログ ライブラリは、構成ファイルを通じてロガーを構成でき、コードに実装することもできますが、プロセスは比較的面倒です。 Loguru は比較的シンプルなので、この関数をコードに実装する方法を見てみましょう。ログ コードは次のとおりです。2.2. ファイルへの書き込み
import sys
from loguru import logger
logger.configure(handlers=[
{
"sink": sys.stderr,
"format": "{time:YYYY-MM-DD HH:mm:ss.SSS} |<lvl>{level:8}</>| {name} : {module}:{line:4} | <cyan>mymodule</> | - <lvl>{message}</>",
"colorize": True
},
{
"sink": 'first.log',
"format": "{time:YYYY-MM-DD HH:mm:ss.SSS} |{level:8}| {name} : {module}:{line:4} | mymodule | - {message}",
"colorize": False
},
])
logger.debug('this is debug')
logger.info('this is info')
logger.warning('this is warning')
logger.error('this is error')
logger.critical('this is critical')ログイン後にコピー
import sys
from loguru import logger
logger.configure(handlers=[
{
"sink": sys.stderr,
"format": "{time:YYYY-MM-DD HH:mm:ss.SSS} |<lvl>{level:8}</>| {name} : {module}:{line:4} | <cyan>mymodule</> | - <lvl>{message}</>",
"colorize": True
},
{
"sink": 'first.log',
"format": "{time:YYYY-MM-DD HH:mm:ss.SSS} |{level:8}| {name} : {module}:{line:4} | mymodule | - {message}",
"colorize": False
},
])
logger.debug('this is debug')
logger.info('this is info')
logger.warning('this is warning')
logger.error('this is error')
logger.critical('this is critical')2.1 との唯一の違いは、
logger.configureが新しいでログ形式を設定するだけですが、モジュール名は可変ではありません。実際のプロジェクト開発では、モジュールごとに記述するときに異なるモジュール名を指定する必要があります。ログ。したがって、より実用的になるようにモジュール名をパラメータ化する必要があります。サンプルコードは次のとおりです。handler
logger.configureを追加し、それをログ ファイルに書き込むことです。 。使い方はとても簡単です。上記は
import sys
from loguru import logger
logger.configure(handlers=[
{
"sink": sys.stderr,
"format": "{time:YYYY-MM-DD HH:mm:ss.SSS} |<lvl>{level:8}</>| {name} : {module}:{line:4} | <cyan>{extra[module_name]}</> | - <lvl>{message}</>",
"colorize": True
},
{
"sink": 'first.log',
"format": "{time:YYYY-MM-DD HH:mm:ss.SSS} |{level:8}| {name} : {module}:{line:4} | {extra[module_name]} | - {message}",
"colorize": False
},
])
log = logger.bind(module_name='my-loguru')
log.debug("this is hello, module is my-loguru")
log2 = logger.bind(module_name='my-loguru2')
log2.info("this is hello, module is my-loguru2")module_name
の機能を簡単に実現できます。さらに、構造化されたログは、のパラメータ化は、bind メソッドによって実現されます。 。 bind は、ログ出力を実行できるログ オブジェクトを返すため、さまざまなモジュールのログ形式を実装できます。loguru のモジュール名をカスタマイズする機能は、標準のロギング ライブラリとは少し異なります。バインドメソッドを利用することで、標準のlogloggingbind および logger.configure
を通じて簡単に実装できます。上記のコードの出力は次のとおりです:
2.3.json log
loguru
構造体として保存 json 形式への変換は非常に簡単で、serialize=True パラメーターを設定するだけです。コードは次のとおりです:
from loguru import logger logger.add('json.log', serialize=True, encoding='utf-8') logger.debug('this is debug message') logger.info('this is info message') logger.error('this is error message')
出力内容は次のとおりです: 2.4. ログのラッピング
loguru
ログ ファイルのサポート 3 つの設定: ループ、保存、圧縮。セットアップも比較的簡単です。特に圧縮形式のサポートが充実しており、"gz"、"bz2"、"xz"、# などの一般的な圧縮形式がサポートされています。 # #"lzma", "tar", "tar.gz", "tar.bz2", "tar.xz " ###、 ###"ジップ"###。サンプルコードは次のとおりです:
from loguru import logger
logger.add("file_1.log", rotation="500 MB") # 自动循环过大的文件
logger.add("file_2.log", rotation="12:00") # 每天中午创建新文件
logger.add("file_3.log", rotation="1 week") # 一旦文件太旧进行循环
logger.add("file_X.log", retention="10 days") # 定期清理
logger.add("file_Y.log", compression="zip") # 压缩节省空间2.5.并发安全
loguru默认是线程安全的,但不是多进程安全的,如果使用了多进程安全,需要添加参数enqueue=True,样例代码如下:
logger.add("somefile.log", enqueue=True)
loguru另外还支持协程,有兴趣可以自行研究。
3.高级用法
3.1.接管标准日志logging
更换日志系统或者设计一套日志系统,比较难的是兼容现有的代码,尤其是第三方库,因为不能因为日志系统的切换,而要去修改这些库的代码,也没有必要。好在loguru可以方便的接管标准的日志系统。
样例代码如下:
import logging
import logging.handlers
import sys
from loguru import logger
handler = logging.handlers.SysLogHandler(address=('localhost', 514))
logger.add(handler)
class LoguruHandler(logging.Handler):
def emit(self, record):
try:
level = logger.level(record.levelname).name
except ValueError:
level = record.levelno
frame, depth = logging.currentframe(), 2
while frame.f_code.co_filename == logging.__file__:
frame = frame.f_back
depth += 1
logger.opt(depth=depth, exception=record.exc_info).log(level, record.getMessage())
logging.basicConfig(handlers=[LoguruHandler()], level=0, format='%(asctime)s %(filename)s %(levelname)s %(message)s',
datefmt='%Y-%M-%D %H:%M:%S')
logger.configure(handlers=[
{
"sink": sys.stderr,
"format": "{time:YYYY-MM-DD HH:mm:ss.SSS} |<lvl>{level:8}</>| {name} : {module}:{line:4} | [ModuleA] | - <lvl>{message}</>",
"colorize": True
},
])
log = logging.getLogger('root')
# 使用标注日志系统输出
log.info('hello wrold, that is from logging')
log.debug('debug hello world, that is from logging')
log.error('error hello world, that is from logging')
log.warning('warning hello world, that is from logging')
# 使用loguru系统输出
logger.info('hello world, that is from loguru')输出为:

3.2.输出日志到网络服务器
如果有需要,不同进程的日志,可以输出到同一个日志服务器上,便于日志的统一管理。我们可以利用自定义或者第三方库进行日志服务器和客户端的设置。下面介绍两种日志服务器的用法。
3.2.1.自定义日志服务器
日志客户端段代码如下:
# client.py
import pickle
import socket
import struct
import time
from loguru import logger
class SocketHandler:
def __init__(self, host, port):
self.sock = socket.socket(socket.AF_INET, socket.SOCK_STREAM)
self.sock.connect((host, port))
def write(self, message):
record = message.record
data = pickle.dumps(record)
slen = struct.pack(">L", len(data))
self.sock.send(slen + data)
logger.configure(handlers=[{"sink": SocketHandler('localhost', 9999)}])
while True:
time.sleep(1)
logger.info("Sending info message from the client")
logger.debug("Sending debug message from the client")
logger.error("Sending error message from the client")日志服务器代码如下:
# server.py
import pickle
import socketserver
import struct
from loguru import logger
class LoggingStreamHandler(socketserver.StreamRequestHandler):
def handle(self):
while True:
chunk = self.connection.recv(4)
if len(chunk) < 4:
break
slen = struct.unpack('>L', chunk)[0]
chunk = self.connection.recv(slen)
while len(chunk) < slen:
chunk = chunk + self.connection.recv(slen - len(chunk))
record = pickle.loads(chunk)
level, message = record["level"].no, record["message"]
logger.patch(lambda record: record.update(record)).log(level, message)
server = socketserver.TCPServer(('localhost', 9999), LoggingStreamHandler)
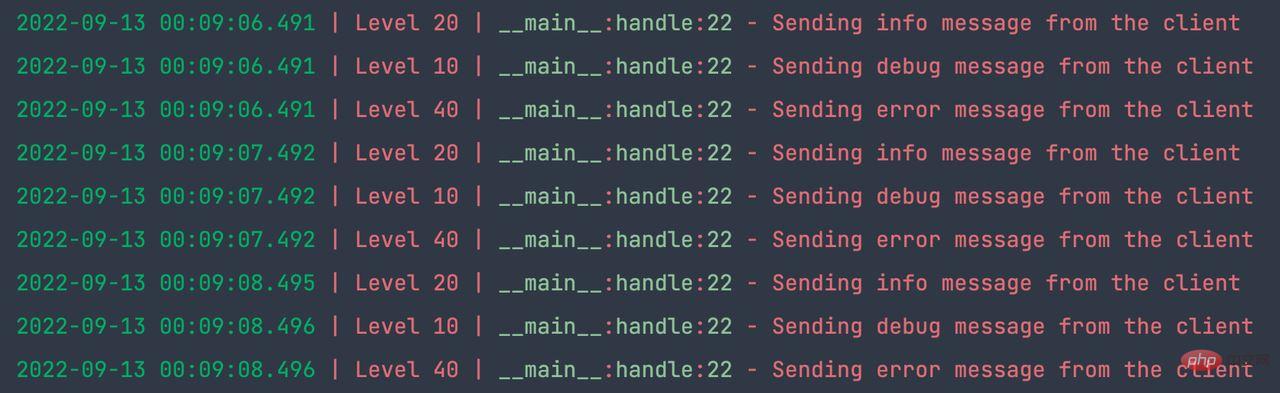
server.serve_forever()运行结果如下:
3.2.2.第三方库日志服务器
日志客户端代码如下:
# client.py
import zmq
from zmq.log.handlers import PUBHandler
from loguru import logger
socket = zmq.Context().socket(zmq.PUB)
socket.connect("tcp://127.0.0.1:12345")
handler = PUBHandler(socket)logger.add(handler)
logger.info("Logging from client")日志服务器代码如下:
# server.py
import sys
import zmq
from loguru import logger
socket = zmq.Context().socket(zmq.SUB)
socket.bind("tcp://127.0.0.1:12345")
socket.subscribe("")
logger.configure(handlers=[{"sink": sys.stderr, "format": "{message}"}])
while True:
_, message = socket.recv_multipart()
logger.info(message.decode("utf8").strip())3.3.与pytest结合
官方帮助中有一个讲解loguru与pytest结合的例子,讲得有点含糊不是很清楚。简单的来说,pytest有个fixture,可以捕捉被测方法中的logging日志打印,从而验证打印是否触发。
下面就详细讲述如何使用loguru与pytest结合的代码,如下:
import pytest
from _pytest.logging import LogCaptureFixture
from loguru import logger
def some_func(i, j):
logger.info('Oh no!')
logger.info('haha')
return i + j
@pytest.fixture
def caplog(caplog: LogCaptureFixture):
handler_id = logger.add(caplog.handler, format="{message}")
yield caplog
logger.remove(handler_id)
def test_some_func_logs_warning(caplog):
assert some_func(-1, 3) == 2
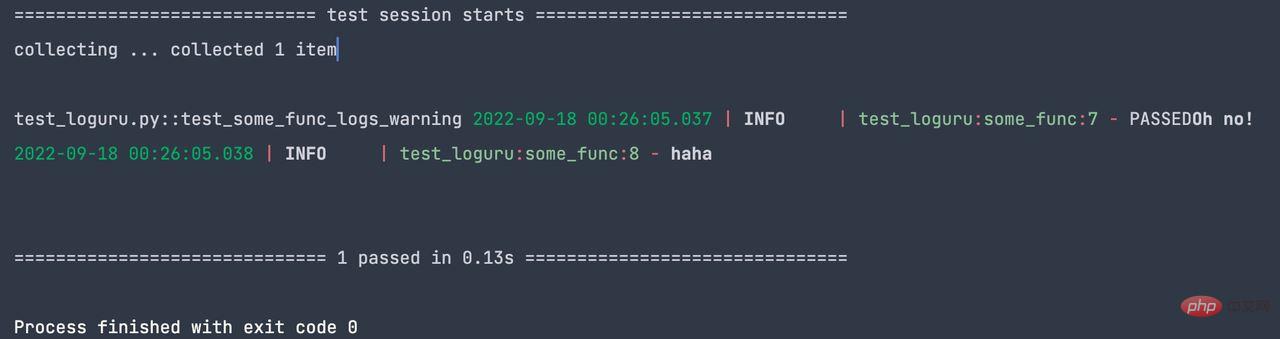
assert "Oh no!" in caplog.text测试输出如下:
以上がPython で loguru ログ ライブラリを使用する方法の詳細内容です。詳細については、PHP 中国語 Web サイトの他の関連記事を参照してください。

ホットAIツール

Undresser.AI Undress
リアルなヌード写真を作成する AI 搭載アプリ

AI Clothes Remover
写真から衣服を削除するオンライン AI ツール。

Undress AI Tool
脱衣画像を無料で

Clothoff.io
AI衣類リムーバー

AI Hentai Generator
AIヘンタイを無料で生成します。

人気の記事
ホットツール

メモ帳++7.3.1
使いやすく無料のコードエディター

SublimeText3 中国語版
中国語版、とても使いやすい

ゼンドスタジオ 13.0.1
強力な PHP 統合開発環境

ドリームウィーバー CS6
ビジュアル Web 開発ツール

SublimeText3 Mac版
神レベルのコード編集ソフト(SublimeText3)
ホットトピック
 7500
7500
 15
1377
52
78
11
19
54
15
1377
52
78
11
19
54

 hadidb:pythonの軽量で水平方向にスケーラブルなデータベース
Apr 08, 2025 pm 06:12 PM
hadidb:pythonの軽量で水平方向にスケーラブルなデータベース
Apr 08, 2025 pm 06:12 PM
hadidb:軽量で高レベルのスケーラブルなPythonデータベースHadIDB(HadIDB)は、Pythonで記述された軽量データベースで、スケーラビリティが高くなっています。 PIPインストールを使用してHADIDBをインストールする:PIPINSTALLHADIDBユーザー管理CREATEユーザー:CREATEUSER()メソッド新しいユーザーを作成します。 Authentication()メソッドは、ユーザーのIDを認証します。 fromhadidb.operationimportuseruser_obj = user( "admin"、 "admin")user_obj。
 MongoDBデータベースパスワードを表示するNAVICATの方法
Apr 08, 2025 pm 09:39 PM
MongoDBデータベースパスワードを表示するNAVICATの方法
Apr 08, 2025 pm 09:39 PM
Hash値として保存されているため、Navicatを介してMongoDBパスワードを直接表示することは不可能です。紛失したパスワードを取得する方法:1。パスワードのリセット。 2。構成ファイルを確認します(ハッシュ値が含まれる場合があります)。 3.コードを確認します(パスワードをハードコードできます)。
 2時間のPython計画:現実的なアプローチ
Apr 11, 2025 am 12:04 AM
2時間のPython計画:現実的なアプローチ
Apr 11, 2025 am 12:04 AM
2時間以内にPythonの基本的なプログラミングの概念とスキルを学ぶことができます。 1.変数とデータ型、2。マスターコントロールフロー(条件付きステートメントとループ)、3。機能の定義と使用を理解する4。
 高負荷アプリケーションのMySQLパフォーマンスを最適化する方法は?
Apr 08, 2025 pm 06:03 PM
高負荷アプリケーションのMySQLパフォーマンスを最適化する方法は?
Apr 08, 2025 pm 06:03 PM
MySQLデータベースパフォーマンス最適化ガイドリソース集約型アプリケーションでは、MySQLデータベースが重要な役割を果たし、大規模なトランザクションの管理を担当しています。ただし、アプリケーションのスケールが拡大すると、データベースパフォーマンスのボトルネックが制約になることがよくあります。この記事では、一連の効果的なMySQLパフォーマンス最適化戦略を検討して、アプリケーションが高負荷の下で効率的で応答性の高いままであることを保証します。実際のケースを組み合わせて、インデックス作成、クエリ最適化、データベース設計、キャッシュなどの詳細な主要なテクノロジーを説明します。 1.データベースアーキテクチャの設計と最適化されたデータベースアーキテクチャは、MySQLパフォーマンスの最適化の基礎です。いくつかのコア原則は次のとおりです。適切なデータ型を選択し、ニーズを満たす最小のデータ型を選択すると、ストレージスペースを節約するだけでなく、データ処理速度を向上させることもできます。
 Python:主要なアプリケーションの調査
Apr 10, 2025 am 09:41 AM
Python:主要なアプリケーションの調査
Apr 10, 2025 am 09:41 AM
Pythonは、Web開発、データサイエンス、機械学習、自動化、スクリプトの分野で広く使用されています。 1)Web開発では、DjangoおよびFlask Frameworksが開発プロセスを簡素化します。 2)データサイエンスと機械学習の分野では、Numpy、Pandas、Scikit-Learn、Tensorflowライブラリが強力なサポートを提供します。 3)自動化とスクリプトの観点から、Pythonは自動テストやシステム管理などのタスクに適しています。
 Amazon AthenaでAWS接着クローラーの使用方法
Apr 09, 2025 pm 03:09 PM
Amazon AthenaでAWS接着クローラーの使用方法
Apr 09, 2025 pm 03:09 PM
データの専門家として、さまざまなソースから大量のデータを処理する必要があります。これは、データ管理と分析に課題をもたらす可能性があります。幸いなことに、AWS GlueとAmazon Athenaの2つのAWSサービスが役立ちます。
 MySQLはSQLサーバーに接続できますか
Apr 08, 2025 pm 05:54 PM
MySQLはSQLサーバーに接続できますか
Apr 08, 2025 pm 05:54 PM
いいえ、MySQLはSQL Serverに直接接続できません。ただし、次のメソッドを使用してデータ相互作用を実装できます。ミドルウェア:MySQLから中間形式にデータをエクスポートしてから、ミドルウェアを介してSQL Serverにインポートします。データベースリンカーの使用:ビジネスツールは、よりフレンドリーなインターフェイスと高度な機能を提供しますが、本質的にはミドルウェアを通じて実装されています。
 Redisでサーバーを開始する方法
Apr 10, 2025 pm 08:12 PM
Redisでサーバーを開始する方法
Apr 10, 2025 pm 08:12 PM
Redisサーバーを起動する手順には、以下が含まれます。オペレーティングシステムに従ってRedisをインストールします。 Redis-Server(Linux/Macos)またはRedis-Server.exe(Windows)を介してRedisサービスを開始します。 Redis-Cli ping(Linux/macos)またはRedis-Cli.exePing(Windows)コマンドを使用して、サービスステータスを確認します。 Redis-Cli、Python、node.jsなどのRedisクライアントを使用して、サーバーにアクセスします。
