


ファイル アップロード機能を実装する場合など、リクエストの処理を完了するために複数のサービスにアクセスする必要がある場合は、まず Redis キャッシュにアクセスし、ユーザーがログインしているかどうかを確認します。次に、HTTP メッセージの本文を受信し、それをディスクに保存し、最後にファイル パスとその他の情報を MySQL データベースに書き込みます。
まず、ブロッキング API を使用して同期コードを記述し、それを段階的にシリアル化することができますが、明らかに現時点では、1 つのスレッドが同時に処理できるリクエストは 1 つだけです。スレッドの数には制限があることがわかっています。スレッドの数が限られているため、数万の同時接続を達成することは不可能です。また、過度のスレッドの切り替えにより CPU 時間が奪われ、1 秒あたりに処理できるリクエストの数が減少します。
したがって、高い同時実行性を実現するには、非同期フレームワークを選択し、ノンブロッキング API を使用してビジネス ロジックを複数のコールバック関数に分割し、多重化によって高い同時実行性を実現します。しかし現時点では、ビジネス コードは同時実行の詳細に過度に注意を払う必要があり、多くの中間状態を維持する必要があるため、コード ロジックでエラーが発生すると、コールバック地獄に陥ってしまいます。
したがって、バグ率が非常に高くなるだけでなく、プロジェクトの開発速度も低下し、タイムリーに製品をリリースすることが困難になる可能性があります。高い同時実行性を確保しながら開発効率を考慮したい場合は、コルーチンが最適な選択です。非同期の動作機構を維持しながら同期的にコードを記述できるため、高い同時実行性を実現するだけでなく、開発サイクルの短縮にもつながり、今後の高パフォーマンスサービスの開発の方向性となります。
ここで、同時実行性の観点からは、「コルーチン」の使用が「ノンブロッキング コールバック」より優れているわけではないことを指摘しなければなりません。また、コルーチンを選択する理由は、そのプログラミング モデルがよりシンプルで、次のようなものであるためです。同期により、非同期コードを同期的に作成できるようになります。 「ノンブロッキングコールバック」方式はプログラミングスキルを試される手法であり、一度エラーが発生すると問題箇所の特定が難しく、コールバック地獄やスタックティアリングなどのジレンマに陥りやすいです。
したがって、同時実行性の高い問題を解決するテクノロジが、マルチプロセスおよびマルチスレッドから非同期およびコルーチンへと変化していることがわかります。さまざまなシナリオに直面し、それらはすべてさまざまな方法で問題を解決しています。同時実行性の高いソリューションがどのように進化してきたか、コルーチンがどのような問題を解決するか、そしてコルーチンをどのように適用する必要があるかを見てみましょう。
ホストのリソースは 1 つの CPU、1 つのディスク、1 つのネットワーク カードと限られていることがわかっていますが、どうすれば数百ものリクエストを同時に処理できるでしょうか?マルチプロセス モードが元のソリューションでした。カーネルは、CPU の実行時間を多くのタイム スライス (タイムスライス) に分割します。たとえば、1 秒を 10 ミリ秒のタイム スライス 100 個に分割できます。各タイム スライスはその後、異なるプロセスに分散されます。通常、各プロセスには複数の時間が必要です。スライスしてリクエストを完了します。
このように、ミクロな視点で見ると、たとえば、CPU はこの 10 ミリ秒の間に 1 つのプロセスしか実行できませんが、マクロな視点で見ると、1 秒間に 100 個のタイムスライスが実行されるため、各タイムスライスが属するプロセスも取得し、リクエストの同時実行を実現するExecution。
ただし、各プロセスのメモリ空間は独立しているため、複数のプロセスを使用して同時実行を実現するには 2 つの欠点があります。1 つは、カーネルの管理コストが高いこと、2 つ目は、カーネルを介して単純にデータを同期することが不可能であることです。記憶力は非常に難しく、不便です。その結果、メモリのアドレス空間を共有することでこれら2つの問題を解決したマルチスレッドモードが登場しました。
ただし、共有アドレス空間ではオブジェクトを簡単に共有できますが、問題も発生します。つまり、いずれかのスレッドでエラーが発生すると、プロセス内のすべてのスレッドが一緒にクラッシュしてしまいます。 Nginx などの安定性を重視するサービスがマルチプロセス モードの使用にこだわるのはこのためです。
しかし実際には、マルチプロセスに基づいても、マルチスレッドに基づいても、主に次の 2 つの理由により、高い同時実行性を実現することは困難です。
次の図では、ディスク IO を例に、ブロック方式を使用してマルチスレッドでディスクを読み取る 2 つのスレッド間の切り替え方式を説明します。
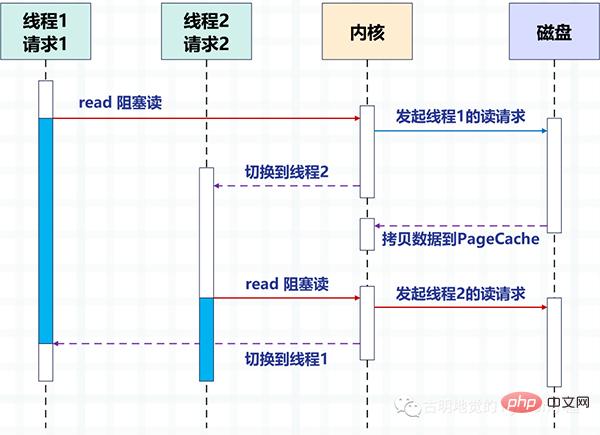
マルチスレッドにより、1 つのスレッドが 1 つのリクエストを処理して同時実行性を実現します。しかし、オペレーティング システムが作成できるスレッドの数が制限されていることは明らかです。スレッドの数が増えると、より多くのリソースが占有され、スレッド間の切り替えのコストも比較的高くなります。これは、カーネル モードとカーネル モードの切り替えが必要になるためです。ユーザーモード。
では、問題は、どうすれば高い同時実行性を達成できるかということです。答えは、「上図でカーネルによって実装されたリクエストの切り替え作業をユーザーモードのコードに任せるだけです。」です。非同期プログラミングは、アプリケーション層コードを通じてリクエストのスイッチングを実装し、スイッチング コストとメモリ フットプリントを削減します。
非同期化は、Linux の epoll などの IO 多重化メカニズムに依存しますが、同時に、カーネルの切り替えによる大量の消費を避けるために、ブロッキング方式を非ブロッキング方式に変更する必要があります。 Nginx や Redis などの高パフォーマンス サービスは、数百万レベルの同時実行性を達成するために非同期に依存しています。
次の図は、非同期 IO のノンブロッキング読み取りが非同期フレームワークと結合された後にリクエストがどのように切り替えられるかを示しています。
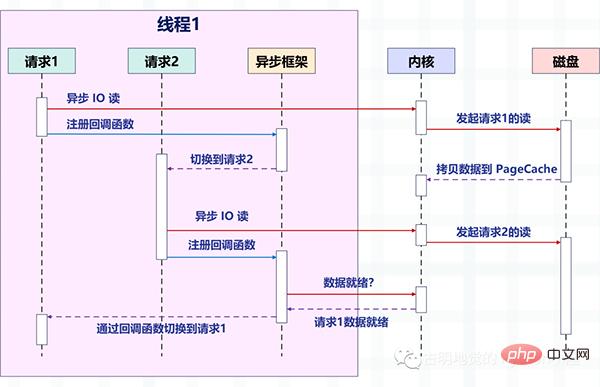
図の変化に注目してください。以前は 1 つのスレッドが 1 つのリクエストを処理していましたが、現在は 1 つのスレッドが複数のリクエストを処理しています。これが「ノンブロッキング コールバック」です。前にも話しましたね。これは、Linux の epoll や BSD の kqueue など、オペレーティング システムによって提供される IO 多重化に依存します。
このときの読み取りおよび書き込み操作はイベントに相当し、イベントごとに対応するコールバック関数が登録されるため、スレッドはブロックされません (この時点では読み取りおよび書き込み操作はノンブロッキングであるため)ただし、他のことを実行して、epoll にこれらのイベントを均一に管理させることもできます。
イベントが発生すると (読み取り可能および書き込み可能になった場合)、epoll がスレッドに通知し、スレッドはイベントに登録されたコールバック関数を実行します。
理解を深めるために、Redis を例として、ノンブロッキング IO と IO 多重化を紹介します。
127.0.0.1:6379> get name "satori"
まず、get コマンドを使用してキーに対応する値を取得できます。その後、問題は、上記の Redis サーバーに何が起こったのかということです。
サーバーは、まずクライアントのリクエストをリッスンし (バインド/リッスン)、次にクライアントが到着すると接続を確立し (受け入れ)、ソケットからクライアントのリクエスト (recv) を読み取り、リクエストを解析する必要があります。 (parse)、ここで解析されるリクエストのタイプはget、キーは「name」で、キーに従って対応する値が取得され、最終的にクライアントに返されます、つまりソケットにデータを書き込みます(send)。
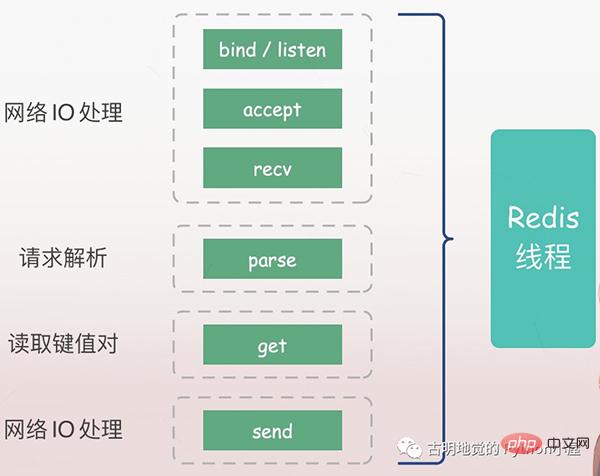
上記の操作はすべて Redis メイン スレッドによって順番に実行されますが、潜在的なブロック ポイント (accept と recv) が存在します。
IO をブロックしている場合、Redis がクライアントからの接続リクエストを検出しても接続の確立に失敗すると、メインスレッドは常に accept 関数でブロックされ、他のクライアントが接続を確立できなくなります。 Redis に接続します。同様に、Redis がクライアントから recv 経由でデータを読み取る場合、データが到着していない場合、Redis のメインスレッドは必ず recv ステップでブロックされるため、Redis の効率が低下します。
しかし、明らかに、Redis はこれが起こることを許可しません。なぜなら、上記はすべてブロッキング IO が直面する状況であり、Redis はノンブロッキング IO を使用するからです。ソケットはノンブロッキング モードに設定されます。まず、ソケット モデルでは、socket() メソッドを呼び出すとアクティブなソケットが返され、bind() メソッドを呼び出して IP とポートをバインドし、次に listen() メソッドを呼び出してアクティブなソケットをリスニング ソケットに変換します。最後に、待機しているソケット ソケットは、accept() メソッドを呼び出して、クライアント接続の到着を待ちます。クライアントとの接続が確立されると、接続されたソケットを返し、接続されたソケットを使用してデータを送受信します。クライアント。
ただし、注意: listen() ステップで、アクティブなソケットがリスニング ソケットに変換され、この時点でのリスニング ソケットのタイプはブロッキングであると述べました。インターフェースは accept() メソッドを呼び出します。接続するクライアントがない場合、インターフェースは常にブロック状態になり、メインスレッドは現時点では他のことを行うことができません。したがって、listen() 時に非ブロッキングに設定できます。非ブロッキングの listen ソケットが accept() を呼び出すとき、クライアント接続要求が到着しない場合、メインスレッドは愚かに待機せず、直接戻り、その後実行します。他のもの。
同様に、接続されたソケットを作成するときに、そのタイプを非ブロッキングに設定することもできます。これは、ブロックされたタイプの接続されたソケットも、send() / recv() を呼び出すときにブロックされるためです。ブロッキング状態 たとえば、クライアントがデータを送信しない場合、接続されたソケットは常に rev() ステップでブロックされます。接続されたソケットがノンブロッキングタイプの場合、recv() が呼び出されてもデータが受信されなかった場合、ブロッキング状態になる必要はなく、直接戻って他のことを行うこともできます。
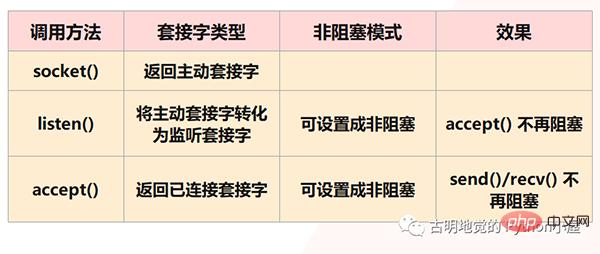
ただし、注意すべき点が 2 つあります:
1) accept() はブロックされなくなりましたが、クライアントが存在しない場合、Redis メインスレッドは他のことを実行できます。しかし、クライアントが後から接続してきた場合、Redis はどのようにしてそれを認識するのでしょうか?したがって、リスニングソケット上で後続の接続リクエストを待機し続け、リクエストが到着したときに Redis に通知できるメカニズムが必要です。
2) send() / recv() がブロックされなくなりました。IO に相当する読み書き処理がブロックされなくなりました。読み書きメソッドは即座に完了してリターンされます。私たちは、IO 操作を実行するためにできるだけ多く書き込むという戦略を採用していますが、これは明らかにパフォーマンスの追求により一致しています。ただし、これには問題もあります。つまり、読み取り操作を実行するときに、データの一部だけが読み取られ、残りのデータがクライアントから送信されていない可能性があります。読める?データの書き込みも同様で、バッファがいっぱいでデータがまだ書き込まれていない場合、残りのデータはいつ書き込めるでしょうか。したがって、Redis メインスレッドが他のことを行っている間も接続されたソケットを監視し続け、読み書きするデータがあるときに Redis に通知できるメカニズムも必要です。
これにより、Redis スレッドが基本 IO モデルのようにブロッキング ポイントで待機したり、実際に到着したクライアント接続リクエストや読み取りおよび書き込み可能なデータを処理できなくなったりすることがなくなります。メカニズムはIO多重化です。
I/O 多重化メカニズムとは、複数の IO ストリームを処理するスレッドを指します。これは、よく耳にする select/poll/epoll です。これら 3 つの違いについては説明しませんが、これらはすべて同じことを行いますが、パフォーマンスと実装原則に違いがあります。 select はすべてのシステムでサポートされていますが、epoll は Linux でのみサポートされています。
簡単に言うと、Redis が 1 つのスレッドのみを実行する場合、このメカニズムにより、複数のリスニング ソケットと接続されたソケットがカーネル内に同時に存在できるようになります。カーネルはこれらのソケット上の接続リクエストまたはデータリクエストを常に監視し、リクエストが到着すると、処理のために Redis スレッドに渡されるため、1 つの Redis スレッドが複数の IO ストリームを処理する効果が得られます。
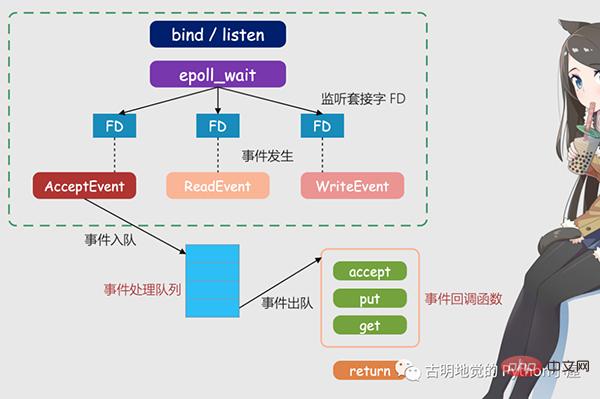
上の図は多重化に基づいた Redis IO モデルです。図内の FD はソケットであり、リスニング ソケットまたは接続されたソケットにすることができます。ソケット、Redis epoll メカニズムを使用して、カーネルがこれらのソケットを監視できるようにします。現時点では、Redis スレッドまたはメイン スレッドは特定のソケットでブロックされません。つまり、特定のクライアント リクエストの処理がブロックされません。したがって、Redis は複数のクライアントに同時に接続してリクエストを処理できるため、同時実行性が向上します。
しかし、リクエストの到着時に Redis スレッドに通知するために、epoll はイベントベースのコールバック メカニズムを提供します。つまり、さまざまなイベントの発生に対応する処理関数を呼び出します。
それでは、コールバック メカニズムはどのように機能するのでしょうか?上の図を例にとると、まず、epoll がリクエストが FD に到着したことを検出すると、対応するイベントをトリガーします。これらのイベントはキューに入れられ、Redis メインスレッドがイベント キューを継続的に処理するため、Redis はリクエストの有無をポーリングし続ける必要がなく、リソースの無駄が回避されます。
同時に、Redis はイベント キュー内のイベントを処理するときに、イベントベースのコールバックを実装する対応する処理関数を呼び出します。 Redis はイベント キューを処理しているため、クライアントの要求にタイムリーに応答でき、Redis の応答パフォーマンスが向上します。
実際の接続リクエストとデータ読み出しリクエストを例にして、もう一度説明してみましょう。接続リクエストとデータ読み取りリクエストは、それぞれ Accept イベントと Read イベントに対応します。Redis は、これら 2 つのイベントに対してそれぞれ accept コールバック関数と get コールバック関数を登録します。Linux カーネルが接続リクエストまたはデータ読み取りリクエストを監視すると、Accept イベントまたは Read イベントがトリガーされます、メインスレッドに通知し、登録された accept 関数または get 関数をコールバックします。
患者が医師の診察を受けるために病院に行くのと同じように、医師が実際に診断する前に、各患者 (リクエストと同様) のトリアージ、測定、登録などが必要です。これらすべての作業を医師が行ってしまうと、医師の作業効率は非常に低くなってしまいます。したがって、病院はトリアージ ステーションを設置しました。トリアージ ステーションは常にこれらの事前診断タスク (Linux カーネルのリスニング要求と同様) を処理し、実際の診断のために医師に転送します。 (Redis のメインスレッドに相当) は非常に効率的です。
这里需要再补充一下:我们上面提到的异步 IO 不是真正意义上的异步 IO,而是基于 IO 多路复用实现的异步化。但 IO 多路复用本质上是同步 IO,只是它可以同时监听多个文件描述符,一旦某个描述符的读写操作就绪,就能够通知应用程序进行相应的读写操作。至于真正意义的异步 IO,操作系统也是支持的,但支持的不太理想,所以现在使用的都是 IO 多用复用,并代指异步 IO。
必须要承认的是,编写这种异步化代码能够带来很高的性能收益,Redis、Nginx 已经证明了这一点。
但是这种编程模式,在实际工作中很容易出错,因为所有阻塞函数,都需要通过非阻塞的系统调用加上回调注册的方式拆分成两个函数。说白了就是我们的逻辑不能够直接执行,必须把它们放在一个单独的函数里面,然后这个函数以回调的方式注册给 IO 多路复用。
这种编程模式违反了软件工程的内聚性原则,函数之间同步数据也更复杂。特别是条件分支众多、涉及大量系统调用时,异步化的改造工作会非常困难,尽管它的性能很高。
下面我们用 Python 编写一段代码,实际体验一下这种编程模式,看看它复杂在哪里。
from urllib.parse import urlparse
import socket
from io import BytesIO
# selectors 里面提供了多种"多路复用器"
# 除了 select、poll、epoll 之外
# 还有 kqueue,这个是针对 BSD 平台的
try:
from selectors import (
SelectSelector,
PollSelector,
EpollSelector,
KqueueSelector
)
except ImportError:
pass
# 由于种类比较多,所以提供了DefaultSelector
# 会根据当前的系统种类,自动选择一个合适的多路复用器
from selectors import (
DefaultSelector,
EVENT_READ,# 读事件
EVENT_WRITE,# 写事件
)
class RequestHandler:
"""
向指定的 url 发请求
获取返回的内容
"""
selector = DefaultSelector()
tasks = {"unfinished": 0}
def __init__(self, url):
"""
:param url: http://localhost:9999/v1/index
"""
self.tasks["unfinished"] += 1
url = urlparse(url)
# 根据 url 解析出 域名、端口、查询路径
self.netloc = url.netloc# 域名:端口
self.path = url.path or "/"# 查询路径
# 创建 socket
self.client = socket.socket()
# 设置成非阻塞
self.client.setblocking(False)
# 用于接收数据的缓存
self.buffer = BytesIO()
def get_result(self):
"""
发送请求,进行下载
:return:
"""
# 连接到指定的服务器
# 如果没有 : 说明只有域名没有端口
# 那么默认访问 80 端口
if ":" not in self.netloc:
host, port = self.netloc, 80
else:
host, port = self.netloc.split(":")
# 由于 socket 非阻塞,所以连接可能尚未建立好
try:
self.client.connect((host, int(port)))
except BlockingIOError:
pass
# 我们上面是建立连接,连接建立好就该发请求了
# 但是连接什么时候建立好我们并不知道,只能交给操作系统
# 所以我们需要通过 register 给 socket 注册一个回调函数
# 参数一:socket 的文件描述符
# 参数二:事件
# 参数三:当事件发生时执行的回调函数
self.selector.register(self.client.fileno(),
EVENT_WRITE,
self.send)
# 表示当 self.client 这个 socket 满足可写时
# 就去执行 self.send
# 翻译过来就是连接建立好了,就去发请求
# 可以看到,一个阻塞调用,我们必须拆成两个函数去写
def send(self, key):
"""
连接建立好之后,执行的回调函数
回调需要接收一个参数,这是一个 namedtuple
内部有如下字段:'fileobj', 'fd', 'events', 'data'
key.fd 就是 socket 的文件描述符
key.data 就是给 socket 绑定的回调
:param key:
:return:
"""
payload = (f"GET {self.path} HTTP/1.1rn"
f"Host: {self.netloc}rn"
"Connection: closernrn")
# 执行此函数,说明事件已经触发
# 我们要将绑定的回调函数取消
self.selector.unregister(key.fd)
# 发送请求
self.client.send(payload.encode("utf-8"))
# 请求发送之后就要接收了,但是啥时候能接收呢?
# 还是要交给操作系统,所以仍然需要注册回调
self.selector.register(self.client.fileno(),
EVENT_READ,
self.recv)
# 表示当 self.client 这个 socket 满足可读时
# 就去执行 self.recv
# 翻译过来就是数据返回了,就去接收数据
def recv(self, key):
"""
数据返回时执行的回调函数
:param key:
:return:
"""
# 接收数据,但是只收了 1024 个字节
# 如果实际返回的数据超过了 1024 个字节怎么办?
data = self.client.recv(1024)
# 很简单,只要数据没收完,那么数据到来时就会可读
# 那么会再次调用此函数,直到数据接收完为止
# 注意:此时是非阻塞的,数据有多少就收多少
# 没有接收的数据,会等到下一次再接收
# 所以这里不能写 while True
if data:
# 如果有数据,那么写入到 buffer 中
self.buffer.write(data)
else:
# 否则说明数据读完了,那么将注册的回调取消
self.selector.unregister(key.fd)
# 此时就拿到了所有的数据
all_data = self.buffer.getvalue()
# 按照 rnrn 进行分隔得到列表
# 第一个元素是响应头,第二个元素是响应体
result = all_data.split(b"rnrn")[1]
print(f"result: {result.decode('utf-8')}")
self.client.close()
self.tasks["unfinished"] -= 1
@classmethod
def run_until_complete(cls):
# 基于 IO 多路复用创建事件循环
# 驱动内核不断轮询 socket,检测事件是否发生
# 当事件发生时,调用相应的回调函数
while cls.tasks["unfinished"]:
# 轮询,返回事件已经就绪的 socket
ready = cls.selector.select()
# 这个 key 就是回调里面的 key
for key, mask in ready:
# 拿到回调函数并调用,这一步需要我们手动完成
callback = key.data
callback(key)
# 因此当事件发生时,调用绑定的回调,就是这么实现的
# 整个过程就是给 socket 绑定一个事件 + 回调
# 事件循环不停地轮询检测,一旦事件发生就会告知我们
# 但是调用回调不是内核自动完成的,而是由我们手动完成的
# "非阻塞 + 回调 + 基于 IO 多路复用的事件循环"
# 所有框架基本都是这个套路一个简单的 url 获取,居然要写这么多代码,而它的好处就是性能高,因为不用把时间浪费在建立连接、等待数据上面。只要有事件发生,就会执行相应的回调,极大地提高了 CPU 利用率。而且这是单线程,也没有线程切换带来的开销。
那么下面测试一下吧。
import time
start = time.perf_counter()
for _ in range(10):
# 这里面只是注册了回调,但还没有真正执行
RequestHandler(url="https://localhost:9999/index").get_result()
# 创建事件循环,驱动执行
RequestHandler.run_until_complete()
end = time.perf_counter()
print(f"总耗时: {end - start}")我用 FastAPI 编写了一个服务,为了更好地看到现象,服务里面刻意 sleep 了 1 秒。然后发送十次请求,看看效果如何。
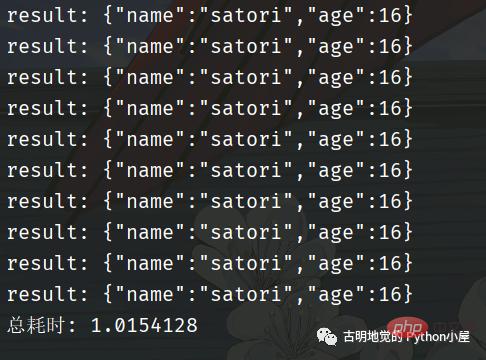
总共耗时 1 秒钟,我们再采用同步的方式进行编写,看看效果如何。
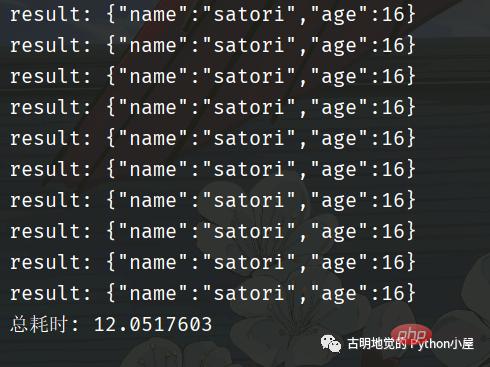
可以看到回调的这种写法性能非常高,但是它和我们传统的同步代码的写法大相径庭。如果是同步代码,那么会先建立连接、然后发送数据、再接收数据,这显然更符合我们人类的思维,逻辑自上而下,非常自然。
但是回调的方式,就让人很不适应,我们在建立完连接之后,不能直接发送数据,必须将发送数据的逻辑放在一个单独的函数(方法)中,然后再将这个函数以回调的方式注册进去。
同理,在发送完数据之后,也不能立刻接收。同样要将接收数据的逻辑放在一个单独的函数中,然后再以回调的方式注册进去。
所以好端端的自上而下的逻辑,因为回调而被分割的四分五裂,这种代码在编写和维护的时候是非常痛苦的。
比如回调可能会层层嵌套,容易陷入回调地狱,如果某一个回调执行出错了怎么办?代码的可读性差导致不好排查,即便排查到了也难处理。
另外,如果多个回调需要共享一个变量该怎么办?因为回调是通过事件循环调用的,在注册回调的时候很难把变量传过去。简单的做法是把该变量设置为全局变量,或者说多个回调都是某个类的成员函数,然后把共享的变量作为一个属性绑定在 self 上面。但当逻辑复杂时,就很容易导致全局变量满天飞的问题。
所以这种模式就使得开发人员在编写业务逻辑的同时,还要关注并发细节。
因此使用回调的方式编写异步化代码,虽然并发量能上去,但是对开发者很不友好;而使用同步的方式编写同步代码,虽然很容易理解,可并发量却又上不去。那么问题来了,有没有一种办法,能够让我们在享受异步化带来的高并发的同时,又能以同步的方式去编写代码呢?也就是我们能不能以同步的方式去编写异步化的代码呢?
答案是可以的,使用「协程」便可以办到。协程在异步化之上包了一层外衣,兼顾了开发效率与运行效率。
协程与异步编程相似的地方在于,它们必须使用非阻塞的系统调用与内核交互,把切换请求的权力牢牢掌握在用户态的代码中。但不同的地方在于,协程把异步化中的两段函数,封装为一个阻塞的协程函数。
这个函数执行时,会使调用它的协程无感知地放弃执行权,由协程框架切换到其他就绪的协程继续执行。当这个函数的结果满足后,协程框架再选择合适的时机,切换回它所在的协程继续执行。我们还是以读取磁盘文件为例,看一张协程的示意图:
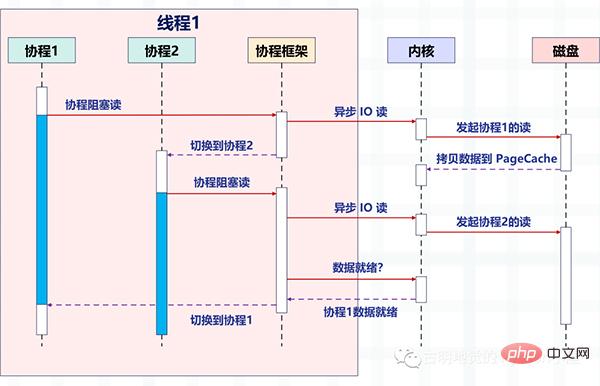
看起来非常棒,所以异步化是通过回调函数来完成请求切换的,业务逻辑与并发实现关联在一起,很容易出错。而协程不需要什么「回调函数」,它允许用户调用「阻塞的」协程方法,用同步编程方式写业务逻辑。
再回到之前的那个 socket 发请求的例子,我们用协程的方式重写一遍,看看它和基于回调的异步化编程有什么区别?
import time
from urllib.parse import urlparse
import asyncio
async def download(url):
url = urlparse(url)
# 域名:端口
netloc = url.netloc
if ":" not in netloc:
host, port = netloc, 80
else:
host, port = netloc.split(":")
path = url.path or "/"
# 创建连接
reader, writer = await asyncio.open_connection(host, port)
# 发送数据
payload = (f"GET {path} HTTP/1.1rn"
f"Host: {netloc}rn"
"Connection: closernrn")
writer.write(payload.encode("utf-8"))
await writer.drain()
# 接收数据
result = (await reader.read()).split(b"rnrn")[1]
writer.close()
print(f"result: {result.decode('utf-8')}")
# 以上就是发送请求相关的逻辑
# 我们看到代码是自上而下的,没有涉及到任何的回调
# 完全就像写同步代码一样
async def main():
# 发送 10 个请求
await asyncio.gather(
*[download("http://localhost:9999/index")
for _ in range(10)]
)
start = time.perf_counter()
# 同样需要创建基于 IO 多路复用的事件循环
# 协程会被丢进事件循环中,依靠事件循环驱动执行
loop = asyncio.get_event_loop()
loop.run_until_complete(main())
end = time.perf_counter()
print(f"总耗时: {end - start}")代码逻辑很好理解,和我们平时编写的同步代码没有太大的区别,那么它的效率如何呢?
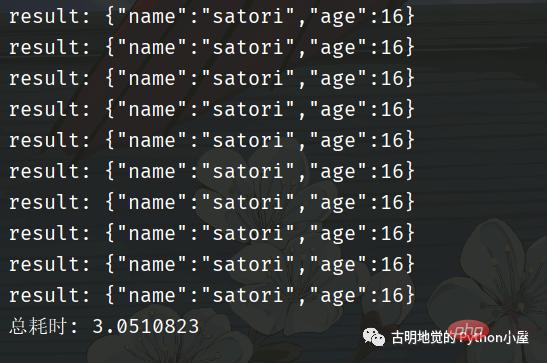
我们看到用了 3 秒钟,比同步的方式快,但是比异步化的方式要慢。因为一开始就说过,协程并不比异步化的方式快,但我们之所以选择它,是因为它的编程模型更简单,能够让我们以同步的方式编写异步的代码。如果是基于回调方式的异步化,虽然性能很高(比如 Redis、Nginx),但对开发者是一个挑战。
回到上面那个协程的例子中,我们一共发了 10 个请求,并在可能阻塞的地方加上了 await。意思就是,在执行某个协程 await 后面的代码时如果阻塞了,那么该协程会主动将执行权交给事件循环,然后事件循环再选择其它的协程执行。并且协程本质上也是个单线程,虽然协程可以有多个,但是背后的线程只有一个。
那么问题来了,协程的切换是如何完成的呢?
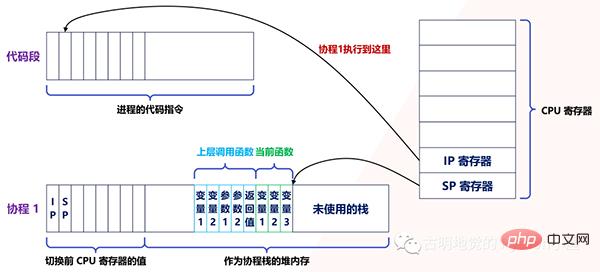
实际上,用户态的代码切换协程,与内核切换线程的原理是一样的。内核通过管理 CPU 的寄存器来切换线程,我们以最重要的栈寄存器和指令寄存器为例,看看协程切换时如何切换程序指令与内存。
每个线程有独立的栈,而栈既保留了变量的值,也保留了函数的调用关系、参数和返回值,CPU 中的栈寄存器 SP 指向了当前线程的栈,而指令寄存器 IP 保存着下一条要执行的指令地址。
因此,从线程 1 切换到线程 2 时,首先要把 SP、IP 寄存器的值为线程 1 保存下来,再从内存中找出线程 2 上一次切换前保存好的寄存器的值,并写入 CPU 的寄存器,这样就完成了线程切换(其他寄存器也需要管理、替换,原理与此相同,不再赘述)。
协程的切换与此相同,只是把内核的工作转移到协程框架来实现而已,下图是协程切换前的状态:
当遇到阻塞时会进行协程切换,从协程 1 切换到协程 2 后的状态如下图所示:
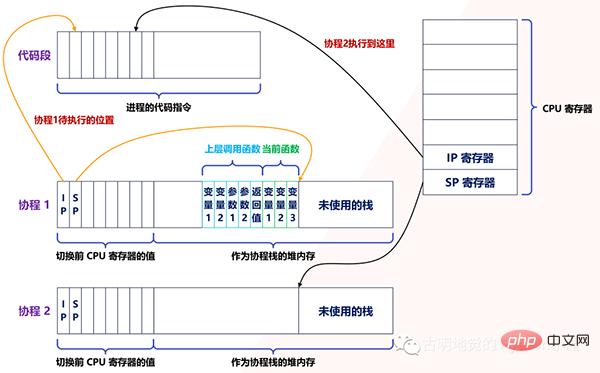
创建协程时,会从进程的堆中分配一段内存作为协程的栈。线程的栈有 8MB,而协程栈的大小通常只有几十 KB。而且,C 库内存池也不会为协程预分配内存,它感知不到协程的存在。这样,更低的内存占用空间为高并发提供了保证,毕竟十万并发请求,就意味着 10 万个协程。
另外栈缩小后,就尽量不要使用递归函数,也不能在栈中申请过多的内存,这是实现高并发必须付出的代价。当然啦,如果能像 Go 一样,协程栈可以自由伸缩的话,就不用担心了。
由此可见,协程就是用户态的线程。然而,为了保证所有切换都在用户态进行,协程必须重新封装所有的阻塞系统调用,否则一旦协程触发了线程切换,会导致这个线程进入休眠状态,进而其上的所有协程都得不到执行。
たとえば、通常のスリープ関数は現在のスレッドをスリープさせ、カーネルはスレッドをウェイクアップします。コルーチン変換後、スリープは現在のコルーチンをスリープさせるだけで、コルーチン フレームワークはその後コルーチンをウェイクアップします。 Python のコルーチンでは time.sleep を書くことはできませんが、asyncio.sleep を書く必要があります。別の例として、スレッド間のミューテックス ロックはセマフォを使用して実装されており、セマフォによってスレッドがスリープ状態になることもあります。ミューテックス ロックがコルーチンに変換された後、フレームワークは各コルーチンの実行も調整および同期します。
したがって、コルーチンの高いパフォーマンスは、切り替えがユーザー モード コードによって完了する必要があるという事実に基づいており、そのためには、コルーチン エコシステムが完全であり、共通コンポーネントを可能な限りカバーしている必要があります。
Python を例に挙げると、async def に request.get を書いてリクエストを送信している人をよく見かけますが、これは間違いです。 request.get への基礎的な呼び出しは同期的にブロックされたソケットであり、これによりスレッドがブロックされます。スレッドがブロックされると、すべてのコルーチンがブロックされます。これはシリアル化と同等です。したがって、これを async def 内に置くのは意味がありません。正しい方法は、aiohttp または httpx を使用することです。したがって、コルーチンを使用する場合は、基になるシステム コールを再カプセル化する必要があり、他に方法がない場合は、スレッド プールにスローして実行する必要があります。
もう 1 つの例は、MySQL によって公式に提供されているクライアント SDK です。これは、ネットワーク アクセスにブロッキング ソケットを使用するため、スレッドがスリープ状態になります。SDK をコルーチン関数に変換するには、非ブロッキング ソケットを使用する必要があります。コルーチンで使用されます。
もちろん、ディスクからの非同期 IO 読み取りなど、すべての関数をコルーチンで変換できるわけではありません。ノンブロッキングですが、PageCache を使用できないため、システムのスループットが低下します。キャッシュされた IO を使用してファイルを読み取る場合、PageCache がヒットしないときにブロッキングが発生する可能性があります。現時点で、より高いパフォーマンス要件がある場合は、スレッドとコルーチンを組み合わせ、実行のためにブロックする可能性のある操作をスレッド プールにスローし、プロデューサー/コンシューマー モデルを通じてコルーチンを操作する必要があります。
実際、マルチコア システムに直面すると、コルーチンとスレッドも連携して動作する必要があります。コルーチンのキャリアはスレッドであり、スレッドは一度に 1 つの CPU しか使用できないため、より多くのスレッドを開いてすべてのコルーチンをこれらのスレッドに分散することで、CPU リソースを最大限に活用できます。 Go 言語の使用経験がある場合は、このことをよく知っているはずです。
さらに、コルーチンがより多くの CPU 時間を取得できるようにするために、スレッドの優先順位を設定することもできます。たとえば、Linux では、スレッドの優先順位を -20 に設定すると、次のようになります。毎回、より長いタイムスライス。さらに、CPU キャッシュはプログラムのパフォーマンスにも影響します。CPU キャッシュの失敗の割合を減らすために、スレッドを CPU にバインドして、コルーチンの実行時に CPU キャッシュにヒットする確率を高めることもできます。
ここでは、コルーチン フレームワークがコルーチンをスケジュールしていると説明しましたが、多くのコルーチン ライブラリは実行の作成、一時停止、再開などの基本的なメソッドのみを提供しており、コルーチン フレームワークは存在しないことがわかります。ビジネス コードはそれ自体でコルーチンをスケジュールします。これは、これらの一般的なコルーチン ライブラリ (asyncio など) はサーバー用に特別に設計されていないためで、サーバーでのクライアント ネットワーク接続の確立によってコルーチンの作成が開始され、リクエストの終了とともに終了する可能性があります。
コルーチンの実行条件が満たされない場合、多重化フレームワークはコルーチンを一時停止し、優先度ポリシーに従って別のコルーチンを選択して実行します。したがって、コルーチンを使用してサーバー側で同時実行性の高いサービスを実装する場合は、コルーチン ライブラリを選択するだけでなく、そのエコシステムから IO 多重化を組み合わせたコルーチン フレームワーク (Tornado など) を見つけて開発をスピードアップすることもできます。
大まかに言えば、コルーチンは軽量の同時実行モデルであり、比較的高レベルです。しかし、狭義のコルーチンとは、一時停止や切り替えが可能な関数を呼び出すことです。たとえば、async def を使用して定義しているのはコルーチン関数ですが、これは本質的には関数であり、コルーチン関数を呼び出すとコルーチンが取得されます。
コルーチンをイベント ループに投げ込むと、イベント ループが実行を駆動します。ブロックされると、実行権限が積極的にイベント ループに渡され、イベント ループが他のコルーチンの実行を駆動します。したがって、最初から最後までスレッドは 1 つだけであり、コルーチンはスレッドの構造を参照してユーザー モードでシミュレートされるだけです。
したがって、通常の関数を呼び出すときは、すべての内部コード ロジックがすべて完了するまで実行されます。コルーチン関数の呼び出し中に、内部ブロッキングがある場合は、他のコルーチンに切り替わります。
ただし、コルーチンがブロックされたときに切り替えられるようにするには重要な前提条件があります。つまり、このブロックには time.sleep や同期ソケットなどのシステム コールを含めることはできません。これらはすべてカーネルの参加を必要とし、カーネルが参加すると、特定のコルーチンをブロックする(OS はコルーチンを認識しない)という単純なブロックではなく、スレッドのブロックを引き起こします。スレッドがブロックされると、その上のすべてのコルーチンがブロックされます。コルーチンはスレッドをキャリアとして使用するため、実際の実行はスレッドでなければなりません。各コルーチンがスレッドをブロックする場合、それは文字列と同等ではありません。完了しましたか?
したがって、コルーチンを使用したい場合は、ブロックされたシステム コールを再カプセル化する必要があります。
@app.get(r"/index1") async def index1(): time.sleep(30) return "index1" @app.get(r"/index2") async def index2(): return "index2"
这是一个基于 FastAPI 编写的服务,我们只看视图函数。如果我们先访问 /index1,然后访问 /index2,那么必须等到 30 秒之后,/index2 才会响应。因为这是一个单线程,/index1 里面的 time.sleep 会触发系统调用,使得整个线程都进入阻塞,线程一旦阻塞了,所有的协程就都别想执行了。
如果将上面的例子改一下:
@app.get(r"/index1") async def index(): await asyncio.sleep(30) return "index1" @app.get(r"/index2") async def index(): return "index2"
访问 /index1 依旧会进行 30 秒的休眠,但此时再访问 /index2 的话则是立刻返回。原因是 asyncio.sleep(30) 重新封装了阻塞的系统调用,此时的休眠是在用户态完成的,没有经过内核。换句话说,此时只会导致协程休眠,不会导致线程休眠,那么当访问 /index2 的时候,对应的协程会立刻执行,然后返回结果。
同理我们在发网络请求的时候,也不能使用 requests.get,因为它会导致线程阻塞。当然,还有一些数据库的驱动,例如 pymysql, psycopg2 等等,这些阻塞的都是线程。为此,在开发协程项目时,我们应该使用 aiohttp, asyncmy, asyncpg 等等。
为什么早期 Python 的协程都没有人用,原因就是协程想要运行,必须基于协程库 asyncio,但问题是 asyncio 只支持发送 TCP 请求(对于协程库而言足够了)。如果你想通过网络连接到某个组件(比如数据库、Redis),只能手动发 TCP 请求,而且这些组件对发送的数据还有格式要求,返回的数据也要手动解析,可以想象这是多么麻烦的事情。
如果想解决这一点,那么必须基于 asyncio 重新封装一个 SDK。所以同步 SDK 和协程 SDK 最大的区别就是,一个是基于同步阻塞的 socket,一个是基于 asyncio。比如 redis 和 aioredis,连接的都是 Redis,只是在 TCP 层面发送数据的方式不同,至于其它方面则是类似的。
而早期,还没有出现这些协程 SDK,自己封装的话又是一个庞大的工程,所以 Python 的协程用起来就很艰难,因为达不到期望的效果。不像 Go 在语言层面上就支持协程,一个 go 关键字就搞定了。而且 Python 里面一处异步、处处异步,如果某处的阻塞切换不了,那么协程也就没有意义了。
但现在 Python 已经进化到 3.10 了,协程相关的生态也越来越完善,感谢这些开源的作者们。发送网络请求、连接数据库、编写 web 服务等等,都有协程化的 SDK 和框架,现在完全可以开发以协程为主导的项目了。
本次我们从高并发的应用场景入手,分析了协程出现的背景和实现原理,以及它的应用范围。你会发现,协程融合了多线程与异步化编程的优点,既保证了开发效率,也提升了运行效率。有限的硬件资源下,多线程通过微观上时间片的切换,实现了同时服务上百个用户的能力。多线程的开发成本虽然低,但内存消耗大,切换次数过多,无法实现高并发。
异步编程方式通过非阻塞系统调用和多路复用,把原本属于内核的请求切换能力,放在用户态的代码中执行。这样,不仅减少了每个请求的内存消耗,也降低了切换请求的成本,最终实现了高并发。然而,异步编程违反了代码的内聚性,还需要业务代码关注并发细节,开发成本很高。
协程参考内核通过 CPU 寄存器切换线程的方法,在用户态代码中实现了协程的切换,既降低了切换请求的成本,也使得协程中的业务代码不用关注自己何时被挂起,何时被执行。相比异步编程中要维护一堆数据结构表示中间状态,协程直接用代码表示状态,大大提升了开发效率。但是在协程中调用的所有 API,都需要做非阻塞的协程化改造。优秀的协程生态下,常用服务都有对应的协程 SDK,方便业务代码使用。开发高并发服务时,与 IO 多路复用结合的协程框架可以与这些 SDK 配合,自动挂起、切换协程,进一步提升开发效率。
最后,协程并不是完全与线程无关。因为线程可以帮助协程充分使用多核 CPU 的计算力(Python 除外),而且遇到无法协程化、会导致内核切换的阻塞函数,或者计算太密集从而长时间占用 CPU 的任务,还是要放在独立的线程中,以防止它影响别的协程执行。
したがって、コルーチンを使用するときは、スレッド プールを使用するのが最善です。一部のブロッキングがカーネルを通過する必要があり、コルーチン化できない場合は、それをスレッド プールにスローして、スレッド レベルでの切り替えを完了します。複数のスレッドを開始するとリソースが占有され、スレッドの切り替えによってオーバーヘッドが生じますが、カーネルのブロックを介して切り替えるためには、これは避けられず、スレッドに期待するしかありません (もちろん、CPU 負荷が高すぎるタスクの場合)。集中的な場合は、スレッド プールにスローすることも検討できます。複数のコアを活用できるのであれば、スレッド プールに放り込むのが合理的ですが、Python のマルチスレッドでは複数のコアを使用できないのに、なぜこのようにするのか、気になる人もいるかもしれません。理由は簡単で、スレッドが 1 つしかない場合、このような CPU 負荷の高いタスクが長時間 CPU リソースを占有し、他のタスクが実行されなくなるからです。マルチスレッドをオンにすると、まだコアが1つしかありませんが、GILによってスレッドスイッチングが発生するため、「楚王の腰が細く、ハーレムが餓死する」という事態は発生しません。 CPU を均等に分散できるため、すべてのタスクを実行できます。
以上がお役立ち情報が満載! Python のコルーチンの実装方法を包括的に紹介します。それが理解できたら、あなたはすごいです!の詳細内容です。詳細については、PHP 中国語 Web サイトの他の関連記事を参照してください。
















![[Web フロントエンド] Node.js クイック スタート](https://img.php.cn/upload/course/000/000/067/662b5d34ba7c0227.png)



