

不同场景下 MySQL 的迁移方案_MySQL

为什么要迁移
MySQL 迁移方案概览
MySQL 迁移实战
注意事项
技巧
总结
一、为什么要迁移
MySQL 迁移是 DBA 日常维护中的一个工作。迁移,是把实际存在的物体挪走,保证该物体的完整性以及延续性。
生产环境中,有以下情况需要做迁移:
1、磁盘空间不够。比如一些老项目,选用的机型并不一定适用于数据库。随着时间的推移,硬盘很有可能出现短缺;
2、业务出现瓶颈。比如项目中采用单机承担所有的读写业务,业务压力增大,不堪重负。如果 IO 压力在可接受的范围,会采用读写分离方案;
3、机器出现瓶颈。机器出现瓶颈主要在磁盘 IO 能力、内存、CPU,此时除了针对瓶颈做一些优化以外,选择迁移是不错的方案;
4、项目改造。某些项目的数据库存在跨机房的情况,可能会在不同机房中增加节点,或者把机器从一个机房迁移到另一个机房。再比如,不同业务共用同一台服务器,为了缓解服务器压力以及方便维护,也会做迁移。
一句话,迁移工作是不得已而为之。实施迁移工作,目的是让业务平稳持续地运行。
二、MySQL 迁移方案概览
MySQL 迁移就是在保证业务平稳持续地运行的前提下做备份恢复。那问题就在怎么快速安全地进行备份恢复。
首先,备份。针对每个主节点的从节点或者备节点,都有备份。这个备份可能是全备,可能是增量备份。在线备份的方法,可能使用 mysqldump(MySQL 用于转存储数据库的实用程序。它主要产生一个SQL脚本,其中包含从头重新创建数据库所必需的命令),xtrabackup(是一个对 InnoDB 做数据备份的工具,支持在线热备份,是商业备份工具 InnoDB Hotbackup 的一个很好的替代品),mydumper(是一个针对MySQL和Drizzle的高性能多线程备份和恢复工具)等。
针对小容量(10GB 以下)的备份,可以使用 mysqldump。但对大容量数据库(GB 或者 TB 级别),mysqldump 就不合适,会产生锁,耗时太长。
此时,可以选择 xtrabackup 或者直接拷贝数据目录。直接拷贝数据目录方法,不同机器传输可以使用 rsync,耗时跟网络相关。使用 xtrabackup,耗时主要在备份和网络传输。如果有全备或者指定库的备份文件,这是获取备份的最好方法。如果备库可以容许停止服务,直接拷贝数据目录是最快的方法。如果备库不允许停止服务,我们可以使用 xtrabackup(不会锁定 InnoDB 表),这是完成备份的最佳折中办法。
其次,恢复。针对小容量(10GB 以下)数据库的备份文件,我们可以直接导入。针对大容量数据库(GB 或者 TB 级别)的恢复,拿到备份文件到本机以后,恢复不算困难。具体的恢复方法可以参考第三节。
三、MySQL 迁移实战
上面试为什么要做迁移,以及迁移需要做什么,接下来是在生产环境如何操作。不同的应用场景,有不同的解决方案。
假设有如下约定:
1、为了保护隐私,本文中的服务器 IP 等信息经过处理;
2、如果服务器在同一机房,用服务器 IP 的 D 段代替服务器,具体的 IP 请参考架构图;
3、如果服务器在不同机房,用服务器 IP 的 C 段 和 D 段代替服务器,具体的 IP 请参考架构图;
4、每个场景给出方法,但不会详细地给出每一步执行什么命令,因为一方面,这会导致文章过长;另一方面,我认为只要知道方法,具体的做法就会迎面扑来的,只取决于掌握知识的程度和获取信息的能力;
5、实战过程中的注意事项请参考第四节。
3.1,场景一:主一从结构迁移从库
我们从简单的结构入手。A 项目,原本是一主一从结构。101 是主节点,102 是从节点。因业务需要,把 102 从节点迁移至 103,架构图如图 1。102 从节点的数据容量过大,不能使用 mysqldump 的形式备份。和研发沟通后,形成一致的方案。
下面是 A 项目 MySQL 架构图。

具体做法是这样:
1、研发将 102 的读业务切到主库;
2、确认 102 MySQL 状态(主要看 PROCESS LIST),观察机器流量,确认无误后,停止 102 从节点的服务;
3、103 新建 MySQL 实例,建成以后,停止 MySQL 服务,并且将整个数据目录 mv 到其他地方做备份;
4、将 102 的整个 mysql 数据目录使用 rsync 拷贝到 103;
5、拷贝的同时,在 101 授权,使 103 有拉取 binlog 的权限(REPLICATION SLAVE, REPLICATION CLIENT);
6、待拷贝完成,修改 103 配置文件中的 server_id,注意不要和 102 上的一致;
7、在 103 启动 MySQL 实例,注意配置文件中的数据文件路径以及数据目录的权限;
8、进入 103 MySQL 实例,使用 SHOW SLAVE STATUS 检查从库状态,可以看到 Seconds_Behind_Master 在递减;
9、Seconds_Behind_Master 变为 0 后,表示同步完成,此时可以用 pt-table-checksum 检查 101 和 103 的数据一致,但比较耗时,而且对主节点有影响,可以和开发一起进行数据一致性的验证;
10、和研发沟通,除了做数据一致性验证外,还需要验证账号权限,以防业务迁回后访问出错;
11、做完上述步骤,可以和研发协调,把 101 的部分读业务切到 103,观察业务状态;
12、如果业务没有问题,证明迁移成功。
3.2,场景二:主一从结构迁移指定库
我们知道一主一从只迁移从库怎么做之后,接下来看看怎样同时迁移主从节点。因不同业务同时访问同一服务器,导致单个库压力过大,还不便管理。于是,打算将主节点 101 和从节点 102 同时迁移至新的机器 103 和 104,103 充当主节点,104 充当从节点,架构图如图二。此次迁移只需要迁移指定库,这些库容量不是太大,并且可以保证数据不是实时的。
下图是 B 项目 MySQL 架构图。

具体的做法如下:
1、103 和 104 新建实例,搭建主从关系,此时的主节点和从节点处于空载;
2、102 导出数据,正确的做法是配置定时任务,在业务低峰做导出操作,此处选择的是 mysqldump;
3、102 收集指定库需要的账号以及权限;
4、102 导出数据完毕,使用 rsync 传输到 103,必要时做压缩操作;
5、103 导入数据,此时数据会自动同步到 104,监控服务器状态以及 MySQL 状态;
6、103 导入完成,104 同步完成,103 根据 102 收集的账号授权,完成后,通知研发检查数据以及账户权限;
7、上述完成后,可研发协作,将 101 和 102 的业务迁移到 103 和 104,观察业务状态;
8、如果业务没有问题,证明迁移成功。
3.3,场景三:主一从结构双边迁移指定库
接下来看看一主一从结构双边迁移指定库怎么做。同样是因为业务共用,导致服务器压力大,管理混乱。于是,打算将主节点 101 和从节点 102 同时迁移至新的机器 103、104、105、106,103 充当 104 的主节点,104 充当 103 的从节点,105 充当 106 的主节点,106 充当 105 的从节点,架构图如图三。此次迁移只需要迁移指定库,这些库容量不是太大,并且可以保证数据不是实时的。我们可以看到,此次迁移和场景二很类似,无非做了两次迁移。
下图是 C 项目 MySQL 架构图。

具体的做法如下:
1、103 和 104 新建实例,搭建主从关系,此时的主节点和从节点处于空载;
2、102 导出 103 需要的指定库数据,正确的做法是配置定时任务,在业务低峰做导出操作,此处选择的是 mysqldump;
3、102 收集 103 需要的指定库需要的账号以及权限;
4、102 导出103 需要的指定库数据完毕,使用 rsync 传输到 103,必要时做压缩操作;
5、103 导入数据,此时数据会自动同步到 104,监控服务器状态以及 MySQL 状态;
6、103 导入完成,104 同步完成,103 根据 102 收集的账号授权,完成后,通知研发检查数据以及账户权限;
7、上述完成后,和研发协作,将 101 和 102 的业务迁移到 103 和 104,观察业务状态;
8、105 和 106 新建实例,搭建主从关系,此时的主节点和从节点处于空载;
9、102 导出 105 需要的指定库数据,正确的做法是配置定时任务,在业务低峰做导出操作,此处选择的是 mysqldump;
10、102 收集 105 需要的指定库需要的账号以及权限;
11、102 导出 105 需要的指定库数据完毕,使用 rsync 传输到 105,必要时做压缩操作;
12、105 导入数据,此时数据会自动同步到 106,监控服务器状态以及 MySQL 状态;
13、105 导入完成,106 同步完成,105 根据 102 收集的账号授权,完成后,通知研发检查数据以及账户权限;
14、上述完成后,和研发协作,将 101 和 102 的业务迁移到 105 和 106,观察业务状态;
15、如果所有业务没有问题,证明迁移成功。
3.4,场景四:主一从结构完整迁移主从
接下来看看一主一从结构完整迁移主从怎么做。和场景二类似,不过此处是迁移所有库。因 101 主节点 IO 出现瓶颈,打算将主节点 101 和从节点 102 同时迁移至新的机器 103 和 104,103 充当主节点,104 充当从节点。迁移完成后,以前的主节点和从节点废弃,架构图如图四。此次迁移是全库迁移,容量大,并且需要保证实时。这次的迁移比较特殊,因为采取的策略是先替换新的从库,再替换新的主库。所以做法稍微复杂些。
下面是 D 项目 MySQL 架构图。

具体的做法是这样:
1、研发将 102 的读业务切到主库;
2、确认 102 MySQL 状态(主要看 PROCESS LIST,MASTER STATUS),观察机器流量,确认无误后,停止 102 从节点的服务;
3、104 新建 MySQL 实例,建成以后,停止 MySQL 服务,并且将整个数据目录 mv 到其他地方做备份,注意,此处操作的是 104,也就是未来的从库;
4、将 102 的整个 mysql 数据目录使用 rsync 拷贝到 104;
5、拷贝的同时,在 101 授权,使 104 有拉取 binlog 的权限(REPLICATION SLAVE, REPLICATION CLIENT);
6、待拷贝完成,修改 104 配置文件中的 server_id,注意不要和 102 上的一致;
7、在 104 启动 MySQL 实例,注意配置文件中的数据文件路径以及数据目录的权限;
8、进入 104 MySQL 实例,使用 SHOW SLAVE STATUS 检查从库状态,可以看到 Seconds_Behind_Master 在递减;
9、Seconds_Behind_Master 变为 0 后,表示同步完成,此时可以用 pt-table-checksum 检查 101 和 104 的数据一致,但比较耗时,而且对主节点有影响,可以和开发一起进行数据一致性的验证;
10、除了做数据一致性验证外,还需要验证账号权限,以防业务迁走后访问出错;
11、和研发协作,将之前 102 从节点的读业务切到 104;
12、利用 102 的数据,将 103 变为 101 的从节点,方法同上;
13、接下来到了关键的地方了,我们需要把 104 变成 103 的从库;
- 104 STOP SLAVE;
- 103 STOP SLAVE IO_THREAD;
- 103 STOP SLAVE SQL_THREAD,记住 MASTER_LOG_FILE 和 MASTER_LOG_POS;
- 104 START SLAVE UNTIL到上述 MASTER_LOG_FILE 和 MASTER_LOG_POS;
- 104 再次 STOP SLAVE;
- 104 RESET SLAVE ALL 清除从库配置信息;
- 103 SHOW MASTER STATUS,记住 MASTER_LOG_FILE 和 MASTER_LOG_POS;
- 103 授权给 104 访问 binlog 的权限;
- 104 CHANGE MASTER TO 103;
- 104 重启 MySQL,因为 RESET SLAVE ALL 后,查看 SLAVE STATUS,Master_Server_Id 仍然为 101,而不是 103;
- 104 MySQL 重启后,SLAVE 回自动重启,此时查看 IO_THREAD 和 SQL_THREAD 是否为 YES;
- 103 START SLAVE;
- 此时查看 103 和 104 的状态,可以发现,以前 104 是 101 的从节点,如今变成 103 的从节点了。
14、业务迁移之前,断掉 103 和 101 的同步关系;
15、做完上述步骤,可以和研发协调,把 101 的读写业务切回 102,读业务切到 104。需要注意的是,此时 101 和 103 均可以写,需要保证 101 在没有写入的情况下切到 103,可以使用 FLUSH TABLES WITH READ LOCK 锁住 101,然后业务切到 103。注意,一定要业务低峰执行,切记;
16、切换完成后,观察业务状态;
17、如果业务没有问题,证明迁移成功。
3.5,场景五:双主结构跨机房迁移
接下来看看双主结构跨机房迁移怎么做。某项目出于容灾考虑,使用了跨机房,采用了双主结构,双边均可以写。因为磁盘空间问题,需要对 A 地的机器进行替换。打算将主节点 1.101 和从节点 1.102 同时迁移至新的机器 1.103 和 1.104,1.103 充当主节点,1.104 充当从节点。B 地的 2.101 和 2.102 保持不变,但迁移完成后,1.103 和 2.101 互为双主。架构图如图五。因为是双主结构,两边同时写,如果要替换主节点,单方必须有节点停止服务。
下图是 E 项目 MySQL 迁移架构图。

具体的做法如下:
1、1.103 和 1.104 新建实例,搭建主从关系,此时的主节点和从节点处于空载;
2、确认 1.102 MySQL 状态(主要看 PROCESS LIST),注意观察 MASTER STATUS 不再变化。观察机器流量,确认无误后,停止 1.102 从节点的服务;
3、1.103 新建 MySQL 实例,建成以后,停止 MySQL 服务,并且将整个数据目录 mv 到其他地方做备份;
4、将 1.102 的整个 mysql 数据目录使用 rsync 拷贝到 1.103;
5、拷贝的同时,在 1.101 授权,使 1.103 有拉取 binlog 的权限(REPLICATION SLAVE, REPLICATION CLIENT);
6、待拷贝完成,修改 1.103 配置文件中的 server_id,注意不要和 1.102 上的一致;
7、在 1.103 启动 MySQL 实例,注意配置文件中的数据文件路径以及数据目录的权限;
8、进入 1.103 MySQL 实例,使用 SHOW SLAVE STATUS 检查从库状态,可以看到 Seconds_Behind_Master 在递减;
9、Seconds_Behind_Master 变为 0 后,表示同步完成,此时可以用 pt-table-checksum 检查 1.101 和 1.103 的数据一致,但比较耗时,而且对主节点有影响,可以和开发一起进行数据一致性的验证;
10、我们使用相同的办法,使 1.104 变成 1.103 的从库;
11、和研发沟通,除了做数据一致性验证外,还需要验证账号权限,以防业务迁走后访问出错;
12、此时,我们要做的就是将 1.103 变成 2.101 的从库,具体的做法可以参考场景四;
13、需要注意的是,1.103 的单双号配置需要和 1.101 一致;
14、做完上述步骤,可以和研发协调,把 1.101 的读写业务切到 1.103,把 1.102 的读业务切到 1.104。观察业务状态;
15、如果业务没有问题,证明迁移成功。
3.6,场景六:多实例跨机房迁移
接下来我们看看多实例跨机房迁移证明做。每台机器的实例关系,我们可以参考图六。此次迁移的目的是为了做数据修复。在 2.117 上建立 7938 和 7939 实例,替换之前数据异常的实例。因为业务的原因,某些库只在 A 地写,某些库只在 B 地写,所以存在同步过滤的情况。
下图是 F 项目 MySQL 架构图。

具体的做法如下:
1、1.113 针对 7936 实例使用 innobackupex 做数据备份,注意需要指定数据库,并且加上 slave-info 参数;
2、备份完成后,将压缩文件拷贝到 2.117;
3、2.117 创建数据目录以及配置文件涉及的相关目录;
4、2.117 使用 innobackupex 恢复日志;
5、2.117 使用 innobackupex 拷贝数据;
6、2.117 修改配置文件,注意如下参数:replicate-ignore-db、innodb_file_per_table = 1、read_only = 1、 server_id;
7、2.117 更改数据目录权限;
8、1.112 授权,使 2.117 有拉取 binlog 的权限(REPLICATION SLAVE, REPLICATION CLIENT);
9、2.117 CHANGE MASTE TO 1.112,LOG FILE 和 LOG POS 参考 xtrabackup_slave_info;
10、2.117 START SLAVE,查看从库状态;
11、2.117 上建立 7939 的方法类似,不过配置文件需要指定 replicate-wild-do-table;
12、和开发一起进行数据一致性的验证和验证账号权限,以防业务迁走后访问出错;
13、做完上述步骤,可以和研发协调,把相应业务迁移到 2.117 的 7938 实例和 7939 实例。观察业务状态;
14、如果业务没有问题,证明迁移成功。
四、注意事项
介绍完不同场景的迁移方案,需要注意如下几点:
1、数据库迁移,如果涉及事件,记住主节点打开 event_scheduler 参数;
2、不管什么场景下的迁移,都要随时关注服务器状态,比如磁盘空间,网络抖动;另外,对业务的持续监控也是必不可少的;
3、CHANGE MASTER TO 的 LOG FILE 和 LOG POS 切记不要找错,如果指定错了,带来的后果就是数据不一致;
4、执行脚本不要在 $HOME 目录,记住在数据目录;
5、迁移工作可以使用脚本做到自动化,但不要弄巧成拙,任何脚本都要经过测试;
6、每执行一条命令都要三思和后行,每个命令的参数含义都要搞明白;
7、多实例环境下,关闭 MySQL 采用 mysqladmin 的形式,不要把正在使用的实例关闭了;
8、从库记得把 read_only = 1 加上,这会避免很多问题;
9、每台机器的 server_id 必须保证不一致,否则会出现同步异常的情况;
10、正确配置 replicate-ignore-db 和 replicate-wild-do-table;
11、新建的实例记得把 innodb_file_per_table 设置为 1,上述中的部分场景,因为之前的实例此参数为 0,导致 ibdata1 过大,备份和传输都消耗了很多时间;
12、使用 gzip 压缩数据时,注意压缩完成后,gzip 会把源文件删除。
13、所有的操作务必在从节点或者备节点操作,如果在主节点操作,主节点很可能会宕机;
14、xtrabackup 备份不会锁定 InnoDB 表,但会锁定 MyISAM 表。所以,操作之前记得检查下当前数据库的表是否有使用 MyISAM 存储引擎的,如果有,要么单独处理,要么更改表的 Engine;
五、技巧
在 MySQL 迁移实战中,有如下技巧可以使用:
1、任何迁移 LOG FILE 以 relay_master_log_file(正在同步 master 上的 binlog 日志名)为准,LOG POS 以 exec_master_log_pos(正在同步当前 binlog 日志的 POS 点)为准;
2、使用 rsync 拷贝数据,可以结合 expect、nohup 使用,绝对是绝妙组合;
3、在使用 innobackupex 备份数据的同时可以使用 gzip 进行压缩;
4、在使用 innobackupex 备份数据,可以加上 --slave-info 参数,方便做从库;
5、在使用 innobackupex 备份数据,可以加上 --throttle 参数,限制 IO,减少对业务的影响。还可以加上 --parallel=n 参数,加快备份,但需要注意的是,使用 tar 流压缩,--parallel 参数无效。
6、做数据的备份与恢复,可以把待办事项列个清单,画个流程,然后把需要执行的命令提前准备好;
7、本地快速拷贝文件夹,有个不错的方法,使用 rsync,加上如下参数:-avhW --no-compress --progress;
8、 不同分区之间快速拷贝数据,可以使用 dd。或者用一个更靠谱的方法,备份到硬盘,然后放到服务器上。异地还有更绝的,直接快递硬盘。
六、总结
本文从为什么要迁移讲起,接下来讲了迁移方案,然后讲解了不同场景下的迁移实战,最后给出了注意事项以及实战技巧。归纳起来,也就以下几点:
第一、迁移的目的是让业务平稳持续地运行;
第二、迁移的核心是怎么延续主从同步,我们需要在不同服务器和不同业务之间找到方案;
第三、业务切换需要考虑不同 MySQL 服务器之间的权限问题;需要考虑不同机器读写分离的顺序以及主从关系;需要考虑跨机房调用对业务的影响。
读者在实施迁移的过程中,可以参考此文提供的思路。但怎样保证每个操作正确无误地运行,还需要三思而后行。
说句题外话,「证明自己有能力最重要的一点就是让一切都在自己的掌控之中。

ホットAIツール

Undresser.AI Undress
リアルなヌード写真を作成する AI 搭載アプリ

AI Clothes Remover
写真から衣服を削除するオンライン AI ツール。

Undress AI Tool
脱衣画像を無料で

Clothoff.io
AI衣類リムーバー

AI Hentai Generator
AIヘンタイを無料で生成します。

人気の記事
ホットツール

メモ帳++7.3.1
使いやすく無料のコードエディター

SublimeText3 中国語版
中国語版、とても使いやすい

ゼンドスタジオ 13.0.1
強力な PHP 統合開発環境

ドリームウィーバー CS6
ビジュアル Web 開発ツール

SublimeText3 Mac版
神レベルのコード編集ソフト(SublimeText3)
ホットトピック
 7392
7392
 15
1630
14
1357
52
1268
25
1216
29
15
1630
14
1357
52
1268
25
1216
29

 自動運転シナリオにおけるロングテール問題を解決するにはどうすればよいでしょうか?
Jun 02, 2024 pm 02:44 PM
自動運転シナリオにおけるロングテール問題を解決するにはどうすればよいでしょうか?
Jun 02, 2024 pm 02:44 PM
昨日の面接で、ロングテール関連の質問をしたかと聞かれたので、簡単にまとめてみようと思いました。自動運転のロングテール問題とは、自動運転車におけるエッジケース、つまり発生確率が低い考えられるシナリオを指します。認識されているロングテール問題は、現在、単一車両のインテリジェント自動運転車の運用設計領域を制限している主な理由の 1 つです。自動運転の基礎となるアーキテクチャとほとんどの技術的問題は解決されており、残りの 5% のロングテール問題が徐々に自動運転の開発を制限する鍵となってきています。これらの問題には、さまざまな断片的なシナリオ、極端な状況、予測不可能な人間の行動が含まれます。自動運転におけるエッジ シナリオの「ロング テール」とは、自動運転車 (AV) におけるエッジ ケースを指します。エッジ ケースは、発生確率が低い可能性のあるシナリオです。これらの珍しい出来事
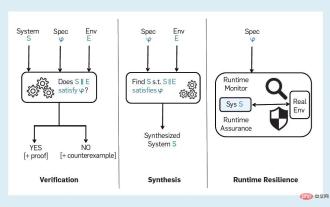 検証可能な AI に向けて: 形式手法の 5 つの課題
Apr 09, 2023 pm 02:01 PM
検証可能な AI に向けて: 形式手法の 5 つの課題
Apr 09, 2023 pm 02:01 PM
人工知能は、人間の知能を模倣しようとするコンピューティング システムであり、学習、問題解決、合理的な思考と行動など、知能に直観的に関連する人間の機能が含まれます。広義に解釈すると、AI という用語は、機械学習などの密接に関連する多くの分野をカバーします。 AI を多用するシステムは、医療、交通、金融、ソーシャル ネットワーク、電子商取引、教育などの分野で社会に大きな影響を与えています。この社会的影響の増大は、人工知能ソフトウェアのエラー、サイバー攻撃、人工知能システムのセキュリティなど、一連のリスクと懸念ももたらしています。したがって、AI システムの検証の問題、および信頼できる AI というより広範なテーマが研究コミュニティの注目を集め始めています。 「検証可能なAI」を確認
 Java で ClassCastException はどのようなシナリオで発生しますか?
Jun 25, 2023 pm 09:19 PM
Java で ClassCastException はどのようなシナリオで発生しますか?
Jun 25, 2023 pm 09:19 PM
Java は、実行時にデータ型の一致を必要とする厳密に型指定された言語です。 Java の厳密な型変換メカニズムにより、コード内でデータ型の不一致がある場合、ClassCastException が発生します。 ClassCastException は Java 言語でよく発生する例外の 1 つで、この記事では ClassCastException の原因と回避方法を紹介します。 ClassCastExceptionとは何ですか
 Linux システム用のこれらのストレス テスト ツールを使用したことがありますか?
Mar 21, 2024 pm 04:12 PM
Linux システム用のこれらのストレス テスト ツールを使用したことがありますか?
Mar 21, 2024 pm 04:12 PM
運用保守担当者として、このようなシナリオに遭遇したことがありますか?ツールを使用して、システムの CPU またはメモリの高い使用率をテストしてアラームをトリガーしたり、ストレス テストを通じてサービスの同時実行機能をテストしたりする必要があります。運用およびメンテナンス エンジニアは、これらのコマンドを使用して障害シナリオを再現することもできます。この記事は、一般的に使用されるテスト コマンドとツールを習得するのに役立ちます。 1. はじめに 場合によっては、プロジェクト内の問題を特定して再現するには、ツールを使用して系統的なストレス テストを実施し、障害シナリオをシミュレートおよび復元する必要があります。現時点では、テストまたはストレス テスト ツールが特に重要になります。次に、さまざまなシナリオに応じてこれらのツールの使用法を検討します。 2. テストツール 2.1 ネットワーク速度制限ツール tctc は、Linux のネットワークパラメータを調整するために使用されるコマンドラインツールで、さまざまなネットワークをシミュレートするために使用できます。
 2 文で言えば、AI に VR シーンを生成させましょう!それとも 3D または HDR パノラマのようなものですか?
Apr 12, 2023 am 09:46 AM
2 文で言えば、AI に VR シーンを生成させましょう!それとも 3D または HDR パノラマのようなものですか?
Apr 12, 2023 am 09:46 AM
Big Data Digest 制作者: Caleb 最近、ChatGPT が非常に人気があると言えます。 OpenAIは11月30日にチャットロボット「ChatGPT」をリリースし、テスト用に無料公開して以来、中国で広く利用されている。ロボットに話しかけるとは、キーワードを入力してAIに対応する画像を生成させるなど、ロボットに特定の命令の実行を依頼することです。これは珍しいことではないようですが、OpenAI も 4 月に DALL-E の新バージョンをアップデートしましたよね? OpenAIさん、あなたは何歳ですか? (なぜいつもあなたなのですか?) ダイジェストが、生成された画像が 3D 画像、HDR パノラマ、または VR ベースの画像コンテンツであると言ったらどうしますか?最近、シンガポール
 PHP の高同時処理におけるスレッド プール最適化ソリューション
Aug 11, 2023 am 10:45 AM
PHP の高同時処理におけるスレッド プール最適化ソリューション
Aug 11, 2023 am 10:45 AM
PHP のスレッド プール最適化ソリューション 高同時実行処理 インターネットの急速な発展とユーザー ニーズの継続的な増大に伴い、最新の Web アプリケーション開発では高同時実行性が重要な問題となっています。 PHP では、シングルスレッドの性質のため、大量の同時リクエストを処理するのは困難です。この問題を解決するには、スレッド プールの概念を導入することが効果的な最適化ソリューションです。スレッド プールは、多数の同時タスクを実行するために使用される再利用可能なスレッドのコレクションです。その基本的な考え方は、スレッドの作成、破棄、管理を分離し、スレッドを再利用することでスレッドの数を減らすことです。
 一般的な Kafka コマンドの使用方法を学び、さまざまなシナリオに柔軟に対応します。
Jan 31, 2024 pm 09:22 PM
一般的な Kafka コマンドの使用方法を学び、さまざまなシナリオに柔軟に対応します。
Jan 31, 2024 pm 09:22 PM
Kafka 学習の必需品: 一般的なコマンドをマスターし、さまざまなシナリオに簡単に対処する 1. Topicbin/kafka-topics.sh--create--topicmy-topic--partitions3--replication-factor22 を作成します。Topicbin/kafka-topics.sh をリストします - -list3. トピックの詳細を表示 bin/kafka-to
 大規模モデルのモデル融合法について話しましょう
Mar 11, 2024 pm 01:10 PM
大規模モデルのモデル融合法について話しましょう
Mar 11, 2024 pm 01:10 PM
これまでの実践では、モデル融合は、特に判別モデルで広く使用されており、パフォーマンスを着実に向上させることができる方法と考えられています。ただし、生成言語モデルの場合、復号化プロセスが関係するため、その動作方法は判別モデルほど単純ではありません。さらに、大規模なモデルのパラメータ数が増加するため、より大きなパラメータスケールのシナリオでは、単純なアンサンブル学習で考慮できる手法は、従来のスタッキング、ブースティング、およびなどの低パラメータの機械学習よりも制限されます。他の方法は、モデルをスタッキングするためです。パラメータの問題は簡単に拡張できません。したがって、大規模なモデルのアンサンブル学習には慎重な検討が必要です。以下では、モデル統合、確率的統合、グラフティング学習、クラウドソーシング投票、MOE という 5 つの基本的な統合手法について説明します。
