

私は昨日、データ テクノロジー カーニバルから戻った後に ChatGLM のセットを導入し、データベースの運用と保守の知識ベースをトレーニングするために大規模な言語モデルの使用を研究する予定だと言いました。多くの友人はそれを信じませんでした。ラオバイさん、もうこんな歳なんだけど、まだできるよ。自分でこんなこといじるつもりなの?これらの友人たちの疑問を払拭するために、今日は過去 2 日間で ChatGLM をトスするプロセスを共有し、また、ChatGLM をトスすることに興味がある友人のために落とし穴を避けるためのヒントをいくつか共有します。
ChatGLM-6B は、2023 年に清華大学 KEG 研究室と Zhipu AI が共同で訓練した言語モデル GLM に基づいて開発され、ユーザーの問題や要件に適切なソリューションを提供する大規模な言語モデルです。サポート。上記の答えは ChatGLM 自身が答えています GLM-6B は 62 億個のパラメータを持つオープンソースの事前学習済みモデルであり、比較的小規模なハードウェア環境でローカルに実行できるのが特徴です。この機能により、大規模な言語モデルに基づくアプリケーションを数千世帯に導入できるようになります。 KEG ラボの目的は、より大規模な GLM-130B モデル (GPT-3.5 に相当する 1,300 億のパラメーター) を 8 ウェイ RTX 3090 を備えたローエンド環境でトレーニングできるようにすることです。
#この目標が本当に達成できれば、大規模な言語モデルに基づいてアプリケーションを作成したい人にとっては間違いなく朗報となるでしょう。 ChatGLP-6B の現在の FP16 モデルは 13G 強、INT-4 量子化モデルは 4GB 未満で、6GB のビデオ メモリを搭載した RTX 3060TI で実行できます。
導入前はこれらの状況についてあまり知らなかったので、高くもなく低くもない 12GB RTX 3060 を購入したため、インストールと導入が完了した後、 FP16モデルはまだ実行できませんでした。自宅でテストと検証を行う方が良いと知っていたら、もっと安価な 3060TI を購入したでしょう。ロスレス FP16 モデルを実行したい場合は、24 GB のビデオ メモリを搭載した 3090 を入手する必要があります。
ChatGLP-6B の機能を自分のマシンでテストしたいだけの場合は、THUDM/ChatGLM を直接ダウンロードする必要はないかもしれません。 6B モデルの他に、huggingface でダウンロードできるパッケージ化された定量的モデルがいくつかあります。モデルのダウンロード速度は非常に遅いため、int4 定量モデルを直接ダウンロードできます。
私は、12G ビデオ メモリの RTX 3060 グラフィックス カードを搭載した I7 8 コア PC にこのインストールを完了しました。このコンピュータは私の仕事用コンピュータなので、システムの WSL サブネットに ChatGLM をインストールしました。 ChatGLM を WINDOWS WSL サブシステムにインストールするのは、LINUX 環境に直接インストールするよりも複雑です。最大の落とし穴は、グラフィック カード ドライバーのインストールです。 ChatGLM を Linux に直接展開する場合は、NVIDIA ドライバーを直接インストールし、modprobe を通じてネットワーク カード ドライバーをアクティブ化する必要があります。 WSL へのインストールはまったく異なります。
ChatGLM は github からダウンロードできます。Web サイトにはいくつかの簡単なドキュメントもあり、Windows WSL に ChatGLM をデプロイするためのドキュメントも含まれています。ただし、この分野の初心者がこのドキュメントに従って完全に展開すると、無数の落とし穴に遭遇することになります。
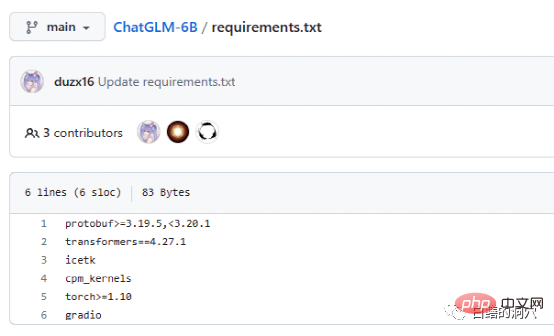
Requriements.txt ドキュメントには、ChatGLM で使用される主要なオープン ソース コンポーネントのリストとバージョン番号がリストされています。コアはトランスフォーマーであり、バージョンが必要です4.27. 1. 実際にはそれほど厳しい要件ではなく、多少低くても大きな問題はありませんが、安全性を考慮すると同じバージョンを使用する方が良いでしょう。 Icetk はトークン処理用、cpm_kernels は中国語処理モデルと cuda のコア呼び出し、protobuf は構造化データ ストレージ用です。 Gradio は、Python を使用して AI アプリケーションを迅速に生成するためのフレームワークです。トーチについての説明は必要ありません。
ChatGLM は、GPU のない環境でも CPU と 32GB の物理メモリを使用して実行できますが、実行速度が非常に遅いため、デモ検証のみに使用できます。 ChatGLM をプレイしたい場合は、GPU を装備するのが最善です。
ChatGLM を WSL にインストールする際の最大の落とし穴は、グラフィック カード ドライバーです。Git 上の ChatGLM のドキュメントは非常に不親切です。このプロジェクトについてあまり知らない人、またはそのようなデプロイメントを行ったことがない人にとっては、ドキュメントが重要です。本当に紛らわしいです。実際、ソフトウェアの導入は難しくありませんが、グラフィックス カードのドライバーは非常に扱いにくいです。
WSL サブシステム上に展開されるため、LINUX は単なるエミュレーション システムであり、完全な LINUX ではありません。したがって、NVIDIA のグラフィックス ドライバーは WINDOWS にインストールするだけで済み、WSL でアクティブ化する必要はありません。ただし、WSL の LINUX 仮想環境には CUDA TOOLS をインストールする必要があります。 WINDOWS上のNVIDIAドライバは公式サイトから最新ドライバをインストールする必要があり、WIN10/11に付属の互換ドライバは使用できませんので、公式サイトから最新ドライバをダウンロードしてインストールすることを省略しないでください。
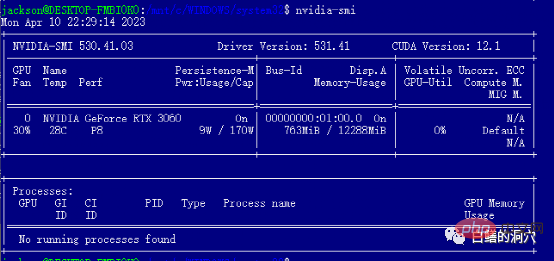
WIN ドライバーをインストールした後、WSL に cuda ツールを直接インストールできます。インストールが完了したら、nvidia-smi を実行し、上記の内容が表示されるかどうかを確認します。インターフェース 、おめでとうございます。最初のピットを回避できました。実際、cuda ツールをインストールするときにいくつかの落とし穴に遭遇することがあります。つまり、システムには、適切なバージョンの gcc、gcc-dev、make、およびその他のコンパイル関連ツールがインストールされている必要があります。これらのコンポーネントが不足している場合、cuda ツールのインストールは失敗します。
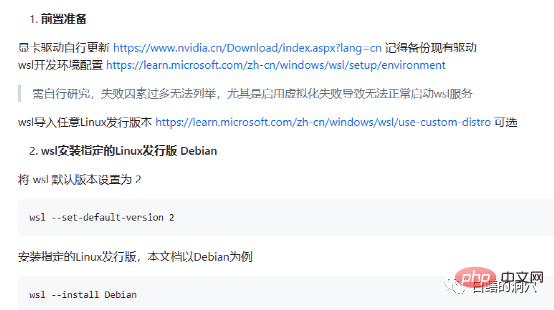
上記は、初期準備の落とし穴ですが、実際には、NVIDIA ドライバーの落とし穴と、その後の準備の落とし穴を回避できます。取り付けはまだ非常にスムーズです。システムの選択に関しては、やはり Debian 互換の Ubuntu を選択することをお勧めします。Ubuntu の新しいバージョンの aptitude は非常にスマートで、多数のソフトウェアのバージョン互換性の問題を解決し、一部のソフトウェアの自動バージョン ダウングレードを実現するのに役立ちます。
以下のインストール作業は、インストールガイドに従ってスムーズに完了できますが、/etc/apt/sources.list のインストールソースを置き換える作業は、ガイドに従って完了するのが最適です。一方では、インストール速度が大幅に向上し、他方では、ソフトウェア バージョンの互換性の問題も回避されます。もちろん、交換しない場合でも、その後のインストール プロセスに必ずしも影響するわけではありません。
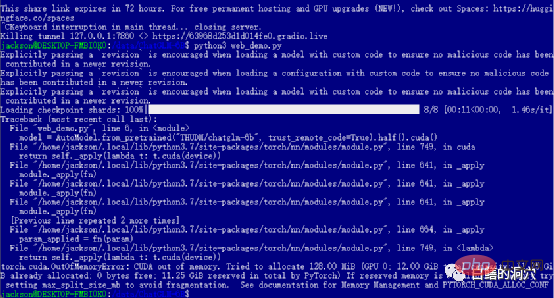
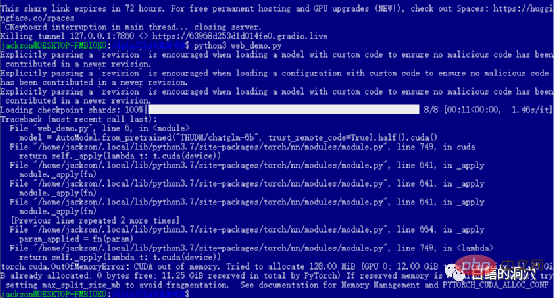
前のレベルに合格した場合は、最後のステップに入り、 web_demo を開始したことになります。 python3 web_demo.py を実行すると、WEB 会話の例を開始できます。このとき、もしあなたが 12GB のビデオメモリを搭載した 3060 しか持っていない貧乏人であれば、間違いなく上記のエラーが表示されます。PYTORCH_CUDA_ALLOC_CONF を最小の 21 に設定したとしても、このエラーは回避できません。この時点では、怠けてはいけません。単純に Python スクリプトを書き直す必要があります。
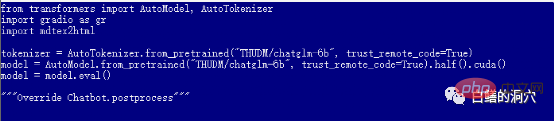
#デフォルトの web_demo.py は、FP16 事前トレーニング済みモデルを使用します。13GB を超えるモデルは、12GB にはロードされません。既存のメモリが存在しないため、このコードを少し調整する必要があります。

以上がChatGLM を使用する際の落とし穴を避けるためのいくつかのヒントの詳細内容です。詳細については、PHP 中国語 Web サイトの他の関連記事を参照してください。

















![[Web フロントエンド] Node.js クイック スタート](https://img.php.cn/upload/course/000/000/067/662b5d34ba7c0227.png)



