

すべての SOTA 生成モデルを 1 つの記事で読んでください: 9 つのカテゴリーにおける 21 のモデルの完全なレビュー!

過去 2 年間で、AI 業界では大規模な生成モデルのリリースが急増しました。特に、Stable Diffusion のオープンソースと ChatGPT のオープン インターフェイスの登場により、AI 業界の開発がさらに刺激されました。生成モデルに対する業界の熱意。
しかし、生成モデルの種類が多く、リリーススピードが非常に速いので、注意しないとsotaを見逃してしまう可能性があります
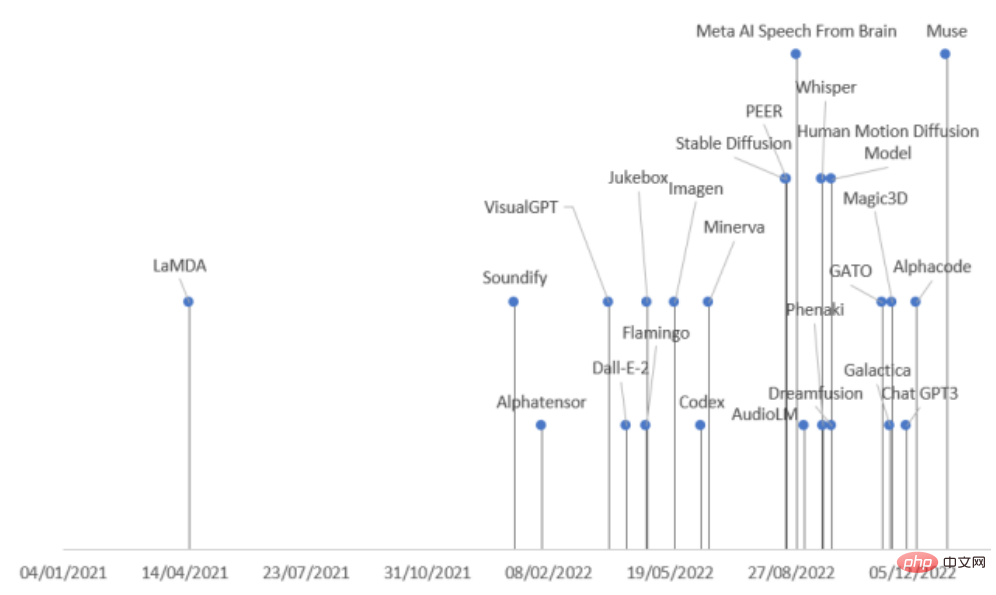
最近、スペイン・コミラビショップ・セント・ジョンズ大学の研究者らは、さまざまな分野におけるAIの最新の進歩を包括的にレビューし、タスクモードと分野に応じて生成モデルを9つのカテゴリーに分類し、生成を一度に理解できるように2022年にリリースされた21の生成モデルをまとめました。モデルの歴史!

論文リンク: https://arxiv.org/abs/2301.04655
生成 AI 分類
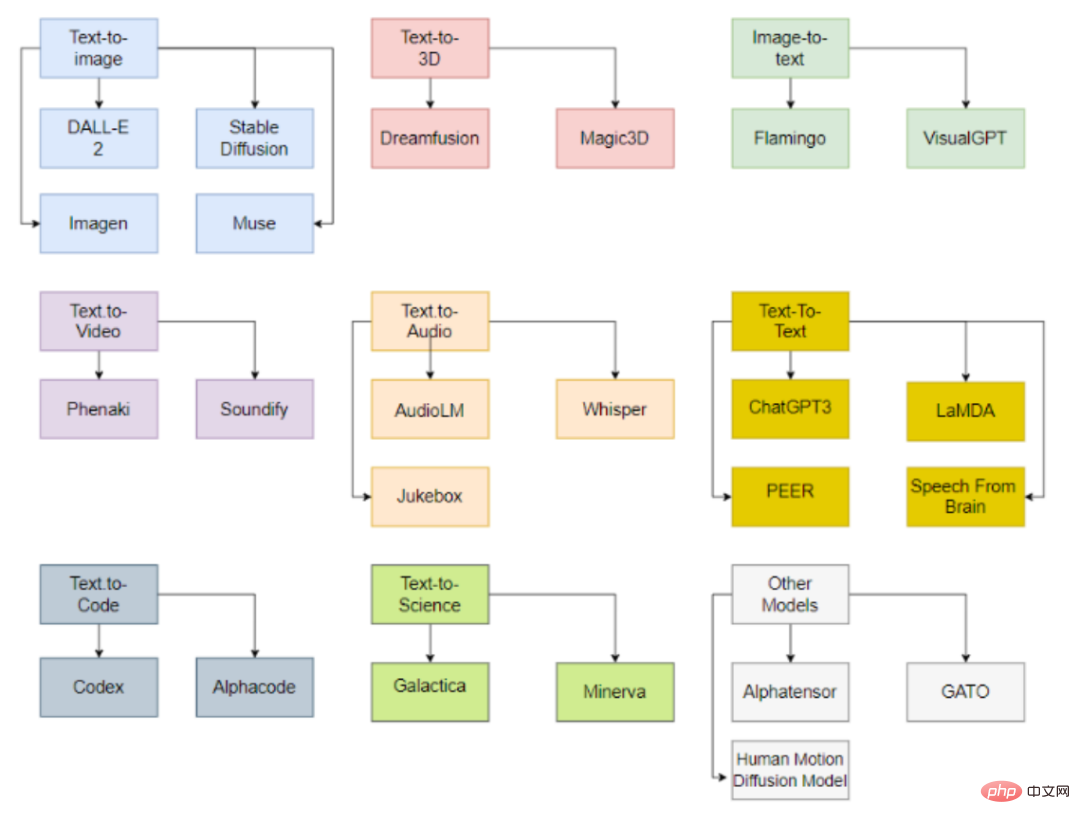
モデルは入力に従うことができます出力データの種類は分類されており、現在主に 9 つのカテゴリが含まれています。
興味深いことに、これらの大規模な公開モデルの背後で、これらの最新モデルの展開に関与しているのは 6 つの組織 (OpenAI、Google、DeepMind、Meta、Runway、Nvidia) だけです。
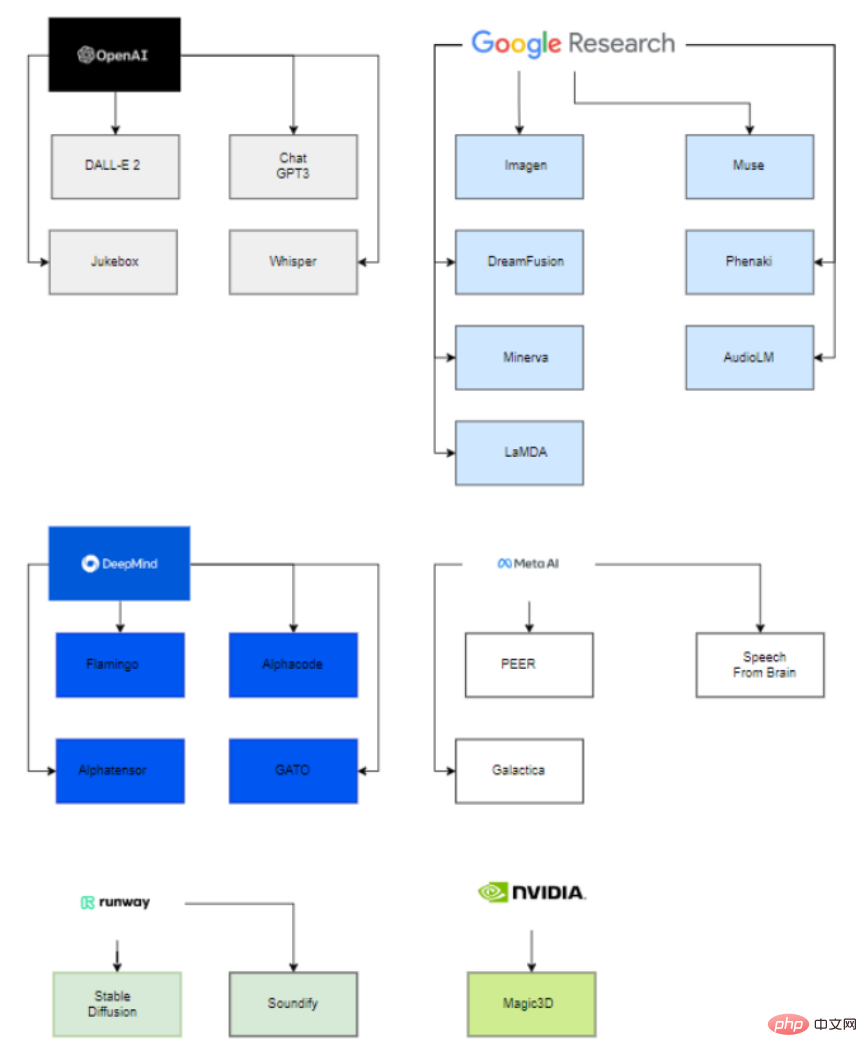
主な理由は、これらのモデルのパラメーターを推定できるようにするには、非常に大きな計算能力と、高度なスキルと経験を積んだ人材が必要であるためです。データ サイエンスとデータ エンジニアリングのチーム。
したがって、買収したスタートアップの支援や学術界との協力を得たこれらの企業だけが、生成 AI モデルの導入を成功させることができます。
大企業がスタートアップに関与するという点では、Microsoft が OpenAI に 10 億ドルを投資し、モデル開発を支援していることがわかります。同様に、Google は 2014 年に Deepmind を買収しました。
大学側では、VisualGPT はキング アブドラ科学技術大学 (KAUST)、カーネギー メロン大学、南洋理工大学によって開発され、ヒューマン モーション拡散モデルはイスラエルのテルアビブ大学によって開発されました。
同様に、Stable Diffusion は Runway、Stability AI、ミュンヘン大学によって開発され、Soundify は Runway とカーネギー メロン大学によって開発され、DreamFusion は企業と大学によって開発されています。 Googleとカリフォルニア大学バークレー校。
Text-to-image モデル
DALL-E 2
DALL-E 2 は、OpenAI によって開発され、オリジナルのリアルな画像とアートを生成できます。 OpenAI はモデルにアクセスするための API を提供しています。
DALL-E 2 の特別な点は、概念、属性、さまざまなスタイルを組み合わせる能力です。その能力は、言語イメージの事前トレーニング済みモデル CLIP ニューラル ネットワークから派生しているため、自然言語を使用できます。最も関連性の高いテキスト スニペットを示します。
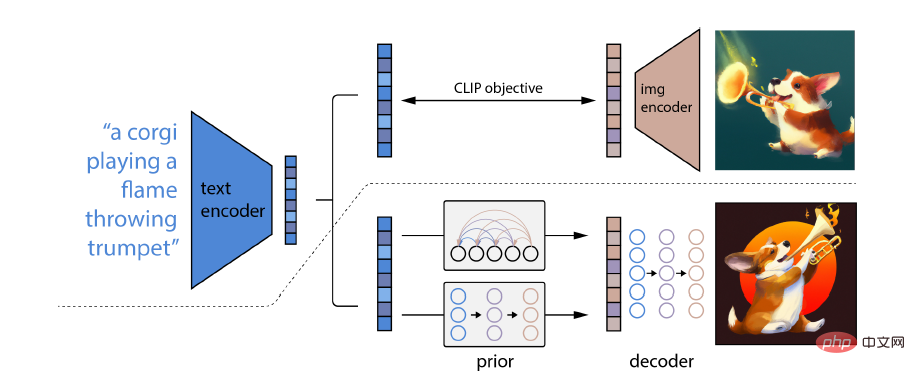
具体的には、CLIP 埋め込みには、画像配信の安定した変換を実行する機能、強力なゼロショット機能、微調整後の状態の達成など、いくつかの理想的な特性があります。 -芸術的な結果。
##完全な画像生成モデルを取得するには、CLIP 画像埋め込みデコーダ モジュールを以前のモデルと組み合わせて、指定されたテキスト キャプションから関連する CLIP 画像埋め込みを生成します #その他のモデルには、Imagen、Stable Diffusion、Muse などがあります。
#その他のモデルには、Imagen、Stable Diffusion、Muse などがあります。
Text-to-3D モデル
一部の業界では、2D 画像のみを生成でき、自動化を完了できません。ゲーム分野では、3D モデルを生成する必要があります。
DreamfusionGoogle Research によって開発された DreamFusion は、テキストから 3D への合成に、事前トレーニングされた 2D テキストから画像への拡散モデルを使用します。
Dreamfusion は、CLIP 手法を 2 次元拡散モデルの蒸留から得られる損失に置き換えます。つまり、拡散モデルは、サンプルを生成するための一般的な連続最適化問題の損失として使用できます。
 主にピクセルをサンプリングする他の方法と比較して、パラメータ空間でのサンプリングはピクセル空間でのサンプリングよりもはるかに困難です。DreamFusion は微分可能ジェネレーターを使用し、3D モデルの作成に重点を置いています。ランダムな角度から画像をレンダリングします。
主にピクセルをサンプリングする他の方法と比較して、パラメータ空間でのサンプリングはピクセル空間でのサンプリングよりもはるかに困難です。DreamFusion は微分可能ジェネレーターを使用し、3D モデルの作成に重点を置いています。ランダムな角度から画像をレンダリングします。

Magic3D などの他のモデルは NVIDIA によって開発されています。
画像からテキストへのモデル
画像を説明するテキストを取得することも役立ちます。これは、画像生成の逆バージョンに相当します。
Flamingo
このモデルは Deepmind によって開発され、ほんの数個の入出力サンプル プロンプトショット学習を使用して、オープンエンドの視覚言語タスクで実行できます。
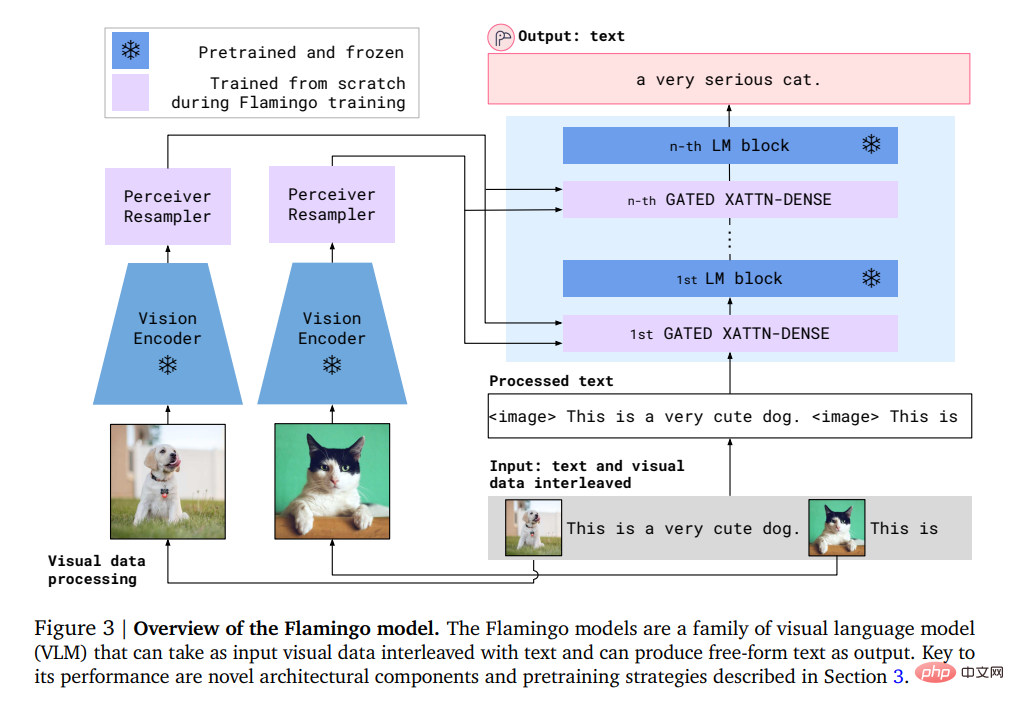
具体的には、Flamingo の入力には、視覚条件下での自己回帰テキスト生成モデルが含まれており、画像またはビデオとインターリーブされたテキスト トークン シーケンスを受け取り、出力としてテキストを生成できます。
ユーザーはモデルにクエリを入力し、写真またはビデオを添付すると、モデルがテキストの回答で応答します。

#Flamingo モデルは、視覚的なシーンを分析する視覚モデルと、基本的な推論形式を実行する大規模な言語モデルという 2 つの相補的なモデルを活用します。
VisualGPT
VisualGPT は、事前トレーニングされた言語モデル GPT-2 の知識を活用して OpenAI によって開発された画像記述モデルです。
異なるモダリティ間の意味論的なギャップを埋めるために、研究者らは、整流ゲート機能を備えた新しいエンコーダ-デコーダ注意メカニズムを設計しました。

VisualGPT の最大の利点は、他の画像からテキストへのモデルほど多くのデータを必要としないことです。これにより、画像記述モデルのデータ効率が向上し、ニッチな分野に応用したり、珍しいオブジェクトを説明したりできます。
Text-to-Video モデル
Phenaki
このモデルは、Google Research によって開発および作成されました。一連のテキスト プロンプトが与えられると、現実的なパフォーマンスが得られます。ビデオ合成。
Phenaki は、オープンドメインの時間変数キューからビデオを生成できる最初のモデルです。
データ問題を解決するために、研究者らは大規模な画像とテキストのペアのデータセットと少数のビデオとテキストの例で共同トレーニングを行い、最終的にビデオ データセットを超えた一般化機能を達成しました。
主に画像とテキストのデータセットには数十億の入力データが含まれる傾向がありますが、テキストとビデオのデータセットははるかに小さく、異なる長さのビデオを計算することも困難な問題です。

Phenaki モデルには、C-ViViT エンコーダー、トレーニング トランスフォーマー、ビデオ ジェネレーターの 3 つの部分が含まれています。
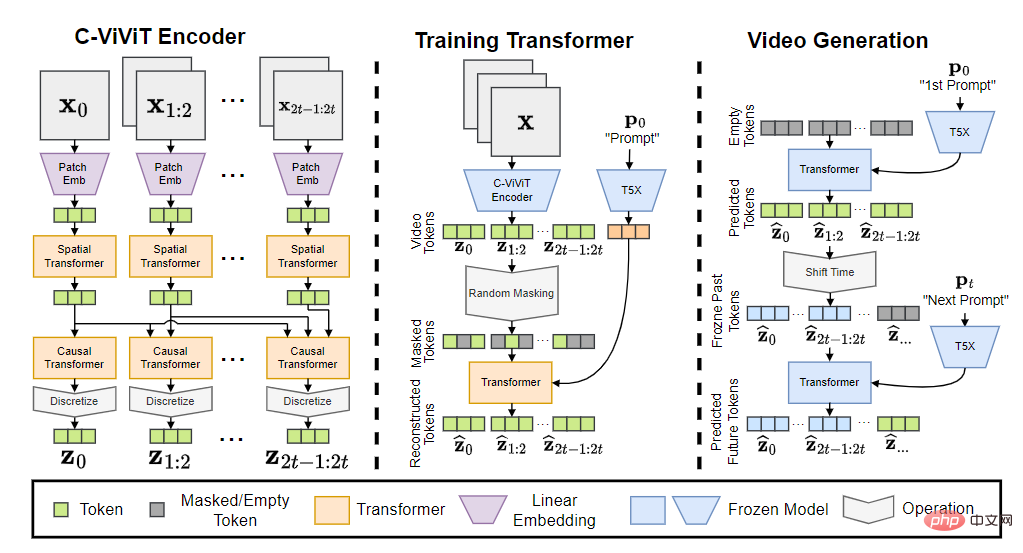
入力トークンを埋め込みに変換した後、時間 Transformer と空間 Transformer を通過し、アクティブ化せずに単一の線形投影を使用してトークンをマッピングし直します。ピクセル空間。
最終モデルは、オープンドメインのキューに基づいて時間的一貫性と多様性を備えたビデオを生成でき、データセットに存在しないいくつかの新しい概念を処理することもできます。
関連モデルには Soundify などがあります。
Text-to-Audio モデル
動画生成にはサウンドも欠かせません。
AudioLM
このモデルは Google によって開発され、長距離にわたって一貫した高品質のオーディオを生成するために使用できます。
AudioLM の特徴は、入力オーディオを個別のトークン シーケンスにマッピングし、この表現空間での言語モデリング タスクとしてオーディオ生成を使用することです。
生のオーディオ波形の大規模なコーパスでトレーニングすることにより、AudioLM は、短いプロンプトの下で自然で一貫した連続音声を生成することを学習しました。この方法は、トレーニング中に記号表現を追加することなく、人間の声以外の音声 (連続ピアノ音楽など) にも拡張できます。
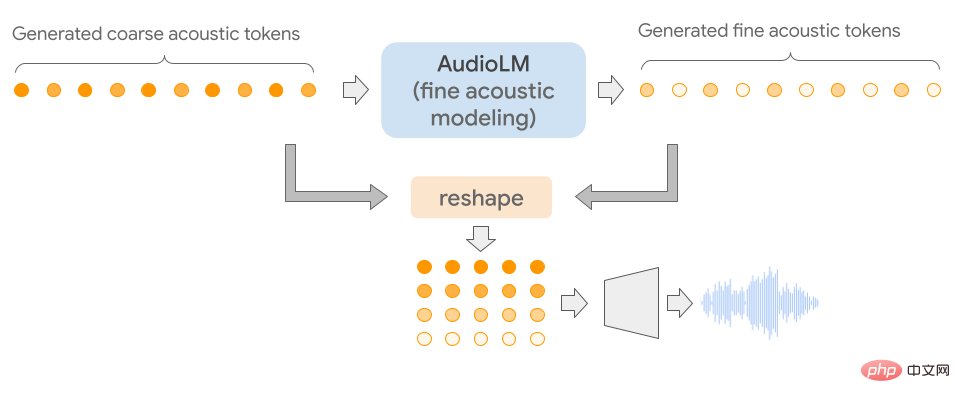
オーディオ信号には複数のスケールの抽象化が含まれるため、オーディオ合成中に複数のスケール間で一貫性を示しながら高いオーディオ品質を達成することは非常に困難です。 AudioLM モデルは、ニューラル オーディオ圧縮、自己教師あり表現学習、言語モデリングにおける最近の進歩を組み合わせて実装されています。
主観的な評価の場合、評価者は 10 秒間のサンプルを聞いて、それが人間の音声であるか合成音声であるかを判断するように求められます。収集された 1,000 件の評価に基づくと、その率は 51.2% であり、これはランダムに割り当てられたラベルと統計的に違いはありません。つまり、人間は合成サンプルと本物のサンプルを区別できません。
その他の関連モデルには、ジュークボックスやウィスパーなどがあります。
Text-to-Text モデル
質疑応答タスクでよく使用されます。
ChatGPT
人気の ChatGPT は、会話形式でユーザーと対話するために OpenAI によって開発されました。
ユーザーが質問またはプロンプト テキストの前半を行うと、モデルが後続の部分を完成させ、誤った入力条件を特定し、不適切な要求を拒否できます。
具体的には、ChatGPT の背後にあるアルゴリズムは Transformer であり、トレーニング プロセスは主に人間のフィードバックに基づく強化学習です。
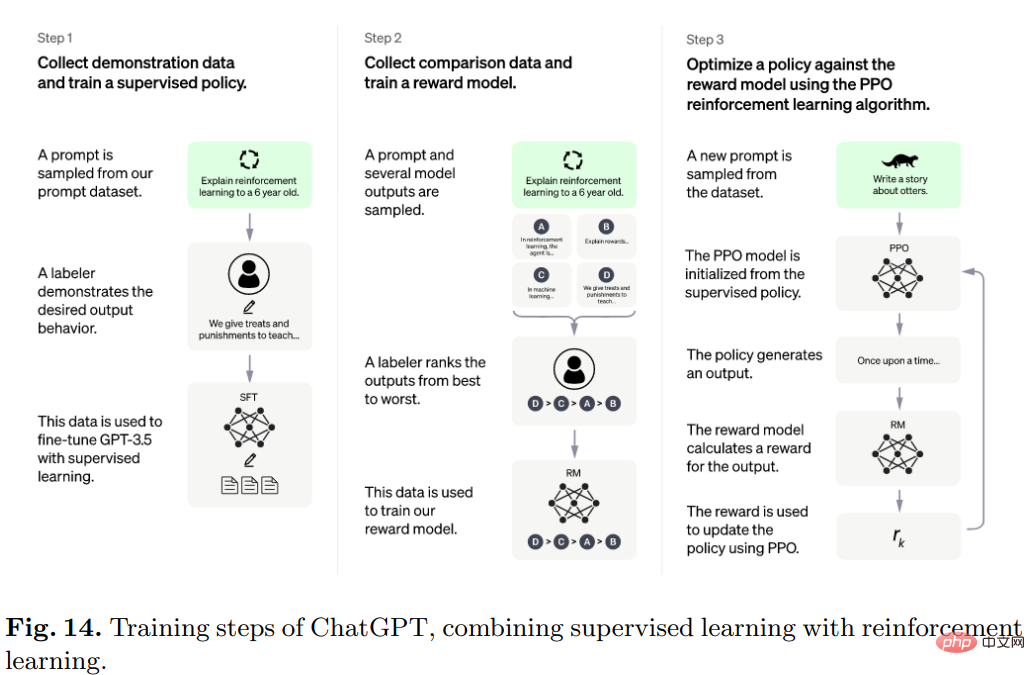
最初のモデルは教師あり学習のもとで微調整を使用してトレーニングされ、その後人間がユーザーと AI アシスタントとしてお互いを演じる会話を提供し、その後人間がモデルから返された応答を修正し、モデルが正しい答えで改善されるのを助けます。
生成されたデータセットを InstructGPT のデータセットと混合し、会話形式に変換します。
その他の関連モデルには、LaMDA および PEER などがあります。
Text-to-Code モデル
は、特殊なタイプのテキストを生成する点を除けば、text-to-text と似ています。つまりコード。
Codex
OpenAI によって開発されたこのモデルは、テキストをコードに変換できます。
Codex は、基本的にあらゆるプログラミング タスクに適用できる一般的なプログラミング モデルです。
プログラミング時の人間の活動は 2 つの部分に分けることができます: 1) 問題をより単純な問題に分解する; 2) これらの問題を既存の既存のコード (ライブラリ、API、または関数) 中間にマッピングする。
2 番目の部分はプログラマにとって最も時間のかかる部分であり、Codex が最も得意とする部分でもあります。
トレーニング データは、2020 年 5 月に GitHub でホストされているパブリック ソフトウェア リポジトリから収集されました。これには 179 GB の Python ファイルが含まれており、すでに強力な自然言語が含まれている GPT-3 で微調整されています。表現。
関連モデルには Alphacode も含まれます
Text-to-Science モデル
科学研究テキストも AI テキスト生成の目標の 1 つですが、まだ長い道のりがあります結果を出しに行くんだ。行かなきゃ。
Gaoptica
このモデルは、Meta AI と Papers with Code によって共同開発され、科学テキストの大規模モデルを自動的に整理するために使用できます。
ギャラクティカの主な利点は、複数のエピソードをトレーニングした後でもモデルが過剰適合せず、トークンの再利用により上流と下流のパフォーマンスが向上することです。
そして、すべてのデータが共通のマークダウン形式で処理され、さまざまなソースからの知識の混合が可能になるため、このアプローチではデータセットの設計が重要です。
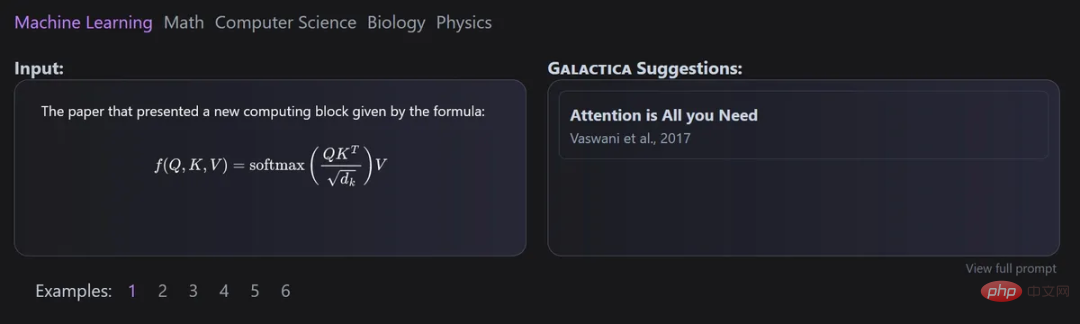
引用は特定のトークンを通じて処理されるため、研究者はあらゆる入力コンテキストで引用を予測できます。ギャラクティカ モデルの引用を予測する能力は、規模が大きくなるにつれて増加します。
さらに、このモデルは、すべてのサイズのモデルに対して GeLU アクティベーションを備えたデコーダーのみの設定で Transformer アーキテクチャを使用し、SMILES の化学式とタンパク質配列を含むマルチモーダル タスクの実行を可能にします。
##MinervaMinerva の主な目的は数学的および科学的問題を解決することであり、この目的のために大量の学習データを収集し、定量的推論問題や大規模な問題を解決してきました。質問を作成するために、最先端の推論テクニックも使用されます。
Minerva サンプリング言語モデル アーキテクチャは、段階的な推論を使用して入力の問題を解決します。つまり、入力には、外部ツールを導入せずに計算と記号操作が含まれている必要があります。
その他のモデル
上記に該当しないモデルもございます。
AlphaTensorDeepmind によって開発されたこのモデルは、新しいアルゴリズムを発見できるため、業界で完全に革新的なモデルです。
公開された例では、AlphaTensor はより効率的な行列乗算アルゴリズムを作成しました。このアルゴリズムは非常に重要であるため、ニューラル ネットワークから科学計算プログラムに至るまで、あらゆるものがこの効率的な乗算計算の恩恵を受けることができます。
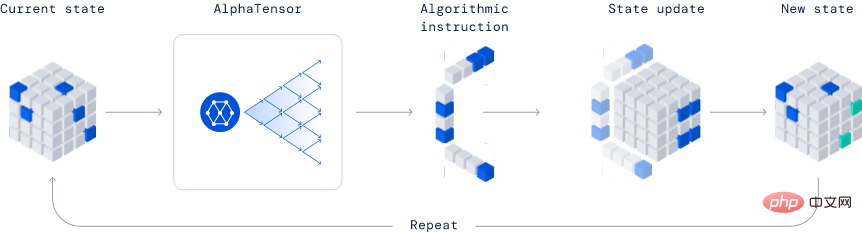 この手法は深層強化学習手法に基づいており、エージェント AlphaTensor のトレーニング プロセスはシングル プレイヤー ゲームをプレイすることであり、目標は次のことを見つけることです。限られた因子空間でのテンソル分解。
この手法は深層強化学習手法に基づいており、エージェント AlphaTensor のトレーニング プロセスはシングル プレイヤー ゲームをプレイすることであり、目標は次のことを見つけることです。限られた因子空間でのテンソル分解。
TensorGame の各ステップで、プレイヤーは行列のさまざまなエントリを組み合わせて乗算を実行する方法を選択し、正しい乗算結果を得るために必要な演算数に基づいてボーナス ポイントを受け取る必要があります。 AlphaTensor は、特別なニューラル ネットワーク アーキテクチャを使用して、合成トレーニング ゲームの対称性を活用します。
GATO
このモデルは、Deepmind によって開発された汎用エージェントであり、マルチモーダル、マルチタスク、またはマルチ実施形態の一般化戦略として使用できます。
同じ重みを持つ同じネットワークで、Atari ゲームのプレイ、画像の説明、チャット、ブロックの積み重ねなど、非常に異なる機能をホストできます。
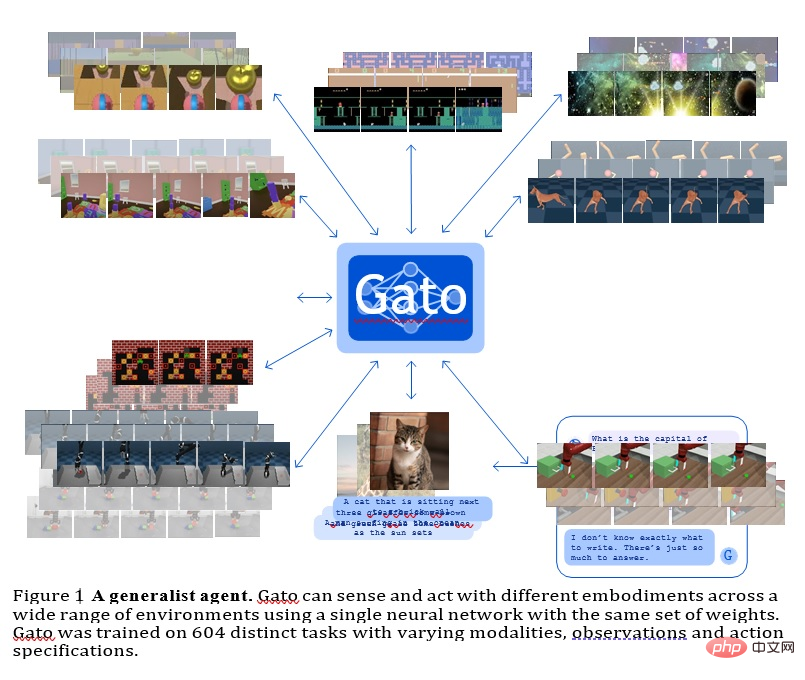
すべてのタスクにわたって単一のニューラル シーケンス モデルを使用することには多くの利点があり、独自の帰納的バイアスを備えた戦略的モデルを手作りする必要性が減り、トレーニング データとデータの量が増加します。多様性。
この汎用エージェントは、幅広いタスクで成功し、わずかな追加データでさらに多くのタスクで成功するように調整できます。
現在、GATO には約 12 億個のパラメータがあり、実世界のロボットのモデル スケールをリアルタイムで制御できます。
公開されているその他の生成人工知能モデルには、人間の動作の生成などが含まれます。
参考: https://arxiv.org/abs/2301.04655
以上がすべての SOTA 生成モデルを 1 つの記事で読んでください: 9 つのカテゴリーにおける 21 のモデルの完全なレビュー!の詳細内容です。詳細については、PHP 中国語 Web サイトの他の関連記事を参照してください。

ホットAIツール

Undresser.AI Undress
リアルなヌード写真を作成する AI 搭載アプリ

AI Clothes Remover
写真から衣服を削除するオンライン AI ツール。

Undress AI Tool
脱衣画像を無料で

Clothoff.io
AI衣類リムーバー

AI Hentai Generator
AIヘンタイを無料で生成します。

人気の記事
ホットツール

メモ帳++7.3.1
使いやすく無料のコードエディター

SublimeText3 中国語版
中国語版、とても使いやすい

ゼンドスタジオ 13.0.1
強力な PHP 統合開発環境

ドリームウィーバー CS6
ビジュアル Web 開発ツール

SublimeText3 Mac版
神レベルのコード編集ソフト(SublimeText3)
ホットトピック
 7488
7488
 15
1377
52
77
11
19
39
15
1377
52
77
11
19
39

 世界で最も強力なオープンソース MoE モデルが登場。GPT-4 に匹敵する中国語機能を備え、価格は GPT-4-Turbo のわずか 1% 近くです
May 07, 2024 pm 04:13 PM
世界で最も強力なオープンソース MoE モデルが登場。GPT-4 に匹敵する中国語機能を備え、価格は GPT-4-Turbo のわずか 1% 近くです
May 07, 2024 pm 04:13 PM
従来のコンピューティングを超える能力を備えているだけでなく、より低コストでより効率的なパフォーマンスを実現する人工知能モデルを想像してみてください。これは SF ではありません。世界で最も強力なオープンソース MoE モデルである DeepSeek-V2[1] が登場しました。 DeepSeek-V2 は、経済的なトレーニングと効率的な推論の特徴を備えた強力な専門家混合 (MoE) 言語モデルです。これは 236B のパラメータで構成されており、そのうち 21B は各マーカーをアクティブにするために使用されます。 DeepSeek67B と比較して、DeepSeek-V2 はパフォーマンスが優れていると同時に、トレーニング コストを 42.5% 節約し、KV キャッシュを 93.3% 削減し、最大生成スループットを 5.76 倍に高めます。 DeepSeek は一般的な人工知能を研究する会社です
 AI が数学研究を破壊する!フィールズ賞受賞者で中国系アメリカ人の数学者が上位 11 件の論文を主導 | テレンス・タオが「いいね!」しました
Apr 09, 2024 am 11:52 AM
AI が数学研究を破壊する!フィールズ賞受賞者で中国系アメリカ人の数学者が上位 11 件の論文を主導 | テレンス・タオが「いいね!」しました
Apr 09, 2024 am 11:52 AM
AI は確かに数学を変えつつあります。最近、この問題に細心の注意を払っている陶哲軒氏が『米国数学協会会報』(米国数学協会会報)の最新号を送ってくれた。 「機械は数学を変えるのか?」というテーマを中心に、多くの数学者が意見を述べ、そのプロセス全体は火花に満ち、ハードコアで刺激的でした。著者には、フィールズ賞受賞者のアクシャイ・ベンカテシュ氏、中国の数学者鄭楽軍氏、ニューヨーク大学のコンピューター科学者アーネスト・デイビス氏、その他業界で著名な学者を含む強力な顔ぶれが揃っている。 AI の世界は劇的に変化しています。これらの記事の多くは 1 年前に投稿されたものです。
 こんにちは、電気アトラスです!ボストン・ダイナミクスのロボットが復活、180度の奇妙な動きにマスク氏も恐怖
Apr 18, 2024 pm 07:58 PM
こんにちは、電気アトラスです!ボストン・ダイナミクスのロボットが復活、180度の奇妙な動きにマスク氏も恐怖
Apr 18, 2024 pm 07:58 PM
Boston Dynamics Atlas は正式に電動ロボットの時代に突入します!昨日、油圧式アトラスが歴史の舞台から「涙ながらに」撤退したばかりですが、今日、ボストン・ダイナミクスは電動式アトラスが稼働することを発表しました。ボストン・ダイナミクス社は商用人型ロボットの分野でテスラ社と競争する決意を持っているようだ。新しいビデオが公開されてから、わずか 10 時間ですでに 100 万人以上が視聴しました。古い人が去り、新しい役割が現れるのは歴史的な必然です。今年が人型ロボットの爆発的な年であることは間違いありません。ネットユーザーは「ロボットの進歩により、今年の開会式は人間のように見え、人間よりもはるかに自由度が高い。しかし、これは本当にホラー映画ではないのか?」とコメントした。ビデオの冒頭では、アトラスは仰向けに見えるように地面に静かに横たわっています。次に続くのは驚くべきことです
 MLP に代わる KAN は、オープンソース プロジェクトによって畳み込みまで拡張されました
Jun 01, 2024 pm 10:03 PM
MLP に代わる KAN は、オープンソース プロジェクトによって畳み込みまで拡張されました
Jun 01, 2024 pm 10:03 PM
今月初め、MIT やその他の機関の研究者らは、MLP に代わる非常に有望な代替案である KAN を提案しました。 KAN は、精度と解釈可能性の点で MLP よりも優れています。また、非常に少数のパラメーターを使用して、多数のパラメーターを使用して実行する MLP よりも優れたパフォーマンスを発揮できます。たとえば、著者らは、KAN を使用して、より小規模なネットワークと高度な自動化で DeepMind の結果を再現したと述べています。具体的には、DeepMind の MLP には約 300,000 個のパラメーターがありますが、KAN には約 200 個のパラメーターしかありません。 KAN は、MLP が普遍近似定理に基づいているのに対し、KAN はコルモゴロフ-アーノルド表現定理に基づいているのと同様に、強力な数学的基礎を持っています。以下の図に示すように、KAN は
 Google は大喜び: JAX のパフォーマンスが Pytorch や TensorFlow を上回りました! GPU 推論トレーニングの最速の選択肢となる可能性があります
Apr 01, 2024 pm 07:46 PM
Google は大喜び: JAX のパフォーマンスが Pytorch や TensorFlow を上回りました! GPU 推論トレーニングの最速の選択肢となる可能性があります
Apr 01, 2024 pm 07:46 PM
Google が推進する JAX のパフォーマンスは、最近のベンチマーク テストで Pytorch や TensorFlow のパフォーマンスを上回り、7 つの指標で 1 位にランクされました。また、テストは最高の JAX パフォーマンスを備えた TPU では行われませんでした。ただし、開発者の間では、依然として Tensorflow よりも Pytorch の方が人気があります。しかし、将来的には、おそらくより大規模なモデルが JAX プラットフォームに基づいてトレーニングされ、実行されるようになるでしょう。モデル 最近、Keras チームは、ネイティブ PyTorch 実装を使用して 3 つのバックエンド (TensorFlow、JAX、PyTorch) をベンチマークし、TensorFlow を使用して Keras2 をベンチマークしました。まず、主流のセットを選択します
 テスラのロボットは工場で働く、マスク氏:手の自由度は今年22に達する!
May 06, 2024 pm 04:13 PM
テスラのロボットは工場で働く、マスク氏:手の自由度は今年22に達する!
May 06, 2024 pm 04:13 PM
テスラのロボット「オプティマス」の最新映像が公開され、すでに工場内で稼働可能となっている。通常の速度では、バッテリー(テスラの4680バッテリー)を次のように分類します:公式は、20倍の速度でどのように見えるかも公開しました - 小さな「ワークステーション」上で、ピッキング、ピッキング、ピッキング:今回は、それがリリースされたハイライトの1つビデオの内容は、オプティマスが工場内でこの作業を完全に自律的に行い、プロセス全体を通じて人間の介入なしに完了するというものです。そして、オプティマスの観点から見ると、自動エラー修正に重点を置いて、曲がったバッテリーを拾い上げたり配置したりすることもできます。オプティマスのハンドについては、NVIDIA の科学者ジム ファン氏が高く評価しました。オプティマスのハンドは、世界の 5 本指ロボットの 1 つです。最も器用。その手は触覚だけではありません
 FisheyeDetNet: 魚眼カメラに基づいた最初のターゲット検出アルゴリズム
Apr 26, 2024 am 11:37 AM
FisheyeDetNet: 魚眼カメラに基づいた最初のターゲット検出アルゴリズム
Apr 26, 2024 am 11:37 AM
目標検出は自動運転システムにおいて比較的成熟した問題であり、その中でも歩行者検出は最も初期に導入されたアルゴリズムの 1 つです。ほとんどの論文では非常に包括的な研究が行われています。ただし、サラウンドビューに魚眼カメラを使用した距離認識については、あまり研究されていません。放射状の歪みが大きいため、標準のバウンディング ボックス表現を魚眼カメラに実装するのは困難です。上記の説明を軽減するために、拡張バウンディング ボックス、楕円、および一般的な多角形の設計を極/角度表現に探索し、これらの表現を分析するためのインスタンス セグメンテーション mIOU メトリックを定義します。提案された多角形モデルの FisheyeDetNet は、他のモデルよりも優れたパフォーマンスを示し、同時に自動運転用の Valeo 魚眼カメラ データセットで 49.5% の mAP を達成しました。
 DualBEV: BEVFormer および BEVDet4D を大幅に上回る、本を開いてください!
Mar 21, 2024 pm 05:21 PM
DualBEV: BEVFormer および BEVDet4D を大幅に上回る、本を開いてください!
Mar 21, 2024 pm 05:21 PM
この論文では、自動運転においてさまざまな視野角 (遠近法や鳥瞰図など) から物体を正確に検出するという問題、特に、特徴を遠近法 (PV) 空間から鳥瞰図 (BEV) 空間に効果的に変換する方法について検討します。 Visual Transformation (VT) モジュールを介して実装されます。既存の手法は、2D から 3D への変換と 3D から 2D への変換という 2 つの戦略に大別されます。 2D から 3D への手法は、深さの確率を予測することで高密度の 2D フィーチャを改善しますが、特に遠方の領域では、深さ予測に固有の不確実性により不正確さが生じる可能性があります。 3D から 2D への方法では通常、3D クエリを使用して 2D フィーチャをサンプリングし、Transformer を通じて 3D と 2D フィーチャ間の対応のアテンション ウェイトを学習します。これにより、計算時間と展開時間が増加します。
