

Penn Machine Learning PhD: 一流の論文をゼロからどうやって書いたのでしょうか?

私は最近、非常に満足のいく論文を完成させました。プロセス全体が楽しく思い出深いだけでなく、真に「学術的影響と産業上の成果」も達成しました。私はこの記事が差分プライバシー (DP) ディープラーニングのパラダイムを変えると信じています。
この経験はあまりにも「偶然」なので(過程は偶然に満ちており、結論は非常に巧妙です)、私の観察をクラスメートと共有したいと思います-- >構想 -->経験的証拠 -->理論 -->大規模実験の完全なプロセス。この記事は軽量なものにし、技術的な詳細はあまり含まないようにするつもりです。

文書アドレス: arxiv.org/abs/2206.07136
論文では発表の順序が異なり、読者を惹きつけるために意図的に結論を最初に置いたり、単純化した定理を先に紹介して完全な定理を付録に置いたりすることがあります。この記事では、私の経験を時系列に記したいと思います。 (つまり、ランニングアカウント))、たとえば、科学研究の道を歩み始めたばかりの学生の参考のために、研究中に行った寄り道や予期せぬ状況を書き留めます。
1. 文献の読み方問題の発端はスタンフォード大学の論文であり、現在は ICLR に記録されています:

論文アドレス: https://arxiv.org/abs/2110.05679
この記事は非常によく書かれています要約すると 3 つのポイントがあります 主な貢献:
1. NLP タスクでは、DP モデルの精度が非常に高いため、言語モデルでのプライバシーの適用が促進されます。 (対照的に、CV の DP は非常に大きな精度の低下を引き起こします。たとえば、CIFAR10 は現在、DP 制限の下で事前トレーニングなしで 80% の精度を持っていますが、DP を考慮しなくても簡単に 95% に達します。当時の ImageNet の最高の DP 精度
#2. 言語モデルでは、モデルが大きいほどパフォーマンスが向上します。たとえば、GPT2 のパフォーマンスが 4 億パラメータから 8 億パラメータに向上したことは明らかであり、多くの SOTA も達成しています。 (ただし、CV および推奨システムでは、多くの場合、大規模なモデルのパフォーマンスは非常に低く、ランダムな推測に近くなります。たとえば、CIFAR10 の DP 最高精度は、以前は ResNet ではなく 4 層 CNN によって取得されていました。)
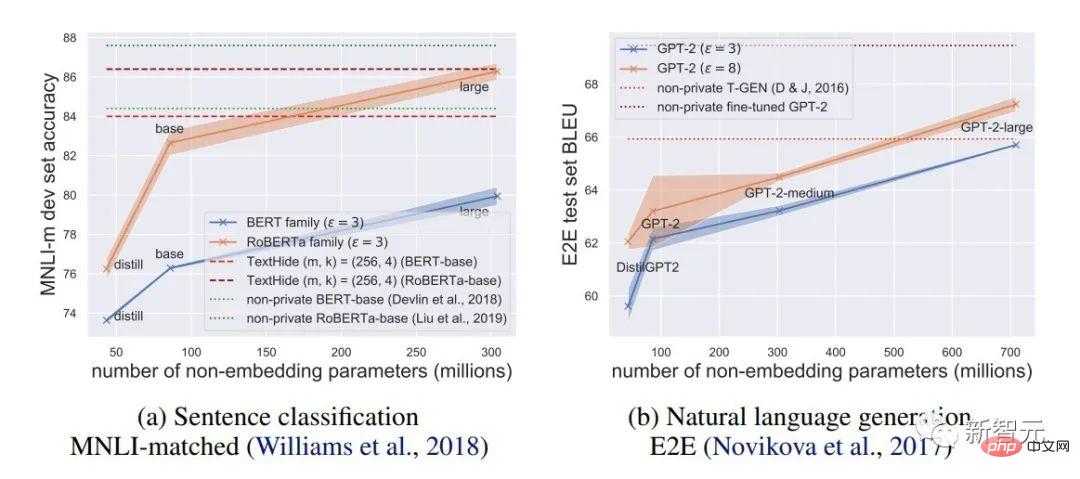
NLP タスクでは、DP モデルが大きいほどパフォーマンスが向上します [Xuechen et al. 2021]
3. 複数のタスクで SOTA を取得するためのハイパーパラメーターは一貫しています: クリッピングしきい値は十分に小さく設定する必要があり、学習率は大きくする必要があります。 (これまでの記事はすべて、タスクごとにクリッピングしきい値を調整するものでしたが、これには時間と労力がかかります。この記事のようなクリッピングしきい値 = 0.1 をすべてのタスクで実行したことはなく、パフォーマンスは非常に良好です。 )
#上記の要約は、論文を読んだ直後に私が理解したものであり、括弧内の内容はこの論文からのものではなく、これまでに多くの読書から生じた印象です。これは、長期にわたる読書の蓄積と、すぐに関連付けて比較するための高度な一般化能力に依存します。実際、多くの学生にとっては、1 つの記事の内容しか見ることができず、ネットワークを形成したり、分野全体の知識ポイントを関連付けることができないため、記事を書き始めるのは困難です。 . .一方で、勉強を始めたばかりの学生は読書量が足りず、知識ポイントを十分に習得していません。これは、長い間教師からプロジェクトを受けていて、自分から提案しない学生に特に当てはまります。一方で、読書量は十分であるものの、その時々で要約が行われていないため、情報が知識として凝縮されなかったり、知識が繋がらなかったりすることがあります。
DP ディープ ラーニングの背景知識は次のとおりです。DP の定義は読みには影響しないので、ここでは省略します。
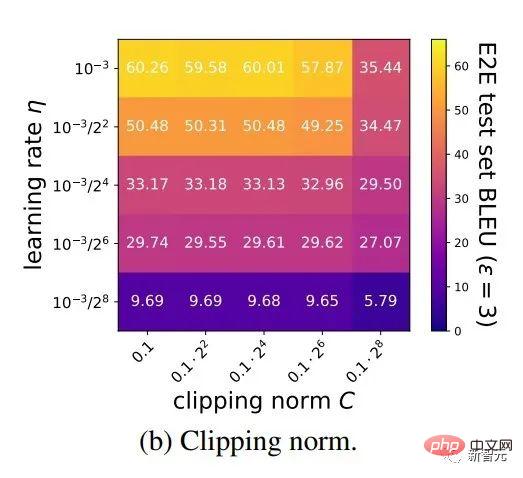
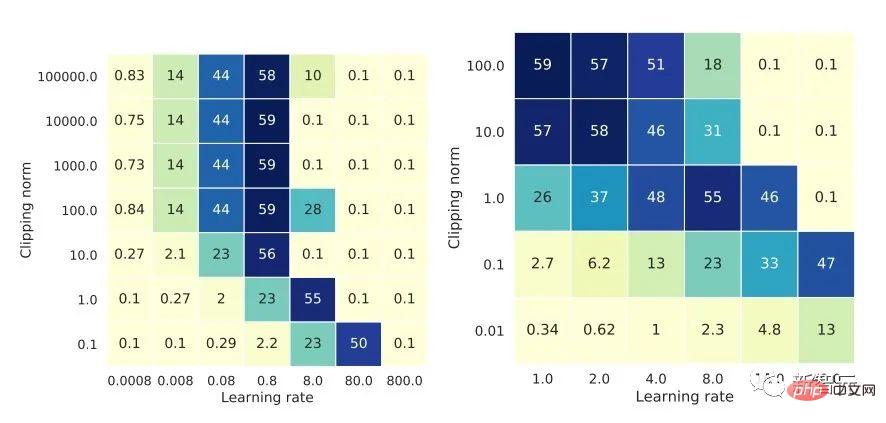
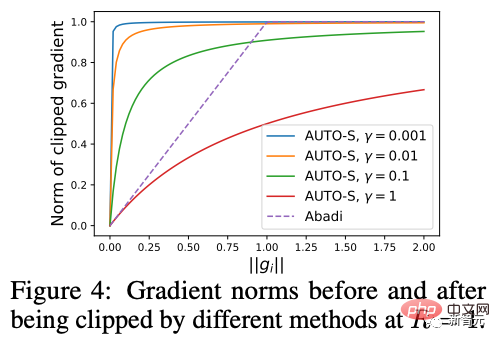
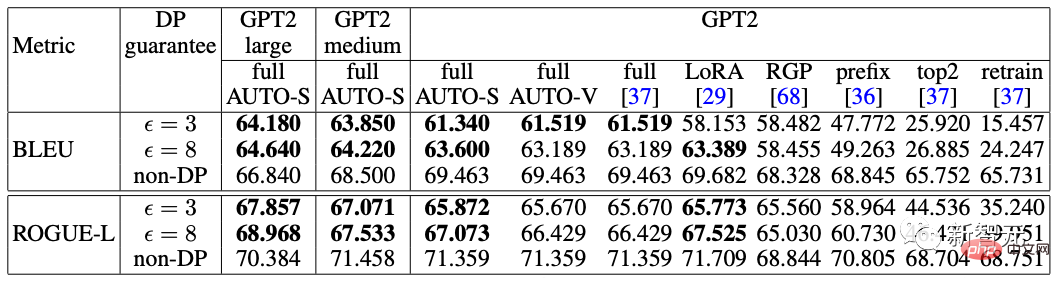
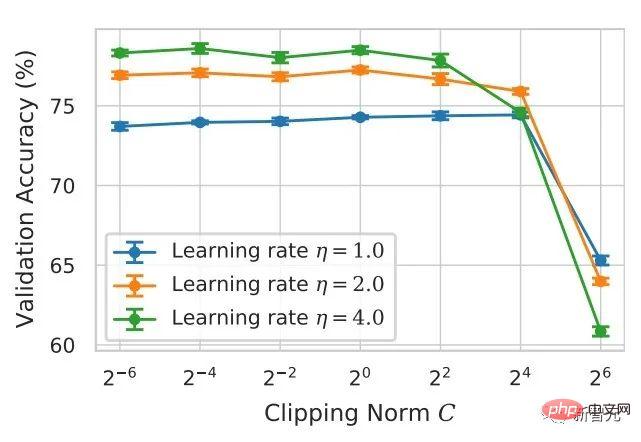
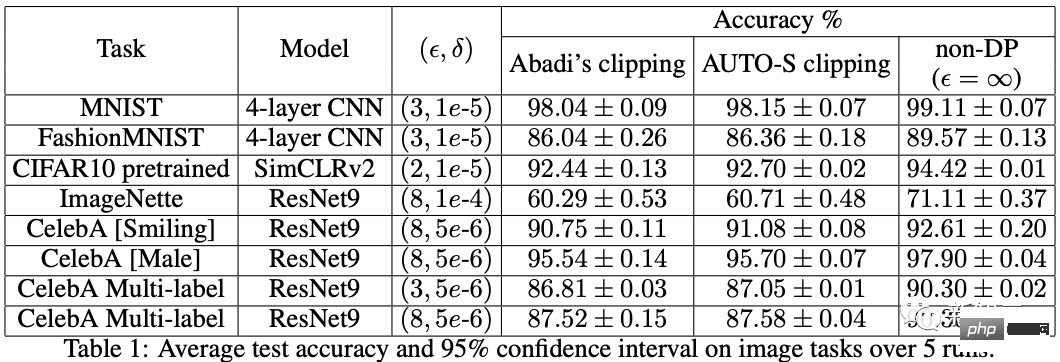
アルゴリズムの観点から見たいわゆる DP ディープ ラーニングは、実際には、サンプルごとの勾配クリッピングとガウス ノイズの追加という 2 つの追加のステップを実行することを意味します。つまり、これらに従って勾配を処理する限り、 2 つのステップ (処理された勾配はプライベート勾配と呼ばれます) その後、SGD/Adam などのオプティマイザーを自由に使用できます。 最終的なアルゴリズムがどの程度プライベートであるかについては、プライバシー会計理論と呼ばれる別のサブ分野の問題です。この分野は比較的成熟しており、強力な理論的基盤が必要ですが、この記事では最適化に焦点を当てているため、ここでは触れません。 g_i はデータ ポイントの勾配 (サンプルごとの勾配)、R はクリッピングしきい値、sigma はノイズ乗数です。 Clip は通常のグラデーションクリッピングと同様にクリッピング関数と呼ばれ、グラデーションが R より長い場合は R までカットされ、R より小さい場合はカットされません。動く。 たとえば、SGD の DP バージョンは、現在のすべての論文で使用されており、プライバシー深層学習の先駆的な研究です (Abadi、Martin ら、「差分プライバシーを備えた深層学習」)。 ") クリッピング関数 (Abadi のクリッピングとも呼ばれます): しかし、これはまったく必要ありません。最初の原則に従い、プライバシー会計理論から始めると、実際、クリッピング関数は、Clip(g_i)*g_i の係数が次の条件を満たすだけで済みます。 R 以下。それだけです。つまり、アバディのクリッピングはこの条件を満たす機能の一つに過ぎず、決して唯一ではないということだ。 記事には輝かしい点がたくさんありますが、そのすべてを私が使用できるわけではありません。私自身のニーズと専門知識に基づいています。 この記事の最初の 2 つの貢献は、実際には非常に経験的であり、掘り下げるのが困難です。最後の貢献は非常に興味深いものです。私はハイパーパラメータのアブレーション研究を注意深く観察し、元の著者が発見しなかった点を発見しました。それは、クリッピングしきい値が十分に小さい場合、実際には、クリッピングしきい値 (つまり、クリッピング ノルム C) 、上の式で R は変数です) は効果がありません。 縦方向では、C=0.1、0.4、1.6 は DP-Adam と違いがありません [Xuechen et al. 2021]。 これは私の興味を呼び起こし、その背後には何らかの原理があるに違いないと感じました。そこで私は、彼らがその理由を知るために使用した DP-Adam を手書きで書きました。実際、それは非常に簡単です: R が十分に小さい場合、クリッピングは次のようになります。実際には正規化と同等です! private gradient (1.1) を単純に置き換えることで、クリッピング部分とノイズ部分からそれぞれ R を抽出できます。 #そして、Adam の形式は次のようになります。 R は勾配と適応ステップ サイズの両方に表示されます。分子と分母がキャンセルされると、R はなくなり、アイデアがそこに存在します。 m と v は両方とも勾配に依存しており、プライベート勾配に置き換えると DP-AdamW になります。 このような単純な置換は、私の最初の定理を証明します。つまり、DP-AdamW では、調整パラメータがなければ、十分に小さいクリッピングしきい値は互いに同等です。 これは簡潔で興味深い観察であることは間違いありませんが、十分な意味を成していないため、この観察が実際にどのような用途があるのかを考える必要があります。 実際、これは、DP トレーニングによりパラメーター調整作業が 1 桁減少することを意味します。学習率と R がそれぞれ 5 つの値に調整されていると仮定すると (上の図に示すように)、最適なハイパーパラメータを見つけるには、25 の組み合わせをテストする必要があります。学習率を 5 つの可能性で調整するだけで済み、パラメータ調整の効率が数倍向上しました。これは業界にとって非常に貴重な問題点です。 意図は十分に高く、数学は十分に簡潔で、良いアイデアが形になり始めています。 Adam/AdamW のみに設定すると、この作業の限界がまだ大きすぎるため、すぐに AdamW に拡張し、 AdaGrad などの他の適応オプティマイザー。実際、すべての適応オプティマイザーについて、クリッピングしきい値がオフセットされることが証明できるため、パラメーターを調整する必要がなく、定理の内容が大幅に向上します。 ここにはもう 1 つの興味深い詳細があります。ご存知のとおり、重み減衰のある Adam は AdamW とは異なります。後者は分離された重み減衰を使用します。この違いについては ICLR が公開されました Adam にはウェイト減衰を追加する方法が 2 つあります。 この違いは DP オプティマイザーにも存在します。 Adam についても同様です。分離されたウェイト減衰が使用される場合、R のスケーリングはウェイト減衰のサイズに影響しません。ただし、通常のウェイト減衰が使用される場合、R を 2 倍に拡大することは、ウェイト減衰を 2 倍に減らすことと同じです。 賢い学生なら、私が常に適応オプティマイザーを強調してきたことに気づいたかもしれません。なぜ SGD について話さないのですか? 答えは次のとおりです。 DP適応オプティマイザの理論を書いた後、GoogleはすぐにCVで使われているDP-SGDの記事を公開し、アブレーションの研究も行ったが、Adamのルールとは全く異なっており、斜め上の印象を残した DP-SGD の場合、R が十分に小さい場合、lr を 10 倍増加させることは、R を 10 倍増加させることと同じです [https : //arxiv.org/abs/2201.12328]。 この記事を見たとき、私は非常に興奮しました。それは、小さなクリッピング閾値の有効性を証明した別の論文だったからです。 科学の世界では、連続する偶然の背後に隠れたパターンが存在することがよくあります。 # 単純な置換の後、SGD は Adam よりも分析が簡単であることがわかりました。(1.3) は次のように近似できます: ##明らかに、R を再度提案し、学習率と組み合わせて、Google の観察を理論的に証明することができます。 「具体的には、クリッピングノルムが k 倍減少した場合、同様の精度を維持するには学習率を k 倍増加する必要があります。」 Google が現象だけを見て理論のレベルまで到達しなかったのは残念です。ここにも偶然があり、上の写真では 2 つのスケールのアブレーション研究を同時に描いています。対角線が見えるのは左側のスケールだけです。右側を見ただけでは結論は出ません... 適応ステップサイズがないため、SGD は Adam のように R を無視せず、R を学習率の一部として扱うため、個別に調整する必要はありません。パラメータが調整されると、学習率も一緒に調整されます。 SGD の理論を運動量に拡張すると、Pytorch でサポートされるすべてのオプティマイザーが分析されました。 革新的な点はありますが、アバディのクリッピングはあくまで近似正規化であり均等化できないため、決定的な分析方法はありません。収束。 ドラえもん鉄人隊の原則に従い、6 年間この分野全体で使用されてきた Abadi クリッピングに代わる新しいサンプルごとの勾配クリッピング関数として正規化を直接命名しました。第二の革新点です。 先ほどの証明の後、新しいクリッピングは厳密には R を必要としないため、自動クリッピング (AUTO-V、バニラの場合は V) と呼ばれます。 アバディのクリッピングとはフォームが違うので精度も違いますし、私のクリッピングは不利になる可能性もあります。 つまり、新しいメソッドをテストするコードを記述する必要がありますが、変更する必要があるのはコードを 1 行だけ変更するだけです (結局のところ、これは単なる 実際には、DP サンプルごとの勾配クリッピングの方向には主に 3 つのクリッピング関数があります。Abadi のクリッピングに加えて、2 つは私が提案したもので、1 つはグローバル クリッピング、もう 1 つは、これは自動クリッピングです。以前の作業で、さまざまな一般的なライブラリでクリッピングを変更する方法をすでに知っていたので、記事の最後の付録に変更方法を記載しました。 テストの後、スタンフォード大学の記事で、GPT2 がトレーニング プロセス全体ですべての反復とすべてのサンプルごとの勾配をクリップしていることがわかりました。言い換えれば、少なくともこの実験では、アバディのクリッピングは自動クリッピングと完全に同等です。その後の実験では SOTA に負けましたが、このことは私の新しい方法に十分な価値があることを示しました。クリッピング閾値を調整する必要がなく、場合によっては精度が犠牲にならないクリッピング関数です。 スタンフォード大学の論文には、主に 2 つのタイプの言語モデル実験があり、1 つはモデルとして GPT2 を使用する生成タスクで、もう 1 つはモデルとして使用されます。 RoBERTa はモデル分類タスクです。自動クリッピングは生成タスクにおける Abadi のクリッピングと同等ですが、分類タスクにおける精度は常に数ポイント劣ります。 私自身の学術的な習慣のため、現時点ではデータセットを変更せず、その後、公開する主要な実験を選択するつもりはありません。ましてやトリック (データ強化や魔法のような変更など) を追加することはありません。モデルなど)。完全に公平な比較で、サンプルごとのグラジエント クリッピングのみを比較し、可能な限り最高の湿気のない効果を達成できることを願っています。 実際、共同研究者との議論の中で、純粋な正規化と Abadi のクリッピングでは、元の勾配に関係なく、つまり自動クリッピングの場合、勾配サイズ情報が完全に破棄されることがわかりました。はクリッピング後の R と同じ大きさであり、Abadi は R より小さいグラデーションのサイズ情報を保持します。 #このアイデアに基づいて、AUTO-S クリッピング (S は安定の略) と呼ばれる、小さいながらも非常に賢い変更を加えました。 これは少し見つかります (通常は 0.01 に設定されます)実際、グラデーション サイズの情報を保持するために、他の正の数に設定することもできます (非常に堅牢です): このアルゴリズムに基づいて、または、1 行変更するだけで Stanford コードを再実行すると、6 つの NLP データ セットの SOTA が得られます。 #E2E 生成タスクでは、AUTO-S は他のすべてのクリッピング関数を上回り、SST2/MNLI/QNLI/QQP 分類タスクでも優れています。上記も同様です。 スタンフォードの記事の 1 つの制限は、NLP のみに焦点を当てていることですが、偶然にも、Google が ImageNet の DP SOTA をブラッシュアップしてから 2 か月後、Google の子会社である DeepMind が、 DP が CV でいかに優れているかに関する記事をリリースし、ImageNet の精度を 48% から 84% に直接向上させました。 文書アドレス: https://arxiv.org/abs/2204.13650 この記事では、付録のこの図に進むまで、最初にオプティマイザーとクリッピングしきい値の選択について検討しました。 # ImageNet 上の #DP-SGD の SOTA では、クリッピングしきい値が十分に小さいことも必要です。 それでも、小さなクリッピングしきい値が最適に機能します。自動クリッピングをサポートする 3 つの高品質な記事により、私はすでに強いモチベーションを持っており、私の仕事が傑出したものになるだろうとますます確信しています。 偶然にも、DeepMind によるこの記事も理論のない純粋な実験であり、これにより彼らは理論的には R が必要ないことをほぼ認識するようになりました。実際、彼らは非常に近いものです。私がアイデアを思いつき、彼らは R を抽出して学習率と統合できることさえ発見しました (興味のある学生は式 (2) と (3) を見てください)。しかし、アバディのクリッピングの慣性が大きすぎた…ルールは理解したものの、それ以上は進まなかった。 DeepMind は、小さなクリッピングしきい値が最適であることも発見しましたが、その理由はわかりませんでした。 この新しい研究に触発されて、私は NLP や CV のための一連の手法を開発する代わりに、私のアルゴリズムをすべての DP 研究者が使用できるように CV の実験を開始しました。別のセットを実行します。 優れたアルゴリズムは汎用的で使いやすいものでなければなりません。事実は、自動クリッピングでも CV データ セットで SOTA を達成できることも証明しています。 上記のすべての論文を見ると、SOTA は大幅に改善され、エンジニアリングを達成しました。結果は満たされていますが、理論は完全に白紙です。 すべての実験を終了した時点で、この作業の貢献はトップカンファレンスの要件を超えています。経験的に小さなクリッピングしきい値を使用して DP-SGD とパラメータの影響を生成します。 DP-Adam は大幅に簡略化されています; 計算効率、プライバシーを犠牲にすることなく、パラメータ調整なしで新しいクリッピング関数が提案されています; 小さな γ は、Abadi のクリッピングと正規化によって引き起こされる勾配サイズ情報の損傷を修復します; 十分な NLP および CV 実験により SOTA が達成されています正確さ。 私はまだ満足していません。理論的サポートのないオプティマイザーは依然として深層学習に実質的な貢献をすることができません。毎年、数十の新しいオプティマイザーが提案されますが、それらはすべて 2 年目に破棄されます。 Pytorch によって正式にサポートされ、業界で実際に使用されているものはまだわずかです。 このため、共同研究者と私はさらに 2 か月かけて自動 DP-SGD 収束解析を行い、プロセスは困難でしたが、最終的な証明は極限まで簡素化されました。結論も非常にシンプルです。バッチ サイズ、学習率、モデル サイズ、サンプル サイズ、その他の変数が収束に及ぼす影響は定量的に表現され、既知のすべての DP トレーニング動作と一致します。 特に、DP-SGD は標準 SGD よりも収束が遅いものの、反復が無限大になる傾向がある場合、収束速度は桁違いであることを証明しました。これにより、プライバシーの計算に信頼性がもたらされます。DP モデルは、遅れてはいるものの収束します。 7ヶ月かけて書き上げた記事がついに完成しました、意外なことに偶然はまだ止まりません。 NeurIPS は 5 月に論文を提出し、内部修正が完了して 6 月 14 日に arXiv で公開されました。その結果、6 月 27 日にマイクロソフト リサーチ アジア (MSRA) が私たちの記事と衝突する記事を公開したのを確認しました。提案されたクリッピングは次のとおりです。自動クリッピングとまったく同じです: は AUTO-S とまったく同じです。 よく見ると、収束の証明もほぼ同じです。そして、この二つのグループには接点がなく、太平洋を越えて偶然が生まれたとも言えます。 2 つの記事の違いについて少し話しましょう。もう 1 つの記事はより理論的なもので、たとえば、Abadi DP-SGD の収束をさらに分析しています (私は自動を証明しただけです)クリッピング、これが彼らの記事の内容です) DP-NSGD、おそらく DP-SGD の調整方法がわかりません)、使用される仮定も多少異なります、そして私たちの実験はますます大規模になっています (12 以上のデータセット) 、そして、Abadi のクリッピングをより明示的に確立します。定理 1 および 2 などの正規化の等価関係は、R がパラメータ調整なしで使用できる理由を説明します。 同時に仕事でもあるので、共感し、補完し合ってこのアルゴリズムを共同で推進できる人がいるととても嬉しいです、コミュニティ全体がこの結果を信じて、できるだけ早くその恩恵を受けることができます。もちろん、私も勝手に次の記事を加速させます!と自分に言い聞かせます。 この記事の創作プロセスを原点から振り返ると、基礎的なスキルが前提条件であり、もう一つの重要な前提条件は、パラメータ調整の難しさは常に念頭に置いています。干ばつが続いているので、適切な記事を読むと蜜を見つけることができます。プロセスに関しては、中心となるのは観察を数学的に理論化する習慣であり、この作業ではコードを実装する能力は最も重要ではありません。別の本格的なコーディング作業に焦点を当てた別のコラムを書く予定ですが、最終的な収束分析も協力者と私自身の不屈の精神に依存しています。幸いなことに、美味しい食事に遅れることは心配ありませんので、そのまま続けてください。 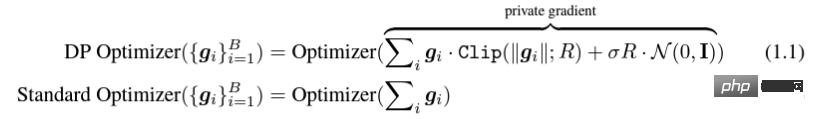
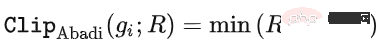 。
。 2. エントリーポイント
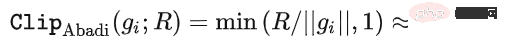
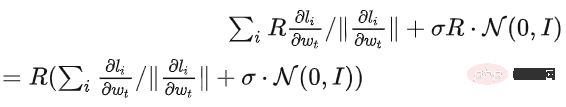
3. 単純な拡張

4. 別の世界があります
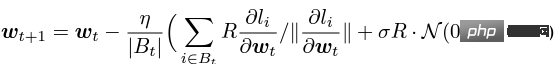
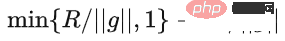 です)。
です)。 6. 抽象的思考に戻る
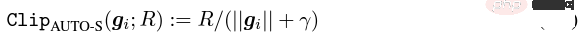
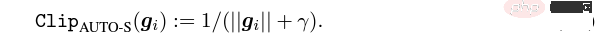
7. 一般的なアルゴリズムを作成する


9. 自動車事故...

10. まとめ
以上がPenn Machine Learning PhD: 一流の論文をゼロからどうやって書いたのでしょうか?の詳細内容です。詳細については、PHP 中国語 Web サイトの他の関連記事を参照してください。

ホットAIツール

Undresser.AI Undress
リアルなヌード写真を作成する AI 搭載アプリ

AI Clothes Remover
写真から衣服を削除するオンライン AI ツール。

Undress AI Tool
脱衣画像を無料で

Clothoff.io
AI衣類リムーバー

AI Hentai Generator
AIヘンタイを無料で生成します。

人気の記事
ホットツール

メモ帳++7.3.1
使いやすく無料のコードエディター

SublimeText3 中国語版
中国語版、とても使いやすい

ゼンドスタジオ 13.0.1
強力な PHP 統合開発環境

ドリームウィーバー CS6
ビジュアル Web 開発ツール

SublimeText3 Mac版
神レベルのコード編集ソフト(SublimeText3)
ホットトピック
 7554
7554
 15
1382
52
83
11
24
96
15
1382
52
83
11
24
96

 Centosシャットダウンコマンドライン
Apr 14, 2025 pm 09:12 PM
Centosシャットダウンコマンドライン
Apr 14, 2025 pm 09:12 PM
Centos Shutdownコマンドはシャットダウンし、構文はシャットダウン[オプション]時間[情報]です。オプションは次のとおりです。-hシステムをすぐに停止します。 -pシャットダウン後に電源をオフにします。 -r再起動; -t待機時間。時間は、即時(現在)、数分(分)、または特定の時間(HH:mm)として指定できます。追加の情報をシステムメッセージに表示できます。
 Centosのgitlabのバックアップ方法は何ですか
Apr 14, 2025 pm 05:33 PM
Centosのgitlabのバックアップ方法は何ですか
Apr 14, 2025 pm 05:33 PM
Centosシステムの下でのGitlabのバックアップと回復ポリシーデータセキュリティと回復可能性を確保するために、Gitlab on Centosはさまざまなバックアップ方法を提供します。この記事では、いくつかの一般的なバックアップ方法、構成パラメーター、リカバリプロセスを詳細に紹介し、完全なGitLabバックアップと回復戦略を確立するのに役立ちます。 1.手動バックアップGitlab-RakeGitlabを使用:バックアップ:コマンドを作成して、マニュアルバックアップを実行します。このコマンドは、gitlabリポジトリ、データベース、ユーザー、ユーザーグループ、キー、アクセスなどのキー情報をバックアップします。デフォルトのバックアップファイルは、/var/opt/gitlab/backupsディレクトリに保存されます。 /etc /gitlabを変更できます
 CentOS HDFS構成をチェックする方法
Apr 14, 2025 pm 07:21 PM
CentOS HDFS構成をチェックする方法
Apr 14, 2025 pm 07:21 PM
CENTOSシステムでHDFS構成をチェックするための完全なガイドこの記事では、CENTOSシステム上のHDFSの構成と実行ステータスを効果的に確認する方法をガイドします。次の手順は、HDFSのセットアップと操作を完全に理解するのに役立ちます。 Hadoop環境変数を確認します。最初に、Hadoop環境変数が正しく設定されていることを確認してください。端末では、次のコマンドを実行して、Hadoopが正しくインストールおよび構成されていることを確認します。HDFS構成をチェックするHDFSファイル:HDFSのコア構成ファイルは/etc/hadoop/conf/ディレクトリにあります。使用
 CentosのPytorchのGPUサポートはどのようにサポートされていますか
Apr 14, 2025 pm 06:48 PM
CentosのPytorchのGPUサポートはどのようにサポートされていますか
Apr 14, 2025 pm 06:48 PM
Pytorch GPUアクセラレーションを有効にすることで、CentOSシステムでは、PytorchのCUDA、CUDNN、およびGPUバージョンのインストールが必要です。次の手順では、プロセスをガイドします。CUDAおよびCUDNNのインストールでは、CUDAバージョンの互換性が決定されます。NVIDIA-SMIコマンドを使用して、NVIDIAグラフィックスカードでサポートされているCUDAバージョンを表示します。たとえば、MX450グラフィックカードはCUDA11.1以上をサポートする場合があります。 cudatoolkitのダウンロードとインストール:nvidiacudatoolkitの公式Webサイトにアクセスし、グラフィックカードでサポートされている最高のCUDAバージョンに従って、対応するバージョンをダウンロードしてインストールします。 cudnnライブラリをインストールする:
 Dockerの原則の詳細な説明
Apr 14, 2025 pm 11:57 PM
Dockerの原則の詳細な説明
Apr 14, 2025 pm 11:57 PM
DockerはLinuxカーネル機能を使用して、効率的で孤立したアプリケーションランニング環境を提供します。その作業原則は次のとおりです。1。ミラーは、アプリケーションを実行するために必要なすべてを含む読み取り専用テンプレートとして使用されます。 2。ユニオンファイルシステム(UnionFS)は、違いを保存するだけで、スペースを節約し、高速化する複数のファイルシステムをスタックします。 3.デーモンはミラーとコンテナを管理し、クライアントはそれらをインタラクションに使用します。 4。名前空間とcgroupsは、コンテナの分離とリソースの制限を実装します。 5.複数のネットワークモードは、コンテナの相互接続をサポートします。これらのコア概念を理解することによってのみ、Dockerをよりよく利用できます。
 Centosはmysqlをインストールします
Apr 14, 2025 pm 08:09 PM
Centosはmysqlをインストールします
Apr 14, 2025 pm 08:09 PM
CentOSにMySQLをインストールするには、次の手順が含まれます。適切なMySQL Yumソースの追加。 yumを実行して、mysql-serverコマンドをインストールして、mysqlサーバーをインストールします。ルートユーザーパスワードの設定など、MySQL_SECURE_INSTALLATIONコマンドを使用して、セキュリティ設定を作成します。必要に応じてMySQL構成ファイルをカスタマイズします。 MySQLパラメーターを調整し、パフォーマンスのためにデータベースを最適化します。
 Centos8はsshを再起動します
Apr 14, 2025 pm 09:00 PM
Centos8はsshを再起動します
Apr 14, 2025 pm 09:00 PM
SSHサービスを再起動するコマンドは次のとおりです。SystemCTL再起動SSHD。詳細な手順:1。端子にアクセスし、サーバーに接続します。 2。コマンドを入力します:SystemCtl RestArt SSHD; 3.サービスステータスの確認:SystemCTLステータスSSHD。
 CentosでPytorchの分散トレーニングを操作する方法
Apr 14, 2025 pm 06:36 PM
CentosでPytorchの分散トレーニングを操作する方法
Apr 14, 2025 pm 06:36 PM
Pytorchの分散トレーニングでは、Centosシステムでトレーニングには次の手順が必要です。Pytorchのインストール:PythonとPipがCentosシステムにインストールされていることです。 CUDAバージョンに応じて、Pytorchの公式Webサイトから適切なインストールコマンドを入手してください。 CPUのみのトレーニングには、次のコマンドを使用できます。PipinstalltorchtorchtorchvisionTorchaudioGPUサポートが必要な場合は、CUDAとCUDNNの対応するバージョンがインストールされ、インストールに対応するPytorchバージョンを使用してください。分散環境構成:分散トレーニングには、通常、複数のマシンまたは単一マシンの複数GPUが必要です。場所
