

イタリアがChatGPTを禁止する最初の国となる! OpenAI CEO: 違反はないと思います

つい昨日、イタリア政府は突然 ChatGPT の禁止を命令しました。
OpenAI CEO の Sam Altman 氏はすぐに、同社がローカルの ChatGPT サービスを閉鎖したと返答しました (ただし、いかなる規制にも違反していないと考えていました)。
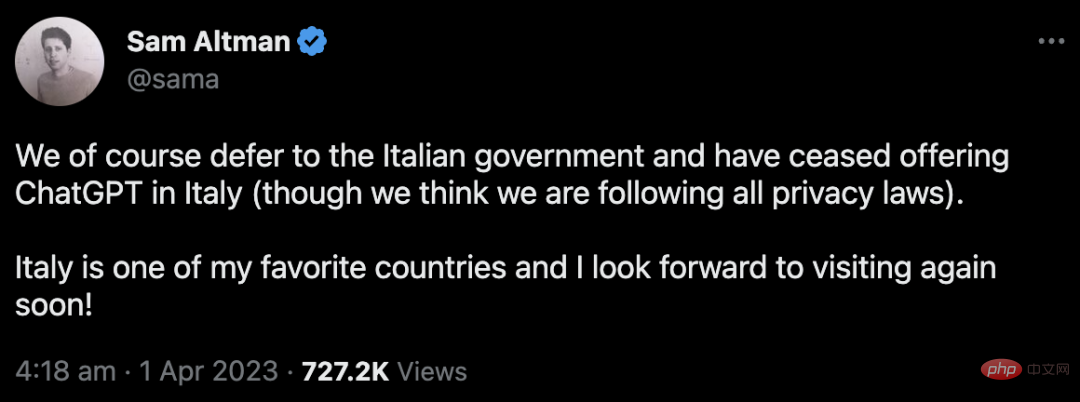
それ以来、イタリアは世界で最初に ChatGPT の禁止を発表した国となりました。
(ChatGPT は、OpenAI が最初からオープンしていないため、他の国や地域では使用できません。)
イタリア、ChatGPT を禁止し、プライバシー問題を徹底的に調査
3 月 31 日、イタリアの国家プライバシー規制当局は正式に ChatGPT の禁止を命令し、OpenAI を「個人データの違法収集」であると非難しました。
この「一時禁止」は、OpenAI が欧州連合の画期的なプライバシー法である一般データ保護規則 (GDPR) を尊重できるようになるまで有効であることは注目に値します。

ファイルアドレス: https://www.garanteprivacy.it/home/docweb/-/docweb-display/docweb/9870847 #english
イタリアの国家データ保護機関 GPDP が発行したプレスリリースによると、ユーザーデータを収集してアルゴリズムの「トレーニング」に使用する OpenAI の行為には法的根拠がありません。
同時に、3 月 20 日のユーザーの会話と支払い情報の漏洩は、OpenAI の個人情報処理の問題点を明らかにしました。
さらに、OpenAI は、ChatGPT は 13 歳以上のユーザーを対象としていると主張していますが、対応する年齢確認メカニズムがないため、未成年者には自分の年齢を超えたコンテンツが表示される可能性があります。自分自身の成長と自己認識のレベルについて。
規制当局は、OpenAI に対して 20 日間の猶予期間を与え、実行可能な是正措置を講じない場合、全世界総額の 4% に相当する最大 2,000 万ユーロの罰金を科すと発表しました。年間売上高です。
これに対し、OpenAI はイタリアのユーザーに対するサービスを終了し、ユーザーのプライバシーを保護することを約束したと述べました。 「ChatGPT のようなシステムをトレーニングする際、私たちは個人データを削減するために懸命に取り組んできました。この AI には個人ではなく世界を理解してもらいたいからです。もちろん、AI の監視も必要であると考えています。」
イタリアにおける ChatGPT の今後の運命は、この 20 日間にかかっているようです。
ただし、イタリアがAIチャットボットに対してこのような措置を講じたのはこれが初めてではない。
2 月、規制当局はチャットボット アプリ Replika.ai を禁止しました。レプリカは一部のユーザーがロボットと親密な関係を築いていたことで「悪名」が高かったが、その後、レプリカはポルノロールプレイングのオプションを削除し、一部のユーザーは自殺ホットラインの助けを必要とした。
AI ツールは制限されるべきですか?
ChatGPT のリリース後、論文やコードを書く能力は眩しいものですが、その誤った情報の拡散、雇用への影響、そして人間社会全体への広範なリスクのすべてが人々を幻惑させています。人々は心配し、警告を発しています。最近、GPT テクノロジーに対する禁止の波が押し寄せています。
チューリング賞受賞者のヨシュア・ベンジオ氏だけでなく、マスク氏、マーカス氏、その他何千人もの偉人たちが公開書簡に署名し、世界中のすべてのAI研究所に対し、より強力なマシンでのトレーニングを中止するよう呼びかけた。 GPT-4AIモデル。
さらに、消費者権利保護団体 BEUC も最近、EU および各国当局に対し ChatGPT を調査するよう呼び掛けました。
さらに、多くの専門家は、AI が国家安全保障、雇用、教育に影響を及ぼす可能性があるため、AI を管理するには新しい規制が必要であるとも述べています。
欧州委員会の広報担当者は、「EUで活動するすべての企業がEUのデータ保護規則を尊重することを願っています。一般データ保護規則の施行はEUデータ保護当局の責任です。」
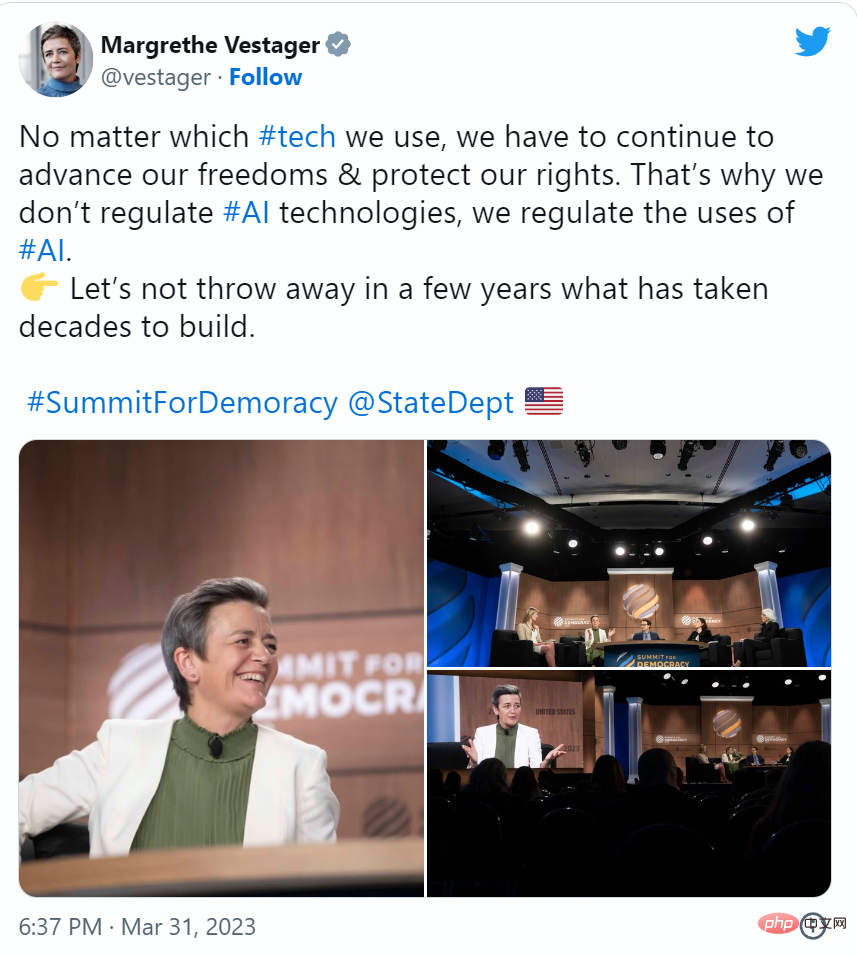
欧州委員会のマルグレーテ・ベステアー副委員長は、EUの人工知能法案を議論している欧州委員会は人工知能を禁止するつもりはないかもしれないとツイッターで述べた。
「どのテクノロジーを使用するとしても、私たちは自分たちの権利を守らなければなりません。これが、私たちが AI テクノロジーを規制するのではなく、AI の使用を規制する理由です。」
米国では、非営利団体 Center for Artificial Intelligence and Digital Policy (CAIDP) も、OpenAI が違反しているかどうかを調査するよう連邦取引委員会 (FTC) に要請しました。消費者保護規則を制定し、それを禁止するさらに GPT-4 をリリースしました。
結局のところ、何千人もの偉い人たちからの共同書簡の前例があることから、CAIDP の訴えはより論理的であるように思えます。さらに、CAIDPのマーク・ローテンバーグ議長は驚くべきことにこの書簡に署名した。

ファイルアドレス: https://cdn.arstechnica.net/wp-content/uploads/2023/03/CAIDP-FTC -Complaint-OpenAI-GPT-033023.pdf
全体として、CAIDP の苦情の内容はその書簡と一致しており、生成 AI モデルの開発の遅延を求めています。 、そしてより厳格な政府の監督を実施します。
しかし、CAIDP はさらに、ChatGPT は「偏見があり、欺瞞的であり、公共の安全に危険をもたらす」と考えています。
OpenAI は AI 生成テキストの潜在的な脅威を公に指摘していますが、CAIDP は GPT-4 は一線をはるかに超えており、消費者を保護するために規制措置を講じるべきであると考えています。
CAIDP は、GPT-4 モデルには、GPT-4 が悪意のあるコードや高度にカスタマイズされたプロパガンダを生成する方法、その偏ったトレーニング データなど、多くの重大な潜在的な脅威があると述べました。採用などの分野で固定観念や不公平な人種的および性別的選好につながります。
CAIDP は、OpenAI の行為が、不公平で欺瞞的な取引慣行を禁止する FTC 法の第 5 条に違反していると考えています。
このうち、AIモデルの幻想もナンセンスも、CAIDPから見ればすべて欺瞞です。 ChatGPTは「虚偽のビジネスステートメントや広告を促進」しており、FTCの管轄に該当する可能性があると警告した。

CAIDPは訴状の中で、FTCに対し、GPTモデルの今後の商用展開をすべて中止し、将来の事前にモデルの見直しを要求するよう求めた。独立した評価を実施します。また、消費者が詐欺行為の苦情を申し立てることができるものと同様の、公的にアクセス可能な報告ツールも求められています。
CAIDP は大手テクノロジー企業が競争を独占しようとしている兆候を探しており、AI 軍拡競争の主要企業の 1 つである OpenAI に対する調査は大きな前進を示していますCAIDPのリナ・カーン委員長は調査の中で、アップグレードしたと述べた。
一部のアナリストは、CAIDP の申し立てによって FTC が短期的に行動を起こすことはないものの、将来的には関連する監督が行われる可能性が高く、GPT-5 のリリースが許可される可能性があると考えています。延期した。
最後に、Googleが懸念していた「風評リスク」がついに到来したとしか言えません。
参考:
https: / /www.php.cn/link/d35a29602005cb55aa57a5f683c8e0c2
以上がイタリアがChatGPTを禁止する最初の国となる! OpenAI CEO: 違反はないと思いますの詳細内容です。詳細については、PHP 中国語 Web サイトの他の関連記事を参照してください。

ホットAIツール

Undresser.AI Undress
リアルなヌード写真を作成する AI 搭載アプリ

AI Clothes Remover
写真から衣服を削除するオンライン AI ツール。

Undress AI Tool
脱衣画像を無料で

Clothoff.io
AI衣類リムーバー

AI Hentai Generator
AIヘンタイを無料で生成します。

人気の記事
ホットツール

メモ帳++7.3.1
使いやすく無料のコードエディター

SublimeText3 中国語版
中国語版、とても使いやすい

ゼンドスタジオ 13.0.1
強力な PHP 統合開発環境

ドリームウィーバー CS6
ビジュアル Web 開発ツール

SublimeText3 Mac版
神レベルのコード編集ソフト(SublimeText3)
ホットトピック
 7480
7480
 15
1377
52
77
11
19
33
15
1377
52
77
11
19
33

 ChatGPT では、無料ユーザーが 1 日あたりの制限付きで DALL-E 3 を使用して画像を生成できるようになりました
Aug 09, 2024 pm 09:37 PM
ChatGPT では、無料ユーザーが 1 日あたりの制限付きで DALL-E 3 を使用して画像を生成できるようになりました
Aug 09, 2024 pm 09:37 PM
DALL-E 3は、前モデルより大幅に改良されたモデルとして2023年9月に正式導入されました。これは、複雑な詳細を含む画像を作成できる、これまでで最高の AI 画像ジェネレーターの 1 つと考えられています。ただし、発売当初は対象外でした
 データに最適なエンベディング モデルの選択: OpenAI とオープンソースの多言語エンベディングの比較テスト
Feb 26, 2024 pm 06:10 PM
データに最適なエンベディング モデルの選択: OpenAI とオープンソースの多言語エンベディングの比較テスト
Feb 26, 2024 pm 06:10 PM
OpenAI は最近、最新世代の埋め込みモデル embeddingv3 のリリースを発表しました。これは、より高い多言語パフォーマンスを備えた最もパフォーマンスの高い埋め込みモデルであると主張しています。このモデルのバッチは、小さい text-embeddings-3-small と、より強力で大きい text-embeddings-3-large の 2 つのタイプに分類されます。これらのモデルがどのように設計され、トレーニングされるかについてはほとんど情報が開示されておらず、モデルには有料 API を介してのみアクセスできます。オープンソースの組み込みモデルは数多くありますが、これらのオープンソース モデルは OpenAI のクローズド ソース モデルとどう違うのでしょうか?この記事では、これらの新しいモデルのパフォーマンスをオープンソース モデルと実証的に比較します。データを作成する予定です
 Spring Boot と OpenAI の出会いによる新しいプログラミング パラダイム
Feb 01, 2024 pm 09:18 PM
Spring Boot と OpenAI の出会いによる新しいプログラミング パラダイム
Feb 01, 2024 pm 09:18 PM
2023年、AI技術が注目を集め、プログラミング分野を中心にさまざまな業界に大きな影響を与えています。 AI テクノロジーの重要性に対する人々の認識はますます高まっており、Spring コミュニティも例外ではありません。 GenAI (汎用人工知能) テクノロジーの継続的な進歩に伴い、AI 機能を備えたアプリケーションの作成を簡素化することが重要かつ緊急になっています。このような背景から、AI 機能アプリケーションの開発プロセスを簡素化し、シンプルかつ直観的にし、不必要な複雑さを回避することを目的とした「SpringAI」が登場しました。 「SpringAI」により、開発者はAI機能を搭載したアプリケーションをより簡単に構築でき、使いやすく、操作しやすくなります。
 携帯電話にchatgptをインストールする方法
Mar 05, 2024 pm 02:31 PM
携帯電話にchatgptをインストールする方法
Mar 05, 2024 pm 02:31 PM
インストール手順: 1. ChatGTP ソフトウェアを ChatGTP 公式 Web サイトまたはモバイル ストアからダウンロードします; 2. それを開いた後、設定インターフェイスで言語を中国語を選択します; 3. ゲーム インターフェイスでヒューマン マシン ゲームを選択し、中国スペクトル; 4 . 起動後、チャット ウィンドウにコマンドを入力してソフトウェアを操作します。
 OpenAI Super Alignment チームの遺作: 2 つの大きなモデルがゲームをプレイし、出力がより理解しやすくなる
Jul 19, 2024 am 01:29 AM
OpenAI Super Alignment チームの遺作: 2 つの大きなモデルがゲームをプレイし、出力がより理解しやすくなる
Jul 19, 2024 am 01:29 AM
AIモデルによって与えられた答えがまったく理解できない場合、あなたはそれをあえて使用しますか?機械学習システムがより重要な分野で使用されるにつれて、なぜその出力を信頼できるのか、またどのような場合に信頼してはいけないのかを実証することがますます重要になっています。複雑なシステムの出力に対する信頼を得る方法の 1 つは、人間または他の信頼できるシステムが読み取れる、つまり、考えられるエラーが発生する可能性がある点まで完全に理解できる、その出力の解釈を生成することをシステムに要求することです。見つかった。たとえば、司法制度に対する信頼を築くために、裁判所に対し、決定を説明し裏付ける明確で読みやすい書面による意見を提供することを求めています。大規模な言語モデルの場合も、同様のアプローチを採用できます。ただし、このアプローチを採用する場合は、言語モデルが
 Rust ベースの Zed エディターはオープンソース化されており、OpenAI と GitHub Copilot のサポートが組み込まれています
Feb 01, 2024 pm 02:51 PM
Rust ベースの Zed エディターはオープンソース化されており、OpenAI と GitHub Copilot のサポートが組み込まれています
Feb 01, 2024 pm 02:51 PM
著者丨コンパイル: TimAnderson丨プロデュース: Noah|51CTO Technology Stack (WeChat ID: blog51cto) Zed エディター プロジェクトはまだプレリリース段階にあり、AGPL、GPL、および Apache ライセンスの下でオープンソース化されています。このエディターは高性能と複数の AI 支援オプションを備えていますが、現在は Mac プラットフォームでのみ利用可能です。 Nathan Sobo 氏は投稿の中で、GitHub 上の Zed プロジェクトのコード ベースでは、エディター部分は GPL に基づいてライセンスされ、サーバー側コンポーネントは AGPL に基づいてライセンスされ、GPUI (GPU Accelerated User) インターフェイス部分はApache2.0ライセンス。 GPUI は Zed チームによって開発された製品です
 OpenAI を待つのではなく、Open-Sora が完全にオープンソースになるのを待ちましょう
Mar 18, 2024 pm 08:40 PM
OpenAI を待つのではなく、Open-Sora が完全にオープンソースになるのを待ちましょう
Mar 18, 2024 pm 08:40 PM
少し前まで、OpenAISora はその驚くべきビデオ生成効果で急速に人気を博し、数ある文学ビデオ モデルの中でも際立って世界的な注目を集めるようになりました。 2 週間前にコストを 46% 削減した Sora トレーニング推論再現プロセスの開始に続き、Colossal-AI チームは世界初の Sora のようなアーキテクチャのビデオ生成モデル「Open-Sora1.0」を完全にオープンソース化し、全体をカバーしました。データ処理、すべてのトレーニングの詳細、モデルの重みを含むトレーニング プロセスを管理し、世界中の AI 愛好家と協力してビデオ作成の新時代を推進します。ちょっと覗いてみましょう。Colossal-AI チームがリリースした「Open-Sora1.0」モデルによって生成された賑やかな街のビデオを見てみましょう。オープンソラ1.0
 Embedding サービスのローカル実行パフォーマンスは OpenAI Text-Embedding-Ada-002 を上回っており、とても便利です。
Apr 15, 2024 am 09:01 AM
Embedding サービスのローカル実行パフォーマンスは OpenAI Text-Embedding-Ada-002 を上回っており、とても便利です。
Apr 15, 2024 am 09:01 AM
Ollama は、Llama2、Mistral、Gemma などのオープンソース モデルをローカルで簡単に実行できるようにする非常に実用的なツールです。この記事では、Ollamaを使ってテキストをベクトル化する方法を紹介します。 Ollama をローカルにインストールしていない場合は、この記事を読んでください。この記事では、nomic-embed-text[2] モデルを使用します。これは、短いコンテキストおよび長いコンテキストのタスクにおいて OpenAI text-embedding-ada-002 および text-embedding-3-small よりも優れたパフォーマンスを発揮するテキスト エンコーダーです。 o が正常にインストールされたら、nomic-embed-text サービスを開始します。
