

上海デジタルブレイン研究所が、超複雑な問題に対する迅速な意思決定を実現できる中国初の大規模マルチモーダル意思決定モデル DB1 をリリース

最近、上海デジタルブレイン研究所(以下、デジタルブレイン研究所)は、初の大規模デジタルブレインマルチモーダル意思決定モデル(DB1)を立ち上げ、国内のこの領域のギャップを明らかにし、テキスト、画像テキスト、強化学習の意思決定、および運用最適化の意思決定における事前トレーニング済みモデルの可能性をさらに検証します。現在、DB1 コードを Github でオープンソース化しています (プロジェクト リンク: https://github.com/Shanghai-Digital-Brain-Laboratory/BDM-DB1)。
以前、数理科学研究所は MADT (https://arxiv.org/abs/2112.02845)/MAT (https://arxiv.org/abs/2205.14953) とその他のマルチインテリジェンス インテリジェンス ボディ モデルでは、いくつかの大規模なオフライン モデルでのシーケンス モデリングを通じて、Transformer モデルを使用していくつかの単一/マルチ エージェント タスクで顕著な結果を達成しており、この方向での研究と探索は継続しています。
ここ数年、事前トレーニングされた大規模モデルの台頭により、学界と産業界は事前トレーニングされたモデルのパラメーター量とマルチモーダル タスクにおいて新たな進歩を続けてきました。大規模な事前トレーニング モデルは、大量のデータと知識の詳細なモデリングを通じて、一般的な人工知能への重要なパスの 1 つであると考えられています。意思決定インテリジェンスの研究に重点を置くデジタル研究所は、事前トレーニング済みモデルの成功を意思決定タスクに模倣するという革新的な試みを行い、ブレークスルーを達成しました。
マルチモーダル意思決定大規模モデル DB1
以前、DeepMind は、単一エージェントの意思決定タスク、複数ラウンドの対話、画像を統合する Gato を立ち上げました。 Transformer の自己回帰問題に基づいて、604 の異なるタスクで良好なパフォーマンスを達成し、いくつかの単純な強化学習意思決定問題がシーケンス予測を通じて解決できることを示しました。これは、数学研究所の研究の方向性を検証しています。大規模な意思決定モデルの方向性。
今回、数研が立ち上げたDB1は主にGatoを再現・検証し、ネットワーク構造とパラメータ量、タスクの種類とタスク数の側面から検証してみました。改善:
-
#パラメータ量とネットワーク構造: DB1 パラメータ量が 12 億 1,000 万に達しました。パラメータに関してはできるだけガトーに近づけるようにしてください。全体として、数値研究所は Gato と同様の構造 (デコーダー ブロックの数、隠れ層のサイズなどは同じ) を使用していますが、FeedForwardNetwork では、GeGLU アクティベーション関数により追加のパラメーター数が 1/3 追加されるため、パラメータ量は Gato に近く、GeGLU アクティベーション関数によって 4 * n_embed 次元の隠れ層状態が 2 * n_embed 次元の特徴に変換されます。それ以外の場合は、入力および出力エンコード側の埋め込みパラメーターを Gato の実装と共有します。 Gato とは異なり、レイヤー正規化の選択に PostNorm ソリューションを採用し、数値安定性を向上させるために Attend では混合精度計算を使用します。
- タスクの種類とタスクの数: DB1 の実験的タスクの数は 870 に達し、これは Gato より 44.04% 多く、50 以上です。 Gato より % 高く、エキスパートのパフォーマンスが 2.23% 向上しています。特定のタスクの種類に関しては、DB1 は Gato の意思決定タスク、画像タスク、およびテキスト タスクを主に継承しており、さまざまなタスクの数は基本的に変わりません。しかし、意思決定タスクに関しては、DB1 は 200 を超える実際のシナリオ タスク、つまり 100 および 200 ノード規模の巡回セールスマン問題 (TSP) も導入しています。このタイプのタスクでは、100 ~ 200 の地理的位置がランダムに選択されます。中国のすべての主要都市にノードを設置。代表) ソリューション。
DB1 の全体的なパフォーマンスは Gato と同等のレベルに達しており、より実際のビジネスに近い需要フィールド本体に向けて進化し始めていることがわかります。 NP ハード TSP 問題は、Gato によってこれまでこの方向で検討されていませんでした。
 #DB1 (右) インジケーターと GATO (左) インジケーターの比較
#DB1 (右) インジケーターと GATO (左) インジケーターの比較
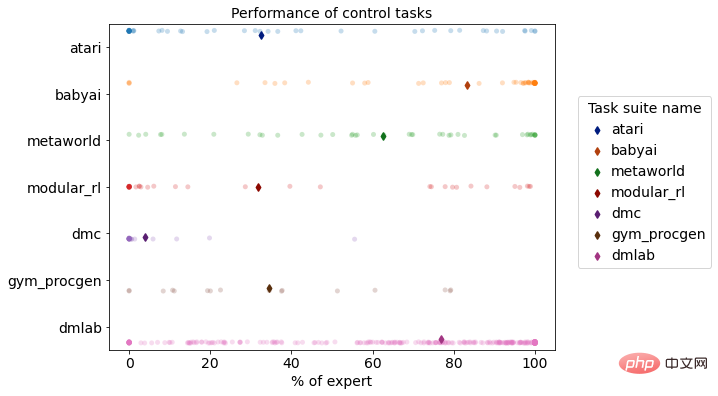
強化学習シミュレーション環境における DB1 のマルチタスクのパフォーマンス分布
従来の意思決定アルゴリズムと比較して、DB1 はクロスタスク意思決定機能と高速移行機能において優れたパフォーマンスを発揮します。タスク間の意思決定能力とパラメータ量の点で、単一の複雑なタスクの数千万のパラメータから、複数の複雑なタスクの数十億のパラメータへの飛躍を達成し、成長を続けており、問題を解決する能力を備えています。複雑なビジネス環境における問題を解決し、実際的な問題を解決する適切な能力。移行機能の点で、DB1 はインテリジェントな予測からインテリジェントな意思決定へ、そしてシングル エージェントからマルチ エージェントへの飛躍を完了し、タスク間移行における従来の方法の欠点を補い、大規模なモデルの構築を可能にしました。企業内で。
DB1 も、開発プロセスで多くの困難に直面したことは否定できません。デジタル研究所は、大規模なモデルのトレーニングと複数のモデルを業界に提供するために多くの試みを行ってきました。タスク トレーニング データ ストレージ。いくつかの標準的なソリューション パスを提供します。モデルパラメータが10億パラメータに達し、タスクの規模が巨大になり、100T(300Bトークン)を超えるエキスパートデータでトレーニングする必要があるため、通常の深層強化学習トレーニングフレームワークでは、高速トレーニングの要件を満たすことができなくなりました。この状況。このため、一方で、数理研では、分散学習において、強化学習、演算最適化、大規模モデル学習などの計算構造を十分に考慮しています。 、ハードウェア リソースを最大限に活用し、モジュールを巧みに設計し、2 つのモデル間の通信メカニズムにより、モデルのトレーニング効率を最大化し、870 タスクのトレーニング時間を 1 週間に短縮します。一方、分散ランダムサンプリングでは、学習プロセスに必要なデータのインデックス作成、保存、読み込み、前処理もボトルネックとなっており、数研研究所はデータセットを読み込む際に遅延読み込みモードを採用して問題を解決しました。メモリ制限を軽減し、利用可能なメモリを最大限に活用します。さらに、ロードされたデータを前処理した後、処理されたデータがハードディスクにキャッシュされるため、後で前処理されたデータを直接ロードできるため、前処理の繰り返しによる時間とリソースのコストが削減されます。
現在、OpenAI、Google、Meta、Huawei、Baidu、DAMO Academy などの国内外の大手企業や研究機関がマルチモーダル大規模モデルの研究を行っており、自社製品への適用やモデル API や関連業界ソリューションの提供など、商業化の試み。対照的に、数理科学研究所は意思決定の問題により重点を置き、ゲーム AI 意思決定タスク、オペレーションズ リサーチ最適化 TSP 解決タスク、ロボット意思決定制御タスク、ブラックボックス最適化解決タスク、およびマルチラウンドダイアログタスク。
タスク パフォーマンス
オペレーション リサーチの最適化: TSP 問題解決
中国語による都市をノードとした部分 TSP 問題
強化学習タスクのビデオデモ
DB1 モデルの完成 870 後さまざまな意思決定タスクをオフラインで学習した結果、タスクの 76.67% が専門家レベルの 50% 以上に達したことが評価結果でわかりました。以下は、いくつかのタスクの効果を示しています。
- 電子ゲーム シナリオ: DB1 は 2D/3D 画像入力を受信でき、Atari や Procgen などの 2D ピクセル ゲームを十分に完成させることができます。 DMLab. DB1 は、現実世界と同様の 3D 画像入力タスクでも優れたパフォーマンスを示しました。

アタリブレイクアウト

##DMLab オブジェクトの場所の探索

連続制御シナリオ: ロボット工学分野の連続制御タスクでは、DB1 は連続アクションのポリシー出力をモデル化し、シミュレーションで適切に完了することもできます。タスク。
#Metaworld PlateSlide

テキスト-画像タスク
テキスト生成: テキスト プロンプトを表示し、長いテキストの説明を生成します
- 入力プロンプト:digital Brain Laboratoryは上海に本拠を置く
- 生成結果:Digital Brain Laboratoryは上海に本拠を置く会社であり、高度な人材を探しています。中国、上海の当社チームに加わっていただける、熟練した経験豊富な人材です。
-
当社はデジタル ブレイン ラボであり、中国、上海の当社チームに加わっていただける、熟練した経験豊富な人材を探しています。
これは、急速な成長段階を迎えている有名な成長企業で働き、市場に影響を与えるチャンスです。
これは全文です。
#私たちは、競争の激しい環境で 5 ~ 10 人のチームを率いることができる、高度なスキルと意欲、経験豊富なソフトウェア エンジニアを探しています
画像説明の生成: 画像を指定して、対応するテキスト説明を生成します

以上が上海デジタルブレイン研究所が、超複雑な問題に対する迅速な意思決定を実現できる中国初の大規模マルチモーダル意思決定モデル DB1 をリリースの詳細内容です。詳細については、PHP 中国語 Web サイトの他の関連記事を参照してください。

ホットAIツール

Undresser.AI Undress
リアルなヌード写真を作成する AI 搭載アプリ

AI Clothes Remover
写真から衣服を削除するオンライン AI ツール。

Undress AI Tool
脱衣画像を無料で

Clothoff.io
AI衣類リムーバー

AI Hentai Generator
AIヘンタイを無料で生成します。

人気の記事
ホットツール

メモ帳++7.3.1
使いやすく無料のコードエディター

SublimeText3 中国語版
中国語版、とても使いやすい

ゼンドスタジオ 13.0.1
強力な PHP 統合開発環境

ドリームウィーバー CS6
ビジュアル Web 開発ツール

SublimeText3 Mac版
神レベルのコード編集ソフト(SublimeText3)
ホットトピック
 7503
7503
 15
1377
52
78
11
19
54
15
1377
52
78
11
19
54

 Bytedance Cutting が SVIP スーパー メンバーシップを開始: 継続的な年間サブスクリプションは 499 元で、さまざまな AI 機能を提供
Jun 28, 2024 am 03:51 AM
Bytedance Cutting が SVIP スーパー メンバーシップを開始: 継続的な年間サブスクリプションは 499 元で、さまざまな AI 機能を提供
Jun 28, 2024 am 03:51 AM
このサイトは6月27日、JianyingはByteDanceの子会社であるFaceMeng Technologyによって開発されたビデオ編集ソフトウェアであり、Douyinプラットフォームに依存しており、基本的にプラットフォームのユーザー向けに短いビデオコンテンツを作成すると報告しました。 Windows、MacOS、その他のオペレーティング システム。 Jianyingは会員システムのアップグレードを正式に発表し、インテリジェント翻訳、インテリジェントハイライト、インテリジェントパッケージング、デジタルヒューマン合成などのさまざまなAIブラックテクノロジーを含む新しいSVIPを開始しました。価格的には、クリッピングSVIPの月額料金は79元、年会費は599元(当サイト注:月額49.9元に相当)、継続月額サブスクリプションは月額59元、継続年間サブスクリプションは、年間499元(月額41.6元に相当)です。さらに、カット担当者は、ユーザーエクスペリエンスを向上させるために、オリジナルのVIPに登録している人は、
 Rag と Sem-Rag を使用したコンテキスト拡張 AI コーディング アシスタント
Jun 10, 2024 am 11:08 AM
Rag と Sem-Rag を使用したコンテキスト拡張 AI コーディング アシスタント
Jun 10, 2024 am 11:08 AM
検索強化生成およびセマンティック メモリを AI コーディング アシスタントに組み込むことで、開発者の生産性、効率、精度を向上させます。 JanakiramMSV 著者の EnhancingAICodingAssistantswithContextUsingRAGandSEM-RAG から翻訳。基本的な AI プログラミング アシスタントは当然役に立ちますが、ソフトウェア言語とソフトウェア作成の最も一般的なパターンに関する一般的な理解に依存しているため、最も適切で正しいコードの提案を提供できないことがよくあります。これらのコーディング アシスタントによって生成されたコードは、彼らが解決する責任を負っている問題の解決には適していますが、多くの場合、個々のチームのコーディング標準、規約、スタイルには準拠していません。これにより、コードがアプリケーションに受け入れられるように修正または調整する必要がある提案が得られることがよくあります。
 微調整によって本当に LLM が新しいことを学習できるようになるのでしょうか: 新しい知識を導入すると、モデルがより多くの幻覚を生成する可能性があります
Jun 11, 2024 pm 03:57 PM
微調整によって本当に LLM が新しいことを学習できるようになるのでしょうか: 新しい知識を導入すると、モデルがより多くの幻覚を生成する可能性があります
Jun 11, 2024 pm 03:57 PM
大規模言語モデル (LLM) は巨大なテキスト データベースでトレーニングされ、そこで大量の現実世界の知識を取得します。この知識はパラメータに組み込まれており、必要なときに使用できます。これらのモデルの知識は、トレーニングの終了時に「具体化」されます。事前トレーニングの終了時に、モデルは実際に学習を停止します。モデルを調整または微調整して、この知識を活用し、ユーザーの質問により自然に応答する方法を学びます。ただし、モデルの知識だけでは不十分な場合があり、モデルは RAG を通じて外部コンテンツにアクセスできますが、微調整を通じてモデルを新しいドメインに適応させることが有益であると考えられます。この微調整は、ヒューマン アノテーターまたは他の LLM 作成物からの入力を使用して実行され、モデルは追加の実世界の知識に遭遇し、それを統合します。
 OpenAI データは必要ありません。大規模なコード モデルのリストに加わりましょう。 UIUC が StarCoder-15B-Instruct をリリース
Jun 13, 2024 pm 01:59 PM
OpenAI データは必要ありません。大規模なコード モデルのリストに加わりましょう。 UIUC が StarCoder-15B-Instruct をリリース
Jun 13, 2024 pm 01:59 PM
ソフトウェア テクノロジの最前線に立つ UIUC Zhang Lingming のグループは、BigCode 組織の研究者とともに、最近 StarCoder2-15B-Instruct 大規模コード モデルを発表しました。この革新的な成果により、コード生成タスクにおいて大きな進歩が達成され、CodeLlama-70B-Instruct を上回り、コード生成パフォーマンス リストのトップに到達しました。 StarCoder2-15B-Instruct のユニークな特徴は、その純粋な自己調整戦略であり、トレーニング プロセス全体がオープンで透過的で、完全に自律的で制御可能です。このモデルは、高価な手動アノテーションに頼ることなく、StarCoder-15B 基本モデルの微調整に応じて、StarCoder2-15B を介して数千の命令を生成します。
 新しい科学的で複雑な質問応答ベンチマークと大規模モデルの評価システムを提供するために、UNSW、アルゴンヌ、シカゴ大学、およびその他の機関が共同で SciQAG フレームワークを立ち上げました。
Jul 25, 2024 am 06:42 AM
新しい科学的で複雑な質問応答ベンチマークと大規模モデルの評価システムを提供するために、UNSW、アルゴンヌ、シカゴ大学、およびその他の機関が共同で SciQAG フレームワークを立ち上げました。
Jul 25, 2024 am 06:42 AM
編集者 |ScienceAI 質問応答 (QA) データセットは、自然言語処理 (NLP) 研究を促進する上で重要な役割を果たします。高品質の QA データ セットは、モデルの微調整に使用できるだけでなく、大規模言語モデル (LLM) の機能、特に科学的知識を理解し推論する能力を効果的に評価することもできます。現在、医学、化学、生物学、その他の分野をカバーする多くの科学 QA データ セットがありますが、これらのデータ セットにはまだいくつかの欠点があります。まず、データ形式は比較的単純で、そのほとんどが多肢選択式の質問であり、評価は簡単ですが、モデルの回答選択範囲が制限され、科学的な質問に回答するモデルの能力を完全にテストすることはできません。対照的に、自由回答型の Q&A
 Yolov10: 詳細な説明、展開、アプリケーションがすべて 1 か所にまとめられています。
Jun 07, 2024 pm 12:05 PM
Yolov10: 詳細な説明、展開、アプリケーションがすべて 1 か所にまとめられています。
Jun 07, 2024 pm 12:05 PM
1. はじめに ここ数年、YOLO は、計算コストと検出パフォーマンスの効果的なバランスにより、リアルタイム物体検出の分野で主流のパラダイムとなっています。研究者たちは、YOLO のアーキテクチャ設計、最適化目標、データ拡張戦略などを調査し、大きな進歩を遂げました。同時に、後処理に非最大抑制 (NMS) に依存すると、YOLO のエンドツーエンドの展開が妨げられ、推論レイテンシに悪影響を及ぼします。 YOLO では、さまざまなコンポーネントの設計に包括的かつ徹底的な検査が欠けており、その結果、大幅な計算冗長性が生じ、モデルの機能が制限されます。効率は最適ではありませんが、パフォーマンス向上の可能性は比較的大きくなります。この作業の目標は、後処理とモデル アーキテクチャの両方から YOLO のパフォーマンス効率の境界をさらに改善することです。この目的を達成するために
 SOTA パフォーマンス、厦門マルチモーダルタンパク質-リガンド親和性予測 AI 手法、初めて分子表面情報を結合
Jul 17, 2024 pm 06:37 PM
SOTA パフォーマンス、厦門マルチモーダルタンパク質-リガンド親和性予測 AI 手法、初めて分子表面情報を結合
Jul 17, 2024 pm 06:37 PM
編集者 | KX 医薬品の研究開発の分野では、タンパク質とリガンドの結合親和性を正確かつ効果的に予測することが、医薬品のスクリーニングと最適化にとって重要です。しかし、現在の研究では、タンパク質とリガンドの相互作用における分子表面情報の重要な役割が考慮されていません。これに基づいて、アモイ大学の研究者らは、初めてタンパク質の表面、3D 構造、配列に関する情報を組み合わせ、クロスアテンション メカニズムを使用して異なるモダリティの特徴を比較する、新しいマルチモーダル特徴抽出 (MFE) フレームワークを提案しました。アライメント。実験結果は、この方法がタンパク質-リガンド結合親和性の予測において最先端の性能を達成することを実証しています。さらに、アブレーション研究は、この枠組み内でのタンパク質表面情報と多峰性特徴の位置合わせの有効性と必要性を実証しています。 「S」で始まる関連研究
 AIなどの市場を開拓するグローバルファウンドリーズがタゴール・テクノロジーの窒化ガリウム技術と関連チームを買収
Jul 15, 2024 pm 12:21 PM
AIなどの市場を開拓するグローバルファウンドリーズがタゴール・テクノロジーの窒化ガリウム技術と関連チームを買収
Jul 15, 2024 pm 12:21 PM
7月5日のこのウェブサイトのニュースによると、グローバルファウンドリーズは今年7月1日にプレスリリースを発行し、自動車とインターネットでの市場シェア拡大を目指してタゴール・テクノロジーのパワー窒化ガリウム(GaN)技術と知的財産ポートフォリオを買収したことを発表した。モノと人工知能データセンターのアプリケーション分野で、より高い効率とより優れたパフォーマンスを探求します。生成 AI などのテクノロジーがデジタル世界で発展を続ける中、窒化ガリウム (GaN) は、特にデータセンターにおいて、持続可能で効率的な電力管理のための重要なソリューションとなっています。このウェブサイトは、この買収中にタゴール・テクノロジーのエンジニアリングチームがGLOBALFOUNDRIESに加わり、窒化ガリウム技術をさらに開発するという公式発表を引用した。 G
