

実際の調査の過程で、実践者は自分のアプリケーションに適した AI モデルを見つけるのに苦労するかもしれません。LLM を選択するべきですか、それともモデルを微調整するべきですか? LLM を使用する場合、どれを選択すればよいですか?
最近、Amazon、テキサス A&M 大学、ライス大学、その他の機関の学者が ChatGPT などの言語モデルの開発プロセスについて議論しており、彼らの論文は Yann LeCun 氏からも賞賛されました。 。
論文: https://arxiv.org/abs/2304.13712
##関連リソース: https://github.com/Mooler0410/LLMsPracticalGuide

1 はじめに
このホワイトペーパーでは、下流の NLP タスクにおける LLM の実践的な応用のさまざまな側面に焦点を当て、実務者とエンドユーザーにガイダンスを提供します。このガイドの目的は、特定のタスクに LLM を使用するかどうか、および最適な LLM を選択する方法について、実践的で役立つアドバイスを読者に提供することです。これには、モデルのサイズ、計算要件、および計算要件などの多くの要素が考慮されます。特定のドメイン、事前トレーニング済みモデルの有無など。また、この記事では、実用的なアプリケーションの観点から LLM を紹介および説明します。これは、実践者やエンドユーザーが LLM の力をうまく活用して独自の NLP タスクを解決するのに役立ちます。
この記事の構成は次のとおりです。 この記事では、まず LLM について簡単に紹介し、最も重要な GPT スタイルと BERT スタイルのアーキテクチャについて説明します。次に、事前トレーニング データ、トレーニング データ/チューニング データ、テスト データなど、データの観点からモデルのパフォーマンスに影響を与える主な要素を詳しく紹介します。最後の最も重要な部分では、この記事ではさまざまな特定の NLP タスクを詳しく掘り下げ、LLM が知識集約型タスク、従来の NLU タスク、および生成タスクに適しているかどうかを紹介し、さらに、新しい機能と課題についても説明します。これらのモデルは、現実世界のアプリケーション シナリオを獲得し続けています。実際の LLM の有用性と制限を強調するために、詳細な例を提供します。
大規模な言語モデルの機能を分析するために、この記事ではそれらを微調整されたモデルと比較します。 LLM と微調整モデルの定義に関して広く受け入れられている標準はまだありません。実用的かつ効果的に区別するために、この記事での定義は次のとおりです: LLM は、大規模なデータセットで事前トレーニングされた大規模な言語モデルを指し、特定のタスクに合わせてデータを調整しません。モデルは通常より小さく、事前トレーニングされています。後で、このタスクでのパフォーマンスを最適化するために、より小さなタスク固有のデータセットに対してさらに微調整が行われます。
この記事では、LLM を次の用途で使用するための実践的なガイドラインを要約します。
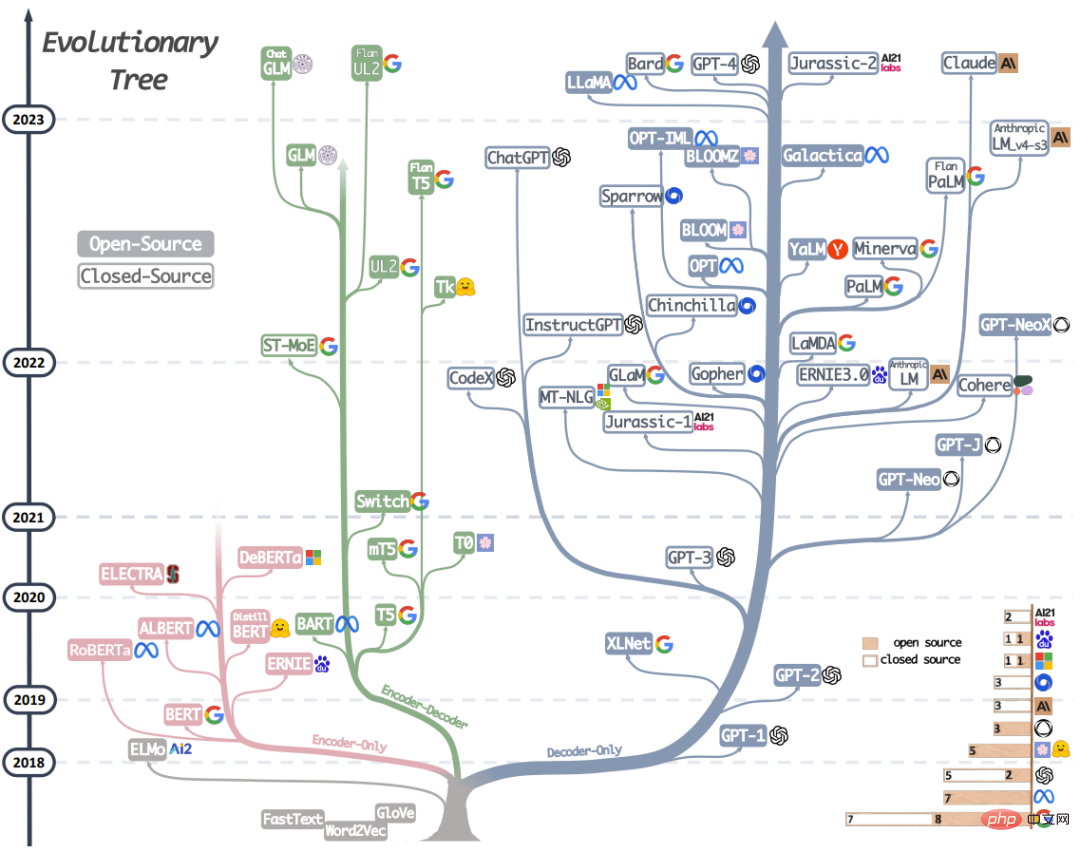
##図 1 : これ最新の LLM の進化ツリーでは、近年の言語モデルの開発を追跡し、最もよく知られているモデルのいくつかに焦点を当てています。同じブランチ上のモデルはより密接に関連しています。トランスベースのモデルは灰色で表されていません。デコーダのみのモデルは青色のブランチ、エンコーダのみのモデルはピンクのブランチ、エンコーダ/デコーダ モデルは緑色のブランチです。タイムライン上のモデルの垂直位置は、そのモデルがいつリリースされたかを示します。黒の四角はオープンソース モデルを表し、空の四角はクローズド ソース モデルを表します。右下隅の積み上げ棒グラフは、各企業および機関のモデルの数を示しています。
#このセクションでは、現在最もパフォーマンスの高い LLM を簡単に紹介します。これらのモデルには、さまざまなトレーニング戦略、モデル アーキテクチャ、およびユースケースがあります。 LLM の全体像をより明確に理解するために、LLM をエンコーダ-デコーダまたはエンコーダのみの言語モデルとデコーダのみの言語モデルという 2 つの大きなカテゴリに分類できます。図 1 は、言語モデルの進化を詳細に示しています。この進化ツリーに基づいて、いくつかの興味深い結論を観察できます。a) デコーダのみのモデルが、LLM 開発において徐々に主流のモデルになりつつあります。 LLM の開発の初期段階では、デコーダのみのモデルは、エンコーダのみのモデルやエンコーダ/デコーダのモデルほど人気がありませんでした。しかし、2021 年以降、GPT-3 の登場により業界の状況が一変し、デコーダー モデルのみが爆発的な発展を遂げました。同時に、BERT はエンコーダ専用モデルにも初期の爆発的な成長をもたらしましたが、その後、エンコーダ専用モデルは徐々に影を潜めていきました。
b) OpenAI は、現在も、おそらく将来も、LLM の方向において主導的な地位を維持し続けます。他の企業や機関は、GPT-3 や GPT-4 に匹敵するモデルを開発するために追い上げを図っています。 OpenAI が主導的な立場にあるのは、たとえそのテクノロジーが初期には広く認識されていなかったとしても、テクノロジーへの継続的な投資によるものと考えられます。
c) Meta は、オープンソース LLM と LLM 研究の促進に多大な貢献をしてきました。 Meta は、開発したすべての LLM をオープンソース化しているため、特に LLM に関連するオープンソース コミュニティへの貢献に関しては、最も寛大な営利企業の 1 つとして際立っています。
d) LLM にはクローズド ソース開発の傾向があります。 LLM 開発の初期段階 (2020 年以前) では、モデルの大部分がオープンソースでした。しかし、GPT-3 の発売により、企業は PaLM、LaMDA、GPT-4 などのモデルをクローズ ソースにすることを選択することが増えています。したがって、学術研究者がLLMトレーニング実験を実施することはますます困難になっています。この結果、API ベースの研究が学術界で主流のアプローチになる可能性があります。
e) エンコーダー/デコーダー モデルにはまだ開発の可能性があります。これは、企業や機関がこのタイプのアーキテクチャを依然として積極的に検討しており、ほとんどのモデルがオープンソースであるためです。 Google は、オープンソースのエンコーダ/デコーダに多大な貢献をしてきました。しかし、デコーダのみのモデルの柔軟性と多用途性により、この方向に固執することで Google が成功する可能性は低くなるように思われます。
#表 1 は、さまざまな代表的な LLM の特徴を簡単にまとめたものです。
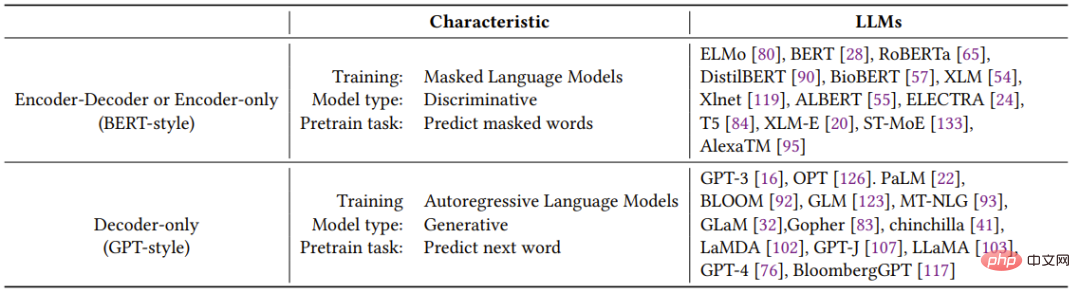
2.1 BERT スタイルの言語モデル: エンコーダー - デコーダー、またはエンコーダーのみ
自然言語の教師なし学習の開発は、自然言語データが簡単に入手でき、教師なしトレーニング パラダイムを使用して非常に大規模なデータ セットを有効に活用できるため、近年大きく進歩しました。一般的なアプローチは、文脈に基づいて文内の遮蔽された単語を予測することです。このトレーニング パラダイムは、マスクされた言語モデルと呼ばれます。このトレーニング方法により、モデルは単語とそのコンテキストの関係をより深く理解できるようになります。これらのモデルは、Transformer アーキテクチャなどの手法を使用して大規模なテキスト コーパスでトレーニングされ、感情分析や固有表現認識などの多くの NLP タスクで最先端のパフォーマンスを達成しています。有名なマスク言語モデルには、BERT、RoBERTa、T5 などがあります。マスクされた言語モデルは、さまざまなタスクで優れたパフォーマンスを発揮するため、自然言語処理の分野で重要なツールとなっています。 2.2 GPT スタイルの言語モデル: デコーダのみ 言語モデルのアーキテクチャは一般にタスクに依存しませんが、 , ただし、これらの方法では、特定の下流タスクのデータセットに基づいて微調整する必要があります。研究者らは、言語モデルのサイズを増やすと、少数のサンプルまたはゼロのサンプルでもパフォーマンスを大幅に向上できることを発見しました。少数またはゼロのサンプルでパフォーマンスを向上させることに最も成功したモデルは、特定のシーケンス内の前の単語に基づいて次の単語を生成するようにトレーニングされた自己回帰言語モデルです。これらのモデルは、テキスト生成や質問応答などの下流タスクで広く使用されています。自己回帰言語モデルには、GPT-3、OPT、PaLM、BLOOM が含まれます。革新的な GPT-3 は、ヒントとコンテキストを介した学習により、少数またはゼロのサンプルでも妥当な結果が得られることを初めて示し、自己回帰言語モデルの優位性を実証しました。 コード生成用の CodeX や金融分野用の BloombergGPT など、特定のタスクに最適化されたモデルもあります。最近の大きな進歩は、ChatGPT です。ChatGPT は、会話タスク用に最適化された GPT-3 のモデルで、現実世界のさまざまなアプリケーションに対して、よりインタラクティブで一貫性のあるコンテキストに応じた会話を生成します。 このセクションでは、下流タスクに適切なモデルを選択する際のデータの重要な役割について説明します。モデルの有効性に対するデータの影響は、事前トレーニング段階で始まり、トレーニング段階と推論段階まで続きます。 キー ポイント 1 (1) ダウンストリーム タスクがディストリビューション外のデータを使用する場合 (敵対的サンプルの使用やデータ ドメインの変更など)今回は、LLM の汎化能力が微調整モデルの汎化能力よりも優れています。 (2) ラベル付きデータが限られている場合は、LLM が微調整モデルよりも優れていますが、ラベル付きデータが豊富な場合は、特定のタスクのニーズに応じて、どちらも合理的な選択となります。 。 (3) 事前トレーニングに使用されるデータ ドメインがダウンストリーム タスクのデータ ドメインと類似しているモデルを選択することをお勧めします。 このセクションでは、LLM がさまざまなダウンストリーム NLP タスクに役立つかどうか、および対応するモデルの機能について詳しく説明します。図 2 は、すべての議論を要約した意思決定フロー図です。特定のタスクに直面したとき、このプロセスに基づいて迅速な決定を下すことができます。 3 データの実践ガイド
4 NLP タスクの実践ガイド
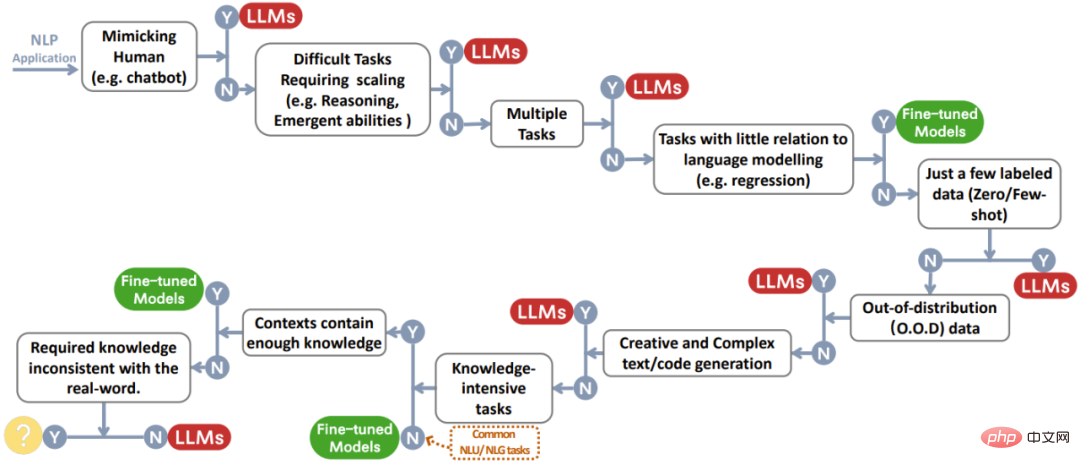
# 図 2: LLM を選択するとき、またはモデルを微調整するときのユーザーの意思決定プロセスNLP アプリケーションの場合。この決定フローチャートは、ユーザーが現在の下流の NLP タスクが特定の基準を満たしているかどうかを評価し、評価結果に基づいて LLM または微調整モデルがアプリケーションに最適であるかどうかを判断するのに役立ちます。図中の意思決定プロセスにおいて、Yは条件を満たすことを示し、Nは条件を満たさないことを示します。最後の条件の Y の隣にある黄色の丸は、現在、このタイプのアプリケーションに適したモデルがないことを示しています。
4.1 従来の NLU タスク
従来の NLU タスクこれは、テキスト分類、固有表現認識 (NER)、含意予測などを含む、NLP 分野の基本的なタスクです。これらのタスクの多くは、ナレッジ グラフの構築に NER を使用するなど、大規模な AI システムの中間ステップとして使用できます。
LLM には適用されません: GLUE や SuperGLUE のタスクなど、ほとんどの自然言語理解タスクでは、タスクに十分に注釈が付けられたデータがすでに豊富で、配布外のテスト セットにデータがほとんどない場合、その場合、微調整されたモデルのパフォーマンスはさらに優れています。タスクやデータセットが異なると、小規模な微調整モデルと LLM の間のギャップも異なります。
LLM に適している: ただし、LLM で処理するのに適した NLU タスクがいくつかあります。 2 つの代表的なタスクは、複雑なテキスト分類問題と敵対的自然言語推論です。
キーポイント 2
従来の自然言語理解タスクの場合、通常、モデルの微調整は LLM よりも優れた選択肢ですが、タスクが強力な一般化機能が必要な場合、LLM が役に立ちます。
4.2 生成タスク
自然言語生成の目標は、一貫性があり、意味があり、文脈に応じたシンボル シーケンスを作成することです。これには、大まかに 2 つのタスク カテゴリが含まれます。最初のカテゴリのタスクは、入力テキストを新しい記号シーケンスに変換することに重点を置いており、例には段落要約や機械翻訳などがあります。タスクの 2 番目のカテゴリは「オープン生成」です。ここでの目標は、電子メールの作成、新しい記事の作成、架空のストーリーの作成、コードの作成など、入力された説明と正確に一致するようにテキストや記号を最初から生成することです。
LLM に適用可能: 生成タスクでは、モデルが入力コンテンツまたは要件を完全に理解する必要があり、また、ある程度の創造性も必要です。これがLLMが優れている点です。
該当なし LLM: リソースが豊富なほとんどの翻訳タスクとリソースが少ない翻訳タスクでは、DeltaLM Zcode など、微調整されたモデルのパフォーマンスが向上します。豊富なリソースを使用した機械翻訳の場合、微調整されたモデルは LLM よりわずかに優れたパフォーマンスを発揮します。英語からカザフ語への翻訳など、リソースが非常に少ない機械翻訳の場合、微調整されたモデルは LLM を大幅に上回りました。
キーポイント 3
LLM は、その強力な生成能力と創造性のおかげで、ほとんどの生成タスクで利点を発揮します。
#4.3 知識集約型タスク
##知識集約型の NLP タスクは、背景知識と専門知識に大きく依存するタスクです。特定の分野 知識または一般的な現実世界の知識のタスク カテゴリ。これらのタスクには、パターン認識や構文分析以上のものが必要です。彼らは記憶と、現実世界の特定の実体、出来事、常識に関連する知識の適切な使用に大きく依存しています。LLM に適している: 一般に、トレーニング トークンとパラメーターが数十億ある場合、LLM に含まれる現実世界の知識の量は、微調整されたモデルの知識の量をはるかに超える可能性があります。
LLM には適用されません: 他の一部のタスクでは、LLM で学習するものとは異なる知識が必要です。必要な知識は、LLM が現実世界について学習するものではありません。このようなタスクでは、LLM には明確な利点はありません。
キーポイント 4
(1) 現実世界の膨大な知識のおかげで、LLM は知識集約的なタスクの処理に優れています。 (2) 知識要件が学習した知識と一致しない場合、LLM は困難に直面します。または、タスクに文脈上の知識のみが必要な場合、微調整モデルは LLM と同じパフォーマンスを達成できます。
4.4 規模の拡張機能
LLM の規模の拡張 (パラメータ、トレーニング計算、など) 言語モデルの事前トレーニングに非常に役立ちます。モデルのサイズを大きくすると、多くの場合、複数のタスクを処理するモデルの能力が向上します。特定の指標に反映されると、モデルのパフォーマンスはモデル サイズとべき乗則の関係を示します。たとえば、言語モデリングのパフォーマンスを測定するために使用されるクロスエントロピー損失は、モデル サイズの指数関数的な増加に伴って直線的に減少します。これは「スケーリング則」としても知られています。推論などの一部の主要な機能については、モデルをスケールアップすることで、これらの機能を非常に低いレベルから使用可能なレベル、さらには人間のレベルに近いレベルまで徐々に向上させることができます。このサブセクションでは、LLM の機能と動作に対するスケールの影響という観点から、LLM の使用方法を紹介します。LLM の推論における使用例: 推論には、情報の理解、推論、意思決定が含まれ、人間の知性の中核となる能力です。 NLP にとって、推論は非常に困難です。既存の推論タスクの多くは、常識推論と算術推論の 2 つのカテゴリに分類できます。モデルを拡大すると、LLM の算術推論能力が大幅に向上します。常識的な推論では、LLM は事実の知識を記憶するだけでなく、事実についていくつかの推論ステップを実行する必要があります。常識的な推論能力は、モデルのサイズが大きくなるにつれて徐々に向上します。微調整されたモデルと比較して、LLM はほとんどのデータセットで優れたパフォーマンスを発揮します。 創発機能における LLM の使用例: モデルのサイズを大きくすると、べき乗則ルールを超えた前例のない素晴らしい機能をモデルに与えることもできます。これらの能力を「創発能力」と呼びます。論文「大規模言語モデルの創発能力」で定義されているように: LLM の創発能力とは、小規模モデルには存在しないが、大規模モデルには現れる能力を指します。 (この論文のさらなる解釈については、「ジェフ・ディーンらの新しい研究: 言語モデルを別の角度から見ると、スケールが十分に大きくないと発見できない」を参照してください) これは、推論や予測ができないことを意味します。この機能は小規模モデルのパフォーマンス向上に基づいており、タスクによっては、モデルのサイズが一定のレベルを超えると、突然優れたパフォーマンスを達成する場合があります。緊急機能は多くの場合、予測不可能で予期しないものであるため、ランダムに発生するタスクや予期しないタスクを処理するモデルの機能が低下する可能性があります。 該当なし LLM と創発の理解: ほとんどの場合、モデルはより大きく、パフォーマンスも向上しますが、例外もあります。 一部のタスクでは、LLM の規模が増加するにつれて、モデルのパフォーマンスが低下し始めます。これは、逆スケーリング現象としても知られています。さらに、研究者らは、スケールに関連する別の興味深い現象、すなわち U 字型現象も観察しました。名前が示すように、この現象は、LLM モデルが大きくなるにつれて、特定のタスクにおけるパフォーマンスが最初は向上し、その後低下し始め、その後再び向上することを意味します。 この分野の研究を進めるには、創発的能力、カウンタースケール現象、U 字型現象についてより深く理解する必要があります。 キーポイント 5 (1) モデルのサイズが指数関数的に増加するにつれて、LLM の算術推論と常識推論の能力も増加します。 。 (2) LLM の規模が大きくなるにつれて、ワープロ機能や論理機能など、創発的な機能が偶然新しい用途を発見する可能性があります。 (3) モデルの機能は規模に応じて必ずしも増加するとは限らず、大規模な言語モデルの機能と規模の関係についての理解はまだ限られています。 4.5 その他のタスク LLM の長所と短所をよりよく理解するために、上記に記載されていないその他の関連タスク。 適用外 LLM: モデルの目標がトレーニング データと異なる場合、LLM はこれらのタスクで困難を伴うことがよくあります。 LLM に適しています: LLM は、特定の特定のタスクに特に適しています。いくつかの例を挙げると、LLM は人間を模倣するのが非常に得意です。LLM は、要約や翻訳などの特定の NLG タスクの品質を評価するためにも使用できます。LLM の一部の機能は、解釈可能性など、パフォーマンスの向上以外の利点ももたらす可能性があります。 キーポイント6 (1) 事前学習目標やLLMのデータからかけ離れたタスクについては、微調整を行うモデルとドメイン固有のモデルにはまだ場所があります。 (2) LLM は人間の模倣、データのアノテーションと生成が得意です。 NLP タスクの品質評価にも使用でき、解釈可能性などの利点があります。 4.6 現実世界の「タスク」 最後に、このセクションでは LLM の使用と微調整について説明します。現実世界のモデル「タスク」アプリケーションをオンにします。学術的な設定とは異なり、現実世界の設定には明確な定義が欠けていることが多いため、ここでは「タスク」という用語が大雑把に使用されています。モデルに対する多くの要件は、NLP タスクとみなすことさえできません。モデルが直面する実際の課題は、次の 3 つの側面から生じます。 #本質的に、ユーザーのリクエストによるこれらの現実世界のパズルは、特定のタスク用に設計された NLP データセットの分布からの逸脱によって引き起こされます。公開されている NLP データセットには、これらのモデルの使用方法が反映されていません。 ポイント 7 モデルの微調整と比較して、LLM は現実世界のシナリオの処理により適しています。ただし、現実世界でのモデルの有効性を評価することは未解決の問題のままです。 LLM はさまざまな下流タスクに適していますが、効率や信頼性など、考慮すべき要素は他にもあります。効率に関わる問題には、LLM のトレーニング コスト、推論レイテンシ、パラメータを効率的に利用するための調整戦略などが含まれます。信頼性の観点からは、LLM の堅牢性と調整機能、公平性と偏り、潜在的なエラー相関関係、およびセキュリティ上の課題を考慮する必要があります。キーポイント 8(1) タスクがコスト重視であるか、レイテンシ要件が厳しい場合は、軽量のローカル微調整モデルを優先する必要があります。モデルをデプロイおよび配信するときは、パラメーターを効率的に使用するためのチューニングを検討してください。 (2) LLM のゼロショット アプローチにより、微調整されたモデルによくある、タスク固有のデータ セットからのショートカットの学習が妨げられます。それにもかかわらず、LLM には依然として特定のショートカット学習の問題が発生します。 (3) LLM の潜在的に有害または偏った出力および幻覚の問題は重大な結果につながる可能性があるため、LLM に関連するセキュリティ問題には最大の注意が必要です。人間によるフィードバックなどの方法は、これらの問題を軽減することを約束します。 この実用的なガイドでは、LLM についての洞察と、さまざまな NLP タスクで LLM を使用するためのベスト プラクティスを提供します。これが研究者や実践者が LLM の可能性を活用し、言語技術の革新を促進するのに役立つことを願っています。 もちろん、LLM には解決すべき課題もいくつかあります。
5 その他の側面
6 概要と今後の課題
以上が大規模な言語モデルの進化ツリー、これは ChatGPT の超詳細な「食べる」ガイドですの詳細内容です。詳細については、PHP 中国語 Web サイトの他の関連記事を参照してください。
















![[Web フロントエンド] Node.js クイック スタート](https://img.php.cn/upload/course/000/000/067/662b5d34ba7c0227.png)



