

修改mysql 表的字符编码_MySQL

在select进行中文查询的时候报了如下的错误
ERROR 1267 (HY000): Illegal mix of collations (latin1_swedish_ci,IMPLICIT) and (utf8_general_ci,COERCIBLE) for operation ‘=‘
查看一下表的编码
show create table t_user_friend;
发现其是latin1编码的,需将其转成utf8
命令如下
alter table t_user_friend convert to character set utf8;
当然还可以设置mysql的客户端和服务器的默认编码
vi /etc/mysql/my.conf
在[mysql] 下面 添加 default-character-set=utf8
在[mysqld] 下面添加
character-set-server=utf8
collaction-server = utf8-greneral-cli
修改完后重启mysql server

ホットAIツール

Undresser.AI Undress
リアルなヌード写真を作成する AI 搭載アプリ

AI Clothes Remover
写真から衣服を削除するオンライン AI ツール。

Undress AI Tool
脱衣画像を無料で

Clothoff.io
AI衣類リムーバー

AI Hentai Generator
AIヘンタイを無料で生成します。

人気の記事
ホットツール

メモ帳++7.3.1
使いやすく無料のコードエディター

SublimeText3 中国語版
中国語版、とても使いやすい

ゼンドスタジオ 13.0.1
強力な PHP 統合開発環境

ドリームウィーバー CS6
ビジュアル Web 開発ツール

SublimeText3 Mac版
神レベルのコード編集ソフト(SublimeText3)
ホットトピック
 7335
7335
 9
1627
14
1352
46
1264
25
1209
29
9
1627
14
1352
46
1264
25
1209
29

 11 の一般的な分類特徴エンコード技術
Apr 12, 2023 pm 12:16 PM
11 の一般的な分類特徴エンコード技術
Apr 12, 2023 pm 12:16 PM
機械学習アルゴリズムは数値入力のみを受け入れるため、カテゴリカルな特徴が見つかった場合は、そのカテゴリカルな特徴をエンコードします。この記事では、11 の一般的なカテゴリカル変数のエンコード方法を要約します。 1. ONE HOT エンコーディング 最も一般的で一般的に使用されているエンコーディング方式は One Hot Enoding です。 n 個の観測値と d 個の個別の値を持つ単一の変数は、n 個の観測値を持つ d 個のバイナリ変数に変換され、各バイナリ変数はビット (0, 1) で識別されます。例: コーディング後の最も簡単な実装は、パンダの get_dummiesnew_df=pd.get_dummies(columns=[‘Sex’], data=df)2 を使用することです。
 utf8 でエンコードされた中国語の文字は何バイトを占めますか?
Feb 21, 2023 am 11:40 AM
utf8 でエンコードされた中国語の文字は何バイトを占めますか?
Feb 21, 2023 am 11:40 AM
UTF8 でエンコードされた中国語文字は 3 バイトを占めます。 UTF-8 エンコードでは、1 つの中国語文字は 3 バイトに相当し、1 つの中国語の句読点は 3 バイトを占めますが、Unicode エンコードでは、1 つの中国語文字 (繁体字中国語を含む) は 2 バイトに相当します。 UTF-8 は各文字のエンコードに 1 ~ 4 バイトを使用します。1 つの US-ASCIl 文字のエンコードには 1 バイトのみが必要です。ラテン語、ギリシャ語、キリル文字、アルメニア語、および発音区別符号付きのヘブライ語。アラビア語、シリア語およびその他の文字は 2 バイトが必要です。エンコーディング。
 Wordで矢印を入力する方法
Apr 16, 2023 pm 11:37 PM
Wordで矢印を入力する方法
Apr 16, 2023 pm 11:37 PM
オートコレクトを使用して Word で矢印を入力する方法 Word で矢印を入力する最も速い方法の 1 つは、定義済みのオートコレクト ショートカットを使用することです。特定の一連の文字を入力すると、Word はそれらの文字を矢印記号に自動的に変換します。この方法を使用すると、さまざまな矢印スタイルを描画できます。 Word でオートコレクトを使用して矢印を入力するには: 矢印を表示する文書内の位置にカーソルを移動します。次の文字の組み合わせのいずれかを入力します。 入力した文字を矢印記号に修正したくない場合は、キーボードのバックスペース キーを押してください。
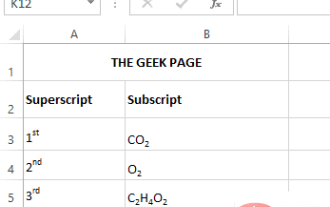 Microsoft Excel で上付き文字と下付き文字の書式設定オプションを適用する方法
Apr 14, 2023 pm 12:07 PM
Microsoft Excel で上付き文字と下付き文字の書式設定オプションを適用する方法
Apr 14, 2023 pm 12:07 PM
上付き文字は、通常のテキスト行の少し上に設定する必要がある、文字または数字の 1 つまたは複数の文字です。たとえば、1st と書く必要がある場合、st の文字は 1 の文字より少し高い位置にある必要があります。同様に、下付き文字は文字のグループまたは単一の文字であり、通常のテキスト レベルよりわずかに低く設定する必要があります。たとえば、化学式を書くときは、通常の文字行の下に数字を配置する必要があります。次のスクリーンショットは、上付き文字と下付き文字の書式設定の例をいくつか示しています。難しい作業のように思えるかもしれませんが、テキストに上付き文字と下付き文字の書式を適用するのは実際には非常に簡単です。この記事では、上付き文字または下付き文字を使用してテキストを簡単に書式設定する方法をいくつかの簡単な手順で説明します。この記事を楽しんで読んでいただければ幸いです。 Excelで上付き文字を適用する方法
 ナレッジ グラフ: 大規模モデルの理想的なパートナー
Jan 29, 2024 am 09:21 AM
ナレッジ グラフ: 大規模モデルの理想的なパートナー
Jan 29, 2024 am 09:21 AM
大規模言語モデル (LLM) は、滑らかで一貫したテキストを生成する機能を備えており、人工知能の会話や創造的な文章などの分野に新たな可能性をもたらします。ただし、LLM にはいくつかの重要な制限もあります。まず、彼らの知識はトレーニング データから認識されたパターンに限定されており、世界に対する真の理解が欠けています。第 2 に、推論スキルには限界があり、論理的な推論を行ったり、複数のデータ ソースからの事実を融合したりすることができません。より複雑で自由回答の質問に直面すると、LLM の答えは「幻想」として知られる不条理または矛盾したものになる場合があります。したがって、LLM はいくつかの面では非常に便利ですが、複雑な問題や現実世界の状況を扱う場合には、依然として一定の制限があります。これらのギャップを埋めるために、検索拡張生成 (RAG) システムが近年登場しました。
 iPhone や Mac で度記号などの拡張文字を入力するにはどうすればよいですか?
Apr 22, 2023 pm 02:01 PM
iPhone や Mac で度記号などの拡張文字を入力するにはどうすればよいですか?
Apr 22, 2023 pm 02:01 PM
物理キーボードまたは数字キーボードでは、表面上に提供される文字オプションの数が限られています。ただし、iPhone、iPad、Mac ではアクセント付き文字や特殊文字などにアクセスする方法がいくつかあります。標準の iOS キーボードを使用すると、大文字、小文字、標準の数字、句読点、文字にすばやくアクセスできます。もちろん他にもたくさんのキャラクターがいます。発音記号を含む文字から逆さまの疑問符まで選択できます。隠れた特殊文字を見つけてしまったかもしれません。そうでない場合は、iPhone、iPad、Mac でアクセスする方法を次に示します。 iPhone および iPad で拡張文字にアクセスする方法 iPhone または iPad で拡張文字を取得するのは非常に簡単です。 「お知らせ」には「
 Java の Character.isDigit() 関数を使用して、文字が数字かどうかを判断します
Jul 27, 2023 am 09:32 AM
Java の Character.isDigit() 関数を使用して、文字が数字かどうかを判断します
Jul 27, 2023 am 09:32 AM
文字が数字かどうかを判断するには、Java の Character.isDigit() 関数を使用します。文字はコンピュータ内部で ASCII コードの形式で表されます。各文字には対応する ASCII コードがあります。このうち、0~9の数字に対応するASCIIコードの値は、それぞれ48~57となります。文字が数値かどうかを判断するには、Java の Character クラスによって提供される isDigit() メソッドを使用できます。 isDigit() メソッドは Character クラスに属します
 matplotlibで中国語の文字を表示する正しい方法
Jan 13, 2024 am 11:03 AM
matplotlibで中国語の文字を表示する正しい方法
Jan 13, 2024 am 11:03 AM
matplotlib で中国語の文字を正しく表示することは、多くの中国人ユーザーがよく遭遇する問題です。デフォルトでは、matplotlib は英語フォントを使用するため、中国語の文字を正しく表示できません。この問題を解決するには、正しい中国語フォントを設定し、それを matplotlib に適用する必要があります。以下は、matplotlib で中国語の文字を正しく表示するのに役立ついくつかの具体的なコード例です。まず、必要なライブラリをインポートする必要があります: importmatplot
