

カスタマイズされたオペレーターの融合により AI のエンドツーエンドのパフォーマンスを向上

グラフの最適化は、AI モデルのトレーニングと推論に使用される時間とリソースを削減する上で重要な役割を果たします。グラフ最適化の重要な機能は、モデル内で融合できる演算子を融合することです。これにより、メモリ使用量と低速メモリでのデータ転送が削減され、計算効率が向上します。ただし、さまざまな演算子融合を提供できるバックエンド ソリューションを実装することは非常に難しく、実際のハードウェア上の AI モデルで使用できる演算子融合は非常に限られます。
コンポーザブル カーネル (CK) ライブラリは、AMD GPU でのオペレーター フュージョンのための一連のバックエンド ソリューションを提供することを目的としています。 CK は汎用プログラミング言語 HIP C を使用しており、完全にオープンソースです。その設計コンセプトは次のとおりです。
- 高性能と高い生産性: CK の中核は、慎重に設計され、高度に最適化された、再利用可能な基本モジュールのセットです。 CK ライブラリのすべての演算子は、これらの基本モジュールを組み合わせて実装されます。これらの基本モジュールを再利用すると、高いパフォーマンスを確保しながら、バックエンド アルゴリズムの開発サイクルが大幅に短縮されます。
- 現在の AI 問題に熟達し、将来の AI 問題に迅速に適応する: CK は、複雑なオペレーターの融合を可能にする、AI オペレーター バックエンド ソリューションの完全なセットを提供することを目指しています。バックエンド全体は、外部オペレーター ライブラリに依存せずに CK を使用して実装されます。 CK の再利用可能な基本モジュールは、一般的な AI モデル (マシン ビジョン、自然言語処理など) で必要なさまざまな演算子とその融合を実装するのに十分です。新しい AI モデルに新しいオペレーターが必要な場合、CK は必要な基本モジュールも提供します。
- AI システム専門家向けのシンプルだが強力なツール: CK すべての演算子は HIP C テンプレートを使用して実装されます。 AI システムの専門家は、インスタンス化テンプレートを通じて、データ型、メタ操作タイプ、テンソル格納形式などのこれらの演算子のプロパティをカスタマイズできます。通常、これに必要なコードは数行だけです。
- フレンドリーな HIP C インターフェイス: HPC アルゴリズム開発者は、AI コンピューティング アクセラレーションの最前線を押し広げてきました。 CK の重要な設計コンセプトは、HPC アルゴリズム開発者が AI の高速化に貢献しやすくすることです。したがって、CK のすべてのコア モジュールは、中間表現 (IR) ではなく HIP C で実装されます。 HPC アルゴリズム開発者は、IR ベースのオペレーター ライブラリの場合のように、特定のアルゴリズムのコンパイラー パスを作成する必要がなく、使い慣れた C コードの形式でアルゴリズムを直接作成できます。そうすることで、アルゴリズムの反復速度が大幅に向上します。
- 移植性: バックエンドとして CK を使用した現在のグラフ最適化は、将来のすべての AMD GPU に移植でき、最終的には AMD CPU にも移植される予定です [2]。
- CK ソース コード: https://github.com/ROCmSoftwarePlatform/composable_kernel
コア コンセプト
CK では、バックエンド開発者の生産性を向上させる 2 つの概念を導入しています:
1. 「テンソル座標変換」の画期的な導入 AI オペレーターの作成の複雑さを軽減。この研究は、再利用可能なテンソル座標変換基本モジュールのセットの定義を開拓し、それらを使用して複雑な AI 演算子 (畳み込み、グループ正規化削減、Depth2Space など) を数学的に厳密な方法で最も基本的な AI に再表現しました。演算子 (GEMM、2D リダクション、テンソル転送など)。このテクノロジーにより、基本的な AI オペレーター用に作成されたアルゴリズムを、アルゴリズムを書き直すことなく、対応するすべての複雑な AI オペレーターで直接使用できるようになります。
2. タイルベースのプログラミング パラダイム: オペレーター フュージョンのバックエンド アルゴリズムの開発は、まず各フュージョン前のオペレーター (独立したオペレーター) を多数の「小さな部分」に分解することと見なされます。データ操作を実行し、これらの「小さな部分」操作を融合演算子に結合します。このようなそれぞれの「小さなブロック」演算は元の独立した演算子に対応しますが、演算されるデータは元のテンソルの一部 (タイル) にすぎないため、そのような「小さなブロック」演算はタイル テンソル 演算子と呼ばれます。 CK ライブラリには、高度に最適化されたタイル テンソル オペレーターの実装のセットが含まれており、CK のすべての AI 独立オペレーターと融合オペレーターは、それらを使用して実装されます。現在、これらのタイル テンソル オペレーターには、タイル GEMM、タイル リダクション、タイル テンソル転送が含まれます。各タイル テンソル オペレーターには、GPU スレッド ブロック、ワープ、スレッドの実装があります。
Tensor 座標変換と Tile Tensor Operator は一緒になって、CK の再利用可能な基本モジュールを形成します。
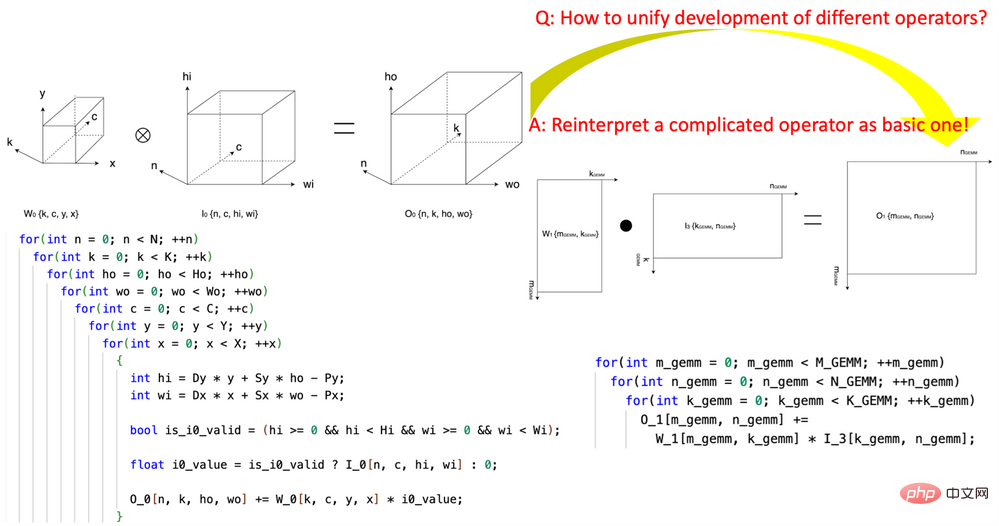
#図 1、CK の Tensor 座標変換基本モジュールを使用して、畳み込み演算子を GEMM 演算子に表現します
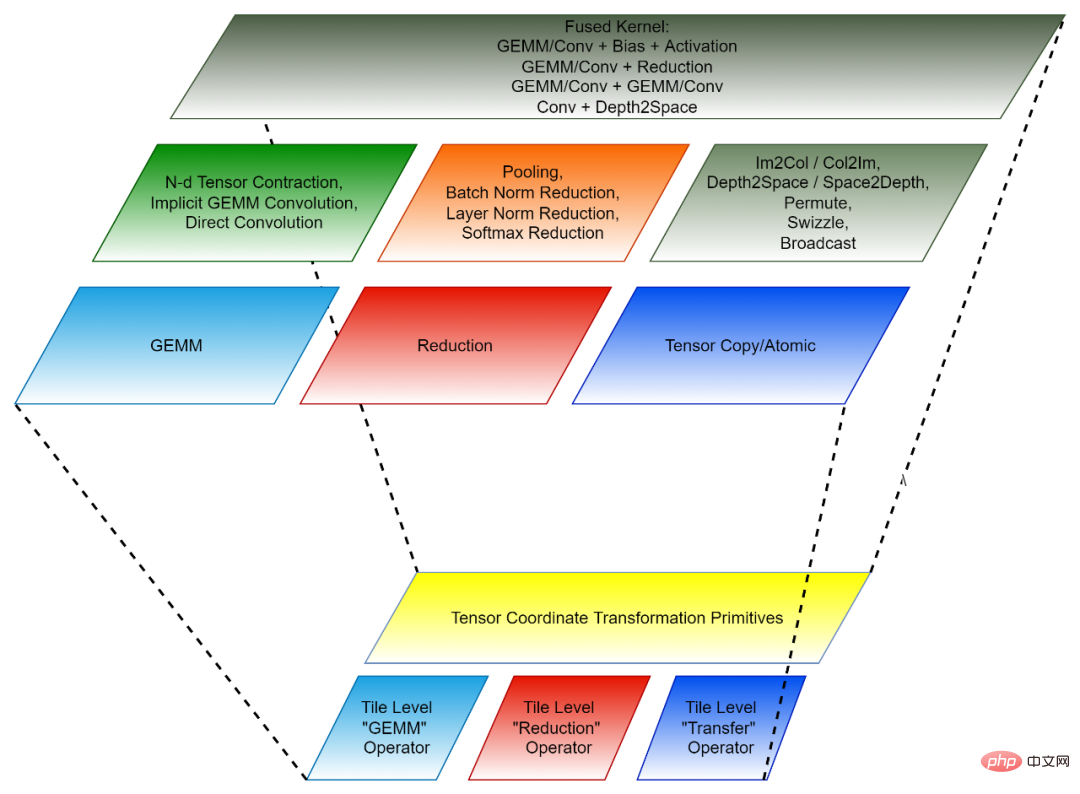
#図 2、CK の構成 (下: 再利用可能な基本モジュール、上: 独立演算子と融合演算子) コード構造
CK ライブラリ構造は、下から上に、テンプレート化されたタイル オペレーター、テンプレート化されたカーネルとインボーカー、インスタンス化されたカーネルとインボーカー、およびクライアント API [3]。各層は異なる現像剤に対応します。
- #AI システム エキスパート: 「直接使用できる、高性能の独立演算子と融合演算子を提供するバックエンド ソリューションが必要です。」この例 [4] で使用されているクライアント API とインスタンス化されたカーネルとインボーカーは、このタイプの開発者のニーズを満たすために、事前にインスタンス化されコンパイルされたオブジェクトを提供します。
- AI システム専門家: 「オープンソース AI フレームワークの最先端のグラフ最適化作業を行っています。すべての融合演算子を提供できる高性能カーネルが必要です」 「グラフの最適化に必要です。バックエンド ソリューション。同時に、これらのカーネルもカスタマイズする必要があるため、「受け入れるか破棄するか」のようなブラックボックス ソリューションではニーズを満たすことができません。テンプレート化されたカーネル層とインボーカー層は、このタイプの開発者を満足させます。たとえば、この例 [5] では、開発者はテンプレート化されたカーネルとインボーカー層を使用して、必要な FP16 GEMM Add Add FastGeLU カーネルをインスタンス化できます。
- HPC アルゴリズムの専門家: 「私のチームは、社内で常に反復される AI モデル用の高性能バックエンド アルゴリズムを開発しています。チームには HPC アルゴリズムの専門家がいます。 「しかし、私たちは依然として複雑なコードを使用したいと考えています。ハードウェア ベンダーが提供する高度に最適化されたソース コードを使用および改善することで、生産性が向上し、コードを将来のハードウェア アーキテクチャに移植できるようになります。現時点ではコードをハードウェア ベンダーと共有することなく、これを実現したいと考えています。」 。 Template Tile Operator レイヤーは、このタイプの開発者に役立ちます。たとえば、このコード [6] では、開発者は Template Tile Operator を使用して GEMM 最適化パイプラインを実装しています。
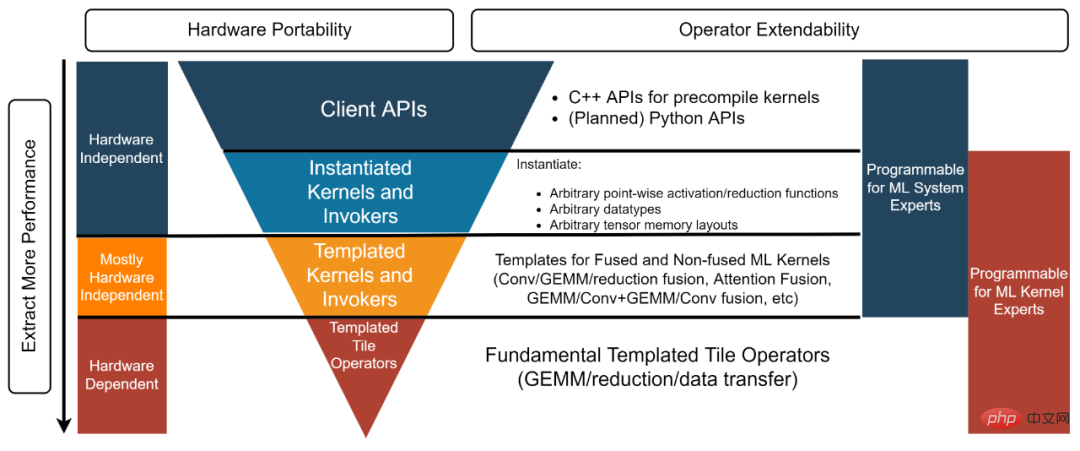
##図 3、CK ライブラリの 4 層構造 AITemplate CK に基づくエンドツーエンドのモデル推論
Meta の AITemplate [7] (AIT) は、AMD と Nvidia GPU を統合する AI 推論システムです。 AITemplate は、CK のテンプレート化されたカーネルとインボーカー層を使用して、AMD GPU 上のバックエンドとして CK を使用します。
AITemplate CK は、AMD Instinct™ MI250 上の複数の重要な AI モデルで最先端の推論パフォーマンスを実現します。 CK における最先端のフュージョン オペレーターの定義は、AITemplate チームのビジョンによって推進されています。多くのフュージョン オペレーター アルゴリズムも、CK チームと AITemplate チームによって共同設計されています。
この記事では、AMD Instinct MI250 および類似製品のいくつかのエンドツーエンド モデルのパフォーマンスを比較します [8]。この記事の AMD Instinct MI250 AI モデルのすべてのパフォーマンス データは、AITemplate[9] CK[10] を使用して取得されました。
実験的
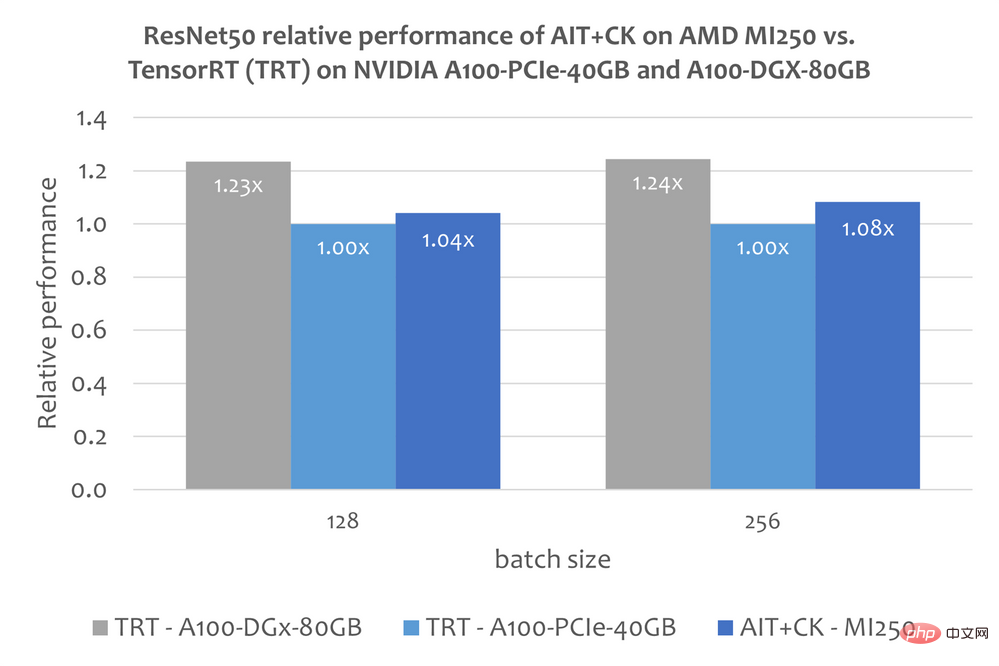
ResNet-50下の画像は、AMD Instinct MI250のパフォーマンスにおけるAITを示しています。 A100-PCIe-40GB および A100-DGX-80GB での CK と TensorRT v8.5.0.12 [11] (TRT) の比較。結果は、AMD Instinct MI250 上の AIT CK が、A100-PCIe-40GB 上の TRT と比較して 1.08 倍の高速化を達成したことを示しています。
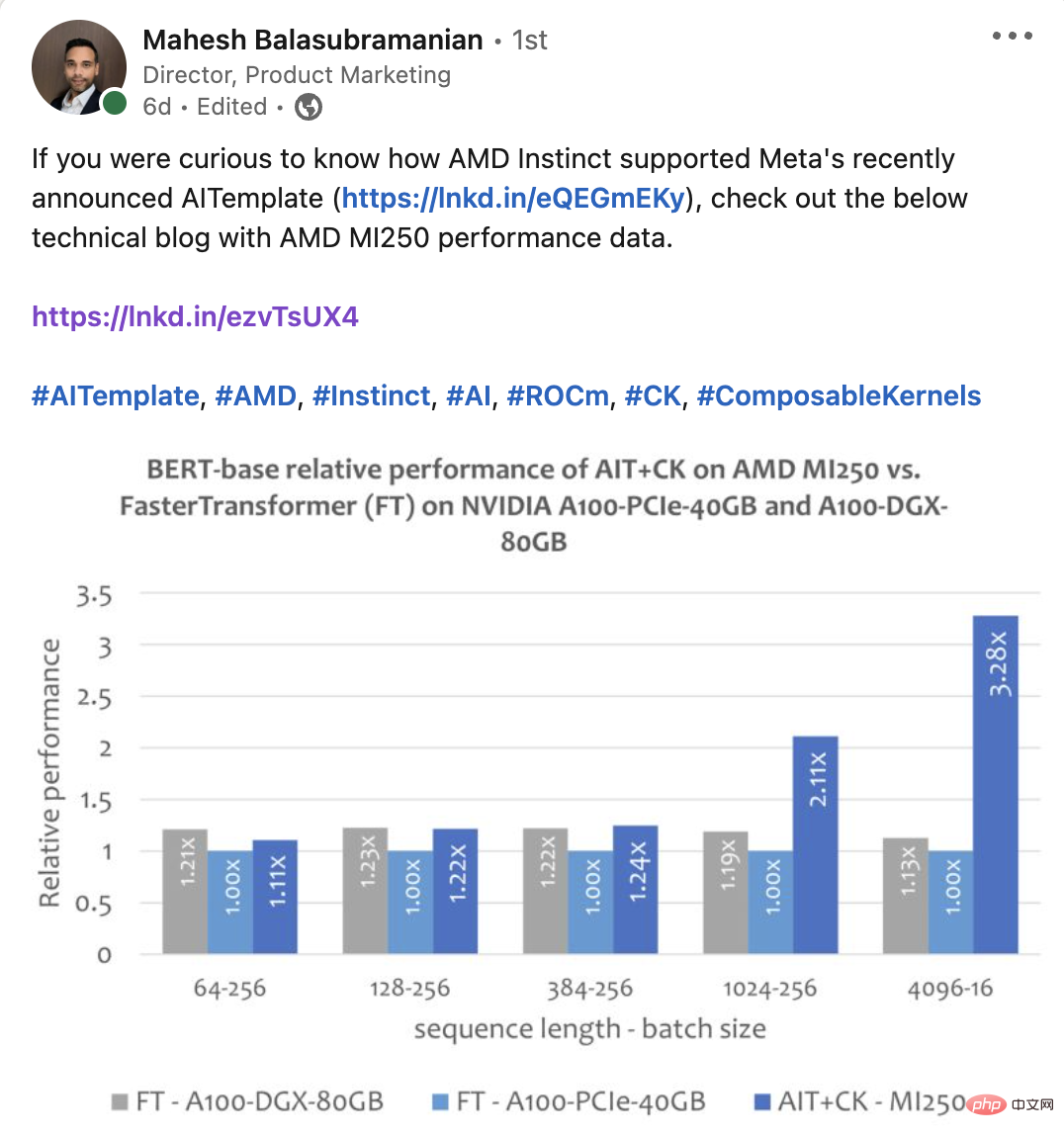
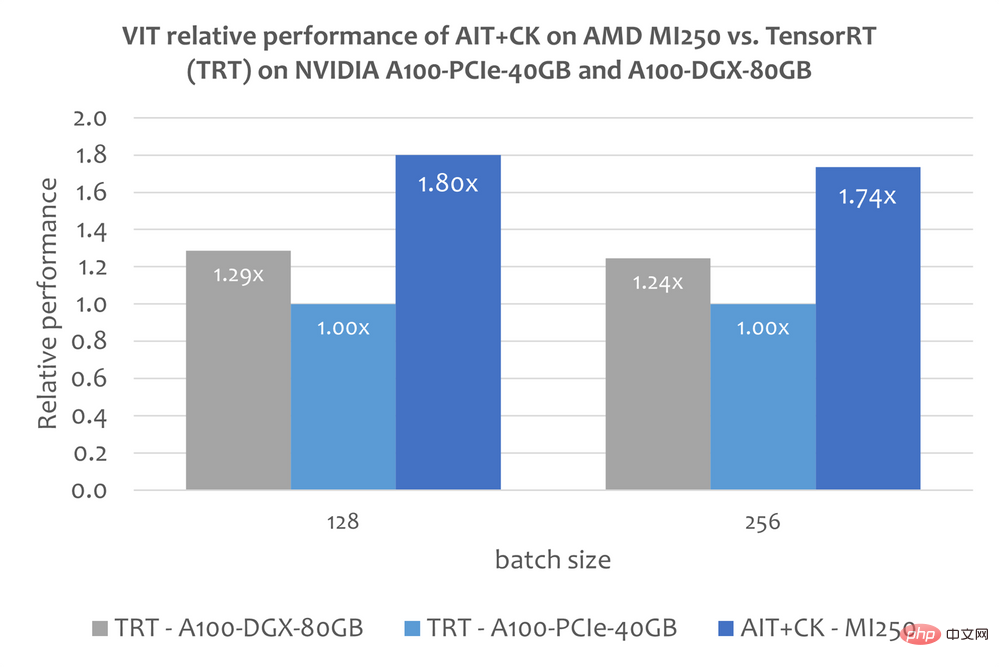
CK に基づいて実装されたバッチ化された GEMM Softmax GEMM フュージョン オペレーター テンプレートは、GPU コンピューティング ユニット (コンピューティング ユニット) と HBM の間の中間結果の転送を完全に排除できます。このフュージョン オペレーター テンプレートを使用することにより、元々帯域幅制限があったアテンション レイヤーの多くの問題が計算ボトルネック (計算制限) になり、GPU の計算能力をより有効に活用できるようになります。この CK 実装は FlashAttendant [12] から深くインスピレーションを得ており、元の FlashAttendant 実装よりも多くのデータ処理を削減します。 次の図は、A100-PCIe-40GB および A100-DGX-80GB での FasterTransformer v5.1.1 バグ修正 [13] (FT) を適用した AMD Instinct MI250 の AIT CK のパフォーマンス比較を示しています。 Bert Base モデル (ケースなし)。 FT は、シーケンスが 4096 の場合、A100-PCIe-40GB および A100-DGX-80GB のバッチ 32 で GPU メモリを使い果たします。したがって、シーケンスが 4096 の場合、この記事ではバッチ 16 の結果のみが表示されます。結果は、AMD Instinct MI250 上の AIT CK が、A100-PCIe-40GB 上の FT と比較して 3.28 倍の FT 高速化を実現し、A100-DGX-80GB と比較して 2.91 倍の FT 高速化を達成していることを示しています。 ビジョン トランスフォーマー (VIT) 下の画像は AMD を示しています。 Instinct A100-PCIe-40GB および A100-DGX-80GB 上の TensorRT v8.5.0.12 (TRT) の Vision Transformer Base (224x224 画像) を使用した MI250 上の AIT CK のパフォーマンス比較。結果は、AMD Instinct MI250 上の AIT CK が、A100-PCIe-40GB 上の TRT と比較して 1.8 倍の高速化、および A100-DGX-80GB 上の TRT と比較して 1.4 倍の高速化を達成していることを示しています。 ##安定した拡散
#ただし、この記事では、TensorRT を使用してStable Diffusion をエンドツーエンドで実行する 最終モデルに関する公開情報。しかし、この記事「TensorRT を使用して安定拡散を 25% 高速化する」[14] では、TensorRT を使用して安定拡散の UNet モデルを高速化する方法について説明しています。 UNet は安定拡散の最も重要で時間のかかる部分であるため、UNet のパフォーマンスは安定拡散のパフォーマンスをほぼ反映します。 以下のグラフは、AMD Instinct MI250 上の AIT CK のパフォーマンスと、TensorRT v8.5.0.12 (TRT) を搭載した A100-PCIe-40GB および A100-DGX-80GB 上の UNet のパフォーマンスを示しています。 。結果は、AMD Instinct MI250 の AIT CK が、A100-PCIe-40GB の TRT と比較して 2.45 倍の高速化、A100-DGX-80GB の TRT と比較して 2.03 倍の高速化を達成していることを示しています。
##ROCm Web ページ: AMD ROCm™ オープン ソフトウェア プラットフォーム | AMD ##AMD Instinct アクセラレーター: AMD Instinct™ アクセラレーター | AMD AMD Infinity Hub: AMD Infinity Hub | AMD エンドノート:
#1. Chao Liu は PMTS ですAMD のソフトウェア開発エンジニアです。Jing Zhang は AMD の SMTS ソフトウェア開発エンジニアです。投稿内容は彼ら自身の意見であり、AMD の立場、戦略、または意見を代表するものではない場合があります。サードパーティのサイトへのリンクは便宜のために提供されており、明示的に記載されていない限り、AMD はかかるリンク先サイトのコンテンツについては責任を負わず、いかなる保証も暗黙的に保証されません。 2.CPU 用 CK は開発の初期段階にあります。 3.C現時点での API、Python API は計画中です。 4.GEMM 用 CK「クライアント API」の例 追加 FastGeLU 融合オペレーターを追加。 https://github.com/ROCmSoftwarePlatform/composable_kernel/blob/685860c2a9483c9e909d2f8bfb95056672491... 5.CK「テンプレート化されたカーネル」の例GEMM の「および Invoker」を追加 FastGeLU ヒューズ オペレーターを追加します。 https://github.com/ROCmSoftwarePlatform/composable_kernel/blob/685860c2a9483c9e909d2f8bfb95056672491... 6.「テンプレート化された CK の使用例」 Tile Operator」プリミティブを使用して GEMM パイプラインを作成します。 https://github.com/ROCmSoftwarePlatform/composable_kernel/blob/685860c2a9483c9e909d2f8bfb95056672491... 7.Meta の AITemplate GitHub リポジトリ。 https://github.com/facebookincubator/AITemplate 8.MI200-71: テストは AMD MLSE 10.23.22 を使用して実施されました。 AITemplate https://github.com/ROCmSoftwarePlatform/AITemplate、コミット f940d9b) コンポーザブル カーネル https://github.com/ROCmSoftwarePlatform/composable_kernel、コミット 40942b9) 2x AMD EPYC 7713 64 コア プロセッサー サーバー (4x 搭載) で ROCm™5.3 を実行AMD Infinity Fabric™ テクノロジーを搭載した AMD Instinct MI250 OAM (128 GB HBM2e) 560W GPU と、2x AMD EPYC 7742 64 コア プロセッサー サーバー上で実行される CUDA® 11.8 を搭載した TensorRT v8.5.0.12 および FasterTransformer (v5.1.1 バグ修正) の比較4x Nvidia A100-PCIe-40GB (250W) GPU および TensorRT v8.5.0.12 および FasterTransformer (v5.1.1 バグ修正) (CUDA® 11.8 搭載) GPU。サーバーの製造元によって構成が異なり、異なる結果が生じる場合があります。パフォーマンスは、最新のドライバーの使用や最適化などの要因によって異なる場合があります。 9.https://github.com/ROCmSoftwarePlatform/AITemplate/tree/f940d9b7ac8b976fba127e2c269dc5b368f30e4e
12.FlashAttendant: IO 認識による高速かつメモリ効率の高い正確なアテンション。 https://arxiv.org/abs/2205.14135 13.FasterTransformer GitHub リポジトリ。 https://github.com/NVIDIA/FasterTransformer 14.TensorRT を使用して安定した拡散を 25% 高速化します。 https://www.photoroom.com/tech/stable-diffusion-25-percent-faster-and-save-seconds/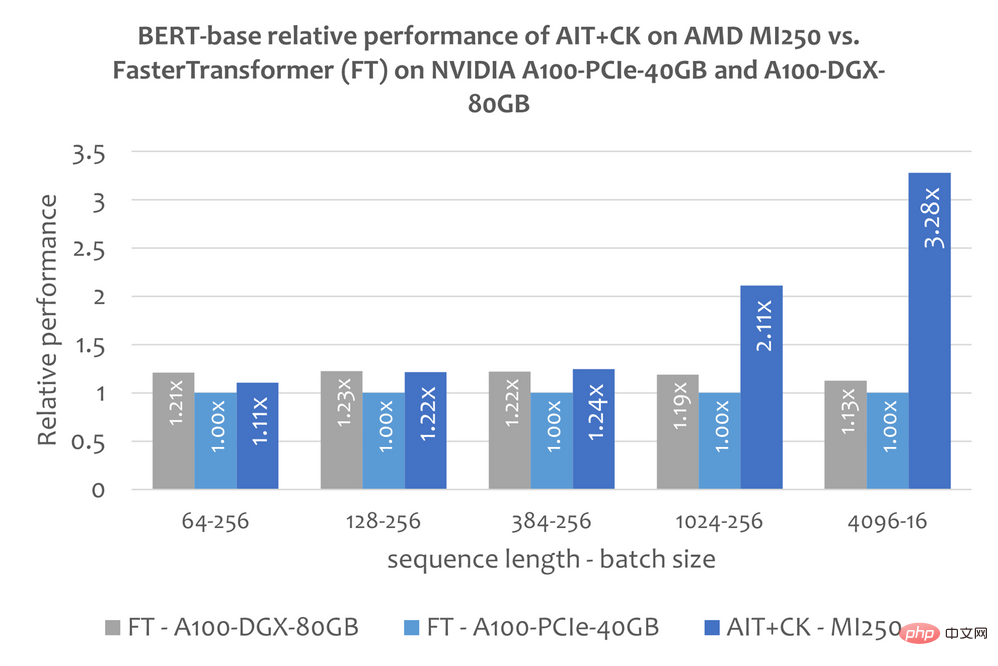
 #UNet in Stable Diffusion
#UNet in Stable Diffusion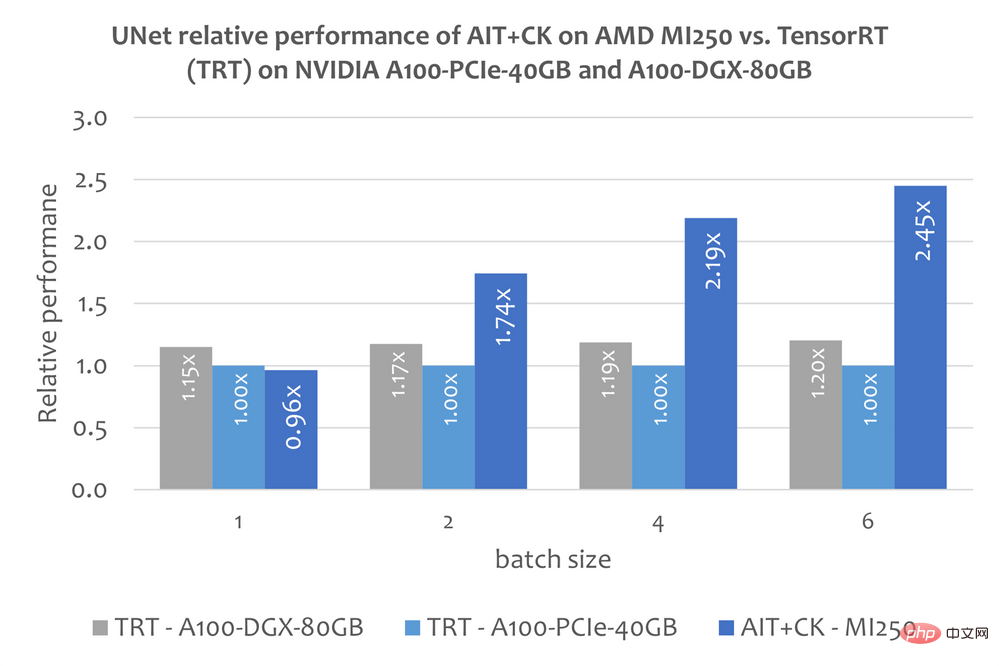 #詳細情報
#詳細情報
以上がカスタマイズされたオペレーターの融合により AI のエンドツーエンドのパフォーマンスを向上の詳細内容です。詳細については、PHP 中国語 Web サイトの他の関連記事を参照してください。

ホットAIツール

Undresser.AI Undress
リアルなヌード写真を作成する AI 搭載アプリ

AI Clothes Remover
写真から衣服を削除するオンライン AI ツール。

Undress AI Tool
脱衣画像を無料で

Clothoff.io
AI衣類リムーバー

AI Hentai Generator
AIヘンタイを無料で生成します。

人気の記事
ホットツール

メモ帳++7.3.1
使いやすく無料のコードエディター

SublimeText3 中国語版
中国語版、とても使いやすい

ゼンドスタジオ 13.0.1
強力な PHP 統合開発環境

ドリームウィーバー CS6
ビジュアル Web 開発ツール

SublimeText3 Mac版
神レベルのコード編集ソフト(SublimeText3)
ホットトピック
 7554
7554
 15
1382
52
83
11
22
96
15
1382
52
83
11
22
96

 オープンソースのフリーテキスト注釈ツールのおすすめ 10 選
Mar 26, 2024 pm 08:20 PM
オープンソースのフリーテキスト注釈ツールのおすすめ 10 選
Mar 26, 2024 pm 08:20 PM
テキスト注釈は、テキスト内の特定のコンテンツにラベルまたはタグを対応させる作業です。その主な目的は、特に人工知能の分野で、より深い分析と処理のためにテキストに追加情報を提供することです。テキスト注釈は、人工知能アプリケーションの教師あり機械学習タスクにとって非常に重要です。これは、自然言語テキスト情報をより正確に理解し、テキスト分類、感情分析、言語翻訳などのタスクのパフォーマンスを向上させるために AI モデルをトレーニングするために使用されます。テキスト アノテーションを通じて、AI モデルにテキスト内のエンティティを認識し、コンテキストを理解し、新しい同様のデータが出現したときに正確な予測を行うように教えることができます。この記事では主に、より優れたオープンソースのテキスト注釈ツールをいくつか推奨します。 1.LabelStudiohttps://github.com/Hu
 オープンソースの無料画像注釈ツールおすすめ 15 選
Mar 28, 2024 pm 01:21 PM
オープンソースの無料画像注釈ツールおすすめ 15 選
Mar 28, 2024 pm 01:21 PM
画像の注釈は、ラベルまたは説明情報を画像に関連付けて、画像の内容に深い意味と説明を与えるプロセスです。このプロセスは機械学習にとって重要であり、画像内の個々の要素をより正確に識別するために視覚モデルをトレーニングするのに役立ちます。画像に注釈を追加することで、コンピュータは画像の背後にあるセマンティクスとコンテキストを理解できるため、画像の内容を理解して分析する能力が向上します。画像アノテーションは、コンピュータ ビジョン、自然言語処理、グラフ ビジョン モデルなどの多くの分野をカバーする幅広い用途があり、車両が道路上の障害物を識別するのを支援したり、障害物の検出を支援したりするなど、幅広い用途があります。医用画像認識による病気の診断。この記事では主に、より優れたオープンソースおよび無料の画像注釈ツールをいくつか推奨します。 1.マケセンス
 win10gpu共有メモリをオフにする方法
Jan 12, 2024 am 09:45 AM
win10gpu共有メモリをオフにする方法
Jan 12, 2024 am 09:45 AM
コンピューターにある程度詳しい友人なら、GPU には共有メモリがあることを知っているはずですが、多くの友人は、共有メモリによってメモリの数が減り、コンピューターに影響が出るのではないかと心配して、GPU をオフにしたいと考えています。見る。 win10gpu 共有メモリをオフにする: 注: GPU の共有メモリをオフにすることはできませんが、その値を最小値に設定することはできます。 1. 起動時に DEL を押して BIOS に入ります。一部のマザーボードでは、F2/F9/F12 を押して入る必要があります。BIOS インターフェイスの上部には、「メイン」、「詳細」、その他の設定を含む多くのタブがあります。「チップセット」を見つけます。 " オプション。以下のインターフェイスで SouthBridge 設定オプションを見つけ、Enter をクリックして入力します。
 GPU ハードウェア アクセラレーションを有効にする必要がありますか?
Feb 26, 2024 pm 08:45 PM
GPU ハードウェア アクセラレーションを有効にする必要がありますか?
Feb 26, 2024 pm 08:45 PM
ハードウェア アクセラレーション GPU を有効にする必要がありますか?テクノロジーの継続的な開発と進歩に伴い、コンピューター グラフィックス処理の中核コンポーネントとして GPU (グラフィックス プロセッシング ユニット) が重要な役割を果たしています。ただし、ハードウェア アクセラレーションをオンにする必要があるかどうかについて疑問を抱くユーザーもいるかもしれません。この記事では、GPU のハードウェア アクセラレーションの必要性と、ハードウェア アクセラレーションをオンにした場合のコンピューターのパフォーマンスとユーザー エクスペリエンスへの影響について説明します。まず、ハードウェア アクセラレーションによる GPU がどのように動作するかを理解する必要があります。 GPUは特化型
 ニュースによると、AMDが新しいRX 7700M / 7800MラップトップGPUを発売するとのこと
Jan 06, 2024 pm 11:30 PM
ニュースによると、AMDが新しいRX 7700M / 7800MラップトップGPUを発売するとのこと
Jan 06, 2024 pm 11:30 PM
TechPowerUp によると、1 月 2 日のこのサイトのニュースによると、AMD は Navi32 GPU をベースにしたノートブック用グラフィックス カードを間もなく発売する予定で、具体的なモデルは RX7700M と RX7800M になる可能性があります。現在、AMD は、ハイエンド RX7900M (72CU)、メインストリーム RX7600M/7600MXT (28/32CU) シリーズ、RX7600S/7700S (28/32CU) シリーズなど、さまざまな RX7000 シリーズ ノートブック GPU を発売しています。 Navi32GPU は 60CU なので、AMD が RX7700M や RX7800M にするか、低消費電力モデル RX7900S を作るかもしれません。 AMDが期待しているのは、
 Beelink EX グラフィックス カード拡張ドックは、GPU パフォーマンスの損失ゼロを約束します
Aug 11, 2024 pm 09:55 PM
Beelink EX グラフィックス カード拡張ドックは、GPU パフォーマンスの損失ゼロを約束します
Aug 11, 2024 pm 09:55 PM
最近発売された Beelink GTi 14 の際立った機能の 1 つは、ミニ PC の下に隠し PCIe x8 スロットがあることです。同社は発売時に、これにより外部グラフィックスカードをシステムに接続しやすくなると述べた。ビーリンクにはnがあります
 推奨: 優れた JS オープンソースの顔検出および認識プロジェクト
Apr 03, 2024 am 11:55 AM
推奨: 優れた JS オープンソースの顔検出および認識プロジェクト
Apr 03, 2024 am 11:55 AM
顔の検出および認識テクノロジーは、すでに比較的成熟しており、広く使用されているテクノロジーです。現在、最も広く使用されているインターネット アプリケーション言語は JS ですが、Web フロントエンドでの顔検出と認識の実装には、バックエンドの顔認識と比較して利点と欠点があります。利点としては、ネットワーク インタラクションの削減とリアルタイム認識により、ユーザーの待ち時間が大幅に短縮され、ユーザー エクスペリエンスが向上することが挙げられます。欠点としては、モデル サイズによって制限されるため、精度も制限されることが挙げられます。 js を使用して Web 上に顔検出を実装するにはどうすればよいですか? Web 上で顔認識を実装するには、JavaScript、HTML、CSS、WebRTC など、関連するプログラミング言語とテクノロジに精通している必要があります。同時に、関連するコンピューター ビジョンと人工知能テクノロジーを習得する必要もあります。 Web 側の設計により、次の点に注意してください。
 AMD FSR 3.1 のリリース: フレーム生成機能は Nvidia GeForce RTX および Intel Arc GPU でも動作します
Jun 29, 2024 am 06:57 AM
AMD FSR 3.1 のリリース: フレーム生成機能は Nvidia GeForce RTX および Intel Arc GPU でも動作します
Jun 29, 2024 am 06:57 AM
AMD は、今年の第 2 四半期に FSR 3.1 をリリースするという 24 年 3 月の当初の約束を果たしました。 3.1 リリースを本当に際立たせているのは、フレーム生成側がアップスケーリング側から切り離されていることです。これにより、Nvidia および Intel GPU の所有者は FSR 3 を適用できるようになります。
