

清華大学崔鵬氏: 信頼できるインテリジェントな意思決定のフレームワークと実践


1. 信頼できるインテリジェントな意思決定フレームワーク
まず最初に、皆さんと共有したいと思います。信頼できるインテリジェントな意思決定フレームワーク。
1. 予測よりも重要な決定
実際の多くのシナリオでは、予測よりも決定の方が重要です。 。なぜなら、予測自体の目的は、将来がどうなるかを予測することだけではなく、予測を通じて現在のいくつかの重要な行動や意思決定に影響を与えることだからです。
ビジネス社会学の分野を含む多くの分野では、継続的な事業の成長(継続的事業成長)、新たな発見などの意思決定が非常に重要です。ビジネスチャンス(新たなビジネスチャンス)など、データドライブを通じて最終的な意思決定をどのようにサポートするかは、人工知能の分野で無視できない仕事の一部です。

# 2. どこでも意思決定

意思決定のシナリオはどこにでもあります。ユーザーに製品を推奨するよく知られたレコメンデーション システムは、実際にはすべての製品の中から選択を決定します。物流サービスの価格設定など、電子商取引における価格設定アルゴリズム、サービスの妥当な価格を設定する方法、医療シナリオでは、患者の症状に応じてどの薬や治療法を推奨するかなど、これらはすべて介入的な意思決定です。シナリオ。
#3. 一般的な意思決定方法 1: シミュレーターを使用して意思決定を行う
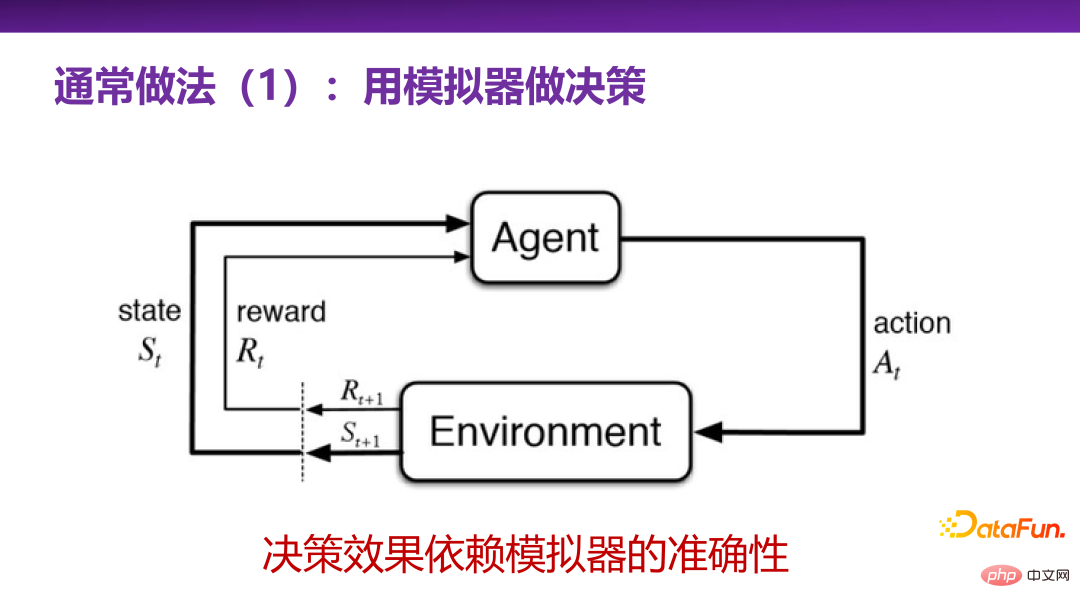
最初の一般的なアプローチは、シミュレーターを使用して意思決定を行うこと、つまり強化学習です。強化学習は、意思決定を行うための非常に強力な方法システムであり、実際のシーン (環境) または実際のシーンのシミュレーションがあることに相当し、それを通じて、インテリジェント エージェントは、実際のシーンで試行錯誤学習を継続的に実行できます。主要なアクション (アクション) を探索し、最終的にこの実際のシナリオで最大の報酬 (報酬) が得られる主要なアクションを見つけます。
多くの実際的な応用問題に関して最初に思い浮かぶのは、強化学習の意思決定システムのセット全体です。しかし、実際のアプリケーション シナリオでは、強化学習を使用する際の最大の課題は、実際のシナリオに適したシミュレータがあるかどうかです。シミュレータ自体の構築は困難な作業です。もちろん、Alphago チェスのようなゲーム シナリオの場合、ルールは一般に比較的閉じられており、シミュレータを構築するのは比較的簡単です。しかし、ビジネスや実生活では、そのほとんどが無人運転などのオープンなシナリオであり、非常に完成度の高いシミュレーターを提供することは困難です。シミュレーターを構築するには、シナリオを非常に深く理解する必要があります。したがって、シミュレータ自体を構築することは、意思決定や予測を行うことよりも難しい問題である可能性があり、これが強化学習の限界です。
4. 一般的な意思決定方法 2: 予測を使用して意思決定を行う
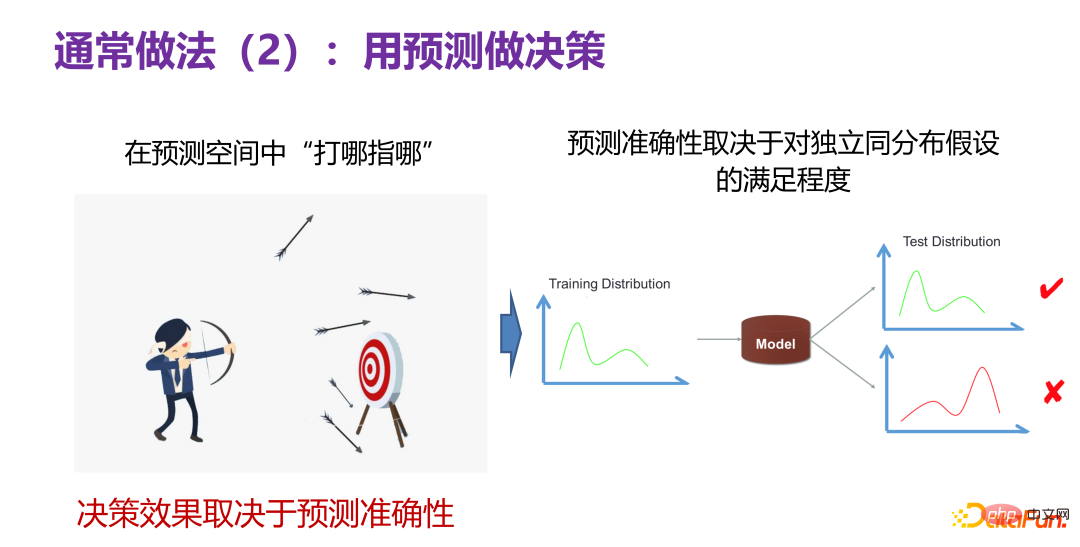
もう 1 つの一般的な方法は、予測を使用して意思決定を行うことです。つまり、現時点ではどのような判断が良いのかは分かりませんが、予測子があれば、下図の左側に示すように、予測空間の「どこを指すのか」を予測できるということです。矢を射る人は、最初に数本の矢を射ることができます。的を射るときに、どの矢がよりよく射れるかがわかれば、その矢の主要な動作を使用して適切な決定を下すことができます。このような予測空間があれば、予測を使用して意思決定を行うことができます。
しかし、意思決定の効果は、予測が正確であるかどうか、予測空間の精度に依存します。予測空間では 10 回ヒットしましたが、実際の生活や製品に適用するとヒット数は 0 となり、予測空間が不正確であることがわかります。これまでのところ、予測タスクで最も信頼性の高いシナリオは、独立した同一の分布、つまりテスト分布とトレーニング分布が同じ分布であるという仮定の下で予測を行うことです。現在、多くの強力な予測が存在します。モデル(予測モデル) )実践的な問題をうまく解決できます。このことから、予測精度が良いかどうかは、実際のシナリオにおけるテスト データとトレーニング データの分布が独立した同一の分布を満たすかどうかにある程度依存します。
#予測の精度について引き続き深く考えてください。予測モデルが履歴データ P(X,Y) に基づいて構築されていると仮定し、いくつかの異なる主要な動作によってもたらされるメリットを調査します。つまり、前述のように複数の矢を射て、どれが最も多くのターゲットを持っているかを確認します。細かく分けると、2つの異なる状況に分けられます。
最初のカテゴリは、特定の決定変数の値を最適化することです。入力変数 X のどれがより適切な決定変数であるかが事前にわかっている場合、たとえば、値が取得された後に何が起こるかにおいて価格が決定変数である場合。
もう 1 つのタイプは、最適な決定変数を探し、その値を最適化するものです。予測モデルによって予測された値のどれが良いかは、事前には分かりません。
この前提に基づくと、決定変数の値を変更すると、実際には P(X) が変更されます。つまり、P(X) が変更されれば、P(X,Y) も確実に変更されます。この場合、独立した同一の分布という仮定自体が無効となり、実際には予測が失敗する可能性が非常に高くなります。したがって、意思決定問題が予測的な方法で解決される場合、決定変数の値を変更すると必然的に分布シフトが生じるため、分布外一般化の問題が引き起こされます。分布の偏りの場合、どのように予測するかは分布外一般化の予測問題の範疇に属し、今日の記事の主題ではありません。分布外一般化の予測問題が 予測フィールドで解決できる場合、予測を使用して意思決定を行うことも実現可能なパスの 1 つです。ただし、現在、ID (In-Distribution) または直接予測 (直接予測) 手法を使用して意思決定を行うことは、理論的には無効であり、問題があります。
#5. 意思決定の問題は因果関係のカテゴリです
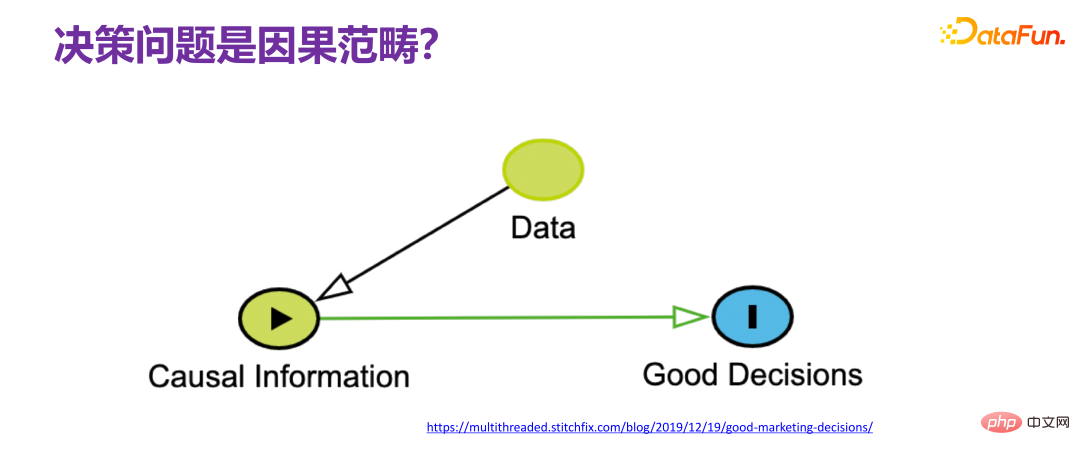
##意思決定の問題について話すとき、私たちは通常、意思決定の問題を原因と結果に直接結びつけますが、いわゆる意思決定とは、どのような意思決定を行うかということを指します。因果関係の連鎖があることは明らかです 学界の多くの学者は、意思決定の問題を解決するには因果関係を避けることはできない、つまり、観察可能なデータから十分な因果関係の情報を取得する必要があるというのがコンセンサスです関連する因果メカニズムを理解します。)、因果メカニズムに基づいて最終的な意思決定のための戦略をいくつか設計します。その全過程を完全に理解できれば、因果関係のメカニズム全体を完全に復元できるので、意思決定は実際には神の視点を持つのと同じであり、意思決定に何の困難もありません。
#6. 意思決定の枠組みの説明
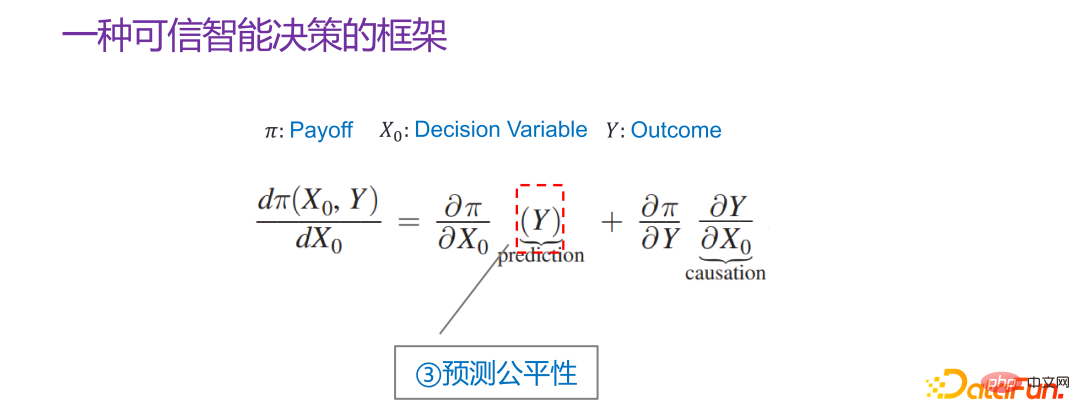
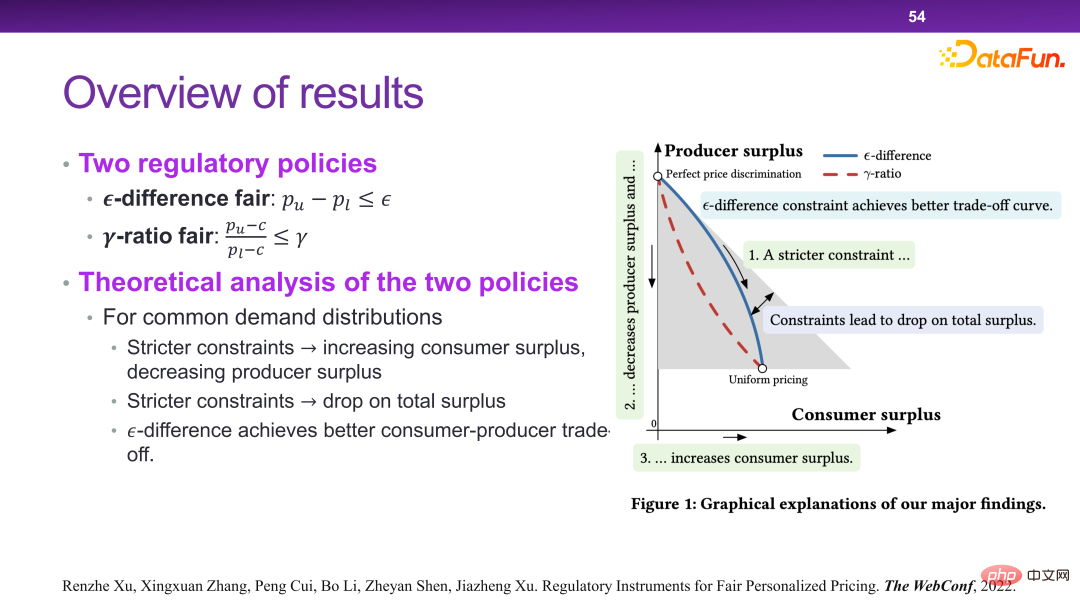
## 2015 年には、Jon Kleinberg が次のような論文を発表しました。意思決定の問題は因果メカニズムによってのみ解決できるわけではありません。つまり、すべての意思決定問題が解決するために因果メカニズムを必要とするわけではありません。ジョン・クラインバーグはコーネル大学の著名な教授で、有名なヒットアルゴリズムや6度スタイル理論などはすべてジョン・クラインバーグの研究成果です。ジョン・クラインバーグは、2015 年に意思決定の問題に関する論文「予測政策の問題」を発表しました[1]。彼は、一部の意思決定の問題は予測戦略の問題であると信じており、この主張を証明するために、以下の図に示すような意思決定の枠組みを説明しました。
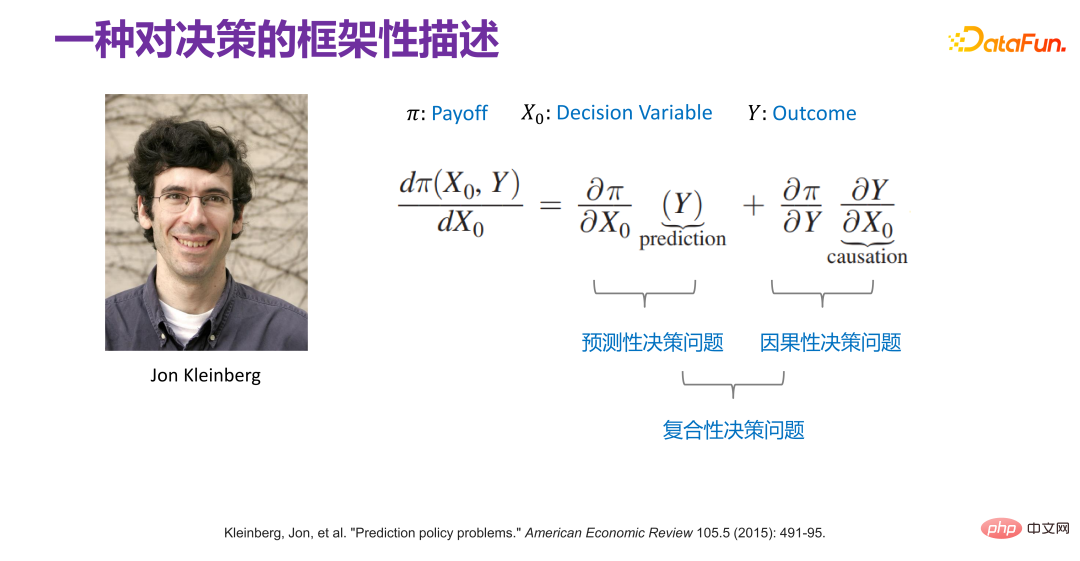
Π は利得関数、#x 0 は決定変数 (Decision Variable)、Y は決定変数による結果 (Outcome) , Π は実際には #0 と Y の関数です。次に、xx0 がどのように変化するか、Π が最大であり、そのような導関数を見つけることができます: 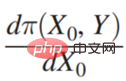 次に、それを展開すると次のようになります。
次に、それを展開すると次のようになります。 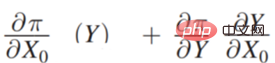 は、Y と
は、Y と
#7. 意思決定シナリオの 2 つのケース

上の図に示すように、2 つの意思決定シナリオがあります。x#0 は決定変数であり、 2 つのシナリオはそれぞれ異なります。
# まず、左側のシーンのケースを見てください。傘を持っていく必要があるかどうかは、雨が降るかどうかとは関係ありません。つまり、#0 は Y には関係ないので、傘を持ってください。 to 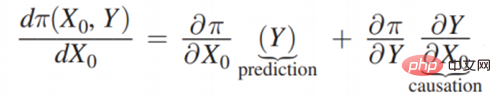 では、つまり:
では、つまり: 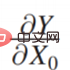 が 0 の場合:
が 0 の場合: 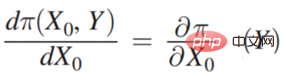 この場合、最終的な収入は、雨が降ります。したがって、この例は明らかに予測による決定です。
この場合、最終的な収入は、雨が降ります。したがって、この例は明らかに予測による決定です。
#右のケースは、あなたが首長である場合、雨乞いのために誰かに踊ってもらうためにお金を払いたいかどうかは、実際には「踊ること」に大きく依存するということです。神様に』 『雨乞いはできるのか、因果関係があるのか。式の右側の  で、雨が降るかどうかを予測できる場合は、次のようになります。は 0、つまり収入 (雨が降るかどうか) と決定変数 (ジャンプするかどうか) の間には実際には関係がありません。したがって、これは予測的な決定ではなく、純粋に因果的な決定です。
で、雨が降るかどうかを予測できる場合は、次のようになります。は 0、つまり収入 (雨が降るかどうか) と決定変数 (ジャンプするかどうか) の間には実際には関係がありません。したがって、これは予測的な決定ではなく、純粋に因果的な決定です。
上記の 2 つの実際の意思決定ケース シナリオを通じて、意思決定の問題は、予測的意思決定と因果的意思決定の 2 つのカテゴリと、意思決定の枠組みに分類できます。 Jon Kleinberg が提供した問題の作成。これも意思決定の区分化を示す良い例です。
8. 意思決定の複雑さ

Jon Kleinberg の論文1 つの観点として、予測的意思決定の問題では、予測が正しいかどうかだけが問題であり、因果関係のメカニズムは必ずしも必要ではありません。予測モデルは意思決定のシナリオで非常に役立ち、意思決定の優れた表現力を備えています。 -問題を起こす:彼らは多くの状況を一つにまとめることができます。しかし、意思決定の実際の複雑さは、予測シナリオについてのこれまでの理解を超えています。ほとんどの場合、予測問題を解決するとき、私たちは最善を尽くして (ベスト エフォート)、最終的な精度を向上させることを期待して、より複雑なモデルとより多くのデータを使用しようとします。つまり、ベスト エフォート モデル (ベスト エフォート モデル) です。
#しかし、意思決定のシナリオには予測よりもはるかに多くの制約があります。意思決定は実際にはラストマイルであり、最終的な決定はあらゆる側面に影響を及ぼし、多くの利害関係者に影響を与え、非常に複雑な社会的および経済的要因が関与します。例えば、同じローンにおいて、性別や地域が異なる人々に対する差別がないかどうかは、アルゴリズムの公平性の典型的な問題です。ビッグデータは身近なもので、同じ商品でも人によって価格が異なることも問題です。近年、比較的狭い範囲でユーザーの興味や関心に基づいてユーザーを継続的に推薦し、情報コクーンルームを形成する情報コクーンについては誰もが深く理解しています。このままでは、悪い文化的、社会的現象が現れるでしょう。したがって、意思決定を行う際には、信頼できる決定を下すためにより多くの要素を考慮する必要があります。
#9. 信頼できるインテリジェントな意思決定のためのフレームワーク
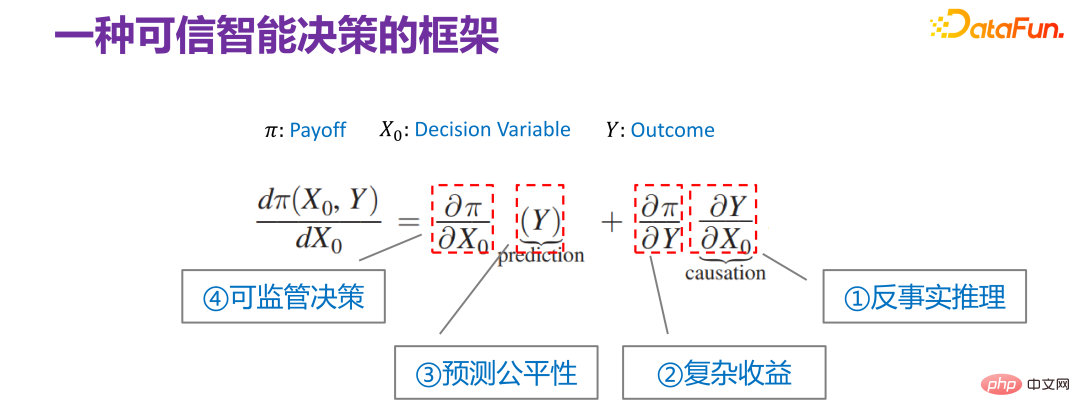
##ジョン・クラインバーグによって与えられた意思決定の問題の枠組みを、意思決定の信頼性の観点から解釈し続けます。ジョン・クラインバーグ自身が、意思決定問題に対する予測モデルの有効性を主張するためにこの意思決定問題フレームワークを提案しましたが、実際には、意思決定問題フレームワークの含意は非常に豊富です。意思決定の問題のフレームワーク。
まず、 は一番右の項目です。いくつかの反論 事実の現象は、何か 推論は因果推論の中核部分であり、もちろん、ユダヤ・パールが与えた枠組みでは、それは 3 番目のはしごです。反事実推論にはさまざまな理解と説明がありますが、ここで説明する反事実推論は、当面は合理的であると考えられます。 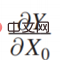
3 番目の項目 # は Y です。中心的なタスクは予測を行うことですが、予測が意思決定に使用され、意思決定シナリオが個人の信用に影響を与えるかどうか、大学入学試験に合格するかどうか、囚人が釈放されるかどうかなど、社会的性質のデータです。これらすべてのいわゆる予測タスクでは、予測が公平である必要があります。性別、人種、アイデンティティなどの次元変数を予測に使用します。
4 番目の項目 は、 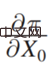
この意思決定問題のフレームワークには、さまざまなレベルのシナリオが含まれており、上記の 4 つの異なるサブ方向性があると考えることもできます。しかし、一般に、上記の 4 つのサブ方向は、信頼できる意思決定に非常に関連しています。つまり、キャラクターが信頼できるものであることを保証したい場合は、要素のあらゆる側面を考慮する必要があります。しかし、一般的に言えば、それはジョン・クラインバーグによって与えられた枠組みを使用して統一的に表現することができます。
#以下では、信頼できるインテリジェントな意思決定フレームワークの下で、反事実的推論、複雑な利益、予測的公平性、規制上の意思決定という 4 つのサブ方向性を紹介します。 。
2. 信頼できる知的な意思決定における反事実推論
まず、信頼できる知的な意思決定に関する情報を紹介します。フレームワークの作成 反事実推論に関するいくつかの考えと実践。

1. 反事実的推論

反事実推論には 3 つのシナリオがあります。
1 つ目は、戦略の平均効果評価 (オフポリシー評価) です。特定のポリシーについては、AB テストのコストが高すぎるため、AB テストを実行したくありません。したがって、オフライン データに対するポリシーの効果を評価することは、母集団全体をテストすることと同じです。または、すべてのサンプルを評価します。すべてのユーザーグループに対する総合的な効果評価。 2つ目は、戦略の個別効果評価(反事実予測)であり、プラットフォーム全体の戦略ではなく、一定の介入を行った上で、戦略の効果を個人レベルで予測するものです。個人にとっては、どのような効果があるでしょうか。 3 つ目は政策の最適化、つまり個人にとって最良の効果をもたらす介入を選択する方法です。個別効果予測とは異なり、個別効果予測は、まず介入方法を知り、その後介入後の効果を予測するものであり、戦略最適化は、事前に介入方法を知るのではなく、介入後に最良の効果を達成する方法を見つけることです。
#2. 戦略平均効果評価# (1) 戦略平均効果評価の問題枠組みの概要
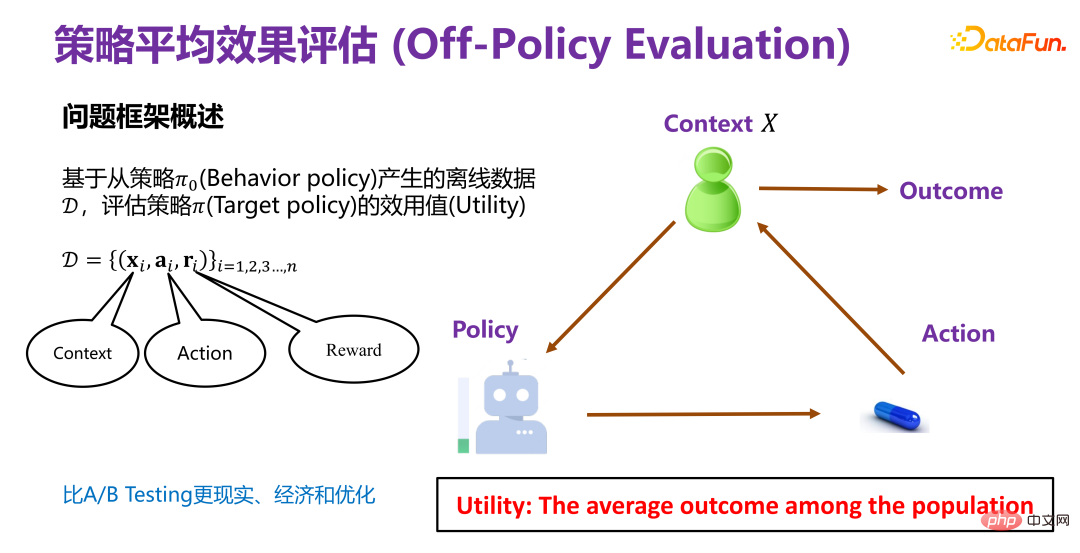
0 に基づいています。 (行動政策)は、政策Π(対象政策)の利用価値(Utility)を評価するためのオフラインデータDを生成する。 Π0 は、既存のレコメンデーション システムで使用されているレコメンデーション戦略などの既存の戦略です。 #既存の戦略に基づいて生成されたオフライン データ D には、上の図に示すように、少なくとも 3 つの次元が含まれています。 ## i は、レコメンデーション システムにおけるユーザーや製品の属性などの背景情報 (コンテキスト) です。a#i システム内の特定の製品がユーザーに公開されているかどうかなどの動作です。ri は最終結果 (報酬) です。ユーザーが最終的に推奨システムで製品をクリックしたか、購入したかどうか。 #過去のデータに基づいて、新しいポリシー Π (ターゲット ポリシー) の利用価値 (Utility) を評価します。全体的な枠組みとしては、特定の状況において、特定の戦略 (政策) には対応する行動または介入変数 (治療) があり、この介入変数 (治療) がトリガーされると、対応する結果が生成されます。このうち利用価値(Utility)は前述の利得であり、単純化を前提にすると全利用者が生み出す成果の合計、つまり平均的な効果となります。 # (2) 戦略の平均効果を評価するための既存の手法 もう 1 つの方法は因果推論に基づいており、傾向スコアを導入しています。中心となるアイデアは、元の戦略での 3 つ組 (xi、ai、ri) を新しい戦略で使用し、どのような重みを使用するかということです。最終結果を重み付けします。重みは、新しい戦略の下での xi のエクスポージャの確率 (ai) と、xi が与えられた元の戦略の下での xi のエクスポージャの確率 (ai) との比である必要があります。つまり、新しい戦略の下では、結果は a に対応します。トリプレット 重み付けのための係数。このアプローチの最も難しい部分は、元の戦略では、xi が与えられた後、ai に対応する確率分布が実際には未知であることです。これは、元の戦略が非常に複雑であるか、複数の戦略の重ね合わせである可能性があるためです。対応する分布を正確に記述する必要があるため、推定する必要がありますが、推定が正確であるかどうかの問題があり、推定値が分母にあるため、分布のばらつきが発生します。メソッド全体が非常に大きくなります。また、傾向スコア(傾向スコア)の推定を利用する際には、傾向指数(傾向スコア)の関数が線形か非線形であるか、それがどのような形であるか、推定が正確であるかという問題があります。 、など。 # # 従来の戦略平均効果評価手法は結果予測手法(直接法)に基づいており、新しい方針(ポリシー)の下でxiが与えられた場合、対象者に対して、公開するか公開しないことを推奨するか、つまり、対応する行動が推奨されます。エンドユーザーが購入するかクリックするかという露出が最終的な結果 (報酬) となります。ただし、報酬は実際には履歴データから取得される予測関数であることに注意してください。過去のデータにおける x、a、r の結合分布は、実際には Π0 で生成されました。今度は、Π によって生成されたデータ分布が変更され、Π0 で生成された結合分布予測モデルが使用されます。モデル) を使用して予測を行います。これが OOD (Out-of-Distribution) 問題であることは明らかです。後で OOD 予測モデルを使用すると、データ分散オフセット問題は軽減される可能性があります。ID (In-Distribution) 予測モデルを使用すると、原則として、間違いなく問題になります。これは、戦略の平均有効性を評価する伝統的な方法です。

## 因果関係の直接交絡因子バランスを利用して、サンプルを直接重み付けする方法が提案されているため、重み付け後の分布 P(X|# は対応する各アクション グループ内) が保証されます。 i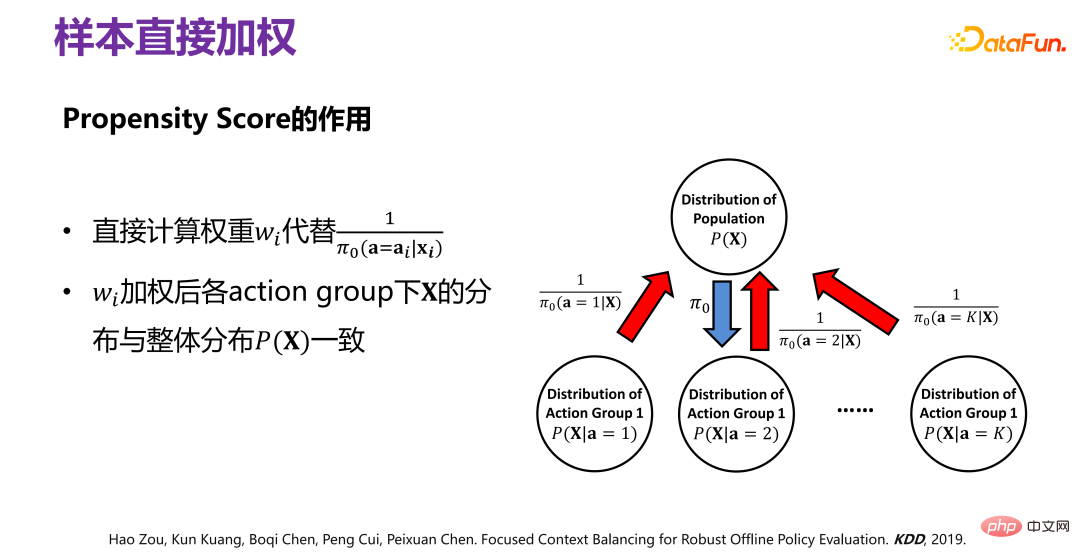 ) は全体として P(X) と一致します。
) は全体として P(X) と一致します。
#履歴データは、指定された Π0 で生成されます。理由を削除するには Π0 分布によって生じる偏差(バイアス)の具体的な方法は上図に示されており、元のデータ分布 P(X) は、Π0 の作用の下で、P を変更するのと等価です。 ( X) はいくつかの部分分布 P(X|a=1)、P(X|a=2)、P(X|a=3)、...、P(X|a=K)、に分割されます。つまり、P(X) に対応する異なる行動のサブセットは不偏分布です。各行動グループには Π0 によって引き起こされるバイアスがあります。バイアスを除去するには、次のようにします。 Π0 によって生成された履歴データを再重み付けすると、重み付け後のすべての部分分布は元の分布 P(X) に近くなります。つまり、サンプルは直接重み付けされます。
過去のデータに基づいて新しい戦略の最終的な効果を予測するには、2 つの手順が必要です。最初のステップは、前述のようにサンプルに直接重み付けを行うことによって、元の戦略 Π0 によって引き起こされたバイアスを除去することです。第 2 ステップは、新しい戦略 Π の効果を予測すること、つまり、新しい戦略 Π によって引き起こされる偏差に基づいて最終的な効果を推定することであるため、新しい戦略 Π によって引き起こされる偏差を追加する必要があります ######### #######################################したがって: 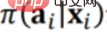 # このうち、
# このうち、
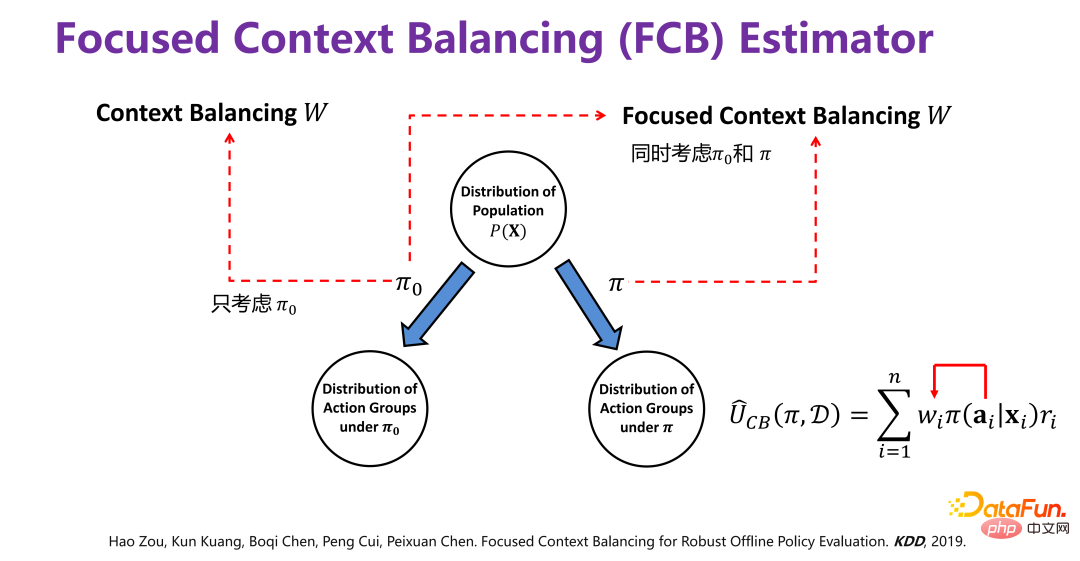
## を削除する最初のステップに相当します。
偏差: 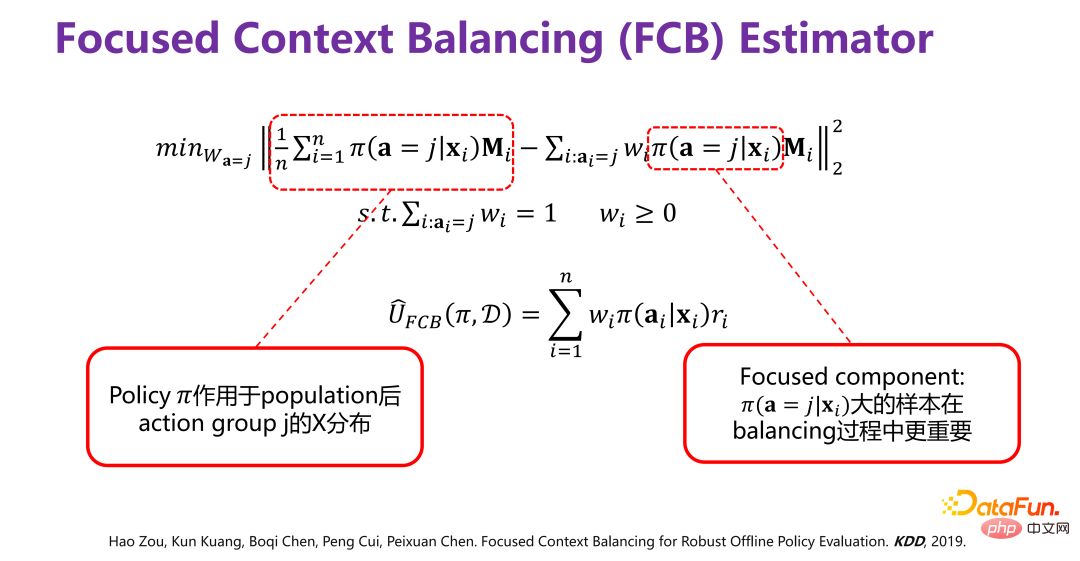
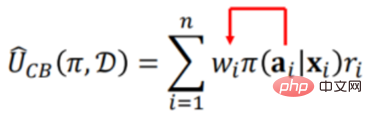
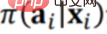 #3. 戦略個別効果予測
#3. 戦略個別効果予測
# (1) 戦略個別効果予測の全体説明
戦略的個人効果予測とは、個人の異質性を十分に考慮し、個人に対して差別化された介入を直接実施すること、つまり個人の意思を尊重し、個人ごとに異なる介入を実施することです。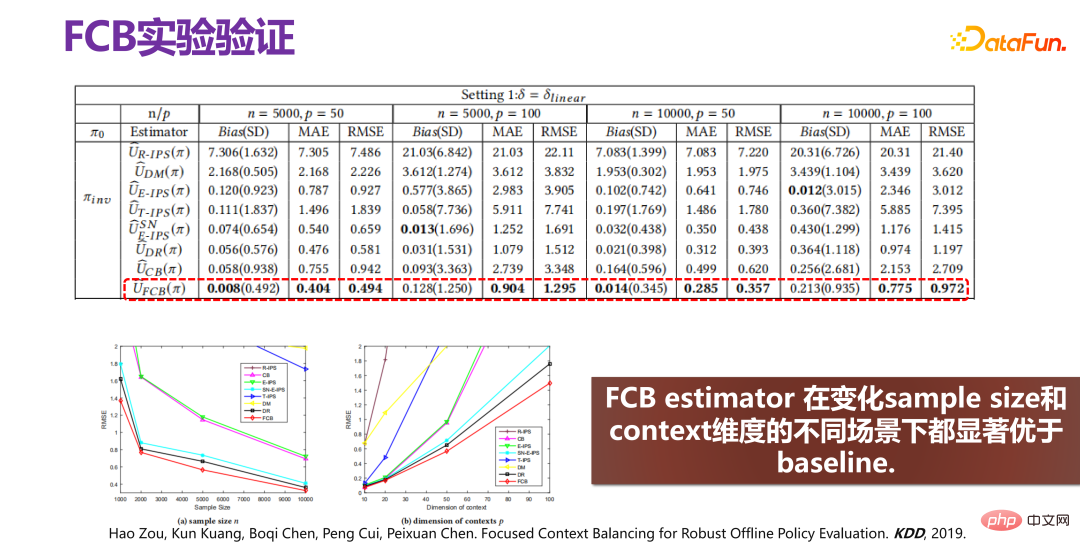
# (2) 既存手法の限界
#戦略の個々の効果を予測するために一般的に使用される方法は、過去の観察データに基づいて、個人を直接予測してモデル化することです:
次に、反事実予測モデル 
を取得するようにトレーニングします。つまり、X と T が与えられると、実際の効果 y がどのようになるかを合理的かつ正確に予測できます。

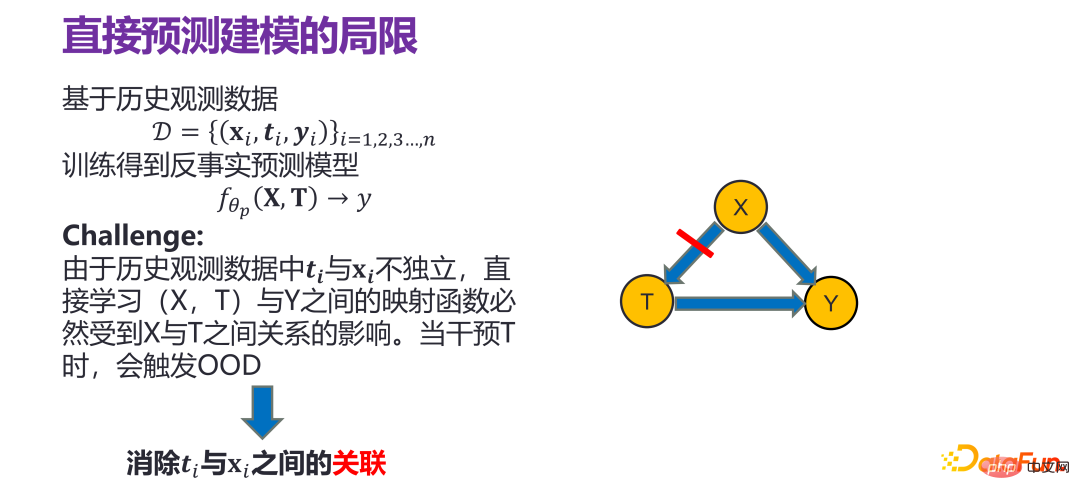
#履歴データの分布の下で回帰分析または同様のモデルを直接実行する場合は、はい問題のある。過去の観測データの ti と xxi は独立していないため、(X, T) と Y の間の直接マッピングを直接学習します。関数は #i 間の関係の影響を受ける必要があります。たとえば、ti は 0 に等しい必要があります。T を介する場合、たとえば t i は変更する必要があります。 1 になると、実際には元の履歴分布に従いません。これは、履歴データ分布に基づいて構築された ID (分布内) 予測モデルが無効であることを意味し、トリガーされます。 OOD (配布外)。 したがって、いわゆる予測モデルを構築するときは、X と T の間の相関を排除し、X が Y と Y に与える影響を推定する必要があります。 T が Y に与える影響 (この場合、T が介入または変更された場合の影響) は、Distribution の問題とは関係がありません。
従来のアプローチは、サンプルの再重み付け (Sample Re-weighting) 方法を使用することです。 X と T の間の関連性を除去するには、(1) 逆傾向スコア重み付け、(2) 変数バランスの 2 つの方法があります。ただし、これらの方法には制限があります。単純なタイプの介入変数 (治療) シナリオ、バイナリ値または離散値にのみ適しています。レコメンドシステムなどの実際のアプリケーションシナリオでは、介在変数(扱い)が高次元でユーザーに製品が推奨されますが、推奨されるのはバンドル、つまり多数の製品から推奨されます。介在変数 (治療) の次元が非常に高い場合、従来の方法を使用して最初の介在変数 (生の治療) と交絡変数 (交絡因子) X を直接相関させることは非常に複雑であり、サンプル空間でさえもサポートするには十分ではありません。高次元、介在変数 (治療)。

高次元介在変数(治療)が低次元の潜在変数構造を持っていると仮定した場合、つまり高次元介在変数(治療)は原理的にランダム生成されないたとえば、レコメンドシステムでは、与えられたレコメンデーション戦略によって推奨される製品バンドルには、製品と製品の間にさまざまな関係があり、低次元の隠れた変数構造、つまり推奨製品リストが存在します。いくつかの要因によって決定されます。
高次元の介在変数 (処理) の下に潜在変数 z がある場合、問題は実際に x と z の関係に変換できます De -相関、つまり潜在的要因との非相関。このようにして、限られたサンプルスペースでバンドル処理を実現できます。 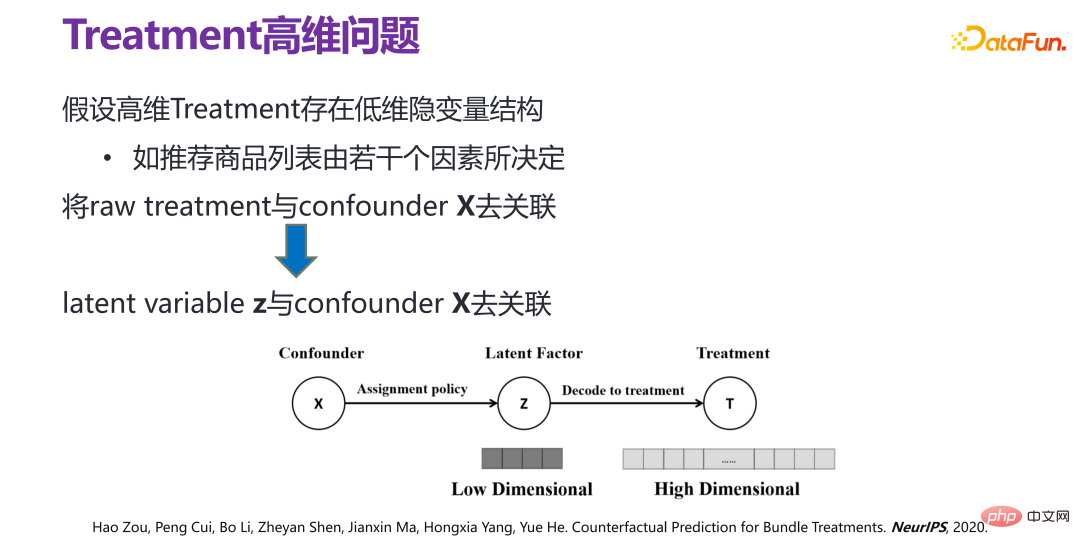
そこで、新しい手法 VSR が提案されます。 VSR法では、最初のステップは、高次元介入変数(治療)の潜在変数z(潜在変数z)を学習すること、つまり、学習に変分オートエンコーダ(VAE)を使用することです。次に、重み関数 w ( x, z) を使用して、サンプルの再重み付けを通じて x と z の相関を取り除き、最後に、再重み付けされた相関分布の下で回帰モデル (回帰モデル) を直接使用して、戦略の個々の効果についてのより理想的な予測モデルを取得します。
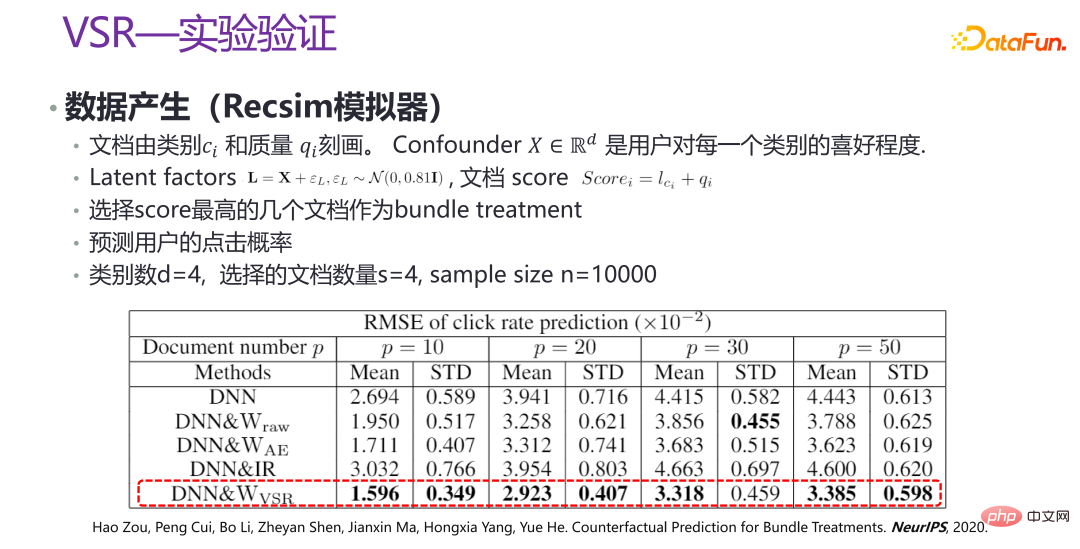
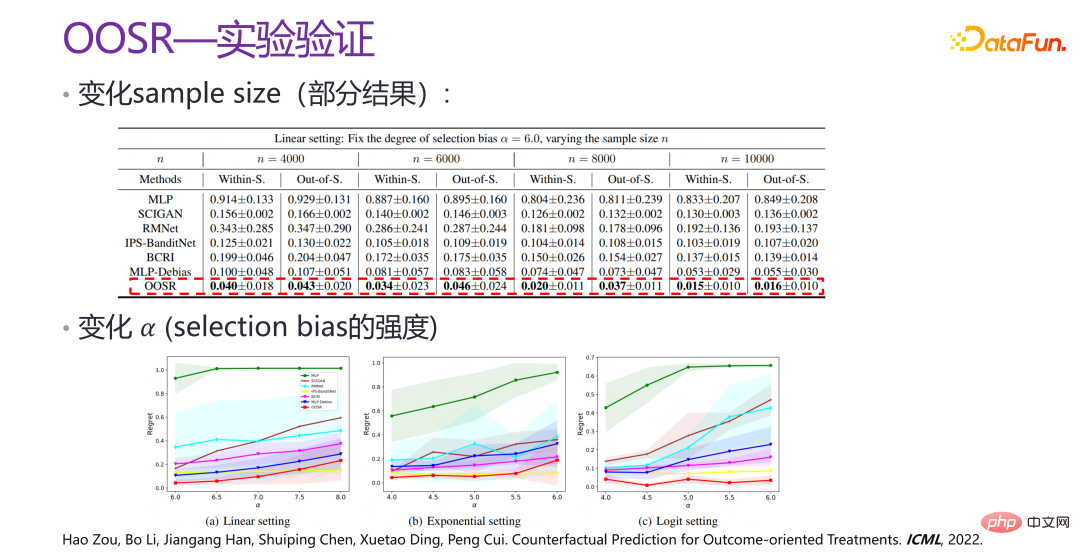
上の写真は、新しい機能の実験です。 VSR 検証方法は、検証のために Recsim シミュレーターを通じていくつかのデータを生成し、いくつかのシナリオで人工的にシミュレートされたデータを生成します。 p の異なる値の下で、VSR のパフォーマンスは比較的安定しており、他の方法と比較して大幅に改善されていることがわかります。関連論文は NeurIPS 2020 に掲載されました [3]。
#4. 戦略の最適化
#戦略の最適化前の 2 種類の予測評価とは根本的に異なります。予測評価とは、最終的な結果を予測するために、事前に戦略(方針)や個別の介入(個別治療)を与えることです。戦略の最適化 (戦略学習とも呼ばれます) の目標は 1 つだけです。それは、より大きな結果を得ることです。例えば、収入を増やしたい場合、どのような介入を行うべきか。
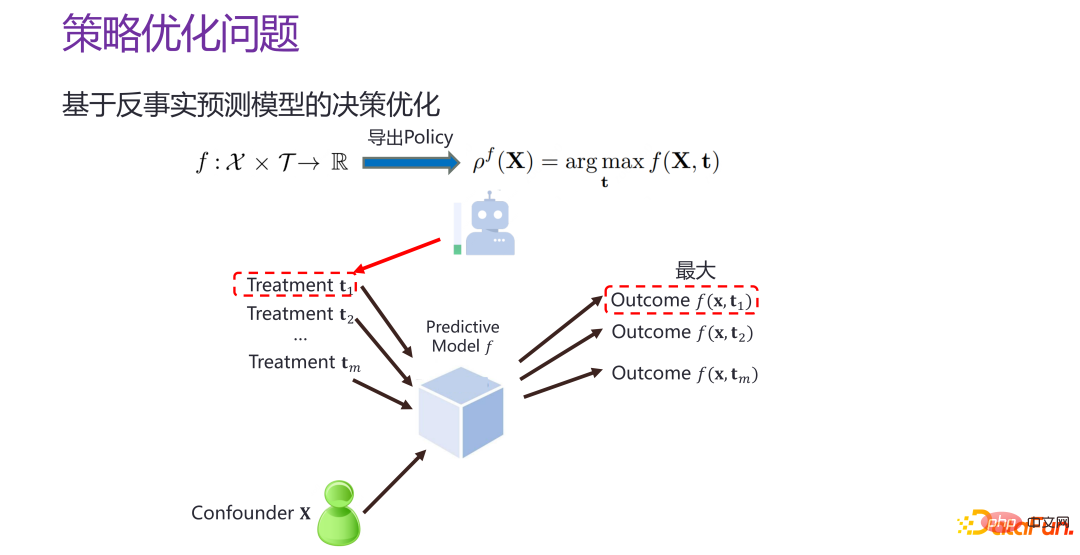
#反事実的な個人レベルの予測モデル f が存在するとします。戦略的個人効果予測モデル f、つまり xxi と ti が与えられた場合、対応する結果を推定できます。 T がトラバースされ、t が任意の値を取る場合、f の値が最大になります。これは、より良い予測空間を構築し、その予測空間内で「どこにヒットするかをターゲットにする」ことに相当します。
#しかし、政策最適化問題を政策の個々の効果の予測モデルの構築に還元することには問題があります。戦略の個別効果予測の目標は、上で述べたように、実際には、反事実の予測状況と実際の状況との間の誤差が可能な限り小さいことを望み、与えられた介入と同等であり、与えられたすべての介入について比較することを望んでいます。正確な。戦略最適化の目標は、pf から離れた点を見つけることです。現実の状況 神の視点から見ると、最適な意思決定の結果間の距離は小さいほど良いのであり、空間全体における個々の戦略の効果を予測するのではなく、最適点に近い領域が予測できるかどうかが問題となる見つかるかどうか、そしてそれを正確に予測できるかどうか、最高のポイントです。戦略最適化と戦略個別効果予測は目的が異なり、明らかな違いがあります。

上記の事例図に示すように、横軸はさまざまな介入 (治療)、緑の線は神の観点から見た実際の関数であり、特定の介入の下での実際の結果を反映しており、赤の線と青の線は 2 つの予測モデルの下での結果を反映しています。戦略の個別の効果予測を評価する観点からは、青線が赤線よりも優れていることは明らかであり、青線と緑線の全体的な偏差は、赤線と緑線の全体的な偏差よりもはるかに小さいです。緑の線。しかし、最適な意思決定の観点から見ると、神の視点から見た赤い線の最適な結果は緑の線の最適な結果に近く、対応する介入もより近くなりますが、青い線は明らかに遠いです。したがって、より優れた戦略個別効果予測モデルが必ずしも最適な決定につながるとは限らず、実際のシナリオではデータ量が不足していることが多く、空間全体で最適化するには、結果の観点からのみ最適化を実行する方がよいでしょう。サブエリアで最適化を行う場合、最適化の効果と強度は異なります。

したがって、より良い結果予測と介入領域を強化することを目的として、戦略的最適化の新しい手法である OOSR が提案されています。空間全体を最適化するのではなく、最適化の取り組みを強化します。したがって、最適化を実行し、結果指向の重み付けを行う場合、現在の介入が訓練された特定の最適解に近づくほど、最適化は強力になります。
#5.反事実的推論の要約
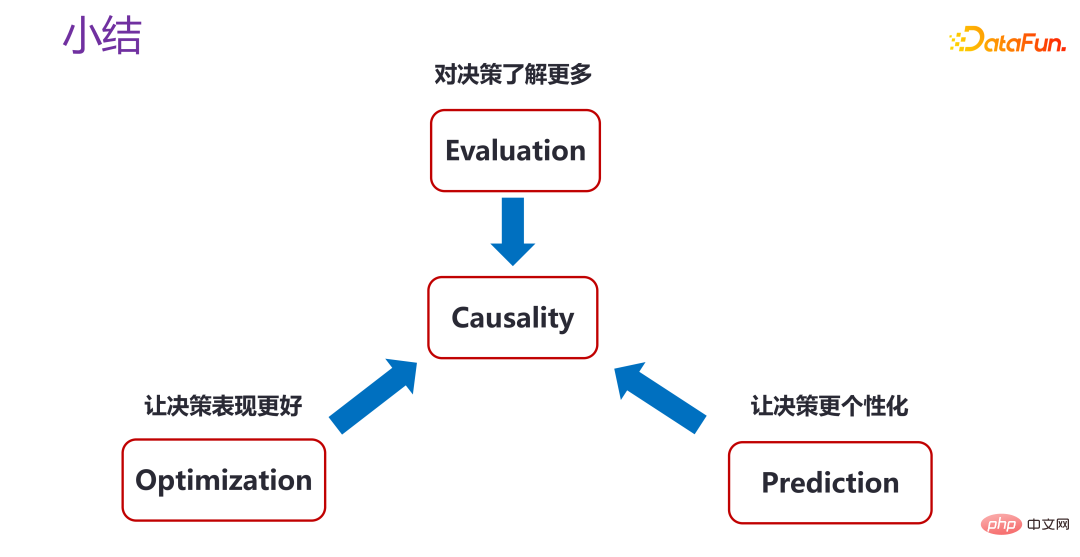 # #戦略の評価、戦略の最適化、または戦略の個別効果の予測のいずれであっても、私たちは実際に因果関係を使用して、意思決定についてさらに学習したり、意思決定のパフォーマンスを向上させたり、意思決定をよりパーソナライズしたりしています。もちろん、さまざまなシナリオに対して未解決の疑問がたくさんあります。
# #戦略の評価、戦略の最適化、または戦略の個別効果の予測のいずれであっても、私たちは実際に因果関係を使用して、意思決定についてさらに学習したり、意思決定のパフォーマンスを向上させたり、意思決定をよりパーソナライズしたりしています。もちろん、さまざまなシナリオに対して未解決の疑問がたくさんあります。
#3. 信頼できるインテリジェントな意思決定による複雑なメリット


## 複素リターンを研究しています: 
最終的な効果から判断すると、上の図に示すように、多くの現実のシナリオで収入が大幅に増加します。関連論文は NeurIPS 2022 に掲載されました [5]。 #4. 信頼できるインテリジェントな意思決定における予測的公平性

#予測が意思決定、特に社会志向の意思決定に参加する場合、予測の公平性が考慮されなければなりません考慮に入れてください。

# 公平性に関しては、従来の方法は DP と EO であり、これらの方法では次の合格確率が必要です。男性と女性が等しい、または男性と女性の予測能力が同じである、これは比較的古典的な指標です。しかし、DP と EO は公平性の問題を本質的に解決することはできません。
#たとえば、大学入学の場合、理論的には各学部の男子と女子の入学率は同じになるはずですが、実際にはそうなります。一般的に女子の入学率は低いことが知られていますが、これは実際には一種のシンプソンのパラドックスです。大学入学は本来公平であるが、DP 指標によって検出されると不公平とみなされ、実際、DP はあまり完璧な公平性指標ではありません。


#EO モデルの本質、性別は意思決定に参加しますが、不公平なシナリオでは、男性と女性の両方にとって完璧な予測因子が存在する場合、それは公平であると見なされます。これは、EOの識別率が不十分であることを示しています。

条件付き公平性の概念は 2020 年に提案されました。条件付き公平性は、最終結果が機密属性から独立していることを完全に保証するものではありませんが、特定の公平性変数が与えられた場合、最終結果が機密属性から独立している場合、最終結果は公平であると見なされます。例えば、専攻選択は学生の主観的な自発性によって決定できるため、公平かつ公正な変数であり、公平性の問題はありません。
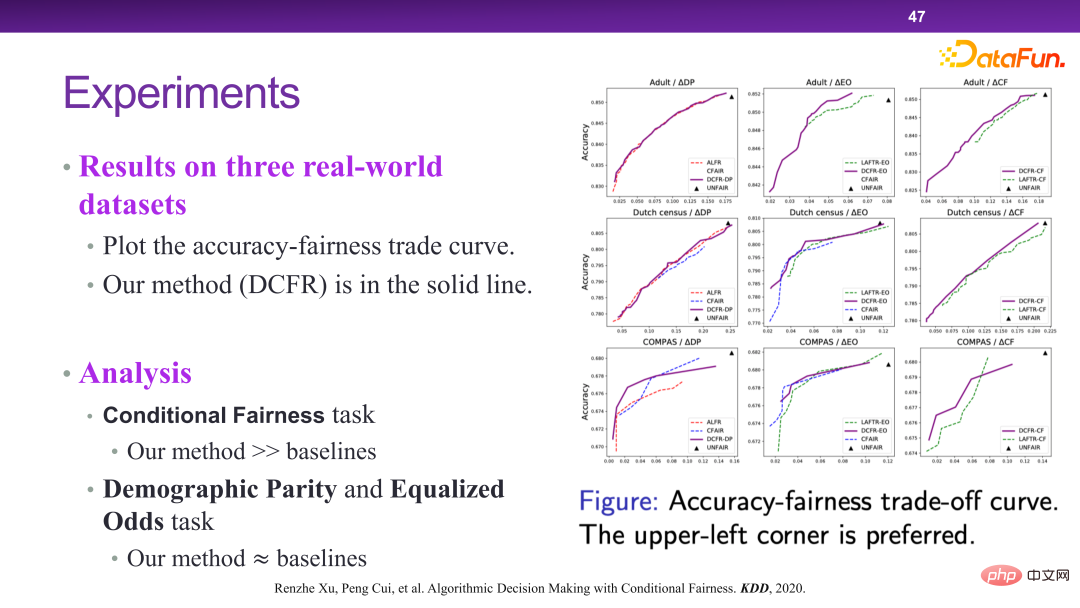
#これにより、多くのメリットがもたらされます。予測の観点から見ると、実際には公平性と予測の間にはトレードオフの関係があり、公平性の要件が強くなるほど、利用できる予測変数は少なくなります。例えば、EO の枠組みでは、性別から結果の意思決定までのリンク上にある変数は使用できませんが、使用した場合、実際には予測効率は非常に高い変数が多くありますが、予測はできません。ただし、条件付き公平性では、公平性変数が指定されているため、リンク上にあるかどうかに関係なく、予測効率が利用可能であることが保証されます。#このフレームワークの下で、次の 3 つの図に示すように、DCFR アルゴリズム モデルが設計および提案されます。


下の図は、DCFR アルゴリズムの実験的検証を示しています。全体として、DCFR アルゴリズムは予測と公平性の間でより良い妥協点を達成することができ、パレート最適性の観点からは、左上の曲線の方が実際には優れています。関連論文は KDD 2020 に掲載されました [6]。
##5. 信頼できるインテリジェントな意思決定における規制上の意思決定
最後に、信頼できるインテリジェントな意思決定には監督上の決定があります。

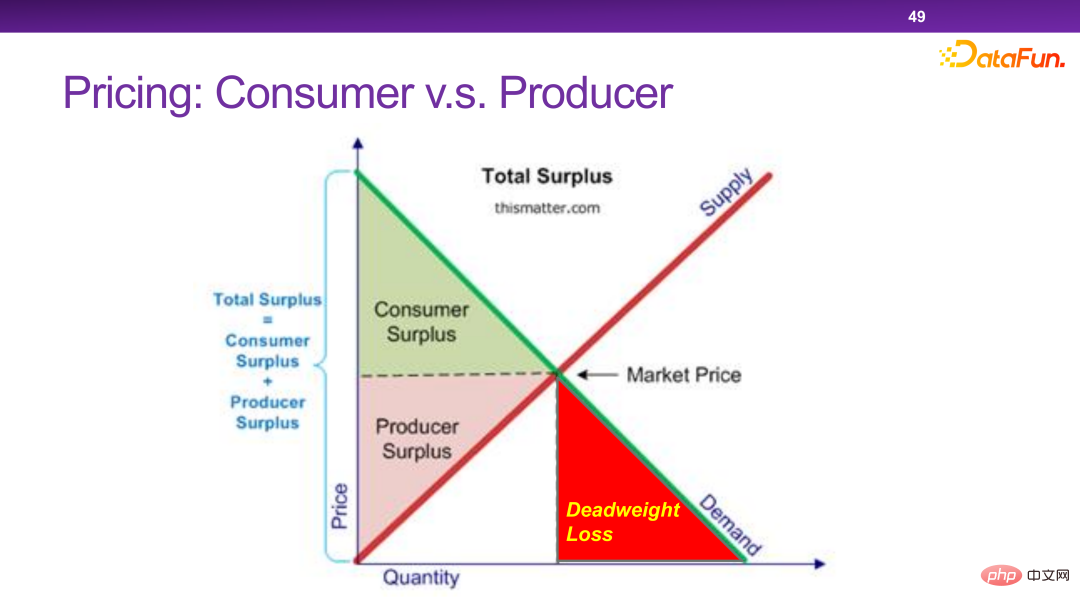
今のプラットフォームには、パーソナライズされた価格設定メカニズムが多数あります。本質的に、パーソナライズされた価格設定は、社会の全体的な効率と全体的な余剰を最大化することができます。しかし、極端な場合には、販売者はユーザーに余剰を残さずにすべての余剰を持ち去ってしまいます。これは私たちが見たくないことです。
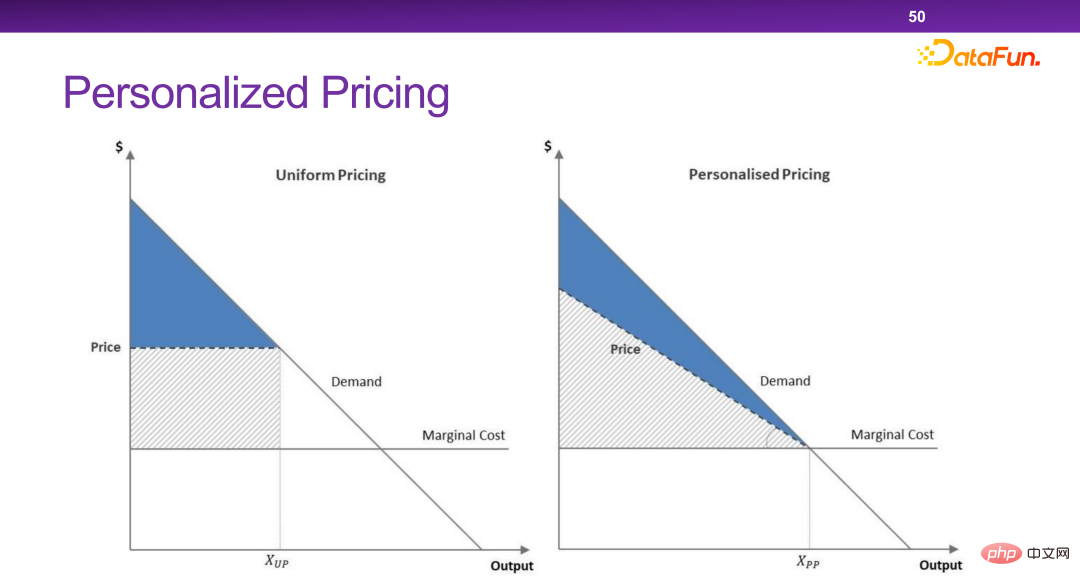



 #こちらこのシナリオでは、基本的に所得関数にいくつかの制約を追加することにより、意思決定を行う際に別のレベルの考慮が必要になります。したがって、このシステムでは、監視に関連するいくつかの戦略またはツールを追加できます。
#こちらこのシナリオでは、基本的に所得関数にいくつかの制約を追加することにより、意思決定を行う際に別のレベルの考慮が必要になります。したがって、このシステムでは、監視に関連するいくつかの戦略またはツールを追加できます。
#6. 信頼できるインテリジェントな意思決定の概要
#上記は、反事実的推論、複雑な利点、予測の公平性、および規制上の決定の各点における、信頼できるインテリジェントな意思決定の枠組みの下にあります。いくつかの試みをしました。全体として、意思決定の範囲は予測よりもはるかに広いです。意思決定の分野には、私たちの生活やビジネスに密接に関係しており、検討する価値のある未解決の問題がまだ多くあります。関連論文は WWW 2022 に掲載されました [7]。 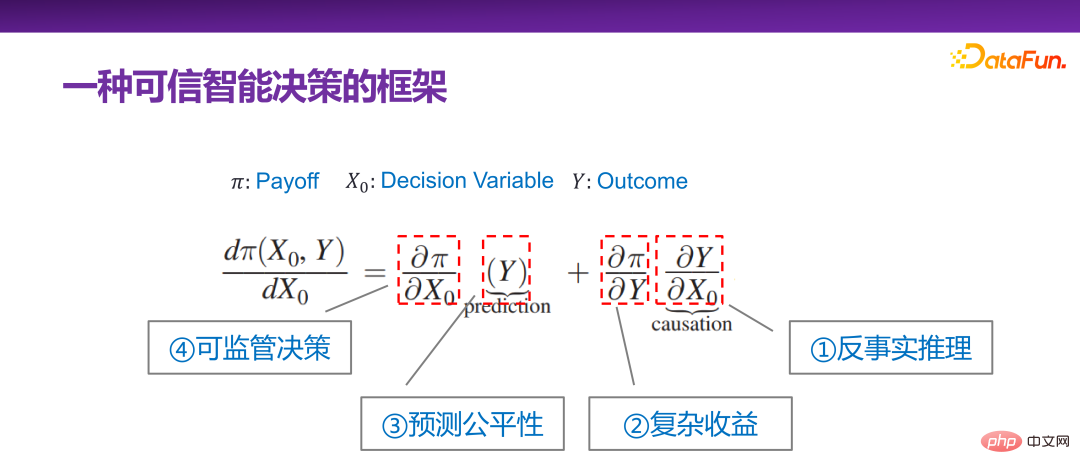
PS: この記事に含まれる多くの技術的な詳細については、信頼できるインテリジェントの方向で Cui Peng のチームによって発行された最近の論文を参照してください。意思決定。
7. 参考文献
[1] Jon Kleinberg、Jens Ludwig、Sendhil Mullainathan、Ziad Obermeyer. 予測ポリシー問題点。AER、2015 年。
##[2] Hao Zou、Kun Kuang、Boqi Chen、Peng Cui、Peixuan Chen. 堅牢なオフライン ポリシー評価のための集中的なコンテキスト バランシング. KDD、2019 年。
[3] Hao Zou、Peng Cui、Bo Li、Zheyan Shen、Jianxin Ma、Hongxia Yang、Yue He. バンドル治療に対する反事実予測。NeurIPS、 2020年。
[4] Hao Zou、Bo Li、Jiangang Han、Shuiping Chen、Xuetao Ding、Peng Cui. 結果指向の治療に対する反事実予測. ICML、2022 。
[5] Renzhe Xu、Xingxuan Zhang、Bo Li、Yafeng Zhang、Xiaolong Chen、Peng Cui. 複数購入による収益最大化のための製品ランキング. NeurIPS、 2022年。
[6] Renzhe Xu、Peng Cui、Kun Kuang、Bo Li、Linjun Zhou、Zheyan Shen、Wei Cui. 条件付き公平性を備えたアルゴリズムによる意思決定. KDD 、2020年。
[7] Renzhe Xu、Xingxuan Zhang、Peng Cui、Bo Li、Zheyan Shen、Jiazheng Xu. 公正な個別価格設定のための規制手段. WWW、2022.
以上が清華大学崔鵬氏: 信頼できるインテリジェントな意思決定のフレームワークと実践の詳細内容です。詳細については、PHP 中国語 Web サイトの他の関連記事を参照してください。

ホットAIツール

Undresser.AI Undress
リアルなヌード写真を作成する AI 搭載アプリ

AI Clothes Remover
写真から衣服を削除するオンライン AI ツール。

Undress AI Tool
脱衣画像を無料で

Clothoff.io
AI衣類リムーバー

AI Hentai Generator
AIヘンタイを無料で生成します。

人気の記事
ホットツール

メモ帳++7.3.1
使いやすく無料のコードエディター

SublimeText3 中国語版
中国語版、とても使いやすい

ゼンドスタジオ 13.0.1
強力な PHP 統合開発環境

ドリームウィーバー CS6
ビジュアル Web 開発ツール

SublimeText3 Mac版
神レベルのコード編集ソフト(SublimeText3)
ホットトピック
 7454
7454
 15
1375
52
77
11
14
9
15
1375
52
77
11
14
9

 Bytedance Cutting が SVIP スーパー メンバーシップを開始: 継続的な年間サブスクリプションは 499 元で、さまざまな AI 機能を提供
Jun 28, 2024 am 03:51 AM
Bytedance Cutting が SVIP スーパー メンバーシップを開始: 継続的な年間サブスクリプションは 499 元で、さまざまな AI 機能を提供
Jun 28, 2024 am 03:51 AM
このサイトは6月27日、JianyingはByteDanceの子会社であるFaceMeng Technologyによって開発されたビデオ編集ソフトウェアであり、Douyinプラットフォームに依存しており、基本的にプラットフォームのユーザー向けに短いビデオコンテンツを作成すると報告しました。 Windows、MacOS、その他のオペレーティング システム。 Jianyingは会員システムのアップグレードを正式に発表し、インテリジェント翻訳、インテリジェントハイライト、インテリジェントパッケージング、デジタルヒューマン合成などのさまざまなAIブラックテクノロジーを含む新しいSVIPを開始しました。価格的には、クリッピングSVIPの月額料金は79元、年会費は599元(当サイト注:月額49.9元に相当)、継続月額サブスクリプションは月額59元、継続年間サブスクリプションは、年間499元(月額41.6元に相当)です。さらに、カット担当者は、ユーザーエクスペリエンスを向上させるために、オリジナルのVIPに登録している人は、
 Rag と Sem-Rag を使用したコンテキスト拡張 AI コーディング アシスタント
Jun 10, 2024 am 11:08 AM
Rag と Sem-Rag を使用したコンテキスト拡張 AI コーディング アシスタント
Jun 10, 2024 am 11:08 AM
検索強化生成およびセマンティック メモリを AI コーディング アシスタントに組み込むことで、開発者の生産性、効率、精度を向上させます。 JanakiramMSV 著者の EnhancingAICodingAssistantswithContextUsingRAGandSEM-RAG から翻訳。基本的な AI プログラミング アシスタントは当然役に立ちますが、ソフトウェア言語とソフトウェア作成の最も一般的なパターンに関する一般的な理解に依存しているため、最も適切で正しいコードの提案を提供できないことがよくあります。これらのコーディング アシスタントによって生成されたコードは、彼らが解決する責任を負っている問題の解決には適していますが、多くの場合、個々のチームのコーディング標準、規約、スタイルには準拠していません。これにより、コードがアプリケーションに受け入れられるように修正または調整する必要がある提案が得られることがよくあります。
 GenAI および LLM の技術面接に関する 7 つのクールな質問
Jun 07, 2024 am 10:06 AM
GenAI および LLM の技術面接に関する 7 つのクールな質問
Jun 07, 2024 am 10:06 AM
AIGC について詳しくは、51CTOAI.x コミュニティ https://www.51cto.com/aigc/Translator|Jingyan Reviewer|Chonglou を参照してください。これらの質問は、インターネット上のどこでも見られる従来の質問バンクとは異なります。既成概念にとらわれずに考える必要があります。大規模言語モデル (LLM) は、データ サイエンス、生成人工知能 (GenAI)、および人工知能の分野でますます重要になっています。これらの複雑なアルゴリズムは人間のスキルを向上させ、多くの業界で効率とイノベーションを推進し、企業が競争力を維持するための鍵となります。 LLM は、自然言語処理、テキスト生成、音声認識、推奨システムなどの分野で幅広い用途に使用できます。 LLM は大量のデータから学習することでテキストを生成できます。
 微調整によって本当に LLM が新しいことを学習できるようになるのでしょうか: 新しい知識を導入すると、モデルがより多くの幻覚を生成する可能性があります
Jun 11, 2024 pm 03:57 PM
微調整によって本当に LLM が新しいことを学習できるようになるのでしょうか: 新しい知識を導入すると、モデルがより多くの幻覚を生成する可能性があります
Jun 11, 2024 pm 03:57 PM
大規模言語モデル (LLM) は巨大なテキスト データベースでトレーニングされ、そこで大量の現実世界の知識を取得します。この知識はパラメータに組み込まれており、必要なときに使用できます。これらのモデルの知識は、トレーニングの終了時に「具体化」されます。事前トレーニングの終了時に、モデルは実際に学習を停止します。モデルを調整または微調整して、この知識を活用し、ユーザーの質問により自然に応答する方法を学びます。ただし、モデルの知識だけでは不十分な場合があり、モデルは RAG を通じて外部コンテンツにアクセスできますが、微調整を通じてモデルを新しいドメインに適応させることが有益であると考えられます。この微調整は、ヒューマン アノテーターまたは他の LLM 作成物からの入力を使用して実行され、モデルは追加の実世界の知識に遭遇し、それを統合します。
 新しい科学的で複雑な質問応答ベンチマークと大規模モデルの評価システムを提供するために、UNSW、アルゴンヌ、シカゴ大学、およびその他の機関が共同で SciQAG フレームワークを立ち上げました。
Jul 25, 2024 am 06:42 AM
新しい科学的で複雑な質問応答ベンチマークと大規模モデルの評価システムを提供するために、UNSW、アルゴンヌ、シカゴ大学、およびその他の機関が共同で SciQAG フレームワークを立ち上げました。
Jul 25, 2024 am 06:42 AM
編集者 |ScienceAI 質問応答 (QA) データセットは、自然言語処理 (NLP) 研究を促進する上で重要な役割を果たします。高品質の QA データ セットは、モデルの微調整に使用できるだけでなく、大規模言語モデル (LLM) の機能、特に科学的知識を理解し推論する能力を効果的に評価することもできます。現在、医学、化学、生物学、その他の分野をカバーする多くの科学 QA データ セットがありますが、これらのデータ セットにはまだいくつかの欠点があります。まず、データ形式は比較的単純で、そのほとんどが多肢選択式の質問であり、評価は簡単ですが、モデルの回答選択範囲が制限され、科学的な質問に回答するモデルの能力を完全にテストすることはできません。対照的に、自由回答型の Q&A
 あなたが知らない機械学習の 5 つの流派
Jun 05, 2024 pm 08:51 PM
あなたが知らない機械学習の 5 つの流派
Jun 05, 2024 pm 08:51 PM
機械学習は人工知能の重要な分野であり、明示的にプログラムしなくてもコンピューターにデータから学習して能力を向上させる機能を提供します。機械学習は、画像認識や自然言語処理から、レコメンデーションシステムや不正行為検出に至るまで、さまざまな分野で幅広く応用されており、私たちの生活様式を変えつつあります。機械学習の分野にはさまざまな手法や理論があり、その中で最も影響力のある 5 つの手法は「機械学習の 5 つの流派」と呼ばれています。 5 つの主要な学派は、象徴学派、コネクショニスト学派、進化学派、ベイジアン学派、およびアナロジー学派です。 1. 象徴主義は、象徴主義とも呼ばれ、論理的推論と知識の表現のためのシンボルの使用を強調します。この学派は、学習は既存の既存の要素を介した逆演繹のプロセスであると信じています。
 SOTA パフォーマンス、厦門マルチモーダルタンパク質-リガンド親和性予測 AI 手法、初めて分子表面情報を結合
Jul 17, 2024 pm 06:37 PM
SOTA パフォーマンス、厦門マルチモーダルタンパク質-リガンド親和性予測 AI 手法、初めて分子表面情報を結合
Jul 17, 2024 pm 06:37 PM
編集者 | KX 医薬品の研究開発の分野では、タンパク質とリガンドの結合親和性を正確かつ効果的に予測することが、医薬品のスクリーニングと最適化にとって重要です。しかし、現在の研究では、タンパク質とリガンドの相互作用における分子表面情報の重要な役割が考慮されていません。これに基づいて、アモイ大学の研究者らは、初めてタンパク質の表面、3D 構造、配列に関する情報を組み合わせ、クロスアテンション メカニズムを使用して異なるモダリティの特徴を比較する、新しいマルチモーダル特徴抽出 (MFE) フレームワークを提案しました。アライメント。実験結果は、この方法がタンパク質-リガンド結合親和性の予測において最先端の性能を達成することを実証しています。さらに、アブレーション研究は、この枠組み内でのタンパク質表面情報と多峰性特徴の位置合わせの有効性と必要性を実証しています。 「S」で始まる関連研究
 AIなどの市場を開拓するグローバルファウンドリーズがタゴール・テクノロジーの窒化ガリウム技術と関連チームを買収
Jul 15, 2024 pm 12:21 PM
AIなどの市場を開拓するグローバルファウンドリーズがタゴール・テクノロジーの窒化ガリウム技術と関連チームを買収
Jul 15, 2024 pm 12:21 PM
7月5日のこのウェブサイトのニュースによると、グローバルファウンドリーズは今年7月1日にプレスリリースを発行し、自動車とインターネットでの市場シェア拡大を目指してタゴール・テクノロジーのパワー窒化ガリウム(GaN)技術と知的財産ポートフォリオを買収したことを発表した。モノと人工知能データセンターのアプリケーション分野で、より高い効率とより優れたパフォーマンスを探求します。生成 AI などのテクノロジーがデジタル世界で発展を続ける中、窒化ガリウム (GaN) は、特にデータセンターにおいて、持続可能で効率的な電力管理のための重要なソリューションとなっています。このウェブサイトは、この買収中にタゴール・テクノロジーのエンジニアリングチームがGLOBALFOUNDRIESに加わり、窒化ガリウム技術をさらに開発するという公式発表を引用した。 G
