

A100 は、3D コンボリューションを使用しない 3D 再構成方法を実装しており、各フレームの再構成にかかる時間はわずか 70 ミリ秒です。

ポーズ画像からの 3D 屋内シーンの再構成は、通常 2 つの段階に分かれています。画像の深さの推定、それに続く深さの結合と表面の再構成です。最近、いくつかの研究が、最終的な 3D 体積特徴空間で直接再構成を実行する一連の方法を提案しています。これらの手法は優れた再構築結果を達成していますが、高価な 3D 畳み込み層に依存しているため、リソースに制約のある環境での適用は制限されます。
現在、Niantic や UCL などの研究機関の研究者は、従来の手法を再利用し、高品質のマルチビュー深度予測に焦点を当てようとしており、最終的にはシンプルで既製の深度を使用しています。フュージョン法、高精度の 3D 再構成。

- 論文アドレス: https://nianticlabs.github .io /simplerecon/resources/SimpleRecon.pdf
- GitHub アドレス: https://github.com/nianticlabs/simplerecon
- 論文のホームページ: https://nianticlabs.github.io/simplerecon/
この研究では最初に強力な画像を使用します A 2D CNNは、平面スキャン特徴量や幾何学的損失だけでなく、実験に基づいて綿密に設計されています。提案された手法 SimpleRecon は、深度推定において大幅に優れた結果を達成し、オンラインでのリアルタイムの低メモリ再構成を可能にします。
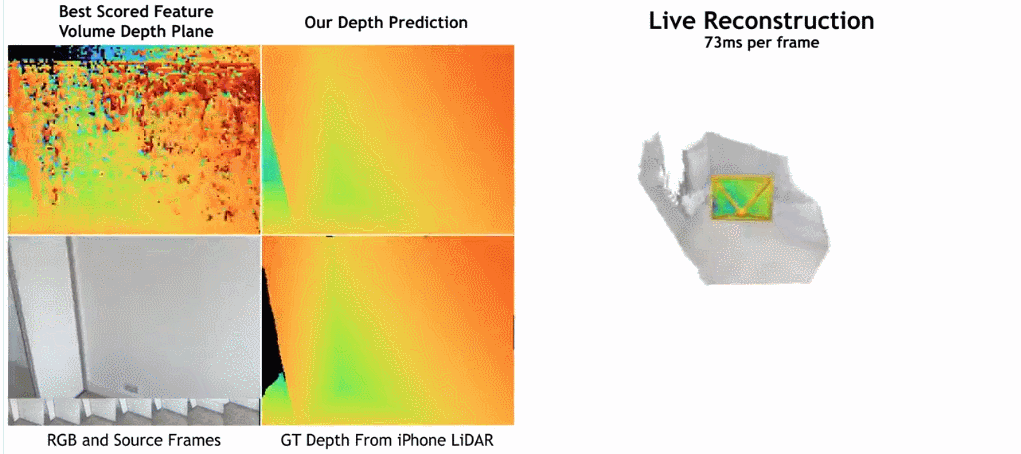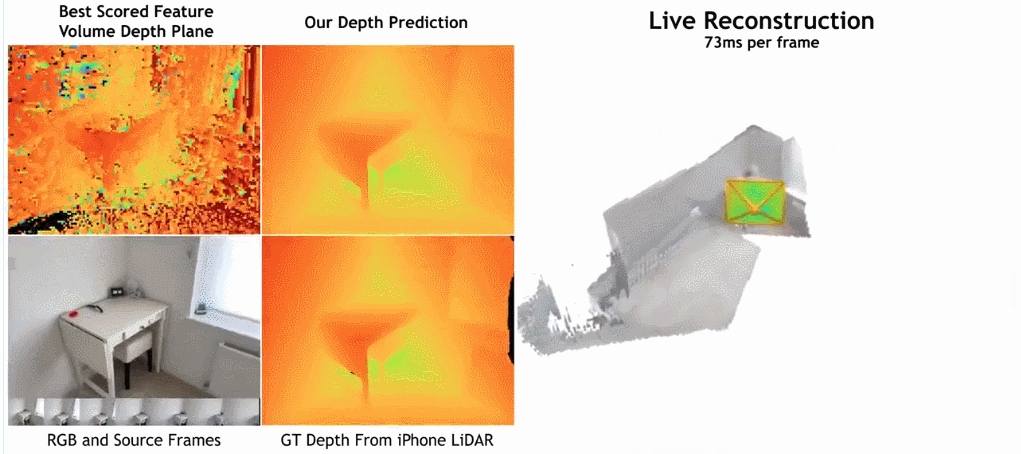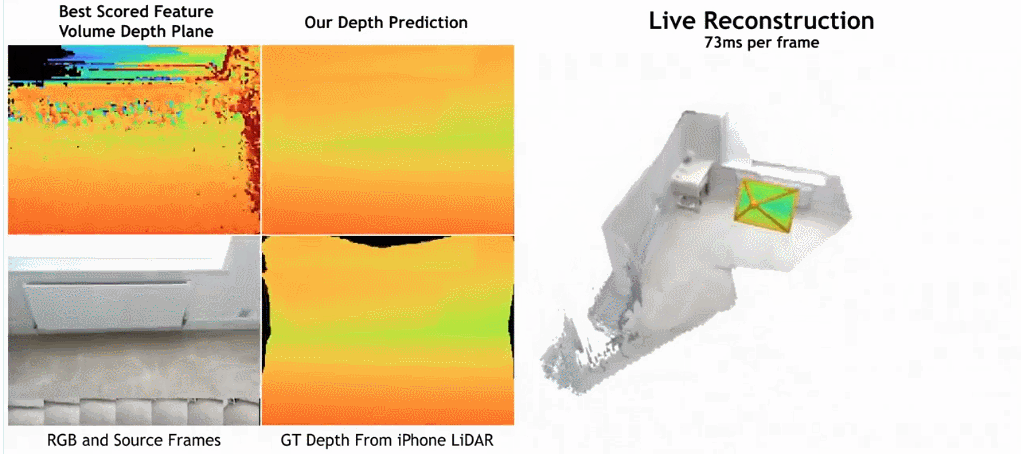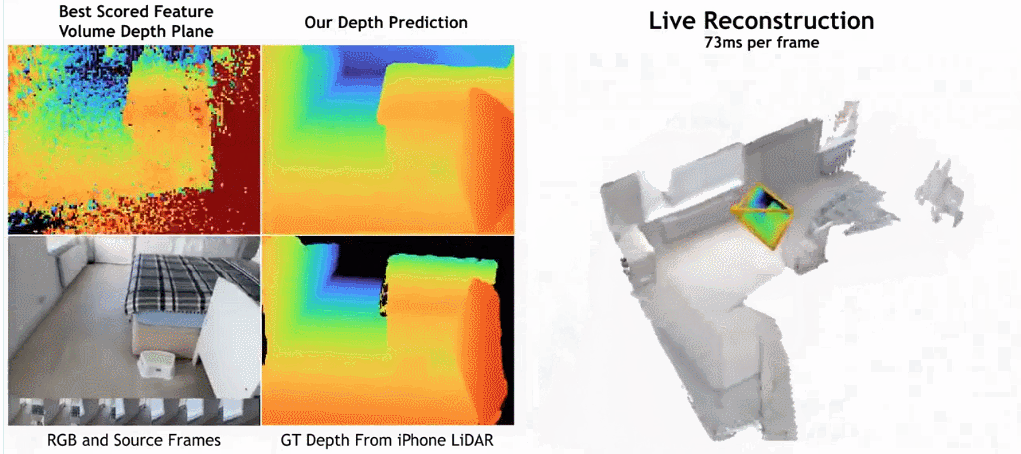
下の図に示すように、SimpleRecon の再構成速度は非常に速く、1 フレームあたりわずか約 70 ミリ秒しかかかりません。

 ##方法
##方法
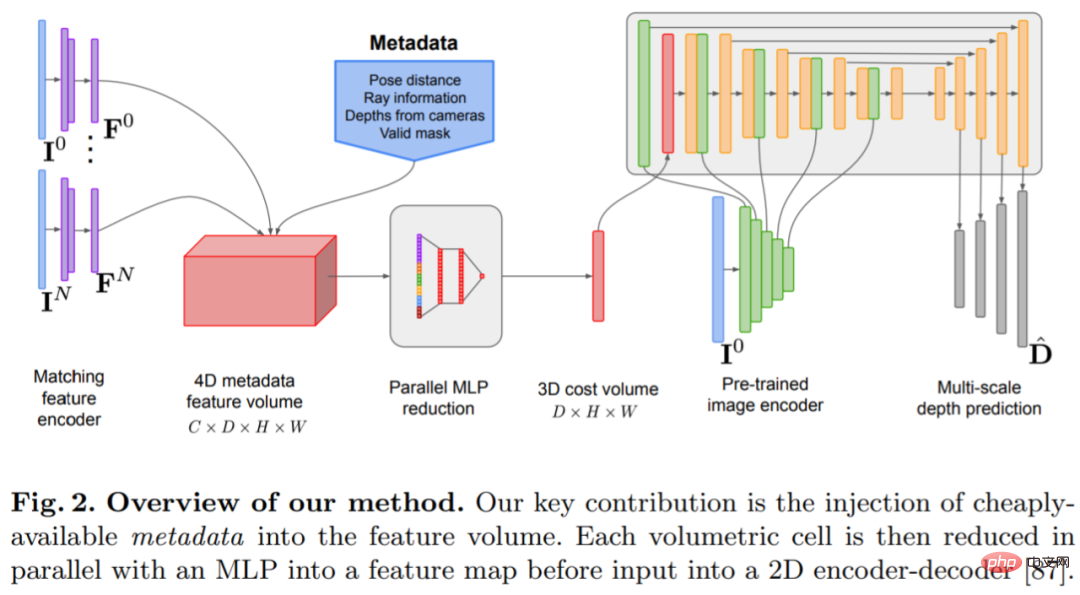
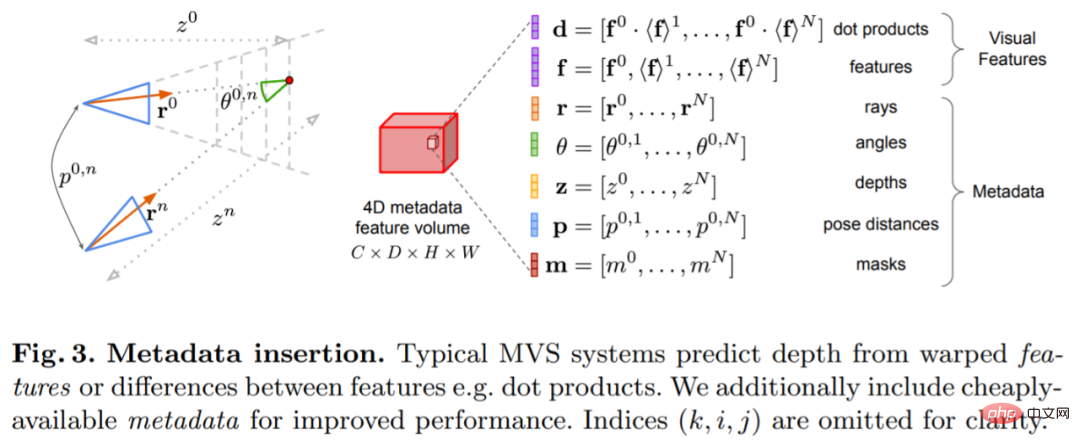
ネットワーク アーキテクチャ設計
ネットワークは、2D 畳み込みエンコーダ/デコーダ アーキテクチャに基づいて実装されています。このようなネットワークを構築する場合、主に次のような、深さの予測精度を大幅に向上させることができる重要な設計上の選択肢がいくつかあることが研究で判明しています。融合法がよく使用されますが、システムの複雑さが大幅に増加します。代わりに、この研究ではコスト ボリューム フュージョンを可能な限り単純にし、参照ビューと各ソース ビューの間のドット積マッチング コストを加算するだけで、SOTA 深度推定と競合する結果が得られることがわかりました。画像エンコーダと特徴マッチングエンコーダ: これまでの研究では、画像エンコーダが単眼推定と多視点推定の両方で奥行き推定に非常に重要であることが示されています。たとえば、DeepVideoMVS は、比較的待ち時間が短い MnasNet を画像エンコーダとして使用します。この研究では、小型だがより強力な EfficientNetv2 S エンコーダを使用することを推奨しています。これにより、深度推定の精度が大幅に向上しますが、パラメータの数が増加し、実行速度が 10% 低下します。
マルチスケール画像特徴をコスト ボリューム エンコーダーに融合する: 2D CNN ベースのデプス ステレオおよびマルチビュー ステレオでは、通常、画像特徴は単一スケールのコスト ボリューム出力と結合されます。最近、DeepVideoMVS は、あらゆる解像度で画像エンコーダーとコスト ボリューム エンコーダーの間にスキップ接続を追加し、複数のスケールでディープ画像特徴をステッチすることを提案しています。これは LSTM ベースのフュージョン ネットワークに役立ちますが、この調査ではアーキテクチャにとっても重要であることがわかりました。
実験
この研究では、3D シーン再構成データセット ScanNetv2 で提案された方法をトレーニングし、評価しました。以下の表 1 では、Eigen et al. (2014) によって提案されたメトリクスを使用して、いくつかのネットワーク モデルの深度予測パフォーマンスを評価しています。
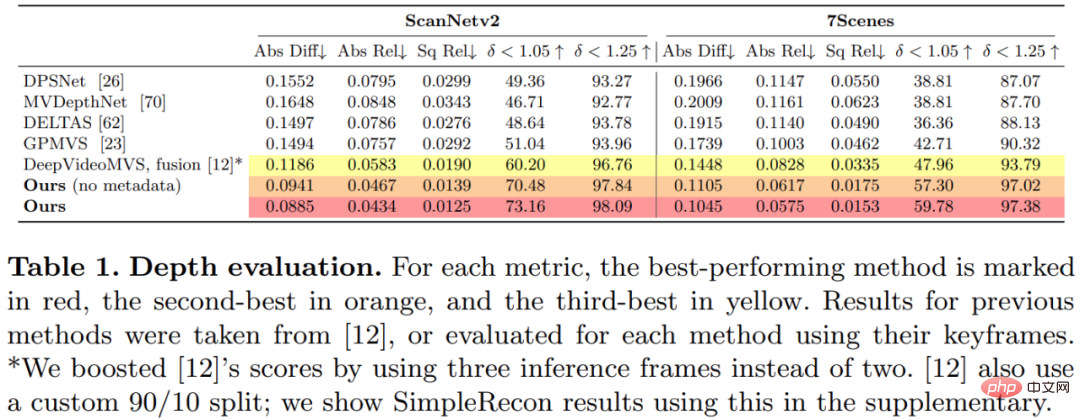
驚くべきことに、この研究で提案されたモデルは 3D 畳み込みを使用していませんが、深度予測指標ではすべてのベースライン モデルを上回っています。さらに、メタデータ エンコーディングを使用しないベースライン モデルも、以前の方法よりも優れたパフォーマンスを発揮します。これは、高品質の深度推定には、適切に設計されトレーニングされた 2D ネットワークで十分であることを示しています。以下の図 4 と図 5 は、深さと法線の定性的な結果を示しています。
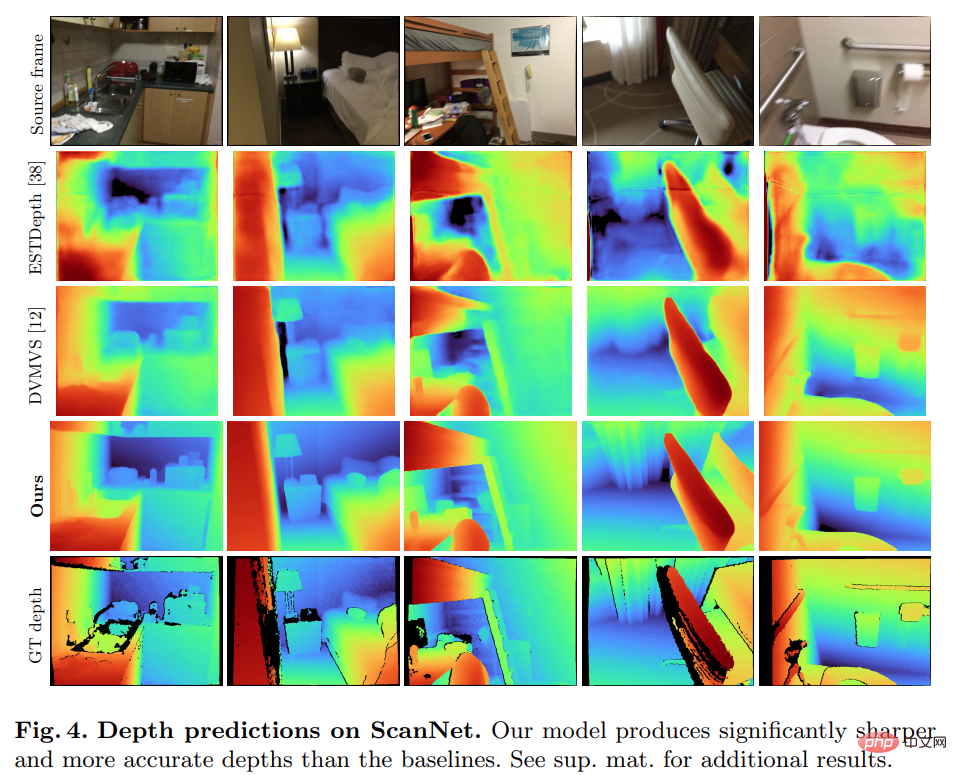

# この研究では、3D 再構築評価のために TransformerFusion によって確立された標準プロトコルを使用しました。結果を表に示します。 2以下です。
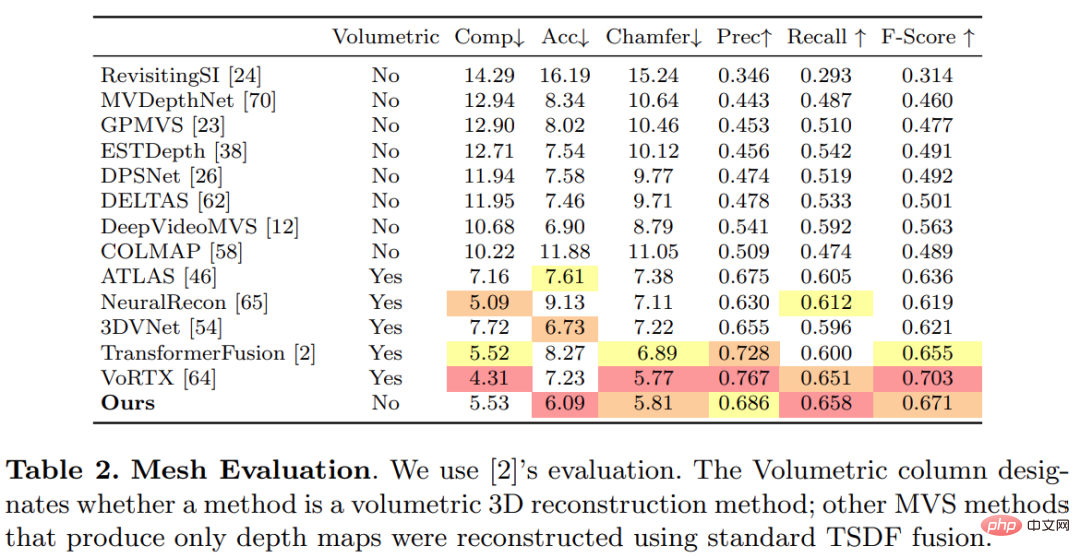
オンラインでインタラクティブな 3D 再構成アプリケーションでは、センサーの遅延を短縮することが重要です。以下の表 3 は、新しい RGB フレームが与えられた場合の各モデルのフレームごとのアンサンブル計算時間を示しています。

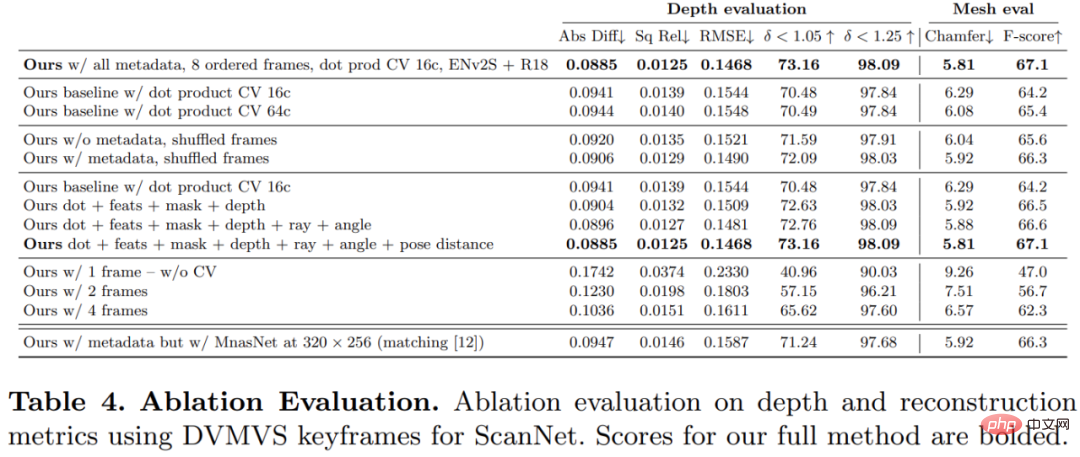
この研究で提案した方法の各コンポーネントの有効性を検証するために、研究者はアブレーション実験を実施しました。その結果は次のとおりです。以下の表 4 に記載されています。
興味のある読者は、論文の原文を読んで研究の詳細を学ぶことができます。
以上がA100 は、3D コンボリューションを使用しない 3D 再構成方法を実装しており、各フレームの再構成にかかる時間はわずか 70 ミリ秒です。の詳細内容です。詳細については、PHP 中国語 Web サイトの他の関連記事を参照してください。

ホットAIツール

Undresser.AI Undress
リアルなヌード写真を作成する AI 搭載アプリ

AI Clothes Remover
写真から衣服を削除するオンライン AI ツール。

Undress AI Tool
脱衣画像を無料で

Clothoff.io
AI衣類リムーバー

AI Hentai Generator
AIヘンタイを無料で生成します。
人気の記事
ホットツール

メモ帳++7.3.1
使いやすく無料のコードエディター

SublimeText3 中国語版
中国語版、とても使いやすい

ゼンドスタジオ 13.0.1
強力な PHP 統合開発環境

ドリームウィーバー CS6
ビジュアル Web 開発ツール

SublimeText3 Mac版
神レベルのコード編集ソフト(SublimeText3)
ホットトピック
 7515
7515
 15
1378
52
79
11
20
66
15
1378
52
79
11
20
66

![WLAN拡張モジュールが停止しました[修正]](https://img.php.cn/upload/article/000/465/014/170832352052603.gif?x-oss-process=image/resize,m_fill,h_207,w_330) WLAN拡張モジュールが停止しました[修正]
Feb 19, 2024 pm 02:18 PM
WLAN拡張モジュールが停止しました[修正]
Feb 19, 2024 pm 02:18 PM
Windows コンピュータの WLAN 拡張モジュールに問題がある場合、インターネットから切断される可能性があります。この状況はイライラすることがよくありますが、幸いなことに、この記事では、この問題を解決し、ワイヤレス接続を再び正常に動作させるのに役立ついくつかの簡単な提案を提供します。 WLAN 拡張モジュールが停止しました。 WLAN 拡張モジュールが Windows コンピュータで動作を停止した場合は、次の提案に従って修正してください。 ネットワークとインターネットのトラブルシューティング ツールを実行して、ワイヤレス ネットワーク接続を無効にし、再度有効にします。 WLAN 自動構成サービスを再起動します。 電源オプションを変更します。 変更します。詳細な電源設定 ネットワーク アダプター ドライバーを再インストールする いくつかのネットワーク コマンドを実行する それでは、詳しく見てみましょう
 win11のDNSサーバーエラーの解決方法
Jan 10, 2024 pm 09:02 PM
win11のDNSサーバーエラーの解決方法
Jan 10, 2024 pm 09:02 PM
インターネットにアクセスするには、インターネットに接続するときに正しい DNS を使用する必要があります。同様に、間違った DNS 設定を使用すると、DNS サーバー エラーが発生しますが、このときは、ネットワーク設定で DNS を自動的に取得するように選択することで問題を解決できます。ソリューション。 win11 ネットワーク dns サーバー エラーを解決する方法. 方法 1: DNS をリセットする 1. まず、タスクバーの [スタート] をクリックして入力し、[設定] アイコン ボタンを見つけてクリックします。 2. 次に、左側の列の「ネットワークとインターネット」オプションコマンドをクリックします。 3. 次に、右側で「イーサネット」オプションを見つけ、クリックして入力します。 4. その後、DNSサーバーの割り当ての「編集」をクリックし、最後にDNSを「自動(D)」に設定します。
 Chrome、Google ドライブ、フォトでの「ネットワーク エラーの失敗」ダウンロードを修正してください。
Oct 27, 2023 pm 11:13 PM
Chrome、Google ドライブ、フォトでの「ネットワーク エラーの失敗」ダウンロードを修正してください。
Oct 27, 2023 pm 11:13 PM
「ネットワーク エラーのダウンロードに失敗しました」問題とは何ですか?解決策を詳しく説明する前に、まず「ネットワーク エラーのダウンロードに失敗しました」問題が何を意味するのかを理解しましょう。このエラーは通常、ダウンロード中にネットワーク接続が中断された場合に発生します。この問題は、インターネット接続の弱さ、ネットワークの混雑、サーバーの問題など、さまざまな理由で発生する可能性があります。このエラーが発生すると、ダウンロードが停止し、エラー メッセージが表示されます。ネットワークエラーで失敗したダウンロードを修正するにはどうすればよいですか? 「ネットワーク エラー ダウンロードに失敗しました」というメッセージが表示されると、必要なファイルへのアクセスまたはダウンロード中に障害が発生する可能性があります。 Chrome などのブラウザを使用している場合でも、Google ドライブや Google フォトなどのプラットフォームを使用している場合でも、このエラーはポップアップ表示され、不便を引き起こします。この問題を解決し、解決するために役立つポイントを以下に示します。
 修正: WD My Cloud が Windows 11 のネットワーク上に表示されない
Oct 02, 2023 pm 11:21 PM
修正: WD My Cloud が Windows 11 のネットワーク上に表示されない
Oct 02, 2023 pm 11:21 PM
WDMyCloud が Windows 11 のネットワーク上に表示されない場合、特にそこにバックアップやその他の重要なファイルを保存している場合は、大きな問題になる可能性があります。これは、ネットワーク ストレージに頻繁にアクセスする必要があるユーザーにとって大きな問題となる可能性があるため、今日のガイドでは、この問題を永久に修正する方法を説明します。 WDMyCloud が Windows 11 ネットワークに表示されないのはなぜですか? MyCloud デバイス、ネットワーク アダプター、またはインターネット接続が正しく構成されていません。パソコンにSMB機能がインストールされていません。 Winsock の一時的な不具合がこの問題を引き起こす場合があります。クラウドがネットワーク上に表示されない場合はどうすればよいですか?問題の修正を開始する前に、いくつかの予備チェックを実行できます。
 Windows 10 の右下に地球が表示されてインターネットにアクセスできない場合はどうすればよいですか? Win10 で地球がインターネットにアクセスできない問題のさまざまな解決策
Feb 29, 2024 am 09:52 AM
Windows 10 の右下に地球が表示されてインターネットにアクセスできない場合はどうすればよいですか? Win10 で地球がインターネットにアクセスできない問題のさまざまな解決策
Feb 29, 2024 am 09:52 AM
この記事では、Win10のシステムネットワーク上に地球儀マークが表示されるがインターネットにアクセスできない問題の解決策を紹介します。この記事では、地球がインターネットにアクセスできないことを示す Win10 ネットワークの問題を読者が解決するのに役立つ詳細な手順を説明します。方法 1: 直接再起動する まず、ネットワーク ケーブルが正しく接続されていないこと、ブロードバンドが滞っていないかを確認します。ルーターまたは光モデムが停止している可能性があります。この場合は、ルーターまたは光モデムを再起動する必要があります。コンピュータ上で重要な作業が行われていない場合は、コンピュータを直接再起動できます。ほとんどの軽微な問題は、コンピュータを再起動することですぐに解決できます。ブロードバンドが滞っておらず、ネットワークが正常であると判断される場合は、別の問題です。方法 2: 1. [Win]キーを押すか、左下の[スタートメニュー]をクリックし、表示されるメニュー項目の電源ボタンの上にある歯車アイコンをクリックし、[設定]をクリックします。
 なぜ自動運転ではガウス スプラッティングが非常に人気があるのに、NeRF は放棄され始めているのでしょうか?
Jan 17, 2024 pm 02:57 PM
なぜ自動運転ではガウス スプラッティングが非常に人気があるのに、NeRF は放棄され始めているのでしょうか?
Jan 17, 2024 pm 02:57 PM
上記と著者の個人的な理解 3 次元ガウシアンプラッティング (3DGS) は、近年、明示的な放射線フィールドとコンピューター グラフィックスの分野で出現した革新的なテクノロジーです。この革新的な方法は、数百万の 3D ガウスを使用することを特徴とし、主に暗黙的な座標ベースのモデルを使用して空間座標をピクセル値にマッピングする神経放射線場 (NeRF) 方法とは大きく異なります。明示的なシーン表現と微分可能なレンダリング アルゴリズムにより、3DGS はリアルタイム レンダリング機能を保証するだけでなく、前例のないレベルの制御とシーン編集も導入します。これにより、3DGS は、次世代の 3D 再構築と表現にとって大きな変革をもたらす可能性のあるものとして位置付けられます。この目的を達成するために、私たちは 3DGS 分野における最新の開発と懸念について初めて体系的な概要を提供します。
 ネットワーク接続を確認してください: lol はサーバーに接続できません
Feb 19, 2024 pm 12:10 PM
ネットワーク接続を確認してください: lol はサーバーに接続できません
Feb 19, 2024 pm 12:10 PM
LOL サーバーに接続できません。ネットワークを確認してください。 近年、オンラインゲームは多くの人にとって日常的な娯楽となっています。中でも、リーグ オブ レジェンド (LOL) は非常に人気のあるマルチプレイヤー オンライン ゲームであり、数億人のプレイヤーの参加と関心を集めています。ただし、LOL をプレイしているときに、「サーバーに接続できません。ネットワークを確認してください」というエラー メッセージが表示されることがあります。これは間違いなくプレイヤーに何らかの問題をもたらします。次に、このエラーの原因と解決策について説明します。まず、LOLがサーバーに接続できない問題として考えられるのは、
 カメラかライダーを選択しますか?堅牢な 3D オブジェクト検出の実現に関する最近のレビュー
Jan 26, 2024 am 11:18 AM
カメラかライダーを選択しますか?堅牢な 3D オブジェクト検出の実現に関する最近のレビュー
Jan 26, 2024 am 11:18 AM
0.前面に書かれています&& 自動運転システムは、さまざまなセンサー (カメラ、ライダー、レーダーなど) を使用して周囲の環境を認識し、アルゴリズムとモデルを使用することにより、高度な知覚、意思決定、および制御テクノロジーに依存しているという個人的な理解リアルタイムの分析と意思決定に。これにより、車両は道路標識の認識、他の車両の検出と追跡、歩行者の行動の予測などを行うことで、安全な運行と複雑な交通環境への適応が可能となり、現在広く注目を集めており、将来の交通分野における重要な開発分野と考えられています。 。 1つ。しかし、自動運転を難しくしているのは、周囲で何が起こっているかを車に理解させる方法を見つけることです。これには、自動運転システムの 3 次元物体検出アルゴリズムが、周囲環境にある物体 (位置を含む) を正確に認識し、記述することができる必要があります。
