

Meta が多目的大規模モデルのオープンソースをリリースし、視覚的な統合に一歩近づくのに役立ちます

「すべてを分割する」SAM モデルをオープンソース化したメタは、「ビジュアルベーシックモデル」への道をどんどん突き進んでいます。
今回、彼らは DINOv2 と呼ばれるモデルのセットをオープンソース化しました。これらのモデルは、微調整することなく、分類、セグメンテーション、画像検索、深度推定などの下流タスクに使用できる高性能の視覚表現を生成できます。
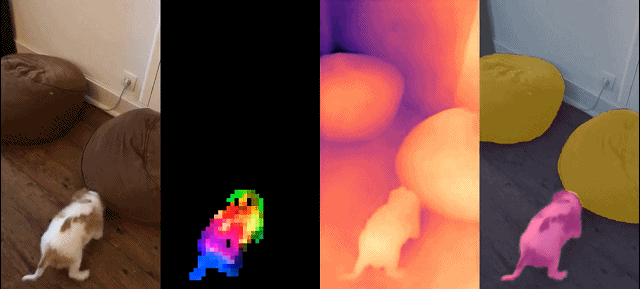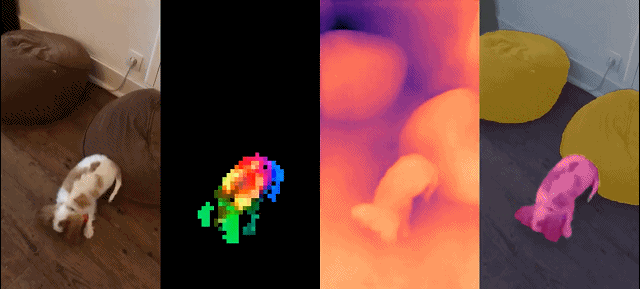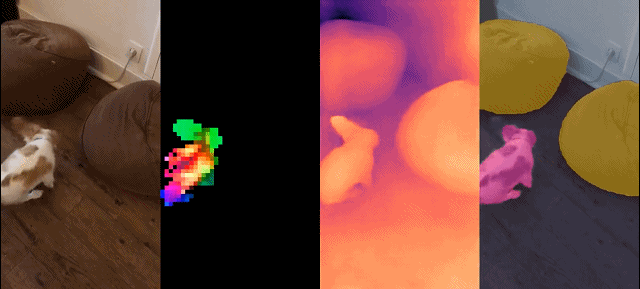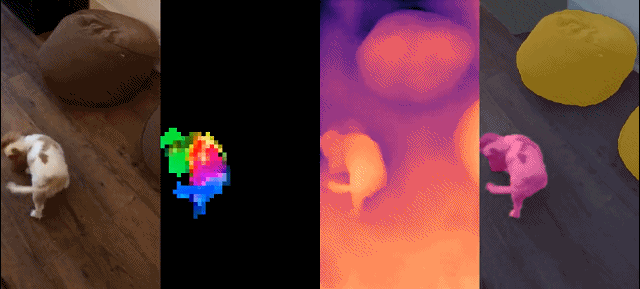
このモデル セットには次の特徴があります:
- 大量のラベル付きデータを必要とせずに自己教師ありトレーニングを使用します。
- は、ほぼすべての CV タスクのバックボーンとして使用できます。画像分類、セグメンテーション、画像検索、深度推定などの調整が必要です。
- テキストの説明に頼らずに画像から直接特徴を学習することで、モデルがローカル情報をよりよく理解できるようになります。
- 任意の画像コレクションから学習可能;
- DINOv2 の事前トレーニング済みバージョンがすでに利用可能であり、CLIP および OpenCLIP に匹敵します。タスクの範囲。

- #紙のリンク: https://arxiv.org/pdf/2304.07193.pdf #プロジェクトリンク: https://dinov2.metademolab.com/
- #論文概要
タスク固有ではない事前トレーニング済み表現の学習は、自然言語処理の標準になっています。これらの機能は「そのまま」使用でき (微調整は必要ありません)、下流のタスクではタスク固有のモデルよりも大幅に優れたパフォーマンスを発揮します。この成功は、言語モデリングやワード ベクトルなどの監視を必要としない補助目標を使用した、大量の生テキストの事前トレーニングによるものです。
NLP の分野でこのパラダイム シフトが起こると、コンピューター ビジョンでも同様の「基本」モデルが登場すると予想されます。これらのモデルは、画像レベル (例: 画像分類) またはピクセル レベル (例: セグメンテーション) のいずれのタスクでも「すぐに使える」視覚的特徴を生成する必要があります。
これらの基本モデルは、テキストガイドによる事前トレーニング、つまり、テキスト監視形式を使用して機能のトレーニングをガイドすることに重点を置くという大きな期待を持っています。この形式のテキストガイドによる事前トレーニングでは、キャプションは画像内の豊富な情報を近似するだけであり、より細かく複雑なピクセルレベルの情報はこの監視では検出できない可能性があるため、保持できる画像に関する情報が制限されます。さらに、これらの画像エンコーダは、すでに位置合わせされたテキストと画像のコーパスを必要とし、対応するテキストのような柔軟性を提供しません。つまり、生データのみから学習することができません。
テキストガイドによる事前トレーニングの代替手段は、画像のみから特徴を学習する自己教師あり学習です。これらのメソッドは概念的には言語モデリングなどのフロントエンド タスクに近く、画像およびピクセル レベルで情報をキャプチャできます。ただし、一般的な特徴を学習できる可能性があるにもかかわらず、自己教師あり学習の改善のほとんどは、洗練された小さなデータセット ImageNet1k での事前トレーニングのコンテキストで達成されています。これらの手法を ImageNet-1k を超えて拡張しようとする研究者もいますが、フィルタリングされていないデータセットに焦点を当てていたため、パフォーマンス品質が大幅に低下することがよくありました。これは、良い結果を生み出すために不可欠なデータの品質と多様性を制御できないことが原因です。
この研究では、研究者たちは、大量の洗練されたデータで事前トレーニングされた場合に、一般的な視覚的特徴を学習する自己教師あり学習が可能かどうかを調査します。彼らは、iBOT など、画像およびパッチ レベルで特徴を学習する既存の自己教師あり識別手法を再考し、大規模なデータセットの下で設計の選択の一部を再検討しています。私たちの技術貢献のほとんどは、モデルとデータのサイズをスケーリングする際の識別的自己教師あり学習を安定させ、加速するように調整されています。これらの改善により、同様の自己教師あり識別法に比べてメソッドが約 2 倍高速になり、必要なメモリが 1/3 減り、より長いトレーニングとより大きなバッチ サイズを活用できるようになりました。
事前トレーニング データに関しては、フィルタリングされていない画像の大規模なコレクションからデータセットをフィルタリングして再バランスするための自動パイプラインを構築しました。これは、NLP で使用されるパイプラインからインスピレーションを得たもので、外部メタデータの代わりにデータの類似性が使用され、手動のアノテーションは必要ありません。画像を処理する際の主な困難は、概念のバランスを再調整し、一部の主要なモードでの過剰適合を回避することです。今回の研究では、単純なクラスタリング手法がこの問題をうまく解決でき、研究者らは手法を検証するために 1 億 4,200 万枚の画像からなる小さいながらも多様なコーパスを収集しました。
最後に、研究者らは、さまざまなビジュアル トランスフォーマー (ViT) アーキテクチャを使用してデータに基づいてトレーニングされた、DINOv2 と呼ばれるさまざまな事前トレーニング済みビジョン モデルを提供します。彼らは、あらゆるデータに対して DINOv2 を再トレーニングするためのすべてのモデルとコードをリリースしました。図 2 に示すように、拡張した場合、画像およびピクセル レベルでさまざまなコンピューター ビジョン ベンチマークで DINOv2 の品質を検証しました。私たちは、自己教師あり事前トレーニングだけでも、公開されている最良の弱教師ありモデルに匹敵する、転送可能な凍結特徴を学習するのに適した候補であると結論付けています。
データ処理
研究者らは、複数の洗練されたデータセット (1 億 4,200 万個のデータセット) の画像に近い、フィルターされていない大量のデータから画像を取得することで、洗練された LVD を組み立てました。彼らは論文の中で、厳選/フィルタリングされていないデータ ソース、画像の重複排除手順、取得システムなど、データ パイプラインの主要コンポーネントについて説明しています。図 3 に示すように、パイプライン全体はメタデータやテキストを必要とせず、画像を直接処理します。モデル方法論の詳細については、付録 A を参照してください。
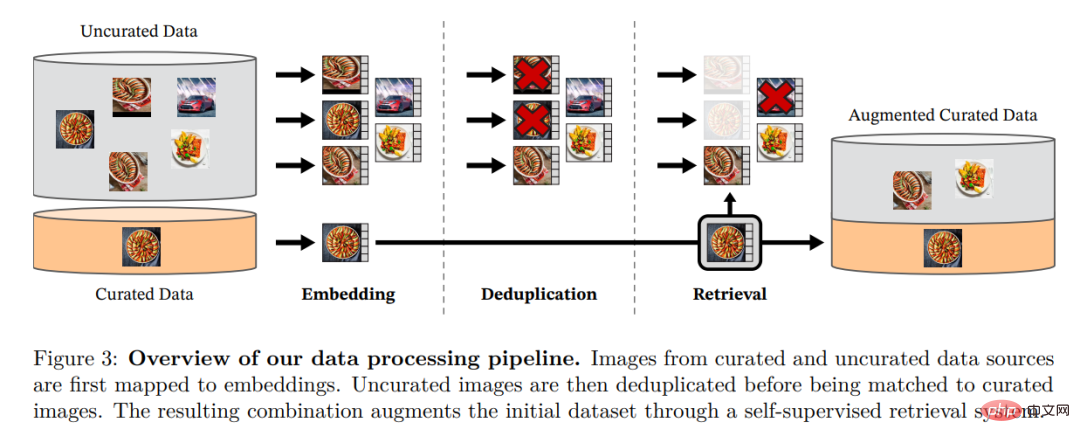
#図 3: データ処理パイプラインの概要。リファインされたデータ ソースとリファインされていないデータ ソースからの画像は、最初にエンベディングにマッピングされます。未精製のイメージは、標準イメージと照合される前に重複排除されます。結果として得られる組み合わせは、自己監視型検索システムを通じて初期データセットをさらに充実させます。
自己教師あり識別型事前トレーニング研究者らは、自己教師あり識別型手法を通じて自分の特徴を学習しました。 SwAV を中心とした DINO 損失と iBOT 損失の組み合わせ。また、特徴を伝播するための正則化機能と短い高解像度トレーニング フェーズも追加されました。
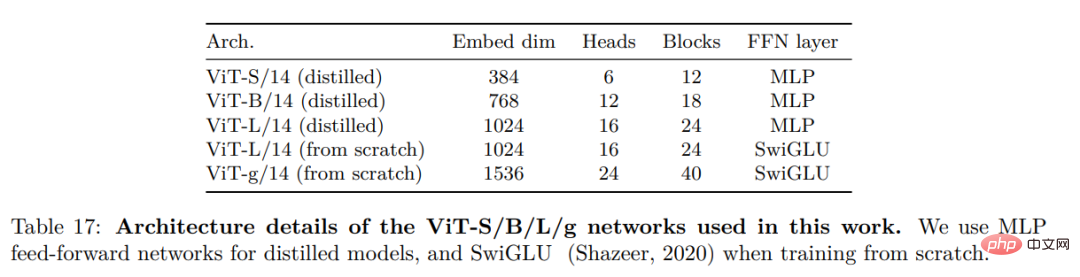
効率的な実装彼らは、大規模なモデルをトレーニングするためにいくつかの改善を検討しました。モデルは PyTorch 2.0 を使用して A100 GPU でトレーニングされており、コードは特徴抽出のために事前トレーニングされたモデルとともに使用することもできます。モデルの詳細は付録表 17 に記載されています。同じハードウェア上で、DINOv2 コードはメモリの 1/3 のみを使用し、iBOT 実装よりも 2 倍高速に実行されます。
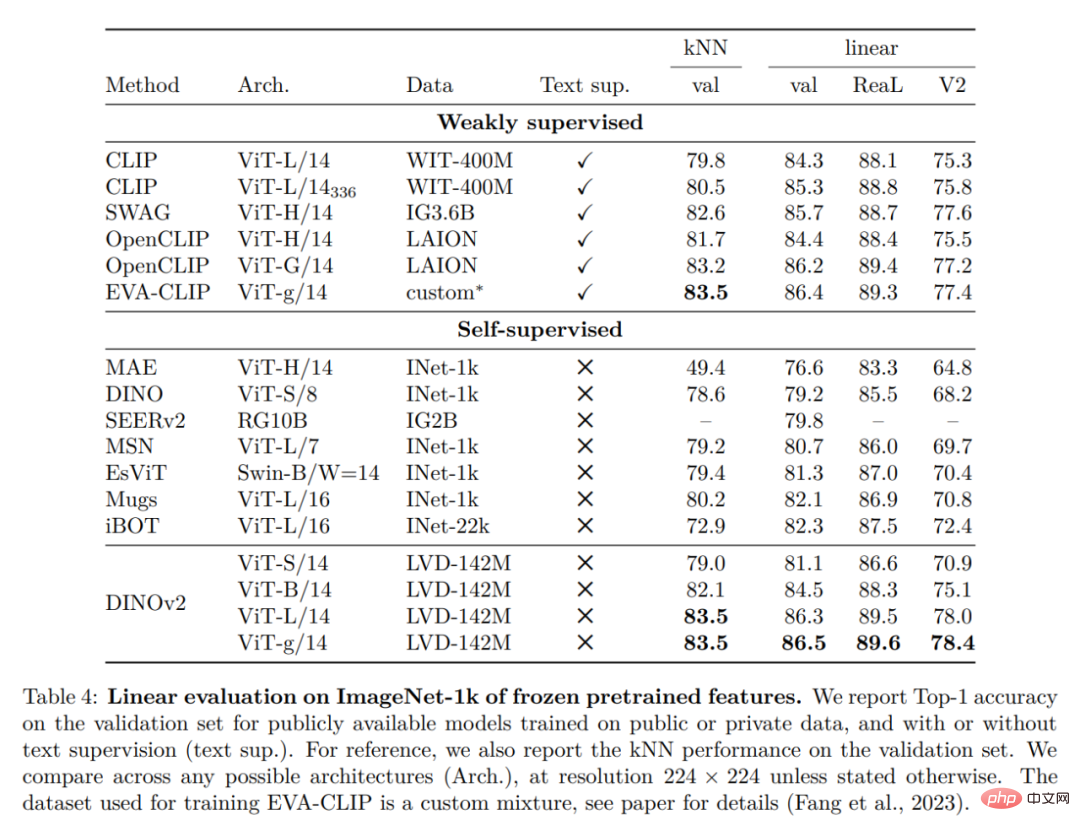
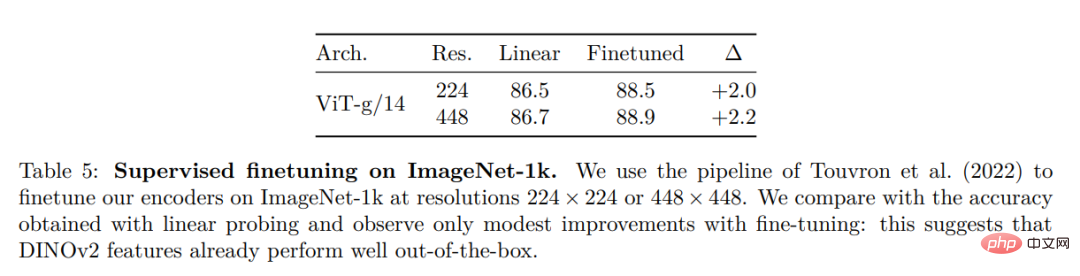
ImageNet 分類
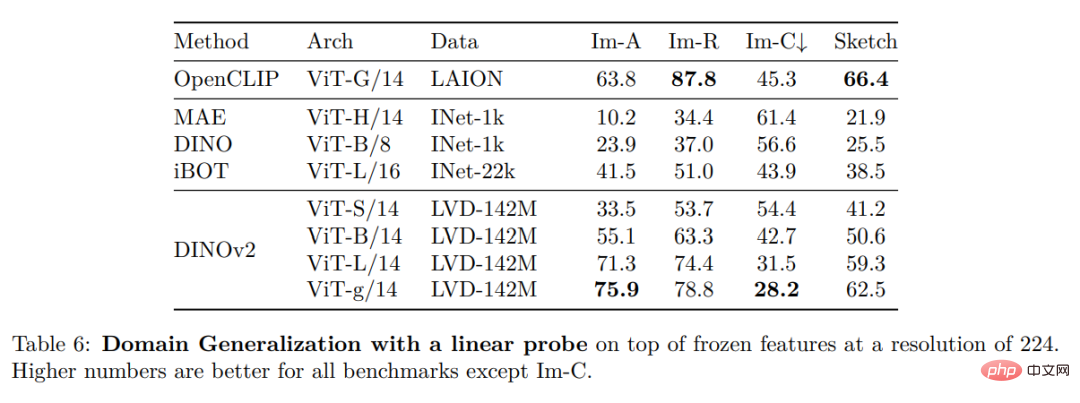
##その他の画像およびビデオ分類ベンチマーク
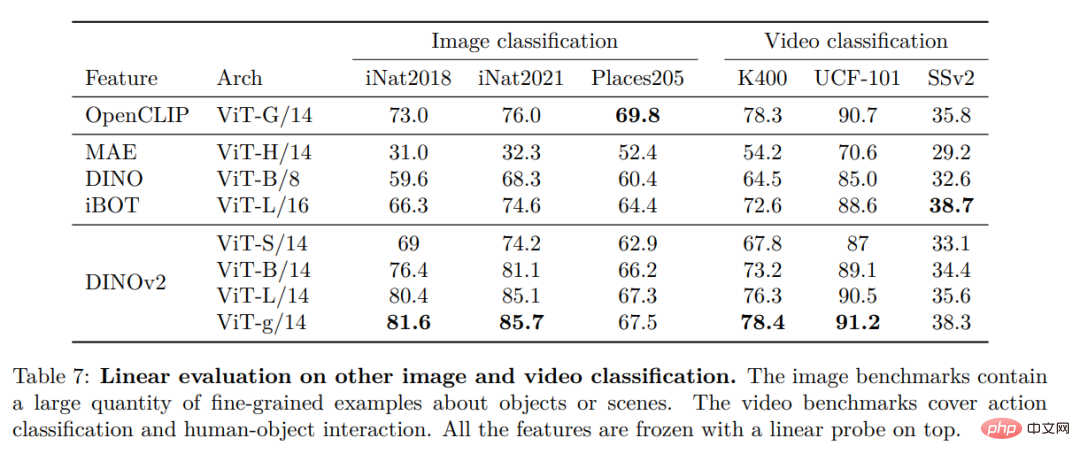
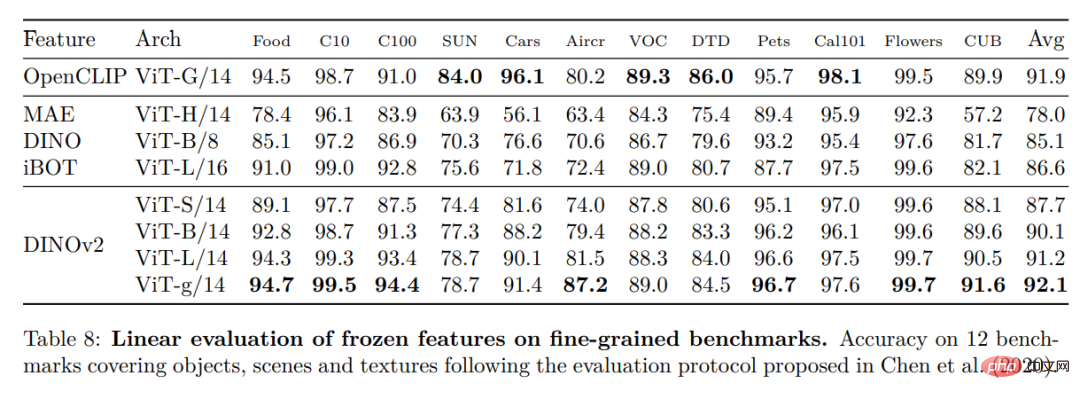
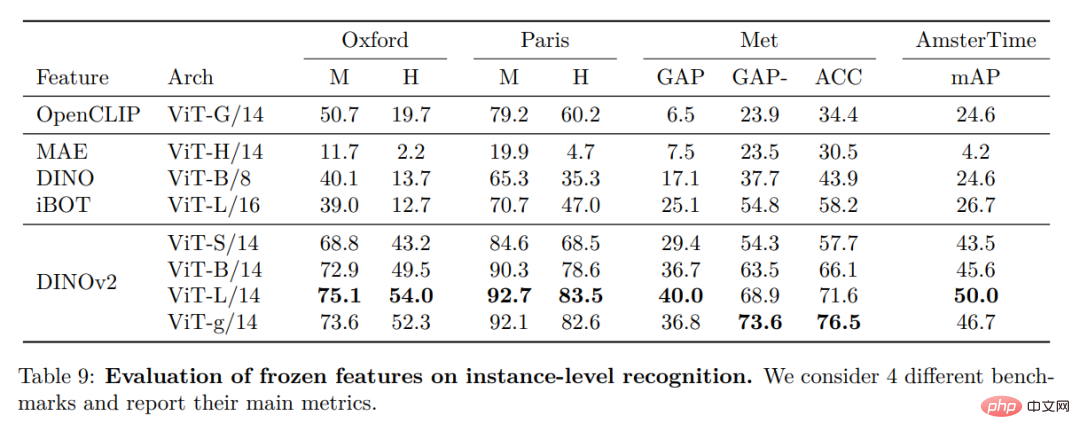 #高密度認識タスク
#高密度認識タスク
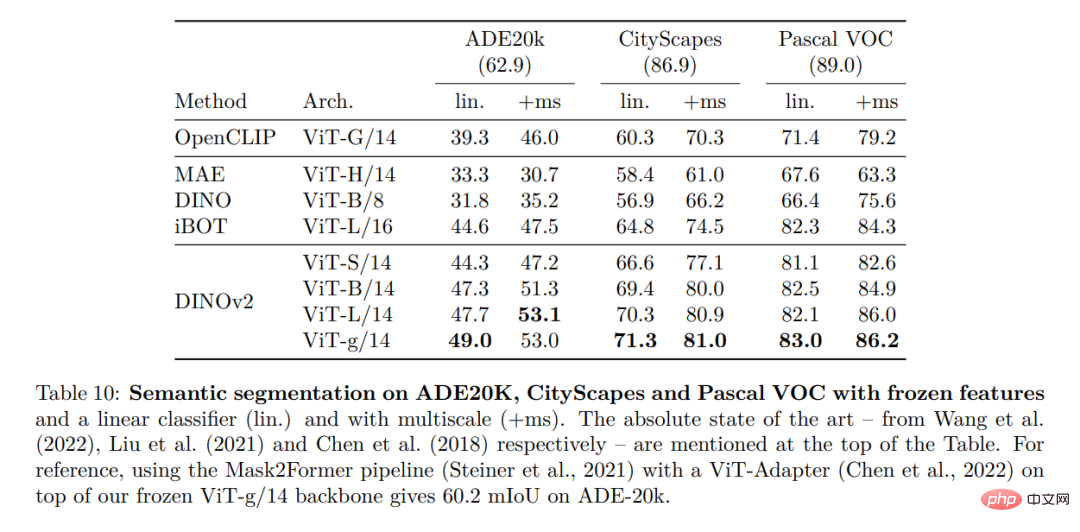
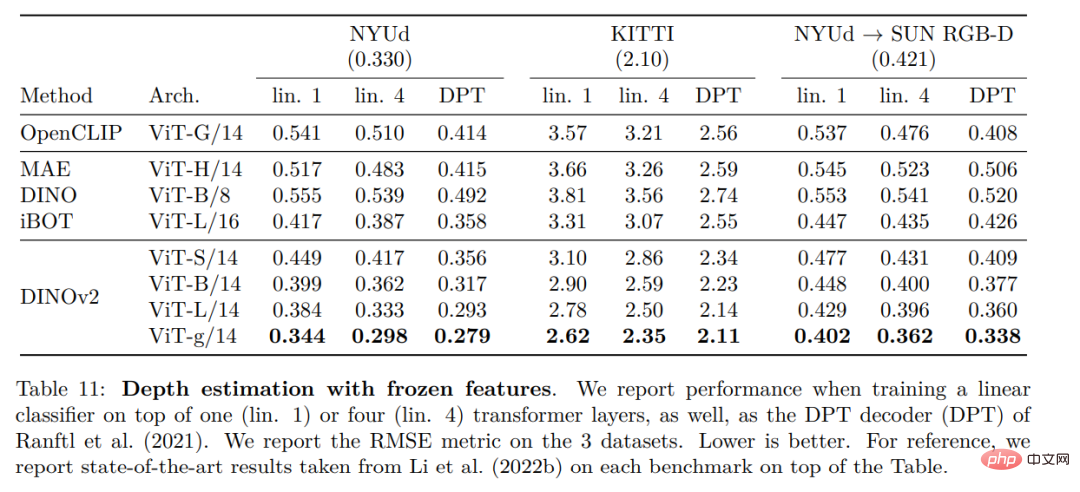 定性的結果
定性的結果


以上がMeta が多目的大規模モデルのオープンソースをリリースし、視覚的な統合に一歩近づくのに役立ちますの詳細内容です。詳細については、PHP 中国語 Web サイトの他の関連記事を参照してください。

ホットAIツール

Undresser.AI Undress
リアルなヌード写真を作成する AI 搭載アプリ

AI Clothes Remover
写真から衣服を削除するオンライン AI ツール。

Undress AI Tool
脱衣画像を無料で

Clothoff.io
AI衣類リムーバー

AI Hentai Generator
AIヘンタイを無料で生成します。

人気の記事
ホットツール

メモ帳++7.3.1
使いやすく無料のコードエディター

SublimeText3 中国語版
中国語版、とても使いやすい

ゼンドスタジオ 13.0.1
強力な PHP 統合開発環境

ドリームウィーバー CS6
ビジュアル Web 開発ツール

SublimeText3 Mac版
神レベルのコード編集ソフト(SublimeText3)
ホットトピック
 7489
7489
 15
1377
52
77
11
19
41
15
1377
52
77
11
19
41

 Goat Simulator 3 でホラーコリドーミッションを完了する方法
Feb 25, 2024 pm 03:40 PM
Goat Simulator 3 でホラーコリドーミッションを完了する方法
Feb 25, 2024 pm 03:40 PM
恐怖の回廊は Goat Simulator 3 のミッションです。どのようにしてこのミッションを完了できますか? 詳細なクリア方法と対応するプロセスをマスターし、このミッションの対応する課題を完了できるようにしてください。以下を実行すると、Goat Simulator 3 の恐怖回廊が表示されます。関連情報を学ぶためのガイド。 Goat Simulator 3 Terror Corridor Guide 1. まず、プレイヤーはマップの左上隅にあるサイレントヒルに行く必要があります。 2. ここには屋上に「RESTSTOP」と書かれた家があり、プレイヤーはヤギを操作してこの家に入る必要があります。 3. 部屋に入ったら、まず直進して右に曲がり、突き当りにドアがありますので、そこから直接お入りください。 4. 入ったら、まず前に歩いてから右に曲がる必要があります。ここのドアに到達すると、ドアが閉まります。戻って見つけてください。
 Goat Simulator 3 で帝国の墓ミッションをクリアする方法
Mar 11, 2024 pm 01:10 PM
Goat Simulator 3 で帝国の墓ミッションをクリアする方法
Mar 11, 2024 pm 01:10 PM
Goat Simulator 3 は、古典的なシミュレーション ゲームプレイを備えたゲームで、プレイヤーはカジュアル アクション シミュレーションの楽しさを十分に体験できます。ゲームには多くのエキサイティングな特別なタスクも用意されています。その中でも、Goat Simulator 3 帝国の墓のタスクでは、プレイヤーは鐘楼を見つける必要があります。プレイヤーの中には、3 つの時計を同時に操作する方法がわからない人もいます。Goat Simulator 3 の Tomb of the Tomb ミッションのガイドは次のとおりです! Goat Simulator 3 の Tomb of the Tomb ミッションのガイドは、鐘を鳴らすことです。順番に。詳細な手順の拡張 1. まず、プレイヤーはマップを開いて梧丘墓地に行く必要があります。 2.鐘楼に上がると、中には鐘が3つあります。 3. 次に、大きいものから小さいものの順に、222312312 の類似度をたどります。 4. ノックが完了したら、ミッションを完了し、ドアを開けてライトセーバーを入手できます。
 修正: Windows タスク スケジューラでのオペレーター拒否要求エラー
Aug 01, 2023 pm 08:43 PM
修正: Windows タスク スケジューラでのオペレーター拒否要求エラー
Aug 01, 2023 pm 08:43 PM
タスクを自動化し、複数のシステムを管理するには、ミッション計画ソフトウェアは、特にシステム管理者にとって貴重なツールです。 Windows タスク スケジューラはその仕事を完璧に実行しますが、最近多くの人がオペレーターによる要求拒否エラーを報告しています。この問題はオペレーティング システムのすべてのバージョンに存在し、広く報告され取り上げられていますが、効果的な解決策はありません。他の人にとって実際に何が役立つかを知るために読み続けてください!オペレーターまたは管理者によって拒否されたタスク スケジューラ 0x800710e0 のリクエストは何ですか?タスク スケジューラを使用すると、ユーザーの入力なしでさまざまなタスクやアプリケーションを自動化できます。これを使用して、特定のアプリケーションのスケジュールと整理、自動通知の構成、メッセージ配信の支援などを行うことができます。それ
 Goat Simulator 3 でスティーブ救出ミッションを実行する方法
Feb 25, 2024 pm 03:34 PM
Goat Simulator 3 でスティーブ救出ミッションを実行する方法
Feb 25, 2024 pm 03:34 PM
スティーブの救出は、Goat Simulator 3 のユニークなタスクです。それを完了するには、具体的に何をする必要がありますか? このタスクは比較的単純ですが、意味を誤解しないように注意する必要があります。ここでは、Goat のスティーブの救出について説明します。 Simulator 3 のタスク戦略は、関連タスクをより効率的に完了するのに役立ちます。 Goat Simulator 3 スティーブ救出ミッション 攻略 1. まずはマップ右下の温泉に来ます。 2. 温泉に到着したら、スティーブを救出するタスクをトリガーできます。 3. 温泉にはスティーブという男性がいますが、このミッションの対象ではありません。 4. この温泉でスティーブという名前の魚を見つけて陸に上げてこのタスクを完了します。
 Douyin ファン グループのタスクはどこで見つけられますか? Douyinファンクラブのレベルは下がりますか?
Mar 07, 2024 pm 05:25 PM
Douyin ファン グループのタスクはどこで見つけられますか? Douyinファンクラブのレベルは下がりますか?
Mar 07, 2024 pm 05:25 PM
TikTok は、現在最も人気のあるソーシャル メディア プラットフォームの 1 つとして、多くのユーザーが参加しています。 Douyin には、ユーザーが特定の報酬や特典を得るために完了できるファン グループのタスクが多数あります。では、Douyin ファンクラブのタスクはどこで見つけられるのでしょうか? 1.Douyin ファンクラブのタスクはどこで確認できますか? Douyin ファン グループのタスクを見つけるには、Douyin の個人ホームページにアクセスする必要があります。ホームページに「ファンクラブ」という項目があります。このオプションをクリックすると、参加しているファン グループと関連タスクを参照できます。ファンクラブのタスク欄には、「いいね!」、コメント、共有、転送など、さまざまな種類のタスクが表示されます。各タスクには対応する報酬と要件があり、通常、タスクを完了すると、一定量の金貨または経験値を受け取ります。
 ORB-SLAM3を超えて! SL-SLAM: 低照度、重度のジッター、弱いテクスチャのシーンはすべて処理されます。
May 30, 2024 am 09:35 AM
ORB-SLAM3を超えて! SL-SLAM: 低照度、重度のジッター、弱いテクスチャのシーンはすべて処理されます。
May 30, 2024 am 09:35 AM
以前に書きましたが、今日は、深層学習テクノロジーが複雑な環境におけるビジョンベースの SLAM (同時ローカリゼーションとマッピング) のパフォーマンスをどのように向上させることができるかについて説明します。ここでは、深部特徴抽出と深度マッチング手法を組み合わせることで、低照度条件、動的照明、テクスチャの弱い領域、激しいセックスなどの困難なシナリオでの適応を改善するように設計された多用途のハイブリッド ビジュアル SLAM システムを紹介します。当社のシステムは、拡張単眼、ステレオ、単眼慣性、ステレオ慣性構成を含む複数のモードをサポートしています。さらに、他の研究にインスピレーションを与えるために、ビジュアル SLAM と深層学習手法を組み合わせる方法も分析します。公開データセットと自己サンプリングデータに関する広範な実験を通じて、測位精度と追跡堅牢性の点で SL-SLAM の優位性を実証しました。
 NeRFとは何ですか? NeRF ベースの 3D 再構成はボクセルベースですか?
Oct 16, 2023 am 11:33 AM
NeRFとは何ですか? NeRF ベースの 3D 再構成はボクセルベースですか?
Oct 16, 2023 am 11:33 AM
1 はじめに Neural Radiation Fields (NeRF) は、深層学習とコンピューター ビジョンの分野におけるかなり新しいパラダイムです。この技術は、ECCV2020 の論文「NeRF: Representing Scenes as Neural Radiation Fields for View Synthesis」(最優秀論文賞を受賞) で紹介され、それ以来非常に人気となり、現在までに 800 件近く引用されています [1]。このアプローチは、機械学習による 3D データの従来の処理方法に大きな変化をもたらします。神経放射線場のシーン表現と微分可能なレンダリング プロセス: カメラ光線に沿って 5D 座標 (位置と視線方向) をサンプリングして画像を合成し、これらの位置を MLP に入力して色と体積密度を生成し、体積レンダリング技術を使用してこれらの値を合成します。 ; レンダリング関数は微分可能であるため、渡すことができます。
 タイミング分析ペンタゴンウォリアー!清華大学が TimesNet を提案: 予測、充填、分類、検出をリード
Apr 11, 2023 pm 07:34 PM
タイミング分析ペンタゴンウォリアー!清華大学が TimesNet を提案: 予測、充填、分類、検出をリード
Apr 11, 2023 pm 07:34 PM
タスクの普遍性を達成することは、基本的な深層学習モデルの研究における中心的な課題であり、最近の大規模モデルの方向性における主な焦点の 1 つでもあります。しかし、時系列の分野では、きめ細かいモデリングが必要な予測タスクや、高度な意味情報の抽出が必要な分類タスクなど、分析タスクの種類は多岐にわたります。さまざまなタイミング解析タスクを効率的に完了するための統合された深い基本モデルを構築する方法はまだ確立されていません。この目的を達成するために、清華大学ソフトウェア学部のチームは、タイミング変更モデリングの基本的な問題に関する研究を実施し、タスク汎用タイミング基本モデルである TimesNet を提案し、この論文は ICLR 2023 に受理されました。著者リスト: Wu Haixu*、Hu Tengge*、Liu Yong*、Zhou Hang、Wang Jianmin、Long Mingsheng リンク: https://ope
