

自動運転車の開発と検証を加速: DRIVE Replicator 合成データ生成テクノロジーを詳しく見る

9 月に開催された GTC カンファレンスで、NVIDIA プロダクト マネージャーの Gautham Sholingar は、「合成データの生成: 自己データの開発と検証の加速」というタイトルで、過去 1 年間の NVIDIA のロングテール シナリオ トレーニングにおける最新の開発について完全に紹介しました。 「Driving Vehicles」の進捗状況と関連エクスペリエンス。特に、開発者が DRIVE Replicator を使用して正確なグラウンドトゥルース データ ラベルを持つ多様な合成データセットを生成し、自動運転車の開発と検証を加速する方法を検討します。この講演は有益な情報に満ちており、業界内で幅広い注目と議論を引き起こしました。この記事では、DRIVE Replicator と自動運転認識アルゴリズムの合成データ生成について誰もがより深く理解できるように、この共有の本質を要約して整理します。

図 1
過去 1 年間、NVIDIA は DRIVE Replicator を使用して、自動運転認識アルゴリズムをトレーニングするためのデータを生成してきました。合成データセットに関しては前向きな進歩が見られました。図 1 は、NVIDIA が現在解決しているロングテール シナリオの課題の一部を示しています。
- 左側の最初の行は、バック カメラの近くにある交通弱者 (VRU) を示しています。 VRU は、自動運転認識アルゴリズムにとって重要なオブジェクト クラスです。この場合、反転魚眼カメラの近くの子供を検出することに焦点を当てます。現実世界におけるデータの収集とデータのラベル付けは非常に困難であるため、これは重要なセキュリティの使用例です。
- 最初の行の中央の図は、事故車両の検出を示しています。自動運転認識アルゴリズムは、物体検出アルゴリズムの信頼性を高めるために、まれで珍しい場面にさらされる必要があります。現実世界のデータセットには事故車両はほとんどありません。 DRIVE Replicator は、開発者がさまざまな環境条件下で予期しないイベント (車の横転など) を作成できるようにすることで、このようなネットワークのトレーニングを支援します。
- 最初の行の右側の図は、交通標識の検出を示しています。場合によっては、データに手動でラベルを付けると時間がかかり、エラーが発生しやすくなります。 DRIVE Replicator は、開発者がさまざまな環境条件で数百の交通標識や信号機のデータセットを生成し、現実世界のさまざまな問題を解決するためにネットワークを迅速にトレーニングするのに役立ちます。
- 最後に、特定の交通用支柱や特定の種類の車両など、都市環境では一般的ではないオブジェクトが多数あります。 DRIVE Replicator は、開発者がデータセット内のこれらの希少オブジェクトの頻度を高め、ターゲットを絞った合成データで現実世界のデータ収集を強化するのに役立ちます。
上記の機能は、NVIDIA DRIVE Replicator を通じて実装されています。
DRIVE Replicator とその関連エコシステムを理解する
DRIVE Replicator は DRIVE Sim ツール スイートの一部であり、自動運転シミュレーションに使用できます。
DRIVE Sim は、Omniverse 上に構築された NVIDIA の主要な自動運転車シミュレーターであり、物理的に正確なセンサー シミュレーションを大規模に実行できます。開発者は、ワークステーションで反復可能なシミュレーションを実行し、データセンターまたはクラウドでバッチ モードに拡張できます。 DRIVE Sim は、USD などの強力なオープン標準に基づいて構築されたモジュラー プラットフォームで、ユーザーは Omniverse 拡張機能を通じて独自の機能を導入できます。
DRIVE Sim には、DRIVE Replicator を含む複数のアプリが含まれています。 DRIVE Replicator は主に、自動運転車のトレーニングとアルゴリズム検証のための合成データの生成に焦点を当てた一連の機能を提供します。 DRIVE Sim と DRIVE Constellation は、ソフトウェアインザループ、ハードウェアインザループ、その他のインザループ シミュレーション テスト (モデル、プラント、人間、もっと)。
DRIVE Sim と従来の自動運転シミュレーション ツールの違いは、合成データ セットを作成するときに、十分に現実的なシーンを復元するために、従来の自動運転シミュレーション ツールがプロのゲーム エンジンと組み合わされることが多いことです。しかし、自動運転シミュレーションの場合、これでは十分とはいえず、物理的精度、再現性、規模などの中核となる要件に対処する必要があります。

図 2
DRIVE Replicator をさらに紹介する前に、まずいくつかの関連概念を紹介します (図 2)。特に Omniverse、 DRIVE Replicator に関連する基礎的な技術サポートを誰もがより深く理解できるようにします。
まず、NVIDIA の大規模シミュレーション用エンジンである Omniverse について学びます。 Omniverse は、ピクサーによって開発された USD (Universal Scene description、仮想世界を記述するための拡張可能な汎用言語) に基づいて構築されています。 USD は、シミュレーション全体とシミュレーションのあらゆる側面 (センサー、3D 環境を含む) の真理値データの単一ソースです。USD を通じて完全に構築されたこれらのシーンにより、開発者はシミュレーション内のすべての要素に階層的にアクセスし、さまざまなデータを生成できます。後続の世代のためのデータ。特殊な合成データ セットの基礎を築きます。
2 番目に、Omniverse は、DRIVE Sim のセンサーをサポートするリアルタイム レイ トレーシング エフェクトを提供します。 RTX は、コンピューテーショナル グラフィックスにおける NVIDIA の重要な進歩の 1 つであり、物理的精度に重点を置いた最適化されたレイ トレーシング API を利用して、カメラ、LIDAR、ミリ波レーダー、超音波センサー (複数の反射、マルチパス効果、ローリング シャッターなど) の複雑な動作を保証します。レンズの歪み) はネイティブにモデル化されます。
3 番目に、NVIDIA Omniverse は、仮想コラボレーションと物理的に正確なリアルタイム シミュレーション用に設計された、簡単にスケーラブルなオープン プラットフォームであり、クラウドまたはデータ センターでワークフローを実行し、マルチ GPU とノードの並列処理を実現できます。世代。
第 4 に、Omniverse と DRIVE Sim はオープンでモジュラー設計を採用しており、このプラットフォームを中心に巨大なパートナー エコシステムが形成されています。これらのパートナーは、3D マテリアル、センサー、車両および交通モデル、検証ツールなどを提供できます。
5 番目に、Omniverse コラボレーションの中核となるのは Nucleus です。Nucleus にはデータ ストレージとアクセス制御機能があり、 DRIVE Sim を使用した一元化されたコンテンツ リポジトリにより、ランタイムをコンテンツから分離し、バージョン管理を改善し、すべてのフッテージ、シーン、メタデータの単一の参照ポイントを作成します。
DRIVE Sim はプラットフォームです。NVIDIA は環境協力アプローチを採用してプラットフォームを構築し、パートナーがこのユニバーサル プラットフォームに貢献できるようにします。現在、DRIVE Sim は 3D アセット、環境センサーモデル、検証などの分野をカバーする巨大なパートナーエコシステムを確立しています。 DRIVE Sim SDK を使用すると、パートナーは独自のセンサー、交通、車両ダイナミクス モデルを簡単に導入し、コア シミュレーション機能を拡張できます。開発者は、Omniverse で拡張機能を作成し、新しい機能を簡単に追加できるだけでなく、共通のプラットフォームで開発する利点も享受できます。Omniverse は、自動運転開発フローに関連する重要な作業を提供するいくつかの主要パートナーを結び付けています。
DRIVE Replicator を使用して合成データ セットと真の値データを生成する方法
次に、上記の内容がどのように組み合わされるか、および合成データを生成するための DRIVE Replicator の 5 つの主なタスクについて説明します。ステップ (図 3): コンテンツ - DRIVE Sim ランタイム - センシング - ランダム化 - データ ライター。
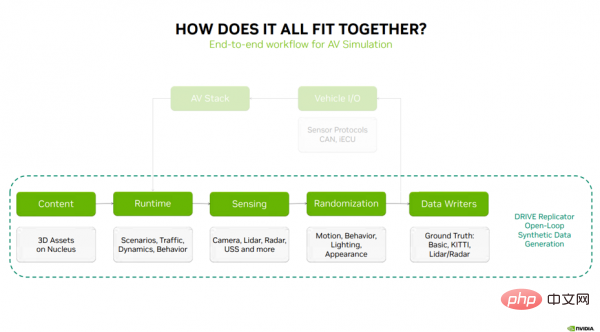
図 3
シミュレーション プロセスの最初のステップは、3D コンテンツとマテリアルを Nucleus サーバーに保存することです。これらの資産は、シナリオ、交通モデル、車両ダイナミクス、動作を実行するためのコアテクノロジーである DRIVE Sim Runtime に渡されます。 DRIVE Sim Runtime は、RTX レイ トレーシング ベースのカメラ、LIDAR、ミリ波レーダー、および USS の認識テクノロジーとともに使用できます。次のステップは、動き、動作、照明、外観のランダム化を通じてデータに多様性を導入することです。閉ループ シミュレーションの場合、次のステップは、車両 I/O を介してシミュレーションを自動運転スタックに接続することです。車両 I/O は通常、センサー プロトコル、CAN メッセージ、仮想 ECU で構成されます (重要な情報を自動運転スタックに送信し、ループを閉じます)。
合成データ生成の場合、これはランダム化されたセンサー データをデータ ライターに送信する開ループ プロセスであり、これらのデータ ライターは自動運転の知覚をトレーニングするためにアルゴリズムの真実のラベルを出力できます。上記の手順は、合成データ生成の完全なワークフローを表しています。
- コンテンツ (コンテンツ)
前述したように、シミュレーション プロセスの最初のステップは、Nucleus サーバーに保存されている 3D コンテンツとマテリアルです。 。このコンテンツはどこから来たのでしょうか?入手方法は?基準や要件は何ですか?
過去数年間、NVIDIA は複数のコンテンツ パートナーと協力して、車両、小道具、歩行者、植生、3D 環境を含む 3D アセット プロバイダーの広大なエコシステムを構築してきました。これらは、DRIVE Sim で使用できるように準備されています。 。
注意すべき点は、これらのアセットを市場から入手したからといって、シミュレーション作業を開始できるわけではなく、これらのアセットをシミュレーションできる状態にする必要があることです。これが SimReady の便利な場所です。
拡張の重要な部分は、3D アセット プロバイダーと協力し、特定の規則、命名、アセット リギング、セマンティック ラベル、および物理プロパティを保証するために必要なツールを提供することです。
SimReady Studio は、コンテンツ プロバイダーが既存のアセットを、3D 環境、動的アセット、静的プロップなどの DRIVE Sim にロードできるシミュレーション対応の USD アセットに変換するのに役立ちます。
それでは、SimReady とは何ですか?これは、DRIVE Sim および Replicator の 3D アセットがエンドツーエンドのシミュレーション ワークフローをサポートできるようにするためのコンバーターと考えることができます。 SimReady には、次のような重要な要素がいくつかあります。
- 各アセットは、一貫性を確保するために、向き、名前、ジオメトリなどに関する一連の規則に従う必要があります。
- セマンティック タグとウェルアセットの各要素に注釈を付けるために定義されたオントロジー。これは、知覚のためのグラウンド トゥルース ラベルを生成するために重要です。
- 剛体の物理学とダイナミクスのサポートにより、生成されたデータセットがリアルに見え、運動学の観点からシミュレーションと現実の間のギャップがなくなります。
- 次のステップは、アセットが特定のマテリアルと命名規則に従っていることを確認して、アセットが RTX レイ トレーシングに対応できるようにし、LIDAR、ミリ波レーダー、超音波センサーなどのアクティブ センサーに対して現実的な応答を生成できるようにすることです。側面は、照明の変更、ドアの作動、歩行者の歩行操作などを可能にする 3D アセットのリギングです。
- 最後の部分は、リアルタイムの高忠実度センサー シミュレーションのためのパフォーマンスの最適化です。
- 上記の理解に基づいて、SimReady Studio を使用して DRIVE Sim で使用できるアセットを取得する方法のプロセスを見てみましょう。
このプロセスは、3D マーケットからアセットを購入することから始まると仮定します。最初のステップは、このアセットを SimReady Studio にインポートすることです。これは、一括で実行することも、複数のアセットをバッチインポートしてこのステップを完了することもできます。
インポート後、これらのコンテンツ アセットのマテリアル名が更新され、マテリアル プロパティも更新され、反射率や粗さなどのプロパティが含まれるように拡張されます。
これは、物理的に現実的なレンダリング データの品質を確保し、マテリアル システムが可視スペクトルで動作するものだけでなく、すべての RTX センサー タイプと相互作用することを保証するために重要です。
次のステップでは、セマンティック タグとタグを更新します。このステップがなぜ重要なのでしょうか?適切なラベルがあるということは、アセットを使用して生成されたデータを AV アルゴリズムのトレーニングに使用できることを意味します。さらに、DRIVE Sim と Omniverse は、中央資産リポジトリとして Nucleus を使用します。 Nucleus には何千ものコンテンツ アセットがあり、検索可能なタグと関連するサムネイルがあれば、新しいユーザーがアセットを見つけやすくなります。
次に、オブジェクトの衝突ボリュームとジオメトリの定義を開始し、物理的な観点からコンテンツ アセットがどのように動作するかを観察します。次に、オブジェクトの物理特性と質量特性を変更して、目的の動作を作成します。
プロセス全体の最後のステップは、アセットを検証して、これらのコンテンツ アセットが正しい規則に従っていることを確認することです。シミュレーション対応の USD アセットを保存し、NVIDIA Omniverse および DRIVE Sim に再インポートできるようになりました。 USD 経由でシーンを構築する最大の利点は、前の手順で作成されたすべてのメタデータが最終アセットとともに転送され、メイン オブジェクトの USD に階層的にリンクされ、その後のさまざまな合成データセットの生成の基礎を築くことです。
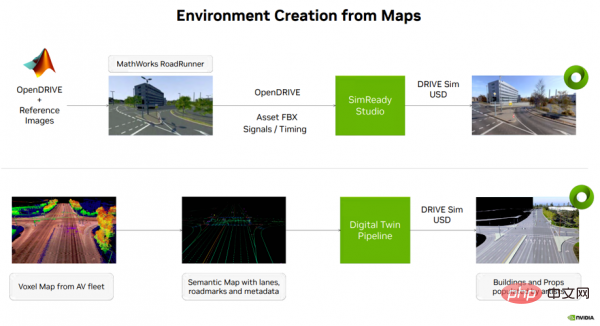
自動運転車シミュレーション コンテンツの作成に戻りますが、通常、マップから環境を作成するにはいくつかの方法があります。データです (図 4 を参照)。 1 つのオプションは、MathWorks の Roadrunner ツールを使用して、オープンな NVIDIA DRIVE マップ (マルチモーダル マップ プラットフォーム) 上に 3D 環境を作成することです。このステップの出力は、セマンティック マップ情報、信号タイミングなどとともに SimReady Studio に転送され、そこで 3D 環境を DRIVE Sim にロードできる USD アセットに変換できます。
もう 1 つのオプションは、自動運転車からのボクセル マップ データを使用し、車線、道路標識、その他のメタデータなどのセマンティック マップ情報を抽出することです。この情報はデジタル ツインを介して作成され、DRIVE Sim にロードできる USD 資産が生成されます。
上記の 2 種類の USD 環境は、自動運転車のエンドツーエンド (E2E) シミュレーション テストと合成データ生成ワークフローをサポートするために使用されます。
- DRIVE Sim ランタイム
- 次に、シミュレーションの 2 番目のステップである DRIVE Sim ランタイムについて紹介します。これは、DRIVE の基礎を築きます。レプリケーター 合成データセットの生成に使用される . のすべての関数の基礎。
DRIVE Sim Runtime は、オープンでモジュール式の拡張可能なコンポーネントです。これは実際には何を意味するのでしょうか (図 5 を参照)。
まず、これはシーンに基づいて構築されており、開発者はシーン内のオブジェクトの特定の位置、動き、および相互作用を定義できます。これらのシナリオは、Python またはシナリオ エディター UI を使用して定義し、後で使用できるように保存できます。
2 番目に、プロセスのステップとして、または DRIVE Sim 2.0 との共同シミュレーションとして、DRIVE Sim SDK を介したカスタム ビークル ダイナミクス パッケージとの統合をサポートします。
3 番目は、トラフィック モデルです。 DRIVE Sim には豊富な車両モデル インターフェイスがあり、ランタイムの助けを借りて、開発者は独自の車両ダイナミクスを導入したり、既存のルールベースの交通モデルを構成したりできます。
4 番目は、アクション システムです。これには、事前定義されたアクション (車線変更など) の豊富なライブラリ、さまざまなオブジェクト間のインタラクション シーンの作成に使用できるタイム トリガーなどが含まれます。
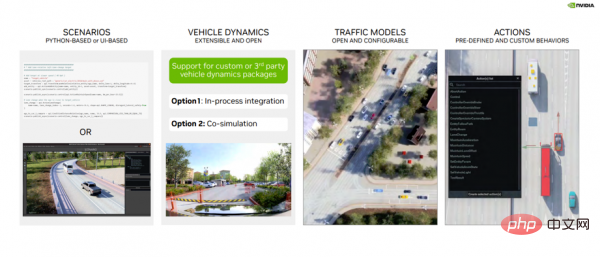
図 5
前の内容を簡単に復習しましょう。シミュレーション プロセスの最初のステップ、SimReady 変換後、シミュレーションの準備完了3D コンテンツとアセットは Nucleus サーバーに保存されます。 2 番目のステップでは、これらのマテリアルが DRIVE Sim Runtime に渡されます。DRIVE Sim Runtime は、シナリオ、交通モデル、車両ダイナミクス、挙動を実行するための中核テクノロジーであり、合成データ セットを生成する後続のすべての機能の基礎を築きます。
- センシング
データを生成する前に、センサーを使用して対象の試験車両をセットアップする必要があります。 Ego Configurator ツールを使用すると、開発者は特定の車両を選択し、シーンに追加できます。
さらに、開発者はシーン内で車両を移動させたり、車両にセンサーを追加したりすることもできます。 Ego コンフィギュレータ ツールは、ユニバーサル センサーと Hyperion 8 センサーをサポートしています。
センサーを車両に追加した後、開発者は、FOV、解像度、センサー名などのパラメーターを変更し、車両上のセンサーの位置を直感的に構成することもできます。
ユーザーは、データ生成シーンを作成する前に、センサー POV からプレビューを表示し、3D 環境で視野を視覚化することもできます。
このツールは、開発者がさまざまな構成のプロトタイプを迅速に作成し、センシング タスクによって達成されるカバレッジを視覚化するのに役立ちます。
- ランダム化 (ドメインのランダム化)
次に、シミュレーション プロセスの 4 番目のステップであるドメインのランダム化、モーションと動作を渡す方法を簡単に紹介します。 、データに多様性を導入するために照明と外観をランダム化します。
これには、Python を使用してシーンを作成する別の方法が含まれます。 DRIVE Replicator の Python API を使用すると、開発者はオープンな NVIDIA DRIVE マップをクエリし、コンテキストを認識した方法で静的および動的アセットの範囲を配置できます。一部のランダマイザーは、自律走行車をある地点から次の地点にテレポートする方法、自律走行車の周囲にオブジェクトを生成する方法、そしてそこからさまざまな合成データセットを生成する方法に焦点を当てます。ユーザーは USD シーンとその環境内のすべてのオブジェクトを直接制御できるため、これらの複雑に聞こえる操作は簡単に実行できます。
トレーニング用の合成データセットを作成する際のもう 1 つの重要なステップは、3D シーンの外観に変化を導入できることです。 USD の強力な機能についても前述しましたが、たとえば、USD を通じて構築されたシナリオでは、開発者はシミュレーション内のすべての要素に階層的にアクセスできます。 SimReady の API は USD を使用して、シーン内の機能を迅速にセットアップします。
例を見てみましょう (図 6 を参照)。路面は少し濡れていますが、さまざまなパラメータを設定すると、路面の濡れ度が変化します。太陽方位や太陽高度などの側面にも同様の変更を加えて、さまざまな環境条件下で現実的なデータセットを生成できます。
もう 1 つのポイントは、照明と外観の変更を可能にする機能です。これらはすべて SimReady API と USD を通じて利用できます。

#図 6
#DRIVE Sim の主な利点の 1 つは、さまざまなセンサーをサポートする RTX センサー ワークフローです。 (図 7 を参照)。これには、カメラ、LIDAR、従来のレーダー、USS 用の汎用モデルと既製モデルが含まれます。さらに、DRIVE Sim は NVIDIA DRIVE Hyperion センサー スイートの完全なサポートを提供し、ユーザーが仮想環境でアルゴリズムの開発と検証作業を開始できるようにします。さらに、DRIVE Sim には、パートナーが IP および独自のアルゴリズムを保護しながら、NVIDIA のレイ トレーシング API を使用して複雑なセンサー モデルを実装できるようにする強力で多用途の SDK が備わっています。このエコシステムは長年にわたって成長しており、NVIDIA はパートナーと協力して、イメージング レーダー、FMCW LIDAR などの新しいタイプのセンサーを DRIVE Sim に導入しています。

#図 7
- データ ライター
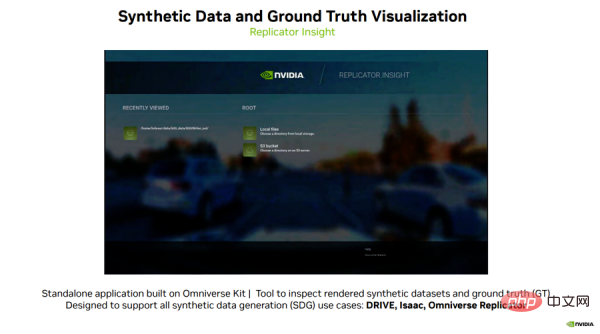
図 8
この視覚化ツールを使用すると、ユーザーはビデオを再生したり、データ セットを調べたり、深度や RGB を表示したりすることもできます。データを取得し、異なるビュー間で比較します。 ユーザーは、再生フレーム レートや深度範囲などのパラメーターを変更したり、自動運転車のトレーニング前にデータ セットをすばやく視覚化したりすることもできます。 これにより、開発者は新しい真理ラベル タイプを簡単に理解し、複雑なデータ セットを解析することができます。 全体として、これはユーザーが本物か合成かにかかわらず、データを見るたびに新しい洞察を得ることができる強力なツールです。 概要上記は、過去 1 年間の DRIVE Replicator の最新開発を要約し、開発者が DRIVE Replicator を使用して多様な合成データ セットと正確なグラウンド トゥルース データ タグを生成し、自動運転車の開発と検証。 NVIDIA は、現実世界のさまざまなユースケース向けに高品質のセンサー データ セットの生成において素晴らしい進歩を遂げており、皆様とのさらなるコミュニケーションを楽しみにしています。以上が自動運転車の開発と検証を加速: DRIVE Replicator 合成データ生成テクノロジーを詳しく見るの詳細内容です。詳細については、PHP 中国語 Web サイトの他の関連記事を参照してください。

ホットAIツール

Undresser.AI Undress
リアルなヌード写真を作成する AI 搭載アプリ

AI Clothes Remover
写真から衣服を削除するオンライン AI ツール。

Undress AI Tool
脱衣画像を無料で

Clothoff.io
AI衣類リムーバー

Video Face Swap
完全無料の AI 顔交換ツールを使用して、あらゆるビデオの顔を簡単に交換できます。

人気の記事
ホットツール

メモ帳++7.3.1
使いやすく無料のコードエディター

SublimeText3 中国語版
中国語版、とても使いやすい

ゼンドスタジオ 13.0.1
強力な PHP 統合開発環境

ドリームウィーバー CS6
ビジュアル Web 開発ツール

SublimeText3 Mac版
神レベルのコード編集ソフト(SublimeText3)
ホットトピック
 1657
1657
 14
1415
52
1309
25
1257
29
1230
24
14
1415
52
1309
25
1257
29
1230
24

 自動運転シナリオにおけるロングテール問題を解決するにはどうすればよいでしょうか?
Jun 02, 2024 pm 02:44 PM
自動運転シナリオにおけるロングテール問題を解決するにはどうすればよいでしょうか?
Jun 02, 2024 pm 02:44 PM
昨日の面接で、ロングテール関連の質問をしたかと聞かれたので、簡単にまとめてみようと思いました。自動運転のロングテール問題とは、自動運転車におけるエッジケース、つまり発生確率が低い考えられるシナリオを指します。認識されているロングテール問題は、現在、単一車両のインテリジェント自動運転車の運用設計領域を制限している主な理由の 1 つです。自動運転の基礎となるアーキテクチャとほとんどの技術的問題は解決されており、残りの 5% のロングテール問題が徐々に自動運転の開発を制限する鍵となってきています。これらの問題には、さまざまな断片的なシナリオ、極端な状況、予測不可能な人間の行動が含まれます。自動運転におけるエッジ シナリオの「ロング テール」とは、自動運転車 (AV) におけるエッジ ケースを指します。エッジ ケースは、発生確率が低い可能性のあるシナリオです。これらの珍しい出来事
 CLIP-BEVFormer: BEVFormer 構造を明示的に監視して、ロングテール検出パフォーマンスを向上させます。
Mar 26, 2024 pm 12:41 PM
CLIP-BEVFormer: BEVFormer 構造を明示的に監視して、ロングテール検出パフォーマンスを向上させます。
Mar 26, 2024 pm 12:41 PM
上記および筆者の個人的な理解: 現在、自動運転システム全体において、認識モジュールが重要な役割を果たしている。道路を走行する自動運転車は、認識モジュールを通じてのみ正確な認識結果を得ることができる。下流の規制および制御モジュール自動運転システムでは、タイムリーかつ正確な判断と行動決定が行われます。現在、自動運転機能を備えた自動車には通常、サラウンドビューカメラセンサー、ライダーセンサー、ミリ波レーダーセンサーなどのさまざまなデータ情報センサーが搭載されており、さまざまなモダリティで情報を収集して正確な認識タスクを実現しています。純粋な視覚に基づく BEV 認識アルゴリズムは、ハードウェア コストが低く導入が容易であるため、業界で好まれており、その出力結果はさまざまな下流タスクに簡単に適用できます。
 自動運転と軌道予測についてはこの記事を読めば十分です!
Feb 28, 2024 pm 07:20 PM
自動運転と軌道予測についてはこの記事を読めば十分です!
Feb 28, 2024 pm 07:20 PM
自動運転では軌道予測が重要な役割を果たしており、自動運転軌道予測とは、車両の走行過程におけるさまざまなデータを分析し、将来の車両の走行軌跡を予測することを指します。自動運転のコアモジュールとして、軌道予測の品質は下流の計画制御にとって非常に重要です。軌道予測タスクには豊富な技術スタックがあり、自動運転の動的/静的知覚、高精度地図、車線境界線、ニューラル ネットワーク アーキテクチャ (CNN&GNN&Transformer) スキルなどに精通している必要があります。始めるのは非常に困難です。多くのファンは、できるだけ早く軌道予測を始めて、落とし穴を避けたいと考えています。今日は、軌道予測に関するよくある問題と入門的な学習方法を取り上げます。関連知識の紹介 1. プレビュー用紙は整っていますか? A: まずアンケートを見てください。
 エンドツーエンドおよび次世代の自動運転システムと、エンドツーエンドの自動運転に関する誤解について話しましょう。
Apr 15, 2024 pm 04:13 PM
エンドツーエンドおよび次世代の自動運転システムと、エンドツーエンドの自動運転に関する誤解について話しましょう。
Apr 15, 2024 pm 04:13 PM
この 1 か月間、いくつかのよく知られた理由により、私は業界のさまざまな教師やクラスメートと非常に集中的な交流をしてきました。この交換で避けられない話題は当然、エンドツーエンドと人気の Tesla FSDV12 です。この機会に、現時点での私の考えや意見を整理し、皆様のご参考とご議論に役立てたいと思います。エンドツーエンドの自動運転システムをどのように定義するか、またエンドツーエンドで解決することが期待される問題は何でしょうか?最も伝統的な定義によれば、エンドツーエンド システムとは、センサーから生の情報を入力し、関心のある変数をタスクに直接出力するシステムを指します。たとえば、画像認識では、従来の特徴抽出 + 分類子方式と比較して、CNN はエンドツーエンドと言えます。自動運転タスクでは、各種センサー(カメラ/LiDAR)からのデータを入力
 C++ での機械学習アルゴリズムの実装: 一般的な課題と解決策
Jun 03, 2024 pm 01:25 PM
C++ での機械学習アルゴリズムの実装: 一般的な課題と解決策
Jun 03, 2024 pm 01:25 PM
C++ の機械学習アルゴリズムが直面する一般的な課題には、メモリ管理、マルチスレッド、パフォーマンスの最適化、保守性などがあります。解決策には、スマート ポインター、最新のスレッド ライブラリ、SIMD 命令、サードパーティ ライブラリの使用、コーディング スタイル ガイドラインの遵守、自動化ツールの使用が含まれます。実践的な事例では、Eigen ライブラリを使用して線形回帰アルゴリズムを実装し、メモリを効果的に管理し、高性能の行列演算を使用する方法を示します。
 FisheyeDetNet: 魚眼カメラに基づいた最初のターゲット検出アルゴリズム
Apr 26, 2024 am 11:37 AM
FisheyeDetNet: 魚眼カメラに基づいた最初のターゲット検出アルゴリズム
Apr 26, 2024 am 11:37 AM
目標検出は自動運転システムにおいて比較的成熟した問題であり、その中でも歩行者検出は最も初期に導入されたアルゴリズムの 1 つです。ほとんどの論文では非常に包括的な研究が行われています。ただし、サラウンドビューに魚眼カメラを使用した距離認識については、あまり研究されていません。放射状の歪みが大きいため、標準のバウンディング ボックス表現を魚眼カメラに実装するのは困難です。上記の説明を軽減するために、拡張バウンディング ボックス、楕円、および一般的な多角形の設計を極/角度表現に探索し、これらの表現を分析するためのインスタンス セグメンテーション mIOU メトリックを定義します。提案された多角形モデルの FisheyeDetNet は、他のモデルよりも優れたパフォーマンスを示し、同時に自動運転用の Valeo 魚眼カメラ データセットで 49.5% の mAP を達成しました。
 C++sort 関数の基礎となる原則とアルゴリズムの選択を調べる
Apr 02, 2024 pm 05:36 PM
C++sort 関数の基礎となる原則とアルゴリズムの選択を調べる
Apr 02, 2024 pm 05:36 PM
C++sort 関数の最下層はマージ ソートを使用し、その複雑さは O(nlogn) で、クイック ソート、ヒープ ソート、安定したソートなど、さまざまなソート アルゴリズムの選択肢を提供します。
 nuScenes の最新 SOTA | SparseAD: スパース クエリは効率的なエンドツーエンドの自動運転に役立ちます。
Apr 17, 2024 pm 06:22 PM
nuScenes の最新 SOTA | SparseAD: スパース クエリは効率的なエンドツーエンドの自動運転に役立ちます。
Apr 17, 2024 pm 06:22 PM
先頭と開始点に書かれている エンドツーエンドのパラダイムでは、統一されたフレームワークを使用して自動運転システムのマルチタスクを実現します。このパラダイムの単純さと明確さにも関わらず、サブタスクにおけるエンドツーエンドの自動運転手法のパフォーマンスは、依然としてシングルタスク手法に比べてはるかに遅れています。同時に、以前のエンドツーエンド手法で広く使用されていた高密度鳥瞰図 (BEV) 機能により、より多くのモダリティやタスクに拡張することが困難になります。ここでは、スパース検索中心のエンドツーエンド自動運転パラダイム (SparseAD) が提案されています。このパラダイムでは、スパース検索は、高密度の BEV 表現を使用せずに、空間、時間、タスクを含む運転シナリオ全体を完全に表します。具体的には、統合されたスパース アーキテクチャが、検出、追跡、オンライン マッピングなどのタスク認識のために設計されています。さらに、重い
