

Kuaishou ユーザー維持率を向上させるために強化学習を使用する方法は?

短編ビデオ レコメンデーション システムの中核的な目標は、ユーザー維持率を向上させて DAU の増加を促進することです。したがって、リテンションは各 APP の中核となるビジネス最適化指標の 1 つです。ただし、リテンションはユーザーとシステムの間の複数のインタラクションを経た後の長期的なフィードバックであり、それを単一の項目または単一のリストに分解することは困難であるため、従来のポイント単位およびリスト単位のモデルでは、直接フィードバックを取得することが困難です。保持を最適化します。
強化学習 (RL) 手法は、環境と対話することで長期的な報酬を最適化し、ユーザー維持率を直接最適化するのに適しています。この研究では、リテンション最適化問題を、無限のホライズン要求粒度を備えたマルコフ決定プロセス (MDP) としてモデル化しています。ユーザーが推奨システムにアクションを決定するよう要求するたびに、複数の異なる短期フィードバック推定値 (視聴期間、視聴時間、いいね、注目、コメント、リツイートなど)ランキングモデルのスコアリング。この作業の目標は、ポリシーを学習し、複数のユーザー セッション間の累積時間間隔を最小限に抑え、アプリを開く頻度を増やし、それによってユーザー維持率を高めることです。
ただし、保持された信号の特性により、既存の RL アルゴリズムを直接適用するには次の課題があります。 1) 不確実性: 保持された信号は推奨アルゴリズムだけによって決定されるわけではありません。 、しかし、多くの外部要因によっても干渉されます; 2) バイアス: 保持シグナルには、さまざまな期間およびさまざまなレベルのアクティビティを持つユーザー グループによって偏差があります; 3) 不安定性: 報酬がすぐに返されるゲーム環境とは異なり、保持シグナルは通常数時間以内に返されます。これにより、RL アルゴリズムがオンラインになり、トレーニングが不安定になる問題が発生します。
この研究では、上記の課題を解決し、ユーザー維持を直接最適化するためのユーザー維持のための強化学習 (RLUR) アルゴリズムを提案します。 RLUR アルゴリズムは、オフラインおよびオンライン検証を通じて、最先端のベースラインと比較して二次保持指数を大幅に向上させることができます。 RLUR アルゴリズムは Kuaishou アプリに完全に実装されており、継続的に大幅な二次リテンションと DAU 収益を達成することができます。RL テクノロジーが実際の運用環境でのユーザー リテンションの向上に使用されたのは業界初です。この作品は WWW 2023 Industry Track に採用されました。

著者: Cai Qingpeng、Liu Shuchang、Wang Xueliang、Zuo Tianyou、Xie Wentao、Yang Bin、Zheng Dong、Jiang Peng
#論文アドレス: https://arxiv.org/pdf/2302.01724.pdf##問題モデリング
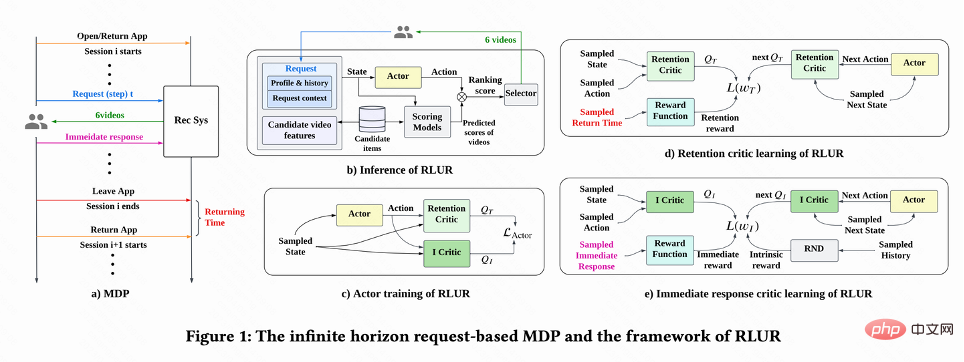
図 1(a) に示すように、この研究では、リテンション最適化問題を無限の地平線リクエストベースのマルコフ決定プロセスとしてモデル化します。このプロセスでは、推奨システムがエージェントであり、ユーザーが環境です。ユーザーがアプリを開くたびに、新しいセッション i が開かれます。図 1(b) に示すように、ユーザーが をリクエストするたびに、推奨システムはユーザーのステータス この研究では、最初に累積再訪問時間を推定する方法について説明し、次に、保持された信号のいくつかの重要な課題を解決する方法を提案します。これらの手法は、ユーザー維持のための強化学習アルゴリズム (RLUR と略称) にまとめられています。 #再訪問時間の推定 図 1(d) に示すように、動作は連続的であるため、この研究では、DDPG アルゴリズムの時間差 (TD) 学習方法を採用して再訪問時間を推定します。 各セッションの最後のリクエストのみに再訪問時間報酬があり、中間報酬は 0 であるため、作成者は割引係数 に基づいてパラメータ ベクトル
に基づいてパラメータ ベクトル  を決定します。 、n さまざまな短期指標 (視聴時間、いいね!、注目など) を推定するランキング モデルにより、各候補ビデオ j
を決定します。 、n さまざまな短期指標 (視聴時間、いいね!、注目など) を推定するランキング モデルにより、各候補ビデオ j がスコア付けされます。次に、並べ替え関数が各ビデオのアクションとスコア ベクトルを入力して各ビデオの最終スコアを取得し、最高スコアを持つ 6 つのビデオを選択してユーザーに表示します。ユーザーは即時にフィードバックを返します
がスコア付けされます。次に、並べ替え関数が各ビデオのアクションとスコア ベクトルを入力して各ビデオの最終スコアを取得し、最高スコアを持つ 6 つのビデオを選択してユーザーに表示します。ユーザーは即時にフィードバックを返します 。ユーザーがアプリを離れると、このセッションは終了します。次にユーザーがアプリを開いたときに、セッション i 1 が開きます。前のセッションの終了と次のセッションの開始の間の時間間隔は、復帰時間 (復帰時間) と呼ばれます。 )、
。ユーザーがアプリを離れると、このセッションは終了します。次にユーザーがアプリを開いたときに、セッション i 1 が開きます。前のセッションの終了と次のセッションの開始の間の時間間隔は、復帰時間 (復帰時間) と呼ばれます。 )、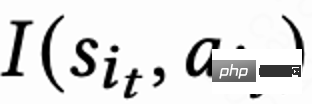 。この研究の目標は、複数のセッションのコールバック時間の合計を最小限に抑える戦略をトレーニングすることです。
。この研究の目標は、複数のセッションのコールバック時間の合計を最小限に抑える戦略をトレーニングすることです。 
RLUR アルゴリズム
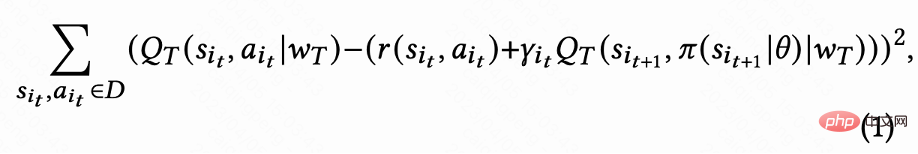
 各セッションの最後のリクエストの値は
各セッションの最後のリクエストの値は 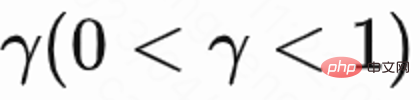 で、他のリクエストの値は 1 です。この設定により、再訪問時間の指数関数的な減衰を回避できます。そして、損失 (1) が 0 の場合、Q は実際に複数のセッションの累積復帰時間
で、他のリクエストの値は 1 です。この設定により、再訪問時間の指数関数的な減衰を回避できます。そして、損失 (1) が 0 の場合、Q は実際に複数のセッションの累積復帰時間 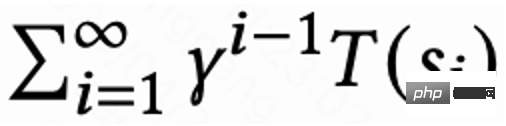 を推定することが理論的に証明できます。
を推定することが理論的に証明できます。
報酬遅延の問題を解決する
再訪問時間は次の時点でのみ発生するため、各セッションの終了が遅くなり、学習効率が低下するという問題が生じます。したがって、著者らはヒューリスティック報酬を使用してポリシー学習を強化します。短期フィードバックは定着率にプラスの関係があるため、著者は短期フィードバックを最初のヒューリスティック報酬として使用します。そして著者は、ランダム ネットワーク蒸留 (RND) ネットワークを採用して、2 番目のヒューリスティック報酬として各サンプルの固有報酬を計算します。具体的には、RND ネットワークは 2 つの同一のネットワーク構造を使用しており、一方のネットワークはランダムに固定に初期化され、もう一方のネットワークは固定ネットワークに適合し、フィッティング損失が固有の報酬として使用されます。図 1(e) に示すように、保持報酬に対するヒューリスティック報酬の干渉を減らすために、この研究では別の批評家ネットワークを学習して、短期フィードバックと本質的報酬の合計を推定します。今すぐ #########。 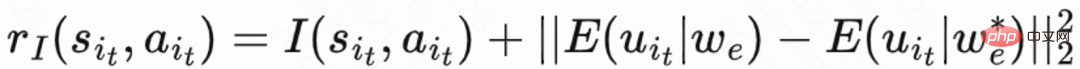
復帰時期により多くの推奨事項を受け取りました訪問 要因の影響により不確実性が高く、学習効果に影響を与えます。この研究では、分散を減らすための正則化方法を提案しています。最初に分類モデル
を推定して、再診時間の確率、つまり、推定された再診時間が より短いかどうかを推定します。  ; 次に、マルコフの不等式を使用して再診時間の下限を取得します。
; 次に、マルコフの不等式を使用して再診時間の下限を取得します。  ; 最後に、実際の再診時間/推定再診時間の下限を正規化された再診報酬として使用します。 。
; 最後に、実際の再診時間/推定再診時間の下限を正規化された再診報酬として使用します。 。 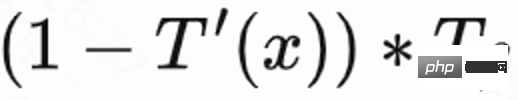
アクティブなグループごとに行動習慣が大きく異なるため、非常にアクティブなユーザー 維持率が高く、トレーニング サンプルの数が低アクティブ ユーザーよりも大幅に多いため、モデル学習が高アクティブ ユーザーによって支配されることになります。この問題を解決するために、この研究では、高アクティビティと低アクティビティの異なるグループに対して 2 つの独立した戦略を学習し、トレーニングに異なるデータ ストリームを使用し、アクターは補助報酬を最大化しながら再訪問時間を最小限に抑えます。図 1(c) に示すように、高アクティビティ グループを例にとると、アクターの損失は次のようになります。
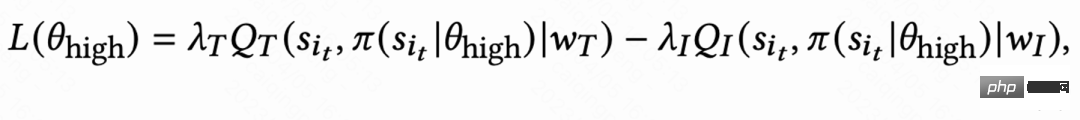
#不安定性の問題の解決
リターン信号遅延による訪問時間は通常、数時間から数日以内に戻ります。これにより、RL オンライン トレーニングが不安定になる可能性があります。既存の動作複製手法を直接使用すると、学習速度が大幅に制限されるか、安定した学習が保証されません。したがって、この研究では、新しいソフト正則化方法、つまりアクター損失にソフト正則化係数を乗算する方法を提案します。 #この正則化手法は本質的にブレーキ効果です。現在の学習戦略とサンプル戦略が大きく乖離している場合、損失は小さくなり、学習は安定する傾向があります。学習速度が安定している傾向がある場合、損失は減少します。大きくなればなるほど、学ぶのは早くなります。
の場合、学習プロセスに制限がないことを意味します。
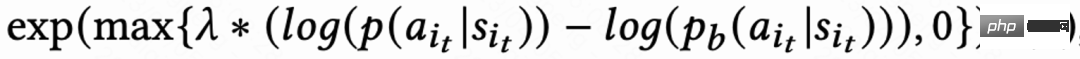
この研究では、RLUR と最先端の強化学習アルゴリズム TD3、およびブラックボックス最適化手法クロス エントロピー法 ( CEM) の公開データセット KuaiRand が比較に使用されます。この作業では、最初に KuaiRand データ セットに基づいてリテンション シミュレーターを構築します。これには、ユーザーの即時フィードバック、ユーザーのセッションからの退出、ユーザーのアプリへの再訪問という 3 つのモジュールが含まれており、次にリテンション シミュレーターのメソッドを評価します。 
#表 1 は、再訪問時間と二次リテンション指標の点で、RLUR が CEM や TD3 よりも大幅に優れていることを示しています。この研究では、アブレーション実験を実施して、RLUR を保持学習部分のみ (RLUR (naive)) と比較します。これは、保持の課題を解決するためのこの研究のアプローチの有効性を示すことができます。そして、
と
を比較すると、複数のセッションの再訪問時間を最小化するアルゴリズムの方が、セッションの再訪問時間を最小化するよりも優れていることが示されています。シングルセッション。 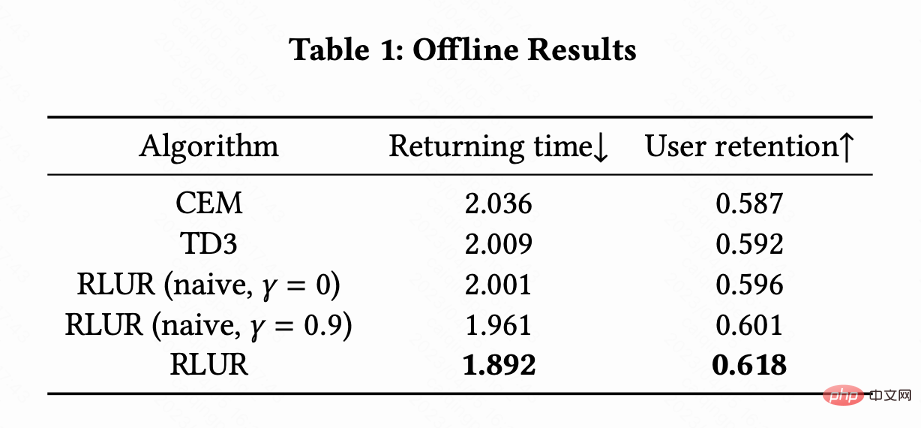
オンライン実験
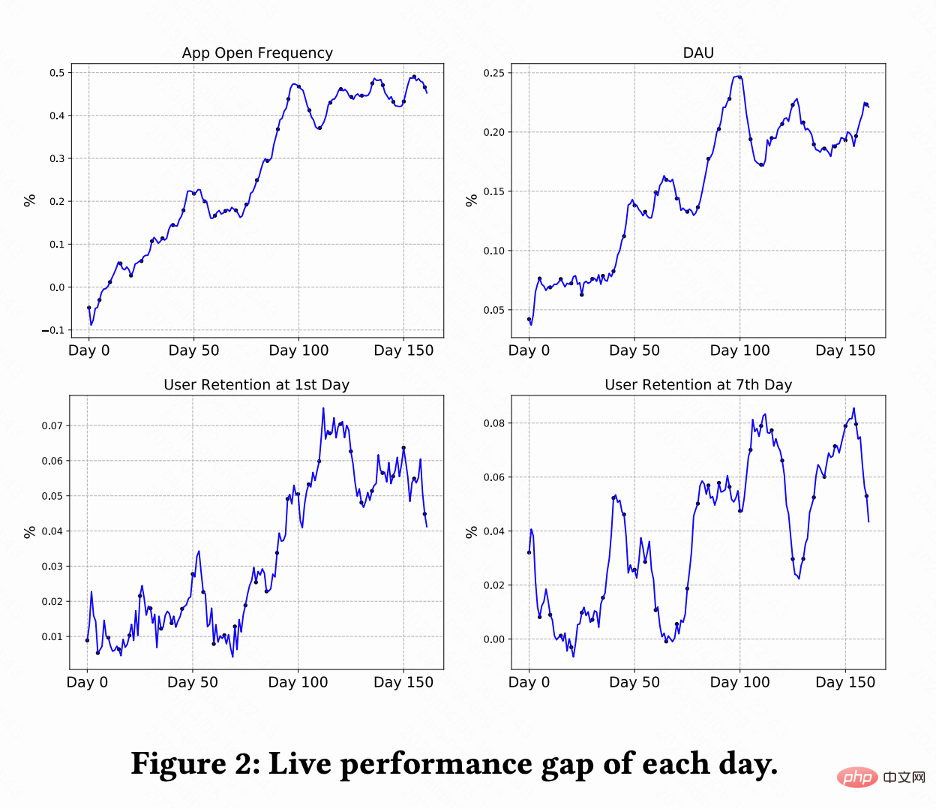
 この作業では、Kuaishou ショートビデオ レコメンデーション システムで A/B テストを実施し、RLUR を比較します。および CEM メソッド。図 2 は、RLUR と CEM とそれぞれ比較した、アプリの起動頻度、DAU、初回保持率、および 7 回目の保持率の改善率を示しています。アプリを開く頻度は徐々に増加し、0 日から 100 日にかけて収束することもあります。また、2 番目の保持率、7 番目の保持率、および DAU 指標の改善も促進します (0.1% の DAU と 2 番目の保持率の 0.01% の改善は、統計的に有意であると考えられます)。
この作業では、Kuaishou ショートビデオ レコメンデーション システムで A/B テストを実施し、RLUR を比較します。および CEM メソッド。図 2 は、RLUR と CEM とそれぞれ比較した、アプリの起動頻度、DAU、初回保持率、および 7 回目の保持率の改善率を示しています。アプリを開く頻度は徐々に増加し、0 日から 100 日にかけて収束することもあります。また、2 番目の保持率、7 番目の保持率、および DAU 指標の改善も促進します (0.1% の DAU と 2 番目の保持率の 0.01% の改善は、統計的に有意であると考えられます)。
以上がKuaishou ユーザー維持率を向上させるために強化学習を使用する方法は?の詳細内容です。詳細については、PHP 中国語 Web サイトの他の関連記事を参照してください。

ホットAIツール

Undresser.AI Undress
リアルなヌード写真を作成する AI 搭載アプリ

AI Clothes Remover
写真から衣服を削除するオンライン AI ツール。

Undress AI Tool
脱衣画像を無料で

Clothoff.io
AI衣類リムーバー

AI Hentai Generator
AIヘンタイを無料で生成します。

人気の記事
ホットツール

メモ帳++7.3.1
使いやすく無料のコードエディター

SublimeText3 中国語版
中国語版、とても使いやすい

ゼンドスタジオ 13.0.1
強力な PHP 統合開発環境

ドリームウィーバー CS6
ビジュアル Web 開発ツール

SublimeText3 Mac版
神レベルのコード編集ソフト(SublimeText3)
ホットトピック



 CLIP-BEVFormer: BEVFormer 構造を明示的に監視して、ロングテール検出パフォーマンスを向上させます。
Mar 26, 2024 pm 12:41 PM
CLIP-BEVFormer: BEVFormer 構造を明示的に監視して、ロングテール検出パフォーマンスを向上させます。
Mar 26, 2024 pm 12:41 PM
上記および筆者の個人的な理解: 現在、自動運転システム全体において、認識モジュールが重要な役割を果たしている。道路を走行する自動運転車は、認識モジュールを通じてのみ正確な認識結果を得ることができる。下流の規制および制御モジュール自動運転システムでは、タイムリーかつ正確な判断と行動決定が行われます。現在、自動運転機能を備えた自動車には通常、サラウンドビューカメラセンサー、ライダーセンサー、ミリ波レーダーセンサーなどのさまざまなデータ情報センサーが搭載されており、さまざまなモダリティで情報を収集して正確な認識タスクを実現しています。純粋な視覚に基づく BEV 認識アルゴリズムは、ハードウェア コストが低く導入が容易であるため、業界で好まれており、その出力結果はさまざまな下流タスクに簡単に適用できます。
 C++ での機械学習アルゴリズムの実装: 一般的な課題と解決策
Jun 03, 2024 pm 01:25 PM
C++ での機械学習アルゴリズムの実装: 一般的な課題と解決策
Jun 03, 2024 pm 01:25 PM
C++ の機械学習アルゴリズムが直面する一般的な課題には、メモリ管理、マルチスレッド、パフォーマンスの最適化、保守性などがあります。解決策には、スマート ポインター、最新のスレッド ライブラリ、SIMD 命令、サードパーティ ライブラリの使用、コーディング スタイル ガイドラインの遵守、自動化ツールの使用が含まれます。実践的な事例では、Eigen ライブラリを使用して線形回帰アルゴリズムを実装し、メモリを効果的に管理し、高性能の行列演算を使用する方法を示します。
 Panda-Gym のロボット アーム シミュレーションを使用した Deep Q-learning 強化学習
Oct 31, 2023 pm 05:57 PM
Panda-Gym のロボット アーム シミュレーションを使用した Deep Q-learning 強化学習
Oct 31, 2023 pm 05:57 PM
強化学習 (RL) は、エージェントが試行錯誤を通じて環境内でどのように動作するかを学習できる機械学習手法です。エージェントは、望ましい結果につながるアクションを実行すると、報酬または罰を受けます。時間の経過とともに、エージェントは期待される報酬を最大化するアクションを取ることを学習します。RL エージェントは通常、逐次的な決定問題をモデル化するための数学的フレームワークであるマルコフ決定プロセス (MDP) を使用してトレーニングされます。 MDP は 4 つの部分で構成されます。 状態: 環境の可能な状態のセット。アクション: エージェントが実行できる一連のアクション。遷移関数: 現在の状態とアクションを考慮して、新しい状態に遷移する確率を予測する関数。報酬機能:コンバージョンごとにエージェントに報酬を割り当てる機能。エージェントの目標は、ポリシー機能を学習することです。
 C++sort 関数の基礎となる原則とアルゴリズムの選択を調べる
Apr 02, 2024 pm 05:36 PM
C++sort 関数の基礎となる原則とアルゴリズムの選択を調べる
Apr 02, 2024 pm 05:36 PM
C++sort 関数の最下層はマージ ソートを使用し、その複雑さは O(nlogn) で、クイック ソート、ヒープ ソート、安定したソートなど、さまざまなソート アルゴリズムの選択肢を提供します。
 人工知能は犯罪を予測できるのか? CrimeGPT の機能を調べる
Mar 22, 2024 pm 10:10 PM
人工知能は犯罪を予測できるのか? CrimeGPT の機能を調べる
Mar 22, 2024 pm 10:10 PM
人工知能 (AI) と法執行機関の融合により、犯罪の予防と検出の新たな可能性が開かれます。人工知能の予測機能は、犯罪行為を予測するためにCrimeGPT (犯罪予測技術) などのシステムで広く使用されています。この記事では、犯罪予測における人工知能の可能性、その現在の応用、人工知能が直面する課題、およびこの技術の倫理的影響について考察します。人工知能と犯罪予測: 基本 CrimeGPT は、機械学習アルゴリズムを使用して大規模なデータセットを分析し、犯罪がいつどこで発生する可能性があるかを予測できるパターンを特定します。これらのデータセットには、過去の犯罪統計、人口統計情報、経済指標、気象パターンなどが含まれます。人間のアナリストが見逃す可能性のある傾向を特定することで、人工知能は法執行機関に力を与えることができます
 改良された検出アルゴリズム: 高解像度の光学式リモートセンシング画像でのターゲット検出用
Jun 06, 2024 pm 12:33 PM
改良された検出アルゴリズム: 高解像度の光学式リモートセンシング画像でのターゲット検出用
Jun 06, 2024 pm 12:33 PM
01 今後の概要 現時点では、検出効率と検出結果の適切なバランスを実現することが困難です。我々は、光学リモートセンシング画像におけるターゲット検出ネットワークの効果を向上させるために、多層特徴ピラミッド、マルチ検出ヘッド戦略、およびハイブリッドアテンションモジュールを使用して、高解像度光学リモートセンシング画像におけるターゲット検出のための強化されたYOLOv5アルゴリズムを開発しました。 SIMD データセットによると、新しいアルゴリズムの mAP は YOLOv5 より 2.2%、YOLOX より 8.48% 優れており、検出結果と速度のバランスがより優れています。 02 背景と動機 リモート センシング技術の急速な発展に伴い、航空機、自動車、建物など、地表上の多くの物体を記述するために高解像度の光学式リモート センシング画像が使用されています。リモートセンシング画像の判読における物体検出
 58 ポートレート プラットフォームの構築におけるアルゴリズムの適用
May 09, 2024 am 09:01 AM
58 ポートレート プラットフォームの構築におけるアルゴリズムの適用
May 09, 2024 am 09:01 AM
1. 58 Portraits プラットフォーム構築の背景 まず、58 Portraits プラットフォーム構築の背景についてお話ししたいと思います。 1. 従来のプロファイリング プラットフォームの従来の考え方ではもはや十分ではありません。ユーザー プロファイリング プラットフォームを構築するには、複数のビジネス分野からのデータを統合して、ユーザーの行動や関心を理解するためのデータ マイニングも必要です。最後に、ユーザー プロファイル データを効率的に保存、クエリ、共有し、プロファイル サービスを提供するためのデータ プラットフォーム機能も必要です。自社構築のビジネス プロファイリング プラットフォームとミドルオフィス プロファイリング プラットフォームの主な違いは、自社構築のプロファイリング プラットフォームは単一のビジネス ラインにサービスを提供し、オンデマンドでカスタマイズできることです。ミッドオフィス プラットフォームは複数のビジネス ラインにサービスを提供し、複雑な機能を備えていることです。モデリングを提供し、より一般的な機能を提供します。 2.58 中間プラットフォームのポートレート構築の背景のユーザーのポートレート 58
 20 分で回路基板の組み立てを学びましょう!オープンソースの SERL フレームワークは 100% の精度制御成功率を誇り、人間の 3 倍高速です
Feb 21, 2024 pm 03:31 PM
20 分で回路基板の組み立てを学びましょう!オープンソースの SERL フレームワークは 100% の精度制御成功率を誇り、人間の 3 倍高速です
Feb 21, 2024 pm 03:31 PM
現在、ロボットは精密な工場制御タスクを学習できるようになりました。近年、ロボットの強化学習技術の分野では、四足歩行や掴み、器用な操作など大きな進歩が見られますが、その多くは実験室での実証段階にとどまっています。ロボット強化学習テクノロジーを実際の運用環境に広く適用するには、依然として多くの課題があり、実際のシナリオでの適用範囲がある程度制限されます。強化学習技術の実用化の過程では、報酬メカニズムの設定、環境のリセット、サンプル効率の向上、行動の安全性の保証など、複数の複雑な問題を克服する必要があります。業界の専門家は、強化学習テクノロジーの実際の実装における多くの問題を解決することは、アルゴリズム自体の継続的な革新と同じくらい重要であると強調しています。この課題に直面して、カリフォルニア大学バークレー校、スタンフォード大学、ワシントン大学、および
